

后端接入层技术的一些思考 - 三国梦回
source link: https://www.cnblogs.com/grey-wolf/p/16437897.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
后端接入层技术的一些思考#
前言#
网上技术文章已经泛滥了,部分写得非常好,看着看着,就觉得自己太菜,感觉也没有下笔的必要了。但是,写文章也是一个梳理自身思路的一个过程,用输出倒逼输入,一直都是挺不错的学习方法,不然网上文章看完就不记得是马什么梅了,因此,还是决定写写自己对于这块技术的一些思考。
接入层,没找到具体的定义,按我的理解,就是位于防火墙之后,承接前端用户请求(通过浏览器或者app等)的最前沿的服务器集群,一般会和用户正向代理软件(浏览器、app之类)直接建立网络连接,负责接收用户请求,转发到逻辑层服务处理,再将逻辑层响应返回给用户。当然,这只是最初级的场景,因为接入层实际是流量入口,所以它可以做很多流量调度的事情,举个例子,大家如果去过都江堰,就会看到江的中间,有一段沙洲,这片沙洲就能将奔流的岷江水分流,分流后,水流就不至于在暴雨时节对下游造成洪涝灾害。
“鱼嘴”是都江堰的分水工程,因其形如鱼嘴而得名,位于岷江江心,把岷江分成内外二江。西边叫外江,俗称“金马河”,是岷江正流,主要用于排洪;东边沿山脚的叫内江,是人工引水渠道,主要用于灌溉。
而且这也才是第一道分水工程,我查了下都江堰的排沙工程,又被秀到了,竟然暗合了软件架构中的限流熔断思想,当初去都江堰还是应该找个导游,现在觉得真是看了个寂寞。
飞沙堰的作用主要是当内江的水量超过宝瓶口流量上限时,多余的水便从飞沙堰自行溢出;如遇特大洪水的非常情况,它还会自行溃堤,让大量江水回归岷江正流。
什么叫“水旱从人,不知饥馑”,这就是。
说回正题,接入层就是个流量口子,我们可以根据我们的想法,自由地分发流量给后端的服务集群(负载均衡),当流量过大时,可以限流熔断,同时,可以进行认证鉴权,打击灰产,日志记录,监控上报,灰度发布等各类功能。
接下来,会说一下典型的架构。
单idc架构(无长连接)#
大部分中小型公司,如果就是提供一个网站对外访问,也不需要接收后端通知的话(如实时IM通信),可能都会是这类架构,我任职过的公司里,也有这类架构。下图就以我熟悉的nginx来作为接入层组件了,lvs也可以,个人研究不多,就先算了。
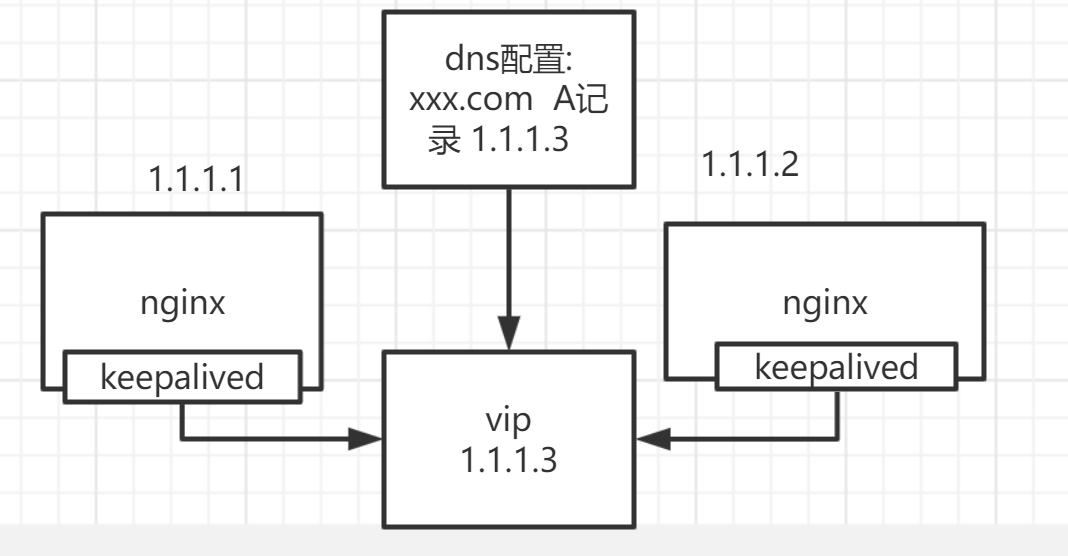
这个架构主要的问题在于,接入服务都在单个机房,一旦这个机房挂了或者这个vip出了问题,服务基本就不可用了。
同城多idc架构(无长连接)#
解决的办法,就是多机房容灾,包括了同城多个机房(一个城市里多个机房)、两地多中心(两个城市,多个机房)、三地多中心(三个城市,多个机房);再根据机房是否多活(多个机房可以同时处理用户请求,即每个机房都有流量),分为了:同城多活、异地多活(异地多活就是异地的多个城市,如深圳、上海,都可以同时处理流量,这时候基本要上单元化架构了)
中小公司,我个人觉得,同城多活基本也就足够了,基本就是下面这个样子。
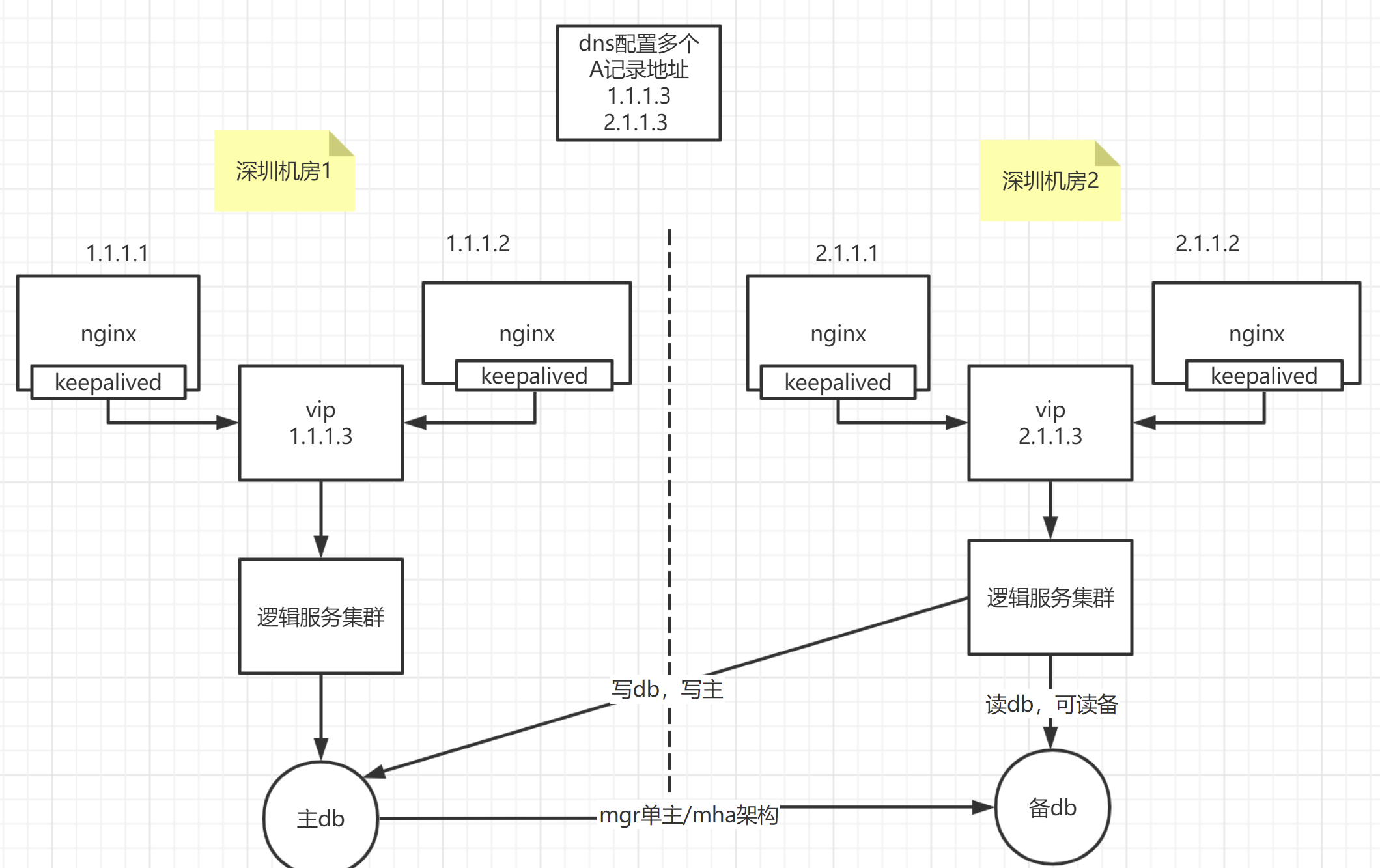
单idc架构(有长连接场景)#
短连接:tcp建立连接,传输完数据后,马上关闭连接。下次要传数据时,再来一次三次握手--传数据--四次挥手。
长连接:tcp建立连接,传输完数据后,不关闭连接,下次要传数据时,找到前面没关的长连接,直接传数据,传完也不关闭。
长连接一般适用于,后端需要主动通知用户的场景,当然了,也不是说,这种时候就必须要用长连接,客户端轮询、长轮询也是可以实现这种场景的,但这里我们只说长连接这种实现方式。
这种方式的好处在于,非常实时,要的就是一个快,后端只要需要给我发消息,我马上能收到。
对于这块的架构,我个人目前倾向于如下设计:
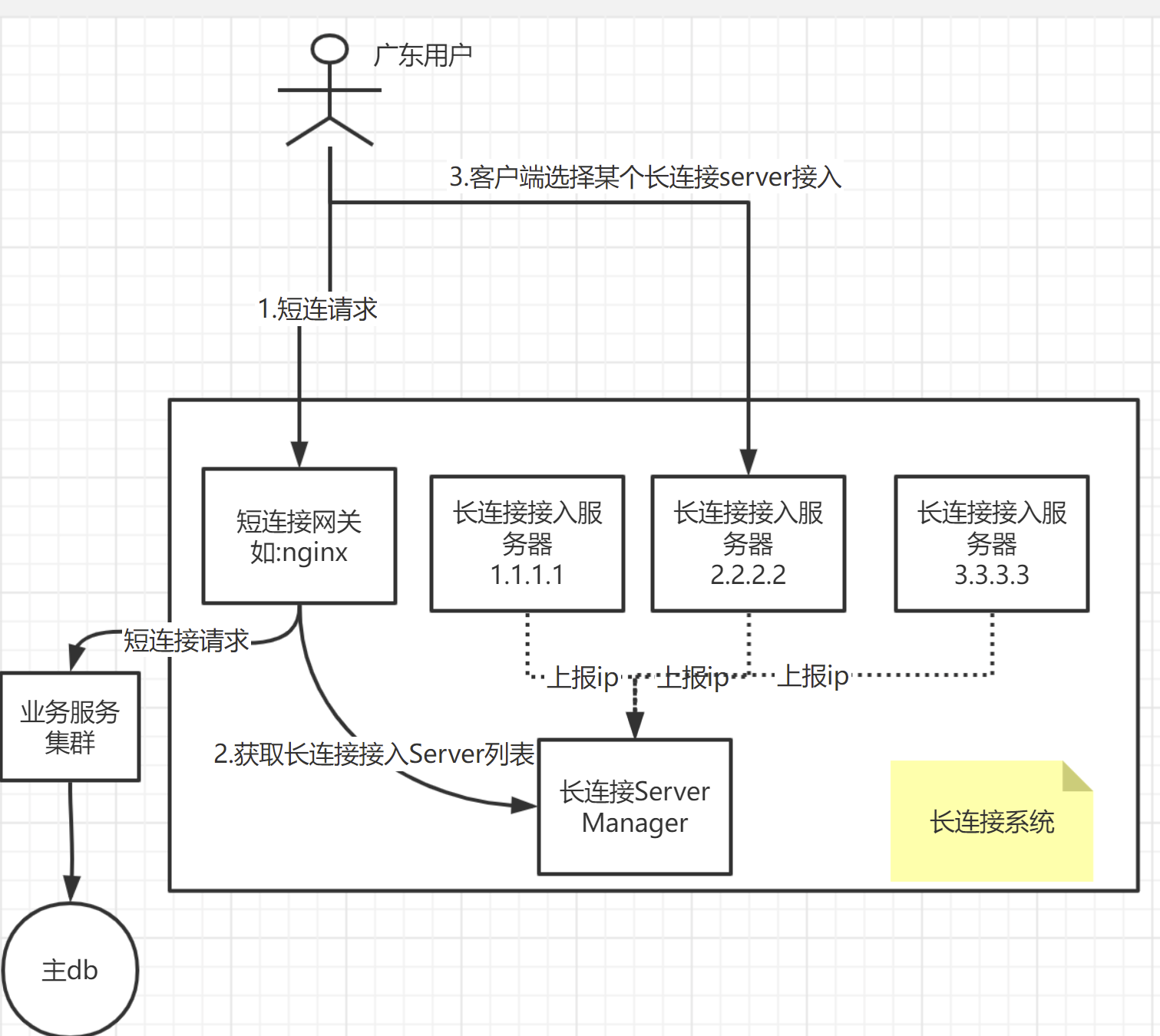
即,用户在准备进行长连接时,首要的事情就是,拿到要接入的长连接服务器的ip+端口,要拿到这个ip+端口,有很多方式,像我图里画的,就是这样一种模式:
- client端,首先调用短连接网关,短连接网关可能首先对用户鉴权,提示登陆等;登陆成功后,client端调用短连接网关,请求获取长连接服务器的"ip+端口"列表。当然,这里为了简单,你可以直接写死成一个配置,但是,我们建议灵活一点,提取一个单独的服务(如上图的长连接server manager),对外提供对应的获取长连接服务器列表的接口。
- client端,拿到长连接服务器列表后,接下来要做的就是选择其中的一个。这块就可以有很多策略了,比如,可以ping一下每个ip,看看延迟,可以选择延迟最低的;或者是根据业务逻辑,自己实现一个策略。
- client拿到想要连接的ip+端口后,进行tcp 连接即可;对应的长连接服务器,收到client连接请求后,就会在内存或者redis之类的,维护一个map,key:用户id/终端id,value:长连接对象。同时,可以上报一些统计数据给长连接server manager,如当前服务器1.1.1.1维护了2000个用户的长连接,届时,长连接server manager就可以根据这些统计数据,来提示client可以连接某个负载比较小的服务器(这块的策略也可以自由实现,比如帮client端推荐一个长连接服务器、强制客户端使用某台服务器等)
这里还有一点,客户端现在是通过调用如上方式,获取长连接服务器;但要是这个链路有问题呢,这时候可以有对应的降级机制,比如使用dns域名方式来获取,或者是使用客户端中写死的一批ip。
服务端如何主动做推送呢?这里不打算展开了,比如要给用户xxx发消息,那此时,有两种方式,一种是,想办法查询到,xxx在哪台接入服务器上;另一种是,给每台接入服务器发请求,类似于广播,接入服务器收到这种广播请求后,检查对应的用户归不归自己管,不归的话,就不管。
多idc架构(有长连接场景)#
这个架构还有啥问题吗?大家可以看到,图里是位于深圳机房的,服务于广东用户,估计延迟还好,要是服务北京用户,北京用户通过长连接,连到深圳,深圳这边推送消息时,走公网推送给用户,这个延迟肯定低不了。有啥好办法吗,我觉得,可以采用多机房,就近接入的方式。
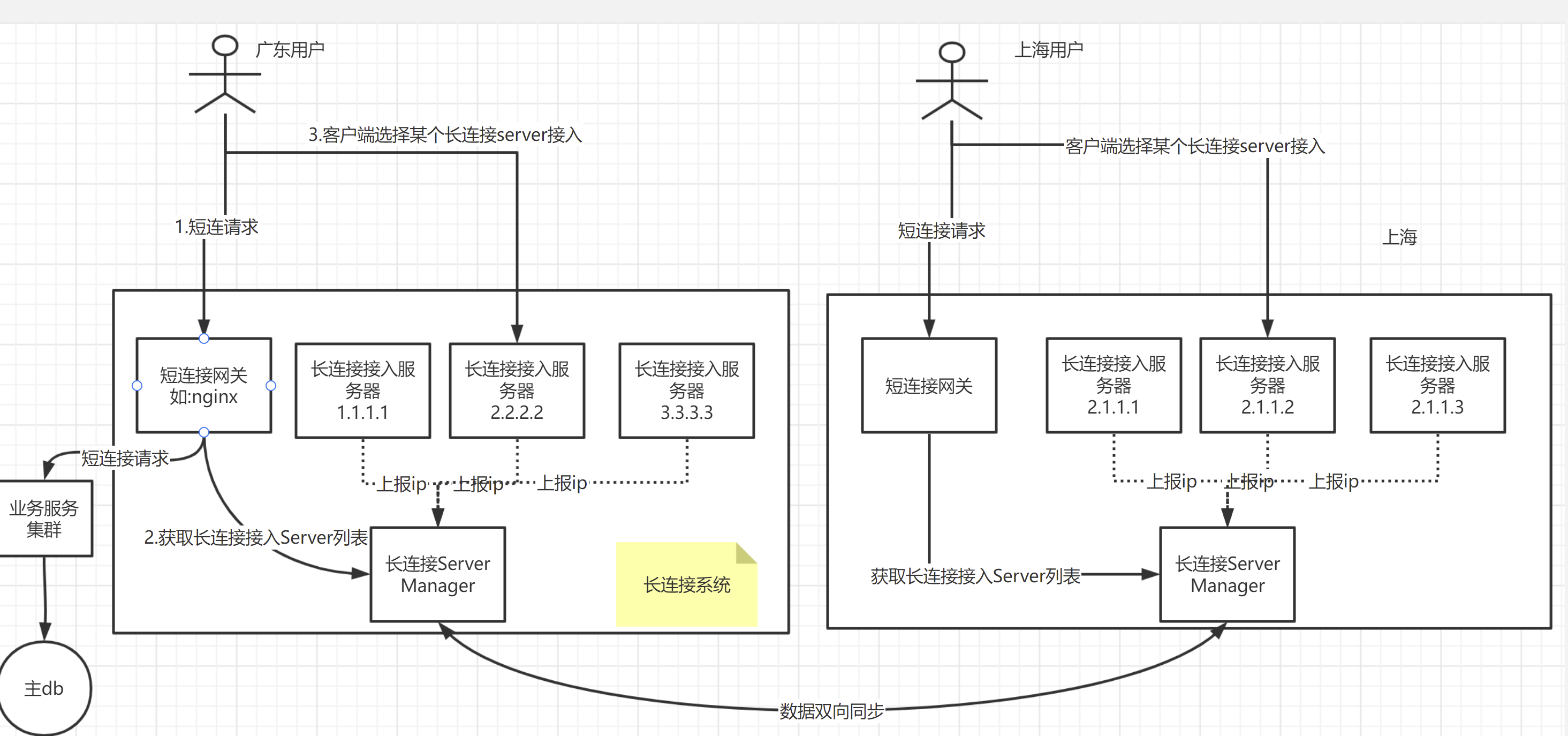
比如,深圳、上海各一个机房,北京用户接入上海机房,物理上就近多了,自然要快一些。这个场景下,流程是如何的呢?
- 用户通过dns(配置多条A记录,指向上海、深圳机房的短连接网关地址),理论上,可以获取到就近的机房的地址;如广东用户应该会取到深圳机房地址,北京用户会取到上海机房的地址。如果不行的话,我们还有其他办法,如gslb,后面讲。
- 此时,假设没有部署异地多活,上海机房只负责了接入层,没部署业务层的服务和db等;此时,深圳侧的业务服务发起消息推送,推给北京某个用户,此时是可以通过长连接Server Manager,查到用户在上海接入;那就把这个推送请求,发给上海这边的接入服务器。因为大公司的机房之间,路线一般是有专网,或者是花了不少钱的,速度肯定比公网要快一些。比如,腾讯的深圳上海机房的延迟,基本就是几十ms。
这边有一个点是,深圳、上海的长连接Server Manager进行了双向同步。不双向同步,感觉也是可以的,我们可以根据用户的登陆ip,查询ip属于哪个省,如果是北京,则认为该用户在上海机房接入了,则交给上海机房去推送即可。
gslb技术#
我们上面提到,深圳、上海各一个机房,此时,dns要配两条A记录地址,指向各机房。同时,我们假设了,dns解析商那边,会把北京用户解析到上海机房。
但这个假设,不一定生效,dns解析商那边的解析还是比较粗糙的,如果我们希望把这块掌握在自己手里,那就可以使用gslb技术(global server load balance)。
有一种简单的实现方式,简单来说,就是dns解析那里,配置两条ns记录,ns记录分别指向深圳、上海机房的自研的dns服务器。自研的dns服务器,就可以用我们自定义的规则,来决定这次dns解析,给用户返回什么地址。自研dns,可以这样做,比如查询用户属于电信还是网通,属于哪个省,来决定返回深圳、还是上海的机房地址。

Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK