

Spark捣鼓记录
source link: https://fenghaojiang.github.io/post/spark-ji-chu/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Spark捣鼓记录
最近业务需要用到spark进行一些大数据的分析。由于业务场景感觉跟执行一些很暴力的SQL没区别,不涉及其他HDFS/Hive操作,于是就只是搭了一个Standalone模式的集群。
感觉不想依赖很多环境/VM,所以选型的时候就没用Scala而是直接用python的pyspark。好吧当时也没想那么多。这几天看完了论文《Resilient Distributed Datasets: A Fault-Tolerant Abstraction for
In-Memory Cluster Computing》
这几天顺便记下笔记。
弹性数据集RDDs其实就是一种新型的数据抽象,这种数据抽象允许了一定范围内的数据复用。
- RDD是只读的。(其实感觉像是分布式的dataframe对象)
- Spark通过创建一个继承(lineage)数据提供了很大的容错程度(fault tolerance),如果一个分区内的RDD丢失了,其他的RDD也有足够的信息去计算派生出丢失的数据。
- RDD可以被复用并且可以选择一个存储级别(memory/disk)
- 需要异步执行的任务并不适合RDDs
Spark经常被称为:“基于内存的分布式计算框架”,但是shuffle还是把数据写入磁盘。
如果不包含shuffle操作叫窄依赖,包含就叫宽依赖(Narrow Dependency/Wide Dependency)
如果父RDD的一个分区只被一个子RDD的一个分区所使用就是窄依赖,否则就是宽依赖。窄依赖典型的操作包括map、filter、union等,不会包含Shuffle操作;宽依赖典型的操作包括groupByKey、sortByKey等,通常会包含Shuffle操作。对于连接(Join)操作,可以分为两种情况。
对于宽依赖和窄依赖而言,窄依赖对于作业的优化很有利。逻辑上,每个RDD操作都是一个fork/join(一种用于并行执行任务的框架),把计算 fork 到每个 RDD 分区,完成计算后对各个分区得到的结果进行 join 操作,然后fork/join下一个RDD操作。如果把一个Spark作业直接翻译到物理实现(即执行完一个RDD操作再继续执行另外一个RDD操作),是很不经济的。首先,每一个RDD(即使是中间结果)都需要保存到内存或磁盘中,时间和空间开销大;其次,join 作为全局的路障(Barrier),代价是很昂贵的,所有分区上的计算都要完成以后,才能进行 join 得到结果,这样,作业执行进度就会严重受制于最慢的那个节点。如果子RDD的分区到父RDD的分区是窄依赖,就可以实施经典的fusion优化,把两个 fork/join 合并为一个;如果连续的变换操作序列都是窄依赖,就可以把很多个 fork/join 合并为一个,通过这种合并,不但减少了大量的全局路障(Barrier),而且无需保存很多中间结果RDD,这样可以极大地提升性能。在Spark中,这个合并过程就被称为“流水线(Pipeline) 优化。
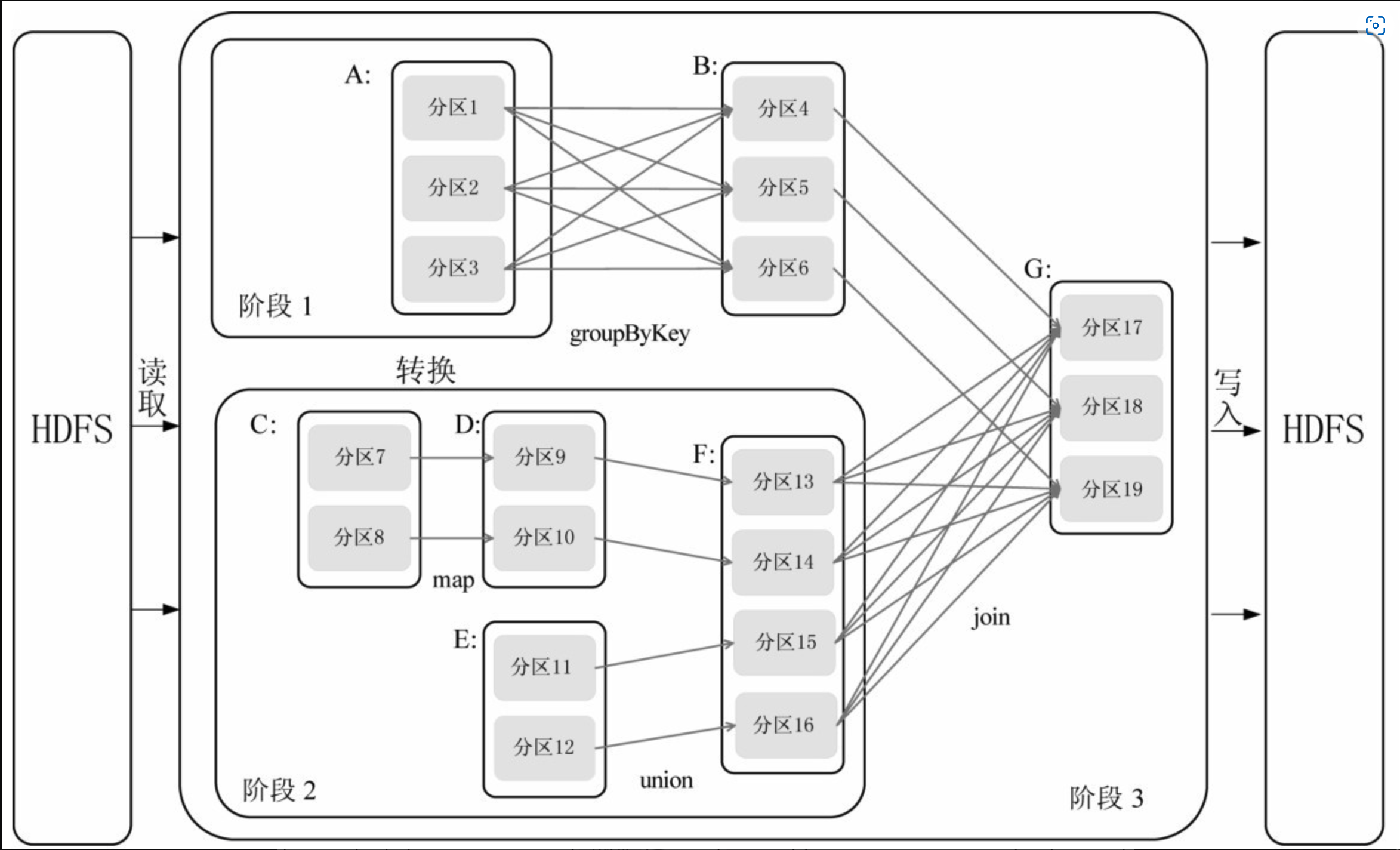
假设从HDFS中读入数据生成3个不同的RDD(即A、C和E),通过一系列转换操作后再将计算结果保存回HDFS。对DAG进行解析时,在依赖图中进行反向解析,由于从RDD A到RDD B的转换以及从RDD B和F到RDD G的转换,都属于宽依赖,因此,在宽依赖处断开后可以得到3个阶段,即阶段1、阶段2和阶段3。可以看出,在阶段2中,从map到union都是窄依赖,这两步操作可以形成一个流水线操作。例如,分区7通过map操作生成的分区9,可以不用等待分区8到分区9这个转换操作的计算结束,而是继续进行union 操作,转换得到分区13,这样流水线执行大大提高了计算的效率。
最后说一下,Spark的Streaming真的是龙鸣一样。类Streaming的解决方案是写一个定时任务然后去submit job算了。
参考资料:(Resilient Distributed Datasets: A Fault-Tolerant Abstraction for
In-Memory Cluster Computing)[https://www.usenix.org/system/files/conference/nsdi12/nsdi12-final138.pdf]
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK