

为什么说谁掌握了人工智能谁就掌握元宇宙?
source link: https://www.36kr.com/p/1816950451842690
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
今天想跟大家聊一下元宇宙跟 AI 结合会碰撞出怎样的火花。
元宇宙,正如我们之前的视频所说,就是以VR为媒介的下一代互联网,突出VR视频和交互技术成熟带来的极致临场感和沉浸感,无限模糊真实和虚拟,拉近人与人之间的距离。
它与AI人工智能的结合可能大家一下就会想到一些科幻电影,比如当年还是沃卓斯基兄弟的沃卓斯基姐妹的传世经典《黑客帝国》系列,再比如去年的那部《失控玩家》。
在黑客帝国里面,AI统治了地球,人类的意识被禁锢在了虚拟世界当中,肉体则成为了培养仓当中的生物电池。各种功能的AI不但无所不能,而且还在虚拟世界里突变进化。比如大反派特工史密斯,作为有思想的杀毒软件,就在虚拟世界的数字信息海洋中,不断学习进化,逆袭了母体,甚至进入了现实世界。
而在失控玩家当中,游戏里面的NPC Guy某一天突然产生了人类一般的自我意识,脱离了他被设定好的那个角色开始在虚拟世界翻云覆雨,还跟现实当中的女主谈起了恋爱。
也就是不管是在AI虚拟世界带来人类末世这种黑暗结局,还是游戏NPC产生人类最珍贵的美好情感这种光明结局当中,至少在两个点上,电影的创作者们达成了共识:
一是虚拟世界会因为AI的存在变得丰富多彩,并且具备一定的脱离人类自我发展迭代的能力
二是AI在脱离现实世界的束缚之后会变得更加的强大,甚至反过来影响现实世界。
所以类似这样的未来是否会成为现实呢?
在深入探讨之前,我觉得有必要先简单地聊一下现在我们称之为AI的那个东西他本质上是个啥,不然空对空说它能干什么不能干什么就有点尬了。对AI非常熟悉的朋友可以忽略这段。
大家印象比较深刻AI应该是2016年3月击败李世石的Alpha Go,它就像一个神话故事中的水晶球,只要把现在的棋谱告诉它,它内部不知道怎么计算了一下,就能输出必然赢得比赛的落子策略,把杰宝之类的人类高手都打哭了。
在Alpha Go之后,短短几年之间,AI扩展到了我们生活的方方面面。我们现在刷的视频大概率是AI推送的,很多视频里面的配音都是AI配的,我们买的东西是AI推荐的,我们电脑显卡手机GPU是AI加速的,张学友演唱会逮捕逃犯是靠AI识别的,连现在这段BGM都是AI谱曲的。
而正如芯片有它的基本单元,也就是可以输出0和1的晶体管一样,AI也有它的基本单元,叫做感知机。
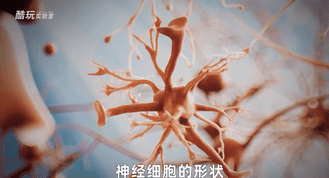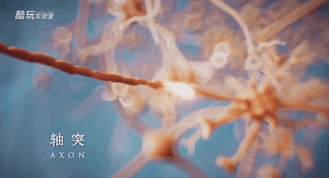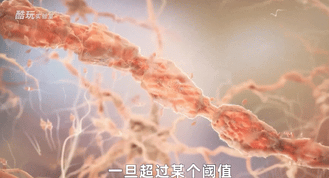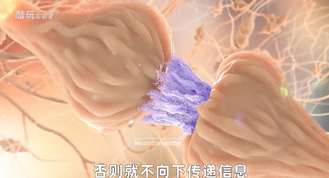
1957年,康奈尔大学的心理学家兼工程师弗朗克·罗森布拉特受到神经细胞的启发,提出了感知机的构想。
神经细胞的形状呢非常的“支棱”,除了那一坨细胞主体之外,它的外壁有很多树杈状的短突起,叫做树突,还有一根长长的“尾巴”叫做轴突。
树突的作用是接收外部输入的各种刺激,形成生物电,这些生物电经过整合后,一旦超过某个阈值,就会经由轴突传导,并在末端分泌神经递质,将信息传递给下一个细胞,否则就不向下传递信息。
所以神经元细胞的输出只有两种状态,用数学表示就是“0”或者“1”,然后人脑有超过一百亿个神经元组成一个神经网络,前面的神经元输出作为后面的神经元输入进一步处理,不断反复,最终实现人类的智能。

参照了输入,处理,分类,输出四个步骤,感知机就模拟出了类似的结构。
每个输入信号乘上对应的权重,对应着树突的刺激输入,累加这个函数符号模拟了神经细胞整合生物电的过程,激活函数则判断累加值是否达到阈值,比阈值大,就输出1,否则输出0。

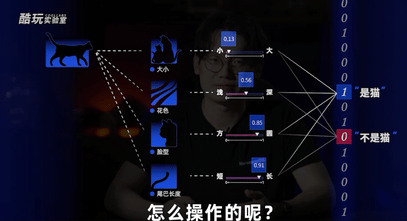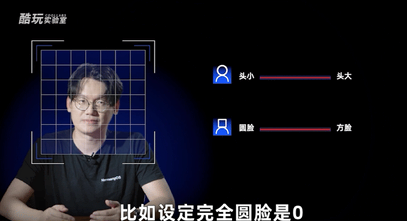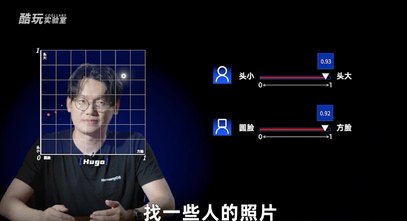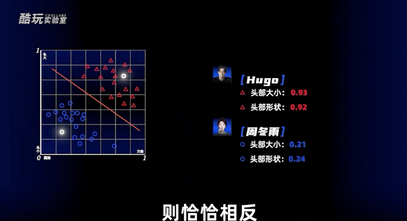
类似于看到一只猫,我知道它是猫,这对我来说是废话,问题是我不知道我是怎么判断的。那我猜想,肯定是眼睛看到猫的一瞬间,采集了大量的信息点,比如它的大小,它的花色,它的脸型,它的尾巴长度等等等等,然后我的大脑经过一瞬间综合考虑,觉得它是个猫。
那只要这些信息点,都是具体的可以衡量的类似大小,色号这类可数据化的参数,就可以转化为计算机的输入信号,而这个调权重加总的过程就可以类比为我脑子里那一瞬间的综合考虑,最终作出一个它是不是猫的分类判断,输出一个0或者1的数。

说白了感知机就是对于人类神经细胞的一个模仿。
那具体是怎么操作的呢?
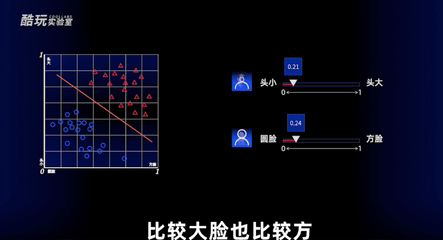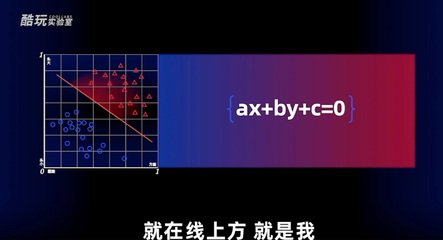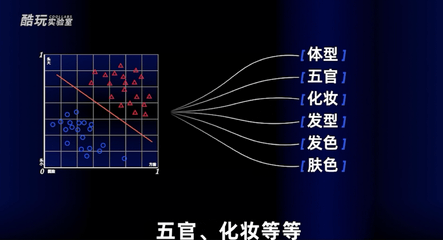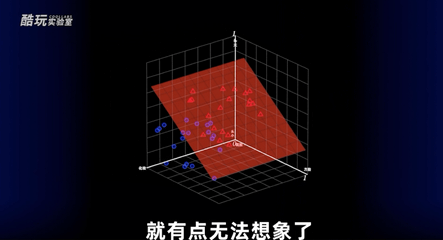
比如,我们看到一个人的照片,要判断一下它是不是我,那你足够细的话,完全可以找出一万个我这个人的特征。但为了便于讨论,让我们姑且通过脸方的程度、头大的程度两个指标用数字表示,让感知机去判断。
比如设定完全圆脸是0,脸方得跟我的世界里面人物一样是1;比如完全没有头是0,头跟大头儿子一样大是1。
分别把这两个输入当成平面坐标系的两个轴,找一些人的照片,记录他们是谁以及脸型、头的大小这些量化指标,放到坐标系里面。
那很显然,我们可以划一条线,把我跟类似周冬雨这样的人大概率地区分出来,因为我都头比较大脸也比较方,像周冬雨这样的女明星恰恰相反。
对于计算机而言,这条线就是ax+by+c=0。
如果加权求和出来的结果大于零就在线上方,就是我,如果小于零,就是周冬雨。
当然,现实当中我们不可能只用两个参数来判断这个人是谁,要做出更精确的判断还需要很多维度的输入,比如体型、五官、化妆等等。
引入化妆这个维度,坐标轴就变成三个,成为了一个三维空间坐标,那根一分为二的线也变成了一个平面。
继续引入第四个、五个输入的话就有点无法想象了,只能通过数学的形式来表现,叫做超平面,不过没有关系,这对电脑不是问题,它还是可以通过公式计算,把一个多维空间一分为二。
乍看起来有点弱智,但这个感知机的精髓就在于它不用我去告诉它该把线画在哪里,它可以通过所谓的“学习”来自己找到准确的画线位置,这就是它跟以往的所有机器或者工具不同的地方。
还是之前那个是我还是周冬雨的问题,在没有样本点输入的情况下,我可以先在平面上随便画一条线,然后规定这条线上方是我,下方是周冬雨。
但输入了实际的数据后发现直线上方居然出现了周冬雨的照片,比如她某些角度看起来脸比较方,那不行。于是我们就可以把这条线往上抬一点。再看一下所有点的分布,再进行判断,如果还不行再挪一下,再判断,以此类推,直到所有照片都能正确分类,感知机逐渐就精确了。

从计算机的操作来看,挪动直线这个动作就是调整输入权重abc的过程。
比如在这台感知机中,我们就可以计算分类错误的点到直线距离的和的函数,这个函数是跟权重参数也就是那个a、b或者c相关,叫做“损失函数”,越大说明错得越离谱。
就比如损失函数随着脸型对应的权重参数a的变化是这样的。

那有一种挪动的方法就是,假设现在权重在大写的A这个位置,我们每次就移动A点的导数乘以一个事先规定的值,这个值叫做步长,然后重复这个过程,直到所有照片都能够被正确分类,我就是我,周冬雨就是周冬雨。
因为是参考结果往前推导“输入的权重”,所以这个方法也叫做“反向传播”。
但是上世纪五六十年代,由于硬件算力的限制和网络结构的过于复杂,当时这种自我学习理论还无法实现,真正反向传播算法的提出还要等很久。
现在回过头来看,感知机毫无疑问是二十世纪乃至于人类历史上最伟大的发明之一,因为它终结了机器只能机械执行人类具体指令的时代,开启了机器会自己想办法完成主人任务的时代。
但是感知机的理论在当时却遭到了另一个人工智能大佬马文·明斯基的强烈反对,明斯基还特意写了一本叫做《感知机》的书来抨击罗森布拉特,认为他的研究没有什么价值。
当然明斯基有羡慕嫉妒恨的嫌疑,但他的攻击也算是有理有据:
他认为感知机的原理过于简单,无法解决一些问题,比如“异或逻辑”。
异或逻辑问题说起来很麻烦,但实际上就是,这个世界上并不是只有我和周冬雨这两种人啊,还有马云呢,马云脸比我还方但头没有我大,还有雷佳音呢,甚至于,还有姚明呢,姚明是真的很大而且很方啊。
很显然如果让感知机去画一条线,是没有办法把我跟这些个脸型和头的大小各异的人都分出来的。
现实是复杂的,是没法简单地一分为二的,明斯基指出了最关键的地方,这一波嘲讽效果拔群,导致以感知机为起点的人工智能研究停滞了大约30年。
上世纪7、80年代,随着信息技术的发展,大家逐渐发现,虽然单个感知机能力有限,但我再加两个感知机,等于多画两条线,不就行了吗?
只要感知机层数够多,无论多复杂的分类问题,不断用反向传播算法进行训练,就能得到最优解。
并且,我们需要注意到,解决了分类问题并不意味我们只能做分类,其实基于分类可以解决很多很多问题。
比如判断和分类,逻辑上就是一回事儿,
智能摄像头判断门口来的那个人是不是公司的同事,判断一个路过的人是不是某个新冠患者,就是分成是和不是两类呗。
在规则明确的情况下,对于接下来发生的事情进行预测,其实本质上也是分类,下棋的话分为这样下下去是会输还是会赢呗,扫地的话分成有没有扫过、会不会撞墙呗。
有了预测了之后,就可以进行决策了,扫地,下棋,推荐,甚至指挥调度,都可以了,简直无所不能啊。
所以,人工智能在上世纪80、90年代开始进入“多层感知机”时代,当时的人工智能在理论上已经非常强大,可以解决大量的问题。
但它还是受到两个关键因素的制约:
一个是系统的算力,也就是动辄几千万参数的反向传播算法需要巨量的算力;
另外一个是数据,也就是需要大量打好数据标签的类似我的照片周冬雨照片这样的东西作为人工智能学习的资料。
搞定了这两项关键资源人工智能才能真正上路!
从1965直到2016年以前,芯片算力都在随着摩尔定律呈几何倍数增长,而最近20年互联网产业蓬勃发展也带来了数据量的爆炸式增长,人工智能的发展有了肥沃的土壤。
另外,科学家也开发了一系列的方法去处理这两个问题。
深度神经网络,卷积神经网络,蒙特卡洛树等等都是试图用更小的算力处理更复杂的问题。
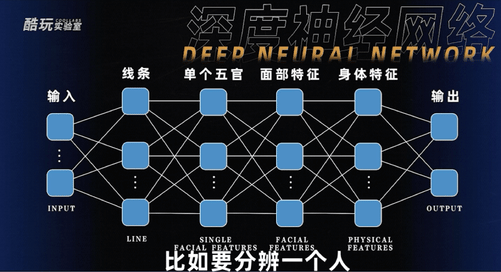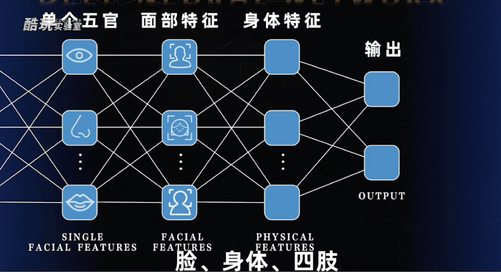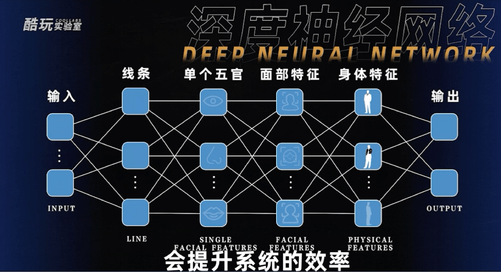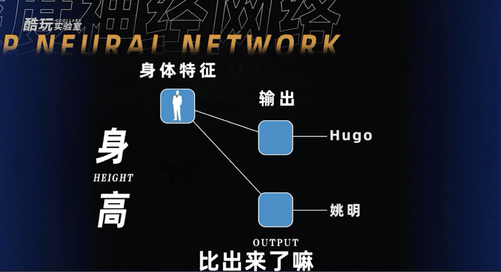
比如深度神经网络,就是把我们能提取到的信息点,根据不同的维度,分成更多的层,比如要分辨一个人,从单个五官,眼睛鼻子嘴各有各的特色,五官又组成了一张脸,脸、身体、四肢又组成了一个人,我们把这些特征分成不同的层不要混在一起计算,会提升系统的效率。就比如为了把我跟姚明区别出来,如果把何种参数混在同一层计算有可能你会发现我跟姚明还挺像,但只要把代表体型的那些参数单独拎出来,那就一点也不像了。
再比如所谓卷积神经网络。卷积计算是一种可以从矩阵中提取某些特征值的运算,我当年上大学的时候对这玩意儿印象很深刻因为它手算起来特别麻烦,到底是哪个傻x发明了这种东西那么无聊,后来发现它还真挺有用。
就比如我们按照片去分辨两个人,那首先我们比较的是两个人吧?你人工智能分析半天在比较后面的背景那算力就完全打了水漂了。同理我们智能停车场识别车牌号得先找到车牌在哪里吧?智能商场识别顾客得先找到人在哪里吧?这是一项我们人类天生就有的能力,找重点的能力。
那如何让计算机也拥有找重点的能力呢?我们就可以引入一个所谓卷积核,一般是个3*3、5*5、7*7像素的矩阵,用它从头到尾扫描图像,把图像和卷积核对应像素点的数值相乘再求和输出,就能得到一张提取了某种特征的更小的图像。然后再基于这些特征,去判断哪些部分是重点,哪些部分是边角料。
在2012年的ImageNet大规模视觉识别挑战赛上,一个叫做AlexNet的深度卷积神经网络在对1000种物体进行分类的比赛中获得了第一名的成绩,错误率仅为15.3%,比第二名低了大约11%之多,基于卷积神经网络的机器学习算法一战成名。
这是人工智能发展历史上的里程碑事件,卷积神经网络是一种通用的提升算力利用效率的技术,它现在基本上是人工智能的标配了。
而所谓蒙特卡洛树搜索,也是一种判断哪里是重点哪里是边角料的方法,当年跟李世石对弈的那个alpha go的算法就是基于蒙特卡洛树,而李世石第四局下出所谓神之一手,其实就是下到边角料上了,边角料是神经网络的数据盲区,于是它就乱了套了。

另一方面,人工智能目前最大的发展瓶颈还是来自于数据,目前相关产业的发展速度基本上就等同于获取大数据的难易程度,比如智能推荐内容,智能推荐商品这些容易获取数据的项目现在就特别的成功,像自动驾驶这种就会比较慢一点。
有一些方法可以人工的去创造数据来喂养神经网络。
就比如所谓强化学习,就是脱离人类数据样本,基于环境和规则自己生成数据往下算。下国际象棋就是它有明确的规则,最终的目标就是吃了对面的王,基于这一点去预测接下来最合适的策略,再通过得到的结果和预测值进行比较,优化自身参数,于是就不用输入太多人类的棋谱了。
在国际象棋中,人类顶尖高手可以预测接下来10步的行动。1997年,当时的IBM研发了一个用来下国际象棋的AI,叫做“深蓝”,
深蓝可以预测12步,每一步都遍历了可能发生的所有情况,相当于用强大的算力进行了12步的暴力穷举,击败了当时等级分排名世界第一的加里·卡斯帕罗夫。
当然这个暴力穷举的方法在目前的算力下,对特别复杂的问题比如围棋、星际争霸会相对无力一点。
然后还有多智能体,就是搞两个或者以上的AI,让它们自己打自己,卷起来。
结合强化学习和多智能体学习,有时候我们会发现,其实很多人类的经验并不靠谱,还不如让AI自己去算然后自己打自己,就比如Alpha Zero的围棋棋力就完爆学习了人类棋谱的Alpha Go。
还有一个特别有意思的方法叫做GAN,所谓对抗生成网络。如果说之前的AI主要干的事儿是判断和决策,在2014年被发展出来的GAN网络则赋予AI比较强的创作能力。
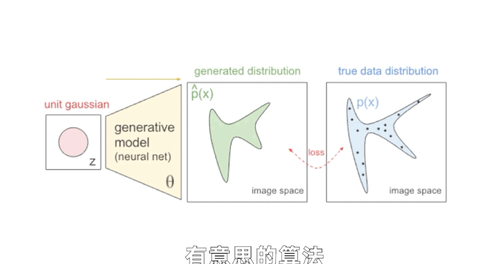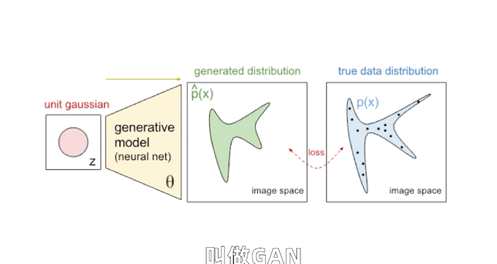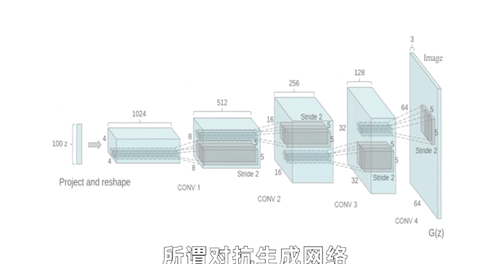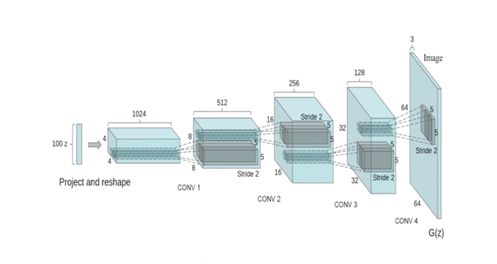

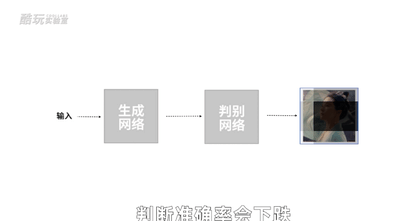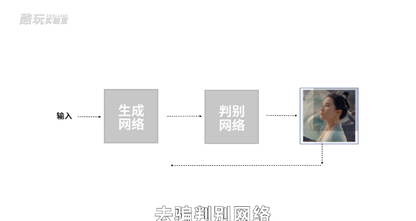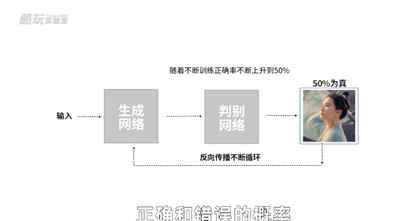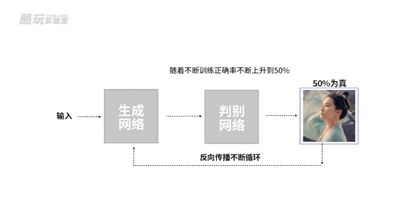
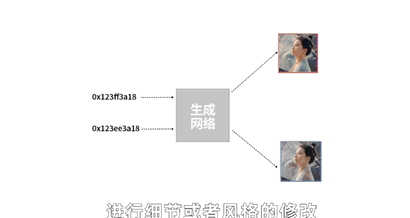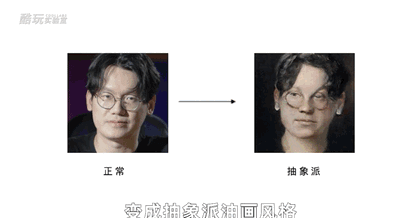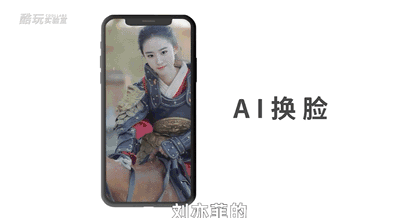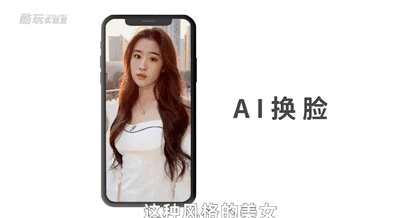
刚才我们不是说可以做一个AI判别网络,去对一类东西进行判断分类吗,还可以搞个多智能体,让几个AI自己卷自己比谁判断的准对吧。那我们可不可以换一个思路,让判别网络去卷一个所谓的生成网络呢?
就比如这样,我做一个画图的生成网络,先给生成网络输入一些随机参数,生成网络就会生成一些初始图片,有点类似于玩游戏通过数据捏脸的过程,只不过一开始生成网络还很懵懂,生成的东西都是四不像。
然后把我们已有的美女照片和生成的四不像照片都做好标记,用这两类带标记的图像去训练判别网络的参数,让它自己学习怎么画线,能把美女的图片和乱画的图片分出来。

接下来,生成网络可以根据判别网络给出的结果差距来学习提升,它画出来的美女就越来越像那么回事儿了。
于是判别网络的判断准确率会下跌,逼得它去提升判别能力,它又逼着生成网络生成更逼真的照片去骗判别网络,不断循环,卷起来。
到最后判别网络分不出来了,它判断成功概率会稳定在50%,这时候我们说生成网络已经做到了“以假乱真”。
生成网络就像是热血动漫吊车尾的男主角,判别网络就像是自带外挂的天才男二,随着剧情的发展,男主最终能和男二五五开了。
我们甚至还能通过调节生成网络的输入参数,来对赝品画作的细节或者风格进行修改。
比如把画面中的普通马变成斑马;或者把我的照片变成抽象派油画风格甚至梵高莫奈的风格,以及我们喜闻乐见的ai换脸。也就是我们既可以生成刘亦菲的各种角度各种表情,也可以把条件放宽一点,生成刘亦菲这种风格的美女。
而且这个创作能力并不仅限于画图哦,写文章,写诗,写剧本,作曲,做动画都是可以的。
07
到了这一步之后,我们再来看下AI它的能力是怎么回事,它既可以做判断,做决策,也可以做创作,那这些正是元宇宙所需要的呀!
之前我们在第一期节目当中说过,在传统的PC互联网和移动互联网当中,其实我们的世界是被降维打击过的。无论是生活中去商店里购物,去跟人聊天吹水,去剧院看戏去茶馆听书,所有这些3D场景都被压缩成了一张2D网页或者App页面,以适应这块屏幕,坏处是没有代入感临场感,好处是实现起来比较简单。
而在元宇宙里面,他们将会实现三维展开,对应的工作量也会提升一个维度。
就拿我们最常用的三类app为例,社交:也就是微信,soul;电商:某宝,某东,某多多;以及短视频;
在元宇宙里面的社交,咱俩在虚拟世界里面,面对面聊天,这相对于在一个对话框里面打字那种社交,是颠覆性的。因为说白了包括我在内,很多比较内向的人,是根本没法跟一个不熟的人微信打字的,你不知道ta的背景ta的爱好,都不知道开什么话题啊。
但是只要见了面坐在一起那还是可以尬聊的,尬着尬着就发现,诶好像大家都对最近曼城踢利物浦的巅峰对决很敢兴趣,或者大家都对新出的蝙蝠侠很感兴趣,这就聊起来了呀,甚至可以开个电影边看边聊。
但前提是,我得有一个我的形象吧?而且得是一个放在元宇宙场景里面并不违和的比较精细的,就好像老黄发布会那样的虚拟形象吧?你也得有一个你的形象吧?
如果是正式场合商务会谈的话,我可能就得用一个跟我现实中的形象比较接近的顶多稍微美颜一下的形象,在家里就没必要那么正式了,喜欢什么形象都可以,比如可以是蝙蝠侠,在一些别的场景下,比如一起去打仗,那我就可以是一个巨型机器人。所以每个人需要好几个不同的形象吧。
那像这样的比较精细的人物模型都是画图师用Zbrush Blender扣几个月才能扣出来的,而且很贵,便宜的也要几万,那些精致的虚拟网红比如柳夜熙那是花上百万打造出来的,就连好一点的游戏捏脸师傅都要大几千。假如十年之后全球有20亿人登陆元宇宙,平均每人要有十个形象。
那这两百亿的形象怎么做啊?
再说元宇宙里面的电商,那真的是一家店,它不是一个页面哦,而且比如我要用我的虚拟人在元宇宙里面试一双鞋,大致试一试肯定是没有意义的,因为我得靠这个决定要不要买啊。像现在得物的那个AR试鞋功能那样是没有卵用的,那是什么玩意儿,我本来看着一双鞋觉得挺好的,用那个一试就不想买了。所以不是随便试一试那么简单,我这个虚拟人的脚的尺码、脚的受力结构得是跟现实中的我的脚一样的,同理鞋也要一样,这样才能试出合不合脚好不好看。
那这么多深度的数字孪生人和商品,谁来做啊?
再比如说短视频。现在的移动互联网时代,我们这种短视频用户主要优点就是勤奋好学,学穿搭、学瑜伽、学化妆、特别是喜欢学跳舞。我想人性的这个需求应该不会随着平台的变迁而发生太大的变化。
那元宇宙里面怎么学跳舞呢?其实就是你坐那儿然后那个dancer在你边上跳呗,然后你可以语音交互“换一个”,然后就换了。这不仅是人要换哦,跳舞那个场景是不是也要换啊,什么场景里面的摆设,场景里的猫猫狗狗也要换啊。我们每天刷那么多短视频,那么多场景,那么多摆设,那么多猫猫狗狗怎么做啊?
只能靠AI,元宇宙里面的这些高级基础设施只能靠AI才能完成啊。
08
然后就是,当我们在元宇宙里面有了非常精细的3D形象之后,当像商店,咖啡厅,游乐场这些场景都实现了三维展开之后,那这些地方的服务人员、NPC他们得像人才行吧?如果人的形象非常真实场景也无比自然,你凑上去跟一个美女打招呼结果她头上突然弹出一个对话框,这就太出戏了。

所以在元宇宙里面我们需要非常像人的AI来提供各种服务。
而这些都正在发生。
比如这个“此物不存在”网页当中,这些猫,这些房间,这些人像,你打开这个网页就好像在看一些人的自拍照,唯一的区别是这些人是AI生成的,他们并不存在于我们的世界。
当2D的人物、场景和物件的生成可以被完美实现的时候,其实3D也就不远了,比如这个PIFuHD算法 ,可以直接从2D图片生成真人的3D模型,并自动补全背面的信息。
但这还不够,到这一步你得到的小姐姐也只是个雕塑而已,得让她动起来呀。于是,就有了I2L-MeshNet,可以从2D图像生成人物动作相关的骨骼和3D建模,导入动作参数,于是小姐姐就真正来到了你的身边。
这还不是终点,因为我们的元宇宙虚拟小姐姐还得多才多艺,更要会互动才行,也就是要实现类似失控玩家里面的效果。
有几个朋友在做一个项目叫做RCT-AI,是一个北京的团队,他们在做一个事情就是用AI去自动生成游戏里面的人物脚本,比如这个“抢银行”的Demo。AI会学习自行判断的如何配合玩家,有时会很怂,有时则会跟劫匪硬刚到底。
配合玩家?如果换一个场景,训练一个女仆或管家型的AI是不是变得可行了呢?
实际上,在服务型AI方面,OpenAI公司的GPT-3,现在不仅可以和人聊天,甚至还能按照人的要求写代码。
也就是若干年以后当我们在元宇宙里面创作的时候,我们大概率扮演的是一个导演或者宏观设计师的角色,那些具体的工作将由AI完成。
而今天的动画游戏作品中,与一个纸片人小姐姐、小哥哥交往,你还需要脑补,但当你明白今天AI的发展程度,就会发现,你所幻想的一切独一无二的美好,正在通过一行行代码,走近现实。
这就是为什么AI毫无疑问是支撑元宇宙的基础设施之一,如果没有AI去辅助人类制造各种数字产品以及担当NPC,元宇宙的应用场景,元宇宙的丰富程度势必受到严重的限制。3D区不能没有蒂法,也不能只有蒂法。
而且我认为更有意思的是,元宇宙也会成为AI起飞的重要推力。
刚才我们有讲到,AI是需要大量数据去喂养的,现在AI产业发展遇到的最大障碍就是,容易获得大数据领域实在是太有限了,那些不容易获得大数据的领域即便有巨大的需求也会发展缓慢,比如自动驾驶汽车。
我们固然可以用计算机模拟去训练自动驾驶算法,但这里面缺乏一个关键的因素,那就是人。就算我们可以完美的模拟路况和车况,路上别的司机行人的各种奇葩举动怎么模拟啊?
而元宇宙不仅能提供更大的数据量,更关键的是它是有大量人类生活在其中的3D虚拟世界。在这样的一个世界AI的应用场景会被大大拓宽,然后现实世界当中的AI产品就可以用元宇宙版本先跑到80分,再去现实中进一步发展。
就比如大家知道我们在3D电影和游戏当中用到的人物表情是个很难做的东西,要做到鲜活真实,就得做真人表情采集,就得找演员用专业设备专业团队,否则就会很假。
而到了元宇宙里面,我们天然就有用虚拟人去呈现自己的表情去嬉笑怒骂的需求啊,在之前的节目中我们说过,facebook的下一代VR一体机设备Project Cambria有内置的表情传感器,于是乎facebook将获取所用用户表情的大数据。
在这里我可以下一个判断,在Project Cambria发售一年之内,AI虚拟人表情假这个问题将会被彻底的解决。
再比如刚才说的自动驾驶,在元宇宙里面我们可以举办公路拉力赛,把场地设定在北京城,然后观众可以走到赛道上,可以往赛道上扔东西,甚至可以把自己家的车开上赛道,这个场景下训练出的自动驾驶AI应对突发状况的能力绝对炸裂。
我之前跟一个做自动驾驶的朋友提过一个广告营销的策划,就是你别像马斯克那样整天推特上说自己的AI出事故概率是人类的五分之一十分之一,这没用,大家不会信的。你干脆拍一条广告,在一个漆黑的雨夜,主角的豪华轿车缓缓驶入一大片阴森的城区,这时候暗中埋伏的几辆车突然亮起车灯,敌人要开车撞死他进入一段追车戏。
但是撞了半天发现主角的控车技术太灵活,根本就撞不到,只能眼睁睁看着他突围而出。最后主角的车行驶到阳光灿烂的开阔公路上,镜头拉近发现驾驶座上竟然没有人。这时候屏幕中间出现他们公司的logo。
如果自动驾驶AI能做到这样,那用户自然会明白,我们安心玩手机就可以了,开车不是我们该管的事儿。
再比如其实很多人都很想要那种非常接近人类能帮我们干各种活的通用型AI机器人,就好像银翼杀手里面的高司令那样,但是在现实当中这种机器人不仅受到智能水平限制,还受到硬件水平的限制,说白了就是它的身体也实现得不好,波士顿动力花了30年才让机器人能像人一样走路。
在元宇宙里面就没有这个限制了,机器人只需要一个模型和一些代码就能行动自如,到时候再把训练好的AI导出来装在现实中的机械躯体上,人与机器的界限就彻底模糊了。
元宇宙作为下一代互联网,人类信息技术手段的集大成者,传播与生成的数据势必呈指数级增长,AI也将受益于这样的数据海洋,进化速度远非今天可比。
我经常听到一种说法,就是人工智能它只能做一些机械式的操作,而人的想象力创造力是人工智能无法取代的。
听完我刚才的分析大家也能看出来,这个说法是完全错误的。
10
事实上无论是扫地拧螺丝这种机械式的劳动,还是下棋打游戏这种竞技运动,亦或是画画谱曲这种创造性工作,充分发展之后的人工智能干什么都会比人类干得好,而且是多快好省,全方位的优势。
如果说我们做事情的套路是先形成欲望,然后在我们所掌握的能力或者资源范围当中去寻找满足这种欲望的方法,最终形成决策,向前推进。
人工智能缺少的不是任何的能力或者方法,它缺的是左边这块,欲望。
也就是说AI无法成为最终的决策者,它提供的只是达成目的的执行力,或者说他只是个工具人,这才是人与AI的根本区别所在。AI做的任何事情背后都必然有人的推动,哪一天AI真的杀了人,你最终肯定能找到一个幕后的始作俑者。
AI会带来生产力的碾压,在AI近乎无限复制的生产力面前,我们现在的那些自动控制技术,什么996007压榨工人的操作,都会变成毛毛雨。
AI会带来战斗力的碾压,在遮天蔽日的智能无人机蜂群面前,再强大的人类飞行员都会成为小可爱。
AI会使得人类变得更加自由,因为它会放大每一个人的能力。同时它也会使怎个社会的价值创造向头部集中,就是当高端玩家的决策能力被AI无限放大的时候,当你们单位联欢会都能找张艺谋来导演的时候,低端玩家就找不到活儿干了。这也是很多人在提全民基本所得背后根本性的原因,因为对于绝大多数人我们目前理解的那种劳动价值将会不复存在。
人工智能的发展提速无法阻挡,必然会对社会造成冲击,而真正重要的是谁能控制人工智能产业。
就像当年的工业革命,我们现在活着的几乎每一个人都因为工业革命而过得更好了,但在它展开的过程当中,有些人借着风口扶摇直上,另一些人则成了发展的垫脚石,甚至有些民族直接没了,作为学习过中国近代史的中国人,我相信大家都明白这是什么意思。
这就是为什么AI产业是我们必须要尽全力掌握和领先的领域,而这确实也是我们的国策。在十四五规划当中出现最多次的专业术语,就是人工智能,如果我没记错的话,出现了18次。
而在那之后会发生什么,就看我们是否能够砥砺前行不忘初心了。
本文来自微信公众号“酷玩实验室”(ID:coollabs),作者:酷玩实验室,36氪经授权发布。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK