

BP神经网络_wx619474981d7fe的技术博客_51CTO博客
source link: https://blog.51cto.com/u_15435076/5583345
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

- 什么是BP神经网络
- BP神经网络介绍
- BP神经网络的推导
感知机是作为神经网络(深度学习) 的起源的算法。 因此, 学习感知机的构造也就是学习通向神经网络和深度学习的一种重要思想。
什么是感知机
感知机接收多个输入信号, 输出一个信号。 这里所说的“信号”可以想象成电流或河流那样具备“流动性”的东西。 像电流流过导线, 向前方输送电子一样, 感知机的信号也会形成流, 向前方输送信息。
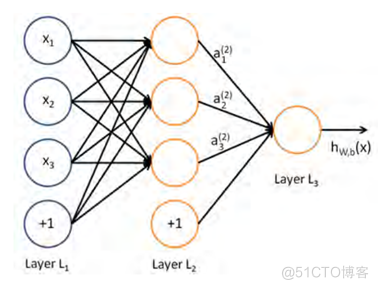
是输入信号,是输出信号,是权重,是“神经元” 或者叫节点,输入信号被送往神经元时, 会被分别乘以固定的权重,也叫加权求和,神经元会计算传送过来的信号的总和。
什么是BP神经网络
BP(BackPropagation) 算法是神经网络深度学习中最重要的算法之一,是一种按照误差逆向传播算法训练的多层前馈神经网络,是应用最广泛的神经网络模型之一 。了解BP算法可以让我们更理解神经网络深度学习模型训练的本质,属于内功修行的部分。
**BP算法的核心思想是:**学习过程由信号的正向传播和误差的反向传播两个过程组成。
**正向传播:**输入层的神经元负责接受外界发来的各种信息,并将信息传递给中间层神经元,中间隐含层神经元负责将接收到的信息进行处理变换,根据需求处理信息,实际应用中可将中间隐含层设置为一层或者多层隐含层结构,并通过最后一层的隐含层将信息传递到输出层,这个过程就是BP神经网络的正向传播过程。
**反向传播:**当实际输出与理想输出之间的误差超过期望时,就需要进入误差的反向传播过程。它首先从输出层开始,误差按照梯度下降的方法对各层权值进行修正,并依次向隐含层、输入层传播。通过不断的信息正向传播和误差反向传播,各层权值会不断进行调整,这就是神经网络的学习训练。当输出的误差减小到期望程度或者预先设定的学习迭代次数时,训练结束,BP神经网络完成学习。
如果隐含层中的神经元节点设置过少,结果可能造成神经网络的训练过程收敛变慢或者不收敛。如果隐层中节点过多,模型的预测精度会提高,但同时网络拓扑结构过大,收敛速度慢,普遍性会减弱。
隐藏层神经元的设置方法:
如果 BP 神经网络中输入层节点数为 m 个,输出层节点是为 n 个,则由下式式可推出隐藏层节点数为 s 个。 其中 b 一般为 1-9 的整数。
BP神经网络的推导

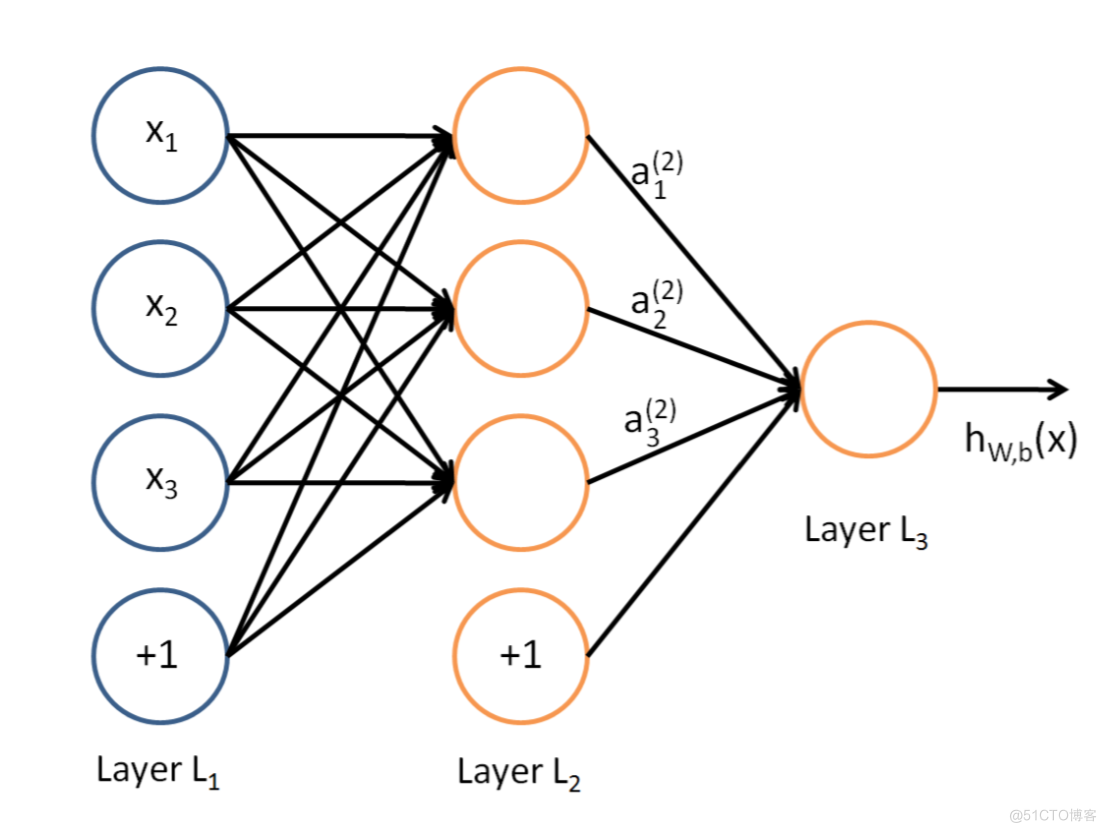
第一层是输入层,包含两个神经元i1,i2,和截距项b1;第二层是隐含层,包含两个神经元h1,h2和截距项(偏置系数)b2,用于控制神经元被激活的容易程度,第三层是输出o1,o2,每条线上标的wi是层与层之间连接的权重,激活函数我们默认为sigmoid函数。
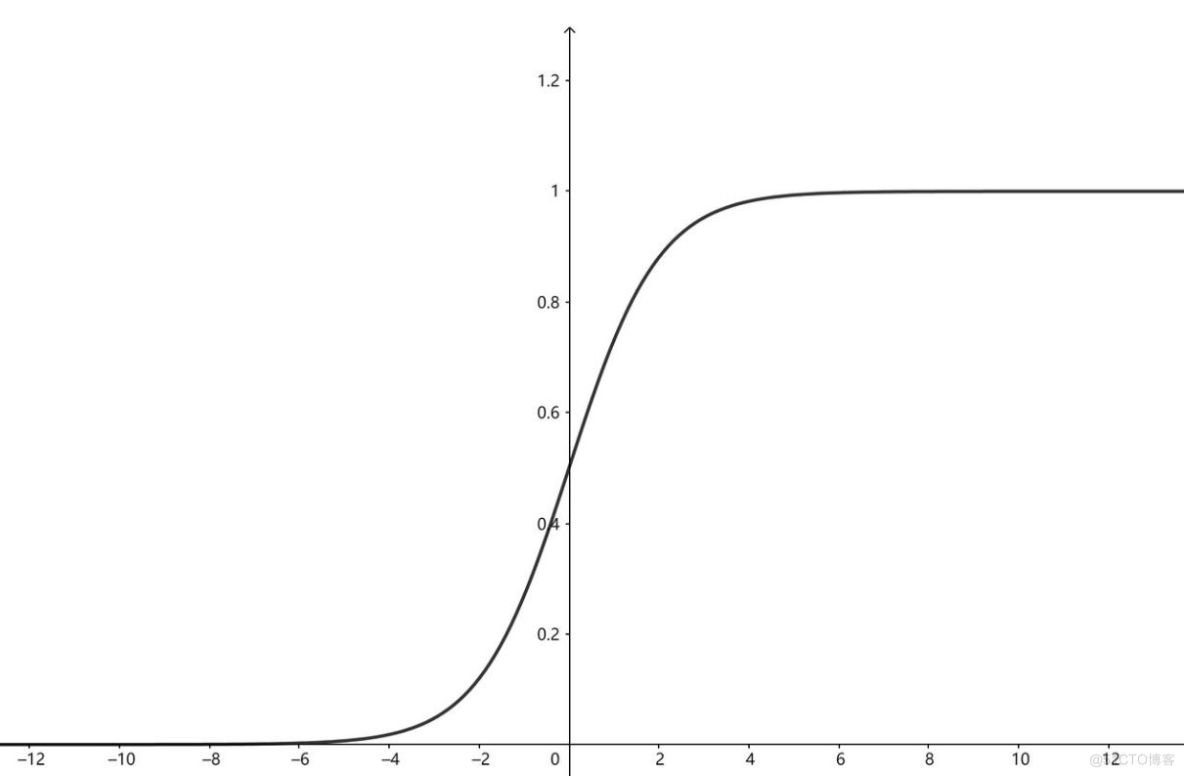
sigmoid函数:
假设现在有5个数字,分别是a=0.8,b=1.5,c=1.2,d=1.9,e=10,它们的关系是a<c<b<d<e。e特别大,有可能是样本采集失误出现的错误数据,经过sigmoid变换,可以看到这几个数据的差异变小了,但大小关系仍然是a<c<b<d<e。根据函数图像可知,sigmoid函数可以在保持数据大小关系不变的情况下使特别大或特别小的数变得普通,这一特性很适用于分类问题和bp网络数据的处理。
损失函数采用均方差:
以数据推导,现在对他们赋上初值,如下图:
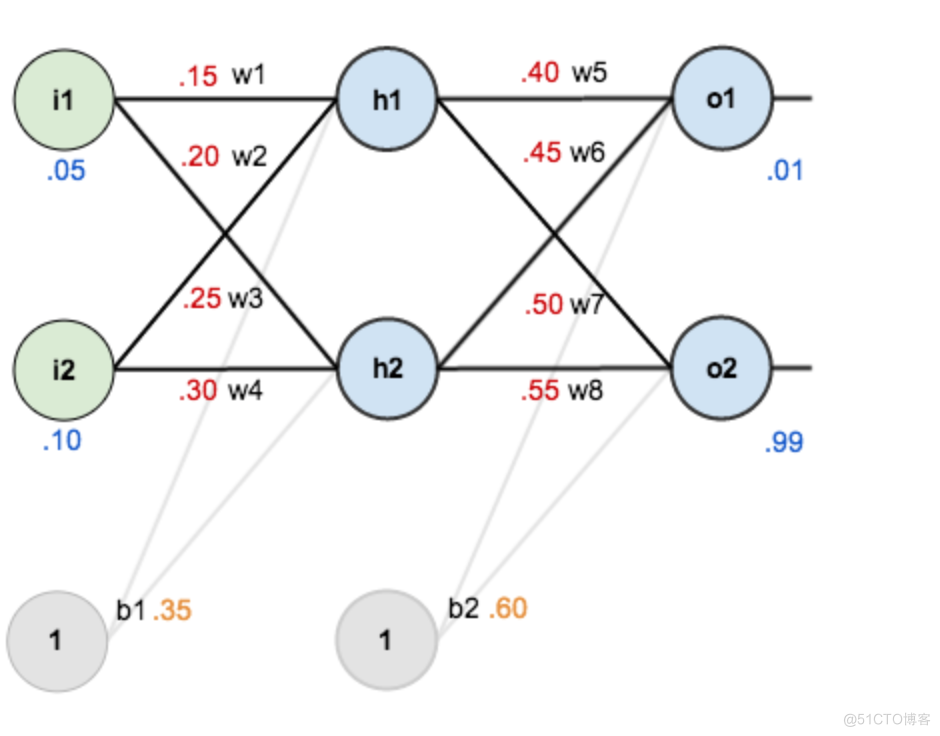
- 输入层--->隐含层:
计算神经元h1的输入加权和:
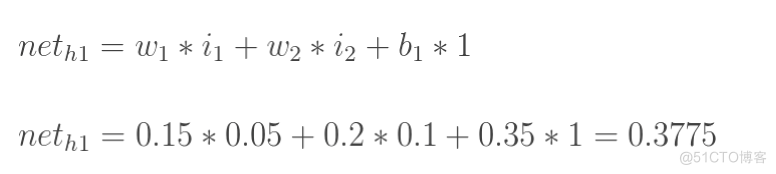
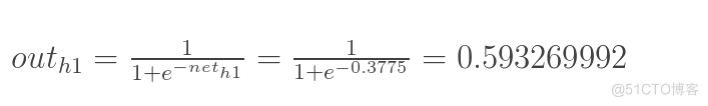

计算输出层神经元o1和o2的值:
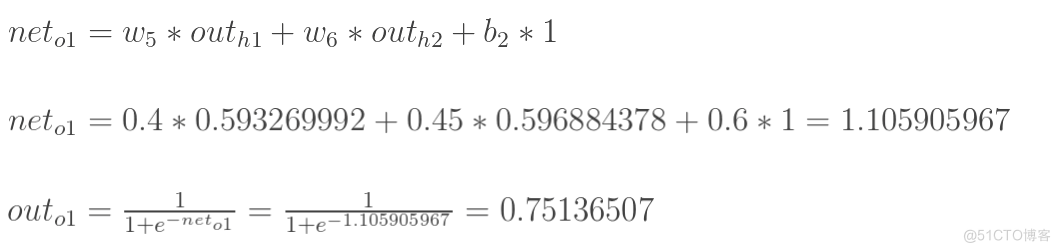
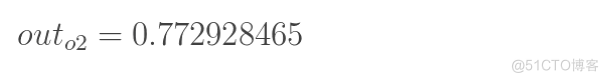
- 计算总误差
总误差:

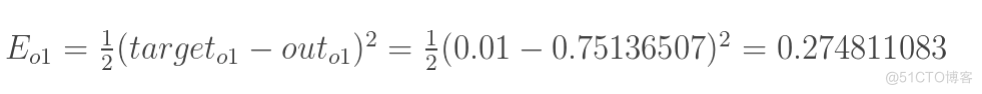

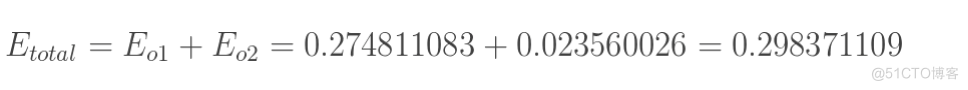
以权重参数w5为例,如果我们想知道w5对整体误差产生了多少影响,可以用整体误差对w5求偏导求出:(链式法则)
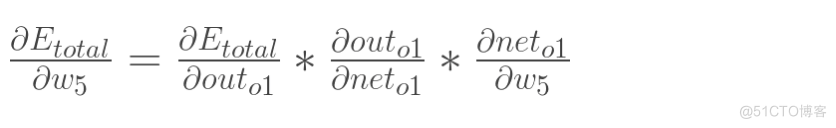
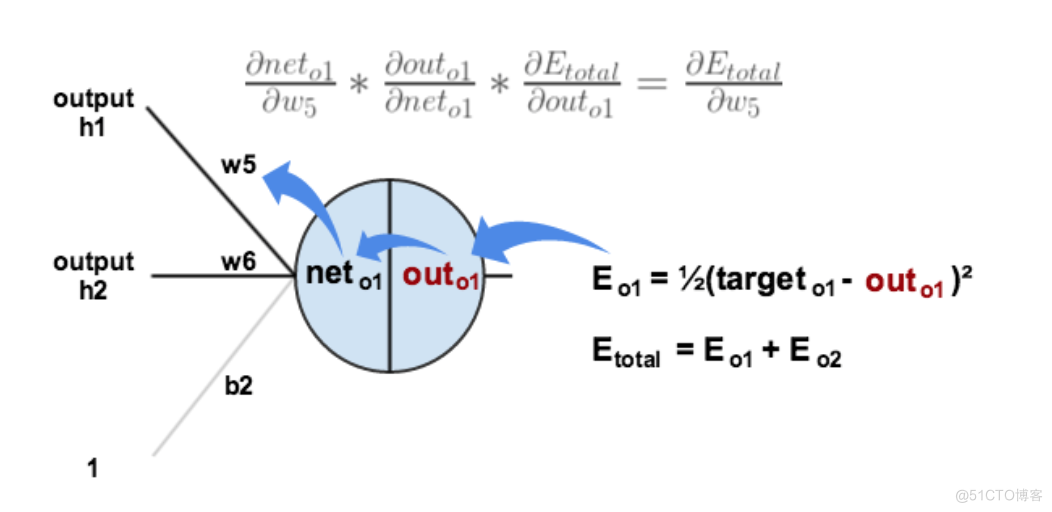
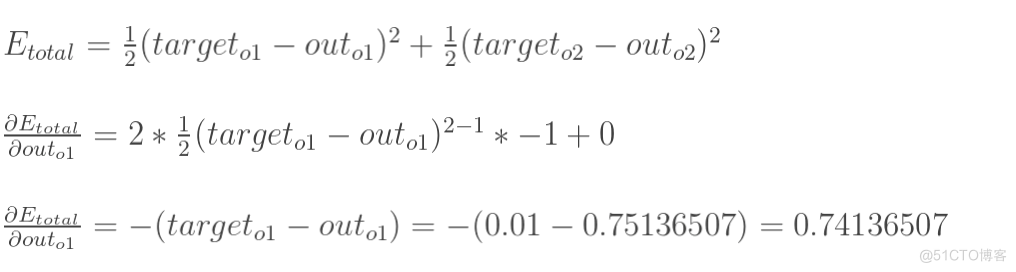
对函数对x求导



最后我们来更新w5的值:
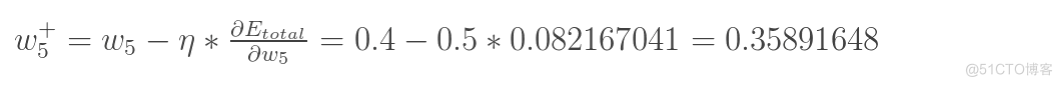
为学习率,设置为0.5,可以调整更新的步伐,合适的学习率能够使目标函数在合适的时间内收敛到局部最小值。学习率设置太小,结果收敛非常缓慢;学习率设置太大,结果在最优值附近徘徊,难以收敛,一般选取为0.01−0.8
- 同理更新其他参数:

方法其实与上面说的差不多,但是有个地方需要变一下,在上文计算总误差对w5的偏导时,是从out(o1)---->net(o1)---->w5,但是在隐含层之间的权值更新时,是out(h1)---->net(h1)---->w1,而out(h1)会接受E(o1)和E(o2)两个地方传来的误差,所以这个地方两个都要计算。
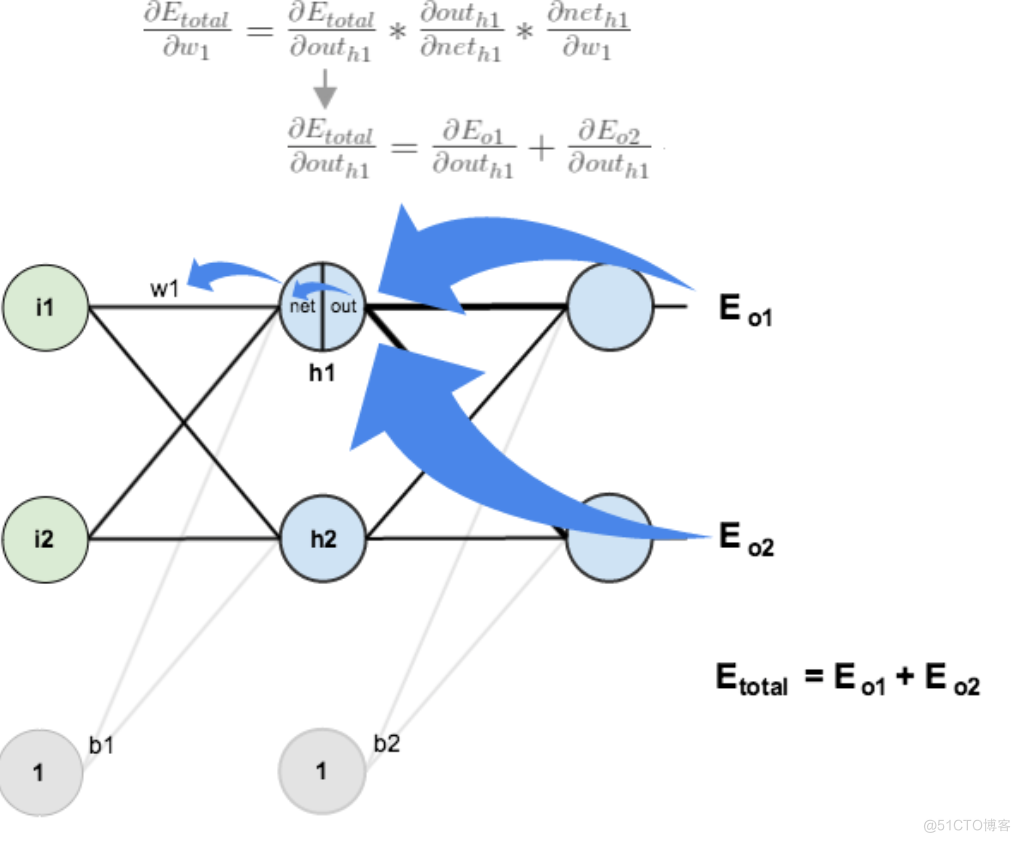

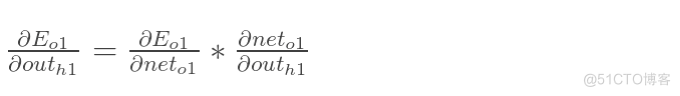
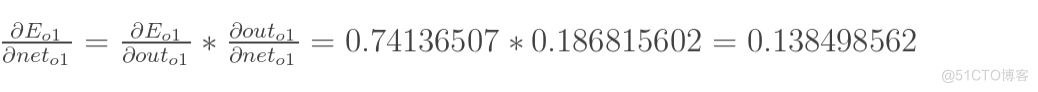
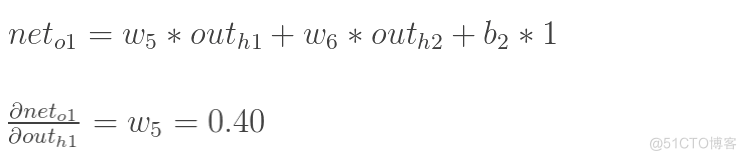
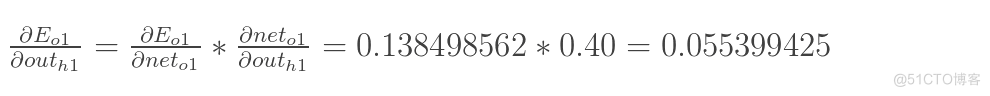
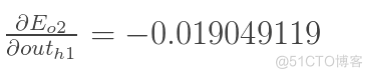
两者相加得到总值:
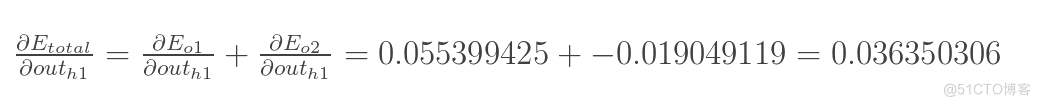
再计算

再计算
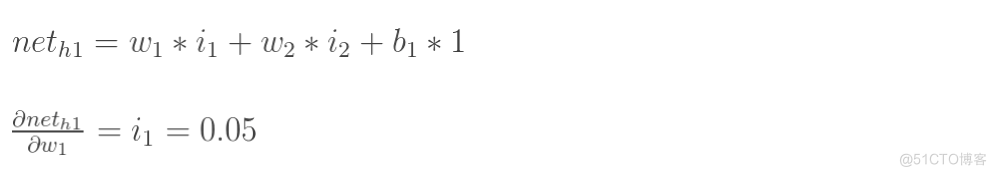
计算

最后,更新w1的权值:

同理,额可更新w2,w3,w4的权值:

这样误差反向传播法就完成了,最后我们再把更新的权值重新计算,不停地迭代,在这个例子中第一次迭代之后,总误差E(total)由0.298371109下降至0.291027924。迭代10000次后,总误差为0.000035085,输出为[0.015912196,0.984065734] (原输入为[0.01,0.99]),证明效果还是不错的。
训练到什么时候结束:
- 设置最大迭代次数,比如使用数据集迭代100次后停止训练
- 计算训练集在网络上的预测准确率,达到一定门限值后停止训练
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK