
4

Scikit-Learn数据集拆分train_test_split
source link: https://www.biaodianfu.com/train-test-split.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

监督机器学习的关键方面之一是模型评估和验证。当您评估模型的预测性能时,过程必须保持公正。为了制作训练数据(training samples)和测试数据(testing samples),常使用sklearn里面的sklearn.model_selection.train_test_split模块。
拆分数据集对于无偏见地评估预测性能至关重要。在大多数情况下,将数据集随机分成三个子集就足够了:
- 训练集用于训练或拟合您的模型。例如,您使用训练集来查找线性回归、逻辑回归或神经网络的最佳权重或系数。
- 验证集用于在超参数调整期间进行无偏模型评估。例如,当您想找到神经网络中的最佳神经元数量或支持向量机的最佳内核时,您可以尝试不同的值。对于每个考虑的超参数设置,您将模型与训练集进行拟合,并使用验证集评估其性能。
- 测试集用于对最终模型进行无偏见的评估。您不应将其用于拟合或验证。

在不太复杂的情况下,当您不必调整超参数时,可以只使用训练集和测试集。
拆分数据集对于检测您的模型是否存在两个非常常见的问题之一(称为欠拟合和过拟合)可能也很重要:
- 欠拟合通常是模型无法封装数据之间关系的结果。例如,当尝试用线性模型表示非线性关系时可能会发生这种情况。欠拟合的模型在训练集和测试集上的表现都可能很差。
- 当模型具有过于复杂的结构并且学习数据和噪声之间的现有关系时,通常会发生过度拟合。此类模型通常具有较差的泛化能力。尽管它们在训练数据上运行良好,但在处理看不见的(测试)数据时通常会产生较差的性能。
train_test_split()简介
当我们在Python中建立机器学习模型时,Scikit Learn包给了我们一些工具来执行常见的机器学习操作。其中一个工具就是train_test_split()函数。Sklearn的train_test_split函数帮助我们创建训练数据和测试数据。这是因为通常情况下,训练数据和测试数据都来自同一个原始数据集。为了得到建立模型的数据,我们从一个数据集开始,然后把它分成两个数据集:训练和测试。
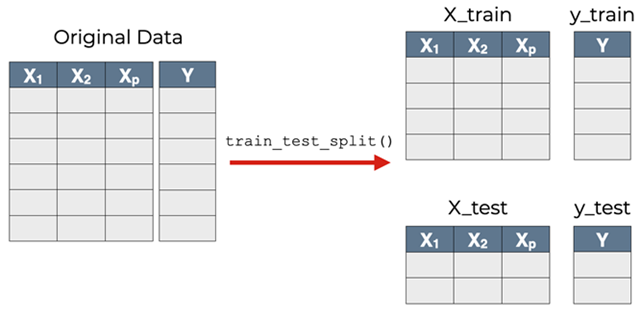
train_test_split()用法
X_train, X_test, y_train, y_test = train_test_split(train_data, train_target, test_size, random_state, shuffle, stratify)
X_train, X_test, y_train, y_test = train_test_split(train_data, train_target, test_size, random_state, shuffle, stratify)
- train_data:还未划分的数据集
- train_target:还未划分的标签
- test_size:可以为浮点、整数或None,默认为None
- 若为浮点时,表示测试集占总样本的百分比
- 若为整数时,表示测试样本数
- 若为None时,test size自动设置成25
- train_size:可以为浮点、整数或None,默认为None
- 若为浮点时,表示训练集占总样本的百分比
- 若为整数时,表示训练样本的样本数
- 若为None时,train_size自动被设置成75
- random_state:可以为整数、RandomState实例或None,默认为None
- 若为None时,每次生成的数据都是随机,可能不一样
- 若为整数时,每次生成的数据都相同
- shuffle:是否在分割前对完整数据进行洗牌(打乱),默认为True,打乱
- stratify:可以为类似数组或None
- 若为None时,划分出来的测试集或训练集中,其类标签的比例也是随机的
- 若不为None时,划分出来的测试集或训练集中,其类标签的比例同输入的数组中类标签的比例相同,可以用于处理不均衡的数据集
问题:train_test_split()只提供了训练集和测试集的拆分,如果要拆分成训练集、验证集和测试集怎么做?
答案:执行2遍train_test_split()
- 先拆分出训练集和测试集
- 在再训练集中拆分一部分数据座位验证集

如何合理的划分数据集?
数据划分的方法并没有明确的规定,不过可以参考3个原则:
- 对于小规模样本集(几万量级),常用的分配比例是 60% 训练集、20% 验证集、20% 测试集。
- 对于大规模样本集(百万级以上),只要验证集和测试集的数量足够即可,例如有 100w 条数据,那么留 1w 验证集,1w 测试集即可。1000w 的数据,同样留 1w 验证集和 1w 测试集。
- 超参数越少,或者超参数很容易调整,那么可以减少验证集的比例,更多的分配给训练集。
参考链接:
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK