

哪个版本的JVM最快?
source link: https://developer.51cto.com/article/712531.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
哪个版本的JVM最快?-51CTO.COM
Chronicle Queue是一个持久性的低延迟Java消息传递框架。它适用于具有高性能的关键性应用程序。由于Chronicle Queue运行在映射到本地的内存上,因此它消除了垃圾收集的需求,并为开发人员提供了确定性和高性能。
本文将使用开源的Chronicle Queue的两个线程,彼此交换256字节的消息数据。同时,为了最小化对于磁盘子系统的影响,所有消息都将被存储在共享内存--/dev/shm中。
通常,在此类基准测试中,一个单一生产者(producer)线程会将消息写入具有纳秒时间戳(nanosecond timestamp)的队列中。而另一个消费者线程则会从该队列中读取消息,并在直方图中记录时间的增量。生产者保持每秒100,000条消息的持续输出速率。其中,每条消息中的有效负载为256字节。由于数据会在100秒的跨度内被测量,因此出现的大多数抖动都能够被反映到测量中,并且可以确保那些具有较高百分位数,落在合理的置信区间内。
我们的目标主机是拥有一个AMD Ryzen 9 5950X的16核处理器,并且以3.4 GHz运行在Linux 5.11.0-49-generic #55-Ubuntu SMP上。由于该CPU的2-8核是隔离的,因此操作系统不会去自动调度任何用户进程,而且会避开在这些核上的大多数中断。
1.Java 代码
下面显示了生产者内部循环的部分代码:
Java
// Pin the producer thread to CPU 2
Affinity.setAffinity(2);
try (ChronicleQueue cq = SingleChronicleQueueBuilder.binary(tmp)
.blockSize(blocksize)
.rollCycle(ROLL_CYCLE)
.build()) {
ExcerptAppender appender = cq.acquireAppender();
final long nano_delay = 1_000_000_000L/MSGS_PER_SECOND;
for (int i = -WARMUP; i < COUNT; ++i) {
long startTime = System.nanoTime();
try (DocumentContext dc = appender.writingDocument()) {
Bytes bytes = dc.wire().bytes();
data.writeLong(0, startTime);
bytes.write(data,0, MSGSIZE);
}
long delay = nano_delay - (System.nanoTime() - startTime);
spin_wait(delay);
}
}而在另一个线程中,消费者(consumer)线程会通过如下代码(下面仅为缩短的部分),在其内部循环运行。
Java
// Pin the consumer thread to CPU 4
Affinity.setAffinity(4);
try (ChronicleQueue cq = SingleChronicleQueueBuilder.binary(tmp)
.blockSize(blocksize)
.rollCycle(ROLL_CYCLE)
.build()) {
ExcerptTailer tailer = cq.createTailer();
int idx = -APPENDERS * WARMUP;
while(idx < APPENDERS * COUNT) {
try (DocumentContext dc = tailer.readingDocument()) {
if(!dc.isPresent())
continue;
Bytes bytes = dc.wire().bytes();
data.clear();
bytes.read(data, (int)MSGSIZE);
long startTime = data.readLong(0);
if(idx >= 0)
deltas[idx] = System.nanoTime() - startTime;
++idx;
}
}
}可以看出,消费者线程会读取每个纳米时间戳,并在一个数组中记录相应的延迟。这些时间戳稍后会在基准测试完成时,被放入供打印的直方图中。而且,只有在JVM被正确地“预热”、以及C2编译器具有了JIT(Just-In-Time)的热执行路径后,测量才会开始。
2.JVM的各种变体版本
目前,Chronicle Queue能够正式支持包括Java 8、Java 11和Java 17在内的,所有最近的LTS(Light Task Schedule)版本,因此它们都可以被用于基准测试。同时,我们还会用到GraalVM的社区版和企业版。以下便是我们在测试中用到的特定JVM变体版本的列表:
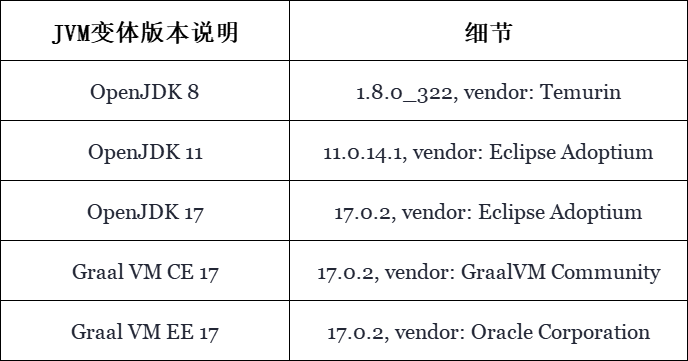
表 1,列出了使用到的特定JVM变体版本
由于基准测试会运行100秒,并且每秒会有100,000条消息被产生,因此在每个基准测试期间,我们会有100,000 * 100 = 1000万条消息需要采样。直方图会将每个样本置于50%(中位数)、90%、99%、以及99.9%等特定的百分位处。下表显示了测试针对这些百分位,所接收到的消息总数:
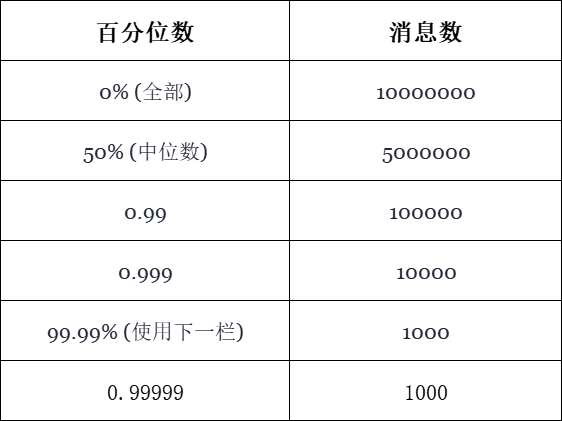
表 2,显示每个百分位数的消息数
对于上表而言,我们锁定测量值的变化相对较小的区间,对于高达99.99%的百分位数,置信区间可能会比较合理。而99.999%的百分位数,则可能需要至少要运行半小时左右,而不是仅仅使用100秒的时间,去收集数据,以生成任何具有合理置信区间的数据。
4.基准测试的结果
对于每个Java变体版本,我们都运行了如下基准测试:
Shell
mvn exec:java@QueuePerformance注意,我们的生产者和消费者线程将会被锁定,以便分别在彼此隔离的CPU的2和4核上运行。以下便是它们运行了一段时间后的典型进程特征:
Shell
$ top
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
3216555 per.min+ 20 0 92.3g 1.5g 1.1g S 200.0 2.3 0:50.15 java可以看出,生产者和消费者线程在每条消息之间都会旋转等待(spin-wait),因此每个都会消耗整个CPU的内核。如果CPU的消耗是一个潜在的问题,那么其延迟和确定性则可以通过在无消息可用的情况下,将线程暂停一小段时间(例如LockSupport.parkNanos(1000)),来降低功耗。通常,我们会以纳秒(ns)为单位来衡量测试结果。当然,许多其他类型的延迟测量也会以微秒(= 1,000 ns)、甚至毫秒(= 1,000,000 ns)为单位进行计量。此处的1 ns大致对应于对CPU 1级高速缓存的访问时间。以下所有测试值均是以ns为单位的基准测试结果:
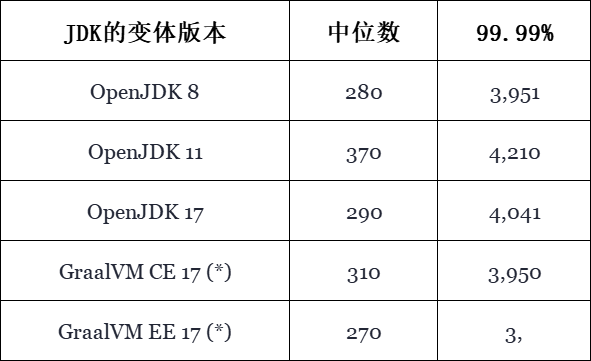
表 3,显示了使用的各种JDK的延迟结果(*)表示未被Chronicle Queue正式支持
5.典型延迟(中位数)
由上表可知,对于典型(中位数)值,各种JDK之间并没有显著的差异,只是OpenJDK 11会比其他版本要慢30%。其中最快的是GraalVM EE 17,它与OpenJDK 8、以及OpenJDK 17的差异很小。下面展示的图表包含了使用各种JDK变体版本,在处理256字节消息时的典型延迟(当然是越低越好):
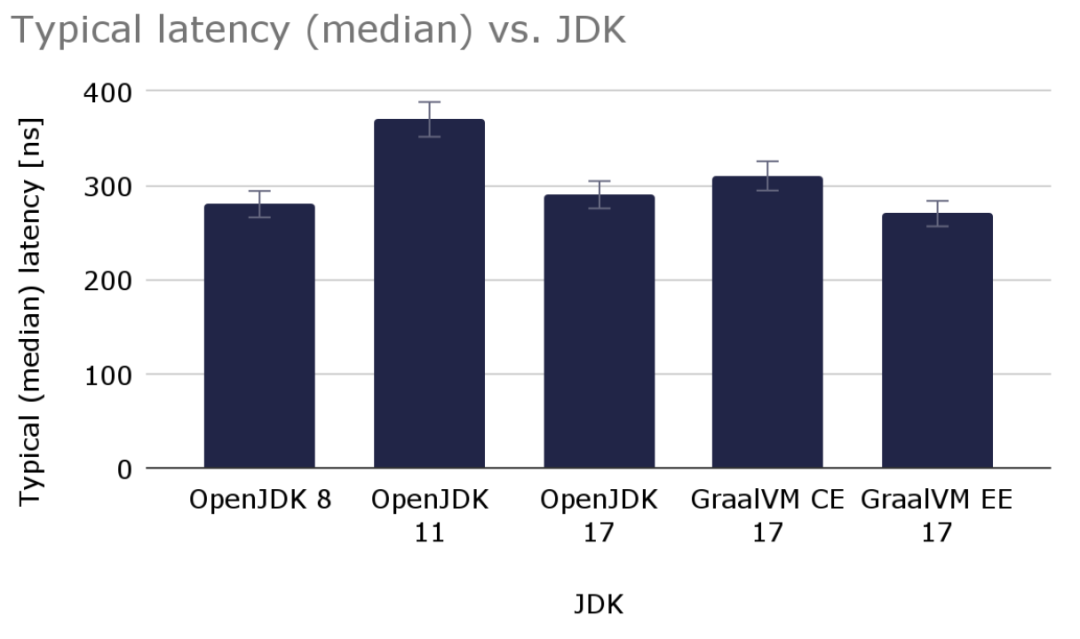
图 1,显示了各种JDK变体版本的中位数(典型)延迟(以ns为单位)
由图可知,典型(中位数)的延迟会因运行环境而略有不同,它们数字的变化约为5%。
6.更高的百分位数
下面是另一种图表,它展示了各种JDK变体版本的99.99%百分位数的延迟(当然也是越低越好)。从较高的百分位数来看,各种受支持的JDK变体版本之间,并没有太大的差异。GraalVM EE再次稍快一点,但是此处的相对差异变得更小了。而OpenJDK 11似乎比其他变体版本稍差一些(-5%),不过其误差增量仍在可接受的范围内。
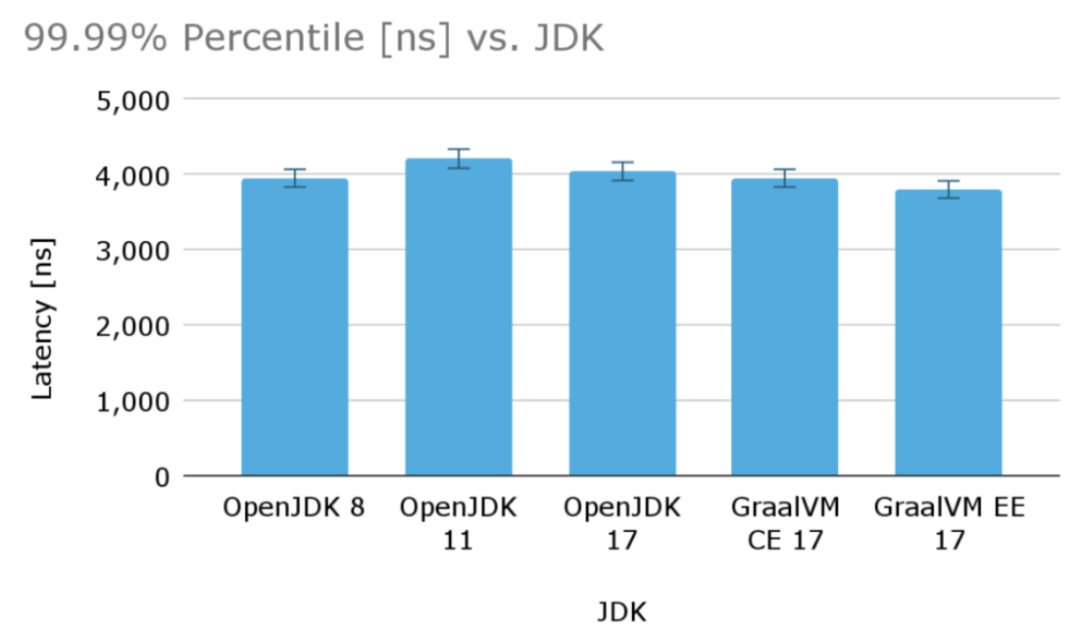
图 2,显示了各种JDK变体版本的99.99%百分位延迟(以ns为单位)
根据上述代码的执行逻辑:从主要内存处访问64位的数据,大约需要100个周期(即,在当前硬件上相当于大约30 ns)。通过上面的测试比较,我们可以看出, Chronicle Queue从生产者那里获取数据,并通过写入内存映射文件的方式持久化数据,为线程间通信和happens-before的保证,应用适当的内存防护,然后将数据提供给消费者。与在30 ns内的单个64位内存访问相比,所有这些通常都发生在600 ns左右的256字节的消息上。这些由Chronicle Queue产生的延迟比较结果令人印象深刻。
可见,OpenJDK 17和GraalVM EE 17都提供了最佳的延迟结果,属于应用程序的优先选择。当然,如果需要抑制异常值、或者尽可能地降低总体延迟的话,那么GraalVM EE 17会更加适合一些。
原文链接:https://dzone.com/articles/which-jvm-version-is-the-fastest
陈峻 (Julian Chen),51CTO社区编辑,具有十多年的IT项目实施经验,善于对内外部资源与风险实施管控,专注传播网络与信息安全知识与经验;持续以博文、专题和译文等形式,分享前沿技术与新知;经常以线上、线下等方式,开展信息安全类培训与授课。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK