

DataOps:深刻影响现代数据栈发展
source link: https://blog.csdn.net/m0_46700908/article/details/126132861
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.


嘉宾 | 代立冬 整理 | 西狩
出品 | CSDN云原生
数字化的时代大潮推动了互联网的发展,云计算、大数据、云原生等技术不断成熟,使数据处理的方式发生变革,现代数据栈也因此开启了“百家争鸣”的新时代。
2022年7月12日,在CSDN云原生系列在线峰会第13期“现代数据栈峰会”上,白鲸开源联合创始人代立冬深入讲解了DataOps中任务编排、数据集成。

为什么是DataOps?
数字化时代
数字化时代的到来,带来了数据量的爆发式增长:
-
全球数据中心流量:每年32ZB;
-
5亿业务数据用户正在不断增长中;
-
200亿台互联设备;
-
超过94%的数据中心流量来自于云端;
-
10亿名工作人员将由AI/ML辅助工作。
伴随着数据的增长,数字化应用的机会空间更加广阔:新的客户获取模式、新的运营体系、新的业务模式、新的产品服务。
与此同时,数据技术也呈现出了多元化发展的趋势,如数据分析和数据可视化、机器学习、流式数据处理、离线数据处理、统计和数据挖掘等。在现代化数据栈中,数据开发者也拥有更多选择。
DataOps的诞生及发展
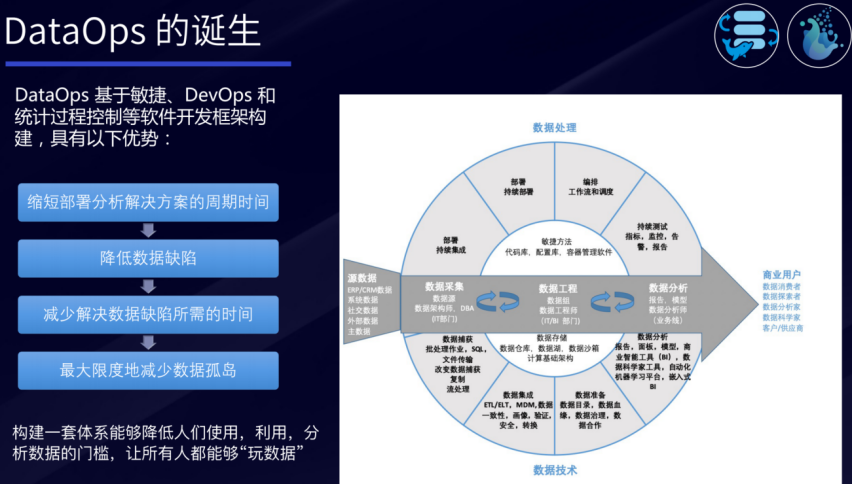
DataOps基于敏捷、DevOps和统计过程控制等软件开发框架构建,具有以下优势:
-
缩短部署分析解决方案的周期时间;
-
降低数据缺陷;
-
减少解决数据缺陷所需的时间;
-
最大限度地减少数据孤岛。
一句话总结DataOps:它构建了一套能够降低人们使用、利用、分析数据门槛的数据体系,让数据能力平民化。
2014年,Lenny Liebmann提出了DataOps的概念,在《3 reasons why DataOps is essential for big data success》这篇文章中,Lenny提出DataOps是优化数据科学和运营团队之间协作的一些实践集。
2015年,Andy Palmer将这个理念发扬光大,提出了DataOps的四个关键构成:数据工程、数据集成、数据安全和数据质量。
2017年,Jarh Euston把DataOps的核心定义为从数据到价值,首次把DataOps和业务价值关联起来。
2018年,Gartner把DataOps纳入到Data Management的技术成熟度曲线,标志着DataOps正式被业界所接纳并推广起来。
Data Community
DataOps的发展催生出了一批全新的DataOps组织,组织由不同分工的数据工作者组成,共同支持Data Community的日常工作。Data Community干什么呢?它负责做高效率的运营和成本的优化,以及去提升分析的洞察力和决策力,还有业务创新和客户体验的改进、风险管理以及数据合规。
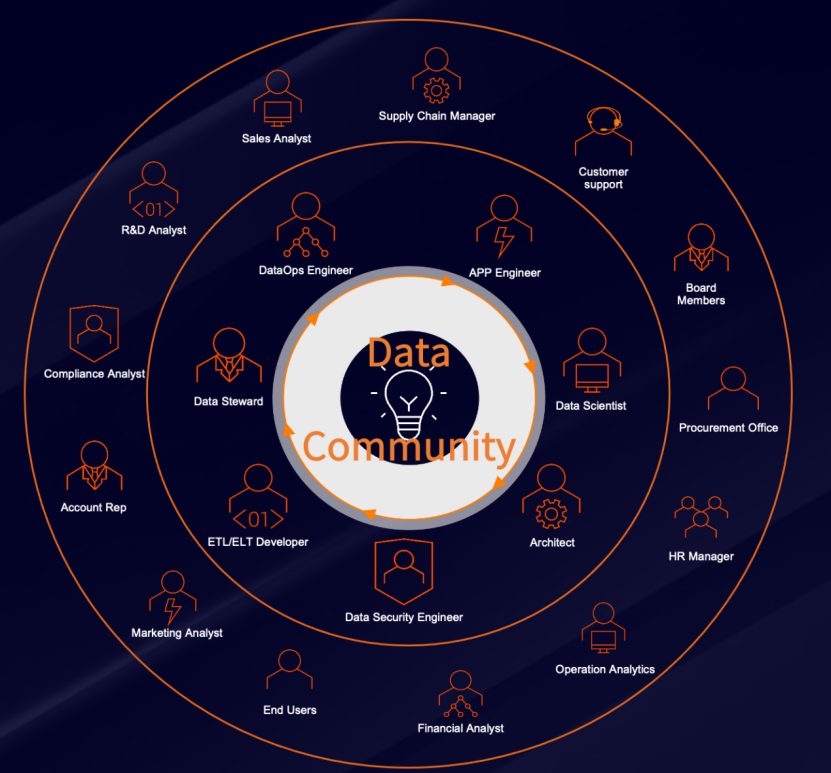
Data Community提供基于DataOps的最佳实践,适用于不同部署能力的所有消费者,可以从小规模业务需求开始,平滑拓展,并且具备全栈技术支持能力和完整的开放的可拓展的能力,能够连接任何数据源,运行在任何环境中。
Modern Data Stack
现代数据栈的终极目标是提供数据分析和数据自服务的灵活性,越来越多的人们在海外依赖于云上的服务。因此,现代数据栈中会更多基于云原生的全套服务组件、以云数据湖仓为核心完成数据处理,并且通过低代码、零代码的界面化操作,将数据处理变得更加简单。
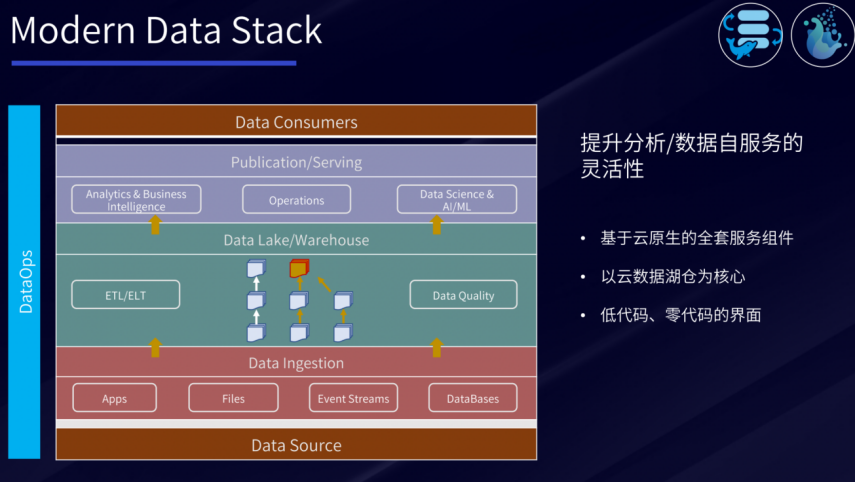
现代化数据管理还具备几个关键能力:云原生、DataOps、AI/ML驱动、Automation、全局治理与隐私、组织/流程。
现代DataOps架构
一个典型的DataOps平台架构从Sources到Insights涉及的技术有:Development、Deployment、Orchestration、Testing and Monitoring,以及Data Warehouse/Lake、Data Integration、Data Governance、Data Analytics等。


DataOps核心与灵魂:数据编排
DolphinScheduler自2017年12月开始启动,到2021年4月9日正式成为Apache顶级项目,再到如今Apache 3.0版本发布,期间经历了20多个版本的发展与迭代,社区发展早期邀请了很多种子用户对DolphinScheduler进行实践落地,使得DolphinScheduler能力逐渐成熟,成为十分流行的数据任务编排平台。
Apache DolphinScheduler任务编排主要具备6大核心能力:可视化、稳定高可用/高性能、丰富的任务类型、依赖、任务日志/告警机制、补数。
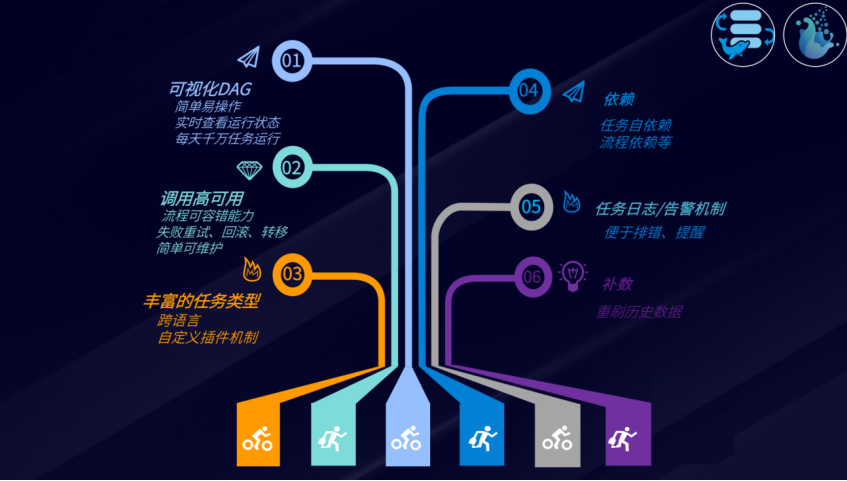
为何选择DolphinScheduler?
DolphinScheduler具备几大核心特点和能力:高可靠、简单易用、使用场景丰富、高扩展性和云原生能力,DolphinScheduler 2.0架构已能支撑每日千万级任务调度场景,也能够支持绝大部分企业级应用场景。

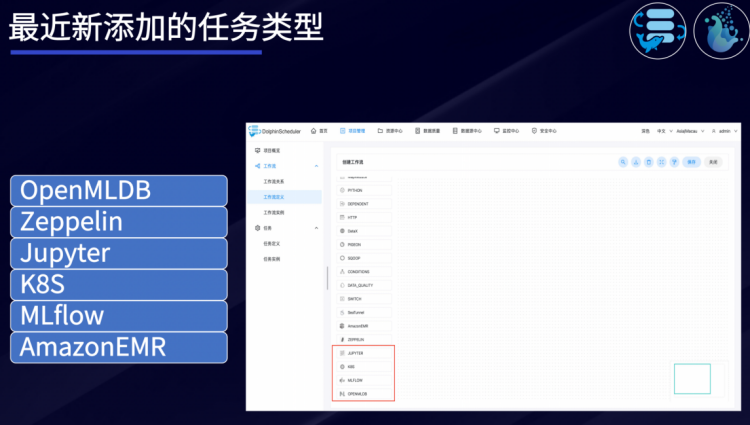
丰富的任务类型
DolphinScheduler最新还添加了OpenMLDB、Zeppelin、Jupyter、K8s、MLflow、AmazonEMR 等任务类型,能够提供更全面的任务处理能力。
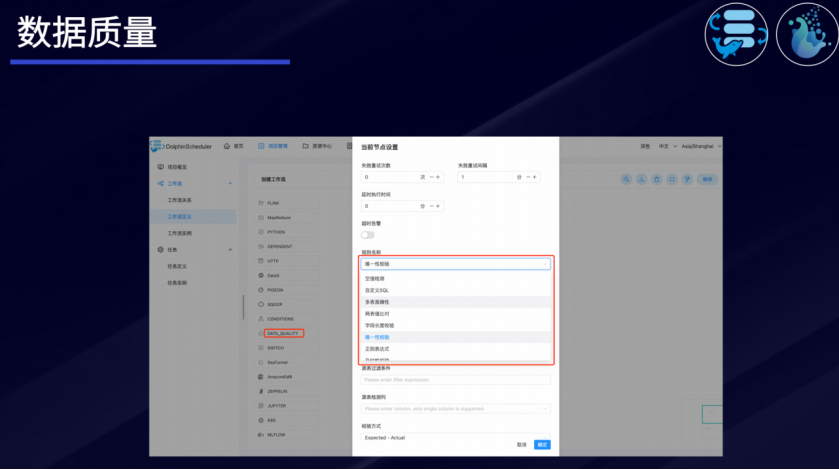
数据质量校验
DolphinScheduler可以通过DATA_QUALITY节点设置数据质量规则,确保得到高质量的数据。数据质量规则包括空值检测、自定义SQL、多表准确性、两表值对比、字段长度校验、唯一性校验、正则表达式等。此外,还支持设置源表过滤条件、设置源表检测列、指定校验方式。
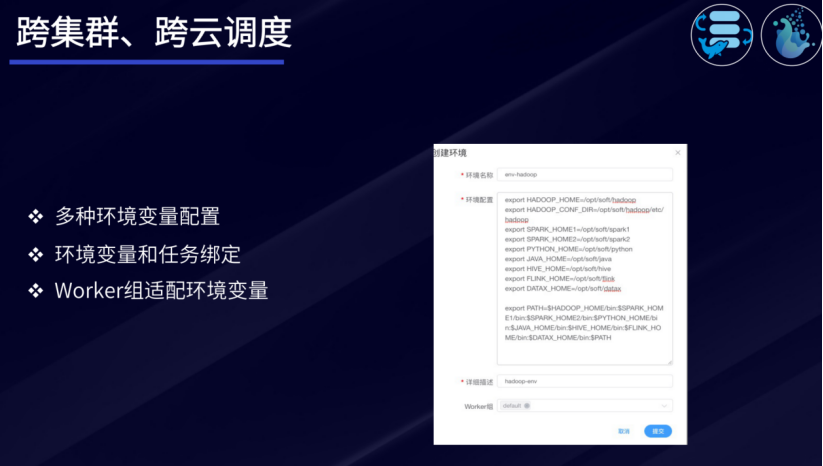
跨集群、跨云调度
DolphinScheaduler能够提供跨集群、跨云调度的治理能力。在3.0版本中,DolphinScheaduler可以通过多种环境变量配置、环境变量和任务绑定、Worker组适配环境变量等方式,支持用户便捷地完成跨集群、跨云调度的任务调度操作。
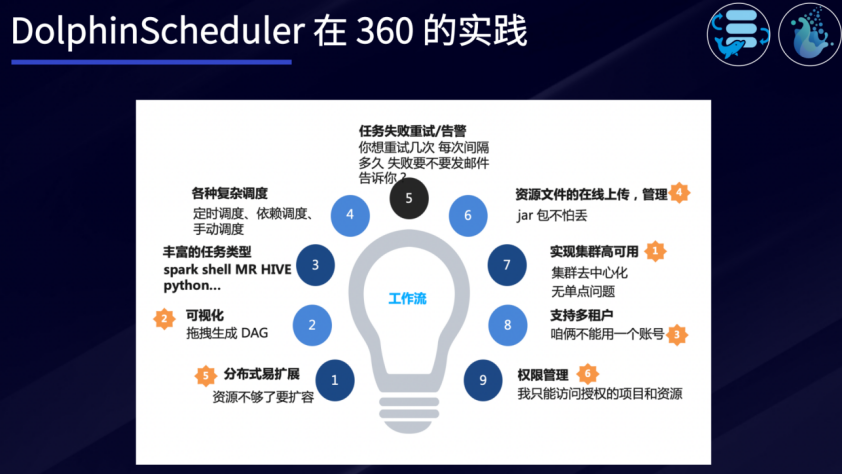
DolphinScheduler实践案例
DolphinScheduler在360完成了9大场景的成功的落地实践经验:
-
分布式易扩展;
-
丰富的任务类型(Spark、Shell、MR、Hive、Python等);
-
各种复杂调度(定时调度、依赖调度、手动调度);
-
任务失败重试/告警;
-
资料文件的在线上传和管理;
-
实现集群高可用;
-
支持多租户;
-
权限管理。

DataOps关键能力:数据集成
Apache SeaTunnel(incubator)是新一代高性能的云原生海量数据集成项目,用于解决数百种数据源之间的数据同步与转换问题,于2017年开源,2021年12月31日正式进入Apache孵化器,有腾讯云、OPPO、Bilibili、Shopee等 100多家公司在使用,目前已经在B站支撑每日千亿级数据集成。
Apache SeaTunnel的优势在于:
-
组件丰富:内置组件,支持各种数据产品方便快捷地传输和集成数据;
-
高扩展性:基于模块化和插件化设计,支持热插拔,带来更好的扩展性;
-
简单易用:特有的架构设计下,使得开发配置更简单,几乎零代码,无使用成本;
-
成熟稳定:经历多家企业,大规模生产环境使用和海量数据的洗礼,稳定健壮。
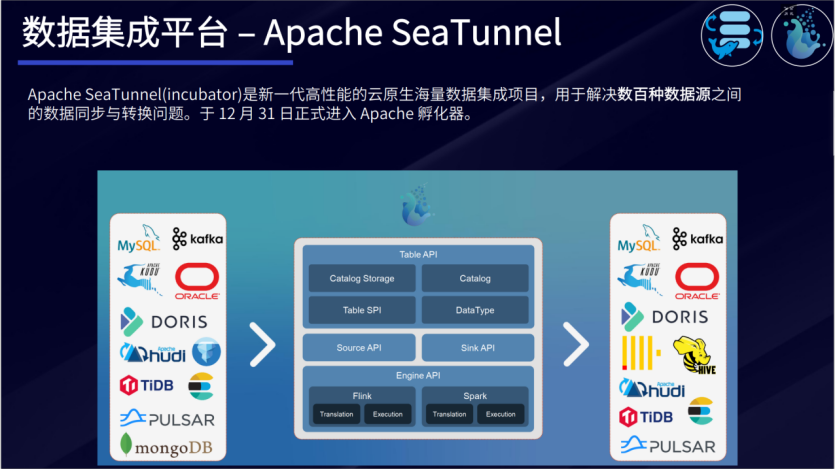
SeaTunnel致力于解决以下问题:
-
数据丢失与重复;
-
任务堆积与延迟;
-
吞吐量低;
-
缺少应用运行状态监控;
-
二次开发扩展复杂。

DataOps与开源
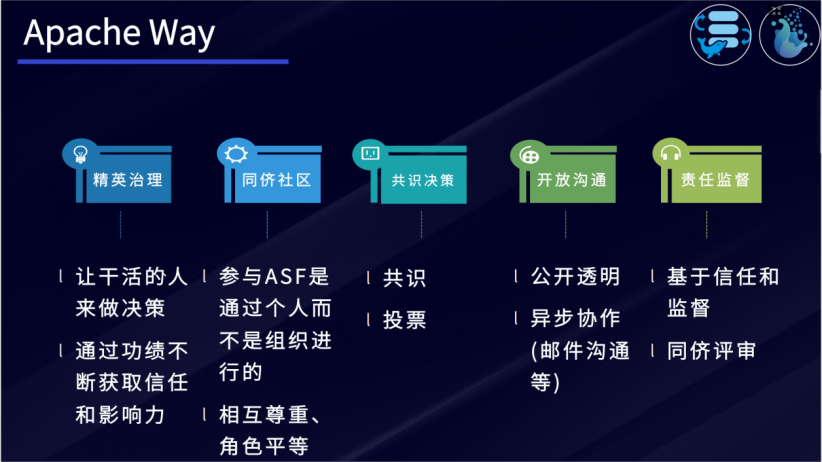
“社区大于代码”是Apache所崇尚的开源文化理念,并且Apache在这基础上构建了一系列的社区治理方法:精英治理、同侪社区、共识决策、开放沟通、责任监督。
这里的社区与前面提到的Data Community是一脉相承的,Data Community 也是一群致力于数据能力平民化而聚集到一起的。
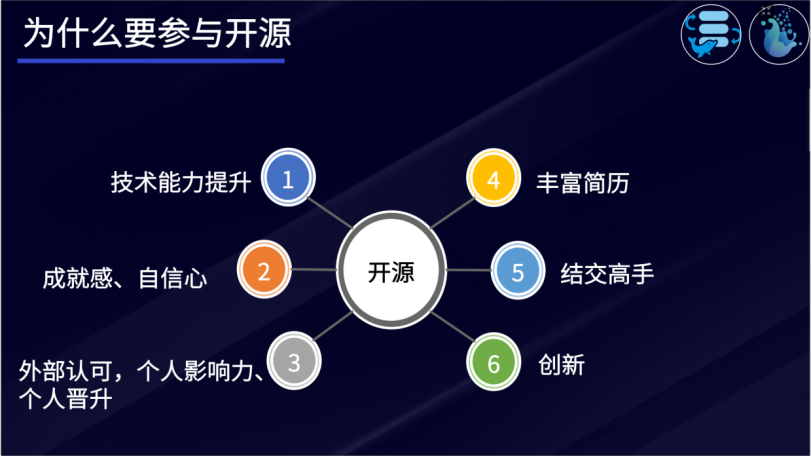
为什么要参与开源
作为一个技术人,有没有必要参与开源?答案是肯定的。开源不是天才的甜点,而是勤奋者的盛宴。
-
参与开源能够让自身技术能力得到提升,进而产生成就感,树立自信心;
-
参与开源能够让你结识更多优秀的人才,提高自己的个人影响力,丰富自身履历;
-
参与开源能够在公司内部得到更好的晋升机会,在外部社会更容易得到认可;
-
参与开源能够与各路高手进行思想碰撞,激发自己的创新能力。
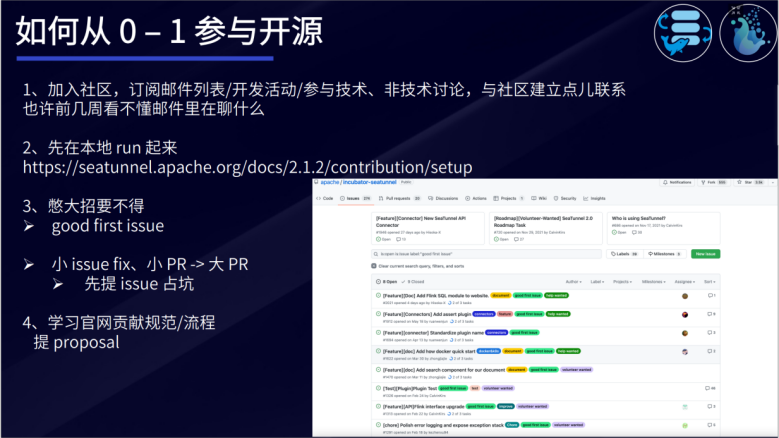
如何从0-1参与开源
想要参与到开源项目中,有几点小建议:
-
与社区建立联系:加入社区,订阅邮件列表/开发活动/参与讨论;
-
实践出真知:先把项目在本地run起来;
-
积跬步以至千里:憋大招要不得,先从小细节入手;
-
无规矩不成方圆:学习官网贡献规范/流程,提proposal。

DolphinScheduler Roadmap
DolphinScheduler目前的Roadmap包括:
-
3.0-beta -> 3.0-release版本发布;
-
实时任务的支持;
-
任务全局优先级;
-
Metrics体系;
-
优化文档;
-
MLOps。
云原生时代下,任务调度需要多方面的能力,针对DolphinScheduler而言,包括这些调度方向:容器调度任务、去ZK化、多云的能力、弹性伸缩和任务隔离、易扩展和高性能。

SeaTunnel Roadmap
从Roadmap上来看,SeaTunnel未来还存在很多挑战:
-
研发核心同步引擎:更好地支持数据集成的同步引擎;
-
扩展Connector:扩展更多的Connector,预计支持近百种的数据源;
-
添加Web可视化界面:提供更友好的可视化界面,降低用户的使用成本。

DataOps收益
在现代化数据栈中,使用DataOps的收益是多方面的:
-
提供实时数据洞察能力;
-
加速数据应用构建过程;
-
让数据价值链每个角色都能更好、更高效地协作;
-
提高数据透明度,更好地数据创新和增进协作;
-
提升数据和数据服务的可复用性;
-
优化数据质量;
-
构建统一、标准化的同源数据协作平台。
Recommend
-
48
企业明知道自己需要数据治理,但并没有为此付诸任何行动 如今高管们都对数据治理感兴趣,下面这些文章就是证据:
-
24
【编者的话】DataOps,即Data和Operations组合。是在数据分析过程中,提升数据质量,减少数据分析的周期时间,提高效率的一系列实践,逐渐发展成一门方法论。DataOps适用于从数据准备到报告的整个数据生命周期。 DataOps是一门快...
-
14
中国5G网络加速成型,未来将深刻影响各个行业! 2020年11月22日
-
11
今日推荐 | 2020年,深刻影响加密数字资产行业的17个大事件火星财经2020-12-30热度: 31287预测未来的最好方法是回顾历史。...
-
7
DataOps是“数据的DevOps”吗? 原创 WOT技术大会 2022-02-24 14:33:31...
-
6
DataOps 是现代数据堆栈的未来吗?-51CTO.COM DataOps 是现代数据堆栈的未来吗? 译文 作者:...
-
9
麦肯锡:人工智能将深刻影响这五大领域 作者:Yu 2022-08-29 11:43:29 人工智能 麦肯锡发布的《2022年技术趋势展望报告》深入研究了人工智能...
-
5
激活数据价值,探究DataOps下的数据架构及其实践丨DTVision开发治理篇 精选 原创 数栈DTinsight...
-
3
11 月 2-4 日,全球最具影响力的金融科技盛会之一 — 新加坡金融科技节(Singap...
-
11
Web3对传统行业的十大深刻影响 • 2023-04-17...
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK