

站点优化日志(2022.08.12)
source link: https://soulteary.com/2022/08/12/site-optimization-log.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
记录自上次更新以来的一些变化。
主要调整内容
- 持续完善构建工具,目前所有构建过程均基于 Golang 1.19,包含在上次网站更新后,新增的用于动态计算网站数据、生成分析页面的工具。
- 因为 Google Analytics 运营策略的原因,使用 “Google Analytics 4” 替换了 “Universal Analytics(UA)”。
- 对 Hugo 进行了多次版本升级,当前使用的版本是 hugo v0.101.0,进一步微调模版,让构建效率更高。
记录一次琐碎的 CI 功能重构
这个小节的内容,主要来自半年前的折腾笔记,有群里的伙伴好奇细节,权当抛砖引玉,简单分享下。
在《站点优化日志(2021.11.29)》一文中,我提到新增了一个“统计分析”的 CI 阶段,用于在每次发布文章时,将文章相关的发布数据、中英文字数进行统计分析,然后输出为可读性好的“报告”。
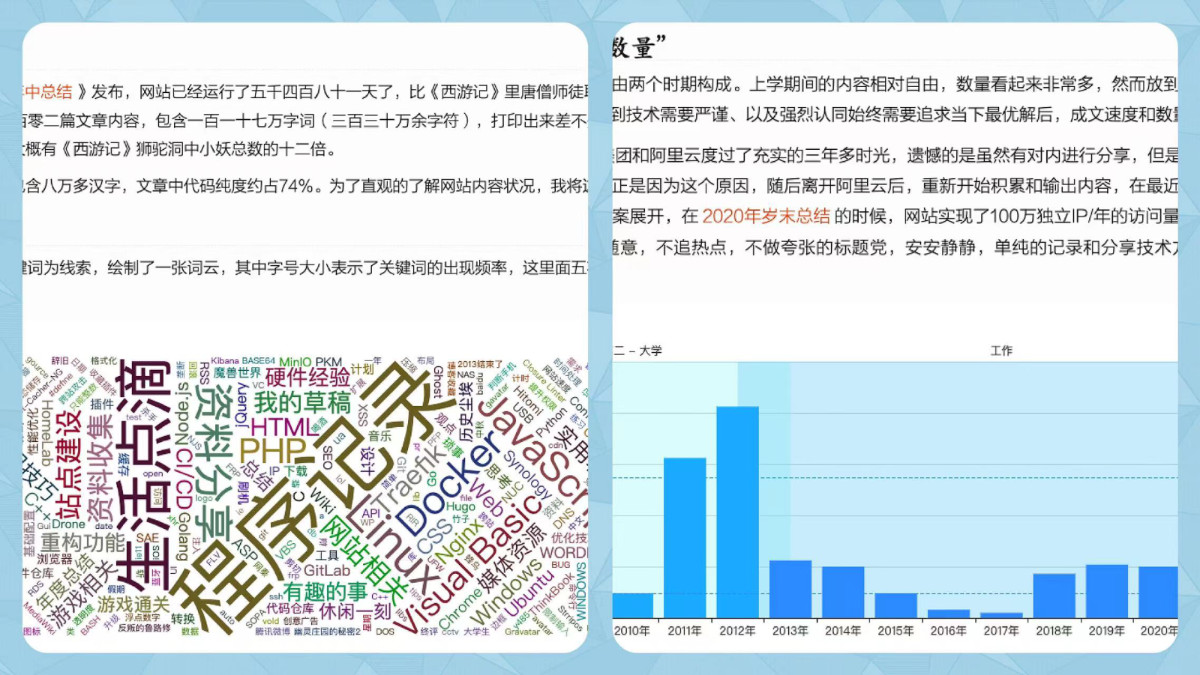
为了快速完成功能原型,程序的第一版采用了 Node.js 编写。程序会对网站里的一千多篇文章进行分析,整个过程需要花费十几秒钟。而除此之外的所有流程加载一起也不过十几秒种,即使构建阶段有一部分可以并行执行,也得额外添加十秒钟的额外成本。
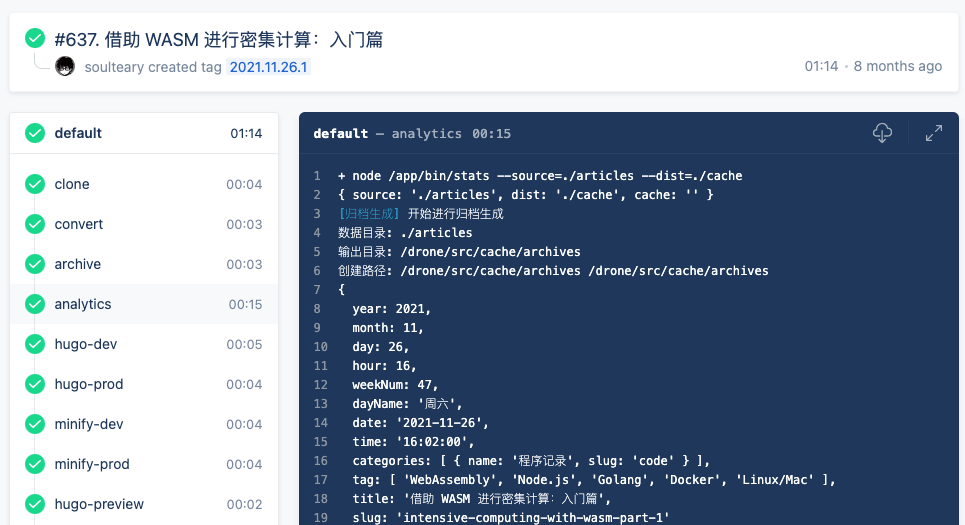
然而,在那篇文章发布之后的一天,一个忍不住,我就把这个 CI 由 Node 替换成了 Go 实现,足足省了 12 秒(500% 性能提升)。
为了减少整体串行任务在 Docker 容器创建唤醒过程所花费的时间,还将 “convert” 和 “archive” 合并成了一个任务,又立省 3 秒。
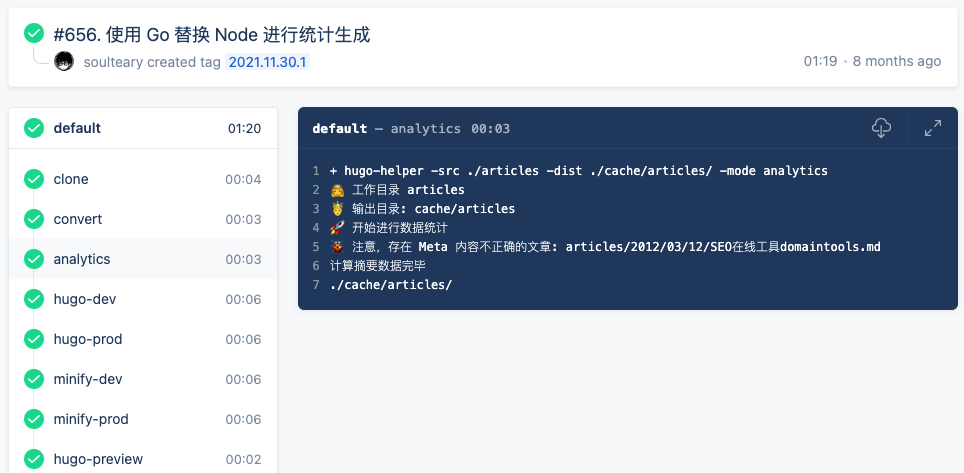
当然,如果是平时写完内容,进行正式预览,所需要的时间也会更短一些。
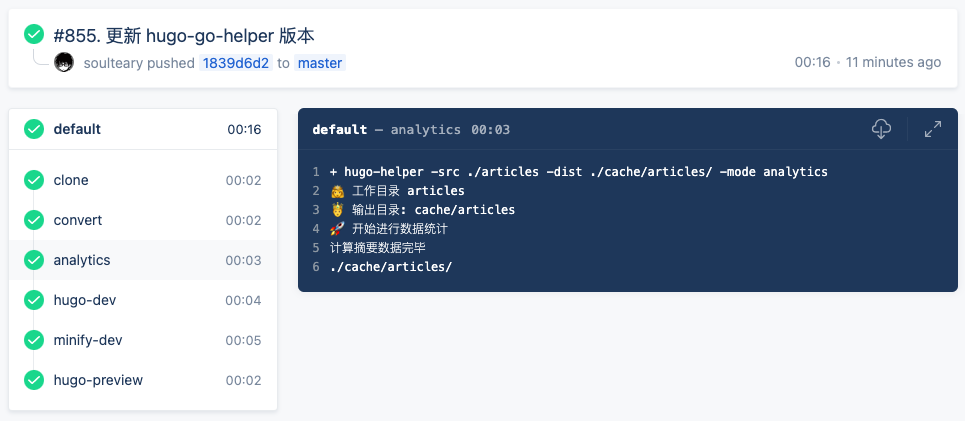
在重构之前,需要先了解这个统计阶段做了哪些事儿。
如何使用 Node 实现一个最简单的原型
借助 echarts,“统计页面”的前端效果实现非常简单,这里就不展开了。我们着重来聊聊如何使用 Node 来快速完成一个功能原型。
想实现这个页面的功能,最核心的两件事是:
- 解析所有文章的内容,将文章内容中的 Markdown 标记语法转换为纯文本内容,并去掉里面包含的英文内容,比如代码块。然后使用最少开发成本的方式进行字符统计。
- 解析所有的包含文章 Meta 信息的 JSON 文件,将数据按照不同的维度进行筛选和分组,比如年、月、日、星期、小时,或者按照一些维度进行组合,输出简单的报表。
将上面的“需求”细化,我们本着使用尽可能少的代码来解决问题的思路,尽可能的使用“现成”方案。比如,可以通过使用 @anydown/maildown 来将 Markdown 格式的内容转换为纯文本。
const maildown = require("@anydown/maildown");
module.exports = function (content) {
return maildown(content, { lineLength: 70 });
}
比如,可以使用 vscode-wordcount-cjk 项目中的中文统计方法,来完成中文字数的统计功能。
/**
* Justify if a char is Chinese character.
*
* 4E00-9FFF: CJK Unified Ideographs
* F900-FAFF: CJK Compatibility Ideographs
*
* Reference:
* http://houfeng0923.iteye.com/blog/1035321 (Chinese)
* https://en.wikipedia.org/wiki/CJK_Unified_Ideographs
* https://en.wikipedia.org/wiki/CJK_Compatibility_Ideographs
*
* @todo Refine to contains only Chinese Chars.
*
* @param ch Char to be tested.
*/
function _countChineseChar(ch) {
// Count chinese Chars
const regexChineseChar = /[\u4E00-\u9FA5\uF900-\uFA2D]/;
if (regexChineseChar.test(ch)) {
_nChineseChars += 1;
}
}
虽然,Node 生态里,没有直接能够统计英文词组的软件包、或者既简单又具备高性能的方案。但是,我们可以使用 spawn 调用 wildcat 这类能够满足需求的、预编译好的二进制工具来搞定需求。
spawnSync("wildcat", ["-w", "./concat.txt"])
剩下的就是一些胶水代码,比如小技巧减少 IO、等等。完整的代码大概百十来行就能够解决战斗了。
使用 Golang 来改善执行效率
Node 在快速完成原型方面和 Python 有一拼,但是想要实现高性能程序,就需要额外付出不少代价了。而且,由于 Node 生态的快速演进,NPM 软件包、NPM 客户端的版本都容易“过时”,过个三年五载的程序,经常出现“可复现”存在问题的情况。
虽然将应用“打成 Docker” 能够解决很大一部分问题,但是镜像体积和再次开发的体验,都属于一言难尽的话题。所以,当针对简单功能考虑进行重构的时候,Go 是一个不错的选择:性能下限高、执行和构建结果都足够稳定,容器镜像也足够小巧。
如何将 JavaScript 使用 Golang 进行重写,我们就不展开了,单单提一个省事的小技巧。在前文中,我们提到了使用 Node 调用 wildcat 来统计词组数量,虽然在 Go 中,我们也可以使用类似的方式,使用程序外部执行调用的方式,来完成功能。但是跨程序调用,毕竟是一个很慢的操作。
本着最小化改动程序,少写代码的原则,我们可以通过将 wildcat 引入程序,然后将待处理的文本内容存到临时文件中,然后调用 wildcat 的处理函数,获得处理结果。如果追求绝对的性能和速度,还可以使用“内存 FS”来解决问题,比如这个项目(soulteary/memfs)。
package wordcounter
import (
...
"github.com/tamada/wildcat"
)
func count(fileName string) string {
...
}
func WordCounter(content string) string {
tmpFile, _ := ioutil.TempFile("", fmt.Sprintf("%s-", filepath.Base("wc")))
defer tmpFile.Close()
tmpFile.WriteString(content)
wc := count(tmpFile.Name())
defer os.Remove(tmpFile.Name())
return wc
}
当然,如果你追求更高效的处理方案,可以通过“mock stdin 和 stdout”来模拟 wildcat 使用过程中类似 “cat” 读取 Linux Pipeline 中的数据,而无需文件落盘。
关于网站统计的一些事情
在折腾一个临时项目的时候,同事提醒我 GA 需要升级新版本,在阅读了运营条款后,虽然服务停止时间是 2023 的 7 月 1 日,但是本着避免后面忘记升级,而导致统计数据缺失,我还是将项目使用的统计模式进行了升级调整,并更新了统计代码。
这里有一个小细节,在升级统计账号之后,别忘记进行新旧账号的关联,可以同时在新、老控制台看板中观察数据。(毕竟,新版本控制台功能还不是很完善)
最后,在最近的一次业务测试中,挑选了能够带来大量读者(十万+)的几个场景中,经过相对严谨的数据比对,发现国内用户在 Google Analytics 中的数据流失率在 70% 以上。那么使用国产统计平台,是否会有质变呢?在以往的总结中,我有提到过,针对开发者群体,在相同的统计目标(网站)上,百度的数据量会比谷歌还少。
所以,如果想要更精准的得到用户行为,进而通过相对精准群体用户画像,来不断优化产品,或许除了使用三方平台,“自建数据统计”也是避不开的事情。
如果让我在 2022 年下半年的此时此刻,再次重新设计美团的统计 SDK。我想,我应该能够拿出一套更完善,对账率更高的方案 :D
Hugo 升级
作为 Hugo 的老用户,我一直以为 0.90+ 会是 1.0 之前的最后篇章,在使用了 Hugo 几年后,应该是能够用上 Hugo 1.0 大版本的。
于是在上一次的网站优化日志之后,我积极的更新了三个 0.90+ 的版本。然而意想不到的是,Hugo 居然打出了 0.100+ 的版本号。
吐槽版本帝这个事情之外,分享下我是如何调优 Hugo 的吧。在 Hugo 的老版本中,我们可以通过下面两个命令来进行分析,找出模版中不靠谱的实现,然后进行逐个击破:
hugo benchmark
hugo --stepAnalysis
在较新版本的 Hugo 中,我们可以通过下面两个替换命令,来实现类似的事情:
hugo --debug
hugo --templateMetrics
在最近的版本中,Hugo 依然持续在针对资源管理上下功夫,除了之前的能够通过简单的内置功能(基于 Go), 来解决传统前端依赖复杂构建工具进行开发的问题之外,还能够针对媒体资源进行优化等。
但是,这里的最佳实践依旧是进行前后端分离,让 Hugo 只做页面生成、路由管理,而非连带“前端”一锅端,因为 99% 的场景下,我们根本无需对前端程序进行改变,想要获得最好的前端程序性能,单靠“开箱即用”的非专业工具完成构建和优化,也是不太现实的。
先写到这里了,依旧期待下一次的站点升级。期待在下一次的更新中,可以分享一个折腾验证了许久的“实用”站内搜索引擎方案。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK