

Python逆向爬虫之scrapy框架,非常详细 - Alvin,
source link: https://www.cnblogs.com/chenyangqit/p/16595123.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
加VX:Alvins0918 领取更多资料
Python逆向爬虫之scrapy框架,非常详细
一、爬虫入门
那么,我相信初学的小伙伴现在一定是似懂非懂的。那么下面我们通过一个案例来慢慢进行分析,具体如下:
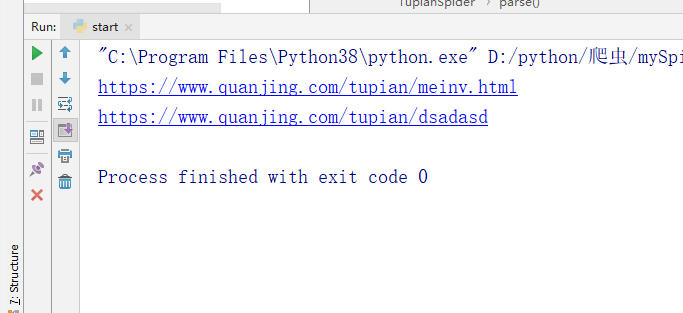
今天,我们的目标是一个图片网站,https://www.quanjing.com/tupian/meinv-1.html
首先,我们第一步需要做的就是项目分析,我们来看看爬取这个网站我们需要哪些步骤。
1.1 定义需求
需求就是将该网站中所有的美女图片分类下载到本地。

1.2 需求分析
如果我们需要下载上面所表示的所有的图片的话,我们需要如下几个步骤:
- 下载某个页面上所有的图片
- 进行下载图片
1.2.1 下载某个页面上所有的图片
# -*- coding: utf-8 -*-
import requests
from lxml import etree
import urllib3
urllib3.disable_warnings()
def getClassification(num):
"""
获取分类链接
:return:
"""
url = f"https://www.quanjing.com/tupian/meinv-{num}.html"
html = sendRequest(url, "get")
htmlValus = htmlAnalysis(html.text, '//*[@id="gallery-list"]/li')
for item in htmlValus:
imgUrl = item.xpath('./a/img/@src')[0]
downLoad(imgUrl)
def downLoad(url):
"""
下载图片
:param url:
:return:
"""
img = sendRequest(url)
imgName = url.split("@")[0].split("/")[-1]
with open("./quanjing/" + imgName, 'wb') as imgValue:
imgValue.write(img.content)
def htmlAnalysis(html, rule):
"""
根据 xpath 获取数据
:param html:
:param rule:
:return:
"""
htmlValues = etree.HTML(html)
value = htmlValues.xpath(rule)
return value
def sendRequest(url, method="get"):
"""
发送请求
:param url:
:param method:
:return:
"""
if method.lower() == "get":
html = requests.get(url=url, headers=getHeader(), verify=False)
elif method.lower() == "post":
html = requests.post(url=url, headers=getHeader())
else:
html = None
return html
def getHeader():
"""
获取Header
:return:
"""
ua_headers = {
"User-Agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36',
"referer": "https://www.quanjing.com/"
}
return ua_headers
def main():
getClassification(1)
if __name__ == '__main__':
main()
1.2.2 分页
def main():
for i in range(10):
getClassification(i)
1.2.3 进行下载图片
def downLoad(url):
"""
下载图片
:param url:
:return:
"""
img = sendRequest(url)
imgName = url.split("@")[0].split("/")[-1]
with open("./quanjing/" + imgName, 'wb') as imgValue:
imgValue.write(img.content)
二、Scrapy 入门
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。
下面我们给出一个 Scrapy 的架构图
上面的架构图明确的说明了 Scrapy 主要有 5 个部分。
- 引擎(Scrapy Engine):引擎负责控制数据流在系统中所有组件中流动,并在相应动作发生时触发事件。
- 管道(Pipline):主要提供存储服务,把需要存储的数据存储到相关数据库之中。
- 调度器(Scheduler):主要提供两个功能,分别是 去重 和 队列。
- 下载器(Downloader):下载器负责获取页面数据并提供给引擎,而后提供给spider。
- 爬虫(Spiders):Spider是Scrapy用户编写用于分析response并提取item(即获取到的item)或额外跟进的URL的类。 每个spider负责处理一个特定(或一些)网站。
其实除了上述的内容外,Scrapy 还提供一些中间件,例如:下载器中间件(Downloader Middlewares)和爬虫中间件(Spider Middlewares)等。
所以,把上面完整的图可以画成如下:

2.1 安装 Scrapy
在命令行模式下使用pip命令即可安装。
$ pip install scrapy
2.2 Scrapy 创建项目
第一步:创建一个scrapy项目
$ scrapy startproject mySpider
第二步:生成一个爬虫
$ cd mySpider
$ scrapy genspider tupian https://www.quanjing.com/
2.3 scrapy 命令
#1 查看帮助
scrapy -h
scrapy <command> -h
#2 有两种命令:其中Project-only必须切到项目文件夹下才能执行,而Global的命令则不需要
Global commands:
startproject #创建项目
genspider #创建爬虫程序
settings #如果是在项目目录下,则得到的是该项目的配置
runspider #运行一个独立的python文件,不必创建项目
shell #scrapy shell url地址 在交互式调试,如选择器规则正确与否
fetch #独立于程单纯地爬取一个页面,可以拿到请求头
view #下载完毕后直接弹出浏览器,以此可以分辨出哪些数据是ajax请求
version #查看scrapy的版本
Project-only commands:
crawl #运行爬虫,必须创建项目才行,确保配置文件中ROBOTSTXT_OBEY = False
check #检测项目中有无语法错误
list #列出项目中所包含的爬虫名
edit #编辑器,一般不用
parse #scrapy parse url地址 --callback 回调函数
bench #scrapy bentch压力测试
#3 官网链接
https://docs.scrapy.org/en/latest/topics/commands.html
2.4 生成文件详情
- scrapy.cfg:项目的主配置信息,用来部署scrapy时使用,爬虫相关的配置信息在settings.py文件中。
- items.py:设置数据存储模板,用于结构化数据,如:Django的Model
- pipelines:数据处理行为,如:一般结构化的数据持久化
- settings.py:配置文件。
- spiders:爬虫目录,如:创建文件,编写爬虫规则
2.5 第一个 scrapy 爬虫程序
2.5.1 编辑 spider
import scrapy
from ..items import MyspiderItem
class TupianSpider(scrapy.Spider):
# 定义爬虫名,scrapy会根据该值定位爬虫程序,所以它必须要有且必须唯一
name = 'tupian'
# 定义允许爬取的域名,如果OffsiteMiddleware启动(默认就启动),
# 那么不属于该列表的域名及其子域名都不允许爬取
allowed_domains = ['www.quanjing.com']
# 如果没有指定url,就从该列表中读取url来生成第一个请求
start_urls = ['https://www.quanjing.com/tupian/meinv.html']
# 爬虫启动函数,必须定义成这个函数名称
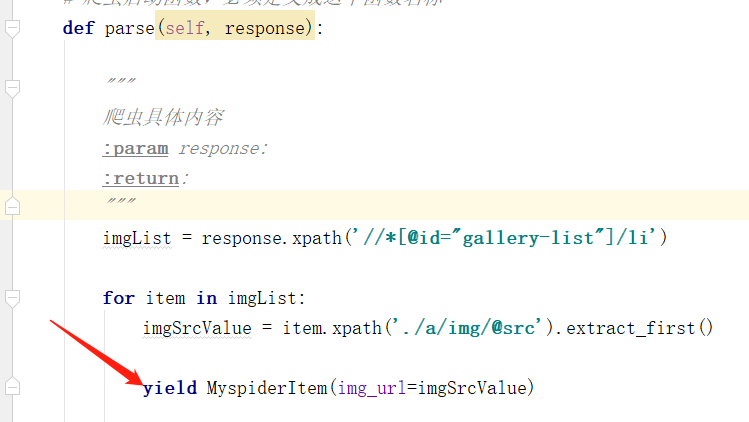
def parse(self, response):
imgList = response.xpath('//*[@id="gallery-list"]/li')
for item in imgList:
imgSrcValue = item.xpath('./a/img/@src').get()
yield MyspiderItem(img_url=imgSrcValue)
2.5.2 编辑 piplines
from itemadapter import ItemAdapter
class MyspiderPipeline:
def process_item(self, item, spider):
print(item)
return item
2.5.3 编辑配置文件
# 设置日志的级别
LOG_LEVEL = "WARNING"
# 关闭 Robots.txt 协议
ROBOTSTXT_OBEY = False
# 开启 pipelines
ITEM_PIPELINES = {
'mySpider.pipelines.MyspiderPipeline': 300,
}
from scrapy import cmdline
# 方法 1
cmdline.execute('scrapy crawl yourspidername'.split())
# 方法 2
sys.argv = ['scrapy', 'crawl', 'down_info_spider']
cmdline.execute()
三、Scrapy Spider
Spider 负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器)。
总结 Spider 主要有三个作用,分别是:链接配置、抓取逻辑和解析逻辑。
Spider 的整个爬取循环过程如下:
- 以初始的 URL 初始化 Request ,并设置回调函数。当该 Request 成功请求并返回时, Response 生成并作为参数传给该回调函数。
- 在回调函数内分析返回的网页内容 。 返回结果有两种形式:
- 一种是解析到的有效结果返回字典或 Item 对象,它们可以经过处理后(或直接)保存
- 另一种是解析得到下一个(如下一页)链接,可以利用此链接构造 Request 并设置新的回调函数,返回 Request 等待后续调度
- 如果返回的是字典或 Item 对象,我们可通过 Feed Exports 等组件将返回结果存入到文件。 如果设置了 Pipeline 的话,我们可以使用 Pipeline 处理 (如过滤、修正等)并保存。
- 如果返回的是 Request ,那么 Request 执行成功得到 Response 之后, Response 会被传递给Request 中定义的回调函数,在回调函数中我们可以再次使用选择器来分析新得到的网页内容,并根据分析的数据生成 Item。
3.1 Spider 详细
Spider 继承自 scrapy.spiders.Spider。scrapy.spiders.Spider 这个类是最简单最基本的 Spider 类,其他 Spider 必须继承这个类。scrapy.spiders.Spider 类提供了start_requests()方法的默认实现,读取并请求 start_urls 属性 ,并根据返回的结果调用 parse() 方法解析结果 。
它有如下一些基础属性:
-
name:爬虫名称,是定义 Spider 名字的字符串。Spider 的名字定义了 Scrapy 如何定位并初始化 Spider ,它必须是唯一的。不过我们可以生成多个相同的 Spider 实例,数量没有限制。name 是 Spider 最重要的属性 。 如果 Spider 爬取单个网站, 一个常见的做法是以该网站的域名名称来命名 Spider。 例如, Spider 爬取 mywebsite.com , 该 Spider通常会被命名为 mywebsite。
-
allowed_domains:允许爬取的域名,是可选配置,不在此范围的链接不会被跟进爬取 。 -
start_urls:它是起始 URL 列表,当我们没有实现start_requests()方法时,默认会从这个列表开始抓取。 -
custom_settings:它是一个字典,是专属于本 Spider 的配置,此设置会覆盖项目全局的设置。此设置必须在初始化前被更新,必须定义成类变量。不同爬虫pipeline设置 custom_settings = { 'ITEM_PIPELINES': { 'video.pipelines.VideoPipeline': 301, } } -
crawler:它是由from_crawler()方法设置的,代表的是本 Spider 类对应的 Crawler 对象 。Crawler 对象包含了很多项目组件,利用它我们可以获取项目的一些配置信息,如最常见的获取项目的设置信息,即 Settings。 -
settings:它是一个 Settings 对象,利用它我们可以直接获取项目的全局设置变量 。
除了基础属性,Spider 还有一些常用的方法。
start_requests():此方法用于生成初始请求,它必须返回一个可迭代对象,该方法可以被重写。此方法会默认使用 start_urls 里面的 URL 来构造 Request,而且 Request 默认是 GET 请求方式。如果我们想在启动时以 POST方式访问某个站点,可以直接重写这个方法,发送 POST请求时使用FormRequest即可 。parse(response):当 Response 没有指定回调函数时,该方法会默认被调用 。 它负责处理 Response 处理返回结果,并从中提取出想要的数据和下一步的请求,然后返回。该方法需要返回一个包含Request或ltem的可迭代对象。closed(reason):当 Spider 关闭时,该方法会被调用,在这里一般会定义释放资源的一些操作或其他收尾操作。
import scrapy
from ..items import MyspiderItem
class TupianSpider(scrapy.Spider):
# 定义爬虫名,scrapy会根据该值定位爬虫程序,所以它必须要有且必须唯一
name = 'tupian'
# 定义允许爬取的域名,如果OffsiteMiddleware启动(默认就启动),
# 那么不属于该列表的域名及其子域名都不允许爬取
allowed_domains = ['www.quanjing.com']
# 如果没有指定url,就从该列表中读取url来生成第一个请求
start_urls = ['https://www.quanjing.com/tupian/meinv.html']
def start_requests(self):
"""
开始请求之前的执行
:return:
"""
print("我是开始")
yield scrapy.Request(
url=self.start_urls[0],
callback=self.parse
)
# 爬虫启动函数,必须定义成这个函数名称
def parse(self, response):
"""
爬虫具体内容
:param response:
:return:
"""
print("我是 parse")
imgList = response.xpath('//*[@id="gallery-list"]/li')
for item in imgList:
imgSrcValue = item.xpath('./a/img/@src').get()
yield MyspiderItem(img_url=imgSrcValue)
def close(spider, reason):
"""
结束时调用
:param reason:
:return:
"""
print("关闭")
return None
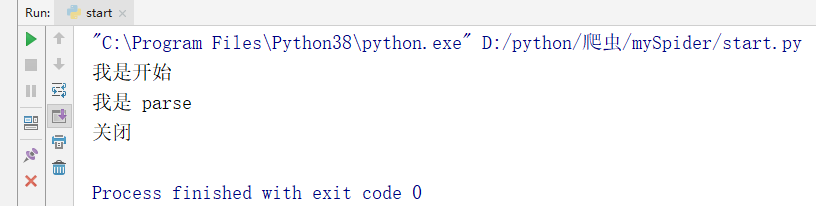
3.2 spider常用的方法
3.2.1 解析常用的几个方法
我们可以通过 scrapy.selector.unified.SelectorList 对象来查找get()、getall()、extract()、extract_first()、re.first()的如何使用。
- extract()方法:获取的是一个列表内容
def parse(self, response):
"""
爬虫具体内容
:param response:
:return:
"""
imgList = response.xpath('//*[@id="gallery-list"]/li').extract()
print(imgList)
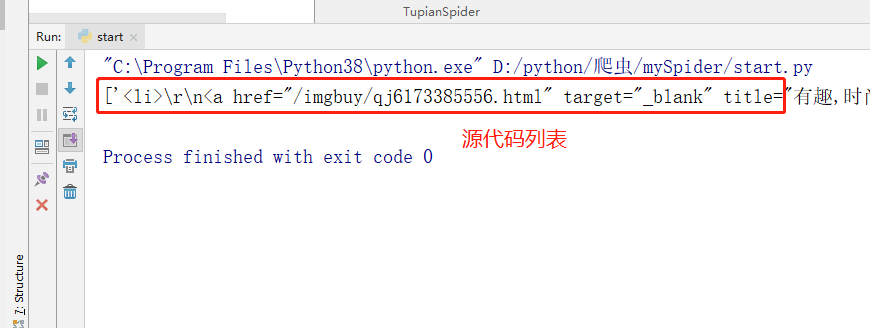
- extract_first()方法:返回列表的第一个内容,也就是extract()列表的第一个元素
def parse(self, response):
"""
爬虫具体内容
:param response:
:return:
"""
imgList = response.xpath('//*[@id="gallery-list"]/li').extract_first()
print(imgList)
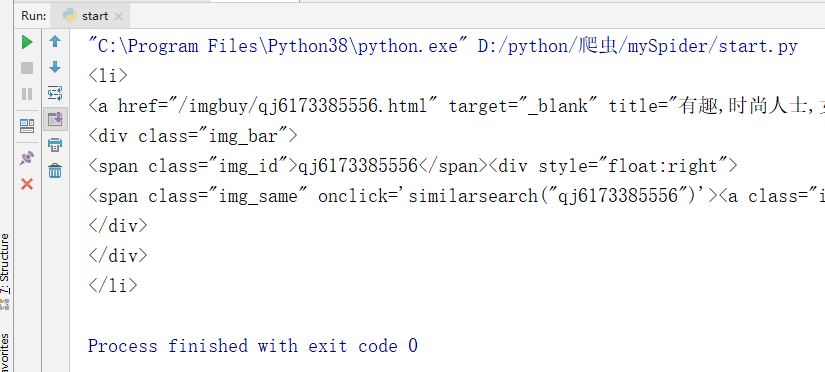
- getall()方法:返回所有的元素
imgList = response.xpath('//*[@id="gallery-list"]/li').extract_first()
print(imgList)
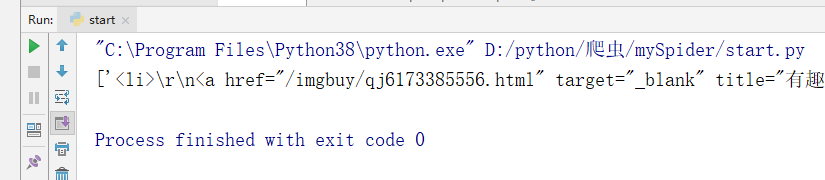
- get()方法:返回第一个元素,是str类型数据
def parse(self, response):
"""
爬虫具体内容
:param response:
:return:
"""
imgList = response.xpath('//*[@id="gallery-list"]/li').get()
print(imgList)
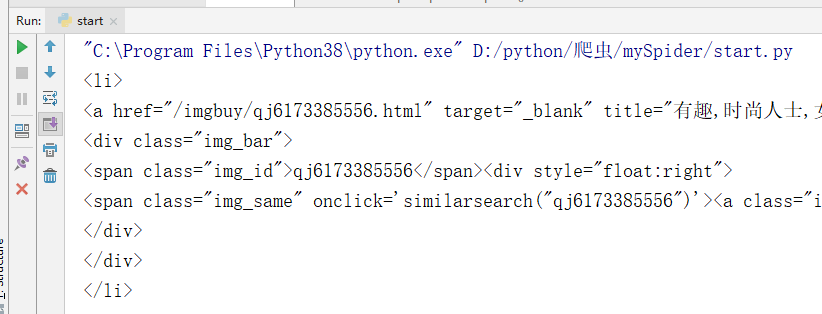
- re()方法:正则的使用。返回所以的满足条件,结果是列表类型
def parse(self, response):
"""
爬虫具体内容
:param response:
:return:
"""
imgList = response.xpath('//*[@id="gallery-list"]/li').re("\d+")
print(imgList)
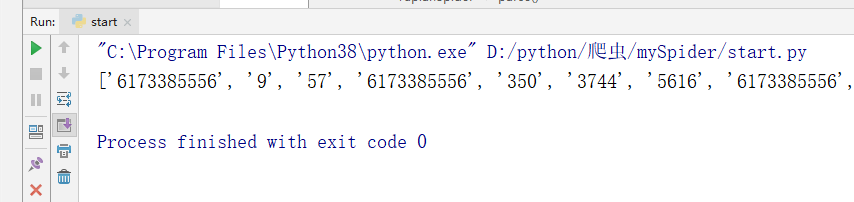
- re_first()方法:正则使用,返回的是满足条件第一个元素
def parse(self, response):
"""
爬虫具体内容
:param response:
:return:
"""
imgList = response.xpath('//*[@id="gallery-list"]/li').re_first("\d+")
print(imgList)
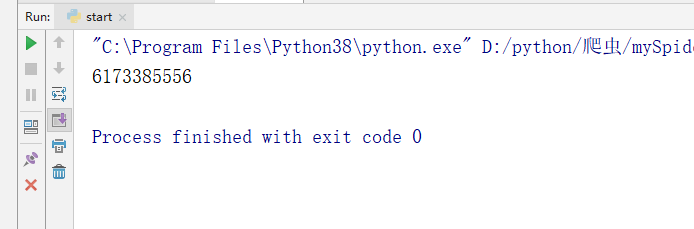
3.2.2 response 常用的几个方法
常见的几个 response 方法。
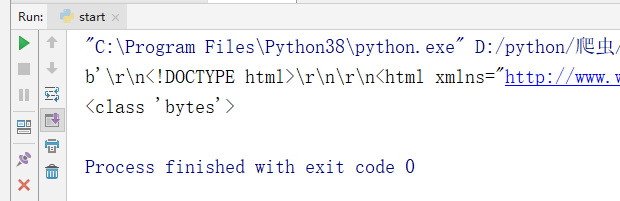
- response.body.decode("utf-8"):返回 HTML 并设置字符集编码

- response.body:以 bytes 类型返回请求的 HTML 。
- response.url:返回 URL
print(response.url)
- response.urljoin("dsadasd"):返回 URL 拼接后的结果
print(response.urljoin("dsadasd"))
- response.encoding:返回请求状态码
四、Scrapy Pipline
当 Item 在 Spider 中被收集之后,就会被传递到 Item Pipeline 中进行处理。
每个 item pipeline 组件是实现了简单的方法的 python 类,负责接收到 item 并通过它执行一些行为,同时也决定此 Item 是否继续通过 pipeline ,或者被丢弃而不再进行处理。
item pipeline 的主要作用:清理html数据、验证爬取的数据、去重并丢弃和保存数据。
每个pipeline组件是一个独立的 pyhton 类,必须实现以process_item(self, item,spider) 方法。
每个item pipeline组件都需要调用该方法,这个方法必须返回一个具有数据的 dict,或者 item对象,或者抛出 DropItem 异常,被丢弃的 item 将不会被之后的 pipeline 组件所处理。
注意:如果要使用哪一个 pipeline ,必须在配置文件中配置 ITEM_PIPELINES。
4.1 pipeline 中的函数
scrapy pipeline 中主要的函数有 open_spider(self,spider)、close_spider(self,spider)和from_crawler(cls,crawler)。
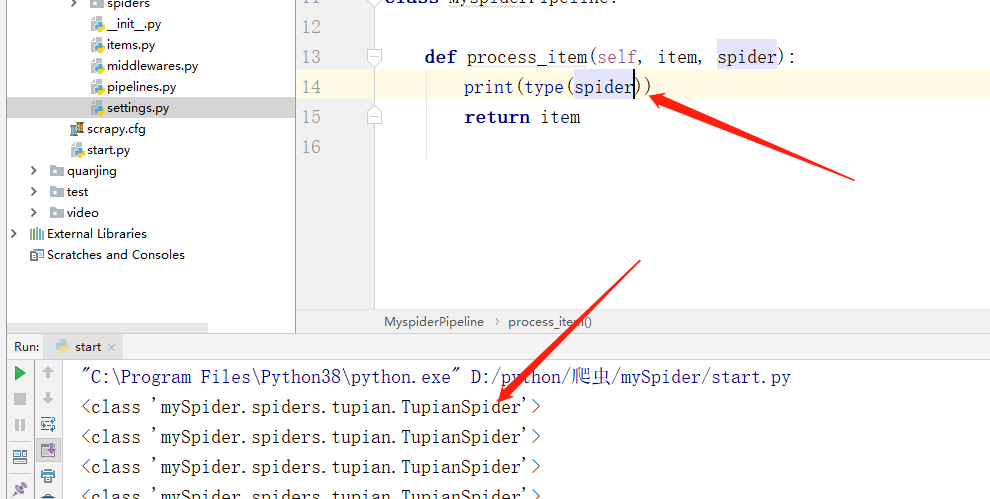
4.1.1 process_item(self, item, spider)
表示当 spider 被开启的时候调用的主方法。
class MyspiderPipeline:
def process_item(self, item, spider):
print(item)
return item
其中,item 参数是 spider 返回的数据。
spider 是调用该管道的 spider。
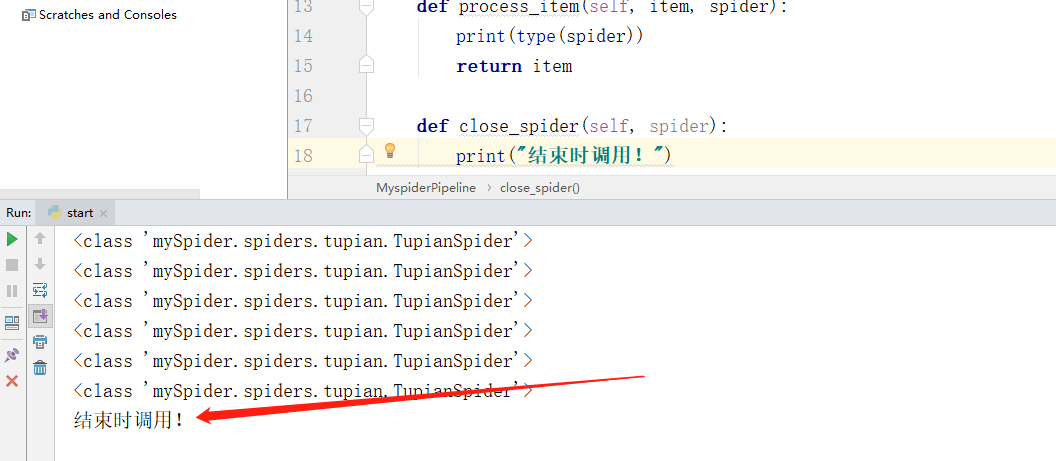
4.1.2 close_spider(self,spider)
当 spider 结束的时候这个方法被调用。
class MyspiderPipeline:
def process_item(self, item, spider):
print(type(spider))
return item
def close_spider(self, spider):
print("结束时调用!")
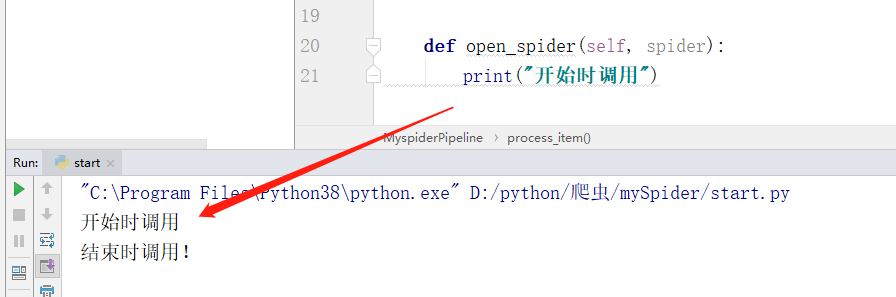
4.1.3 open_spider(self,spider)
表示当 spider 被开启的时候调用这个方法。
def open_spider(self, spider):
print("开始时调用")
4.1.4 from_crawler(cls,crawler)
获取参数。
@classmethod
def from_crawler(cls, crawler):
log_level = crawler.settings.get('LOG_LEVEL')
# FIXME: for now, stats are only supported from this constructor
return cls(log_level)
def __init__(self, log_level):
self.log_level = log_level
但是,scrapy 还提供一个新的获取配置的方法。
from scrapy.utils.project import get_project_settings
settings = get_project_settings()
print(settings.get('LOG_LEVEL'))
4.2 scrapy 自带的 pipeline
scrapy 默认携带了很多常用的中间件。下面我们来跟大家介绍几个常用的自带中间件。
4.2.1 FilesPipeline
文件下载中间件。
注意:使用 ImagesPipeline 首先定义存储文件的路径,所以需要定义一个FILES_STORE变量,在settings.py中添加如下代码:
FILES_STORE = "./quanjing/"
1. get_media_requests
设置下载文件时的请求头, 并返回一个 request 对象。
def get_media_requests(self, item, info):
"""
设置下载文件时的请求头, 返回一个 request 对象
:param item:
:param info:
:return:
"""
yield scrapy.Request(item['img_url'], meta={'Referer': item['img_url']})
2. file_path
设置下载文件的名称。
def file_path(self, request, response=None, info=None, *, item=None):
"""
设置下载路径
:param request:
:param response:
:param info:
:param item:
:return:
"""
return request.url.split("@")[0].split("/")[-1]
4.2.2 ImagesPipeline
图片下载管道。
注意:使用 ImagesPipeline 首先定义存储文件的路径,所以需要定义一个IMAGES_STORE变量,在settings.py中添加如下代码:
IMAGES_STORE = './images'
1. get_media_requests
设置下载文件时的请求头, 并返回一个 request 对象。
def get_media_requests(self, item, info):
"""
设置下载文件时的请求头, 返回一个 request 对象
:param item:
:param info:
:return:
"""
yield scrapy.Request(item['img_url'], meta={'Referer': item['img_url']})
2. file_path
设置下载文件的名称。
def file_path(self, request, response=None, info=None, *, item=None):
"""
设置下载路径
:param request:
:param response:
:param info:
:param item:
:return:
"""
return request.url.split("@")[0].split("/")[-1]
3. item_completed
当下载结束之后调用。
def item_completed(self, results, item, info):
"""
当下载文件结束之后调用
:param results:
:param item:
:param info:
:return:
"""
image_path = []
error_path = []
for ok, x in results:
if ok:
image_path.append(x)
else:
error_path.append(x)
print(error_path)
print(image_path)
return item
# []
# [{'url': 'https://pic.quanjing.com/9e/57/QJ6173385556.jpg@!350h', 'path': 'QJ6173385556.jpg', 'checksum': 'e5af2c0cf607b968c1e7eec24e4934ac', 'status': 'uptodate'}]
五、scrapy 中间件
scrapy 中间件是 scrapy框架的重要组成部分,主要分为两大种类,分别是:下载器中间件(DownloaderMiddleware)和 爬虫中间件(SpiderMiddleware)。
引擎(engine)将 request 对象交给下载器之前,会经过下载器中间件;并且 scrapy 是支持同时使用多个中间件的。多个中间件之间遵循先进后出的原理。
5.1 下载中间件(DownloaderMiddleware)
位于 Scrapy 引擎和下载器之间,主要用来处理从 EGINE 传到 DOWLOADER 的请求 request 和已经从 DOWNLOADER 传到 EGINE 的响应 response。在这个过程中你可用该中间件做以下几件事,分别是:添加ip代理、添加cookie、添加UA 和 请求重试 等。

在下载中间件中,主要包含了 process_request(request, spider)、process_response(request, response, spider) 和 process_exception(request, exception, spider)三个函数。
5.1.1 process_request(request, spider)
当每个request通过下载中间件时,该方法被调用。process_request() 必须返回其中之一: 返回 None 、返回一个 Response 对象、返回一个 Request 对象或raise IgnoreRequest 。
- 返回 None 时,,Scrapy 将继续处理该 request,执行其他的中间件的相应方法,直到合适的下载器处理函数 (download handler) 被调用, 该request被执行(其response被下载)。
- 如果其返回 Response 对象,Scrapy将不会调用 任何 其他的 process_request() 或 process_exception() 方法,或相应地下载函数; 其将返回该response。 已安装的中间件的 process_response() 方法则会在每个response返回时被调用。
- 如果其返回 Request 对象,Scrapy 则停止调用 process_request 方法并重新调度返回的 request。当新返回的 request 被执行后, 相应地中间件链将会根据下载的 response 被调用。
- 如果其 raise 一个 IgnoreRequest 异常,则安装的下载中间件的 process_exception() 方法会被调用。如果没有任何一个方法处理该异常, 则 request 的 errback(Request.errback) 方法会被调用。如果没有代码处理抛出的异常, 则该异常被忽略且不记录(不同于其他异常那样)。
5.1.2 process_response(request, response, spider)
当下载器完成HTTP请求,传递响应给引擎的时候调用,它会返回 Response、Request、IgnoreRequest三种对象的一种。
- 若返回 Response 对象,它会被下个中间件中的 process_response() 处理
- 若返回 Request 对象,中间链停止,然后返回的 Request 会被重新调度下载
- 抛出 IgnoreRequest,回调函数 Request.errback 将会被调用处理,若没处理,将会忽略
5.1.3 process_exception(request, exception, spider)
当下载处理器 (download handler) 或 process_request() 抛出异常(包括 IgnoreRequest 异常)时, Scrapy 调用 process_exception() ,通常返回 None,它会一直处理异常
5.1.3 下载图片案例
- tupian.py
import scrapy
from ..items import MyspiderItem
class TupianSpider(scrapy.Spider):
# 定义爬虫名,scrapy会根据该值定位爬虫程序,所以它必须要有且必须唯一
name = 'tupian'
# 定义允许爬取的域名,如果OffsiteMiddleware启动(默认就启动),
# 那么不属于该列表的域名及其子域名都不允许爬取
allowed_domains = ['www.quanjing.com', 'pic.quanjing.com']
# 如果没有指定url,就从该列表中读取url来生成第一个请求
start_urls = ['https://www.quanjing.com/tupian/meinv.html']
# 爬虫启动函数,必须定义成这个函数名称
def parse(self, response):
"""
爬虫具体内容
:param response:
:return:
"""
imgList = response.xpath('//*[@id="gallery-list"]/li')
ua_header = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Language': 'zh-CN,zh;q=0.9',
"Referer": "https://www.quanjing.com/"
}
for item in imgList:
imgSrcValue = item.xpath('./a/img/@src').extract_first()
yield scrapy.Request(
url=imgSrcValue,
callback=self.parse_detail,
headers=ua_header,
meta={ "img_url": imgSrcValue }
)
def parse_detail(self, response):
"""
图片详情
:param response:
:return:
"""
item = MyspiderItem()
item['img_url'] = response.meta['img_url']
item['img_body'] = response.body
yield item
- item.py
import scrapy
class MyspiderItem(scrapy.Item):
# define the fields for your item here like:
img_url = scrapy.Field()
img_body = scrapy.Field()
- pipeline.py
class MyspiderPipeline:
def process_item(self, item, spider):
settings = get_project_settings()
with open(settings['IMAGES_STORE'] + item['img_url'].split("@")[0].split("/")[-1], 'wb') as f:
f.write(item['img_body'])
return item
- setting.py
IMAGES_STORE = "./quanjing/"
5.2 scrapy 爬虫(spider)中间件
spider 中间件是一个与 Scrapy 的 spider 处理机制挂钩的框架,您可以在其中插入自定义功能来处理发送给spider进行处理的响应,并处理从 spider 生成的请求和项目。
5.2.1 激活 Spider 中间件
要激活蜘蛛中间件组件,请将其添加到 SPIDER_MIDDLEWARES设置中,这是一个 dict,其键是中间件类路径,它们的值是中间件顺序。
SPIDER_MIDDLEWARES = {
'mySpider.middlewares.MyspiderSpiderMiddleware': 543,
}
5.2.2 Spider 中间件
spider 中间件主要是作用于引擎和调度器之间的。
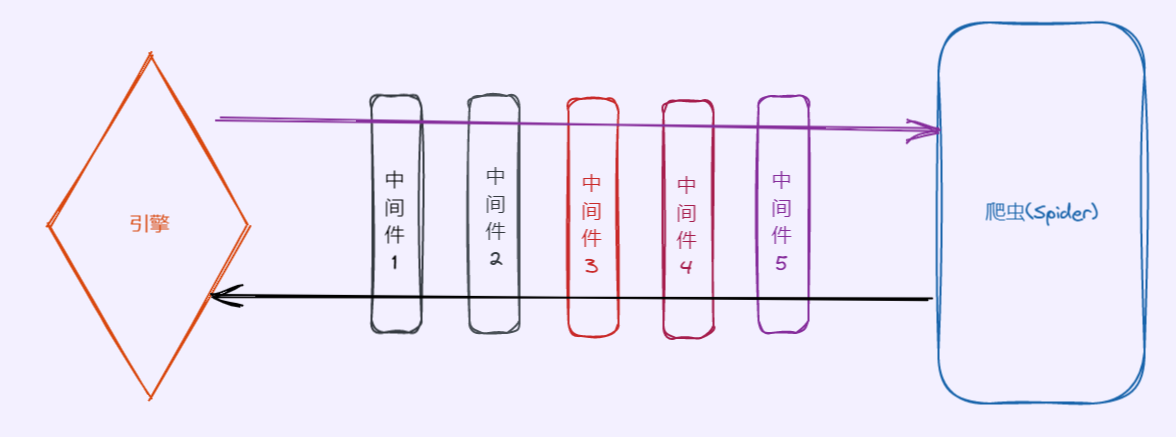
- from_crawler:类方法,用于初始化中间件
- process_spider_input:当 response 通过 spider 中间件时,该方法被调用,处理该 response
- process_spider_output:当 Spider 处理 response 返回 result 时,该方法被调用
- process_spider_exception:异常时,该方法被调用
- process_start_requests:该方法以 spider 启动的 request 为参数被调用,执行的过程类似于
- process_spider_outpu ,只不过其没有相关联的 response 并且必须返回 request(不是item)。
调用顺序为:from_crawler --> spider_opened --> process_start_requests --> process_spider_input --> process_spider_output。
5.3 Scrapy 自带中间件
scrapy 默认自带了一部分常用的中间件。下面我们举几个案例介绍一些 Scrapy 自带的中间件。
5.3.1 HttpProxyMiddleware 代理中间件
middlewares.py
class RequestProxyMiddleware(HttpProxyMiddleware):
def process_request(self, request, spider):
settings = get_project_settings()
self.proxies = settings.get("HTTP_PROXY")
request.meta["proxy"] = random.choice(self.proxies)
return None
settings.py
DOWNLOADER_MIDDLEWARES = {
'mySpider.middlewares.RequestProxyMiddleware': 544
}
HTTP_PROXY = {
"47.92.113.71:80",
"59.124.224.205:3128",
"118.163.13.200:8080",
"47.57.188.208:80",
"59.124.224.205:3128",
"59.124.224.205:3128",
"59.124.224.205:3128",
"112.250.107.37:53281",
"59.124.224.205:3128",
"47.92.113.71:80",
"59.124.224.205:3128"
}
六、CrawlSpider全站数据抓取
CrawlSpider 其实是 Spider 的一个子类,除了继承到 Spider 的特性和功能外,还派生除了其自己独有的更加强大的特性和功能。其中最显著的功能就是 ”LinkExtractors链接提取器“。Spider 是所有爬虫的基类,其设计原则只是为了爬取 start_url 列表中网页,而从爬取到的网页中提取出的 url 进行继续的爬取工作使用 CrawlSpider 更合适。
6.1 创建 CrawSpider 项目
$ scrapy startproject crawSpiderProject
$ cd crawSpiderProject
$ scrapy genspider -t crawl netbian pic.netbian.com
6.2 参数说明
- allow:接收一个正则表达式或一个正则表达式列表,提取绝对url于正则表达式匹配的链接,如果该参数为空,默认全部提取。
- deny:接收一个正则表达式或一个正则表达式列表,与allow相反,排除绝对url于正则表达式匹配的链接,换句话说,就是凡是跟正则表达式能匹配上的全部不提取。
- allow_domains:接收一个域名或一个域名列表,提取到指定域的链接。
- deny_domains:和allow_doains相反,拒绝一个域名或一个域名列表,提取除被deny掉的所有匹配url。
- deny_extensions:拒绝一个后缀。
- restrict_xpaths:接收一个xpath表达式或一个xpath表达式列表,提取xpath表达式选中区域下的链接。
- restrict_css:这参数和restrict_xpaths参数经常能用到,所以同学必须掌握
- tags:接收一个标签(字符串)或一个标签列表,提取指定标签内的链接,默认为tags=(‘a’,‘area’)
- attrs:接收一个属性(字符串)或者一个属性列表,提取指定的属性内的链接,默认为attrs=(‘href’,),示例,按照这个中提取方法的话,这个页面上的某些标签的属性都会被提取出来,如下例所示,这个页面的a标签的href属性值都被提取到了
- process_value (callable) :它接收来自扫描标签和属性提取每个值, 可以修改该值, 并返回一个新的, 或返回 None 完全忽略链接的功能。如果没有给出, process_value 默认是 lambda x: x。
- cononicalize=(boolean) 规范化每个提取的url(使用w3lib.url.canonicalize_url)。默认为True。
- unique=(boolean) 是否应对提取的链接应用重复过滤。
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class CrawlquanjingSpider(CrawlSpider):
name = 'crawlquanjing'
allowed_domains = ['so.gushiwen.cn']
start_urls = ['https://so.gushiwen.cn/guwen/default.aspx?p=1']
# 需求:
# 爬取所有的图片
# follow : 是否将该规则作用于 response
# 1 2 3 4 5 ... 77 78 79 5 3 4 5 6 ... 77 78 79
# 1 2 3 4 5 77 78 79 6 ~ 76
rules = (
# 列表页 规则
# Rule(LinkExtractor(allow=r'https://movie.douban.com/subject/\d+/'), callback='parse_item'),
# # 下一页 规则
Rule(LinkExtractor(allow=r'/guwen/default.aspx\?p=\d+',
deny_extensions=['xxx'],
deny=r'/user/\w+\.aspx'),
follow=True, callback='parse_item'),
)
def parse_item(self, response, **kwargs):
# 只需要出来结果,不需要处理请求
print(response.url)
item = {}
# item['domain_id'] = response.xpath('//input[@id="sid"]/@value').get()
# item['name'] = response.xpath('//div[@id="name"]').get()
# item['description'] = response.xpath('//div[@id="description"]').get()
return item
七、分布式爬虫
搭建一个分布式的集群,让其对一组资源进行分布联合爬取,提升爬取效率。
pip install scrapy-redis
7.1 scrapy框架是否可以自己实现分布式?
不可以!!!
- 其一:因为多台机器上部署的scrapy会各自拥有各自的调度器,这样就使得多台机器无法分配start_urls列表中的url。(多台机器无法共享同一个调度器)
- 其二:多台机器爬取到的数据无法通过同一个管道对数据进行统一的数据持久化存储。(多台机器无法共享同一个管道)
7.2 基于scrapy-redis组件的分布式爬虫
scrapy-redis组件中为我们封装好了可以被多台机器共享的调度器和管道,我们可以直接使用并实现分布式数据爬取。
- 实现方式:
- 基于该组件的RedisSpider类
- 基于该组件的RedisCrawlSpider类
7.3 分布式实现流程
上述两种不同方式的分布式实现流程是统一的
1.下载 scrapy-redis 组件
pip install scrapy-redis
2. redis 配置文件的配置
- linux或者mac:redis.conf
- windows:redis.windows.conf
修改
- 注释该行:bind 127.0.0.1,表示可以让其他ip访问redis
- 将yes改为no: protected-mode no,表示可以让其他ip操作redis
3. 修改爬虫文件中的相关代码
- 将爬虫类的父类修改成基于RedisSpider或者RedisCrawlSpider。
注意:如果原始爬虫文件是基于Spider的,则应该将父类修改成RedisSpider,如果原始爬虫文件是基于CrawlSpider的,则应该将其父类修改成RedisCrawlSpider。
- 注释或者删除start_urls列表,且加入redis_key属性,属性值为scrpy-redis组件中调度器队列的名称
4. 在配置文件中进行相关配置,开启使用scrapy-redis组件中封装好的管道
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline': 400
}
5. 在配置文件(setting)中进行相关配置,开启使用scrapy-redis组件中封装好的调度器
# 增加了一个去重容器类的配置, 作用使用Redis的set集合来存储请求的指纹数据, 从而实现请求去重的持久化
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# 使用scrapy-redis组件自己的调度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# 配置调度器是否要持久化, 也就是当爬虫结束了, 要不要清空Redis中请求队列和去重指纹的set。如果是True, 就表示要持久化存储, 就不清空数据, 否则清空数据
SCHEDULER_PERSIST = True
6. 在配置文件中进行爬虫程序链接redis的配置
REDIS_HOST = 'redis服务的ip地址'
REDIS_PORT = 6379
REDIS_ENCODING ='utf-8'
REDIS_PARAMS = {'password':'xx'}
7. 运行爬虫文件:scrapy runspider SpiderFile(x.py)
scrapy runspider xxx.py
8.向调度器队列中扔入一个起始url(在redis客户端中操作):lpush redis_key属性值 起始url
八、布隆过滤器
pip install scrapy-redis-bloomfilter
# 替换scrapy_redis的去重类
DUPEFILTER_CLASS = "scrapy_redis_bloomfilter.dupefilter.RFPDupeFilter"
# 替换原来的请求调度器的实现类,使用 scrapy-redis 中请求调度器
SCHEDULER = "scrapy_redis_bloomfilter.scheduler.Scheduler"
# 设置布隆过滤器散列函数的个数,默认为6,可以自行修改
BLOOMFILTER_HASH_NUMBER = 6
# Bloom Filter的bit参数,默认30,占用128MB空间,可存储数据量级1亿
# BLOOMFILTER_BIT决定了位图的位数。如果BLOOMFILTER_BIT为30,那么位数组位数为2的30次方,这将占用Redis 128 MB的存储空间,去重量级在1亿左右。
BLOOMFILTER_BIT = 30
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK