

MongoDB基础入门 - 女友在高考
source link: https://www.cnblogs.com/javammc/p/16471833.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

MongoDB简介
MongoDB是一个基于分布式文件存储的数据库。由C++语言编写。旨在为WEB应用提供可扩展的高性能数据存储解决方案。
MongoDB是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。它支持的数据结构非常松散,是类似json的bson格式,因此可以存储比较复杂的数据类型。Mongo最大的特点是它支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引。
MongoDB体系结构

MongoDB与关系型数据库对比
| 关系型数据库 | MongoDB |
|---|---|
| database(数据库) | database(数据库) |
| table(表) | collection(集合) |
| row(行) | document(BSON文档) |
| column(列) | field(字段) |
| index(唯一索引、主键索引) | index(地理位置索引、全文索引、哈希索引) |
| join(主外键关联) | embedded Document(嵌套文档) |
| primary key(指定1至N个列做主键) | primary key(指定_id field为主键) |
前面说MongoDB用的是BSON文档,那么什么是BSON呢?
BSON简介
BSON是一种类json的一种二进制形式的存储格式,简称BinaryJSON,它和JSON一样,支持内嵌的文档对象和数组对象,但是BSON有JSON没有的一些数据类型,如Date和BinaryData类型。
BSON可以做为网络数据交换的一种存储形式,是一种schema-less的存储形式,它的优点是灵活性高,但它的缺点是空间利用率不是很理想。{key:value,key2:value2}这是一个BSON的例子,其中key是字符串类型,后面的value值,它的类型一般是字符串,double,Array,ISODate等类型。
BSON有三个特点:轻量性、可遍历性、高效性
MongoDB中使用了BSON来存储数据和网络数据交换。把这种格式转化成文档这个概念,这里的一个Document也可以理解成关系型数据库中的一条记录,只是这里的Document的变化更丰富一些,如Document可以嵌套。
下面是MongoDB中Document里面可以出现的数据类型:

MongoDB安装
- 下载社区版MongoDB,下载地址:https://www.mongodb.com/try/download/community
- 将压缩包解压
- 可以直接启动或使用配置文件启动
- 新建目录/data/mongo
- 新建配置文件mongo.conf,内容如下:
#数据库目录
dbpath=/data/mongo/
port=27017
#监听ip地址,默认全部可以访问
bind_ip=0.0.0.0
#是否以后台启动的方式登录
fork=true
#日志路径
logpath = /data/mongo/MongoDB.log
#是否追加日志
logappend = true
#是否开启用户密码登录
auth=false
./bin/mongod -f mongo.conf
Mongo shell
- 启动mongo shell
./bin/mongo
- 指定主机和端口的方式
./bin/mongo --host=主机ip --port=端口
MongoDB GUI工具
- MongoDB Compass Community
MongoDBCompassCommunity由MongoDB开发人员开发,这意味着更高的可靠性和兼容性。它为MongoDB提供GUImongodb工具,以探索数据库交互,具有完整的CRUD功能并提供可视方式。借助内置模式可视化,用户可以分析文档并显示丰富的结构。为了监控服务器的负载,它提供了数据库操作的实时统计信息。就像MongoDB一样,Compass也有两个版本,一个是Enterprise(付费),社区可以免费使用。适用于Linux、Mac或Windows。
- NoSQLBooster(mongobooster)
NoSQLBooster是MongoDBCLI界面中非常流行的GUI工具。它正式名称为MongoBooster。NoSQLBooster是一个跨平台,它带有一堆mongodb工具来管理数据库和监控服务器。这个Mongodb工具包括服务器监控工具,VisualExplainPlan,查询构建器,SQL查询,ES2017语法支持等等......它有免费,个人和商业版本,当然,免费版本有一些功能限制。NoSQLBooster也适用于Linux、Mac或Windows。
MongoDB基础操作
1. 数据库与集合
1.1 查看数据库
show dbs;
1.2 切换数据库(如果没有对于数据库则创建)
use 数据库名;
1.3 查看集合
show tables;
#或者
show collections;
1.4 删除集合
db.集合名.drop();
1.5 删除当前数据库
db.dropDatabase();
2. 数据增删改查
新增
2.1 数据新增
db.user.insert({name:"小明",bithday:new ISODate("2020-09-01"),expectSalary:15000,gender:0,city:"bj"});
2.2 新增多条
db.user.insert([{name:"小李",bithday:new ISODate("2020-09-01"),expectSalary:18000,gender:0,city:"bj"},{name:"小王",bithday:new ISODate("2020-09-01"),expectSalary:25000,gender:0,city:"bj"}]);
查询
2.3 比较条件查询
db.集合名.find(条件)
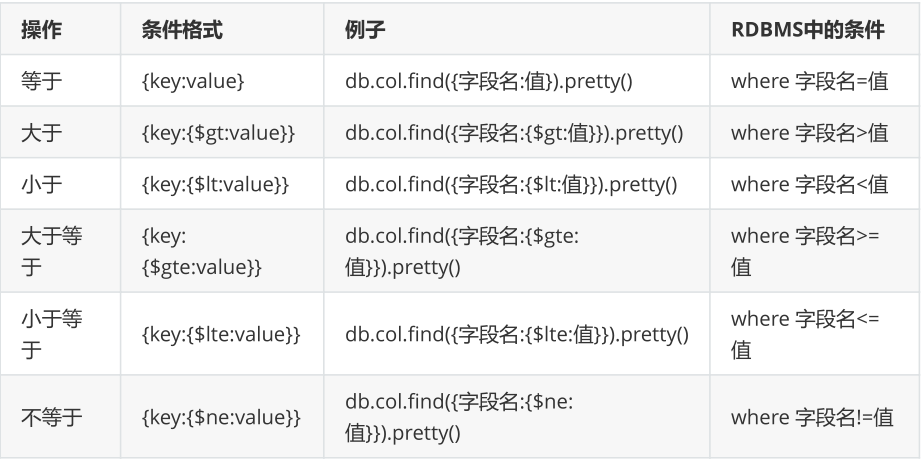
db.user.find({expectSalary:{$gt:18000}})
2.4 逻辑条件查询
and 条件
MongoDB的find()方法可以传入多个key,每个key之间用逗号隔开,多个key之间是and的关系
db.集合名.find({$or:[{key1:value1}, {key2:value2}]})
not条件
db.集合名.find({key:{$not:{$操作符:value}})
db.user.find({city:"bj",expectSalary:{$gt:15000}})
db.user.find({$or:[{city:"bj"},{expectSalary:{$gt:15000}}]});
2.5 分页查询
db.集合名.find({条件}).sort({排序字段:排序方式})).skip(跳过的行数).limit(一页显示多少数据)
db.user.find().sort({expectSalary:1}).limit(3)
排序时1代表升序,-1代表降序。
修改
2.6 数据更新
$set :设置字段值
$unset :删除指定字段
$inc:对修改的值进行自增
db.集合名.update(
<query>,
<update>,
{
upsert: <boolean>,
multi: <boolean>,
writeConcern: <document>
}
)
参数说明:
- query:update的查询条件,类似sql里面update语句where后面那段
- update,update的对象和更新的操作符。$set、$inc等
- upsert:可选,如果不存在的记录,是否新增。true:新增;false:不新增
- multi:可选,默认是false,只更新查询到的第一条记录,true:代表把查询出来的多条记录都更新。
- writeConcern:可选,用来指定mongo对写操作的回执行为。
db.user.update({name:"小明"},{$set:{gender:1}},{multi:true})
删除
2.7 数据删除
db.集合名.remove(
<query>,
{
justOne: <boolean>,
writeConcern: <document>
}
)
参数说明:
- query:删除的文档的条件
- justOne:如果设为true或1,则只删除一个文档,如果不设置该参数或使用默认值false,则删除查询到的所有文档。
- writeConcern:用来指定mongo对写操作的回执行为
db.user.remove({name:"小王"})
MongoDB聚合操作
聚合是MongoDB的高级查询语言,它允许我们通过转化合并由多个文档的数据来生成新的在单个文档里不存在的文档信息。一般都是将记录按条件分组之后进行一系列求最大值、最小值、平均值的简单操作,也可以对记录进行复杂数据统计、数据挖掘的操作。聚合操作的输入是集中的文档,输出可以是一个文档也可以是多个文档。
单目的聚合操作
常用命令:count()
db.user.find().count();
聚合管道
db.集合名.aggregate(操作)
MongoDB中聚合(aggregate)主要用于统计数据(诸如统计平均值、求和等),并返回计算后的数据结果。表达式:处理输入文档并输出。表达式只能用于计算当前聚合管道的文档,不能处理其它的文档。
聚合常见操作:
| 操作 | 描述 |
|---|---|
| $group | 将集合中的文档分组,可用于统计结果。 |
| $project | 修改输入文档的结构。可以用来重命名、增加或删除域,也可以用于创建计算结果以及嵌套文档。 |
| $match | 用于过滤数据,只输出符合条件的文档。$match使用MongoDB的标准查询操作。 |
| $limit | 用来限制MongoDB聚合管道返回的文档数。 |
| $skip | 在聚合管道中跳过指定数量的文档,并返回余下的文档。 |
| $sort | 将输入文档排序后输出。 |
| $geoNear | 输出接近某一地理位置的有序文档。 |
表达式:处理输入文档并输出。表达式只能用于计算当前聚合管道的文档,不能处理其它的文档。
| 表达式 | 描述 |
|---|---|
| $sum | 计算总和 |
| $avg | 计算平均值 |
| $min | 获取集合中所有文档对应值得最小值 |
| $max | 获取集合中所有文档对应值得最大值 |
| $push | 在结果文档中插入值到一个数组中 |
| $addToSet | 在结果文档中插入值到一个数组中,但数据不重复 |
| $first | 根据资源文档的排序获取第一个文档数据 |
| $last | 根据资源文档的排序获取最后一个文档数据 |
db.user.aggregate([{$group:{_id:"$city",avgSal:{$avg:"$expectSalary"}}},{$project:{city:"$city",salary:"$avgSal"}}]);
db.user.aggregate([{$group:{_id:"$city",avgSal:{$avg:"$expectSalary"}}},{$match:{avgSal:{$gt:440}}}]);
db.user.aggregate([{$limit:2},{$sort:{expectSalary:-1}},{$group:{_id:"$name",avgSal:{$avg:"$expectSalary"}}}]);
MapReduce编程模型
Pipeline查询速度快于MapReduce,但是MapReduce的强大之处在于能够在多台Server上并行执行复杂的聚合逻辑。MongoDB不允许Pipeline的单个聚合操作占用过多的系统内存,如果一个聚合操作消耗20%以上的内存,那么MongoDB直接停止操作,并向客户端输出错误消息。
MapReduce是一种计算模型,简单的说就是将大批量的工作(数据)分解(MAP)执行,然后再将结果合并成最终结果(REDUCE)。
db.collection.mapReduce(
function() {emit(key,value);}, //map 函数
function(key,values) {return reduceFunction}, //reduce 函数
{
out: collection,
query: document,
sort: document,
limit: number,
finalize: <function>,
verbose: <boolean>
}
)
使用MapReduce要实现两个函数Map函数和Reduce函数,Map函数调用emit(key,value),遍历collection中所有的记录,将key与value传递给Reduce函数进行处理。
参数说明:
- out:统计结果存放集合
- query:一个筛选条件,只有满足条件的文档才会调用map函数
- sort:和limit结合的sort排序参数
- limit:发往map函数的文档数量上限
- finalize:可以对reduce输出结果再一次修改
- verbose:是否包括结果信息中的时间信息,默认为false
db.user.mapReduce(function(){emit(this.city,this.expectSalary);},function(key,value){return Array.avg(value)},{query:{expectSalary:{$gt:15000}},out:"cityAvgSal"})
Recommend
-
6
Elasticsearch学习系列二(基础操作) 本文将分为3块讲...
-
4
Query文档搜索机制剖析 1. query then fetch(默认搜索方式) 搜索步骤如下: 发送查询到每个shard 找到所有匹配的文档,并使用本地的Term/Document Frequery信息进行打分
-
2
MongoDB慢查询 慢查询分析 开启内置的慢查询分析器 db.setProfilingLevel(n,m),n的取值可选0,1,2 0:表示不记录 1:表示记录慢速操作,如果值为1...
-
10
Apache Hadoop 分布式集群搭建 基础环境准备 三台 linux 节点,操作系统(Centos7) 关闭防火墙 systemctl stop firewalld...
-
4
HDFS简介 HDFS(全称:Hadoop Distribute File System)分布式文件系统,是Hadoop核心组成。 HDFS中的重要概念 分块存储 HDFS中的文件在物理上是分块存储的,块的大小可以通...
-
7
MapReduce 中的排序 MapTask 和 ReduceTask 都会对数据按key进行排序。该操作是 Hadoop 的默认行为,任何应用程序不管需不需要都会被排序。默认排序是字典顺序排序,排序方法是快速排序 下面介绍排序过程...
-
9
一、Amdahl定律 加速=优化前耗时/优化后耗时比 公式图:
-
3
HBase概念入门 - 女友在高考 - 博客园 HBase简介 HBase基于Google的BigTable论文而来,是一个分布式海量列式非关系型数据库系...
-
10
Flink 概述 什么是 Flink Apache Apache Flink 是一个开源的流处理框架,应用于分布式、高性能、高可用的数据流应用程序。可以处理有限数据流和无限数据,即能够处理有边界和无边界的数据流。无边界的数据...
-
7
git 中的术语解释:
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK