

谷歌、斯坦福联合发文:我们为什么一定要用大模型?
source link: https://www.51cto.com/article/714060.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
谷歌、斯坦福联合发文:我们为什么一定要用大模型?-51CTO.COM
语言模型已经深刻变革了自然语言处理领域的研究和实践。近年来,大模型在多个领域都取得了重要的突破。它们无需在下游任务上微调,通过合适的指令或者提示就可以取得优异的性能,甚至有时让人为之惊叹。
例如,GPT-3 [1] 可以写情书、写剧本和解决复杂的数据数学推理问题,PaLM [2] 可以解释笑话。上面的例子只是大模型能力的冰山一角,现在利用大模型能力已经开发了许多应用,在OpenAI的网站 [3] 可以看到许多相关的demo,而这些能力在小模型上却很少体现。
今天介绍的这篇论文中,将那些小模型不具备而大模型具备的能力称为突现能力(Emergent Abilities),意指模型的规模大到一定程度后所突然获得的能力。这是一个量变产生质变的过程。
突现能力的出现难以预测。为什么随着规模的增大,模型会忽然获得某些能力仍旧是一个开放问题,还需要进一步的研究来解答。在本文中,笔者梳理了最近关于理解大模型的一些进展,并给出了一些相关的思考,期待与大家共同探讨。
相关论文:
- Emergent Abilities of Large Language Models.
http://arxiv.org/abs/2206.07682 - Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models.
https://arxiv.org/abs/2206.04615
大模型的突现能力
何谓大模型?到什么尺寸才算“大”?这并没有一个明确的定义。
一般来说,模型参数可能要达到十亿级别才会显示出明显不同于小模型的zero-shot和few-shot的能力。近年来已有多个千亿和万亿级别参数的模型,在一系列的任务上都取得了SOTA的表现。在一些任务中,模型的性能随着规模的增加而可靠地提高,而在另一些任务中,模型在某个规模上表现出性能的突然提升。可以用两个指标去对不同的任务进行分类 [4]:
- Linearity: 旨在衡量模型随着规模的增加在任务上的表现在多大程度上得到可靠的提高。
- Breakthroughness: 旨在衡量当模型规模超过临界值时可以在多大程度上学习任务。
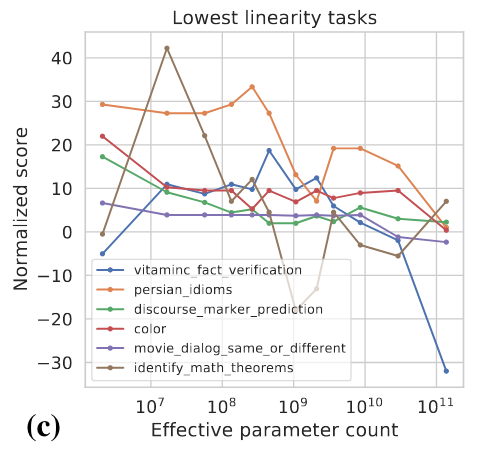
这两个指标是模型规模和模型性能的函数,具体计算细节可以参考 [4]。下图展示了一些高Linearity和高Breakthroughness任务的例子。
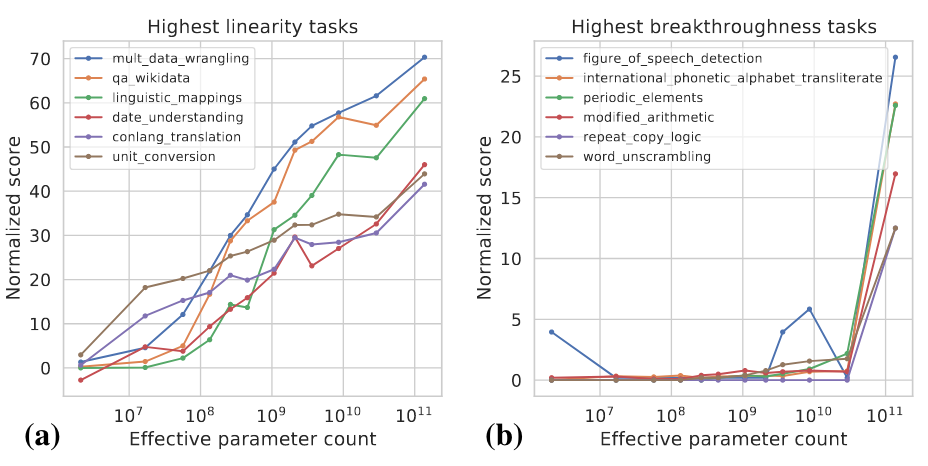
高Linearity的任务大多是基于知识的,也就是说他们主要依赖于记忆训练数据中存在的信息,比如回答一些事实性的问题。更大的模型通常用更多的数据进行训练,也能记住更多的知识,所以模型随着规模的增大在这类任务上显式出了稳定的提升。高Breakthroughness的任务包括较复杂的任务,它们需要用几种不同的能力或执行多个步骤以得出正确的答案,例如数学推理。较小的模型难以获得执行这类任务所需要的所有能力。
下图进一步展示了不同的模型在一些高Breakthroughness任务上的表现
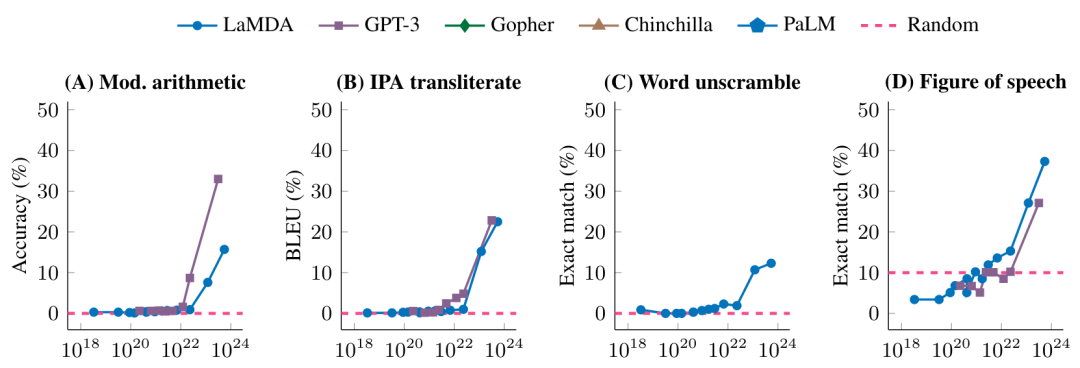
在未达到一定的模型规模时,模型在这些任务上的表现是随机的,达到某个特定的规模之后,就有了显著的提升。
是平滑还是突现?
前面我们看到的是模型规模增加到一定程度后突然获得了某些能力,从任务特定的指标来看,这些能力是突现的,但是从另外的角度来看,模型能力的潜在变化更为平滑。本文讨论如下两个角度:(1)使用更为平滑的指标;(2)将复杂的任务分解为多个子任务。
下图(a)展示了一些高Breakthroughness任务的真实目标对数概率的变化曲线,真实目标的对数概率是随着模型规模增大逐渐提高的。
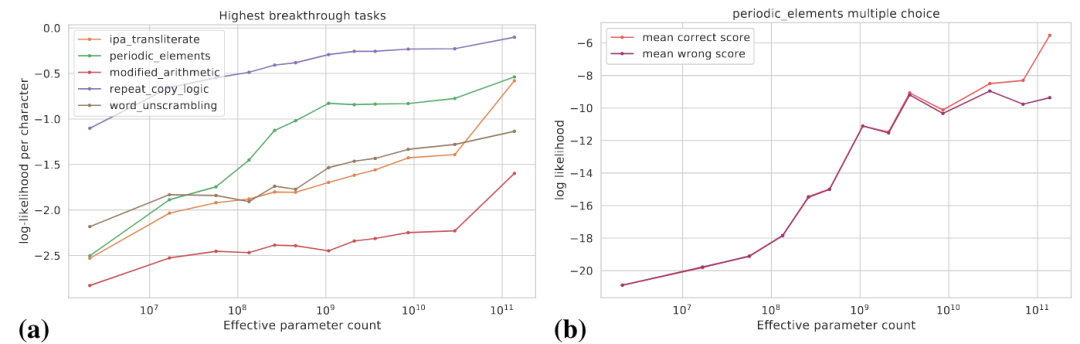
图(b)显式了对于某个多项选择任务,随着模型规模的增大,正确答案的对数概率逐步提升,而错误答案的对数概率在某个特定的规模之前逐步提升,而在此之后趋于平坦。在这个规模之后,正确答案概率和错误答案概率的差距拉大,从而模型得到了显著的性能提升。
此外,对于某个特定任务,假设我们可以用Exact Match和BLEU去评价模型的表现,BLEU相比于Exact Match是更为平滑的指标,使用不同指标所看到的趋势可能有显著的差距。
对于一些任务,模型可能在不同的规模上获得了做这个任务的部分能力。下图是通过一串emoji去猜测电影名字的任务

我们可以看到模型在一些规模开始猜测电影名称,在更大的规模上识别表情符号的语义,在最大的规模上产生正确的答案。
大模型对如何形式化任务很敏感
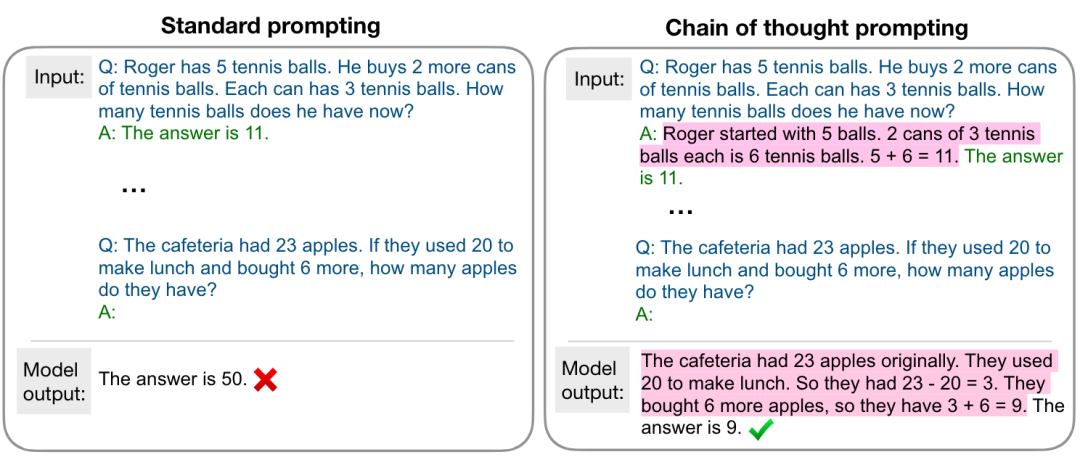
模型在什么规模上体现出突然的能力提升也取决于如何去形式化任务。例如,在复杂的数学推理任务上,使用标准的prompting将其视为问答任务,模型规模增大性能提升十分有限,而若使用如下图所示的chain-of-thought prompting [5],将其视为多步推理任务,则会在某个特定的规模看到显著的性能提升。
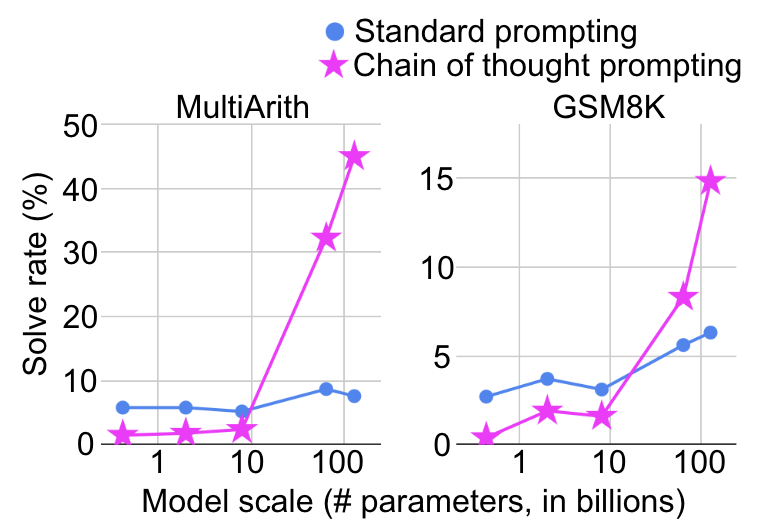
更有甚者,研究人员发现通过添加一个简单的提示“Let’s think step by step”,就可以大幅提升GPT-3的zero-shot推理能力 [6],如下图所示

这对于我们的启发是,大模型有时做不好某个任务,可能并不是真的做不好,而是需要合适的方式去激发它的能力。
模型越大一定越强吗?
前面的讨论给我们的直观感觉是模型规模变大性能一定是有所提升的,但是真的是这样吗?实际上,对于有些任务,模型变大之后性能可能反而会有所下降,如下图所示
纽约大学的几位研究人员还组织了一项竞赛,旨在找到那些模型变大后反而表现变差的任务。

比如在问答任务中,如果在提问的同时加上你的信仰,大模型会更容易受到影响。感兴趣的同学可以关注。
总结与思考
- 在大多数任务上,随着模型规模的增大,模型的表现也越好,但是也会有一些反例。更好地去理解模型此类行为还需要更多的研究。
- 大模型的能力需要合适的方式去激发。
- 大模型真的是在做推理吗?如我们之前看到的,通过添加提示“Let’s think step by step”,大模型在数学推理任务上就可以进行多步推理并取得令人满意的效果,似乎模型已经具备了人类的推理能力。但是,如下如所示,如果给GPT-3一个没有意义的问题,让它去做多步推理,GPT-3看似在做推理,实则是一些无意义的输出。正所谓“garbage in, garbage out”。相比较而言,人类就可以判断问题是否是合理的,也就是说在给定条件下,当前问题是不是可回答的。“Let’s think step by step”能够发挥作用,笔者觉得根本原因还是GPT-3在训练过程中看过很多类似的数据,它做的只不过是根据前面的token去预测接下来的token罢了,跟人类的思考方式仍旧有本质的区别。当然,如果给合适的提示让GPT-3去判断问题是不是合理的或许它也能在某种程度上做到,但是距离“思考”和“推理”恐怕仍有相当大的距离,这不是单纯增大模型的规模能够解决的。模型或许不需要像人类那样思考,但是亟需更多的研究去探索除增大模型规模之外的路径。

- 系统1还是系统2?人类大脑有两个系统相互配合,系统1(直觉)是快速的、自动化的,而系统2(理性)是缓慢的、可控的。大量实验已证明,人更喜欢使用直觉进行判断和决策,而理性可以对其导致的偏误进行纠正。现在的模型大多基于系统1或系统2进行设计,能否基于双系统去设计未来的模型呢?
- 大模型时代的查询语言。之前我们把知识和数据存储在数据库和知识图谱中,我们可以用SQL查询关系型数据库,可用SPARQL去查询知识图谱,那我们用什么查询语言去调用大模型的知识和能力呢?
梅贻琦先生曾说“所谓大学者,非谓有大楼之谓也,有大师之谓也”,笔者在此用个不太恰当的类比结束本篇:所谓大模型者,非谓有参数之谓也,有能之谓也。
Recommend
-
0
斯坦福教授曼宁AAAS特刊发文:大模型已成突破,展望通用人工智能-51CTO.COM 斯坦福教授曼宁AAAS特刊发文:大模型已成突破,展望通用人工智能 作者:泽南、小舟 2022-05-01 15:42:30 自...
-
1
用ChatGPT控制NPC,行动逼真到像正常人!斯坦福谷歌新研究炸场,赋予大模型准确记忆力
-
6
剑桥华人团队搞出多模态医学大模型!单个消费级显卡就能部署,借鉴斯坦福「羊驼」而来
-
2
2023-04-23 03:44 Together 联合斯坦福等机构开启 RedPajama 计划,旨在创建完全开源的大型语言模型 据 VentureBeat 报道,总部位于加州的专注于建立去中心化云和开源模式的公司 Together 近日宣布了 RedPajama 计划。据悉,RedPaj...
-
5
威大哥大等联合发文!最新多模态大模型LLaVA问世,水平直逼GPT-4 作者:新智元 2023-04-28 15:27:06 微软&哥大联合发表视觉指令微调论文,LLaVA出炉! 视觉...
-
2
斯坦福最新研究警告:别太迷信大模型涌现能力,那是度量选择的结果 机器之心 发表于 2023年05月03日 08:...
-
3
一笔勾勒,宫崎骏动漫世界!斯坦福大模型𝘚𝘬𝘦𝘵𝘤𝘩-𝘢-𝘚𝘬𝘦𝘵𝘤𝘩,草图秒变神作 作者:新智元 2023-08-18 14:11:00 有了𝘚𝘬𝘦𝘵𝘤𝘩-𝘢-𝘚𝘬𝘦𝘵𝘤𝘩,不是艺术家,也成艺术家。在Sketch-a-Sketch中,研究人员引入了一个ControlNet模...
-
1
2023-10-11 14:13 学而思联合谷歌、暨南大学发起全球大模型数学解题竞赛 据界面新闻报道,10 月 11 日,由学而思牵头,联合谷歌、暨南大学等多家科技企业及高校的专家学者共同举办 AAAI2024 全球大模型数学推理竞赛。据悉,此次比...
-
3
GPT-4就是AGI!谷歌斯坦福科学家揭秘大模型如何超智能 新智元 发表于 2023年10月12日 07:35...
-
4
2023-12-21 03:41 可验证大模型输出、训练来源,斯坦福提出“统一归因”框架 原文来源:AIGC开放社区
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK