

强化学习-学习笔记12 | Dueling Network - climerecho
source link: https://www.cnblogs.com/Roboduster/p/16460740.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
这是价值学习高级技巧第三篇,前两篇主要是针对 TD 算法的改进,而Dueling Network 对 DQN 的结构进行改进,能够大幅度改进DQN的效果。
Dueling Network 的应用范围不限于 DQN,本文只介绍其在 DQN上的应用。
12. Dueling Network
12.1 优势函数
Advantage Function.
回顾一些基础概念:
折扣回报:
Ut=Rt+γ⋅Rt+1+γ2R+...Ut=Rt+γ⋅Rt+1+γ2R+...
动作价值函数:
Qπ(st,at)=E[Ut|St=st,At=at]Qπ(st,at)=E[Ut|St=st,At=at]
消去了未来的状态 和 动作,只依赖于当前动作和状态,以及策略函数 ππ。
状态价值函数:
Vπ(st)=E[Qπ(st,A)]Vπ(st)=E[Qπ(st,A)]
只跟策略函数 ππ 和当前状态 stst 有关。
最优动作价值函数
Q∗(s,a)=maxπQπ(s,a)Q∗(s,a)=maxπQπ(s,a)
只依赖于 s,a,不依赖策略函数。
最优状态价值函数
V∗(s)=maxaVπ(S)V∗(s)=maxaVπ(S)
只依赖 S。
下面就是这次的主角之一:
-
Optimal Advantage function 优势函数:
A∗(s,a)=Q∗(s,a)−V∗(s)A∗(s,a)=Q∗(s,a)−V∗(s)
V* 作为 baseline ,优势函数的意思是动作 a 相对 V* 的优势,A*越好,那么优势就越大。
下面介绍一个优势函数有关的定理:
定理一:V∗(s)=maxaQ∗(s,a)V∗(s)=maxaQ∗(s,a)
这一点从上面的回顾不难看出,求得最优的路径不同,但是相等。
上面提到了优势函数的定义:A∗(s,a)=Q∗(s,a)−V∗(s)A∗(s,a)=Q∗(s,a)−V∗(s)
同时对左右求最大值:maxaA∗(s,a)=maxaQ∗(s,a)−V∗(s)maxaA∗(s,a)=maxaQ∗(s,a)−V∗(s),而等式右侧正是上面定理,所以右侧==0;因此优势函数关于a的最大值=0,即:
maxaA∗(s,a)=0maxaA∗(s,a)=0
我们把这个 0 值式子加到定义上,进行简单变形:
定理二:Q∗(s,a)=V∗(s)+A∗(s,a)−maxaA∗(s,a)Q∗(s,a)=V∗(s)+A∗(s,a)−maxaA∗(s,a)
Dueling Network 就是由定理二得到的。
12.2 Dueling Network 原理
此前 DQN 用Q(s,a;w)Q(s,a;w) 来近似 D∗(s,a)D∗(s,a) ,结构如下:
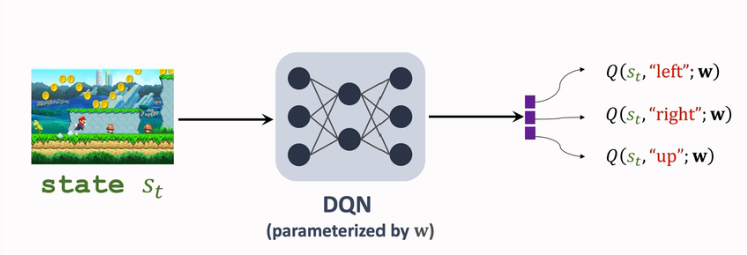
而 Dueling Network 对 DQN 的结构改进原理是:
-
我们对于DQN的改进思路就是基于上面的定理2:Q∗(s,a)=V∗(s)+A∗(s,a)−maxaA∗(s,a)Q∗(s,a)=V∗(s)+A∗(s,a)−maxaA∗(s,a)
- 分别用神经网络 V 和 A 近似 V-star 和 A-star
- 即:Q(s,a;wA,wV)=V(s;wV)+A(s,a;wA)−maxaA(s,a;wA)Q(s,a;wA,wV)=V(s;wV)+A(s,a;wA)−maxaA(s,a;wA)
- 这样也完成了对于 Q-star 的近似,与 DQN 的功能相同。
-
首先需要用一个神经网络 V(s;wV)V(s;wV) 来近似 V∗(s)V∗(s):
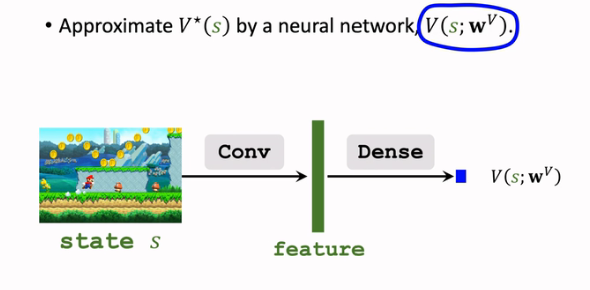
注意这里的输出是一个实数,是对状态的打分,而非向量;
- 用另一个神经网络A(s,a;wA)A(s,a;wA) 对A∗(s,a)A∗(s,a) 进行近似:
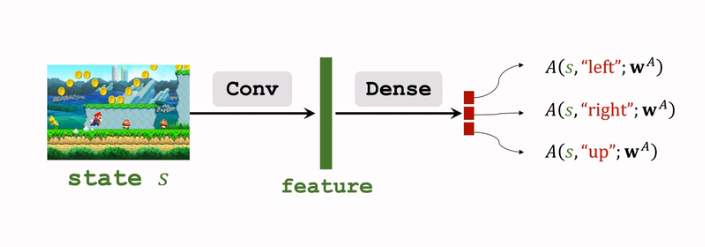
这个网络和上面的网络 VV 结构有一定的相像,可以共享卷积层的参数;
后续为了方便,令 w=(wA,wV)w=(wA,wV),即:
现在 左侧 与 DQN 的表示就一致了。下面搭建Dueling Network,就是上面 V 和 A 的拼接与计算:
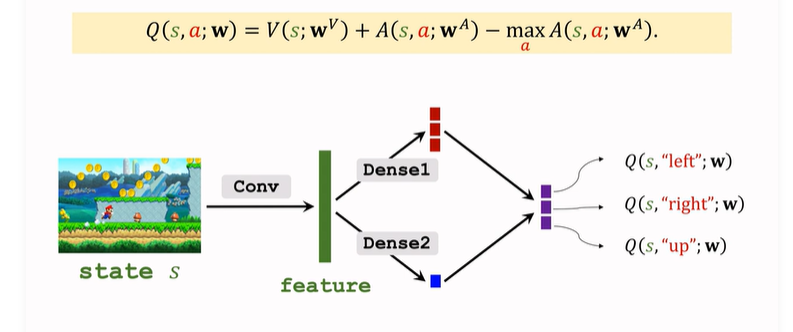
- 输入 状态 s,V 和 A 共享一些 卷积层,得到特征向量;
- 分别通过不同的全连接层,A输出向量,V输出实数;
- 通过上面的式子运算输出最终结果,是对所有动作的打分;
可见Dueling Network 的输入 和 输出 和 DQN 完全一样,功能也完全一样;但是内部的结构不同,Dueling Network 的结构更好,所以表现要比 DQN好;
注意,Dueling Network 和 DQN 都是对 最优动作价值函数 的近似。
12.3 训练 Dueling Network
接下来训练参数 w=(wA,wv)w=(wA,wv),采用与 DQN 相同的思路,也就是采用 TD算法训练 Dueling Network。
之前介绍的 TD算法 的三种优化方法:
- 经验回放 / 优先经验回放
- Double DQN
- M-step TD target
都可以用在 训练 Dueling Network 上。
12.4 数学原理与不唯一性
之前推导 Dueling Network 原理的时候,有如下两个式子:
- Q∗(s,a)=V∗(s)+A∗(s,a)Q∗(s,a)=V∗(s)+A∗(s,a)
- Q∗(s,a)=V∗(s)+A∗(s,a)−maxaA∗(s,a)Q∗(s,a)=V∗(s)+A∗(s,a)−maxaA∗(s,a)
我们为什么一定要用等式 2 而不是等式 1 呢?也就是为什么要加上一个 值为 0 的 maxaA∗(s,a)maxaA∗(s,a)?
-
这是因为 等式1 有一个问题。
-
即我们无法通过学习 Q-star 来 唯一确定 V-star 和 A-star,即对于求得的 Q-star 值,可以分解成无数组 V-star 和 A-star。
-
Q(s,a;wA,wV)=V(s;wV)+A(s,a;wA)−maxaA(s,a;wA)Q(s,a;wA,wV)=V(s;wV)+A(s,a;wA)−maxaA(s,a;wA)
-
我们是对 左侧Q 来训练整个 Dueling Network 的。如果 V 网络 向上波动 和 A 网络向下波动幅度相同,那么 Dueling Network 的输出完全相同,但是V-A两个网络都发生了波动,训练不好。
-
而加上最大化这一项就能避免不唯一性;即如果 V-star 向上波动10,A-star 向下波动10,那么整个式子的值会发生改变
因为max项随着A-star 的变化 也减少了10,总体上升了10
在上面的数学推导中,我们使用的是 maxaA(s,a;wA)maxaA(s,a;wA)来近似最大项maxaA(s,a)maxaA(s,a),而在实际应用中,用 meanaA(S,a;wA)meanaA(S,a;wA)来近似效果更好;这种替换没有理论依据,但是实际效果好。
x. 参考教程
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK