

简述机器学习中的特征工程 - 叶小小`
source link: https://www.cnblogs.com/yj179101536/p/16427796.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
何为特征工程?
特征工程是利用数据领域的相关知识来创建能够使机器学习算法达到最佳性能的特征的过程,用一系列工程化的方式从原始数据中筛选出更好的数据特征,以提升模型的训练效果。业内有一句广为流传的话是:数据和特征决定了机器学习的上限,而模型和算法是在逼近这个上限而已。由此可见,好的数据和特征是模型和算法发挥更大的作用的前提。特征工程通常包括数据预处理、特征选择、降维等环节。
特征工程的重要性
- 特征越好,灵活性越强
- 特征越好,构建的模型越简单
- 特征越好,模型的性能越出色
一、数据预处理
数据预处理是特征工程中最为重要的一个环节,良好的数据预处理可以使模型的训练达到事半功倍的效果。数据预处理旨在通过数据清洗、归一化、标准化、正则化等方式改进不完整、不一致、无法直接使用的数据。具体方法有:
-
去除唯一属性
唯一属性通常是一些id属性,这些属性并不能刻画样本自身的分布规律,所以简单地删除这些属性即可。
-
处理缺失值
1. 删除数据:根据缺失情况,按行删除或者按列删除
2.度量填补缺失值:可以根据数据属性,采用均值、中位数、众数等中心度量值来填补缺失数据(字符串类型数据一般采用众数处理方式)
3.预测填补缺失值:可以将缺失属性作为因变量,建立分类或回归模型,对缺失值进行建模填补
归一化是对数据集进行区间缩放,缩放到[0,1]的区间内,把有单位的数据转化为没有单位的数据,即统一数据的衡量标准,消除单位的影响。这样方便了数据的处理,使数据处理更加快速、
敏捷。Skearn中最常用的归一化的方法是:MinMaxScaler。此外还有对数函数转换(log),反余切转换等。
标准化是在不改变原数据分布的前提下,将数据按比例缩放,使之落入一个限定的区间,使数据之间具有可比性。但当个体特征太过或明显不遵从高斯正态分布时,标准化表现的效果会比较差。标准化的目的是为了方便数据的下一步处理,比如:进行的数据缩放等变换。常用的标准化方法有z-score标准化、StandardScaler标准化等。
离散化是把连续型的数值型特征分段,每一段内的数据都可以当做成一个新的特征。具体又可分为等步长方式离散化和等频率的方式离散化,等步长的方式比较简单,等频率的方式更加精准,会跟数据分布有很大的关系。 代码层面,可以用pandas中的cut方法进行切分。总之,离散化的特征能够提高模型的运行速度以及准确率。
特征的二值化处理是将数值型数据输出为布尔类型。其核心在于设定一个阈值,当样本书籍大于该阈值时,输出为1,小于等于该阈值时输出为0。我们通常使用preproccessing库的Binarizer类对数据进行二值化处理。
-
哑编码
我们针对类别型的特征,通常采用哑编码(One_Hot Encodin)的方式。所谓的哑编码,直观的讲就是用N个维度来对N个类别进行编码,并且对于每个类别,只有一个维度有效,记作数字1 ;其它维度均记作数字0。但有时使用哑编码的方式,可能会造成维度的灾难,所以通常我们在做哑编码之前,会先对特征进行Hash处理,把每个维度的特征编码成词向量。
以上介绍了几种较为常见、通用的数据预处理方式,但只是浩大特征工程中的冰山一角。往往很多特征工程的方法需要我们在项目中不断去总结积累比如:针对缺失值的处理,在不同的数据集中,用均值填充、中位数填充、前后值填充的效果是不一样的;对于类别型的变量,有时我们不需要对全部的数据都进行哑编码处理;对于时间型的变量有时我们有时会把它当作是离散值,有时会当成连续值处理等。所以很多情况下,我们要根据实际问题,进行不同的数据预处理。
二、特征选择
不同的特征对模型的影响程度不同,我们要自动地选择出对问题重要的一些特征,移除与问题相关性不是很大的特征,这个过程就叫做特征选择。特征的选择在特征工程中十分重要,往往可以直接决定最后模型训练效果的好坏。常用的特征选择方法有:过滤式(filter)、包裹式(wrapper)、嵌入式(embedding)等。
1 . 过滤方法(Filter approaches)
过滤方法,也被称为分类器独立的方法。它独立于任何归纳算法,基于距离、信息、依赖性和一致性四种不同的评价标准进行评价,利用数据的内在特征对特征进行评价和排序,根据训练数据的共同特征来选择合适的特征,而不涉及任何特定的学习器。
基于滤波器的方法可以分为单变量方法和多变量方法。在单变量中,特征的重要性是单独计算的,而忽略了特征之间的关系,而在多变量中,将考虑特征的相互作用和依赖关系。其优点是速度快、计算简单、经济,更适合于解决高维数据集问题。
最流行的为特征相关性进行评分的标准之一是皮尔逊相关系数,计算公式为:
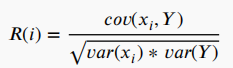
其中,为第i个特征,𝑌为类标签,𝑐𝑜𝑣()为协方差,𝑣𝑎𝑟()为方差。该准则只能检测变量与目标之间的线性依赖关系。
2 . 嵌入式方法(Embedded methods)
指那些直接将特征选择作为分类算法优化目标的方法,寻求在学习算法中加入特征选择能力,即在训练和建立归纳模型的过程中进行特征选择。计算成本较低,也不太容易发生过拟合。如使用分类器的权重进行特征排序,权重定义为:
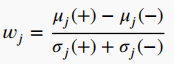
其中和𝜎𝑗为(+)和(-)类样本的平均值和标准差。较大的正𝑤𝑗值表示与类(+)有很强的相关性,而较大的负𝑤𝑗值表示与类(-)有很强的相关性。
一些嵌入式方法涉及到改变分类器的目标函数,以学习使用模型权重向量的特征排序。例如,修改支持向量机(SVM)的成本函数,以执行递归特征消除(RFE)的方法被称为SVM-RFE方法,类似的技术已经被开发出来用于多层神经网络。
3 . 包装器方法(wrapper methods)
通过迭代搜索整个特征空间,生成候选特征子集,将优化一个特定分类器的性能度量,这种性能度量或目标函数取决于问题的类型。例如,回归评价标准可以是r-平方,而分类评价标准可以是准确性、查全率、精确度、f1-分数等。用于包装器特征选择的常用搜索算法包括分支和绑定方法和几种元启发式算法。除了启发式搜索算法外,一些包装器特征选择方法还基于顺序选择算法,如顺序前向选择(SFS)、顺序后向选择(SBS)、顺序前向浮动选择(SFFS)和顺序后向浮动选择(SBFS)。这些方法迭代地添加或删除特征,直到满足终止标准。
缺点:计算复杂度随着特征空间的增长而增加。
优点:由于特征选择针对特定的学习算法进行优化,不包含关于特定结构的分类或回归函数的知识,因此可以与任何学习机器结合。
如果拿特征选择后的数据直接进行模型的训练,由于数据的特征矩阵维度大,可能会存在数据难以理解、计算量增大、训练时间过长等问题,因此我们要对数据进行降维。降维是指把原始高维空间的特征投影到低维度的空间,进行特征的重组,以减少数据的维度。降维与特征最大的不同在于,特征选择是进行特征的剔除、删减,而降维是做特征的重组构成新的特征,原始特征全部“消失”了,性质发生了根本的变化。常见的降维方法有:主成分分析法(PCA)等。
降维的用处
-
随着数据维度不断降低,数据存储所需的空间也会随之减少。
-
低维数据有助于减少计算/训练用时。
-
一些算法在高维度数据上容易表现不佳,降维可提高算法可用性。
-
降维可以用删除冗余特征解决多重共线性问题。比如我们有两个变量:“一段时间内在跑步机上的耗时”和“卡路里消耗量”。这两个变量高度相关,在跑步机上花的时间越长,燃烧的卡路里自然就越多。因此,同时存储这两个数据意义不大,只需一个就够了。
-
降维有助于数据可视化。如前所述,如果数据维度很高,可视化会变得相当困难,而绘制二维三维数据的图表非常简单。
-
主成分分析(PCA)
PCA(Principal Component Analysis)主成分分析法,即通过正交变换将原始的n维数据,变换到一个新的被称为主成分的数据集中,将从现有的大量特征中提取一组新的变量特征。下面是PCA的一些要点:
- 主成分是原始变量的线性组合;
- 第一个主成分具有最大的方差值;
- 第二个主成分试图解释数据集中的剩余方差,且与第一主成分不相关(正交);
- 第三个主成分试图解释前两个主成分没有解释的方差。
from sklearn.decomposition import PCA
# n_components 为将要转换数据中的主成分个数
pca = PCA(n_components = 4)
# 分量解释的方差
plt.plot(range(4), pca.explained_variance_ratio_)
# 累计解释的方差
plt.plot(range(4), np.cumsum(pca.explained_variance_ratio_))
plt.title("Component-wise and Cumulative Explained Variance")-
反向特征消除(Backward Feature Elimination)
基本步骤:
- 先使用数据集中的全部特征变量,去训练一个模型;
- 计算模型性能;
- 每次删除一次特征变量后,重新计算模型性能;
- 确定对模型性能影响最小的特征,删除该特征;
- 重复此过程,直到不能再删除任何特征;
很明显可以看出来,该方法计算成本高、耗时久,因此只适用于特征变量较少的数据集。一般在构建线性回归和逻辑回归模型时选择使用此方法。
from sklearn.linear_model import LinearRegression
from sklearn.feature_selection import RFE
# 线性回归模型
lreg = LinearRegression()
rfe = RFE(lreg, 10)
rfe = rfe.fit_transform(train_data, y_train_data)-
随机森林(Random Forest)
随机森林在作为特征选择使用的算法时,效果较为良好,也是现在广泛使用的一种特征选择办法。随机森林会自动帮我们选择出重要性高的特征。随机森林回归的输入只接受数值型数据,因此需先将数据转换成数字格式。
# 导入集成模型中的随机森林回归模型
from sklearn.ensemble import RandomForestRegressor
# 转换成矩阵(独热编码)
data = pd.get_dummies(train_data)
rfr = RandomForestRegressor(random_state = 1, max_depth = 10)
rfr.fit(data, y_train_data)
# 根据特征的重要性,绘制成图表
features = train_data.columns
importances = rfr.feature_importances_
# 前10个重要的特征
indices = np.argsort(importances[0:9])
plt.title('Feature Importances')
plt.barh(range(len(indices)), importances[indices], color='b', align='center')
plt.yticks(range(len(indices)), [features[i] for i in indices])
plt.xlabel('Relative Importance')
plt.show()得到绘制出的图表后,我们可以根据图表中的特征来手动进行选择,从而达到降维的目的。
如果使用sklearn提供的特征选择类的话,我们可以使用SelectFromModel类,它会自动帮我们根据特征的权重选择重要的特征。代码如下:
# 从feature_selection中导入SelectFromModel类
from sklearn.feature_selection import SelectFromModel
feature = SelectFromModel(rfr) # 模型为随机森林回归以上就是机器学习中特征工程的基本简述
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK