

小海豚“变身”全新智能调度引擎,深入浅出在DDS的实践开发应用-开源基础软件社区-51CTO...
source link: https://ost.51cto.com/posts/14953
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

这次在 7月 Meetup 为大家带来的是基于DolphinScheduler的智能调度引擎在DDS的应用,这场演讲主要会跟大家介绍宇动源-DDS(自研的图形化数据开发工作室)、大数据架构、DDS产品和使用中遇到的问题,包括在迁移过程中的调研情况、遇到的困难、解决方案以及针对需求的优化,还有一些心得体会,希望你有所收获。

王子健
宇动源大数据平台开发工程师
原搜狐畅游数据仓库开发工程师
本次演讲主要包含四个部分:
-
关于宇动源-DDS
-
全新调度引擎的迁移-DS
-
引擎功能优化
-
总结与计划
关于宇动源-DDS
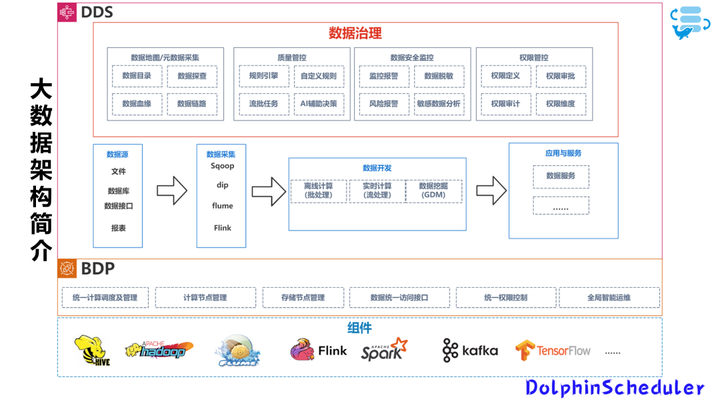
😀宇动源DDS架构图
01 什么是BDP?
BDP是宇动源自研的大数据基础平台,类似的商业的应用主要有fusioninsget 和 EMR,都是在工业互联网领域比较领先的大数据平台,他们也都对现有开源大数据底层组件的封装和统一管理,使其更适用于工业领域的实时数据、时序数据、生产监控数据等,为DDS上层应用提供一个使用更方便、更容易使用的基础平台。
主要提供的功能:统一计算调度及管理、计算节点管理、存储节点管理、数据统一访问接口、统一权限控制、全局智能运维
有了BDP之后,我们不需要手动的安装/维护这些组件,包括我们DDS所有的组件也都是通过BDP进行安装和维护。
02 关于DDS
DDS实际上是对底层的调度引擎的优化,主要是使用的workflow code 和Stream code 的两种开发方式,利用拖拉拽快速完成大数据开发。
除此之外还支持Notebook 交互式开发方式,当我们使用Shell SQL节点的时候可以在线编辑。
最终在执行过程,其实和我们平时使用DolphinScheduler一样,在运行后,也会生成一个调度任务,并且可以在调度管理中查看/管理。
03 缺点与不足
案例一:某能源集团火力发电远程告警系统
问题:基于上一代调度引擎在性能、权限控制等方面存在缺陷,导致出现告警延迟、无法精准控制权限等问题。
案例二:某石油加工集团云边端设备采集项目
问题:DDS与Hadoop架构紧密耦合,不仅前期需要额外部署Hadoop集群(即使客户不使用),后期Hadoop集群维护也增加了运维成本。
案例三:某军部数字化建设项目
问题:无法对整个集群的运行状态进行统计,比如1000个任务,在运行过程中,我们不知道哪些任务是正常运行的,哪些任务挂掉了;
DDS中老调度引擎无法获取日志(日志的粒度依赖oozie 的日志)从而增加了调试维护成本,在开发过程中,命令行的方式也不是很友好,XML配置文件容易出错,开发效率低,无法更全面的统计与维护。
综上所诉的这些缺点和问题,导致了我们需要迭代一个新的版本,在DDS的后续版本准备对调度引擎进行替换,来解决这些使用当中的痛点。
全新调度引擎的迁移
01调研阶段
接下来跟大家分享的就是在迁移过程当中,我们的一些调研工作、遇到的问题以及解决方案。
我们调研了oozie,azkaban,Airflow, 还有DolphinScherduler,当然还有一些其他的调度,这个表格里就没整理,在整个调研的阶段,我们特别重视的指标主要是资源的监控和分布式和日志,还有权限等方面的控制。
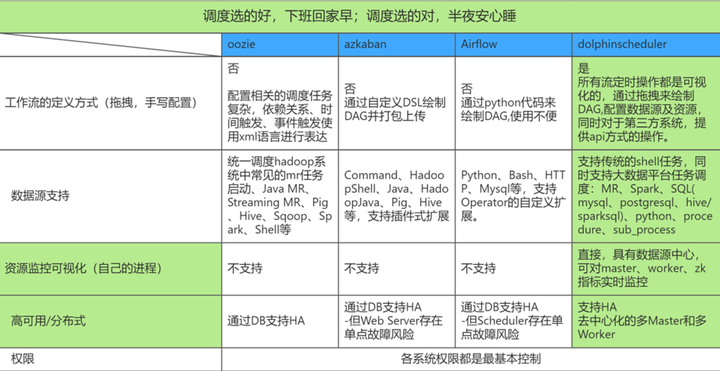
为什么选择DolphinScheduler ?
资源方面,DolphinsScheduler 可以有自己的数据中心,可以对master worker运行状态和指标实时监控;
分布式方面,支持HA,是去中心化的,支持多Master多worker;
**日志方面,**通过DolphinsScheduler我们能准确的定位到每一个task任务执行的日志。也可以监控在执行过程当中启动时间,停止时间,然后运行的机器所在的运行阶段;
容错机制也很有特色;
支持多租户。DolphinsScheduler的租户能和Hadoop的用户能实现映射关系,实现对资源的精确管理;
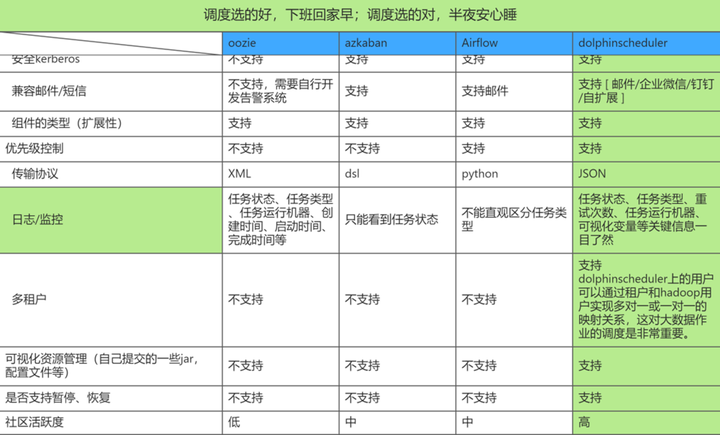
02 引擎接入方案(dds-adaptor)
接入方案-典型问题
在迁移的过程当中,我们遇到了一个典型的问题:DolphinScheduler中的描述文件(json)无法与DDS的工作流描述文件(xml)兼容。就是DDS中的工作流是用xml的格式来绘制描述的。而DolphinScheduler中是使用json格式来描述的,这样就会导致于现有的前端生成的XML,无法兼容DolphinScheduler。
问题解决方案
我们在DDS和DolphinScheduler中间,加入了DDS-adaptor服务,它有一个自己的API,DDS前端绘制完工作流,会将XML格式的请求体,通过API接口的形式发送到parser-engine,parser-engine收到了带有XML参数的请求后,会将它解析成JSON格式 ,当然这个JSON就是我们DS引擎能解析和兼容的。这样就解决了保留DDS前端框架不变的情况下,将原有的XML描述方式,适配到DolphinScheduler的json方式。
这样也就实现了我们在DDS前端创建task 任务,在DS的后端会生成DolphinScheduler task 规则的任务。
也就是说可能有个客户DDS使用了几年。上面配了几千个任务,用这个架构接入方案它就不需要重新的做任务的迁移,可以无缝的实现底层调度引擎的迁移。
03 实现简介
DDS_adaptor架构
DDS_adaptor项目里边包含两个子项目,一个dsengine-core和external-model,那么前面说的API是在controller层里,当我们接收到xml的请求,会通过engine-core去对它进行解析。
具体的实现
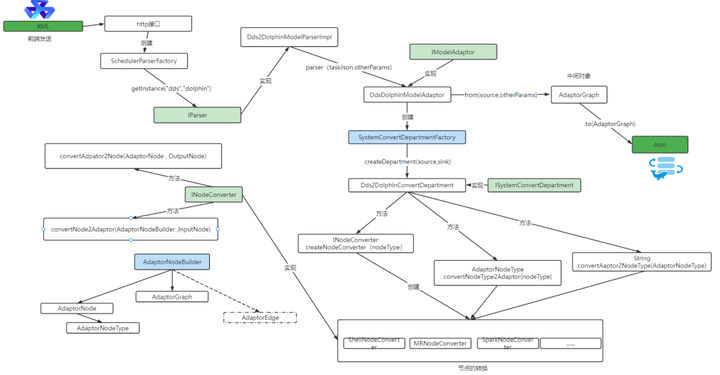
实现流程:
1.前端先发送XML文件到HTTP接口
2.HTTP接到之后会创建一个解析工厂也就是SchedulerParserFactory
3.解析工厂生成一个IParser接口
4.然后实现Dds2DolphinModelParser,也就是模型解析实现类
5.其中parser方法实际上是XML格式的字符串,里面调用的是核心方法、核心类
6.DdsDolphinModelAdaptor,即模型适配器。在接收parser传进来的参数后会有两个方法,分别是from和.to,from是将DDS的Graph转换成中间对象的Graph。.to是将中间对象的Graph转换成Dolphin的Graph。
7.创建SystemConvertDepartmentFactory,它同时会创建DDS转换成Dolphin特有的转换方法,分别有3个:
方法一:
INodeConvertercreateNodeConverter(nodeType):创建节点转换器
方法二:
AdaptorNodeTypeconvertNodeType2Adaptor(nodeType) :目标节点转为中间节点
方法三:
StringconvertAaptor2NodeType(AdaptorNodeType):中间节点转为目标节点
在第一步中需要将DDS Graph 转为 Adaptor Graph ,这个实际上执行的时是AdaptorNodeType convertNodeType2Adaptor(nodeType) 方法,将Graph做转换,
但是每个Graph 中包含很多组件,因此每个组件都需要进行转换,需要调用到的方法是
convertAdpator2Node(AdaptorNode , OutputNode)
convertNode2Adaptor(AdaptorNodeBuilder,InputNode),针对每个组件进行转换,实现了将DDS Graph 转为 Adaptor Graph。
第二步是中间对象转换成目标对象,我们想要的是Dolphin的Graph,这个时候实际上就是将中间组件转换成目标组件,这样就实现了中间的Graph转换成目标Graph,中间的Graph就是Adaptor-Garph,目标组件就是Dolphin-Graph,这样就实现了前端以XML的方式发送,引擎解析出来是Dolphin支持的json格式
引擎功能优化(更智能)
主要介绍扩展的两个功能,第一个是节点推荐机制,第二个是重跑控制策略。
节点推荐机制
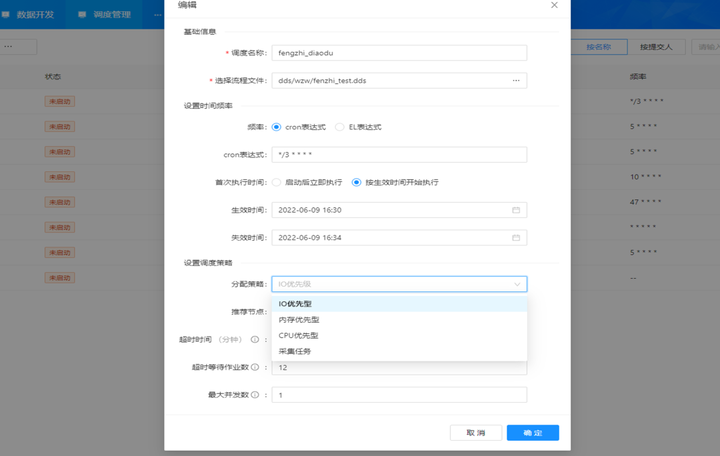
在DDS调度启动之前,可以进行一个调度策略的设置,分别有一个分配策略和推荐节点;
在分配策略的时候,我们可以根据实际情况来选择,比如你是采集任务还是计算任务?是让它网络优先,还是IO优先,在这里你可以根据不同的情况自定义选择。
时间架构
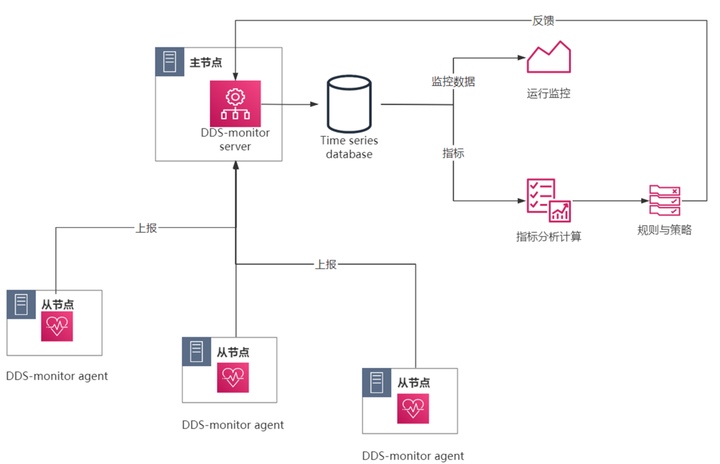
这里没有展示时间关系代码,主要依赖是基于DDS-monitor。在每一个子节点上部署 agent,那么agent它会采集系统的各种信息,比如说我们的系统版本,CPU,内存,磁盘等。
agent会将这些信息上报给server端,sever端将这些指标全部存在时序数据库里,数据库主要有两个用途,一个是我们监控数据,我们可以监控每一个agent上面的信息,另一个就是分析计算,指标分析计算后,根据我们的策略规则,会将符合功能策略的节点推荐返回给server,从而实现了节点的推荐机制。
分析指标
我们指标分析计算里面涉及到的一些指标,有系统版本、CPU、内存、磁盘、进程、端口、网络io等等
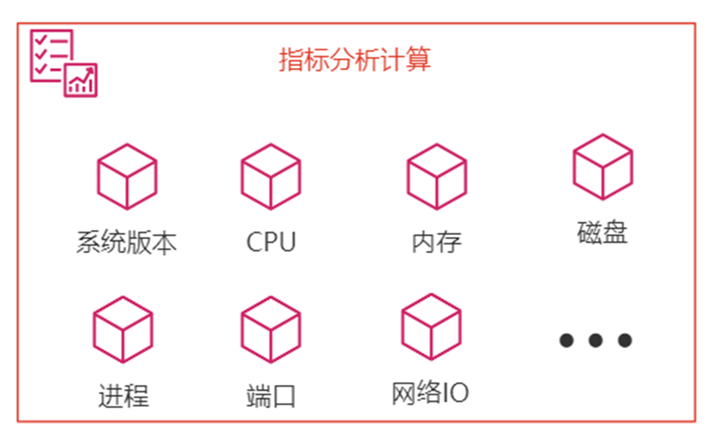
那么配置规则里有IO相关的配置,有符合我们特定业务类型的配置。

重跑控制策略
我们对调度的是否重跑可以进行控制。比如说当任务运行到一半的时候,节点重启,所有的任务都失败了,有一些任务可以直接进行重跑覆盖,但是有一些任务重跑会影响它的结果,所以对这些重跑的限制也是针对需求来进行优化的点。
总结与计划
一方面,不管是基于DolphinScheduler引擎去开发自己的调度系统,还是直接使用DolphinScheduler进行二次开发,都是需要根据自己的开发环境来实际操作,比如说公司的环境要求、规范、前后端技术栈、开发环境等等,不要拿过来就开发,需要多方面的考虑。
另一方面,我们在devops过程当中需要收集和整理产生的这些缺陷、缺点和一些用户的痛点, 我们需要在这个版本的迭代当中,有针对性的去处理这些问题。
我们后续也有很多功能在实现当中,给大家列举一下,比如说后续的Task组件节点之间结果集的传递、SQL 运行后传递给后续节点等,然后还需要集成一些热门的时序数据库,比如说influxdb、open plant等。
等实现之后希望还有机会和大家一起交流分享,谢谢大家。
参与贡献
随着国内开源的迅猛崛起,Apache DolphinScheduler 社区迎来蓬勃发展,为了做更好用、易用的调度,真诚欢迎热爱开源的伙伴加入到开源社区中来,为中国开源崛起献上一份自己的力量,让本土开源走向全球。
参与 DolphinScheduler 社区有非常多的参与贡献的方式,包括:

贡献第一个PR(文档、代码) 我们也希望是简单的,第一个PR用于熟悉提交的流程和社区协作以及感受社区的友好度。
社区汇总了以下适合新手的问题列表:https://github.com/apache/dolphinscheduler/issues/5689
非新手问题列表:https://github.com/apache/dolphinscheduler/issues?q=is%3Aopen+is%3Aissue+label%3A"volunteer+wanted"
如何参与贡献链接:https://dolphinscheduler.apache.org/zh-cn/docs/development/contribute.html
来吧,DolphinScheduler开源社区需要您的参与,为中国开源崛起添砖加瓦吧,哪怕只是小小的一块瓦,汇聚起来的力量也是巨大的。
参与开源可以近距离与各路高手切磋,迅速提升自己的技能,如果您想参与贡献,我们有个贡献者种子孵化群,可以添加社区小助手微信(Leonard-ds) ,手把手教会您( 贡献者不分水平高低,有问必答,关键是有一颗愿意贡献的心 )。
添加小助手时请说明想参与贡献,来吧,开源社区非常期待您的参与。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK