

主流前沿的开源监控和报警系统Prometheus+Grafana入门之旅 - itxiaoshen
source link: https://www.cnblogs.com/itxiaoshen/p/16578325.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Prometheus概述
Prometheus 官网地址 https://prometheus.io/
Prometheus 官网文档地址 https://prometheus.io/docs/introduction/overview/
Prometheus GitHub地址 https://github.com/prometheus/prometheus
Prometheus是一个开源的系统监控和警报工具包,最初由SoundCloud开发的,社区活跃,2016年加入了云原生计算基金会成为继Kubernetes之后的第二个托管项目;普罗米修斯以时间序列数据的形式收集并存储度量值;大部分模块由Go语言编写的。最新版本v2.37.0
- 多维数据模型,时间序列数据由指标名称和键/值对标识。
- PromQL灵活的查询语言。
- 不依赖于分布式存储,单个节点自治。
- 时间序列收集通过拉模型基于HTTP。
- 基于网关实现采集监控指标数据的推送。
- 目标通过服务发现或静态配置。
- 多种模式的图形化和仪表板支持。
- 支持分层和水平联合。
- Prometheus服务器:用于抓取和存储时间序列数据。
- Prometheus本身是一个以进程方式启动,之后多进程和多线程实现监控数据收集,计算,查询,更新,存储的咋样一个C/S模型运行模式。
- Prometheus采用的是time-series(时间序列)的方式以一种自定义的格式存储在本地硬盘上。
- Prometheus的本地T-S(time-series)数据库以每两小时为间隔来分block(块)存储,每一个块中又分为多个chunk文件,chunk文件是用来存放采集过来的T-S数据,metadata和索引文件(index)。
- index文件,是对metrics(Prometheus中一次K/V采集数据,叫做一个metric)和labels(标签)进行索引,之后存储在chunk中,chuunk是作为存储的基本单位,index and metadata是作为子集。
- Prometheus平时是将采集过来的数据,先都存放在内存之中(Prometheus对内存的消耗还是不小的),以类似缓存的方式,用于加快搜索和访问
当出现宕机时,Prometheus有一种保护机制叫做WAL,可以将数据定期存入硬盘中,以chunk来表示,并在重新启动时,用以恢复进入内存。
- 客户端库:编写自定义收集器从其他系统提取指标,并将指标公开给普罗米修斯。
- Pushgateway:网关,支持短周期的监控指标推送。
- exporters:用于HAProxy, StatsD, Graphite等服务的特殊用途采集。
- alertmanager:处理各种警报支持工具。
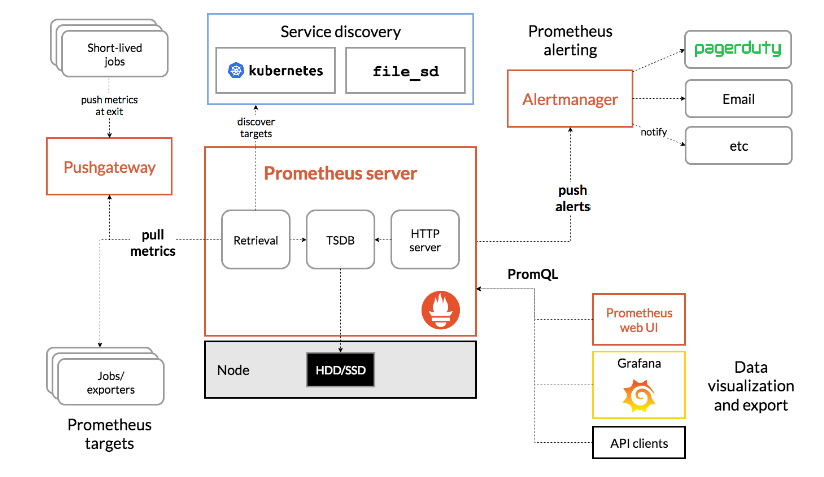
Prometheus可以通过exporters直接拉取监控指标,或者通过Pushgateway获取短期任务推送监控数据,数据存储在Prometheus服务端本地,基于存储时间序列的数据上运行分析、聚合、生成警报。可以使用Grafana或其他API消费者对收集的数据进行可视化。普罗米修斯可以很好地记录任何纯数字的时间序列,它既适合以机器为中心的监视,也适合高度动态的面向服务的体系结构的监视,特别擅长于微服务和容器下多维数据收集和查询。也适合对可靠性要求高场景,每个Prometheus服务器都是独立的,不依赖于网络存储或其他远程服务。
- 相比其他老款监控的不可被替代的巨大优势,功能更加强大
- 监控数据的精细程度高,可以精确到1~5秒的采集精度,是其他监控系统无法企及的。
- 集群部署的速度,监控脚本的制作(指的是熟练之后)非常快速,大大缩短监控的搭建时间成本,周边插件很丰富大多数都不需要自己开发了。
- 本身基于数学计算模型,大量的实用函数可以实现很复杂规则的业务逻辑监控(例如QPs的曲线弯曲凸起下跌的比例等等模糊概念)。
- 可以嵌入很多开源工具的内部进行监控数据更准时更可信(其他监控很难做到这一点)。
- 本身是开源的,更新速度快,bug修复快·支持N多种语言做本身和插件的二次开发。
- 图形很高大上很美观老板特别喜欢看这种业务图(主要是指跟 Grafana的结合)。
对运维要求
- 要求对操作系统有很深入扎实的了解,不能只是浮在表面。
- 对数据思维有一定的要求,因为它基本的内核就是数学公式。
- 对监控的经验有很高的要求,很多时候,监控项需要很细的定制。
数据模型(DATA MODEL)
从根本上说,Prometheus将所有数据存储为时间序列:带有时间戳的数据流属于同一度量标准和同一组标记维度。除了存储的时间序列,Prometheus还可以生成临时的派生时间序列作为查询的结果。
- 度量名称和标签(Metric names and labels):每个时间序列由其度量名称和可选的键值对(称为标签)唯一标识。
- 样本(Samples):样本构成实际的时间序列数据。每个样本包括,float64值和毫秒精度的时间戳。
- 标记(Notation):给定一个度量名称和一组标签,时间序列经常使用以下符号来标识。
工作和实例(JOBS AND INSTANCES)
在Prometheus术语中,可以抓取的端点称为实例,通常对应于单个进程。具有相同目的的实例集合,例如为了可伸缩性或可靠性而复制的进程,称为作业。
例如一个有四个复制实例的API服务器作业
- job:api-server
- instance 1:
1.2.3.4:5670 - instance 2:
1.2.3.4:5671 - instance 3:
5.6.7.8:5670 - instance 4:
5.6.7.8:5671
- instance 1:
自动生成标签和时间序列,当Prometheus抓取目标时,它会自动在抓取的时间序列上附加一些标签,用于识别被抓取的目标:
- job:配置的目标所属的作业名称。
- instance:被抓取的目标URL的:部分。
指标度量(metrics)
Prometheus监控中,对于采集过来的数据,统一成为metrics数据,metrics已经相信大家都已耳熟,当我们需要为某个系统某个服务做监控、做统计,就需要用到metrics。metrics是一种对采集数据的总称(metrics并不代表某一种具体的数据格式,是一种对于度量计算单位的抽象)
Prometheus客户端库提供了四种核心度量类型;目前仅在客户端库(以支持针对特定类型的使用进行定制的api)和连接协议中区分这些类型。Prometheus服务器还没有使用类型信息,并将所有数据扁平化为无类型的时间序列;常见使用的就是counter、gauges和histogram
- Gauges
- 最简单的度量指标,只有一个简单的返回值,或者叫瞬间状态,举个例子:要监控硬盘容量或者内存的使用量,那么就应该使用Gauges的metrics格式来度量。
- 因为硬盘的容量或者内存的使用量是随着时间的推移,不过的瞬时变化这种变化没有规律,当前是多少采集回来就是多少,既不能肯定是一直持续增长,也不能肯定是一直降低,这种就是Gauges使用类型的代表。
- Counter
- Counter计数器,从数据量0开始累积计算,在理想状态下,只能是永远的增长,不会降低(一些特殊情况另说).举个例子:比如对用户访问量的采样数据,产品被用户访问一次就是1,过了10分钟后,累积到100过一天后,累积到20000一周后,积累到100000。
- Histograms
- Histogram统计数据的分布情况,比如最小值,最大值,中间值,还有中位数,75百分位,90百分位,95百分位,98百分位,99百分位,和99.9百分位的值(percentiles)。这是一种特殊的Metrics数据类型,代表的是一种近似的百分比估算数值。
- 可以通过Histogram类型(prometheus中,其实提供了一个基于histogram算法的函数,可以直接使用)可以分别统计出,全部用户的响应时间中~=0.05秒的量有多少 0 ~ 0.05秒的有多少, > 2秒的有多少 > 10 秒的有多少 = 1%多少处于速度极快的用户,多少处于慢请求或者有问题的请求。
- Summary
- 与直方图类似,摘要采样观察结果(通常是像请求持续时间和响应大小这样的东西)。虽然它还提供了观测的总数和所有观测值的总和,但它在滑动时间窗口中计算可配置的分位数。
Prometheus的查询提供很多内置的函数,这些函数后续在实战使用到再说,可以在使用查阅官网文档说明,比如
- rate() 函数:就是是专门搭配counter类型数据使⽤的函数,它的功能是按照设置⼀个时间段,取counter在这个时间段中的平均每秒的增量。
- increase():increase 函数 在promethes中,是⽤来 针对Counter 这种持续增长的数值,截取其中⼀段时间的增量。
Prometheus部署
Docker部署
# 挂载配置文件方式部署,准备prometheus.yml文件,可以从二进制文件拷贝,默认配置无需修改,或者从github中获取,这里暴露端口我改为9080,本机已有9090的服务
docker run \
-p 9080:9090 \
-v /home/commons/prometheus/config/prometheus.yml:/etc/prometheus/prometheus.yml \
prom/prometheus
# 挂载配置目录方式部署
docker run \
-p 9090:9090 \
-v //home/commons/prometheus/config:/etc/prometheus \
prom/prometheus
查看docker容器进程

访问http://192.168.50.95:9080/ 出现prometheus的控制台页面
二进制部署
# 下载最新版本v2.37.0的prometheus server
wget https://github.com/prometheus/prometheus/releases/download/v2.37.0/prometheus-2.37.0.linux-amd64.tar.gz
# 解压文件
tar -xvf prometheus-2.37.0.linux-amd64.tar.gz
# 进入目录
cd prometheus-2.37.0.linux-amd64
# 后台运行prometheus server,可通过nohup &之类或后台运行管理工具如daemonize、screen
nohup ./prometheus > prometheus.log 2>&1 &
默认情况下无需修改prometheus根目录下的prometheus.yml配置文件就可启动
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# scrape_interval. 抓取采详数据的时间间隔,默认每15秒去被监控机上采详一次,这个就是我们所说的Prometheus的自定义数据采集频率
# evaluation_interval. 监控数据规则的评估频率,默认为15秒,这个参数是Prometheus多长时间会进行一次监控规则的评估,假如设置当内存使用量 > 70%时,发出报警,这么一条rule(规则),那么Prometheus会默认每15秒来执行一次这个规则,检查内存的情况。
# Alertmanager configuration 这个是Alertmanager是Prometheus的一个用于管理和发出报警的插件
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
# 在这个Jobs 的名字下面,具体来定义,要被监控的节点,以及节点上具体的端口信息等等,如果Prometheus配合,例如consul这种服务发现软件,Prometheus的配置文件,就不在需要人工去手工定义出来,而是能自动发现集群中,有哪些新机器以及新机器上出现了哪些新服务可以被监控
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "prometheus"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["localhost:9090"]
访问http://192.168.5.52:9090/ 出现prometheus的控制台页面,无账号密码验证(如果希望加上验证,可以使用apache httpass方式添加)
访问http://192.168.5.52:9090/ 出现prometheus的控制台页面,无账号密码验证(如果希望加上验证,可以使用apache httpass方式添加)
命令行支持参数可以查阅控制台页面http://192.168.5.52:9090/flags ,也可以直接通过控制台页面查询prometheus.yml的配置内容
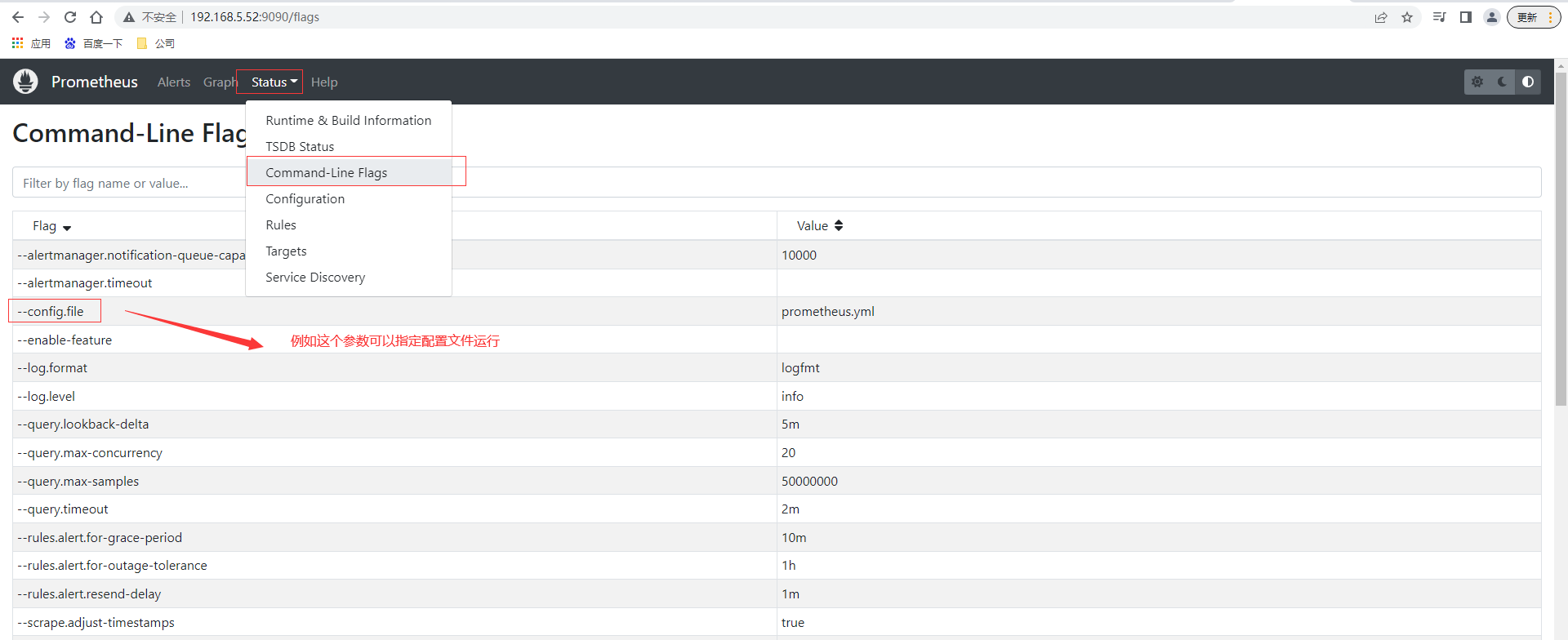
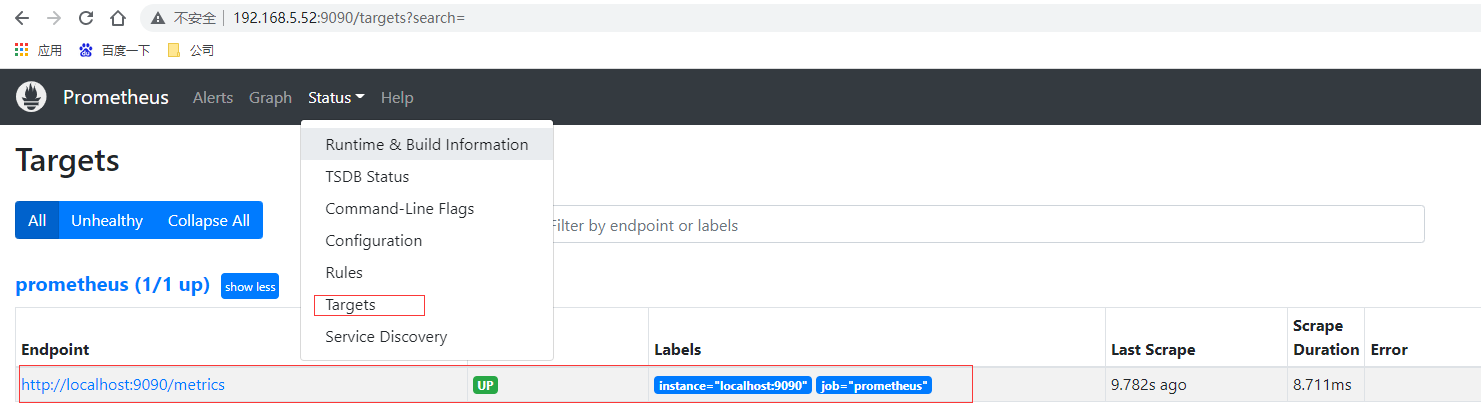
通过上面scrape_configs配置可以知道默认情况下配置了对prometheus的监控,查询控制台页面prometheus的实例节点也是UP状态
prometheus数据存放在data目录下,其中长串字母的是历史数据保留,⽽当前近期数据实际上保留在内存中,并且按照⼀定间隔存放在 wal / ⽬录中防⽌突然断电或者重启以⽤来恢复内存中的数据。
监控对运维重要性
- 运维是什么?
- 说白了就是管理服务器,保证服务器给线上产品提供稳定运行的服务环境。
- 监控是什么?
- 说白了就是用一种形式去盯着观察服务器把服务器的各种行为表现都显示出来用以发现问题和不足。
- 报警是什么?
- 监控和报警这两个词一定要分开说分开理解!监控是监控,报警是报警。监控是把行为表现展示出来,用来观察的。报警则是当监控获取的数据发生异常并且到达了某个临界点的时候,采用各种途径来通知用户通知管理员通知运维人员甚至通知老板。
- 很多时候总是把监控和报警混在一起说这是不正确的需要纠正,报警跟监控 严格来说 是需要分开对待的。
- 因为报警也有专门的报警系统。
- 报警系统包括⼏种主要的展现形式 : 短信报警,邮件报警,电话报警(语⾳播报), 通讯软件。
- 不像监控系统 ⽐较成型的报警系统 ⽬前⼤多数都是收费的 商业化。
- 报警系统中 最重要的⼀个概念之⼀ 就是对报警阈值的理解,阈值(Trigger Value) ,是监控系统中 对数据到达某⼀个临界值的定义;例如: 通过监控发现,当前某⼀台机器的CPU突然升⾼,到达了 99%的使⽤率,99 就是作为⼀次报警的 触发阈值。
监控理论基础
-
监控重要性
- 监控在企业中扮演着重要的监督者的⾓⾊,任何⼀个地⽅出现问题都需要及时的知道,很多情况下企业对某种类型的监控需要⾮常的敏感(采集的精度),例如⽤户正常访问这种业务级别的监控⼀旦出现了问题需要在秒级时间知道,(时间=钱)不然就是毁灭性的灾难和损失由其是针对哪些⼤规模的企业。
-
监控运维基础⼯作
- 基础运维(系列第⼀阶段)⼀线 主要扮演着 ⼀个处理⽇常任务,及时救⽕这样的⾓⾊。
- 监控的搭建 和 数据采集的⼯作 很多时候 需要依赖于 运维开发的协助(开发 创新),不管是哪⼀种运维(哪怕你是运维架构师 运维专家)在紧急的时候 ⼈⼈都要扮演起 救⽕英雄的⾓⾊⽽救⽕ 指的是 及时的发现和解决线上出现的各种故障 问题那么为了要做到 及时的发现问题,那么⼀个好的完善的监控系统 就很⾃然的作为运维⼯作中的第⼀优先任务。
-
监控系统设计
- 评估系统的业务流程 业务种类 架构体系,各个企业的产品不同,业务⽅向不同,程序代码不同,系统架构更不同,对于各个地⽅的细节 都需要有⼀定程度的认知 才可以开起设计的源头
- 分类出所需的监控项种类,⼀般可分为 : 业务级别监控 / 系统级别监控 / ⽹络监控 / 程序代码监控/ ⽇志监控 / ⽤户⾏为分析监控/ 其它种类监控⼤的分类 还有更多的细⼩分类。
-
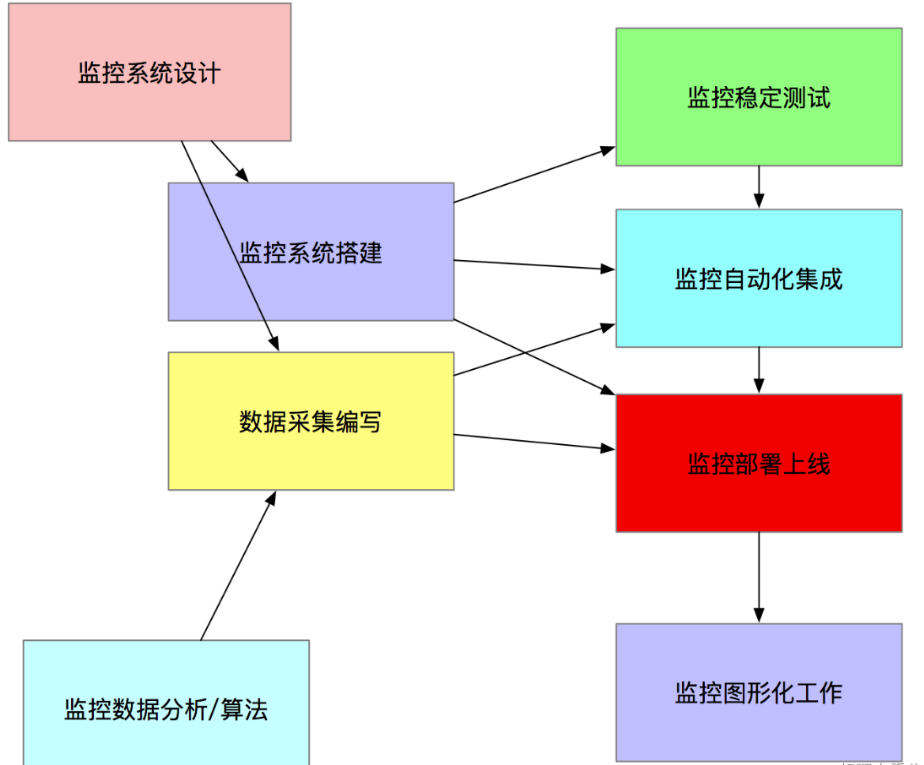
监控系统实施总体过程
- 监控系统搭建
- 单点服务端的搭建(prometheus)
- 单点客户端的部署
- 单点客户端服务器测试
- 采集程序单点部署
- 采集程序批量部署
- 监控服务端HA / cloud
- 监控数据图形化搭建(Grafana)
- 报警系统测试(如Pagerduty)
- 报警规则测试
- 监控+报警联合测试
- 正式上线监控
- 数据采集编写
- shell / python / awk / lua (Nginx 安全控制,功能分类)/ php / perl/ go,作为监控数据采集, ⾸推 shell + python , 如果说 数据采集选取的模式 对性能/后台/界⾯ 不依赖, 那么shell速度最快 成本最低。
- ⼀次性采集和后台采集。
- 监控数据分析/算法
- 监控的数据分析和算法 其实⾮常依赖 运维架构师对Linux操作系统的各种底层知识的掌握
- 监控稳定测试
- 稳定性测试 就是通过⼀段时间的单点部署观察 对线上有没有任何影响
- 监控自动化
- 如监控客户端的批量部署,监控服务端的HA再安装,监控项⽬的修改,监控项⽬的监控集群变化的自动化, Puppet(配置⽂件部署),Jenkins(CI 持续集成部署) , CMDB(配置管理数据库)
- 监控图形化
- 采集的数据 和 准备好的监控算法,最终需要⼀个好的图形展⽰ 才能发挥最好的作⽤
- 监控系统搭建
监控面临问题
- 监控自动化依然不够
- 很少能和CMDB完善的结合起来
- 监控依然需要大量人工
- 监控的准确性和真实性 提⾼的缓慢
- 监控工具和方案的制定较为潦草
- 对监控本身的重视程度依然有待提高
Prometheus部署
Prometheus主要有两种方式采集:pull 主动拉取的形式和push 被动推送的形式。
pull : 指的是客户端(被监控机器)先安装各类已有exporters(由社区组织或企业开发的监控客户端插件)在系统上之后,exporters以守护进程的模式运行,并开始采集数据,exporter本身也是一个http_server可以对http请求作出响应返回数据,Prometheus用pull这种主动拉取的方式(HTTP get)去访问每个节点上exporter并采集回需要的数据。
push: 指的是在客户端(或服务端)安装官方提供的pushgateway插件,然后使用我们运维自行开发的各种脚本,把监控数据组织成K/V的形式metrics形式,发送给pushgateway之后pushgateway会在推送给Prometheus,这种是一种被动的数据采集模式。
exporter的使用
官网提供提供多种独立常用的exporter,这些exporter分别使用不同的开发语言开发
- prometheus
- alertmanager
- blackbox_exporter
- consul_exporter
- graphite_exporter
- haproxy_exporter
- memcached_exporter
- mysqld_exporter
- node_exporter
- pushgateway
- statsd_exporter
比如最常用的 node_exporter就非常强大,几乎可以把Linux系统中和系统自身相关的监控数据全抓出来(很多参数)
# 下载最新版本v1.4.0node_exporter
wget https://github.com/prometheus/node_exporter/releases/download/v1.4.0-rc.0/node_exporter-1.4.0-rc.0.linux-amd64.tar.gz
# 解压
tar -xvf node_exporter-1.4.0-rc.0.linux-amd64.tar.gz
# 进入目录
cd node_exporter-1.4.0-rc.0.linux-amd64
# 启动node_exporter
nohup ./node_exporter > node_exporter.log 2>&1 &
node_exporter默认工作在9100端口,可以响应Prometheus_server发过来的HTTP_GET请求,也可以响应其它方式的HTTP_GET请求,测试下请求
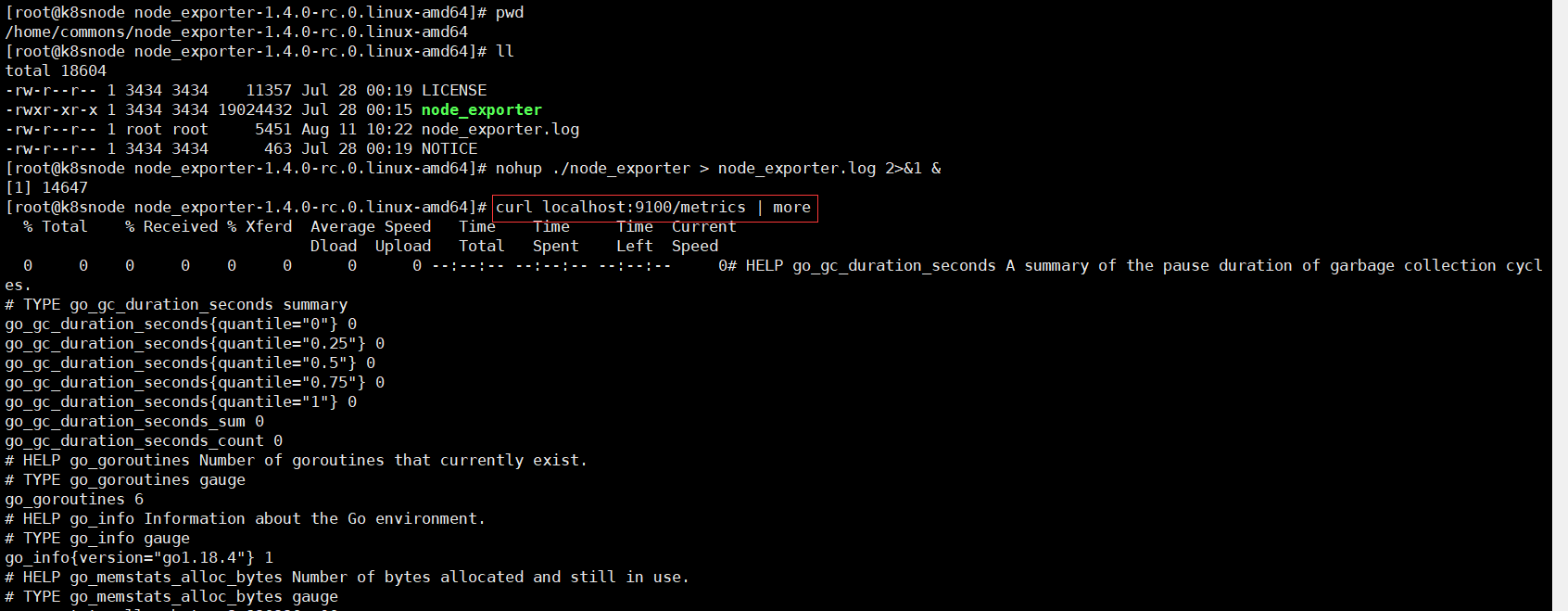
执行curl之后,可以看到node_exporter返回了大量的metrics类型的K/V数据,这些返回的K/V数据,其中的Key名称,可以直接复制到Prometheus的查询命令行来查看结果。将刚才node_exporter部署节点的通过文件配置发现的加入Prometheus的监控中,在Prometheus的prometheus.yml配置文件内scrape_configs配置节点中增加job_name: "node_exporter"的配置信息
scrape_configs:
- job_name: "node_exporter"
static_configs:
# targets可以并行写入多个节点,用逗号隔开,机器名或者IP+端口号,端口号:通常用的就是exporter的端口,这里9100其实是node_exporter的默认端口
- targets: ["192.168.50.95:9100"]
重新启动prometheus,prometheus就可以通过配置文件识别监控的节点,持续开始采集数据。查看监控目标页面已经有加进来的node_exporter节点了
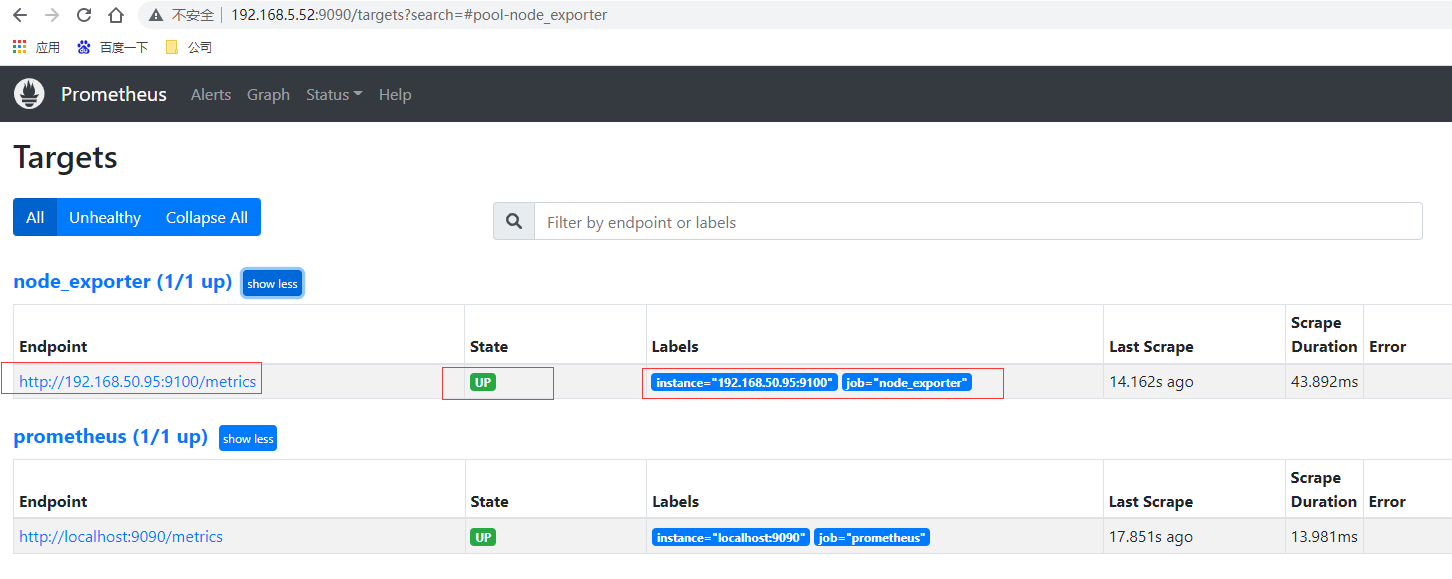
# 先通过http请求查看刚部署的node_exporter节点的内存信息
curl localhost:9100/metrics | grep node_memory_MemFree

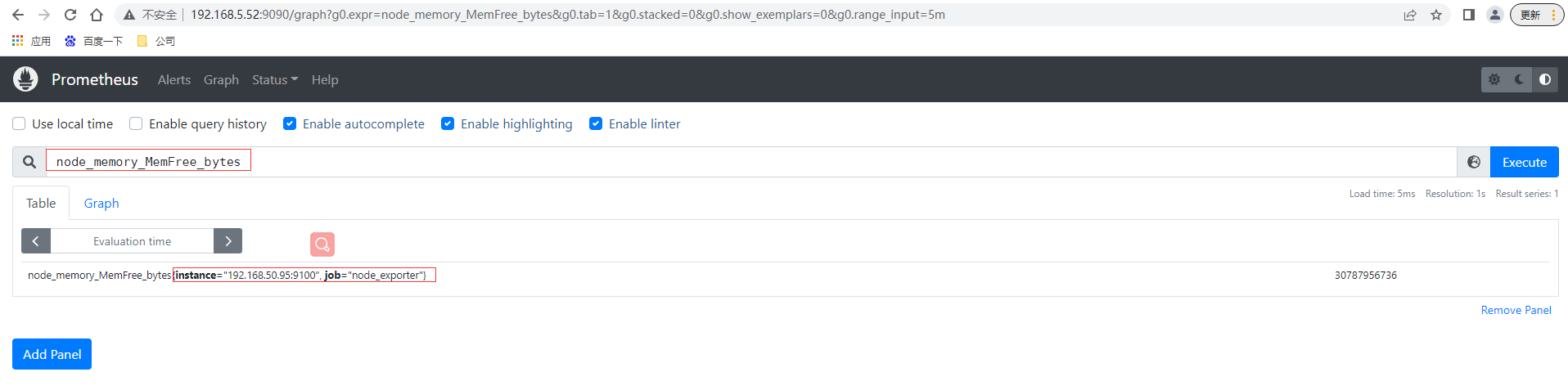
本⾝node_exporter提供的 keys 实在太多了 (因为 都是从Linux系统中的底层各种挖掘数据回来),找到key为node_memory_MemFree_bytes后直接复制在prometheus的Graph页面中查看,已经可以看到查询的数据
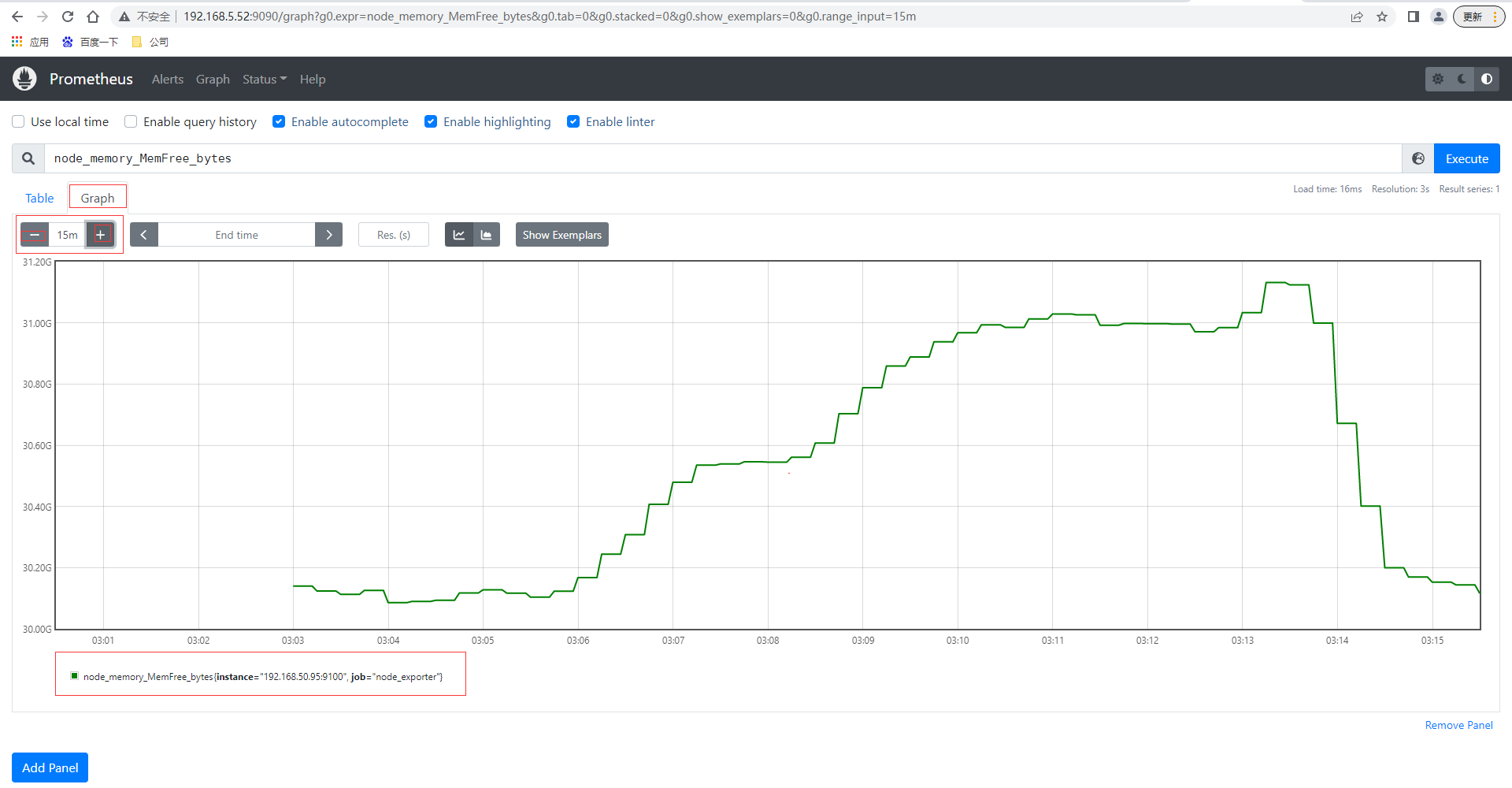
还可以切换到图查看最近15分钟的数据曲线趋势图
pushgateway使用
pushgateway 是另⼀种采⽤被动推送的⽅式(⽽不是exporter主动获取)获取监控数据的prometheus 插件,它是可以单独运⾏在 任何节点上的插件(并不⼀定要在被监控客户端),然后通过⽤户⾃定义开发脚本把需要监控的数据发送给pushgateway,然后pushgateway再把数据推送给prometheus server。
pushgateway的安装以及运行和配置,pushgateway 跟 prometheus和 exporter ⼀样。
# 下载最新版本v1.4.0node_exporter
wget https://github.com/prometheus/pushgateway/releases/download/v1.4.3/pushgateway-1.4.3.linux-amd64.tar.gz
# 解压
tar -xvf pushgateway-1.4.3.linux-amd64.tar.gz
# 进入目录
cd pushgateway-1.4.3.linux-amd64/
# 启动pushgateway
nohup ./pushgateway > pushgateway.log 2>&1 &
从上面可以看到pushgateway默认的端口为9091,接下来 在prometheus.yml 配置⽂件中, 单独定义⼀个job配置target 指向到pushgateway运⾏所在的机器名和pushgateway运⾏的端口即可
- job_name: "pushgateway"
static_configs:
# targets可以并行写入多个节点,用逗号隔开,机器名或者IP+端口号,端口号:通常用的就是pushgateway的端口,这里9091其实是pushgateway的默认端口
- targets: ["192.168.50.94:9091"]
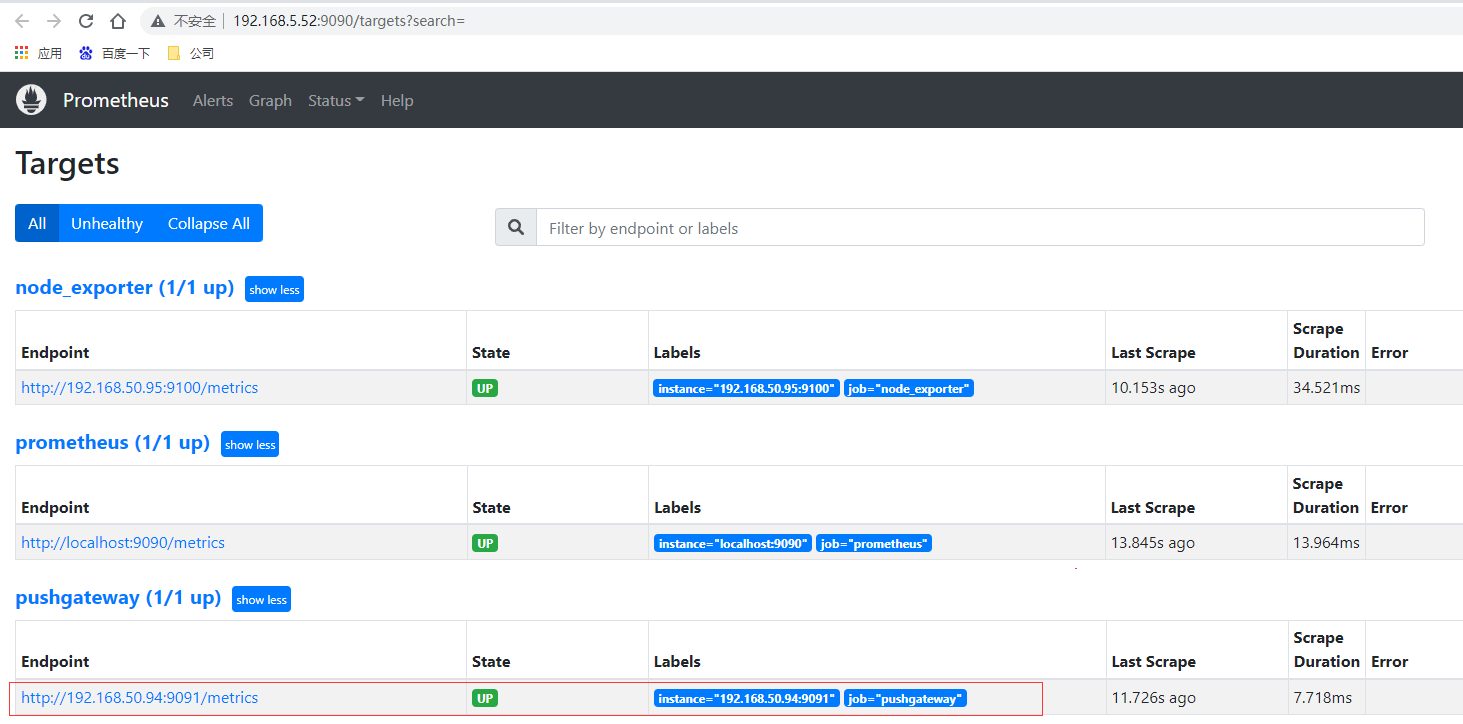
重新启动prometheus,查看监控目标页面已经有加进来的pushgateway节点了
pushgateway 本⾝是没有任何抓取监控数据的功能的 它只是被动的等待推送过来,pushgateway 编程脚本的写法,这里使⽤shell 编写的 pushgateway脚本⽤于抓取 TCP waiting_connection 瞬时数量,编写monitor.sh如下
#!/bin/bash
instance_name=`hostname -f | cut -d'.' -f1` #本机机器名变量于之后的 标签
if [ $instance_name == "localhost" ];then # 要求机器名不能是localhost不然标签就没有区分了
echo "Must FQDN hostname"
exit 1
fi
# For waitting connections
label="count_netstat_wait_connections" # 定义个新的 key
# 定义1个新的数值 netstat中 wait 的数量,通过Linux命令⾏ 就简单的获取到了需要监控的数据 TCP_WAIT数
count_netstat_wait_connections=`netstat -an | grep -i wait | wc -l`
echo "$label : $count_netstat_wait_connections"
# 把 key & value 推送给 pushgatway
echo "$label $count_netstat_wait_connections" | curl --data-binary
@- http://192.168.50.94:9091/metrics/job/pushgateway/instance/$instance_name
如果是每分钟推送一次则可以结合crontab,如* * * * * sh /home/commons/script/monitor.sh,如果是短于一分钟也可以shell脚本通过循环使用sleep实现;再到页面上查看刚才自定义的key,已经有采集到数据。
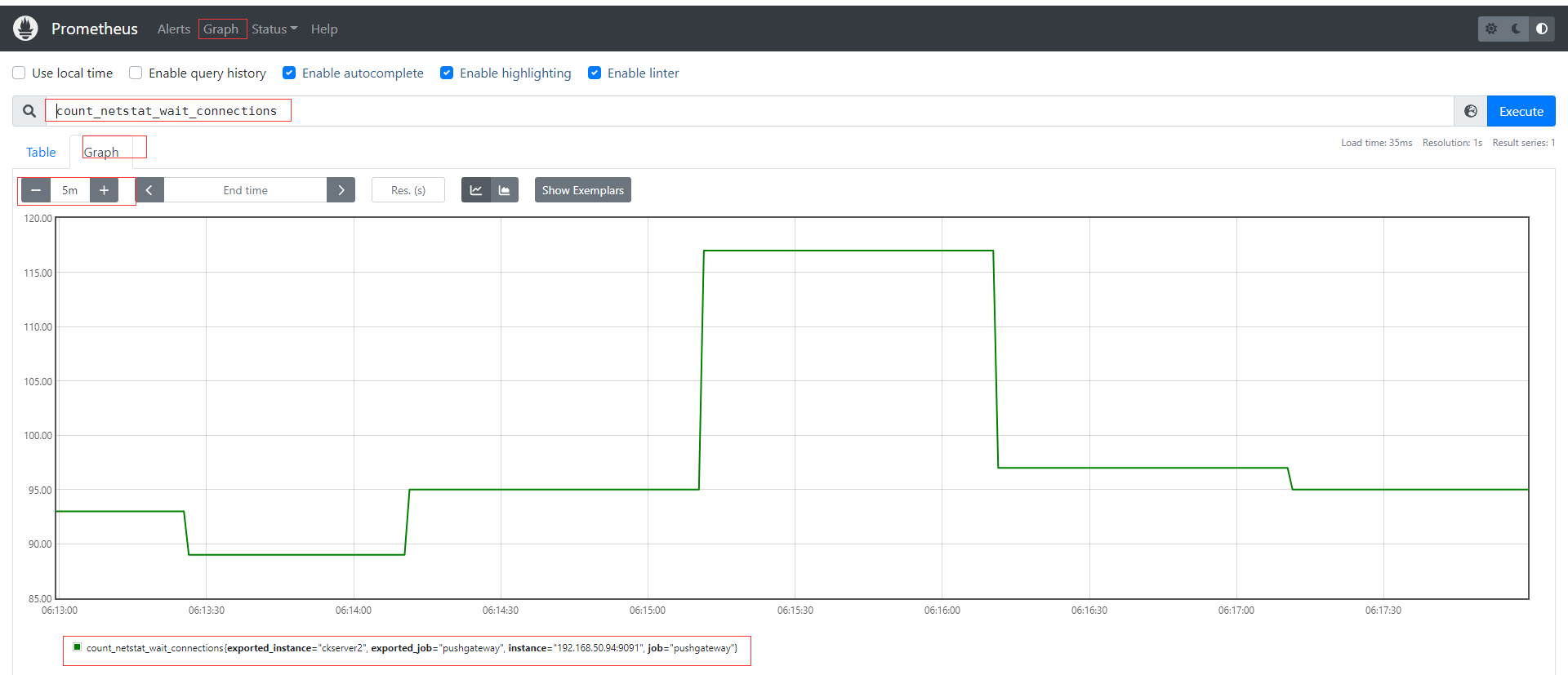
其他种类的监控数据我们都可以通过类似的形式直接写脚本发送实现自定义采集。
pushgateway这种⾃定义的采集⽅式⾮常的快速⽽且极其灵活⼏乎不收到任何约束,⾮常希望 使⽤pushgateway来获取监控数据的,各类的exporters虽然玲琅满⽬⽽且默认提供的数据很多了已经,⼀般情况下企业中只安装 node_exporter 和 DB_exporter两个,其他种类的 监控数据倾向于全部使⽤pushgateway的⽅式采集 (要的就是快速~ 灵活~)。官网在最佳实践章节也有说明何时使用pushgateway,Pushgateway是一个中介服务,它允许你从无法抓取的工作中推送指标。
- pushgateway 会形成⼀个单点瓶颈,假如好多个脚本同时发送给 ⼀个pushgateway的进程如果这个进程没了,那么监控数据也就没了。
- pushgateway 并不能对发送过来的脚本采集数据进⾏更智能的判断,假如脚本中间采集出问题了那么有问题的数据pushgateway⼀样照单全收发送给Prometheus。
CPU使用率监控示例
# 通过node_cpu关键字查看关于cpu的监控项
curl localhost:9100/metrics | grep node_cpu
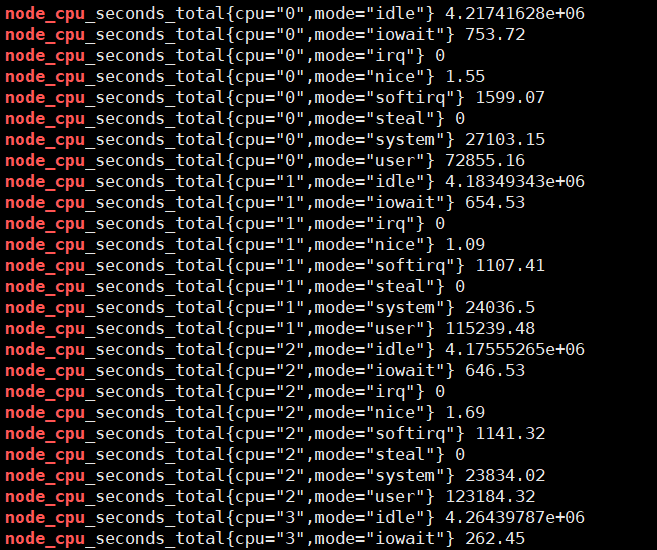
输入查询之后,可以看到结果,这个值是CPU各个核各个状态下从开机开始一直累积下来的CPU使用时间的累计值,但我们理解的CPU应该是使用率,类似百分50%和80%这样的数据才更好理解。
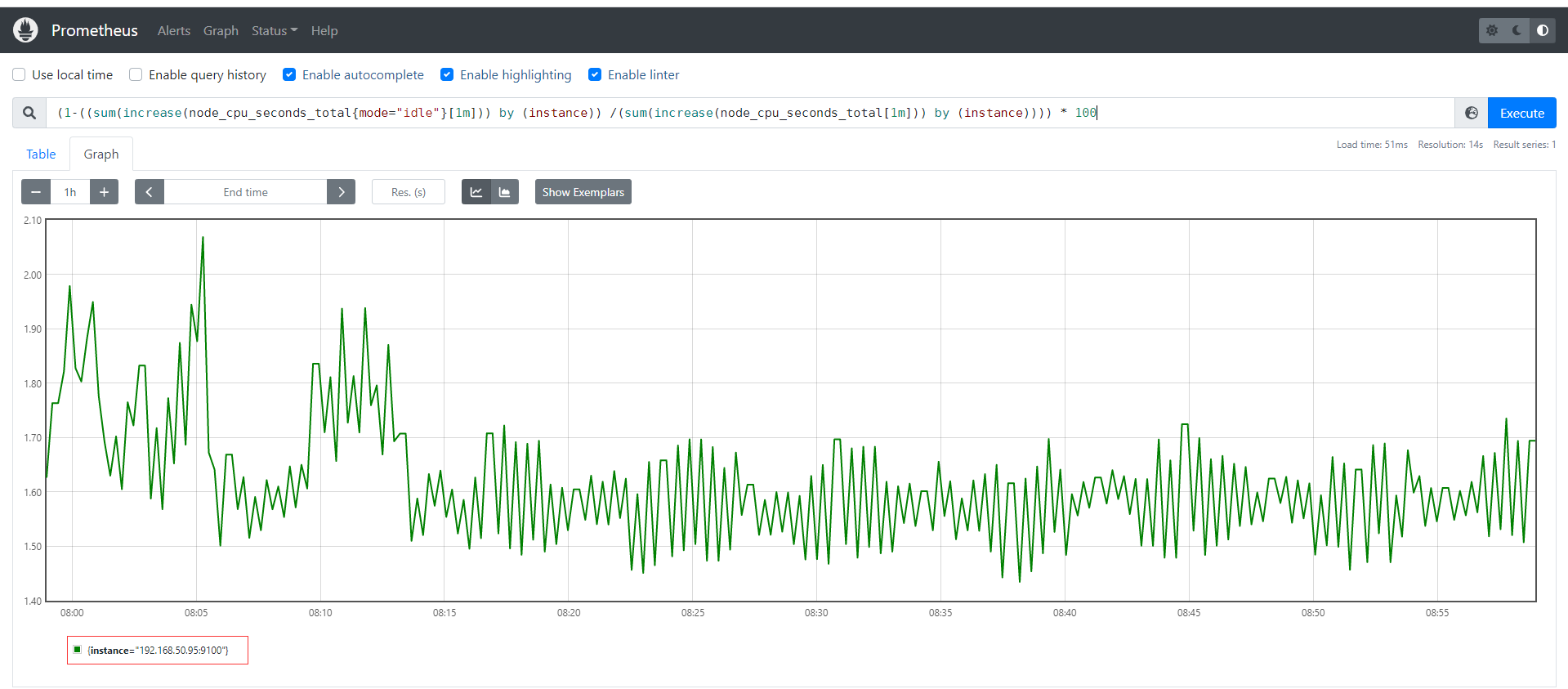
Prometheus对linux CPU的采集,并不是直接给我们返回一个现成的CPU百分比,而是返回Linux中很底层的cpu时间片,累积数值的咋样一个数据(我们平时用惯了top/uptime这种简便的方式看CPU使用率,根本没有深入理解所谓的CPU使用率在Linux中到底怎么回事),CPU使用时间包括CPU用户态使用时间,系统/内核态使用时间,nice值分配使用时间,空闲时间,中断时间等等。各个CPU状态的时间单位解如下:

# 编写数学公式如下,所以说需要理解底层原理和Prometheus对于数学的支持
(1-((sum(increase(node_cpu_seconds_total{mode="idle"}[1m])) by (instance)) /(sum(increase(node_cpu_seconds_total[1m])) by (instance)))) * 100
Grafana部署
Grafana 官网地址 https://grafana.com/
Grafana 官网文档地址 https://grafana.com/docs/grafana/latest/?pg=oss-graf&plcmt=resources
Grafana GitHub地址 https://github.com/grafana/grafana
Grafana 是⼀款近⼏年新兴的开源数据绘图⼯具平台默认⽀持如下这么多种数据源作为输⼊,无论它们存储在哪里都可以查询、可视化、警告和理解您的指标,Grafana可以通过漂亮、灵活的仪表板创建、探索和共享所有的数据。最新版本为9.0.7,由于Grafana有告警功能,因此可以直接Grafana来替换prometheus自身提供的告警系统,这也是目前各大企业最青睐可视化产品和最佳实践。
# 下载最新版本v9.0.7的grafana
wget https://dl.grafana.com/enterprise/release/grafana-enterprise-9.0.7.linux-amd64.tar.gz
# 解压文件
tar -xvf grafana-enterprise-9.0.7.linux-amd64.tar.gz
# 进入目录
cd grafana-9.0.7
# 后台运行grafana-server,可通过nohup &之类或后台运行管理工具如daemonize、screen
nohup ./grafana-server > grafana-server.log 2>&1 &
访问grafana默认端口3000,http://192.168.5.52:3000/ 输入用户名密码admin/admin ,下一步需要修改密码后进入主页面如下
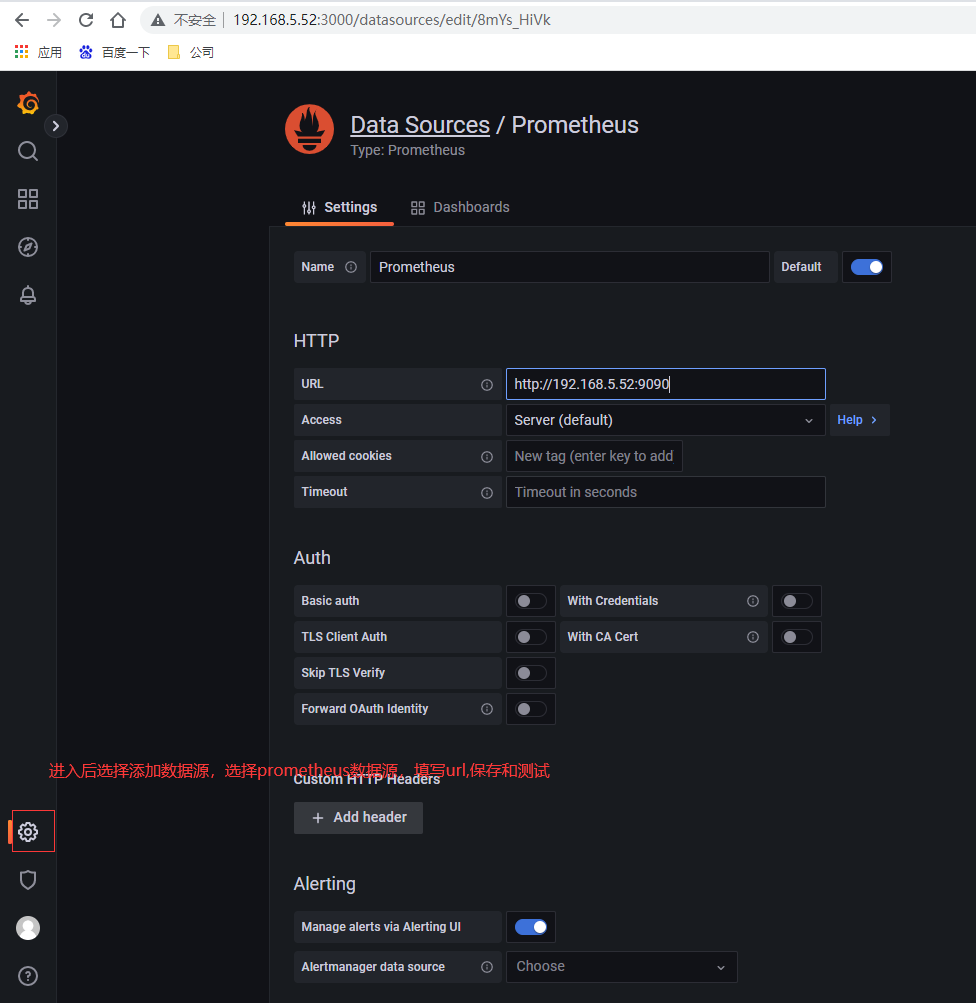
配置数据源
选择左侧面板下面按钮,然后选择数据源,类型为prometheus,输入url即可
创建测试Graph
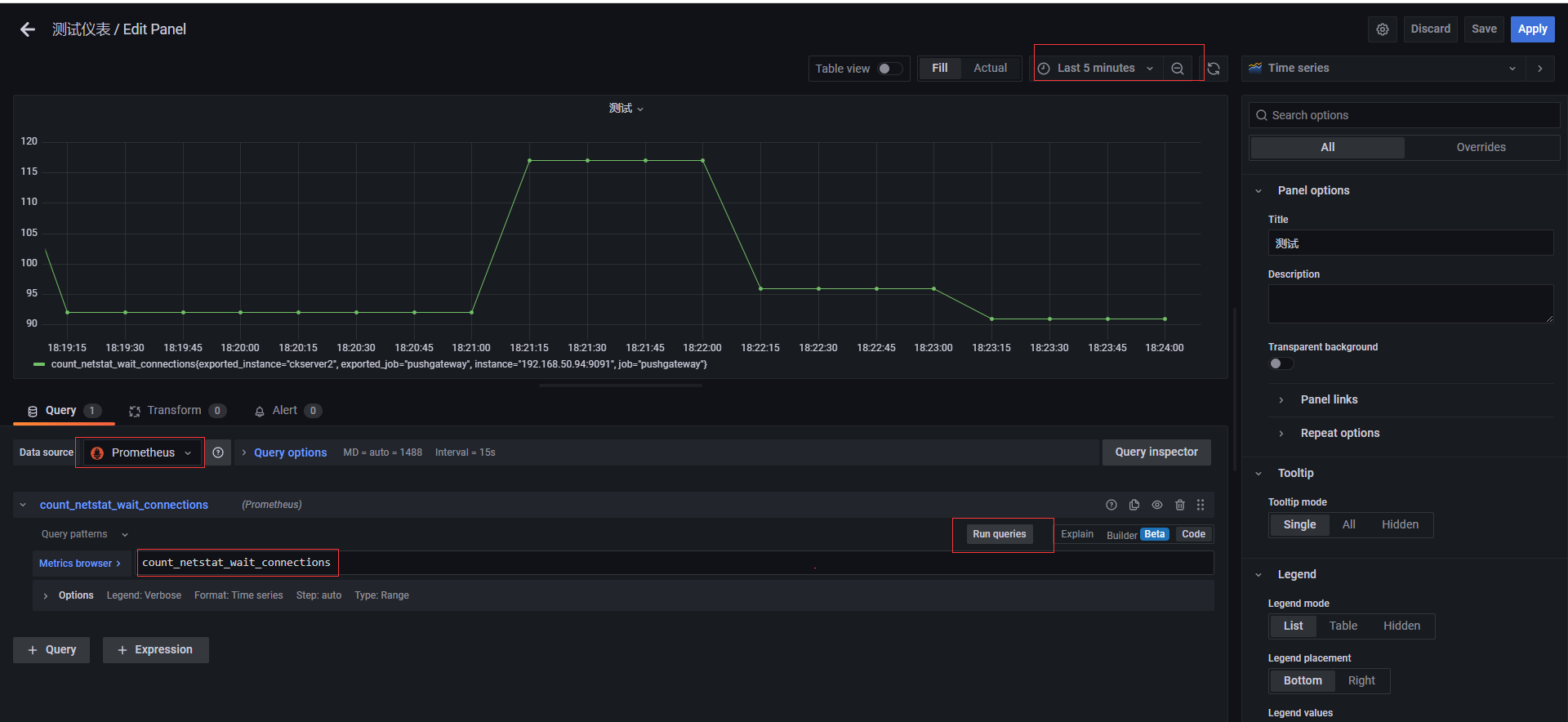
创建一个dashboards,编辑仪表盘,添加图,选择数据源,选择原始查询方式,填入前面自定义收集指标count_netstat_wait_connections,运行查询之后,选择最近5分钟的数据,简单图就出来了
**本人博客网站 **IT小神 www.itxiaoshen.com
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK