

技术场景| 搭建企业级实时数据融合平台难吗?MongoDB + ES + Tapdata 就能搞定!
source link: https://mongoing.com/archives/82360
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

技术场景| 搭建企业级实时数据融合平台难吗?MongoDB + ES + Tapdata 就能搞定!
阅读完文章不要划走,文末有惊喜~
在大数据时代,几乎每家企业都有上一套数据平台的冲动,目前也有很多的离线解决方案,包括 Hadoop 体系的 CDH、TDH,还有一些传统的数仓。但是有两大因素让企业无从下手:一是“实时”,二是“融合”。一方面,随着 IT 架构的迭代升级和业务端的全渠道营销,企业对于数据的实时性要求越来越高,另一方面,过去几十年的企业数字化造成了许多的孤岛系统和数据,只有“融合”后的数据才能真正用起来。
如何打造一套企业级的实时数据融合平台?Tapdata 已经找到了最佳实践,下文将以 Tapdata 的零售行业客户为例,与您分享:基于 ES 和 MongoDB 来快速构建一套企业级的实时数据融合平台。
Tapdata 的案例客户是珠宝零售行业的头部企业,历史悠久,早在上世纪90年代就已经开始 IT 建设,在中国大陆及港澳台地区有超过700家线下零售门店,且产品线非常丰富包括珠宝及其周边产品,营销渠道还覆盖了移动端、线上商城等。
随着业务体量越来越大,需要对接多个电商平台进行商品的上下架,并且开发新营销应用的频率越来越高,IT 部门要完成这些需求,就需要每次到各个数据库中捞取目标数据,然后才能去做迭代开发,造成开发成本居高不下,数据准备阶段占用过多的部门精力。
一个典型的场景是:门店库存盘点。门店店员每卖一个货,有销售系统会登记销售记录,每天可以从销售系统里查到当前的库存数据。这个数据是截止到目前为止的存货数量,但是这个数字是销售系统内的统计数字,不一定和实际门店的存货数字对的起来。 比如: 门店店员卖掉一件货,就会去销售系统开一个销售单,销售系统就减掉一件货。现实中可能会发生以下情况:
(1)但店员如果忘记录入了,那系统记录有 1000 件,实际只有 999 件,这就会导致:实际 999 件,如果不盘点,财务、后勤都不知道,因为系统有1000 件。
(2)之前盘点都是分店店员根据店里的存货去和手账的记录做手工对账,因为工作量巨大,所以做不了每天盘货,只能做季度大盘。
这里有 2 个问题:人工盘点费时;出错率高。
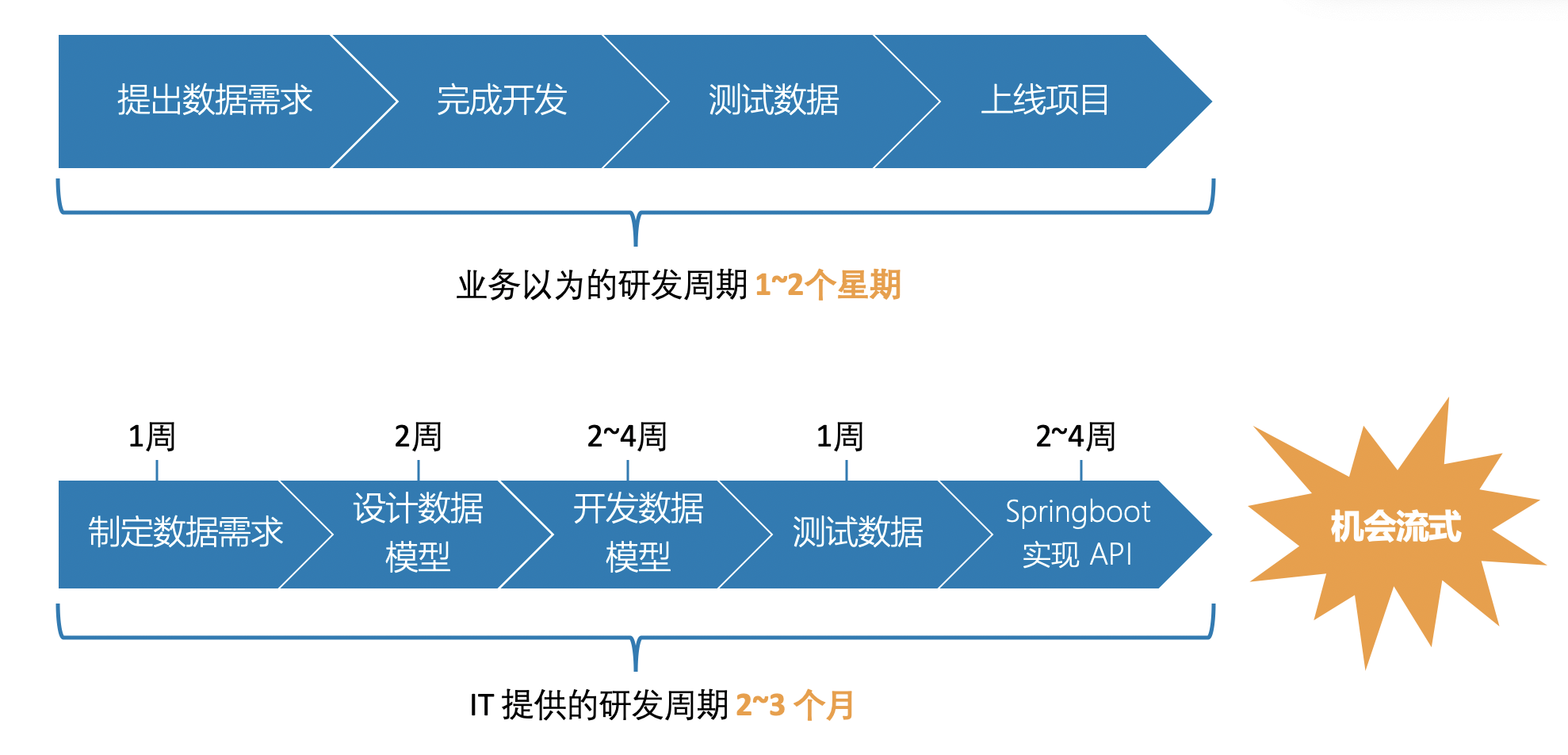
上述问题的根本原因在于,传统的 IT 开发模式中,基本都先制定需求,和 BA 确定好要做的事情,然后把业务需求背后对应的数据模型定义完,再开始做数据的开发等。但在业务需求部门看来,他们会认为这样的需求无非就是让 IT 部门做个页面、加张报表,顶多一周就能搞定,于是需求不断叠加,而 IT 部门疲于应对,这样一来,整个新业务系统的上线时间将大幅拉长,短则一个月,长则两三个月。
反过来说,业务部门也来无法接受延迟上线,比如双11大促,业务部门提前三个月跟研发提需求,但是临近一两个礼拜,突然出了一个policy,因为某些原因审计过不了了,业务流程得换一个策略,研发这个时候说已经调整不了了,导致的结果就是活动只能被迫停掉。这对于零售行业来说,错过618、双11这种大促机会,将对全年业绩造成巨大冲击。
这个“锅”谁来背?深入分析,我们发现根本症结是:数据架构没有跟上需求升级的步伐。
一是数据孤岛,在很多的传统的企业,以业务为生的企业中都会面临这种问题。这类企业的发展进程是以业务为生,他们的 IT 系统大部分都来自于第三方的采购,每一套业务系统采购进来之后,都会带着他们绑定的数据库,如 Oracle ,SQL Server,PG,以及其他一些新的非关系型的数据库。对于企业来说,采购系统解决了他们的业务问题,但是对于他们的 IT 来说,一旦要在这些业务系统之上做新的业务就会非常的头疼。
二是有太多的业务系统,且系统年龄非常悠久,他们的可维护性已经变得越来越低。例如,有一些存储过程有一两千行,代码是从2000年开始维护的,每一个存储过程大概有十几个人维护,前前后后这种历史原因会导致整个系统难进行有效的迭代和维护。
三是这些业务系统都分管于不同的业务部门,例如,有的甚至是 Hr 来管业务系统,就导致某些业务数据很难拿到,跨部门协调数据,直接影响了整个开发周期。
最后是,对于研发来说,明确需求之后就开始研发,最怕做到一半的时候改需求,或者快做完了得到反馈说这不是想要这个东西。
那么,我们是如何帮助企业彻底解决这些问题呢?Tapdata 提出了基于 DaaS 架构的解决方案,通过打造一个实时数据融合平台,并提供多个能力支撑。
首先是提供异构数据库的实时同步,解决业务系统到下游系统的实时查询问题。同时统一数据,由于历史原因导致客户多个地区的数据库全都是分散的,一个订单在所有的数据库里面都会存一份,但是状态会不一致,当你想要拿订单最终的一个状态的时候,就需要去所有的数据库里面查一遍,可想而知这个速度快不起来。
其次是基于实时同步+数据建模,向 ES 供数,解决全文搜索的时效性问题,满足零售行业在移动端前台搜索,实时看到结果。对于很多传统的零售行业来说,常用的搜索方式是在关系数据库里面做很多的 SQL 查询,或 like 模糊查询,现有的一些系统可能要等待十几秒才能出查询结果,这大大降低了门店销售员的查询效率。
再次就是支持快速发布 API,形成最后的数据闭环。为下游业务系统提供统一、可靠的数据出口。标准的 RESTful API 可以极大降低研发对接成本,丰富的类 GraphQL 查询语义,可以满足各种业务场景的条件查询。
综上,Tapdata 是为客户提了一个能够做到实时查询、全文搜索,然后能很快的提供数据统一服务的平台。

△ Tapdata 实时数据服务平台
值得强调的是,主数据管理在零售行业十分重要。在零售行业基本上就是订单、库存、商品,这三个为核心的主数据,这些主数据和传统数仓比较,它最大的区别就是数仓都是一些维度表、事实表,基本上用于做一些报表,而这些主数据则是所有项目都离不开的数据,包括市场活动、营销等,这种数据我们称之为叫企业实时主数据。
出于传统关系型数据库设计,一张商品表相关的属性表有二三十张,所以在实际开发中,有大部分的时间都消耗在数据准备上,我们需要去不同项目组获取基础数据,或者是企业的核心数据,去数据库里面去拿一份,但是数据的一致性谁来维护?自己项目组的人来维护,最终就会造成从这个基础库里面出去的所有的数据链路会越来越多,而每一个开发组自己对于数据同步的业务逻辑理解又不一样,最终造成出去的数据的一致性没法得到保证。这可能导致两个应用出来的报表在同一个维度的数字却对不起来,这个是很多现在企业中面临的问题。
不难发现,在研发周期占比上,大部分时间都在数据准备上,而没有把更多的时间聚焦在核心业务上,Tapdata 的实时数据融合平台便能够帮用户完成从前到后的数据融合,大幅降低数据准备阶段的时间和人力投入。
Tapdata 是如何实现的呢?
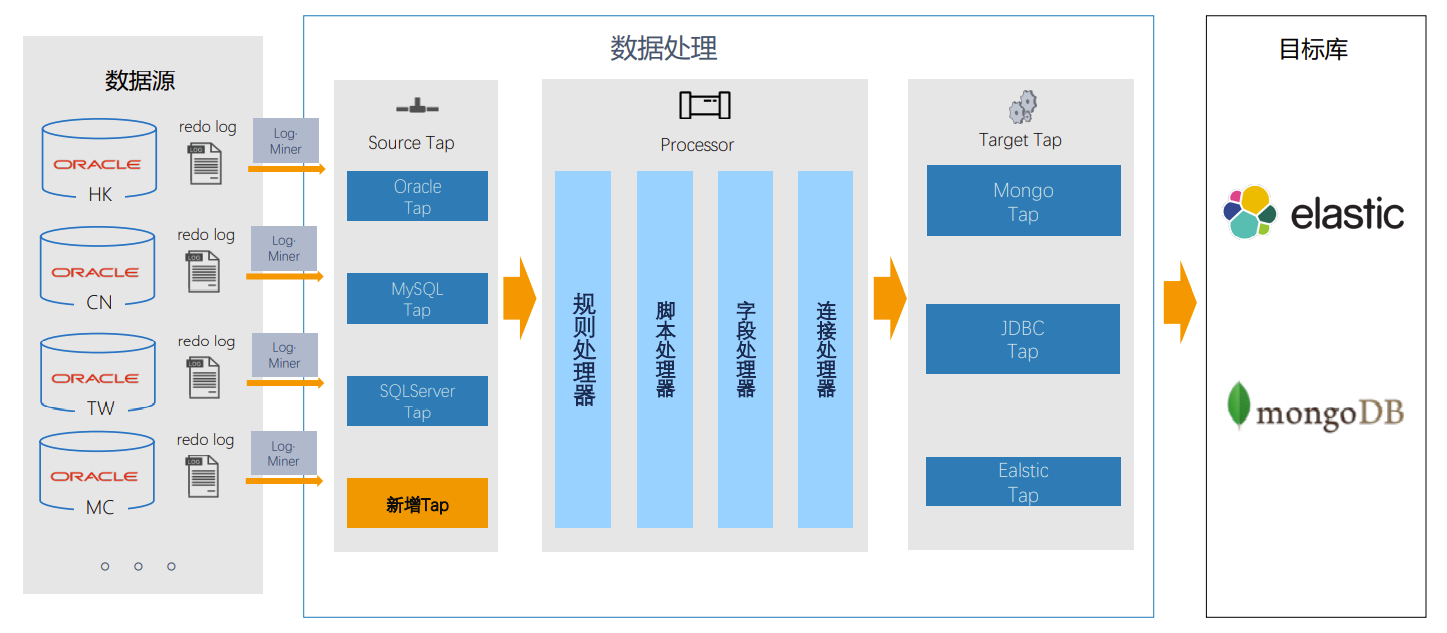
第一步是将所有的数据库,无论是 oracle,mysql 等传统关系型数据库还是非关系型也好,全部通过实时同步进入我们的平台。平台采用了两种数据库:es + MongoDB,它们的模型非常相近,在很多的业务场景中可以互相配合。比如,es 非常适合做前端的查询,在本文将的零售行业场景中它就是来解决用户大批量的模糊关键字搜索以及一些聚合的复杂查询,而 MongoDB 负责把所有的模型快速的处理掉,并且响应到前端去。然后我们把数据进到 MongoDB 里面并完成数据的融合。
△ Tapdata 实时数据同步
比如说商品模型,它在关系数据库里面由二三十张表组成,我们就可以把这些表全部合并成一张固化视图,即一张大宽表,但这张大宽表是实时业务在更新的,如果 erp 或者 mes 下了一个新的订单,大宽表中关于那条订单的状态就会被更新到最新,然后再把 MongoDB 中的商品主数据推到 es 去。
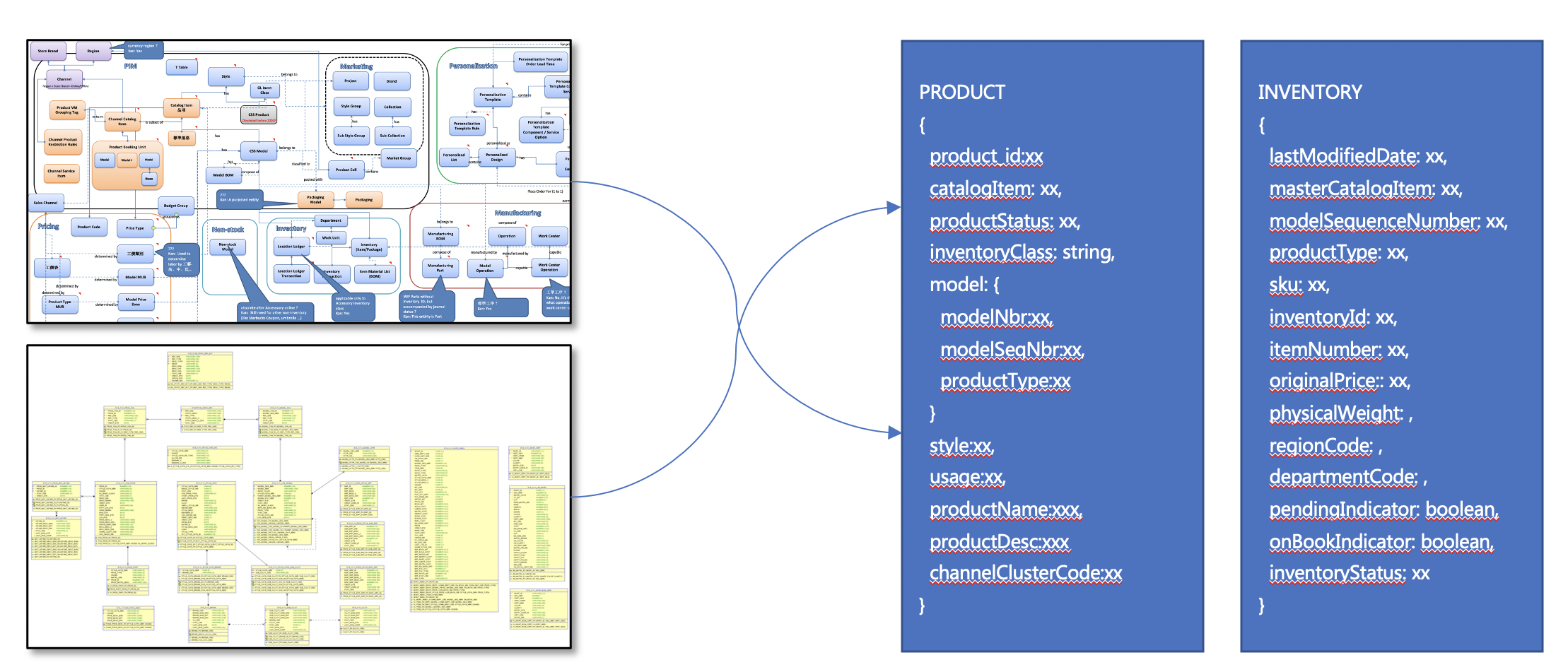
△ Tapdata 多表关联
对于前端来说,我们不再只是针对于普通的 BI ,比如说 powerbi、tableau 这些展现,或者是一些数字大屏,而更多的是面向于业务系统,如 crm、scm、或者是一些营销系统,直接服务于业务和销售。
在本零售行业案例中,数据实时同步的方案是,首先把所有的 oracle 从 4 个地方(中国大陆及港澳台)的 pos 系统拿过来,通过 logminer 的方式监听进来,然后经过中间的各种处理,比如说规则处理、脚本处理、字段处理、大小写转换等等,再把这些全部都处理完的结果写到 MongoDB 里面去,之后通过实时同步写到 es 里面去。
这里的 MongoDB 和 es 不一定是 1:1 的写入,Tapdata 还会做一些模型的过滤,因为 MongoDB 中的主数据模型是一张非常完整的宽表(包括整个集团所有的商品属性),而 es 面对于不同的前端应用查询的时候,我们会生成不同的报表,包括一些模型给到前端,最终的目的就是对于前端来说,他要查一个聚合数字,就不需要再拿到 es 的数据之后自己去做 groupby,而是通过直接查询 es 的某个记录就能够把数字查出来了。
此外,在 MongoDB 到 es 的过程中,Tapdata 也完成了实时的增量聚合处理动作,落到 es 的数据就是所有的前端业务要拿来展现的数据,而并不是传统开发模式中,需要从数据库里面拿一条数据,然后自己在前端也好,后端也好把它处理完再给出去。
从整个模式可以看到,通过这种流式处理,实时的将源端业务系统的数据经过计算加工之后提供到前端。对业务和销售人员来说,他们可以直接访问 es 高性能查询数据库,从而大幅提高了查询效率。
对于增量聚合来说,我们很多时候会面临这样的一个聚合场景,以往都是通过 sql,当有一条数据就得 groupby 一把,基本上都是在夜间跑批完成,现在还有很多企业都是在做这种方式。第二种场景就是现在大数据产生了,用 spark 去做(它其实还是通过窗口的方式在做),到最后我们现在有 flink 来做一些流式计算。
我们的实时聚合框架在初始化的时候逃不掉,也会做一次全量,接下来增量聚合过程中我们可以理解为,就像 groupby 一定会有 groupby fields,基于 groupby fields 去做一个小范围的增量聚合。其实一条源端数据匹配到目标数据的可能就那么十几条,哪怕你源端有增删改查,我们也可以做到对目标端对应的报表数字进行回滚,或者是新增或者计算等等实时计算。
对用户来说,他可能希望有一套完整的数据服务平台。用户不希望再像以前一样,还是从 9 个 oracle 里面去取数,然后自己的项目 Java code 里面去做很多计算。而是希望通过有一个统一的出入口,对于 dba 来说它非常容易管理,因为它只要管理统一的出入口的账号权限就可以了,而对于应用端的权限来说是有统一的数据服务来管理的。对于应用端来说,它只要取 API 来作为一个访问的出入口,所以 API 会连入我们的 MongoDB 和 es。
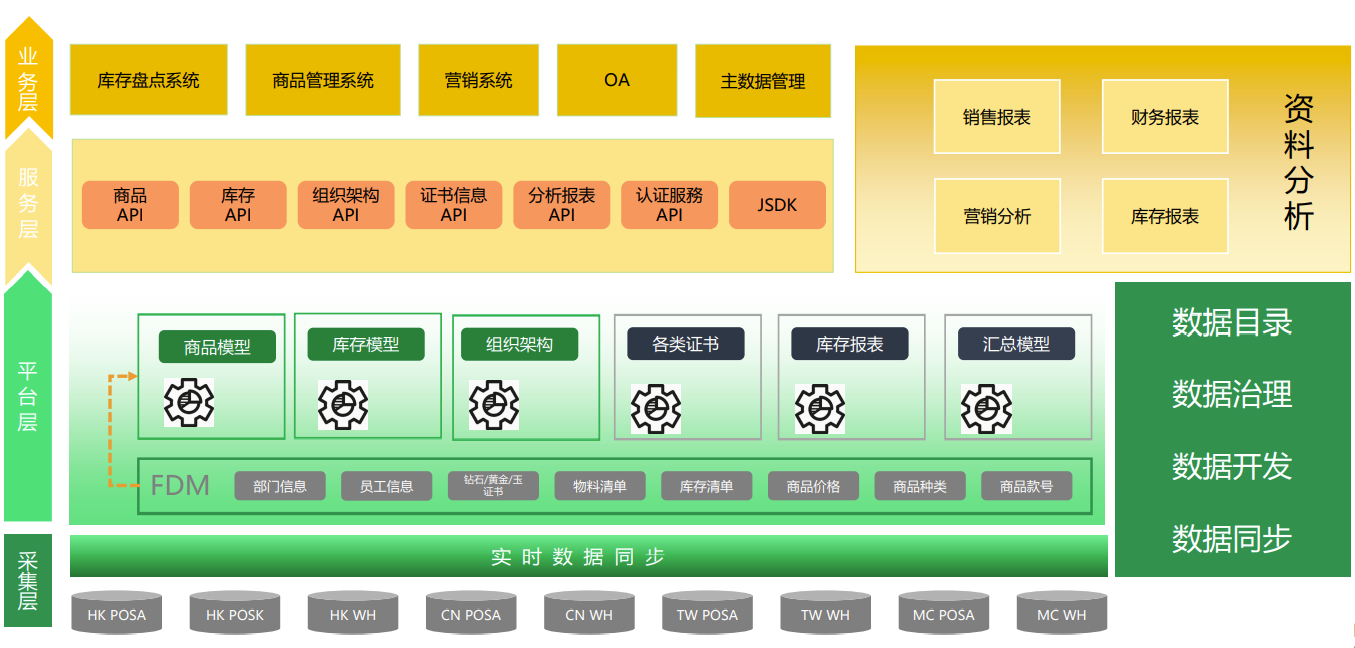
△ Tapdata 构建实时数仓和业务数据双底座
有了这样的一套数据服务之后,向上可以应用于全渠道商品库存中心、营销中心、实时盘点等,对于用户来说,他们的对接成本会降到最低,因为他们只要接API,而API的格式采用了标准的 restful 格式。
本文的零售行业客户案例中,所有的数据库在底座通过 Tapdata 的批流一体方式,数据采集完之后进到 MongoDB 中进行建模(采集即数据同步),建模会参考一些数仓的规范建模,但都是基于业务来做的。
在有了主数据和贴原层数据之后,我们向上就可以提供一些业务模型。

△ Tapdata 统一数据服务
在有一个非常完整的商品模型和订单库存模型的情况下,假设要统计今天各个门店的销售报表,只需要把订单进行聚合就可以了,基于实时增量聚合的框架,就能很快算出来。再假设业务端要查一个基于月的报表,这个报表还是基于实时聚合,对于这类查询的模型来说,永远在查这一个库存模型,可能会有商品模型和库存模型合并的这种场景出现,比如说我这个商品下面有多少个订单,其实也就是把这两个主数据模型进行合并,所以一旦有了我们中间这一层主数据模型之后,向上做任何的业务模型就会非常的快,整个链路因为又可以做到实时,所以对于应用端来说,他们拿到的API的数据也都是实时的。而且,API 是建立在 MongoDB 和 es 这类处理面向 TP 业务的数据库,当然 Tapdata 也能做 AP,而且是实时的 AP。
总结一下,搭建实时数据融合平台的过程,是从 oracle 进到 MongoDB,es,以API的方式提供给微服务。对于前端业务来说,所有的集团级别的业务系统全部都接入进来。
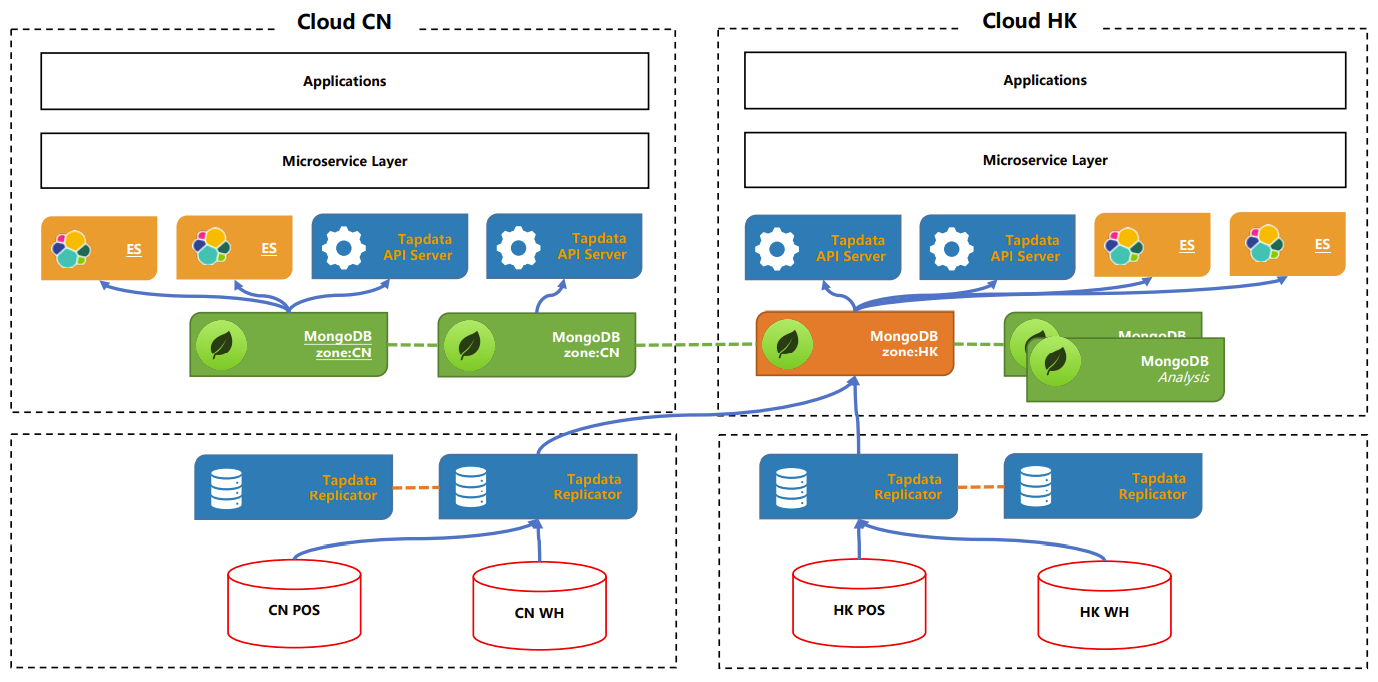
△ DaaS 物理部署架构图
一个两地两中心的架构,在大陆这边一个,在香港这边也有一个中心,所有的 MongoDB 都是分布式的,es 也是采用分片集群部署,读写全部做分离。比如说我们的主节点是在香港,接下来我们的数据会从香港去写入,但是对于我们的读来说,包括业务端来说,他们会就近访问 API,这一层的读写分离,包括策略的转发,是通过客户自己的一套类似于像 apache 来做的。
最后,分享一下 Tapdata 是如何来实施的,这包括几个关键步骤,第一就是了解需求,然后接下来去做一些数据源的准备,接下来就开始做建模,贴源层、主数据层、业务层,最后就上线。涉及到的一些人员分配,可能是一个人会对应多个角色,基本上都是以数据为主要核心。
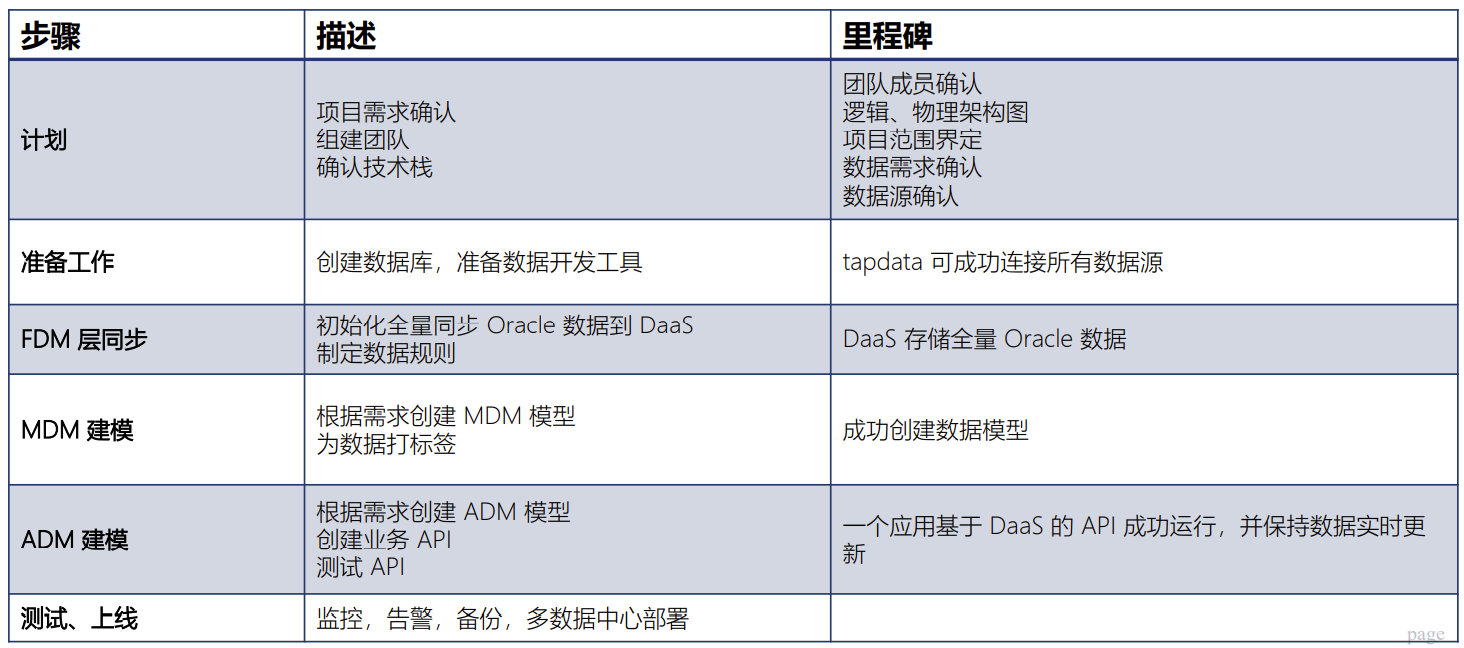
△ Tapdata DaaS 落地步骤
这个案例没有用到特别多的服务器,都是8核16g、16核64g,就能搞定整个集团的数据同步。
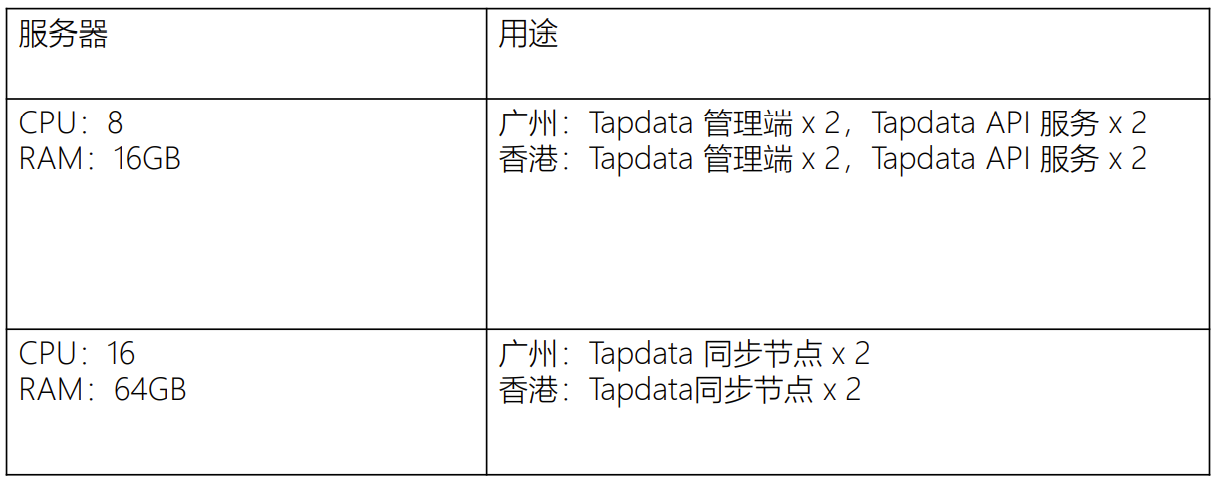
△ Tapdata DaaS 落地硬件配置
三层建模是我们的最佳实践,先把所有的数据放到 MongoDB 里面去,作为贴原层数据,为什么要这么放?是因为第一我们能够极大的减少对于源端数据库的一个压力,因为它只做一个单表同步没有任何计算。第二个就是放进来之后,数据就不会再冗余了,用户的数据都在这里面存了一份,而不是所有的项目都从源端的业务库去拉。
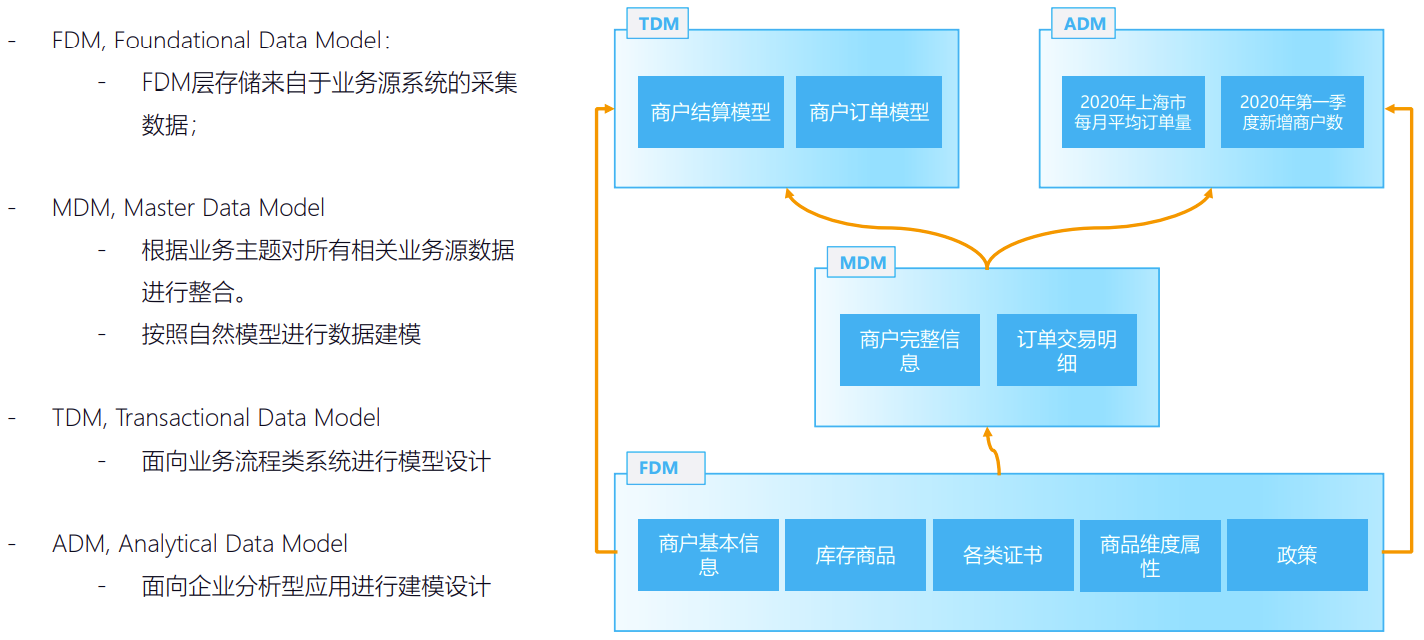
△ Tapdata DaaS 三层建模
接下来我们在贴源层之上,可以去快速建立一个主数据模型,在主数据模型之上去做业务模型、分析模型都会很快。当然也可以直接从贴源层去做业务模型,因为有可能它不一定会有主数据模型,或者说主数据模型太大了。这就是我们的一个实际的演进过程,大家可以看到上面就是一个订单模型,订单状态的流程,他们整个一个订单的流程、流程的 logic,原来都是写在 Java code 和 mq 里面,后来就被放到我们的平台里面去,所以 Tapdata 实时数据服务平台不只是在做数据的同步,仅在贴源层做数据同步,从贴源层到主数据层就开始在做数据的建模以及业务关系的处理,订单状态的变更,以及对后面价格计算、金价变化等等,这些对于业务来说是比较重要的一些属性。

△ Tapdata 实时数据处理
在搭建了企业级实时数据融合平台后,客户获得了几个核心收益:
第一个就是前端响应从10秒降到了亚秒级别。 es 承担了整个前台的所有业务压力,这个组合中帮用户的查询性能直接降到了亚秒级别,查询次数也从 5 次降低为 1 次。
第二个是极大降低数据维护成本。数据门户对于 DBA 来说,帮助是非常大的,他们很多日常工作都是在数据查询上,比如一些报表等等,现在有了实时数据融合平台之后,可以通过开放数据去查,通过包括 BA 和一些非技术人员都可以去平台上自助查询,从而帮 DBA 释放了很多的工作量,同时研发部门无需跨部门沟通数据,极大提升了开发效率。
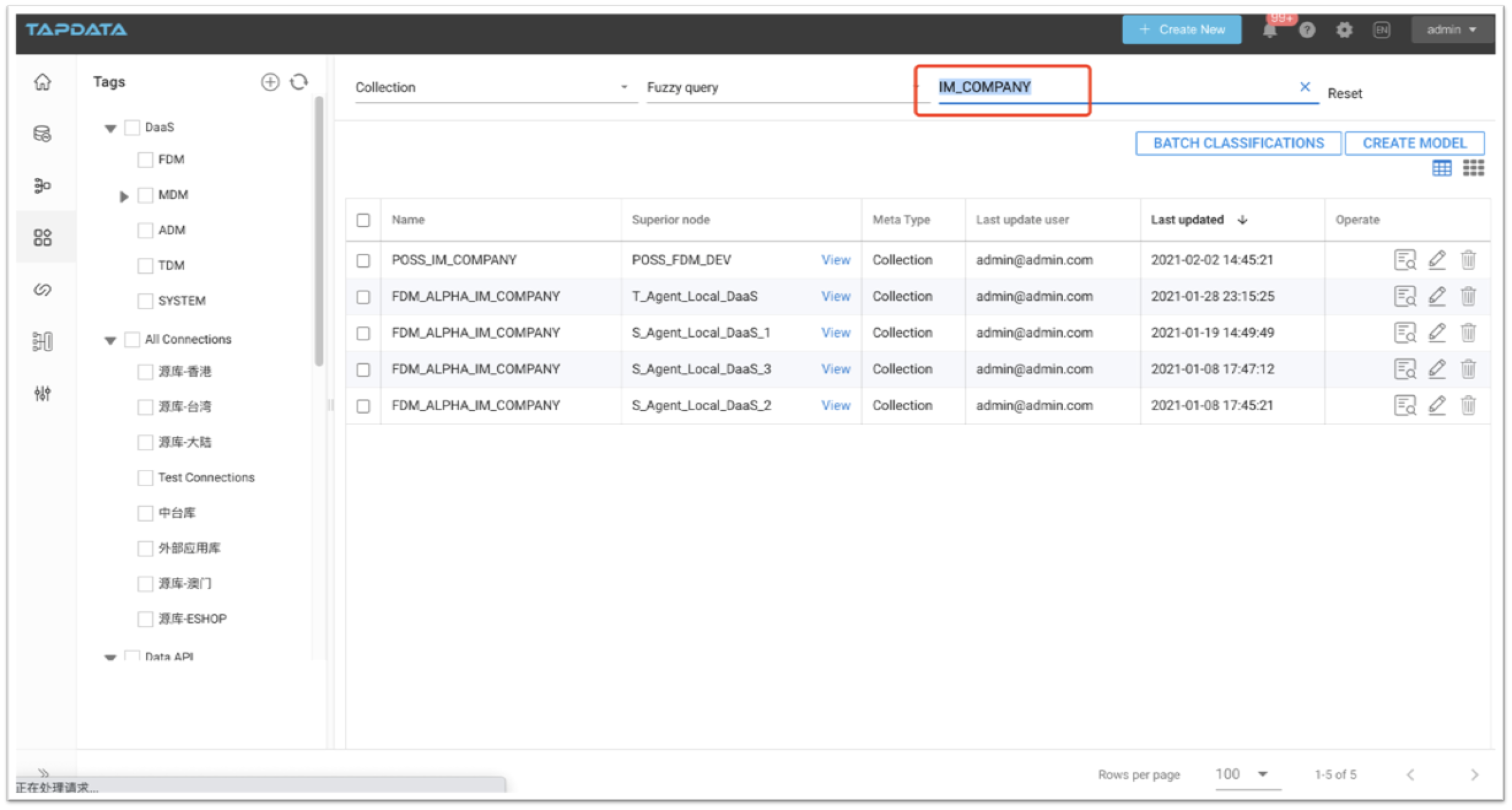
△ Tapdata 数据目录
第三个是改善 API 流程,缩短研发周期。原来整个API 的研发流程可能要做两三个月,现在只需要几天,至多也不会超过一周的时间,因为所有的数据已经都在平台中了,包括主数据模型在 es 那边都有了,数据在平台里面如果暂时搜不到,那么只需要简单的再同步一次,把数据和模型放到平台里面,接下来如果再用到,就不用再重复的去做这个事。从提交需求-研发-上线都非常快,另外 Tapdata 在发布 API 的时候,也会有一些 Swagger 自动生成,对研发来说就无需写对接文档等。
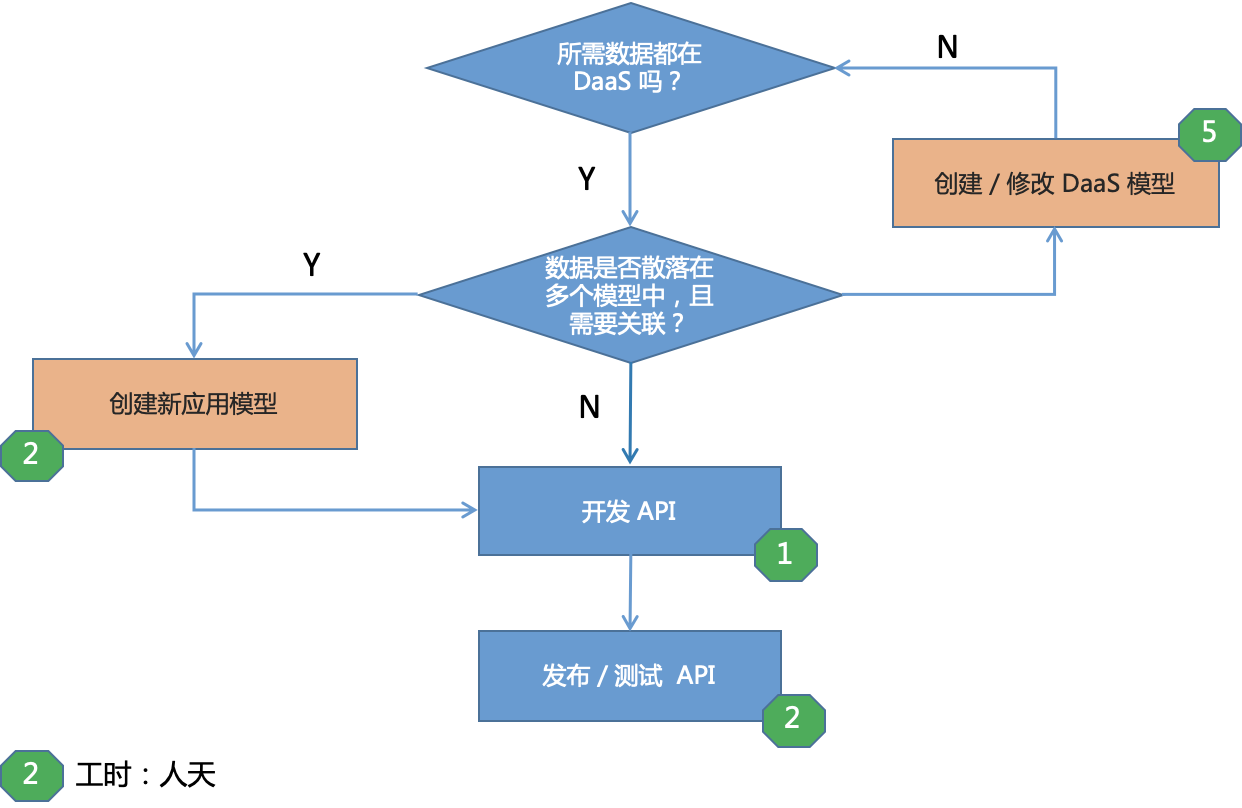
△ Tapdata DaaS API 开发流程
现在,这个零售行业客户已经有十几个大小应用在 Tapdata 实时数据服务平台上运营了,因为有了融合后的实时数据,原来很多的 IT 痛点都被解决掉了。如您想进一步了解 Tapdata 实时数据服务平台,可访问 Tapdata 官方技术博客,或申请试用 Tapdata 产品。
本文作者:Arthur 杨庆麟
Tapdata 首席架构师,MongoDB Professionor(中国15位获得者之一)/ 平安集团mongoDB特邀讲师 /CSDN 认证博客专家。
拥有丰富的数据中台架构经验,主导多个实时数据融合平台的项目,涉及 零售、物联网、车联网、教育等行业。
Recommend
-
10
作者介绍: TJ,唐建法,Tapdata 钛铂数据 CTO,MongoDB中文社区主席,原MongoDB大中华区首席架构师,极客时间MongoDB视频课程讲师。 “...
-
11
Tapdata 实时数据融合平台解决方案(三):数据中台的技术需求 作者介绍:TJ,唐建法,Tapdata 钛铂数据 CTO,MongoDB中文社区主席,原MongoDB大中华区首席架构师,极客时间MongoDB视频课程讲师。
-
12
Tapdata 是由深圳钛铂数据有限公司研发的一款实时数据处理及服务的平台产品,企业可以使用 Tapdata 快速构建数据中台和实时数仓, Tapdata 提供了一站式的解决方案,包括实时数据采集、数据融合以及数据发布等功能和能力。 ...
-
9
Tapdata 唐建法:是时候告别ESB和MQ了, 不妨这样“实时”打通数据孤岛 数据孤岛已成企业数字化转型“绊脚石”。 早期系统设计,不考虑数据互通,传统的 ERP、OA、CRM……每个系统都是独立的,不同架构之间具有天然的层级,数据库也多为单体式,在数...
-
6
Tapdata 肖贝贝:实时数据引擎系列(一) - 新鲜的数据流发布于 25 分钟前2006 年诞生的 hadoop 和 她周边的生态, 在过去的这些年里为大数据的火热提供了足够的能量,...
-
5
Tapdata 在线研讨会:实时数据同步应用场景及实现方案探讨数字化时代的到来,企业业务敏捷度的提升,对传统的数据处理和可用性带来更高的要求,实时数据同步技术的发展,给基于数据的业务创新带来了更多的可能性。9月8日晚,Tapdata 联合MongoDB 中文社区和CSDN举...
-
5
Tapdata 在线研讨会:DaaS vs 大数据平台,是竞争还是共处?从20年前的传统数仓,到10年前大数据平台,5年前开始火热的数据中台以及最近出现的湖仓一体新数据平台,今天被数据孤岛困扰的企业,面临着太多的选择。这些数据产品及架构有一个共性:他们本质上...
-
9
MongoDB 数据实时同步利器-Tapdata Cloud 免费上手指南 偶然接触到 Tapdata Cloud,据说不仅可以实现MongoDB数据实时同步,还永久 100% 免费,但就是不知道怎么获取、怎么用? 打开相关文档逐渐陷入迷茫,术语随处可见,小白慌张?...
-
9
Tapdata 肖贝贝:实时数据引擎系列(六)-从 PostgreSQL 实时数据集成看增量数据缓存层的必要性 原创 Tapdata...
-
6
Tapdata PDK 生态共建计划启动!Doris、OceanBase、PolarDB、SequoiaDB 等十余家厂商首批加入 2022年4月7日,Tapdata 正式启动 PDK 插件生态共建计划,致力于全面连接数据孤岛,加速构建更加开放的数据生态,以期让各行各业的使用者都能释放...
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK