

YOLOv7速度精度超越其他变体,大神AB发推,网友:还得是你!
source link: https://www.qbitai.com/2022/07/35891.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
YOLOv7速度精度超越其他变体,大神AB发推,网友:还得是你!

前脚美团刚发布YOLOv
Pine 发自 凹非寺
量子位 | 公众号 QbitAI
前脚美团刚发布YOLOv6, YOLO官方团队又放出新版本。
曾参与YOLO项目维护的大神Alexey Bochkovskiy在推特上声称:
官方版YOLOv7比以下版本的精度和速度都要好。
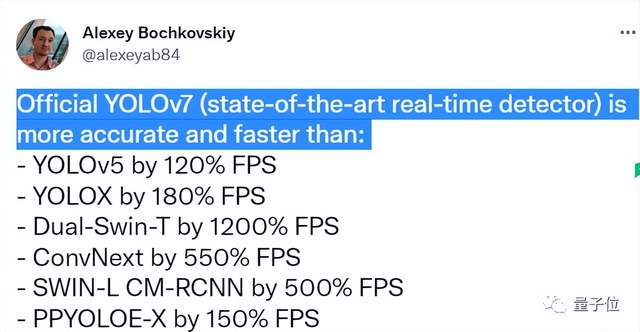
在论文中,团队详细对比了YOLOv7和其他变体的性能对比,并介绍v7版本的新变化。

话不多说,YOLOv7有多强一起来看实验结果。
速度、精度都超越其他变体
论文中,实验以之前版本的YOLO和最先进的目标检测模型作为基准。
表格是YOLOv7模型在相同的参数设置下与其他版本的比较:
数据标绿代表性能相较于之前版本有所提升,参数量和计算量相较于之前版本,大部分均有所减少,AP也有所提升。
即使在云GPU模型上,最新模型仍可以保持较高的AP,与此同时计算量和参数量相较于之前模型也均有所下降。
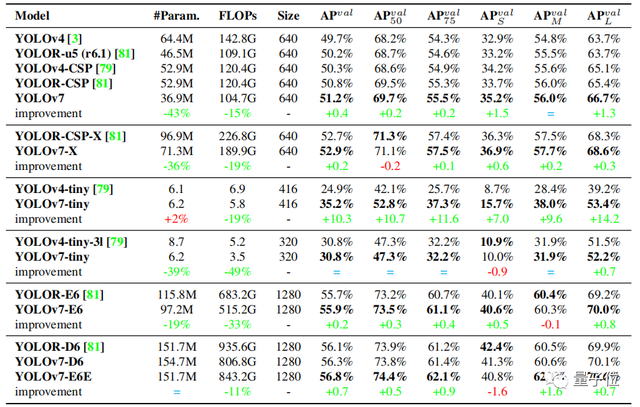
YOLOv7可以很好地平衡速度与精度。
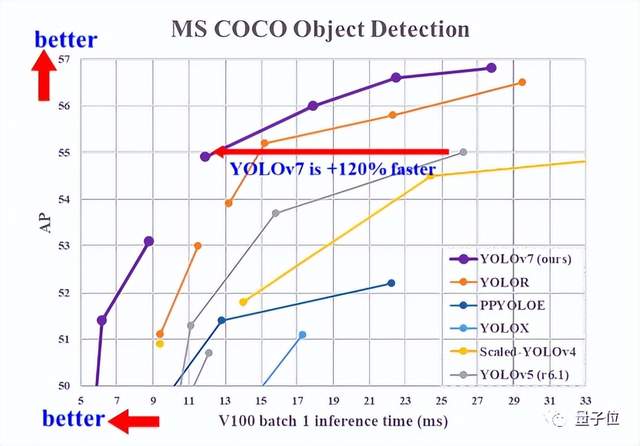
与现有的通用GPU和移动GPU的目标检测模型进行比较:
YOLOv7在速度(FPS)和精度(AP)均超过其他目标检测模型。
比如,在输入分辨率为1280时,将YOLOv7与YOLOR进行比较,YOLOv7-W6的推理速度比YOLOR-P6快8fps,检测率也提高了1%AP。
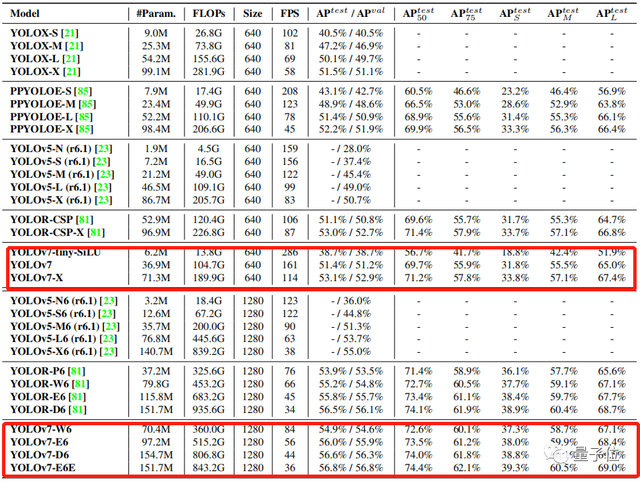
性能是怎么提升的?
改进实时目标检测模型的性能,往往要从以下几点入手:
1、更快更强的网络架构;
2、更有效的特征集成方法;
3、更准确的检测方法;
4、更精确的损失函数;
5、更有效的标签分配方法;
6、更有效的训练方法。
YOLOv7主要从4、5、6入手设计性能更好的检测模型。
首先,YOLOv7扩展了高效长程注意力网络,称为Extended-ELAN(简称E-ELAN)。
在大规模的ELAN中,无论梯度路径长度和块的数量如何,网络都能达到稳定状态。
但是如果无限地堆叠计算块,这种稳定状态也可能会被破坏,参数利用率也会降低。
E-ELAN对基数(Cardinality)做了扩展(Expand)、乱序(Shuffle)、合并(Merge cardinality),能在不破坏原始梯度路径的情况下,提高网络的学习能力。
在架构方面,E-ELAN只改变了计算块中的体系结构,没有改变过渡层的体系结构。
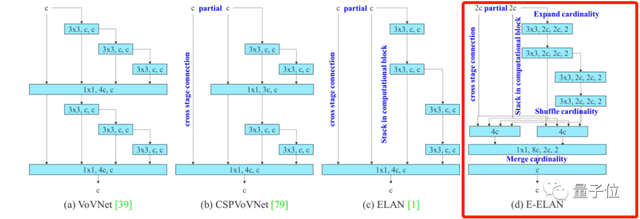
除了保持原来ELAN的设计架构外,E-ELAN还可以引导不同的计算块组来学习更多样化的特性。
而后,YOLOv7采用基于级联的(Concatenation-based)模型缩放方法。
模型缩放是指调整模型的一些属性,生成不同尺度的模型,以满足不同推理速度的需求。
然而,模型缩放如果应用于基于连接的架构,当扩大或缩小执行深度时,基于连接的翻译层的计算块将减少或增加。
由此可以推断,对于基于级联的模型,不能单独分析不同的缩放因子,必须一起考虑。
基于级联的模型缩放方法是一个复合模型缩放方法,当缩放一个计算块的深度因子时,同时也要计算该块输出通道的变化。
然后,对过渡层以相同的变化量进行宽度因子缩放,这样就可以保持模型在初始设计时的特性,并保持最优结构。

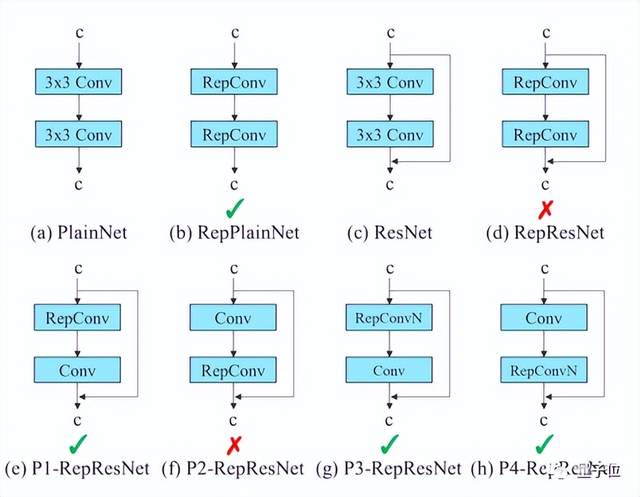
在论文研究中,作者还设计了有计划的重新参数化卷积(Planned re-parameterized convolution)。
RepConv在VGG中有比较优异的性能,但当它直接应用于ResNet、DenseNet或者其他架构时,精度会明显降低。
这是因为RepConv中的直连(Identity connection)破坏了ResNet中的残差和DenseNet中的连接。
因此,论文研究中使用没有直连的RepConv(RepConvN)来设计网络结构。
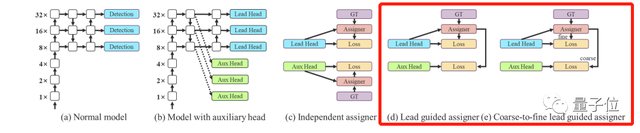
在YOLOv7的标签分配机制中,需要同时考虑网络预测结果与基准,然后将软标签(综合考虑,优化之后的标签)分配到“label assigner”机制。
那么接下来,“软标签要分配给auxiliary head还是lead head呢?”
论文提出了一种新的标签分配法,如下图中的(d)、(e),基于lead head预测,生成从粗到细的层次标签,分别用于lead head和auxiliary head的学习。
图(d)让较浅的auxiliary head学习lead head已经学习到的信息,而输lead head则可以更专注于为学习到的残差信息。
而e图中,会生成两组软标签,即粗标签和细标签。auxiliary head不如lead head学习能力强,因此要重点优化它的召回率,避免丢失掉需要学习的信息。
目前,YOLOv7已官方开源,有兴趣的伙伴可以戳下文链接。
参考链接:
[1] https://twitter.com/alexeyab84/status/1544877675004788739
[2] https://arxiv.org/abs/2207.02696
[3] https://github.com/WongKinYiu/yolov7/releases
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK