

数据来源仍然是人工智能主要瓶颈
source link: https://www.51cto.com/article/716317.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
数据来源仍然是人工智能主要瓶颈-51CTO.COM
根据Appen本周发布的《人工智能和机器学习状况》报告,各机构仍在努力获取良好、干净的数据,以维持其人工智能和机器学习计划。

根据Appen对504名商业领袖和技术专家的调查,在人工智能的四个阶段中,数据来源;数据准备;模型训练和部署;人工主导的模型评估阶段——数据来源消耗的资源最多、时间最长、最具挑战性。
根据Appen的调查,数据来源平均消耗企业组织34%的人工智能预算,数据准备、模型测试和部署各占24%,模型评估占15%。该调查由哈里斯调查(Harris Poll)进行,受访者包括来自美国、英国、爱尔兰和德国的IT决策者、商业领袖和经理以及技术从业者。
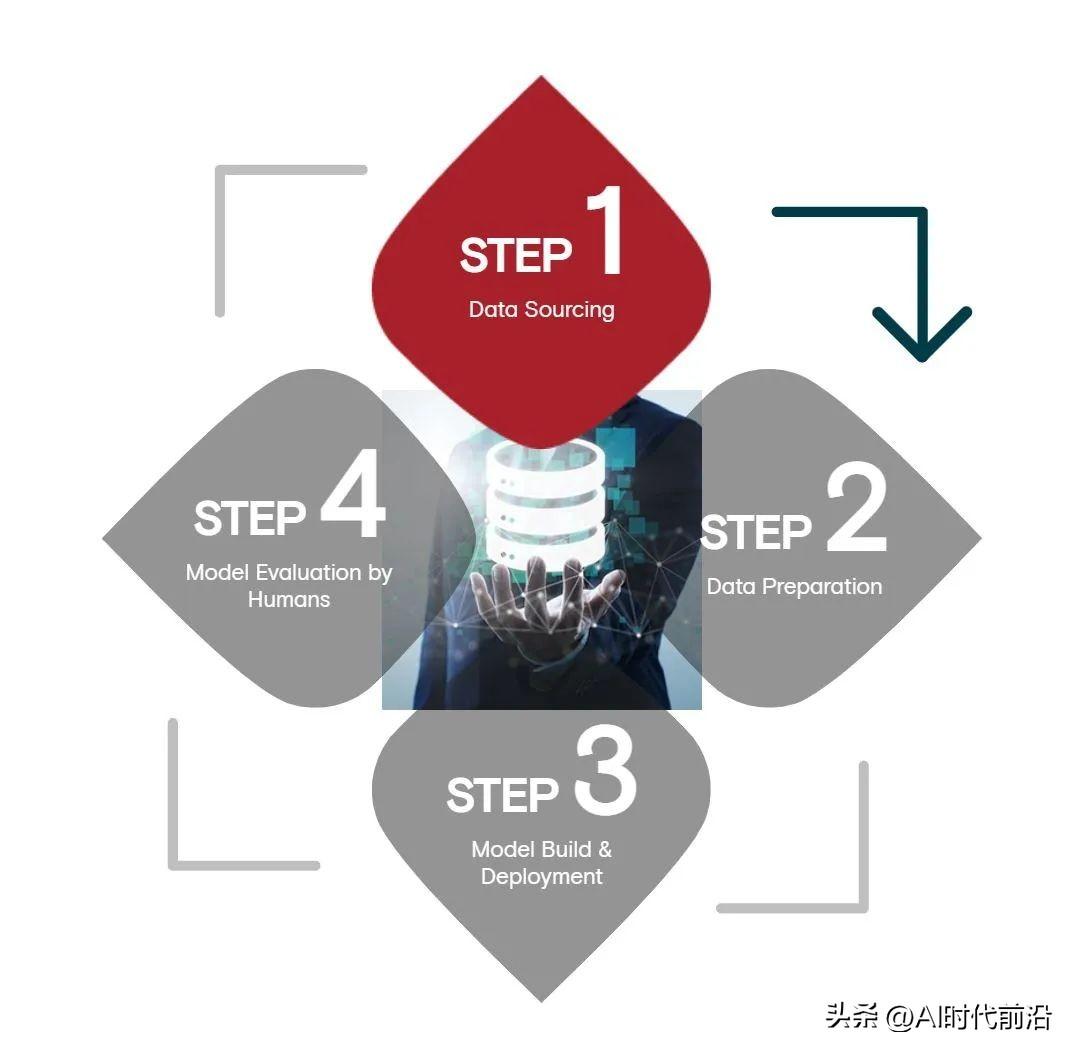
就时间而言,数据来源大约消耗26%的时间,数据准备的时间为24%,模型测试、部署和模型评估的时间各为23%。最后,42%的技术人员认为数据来源是AI生命周期中最具挑战性的阶段,其他阶段情况分别为:模型评估(41%)、模型测试和部署(38%)和数据准备(34%)。
尽管面临挑战,但各企业组织都在努力使其发挥作用。据Appen称,五分之四(81%)的受访者表示,他们有足够的数据支持他们的人工智能计划。成功的关键可能在于:绝大多数(88%)的公司通过使用外部AI训练数据提供商(如Appen)来扩充数据。
然而,数据的准确性还有待商榷。Appen发现,只有20%的受访者报告数据准确率超过80%。只有6%(大约每20个人中有一个)说他们的数据准确性达到90%或更高。
考虑到这一点,根据Appen的调查,近一半(46%)的受访者认为数据的准确性很重要。只有2%的人认为数据准确性不是很大的需求,而51%的人认为这是至关重要的需求。
Appen的首席技术官Wilson Pang对数据质量的重要性有着不同的看法,他的客户中有48%认为数据质量不重要。
报告中说:“数据的准确性对人工智能和ML模型的成功至关重要,因为质量丰富的数据会产生更好的模型输出和一致的处理和决策。”“为了获得好的结果,数据集必须准确、全面和可扩展。”
深度学习和以数据为中心的人工智能的兴起,已经将人工智能成功的动力从良好的数据科学和机器学习建模转移到良好的数据收集、管理和标签。在当今的迁移学习技术中,这一点尤其明显。人工智能的实践者会放弃一个大型的预先训练的语言或计算机视觉模型,用他们自己的数据对其中的一小部分进行再训练。
更好的数据还可以帮助防止不必要的偏见渗透到人工智能模型中,防止人工智能可能导致的坏结果。对于大型语言模型来说,这一点尤其明显。
报告中说:“随着在多语言网络抓取数据上训练的大型语言模型(LLM)的兴起,企业正面临另一个挑战。由于训练语料库中充斥着有毒的语言,以及种族、性别和宗教偏见,这些模型通常会表现出不受欢迎的行为。”
网络数据的偏见引发了棘手的问题,虽然有一些变通办法(改变训练方案,过滤训练数据和模型输出,并从人类反馈和测试中学习),但需要进行更多的研究,以创建一个“以人为中心的LLM”基准和模型评估方法的良好标准。
Appen表示,数据管理仍然是人工智能面临的最大障碍。调查发现,在人工智能循环中,41%的人认为数据管理是最大的瓶颈。排在第四位的是缺乏数据,30%的受访者认为这是人工智能成功的最大障碍。
但也有一些好消息:企业用于管理和准备数据的时间正在下降。Appen说,今年的比例刚刚超过47%,而去年报告中的比例为53%。
“由于大多数受访者使用外部数据提供商,可以推断,通过外包数据来源和准备,数据科学家正在节省适当管理、清洁和标签他们的数据所需的时间。”数据标签公司说。
然而,根据数据中相对较高的错误率判断,也许组织不应该缩减其数据来源和准备过程(无论是内部的还是外部的)。当涉及到建立和维护AI流程时,有很多相互竞争的需求——雇佣合格的数据专业人员的需求是Appen确定的另一个首要需求。但是,在数据管理取得重大进展之前,组织应该继续向他们的团队施加压力,继续推动数据质量的重要性。
调查还发现,93%的组织强烈或在一定程度上同意AI伦理应该是AI项目的“基础”。Appen首席执行官Mark Brayan表示,这是一个良好的开端,但还有很多工作要做。Brayan在一份新闻稿中说:“问题是,许多人正面临着试图用糟糕的数据集构建伟大的人工智能的挑战,这为实现他们的目标制造了巨大的障碍。”
根据Appen的报告,企业内部自定义收集的数据仍然是用于人工智能的主要数据集,占数据的38%至42%。合成数据表现出惊人的强劲,占组织数据的24%至38%,而预标记数据(通常来自数据服务提供商)占数据的23%至31%。
特别是,合成数据有可能减少敏感AI项目中的偏差发生率,Appen 97%的调查参与者表示,他们在“开发包容性训练数据集”中使用了合成数据。
报告中其他有趣地发现包括:
- 77%的组织每月或每季度对他们的模型进行再训练;(Ai时代前沿解读:人工智能不是一劳永逸的,根据应用需求不断提升,需要不断更新。)
- 55%的美国企业声称自己领先于竞争对手,而在欧洲这一比例为44%;(Ai时代前沿解读:欧洲人略微比美国人低调一些。)
- 42%的组织报告称人工智能“广泛”推出,而在《2021年人工智能状态报告》中,这一比例为51%;(Ai时代前沿解读:人工智能应用越来越广泛了。)
- 7%的机构报告称人工智能预算超过500万美元,而去年这一比例为9%。(Ai时代前沿解读:一方面可能由于人工智能逐渐成熟降低了成本,也说明人工智能不再是一个“奢侈品”,正逐渐成为企业的“必备品”。)
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK