

啃论文俱乐部—数据密集型应用内存压缩
source link: https://os.51cto.com/article/712470.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

【技术DNA】
【智慧场景】
********** | ******************** | ******************** | ******************** | ******************** | ******************** | ******************** | ******************** | ******************** | ******************** | ******************** | ******************** | ******************** | ******************** | ******************** | ***************** | ***************** | ******************** |
场景 | 自动驾驶 / AR | GPU 渲染 | 科学、云计算 | 数据库服务器 | 人工智能图像 | GAN媒体压缩 | 数据库系统 | 系统数据读写 | |||||||||
技术 | 稀疏快速傅里叶变换 | 有损视频压缩 | 动态选择压缩算法框架 | 分层数据压缩 | 医学图像压缩 | 无损通用压缩 | 人工智能图像压缩 | 短字符串压缩 | GAN 压缩的在线多粒度蒸馏 | 文件传输压缩 | 快速随机访问字符串压缩 | 高通量并行无损压缩 | 增强只读文件系统 | ||||
开源项目 | SFFT | Ares | LZ4 | DICOM | Brotli | RAISR | AIMCS | OMGD | rsync | FSST | ndzip | EROFS |
随着随着互联网突飞猛进地发展,我们已经进入了“大数据时代”。对于大部分像抖音、淘宝等应用来说,其庞大的数据量、数据的复杂程度等都无疑会带来很多问题;就拿淘宝来说,打开淘宝APP,一大堆的信息就会推送给你,像是文字、图片、直播的视频等等都会在数据方面带来巨大的开销。如果能够试图压缩这些 “数据密集型(data-intensive)” 应用所带来的数据,那么对于手机、电脑等等消费设备来说,人们将会从价格高昂的高端设备转而选择更便宜的配备小内存的型号。

要想让“数据密集型”应用所产生的数据“瘦下来”可不是一件容易的事,因为 “压缩自古两难全”,想要压缩比高,又不在性能(压缩速度)上减少,很难有这种两全其美的事。但对于一个应用来说,用户体验不能太差,这直接关系到内存中的数据压缩,因为内存访问的性能将会严重影响整个系统的性能,为此 Wilson 等人提出了 WKdm 算法,该算法利用了从内存数据中观察的规律,从而展现出了非常出色的压缩速度,但是它较差的压缩比成为了它迈向成功的“绊脚石”。因此,作者将本文中提出的算法与其做对照。
文中,作者提出了一种新的压缩算法,LZ4m;和 Wilson 提出的 WKdm 算法一样,通过内存数据中经常观察到的特征来加快 LZ4 算法输入流的扫描;其次,针对 LZ4 算法,作者修改了其编码方案,使其压缩后的数据能够以更简洁的形式表示,结果表明,LZ4m 在压缩和解压缩的速度上分别比 LZ4 算法提高了 2.1x 和 1.8x,压缩比的 marginal loss 小于 3%。
LZ4 分析
很多低压缩延迟的压缩算法都是基于 Lempel-Ziv 算法的,但是其仍有缺点,因为其最长匹配以及部分较长的匹配很难再带来时间和空间开销的减少,从而招致很高的时间和空间开销。因此,在实践中,大家通常会改变策略来快速识别足够长的子字符串。
LZ4 则是在 Lempel-Ziv 算法的基础上发展起来的最成功的压缩算法之一,下面为对 LZ4 的匹配过程进行解释:
从算法上看
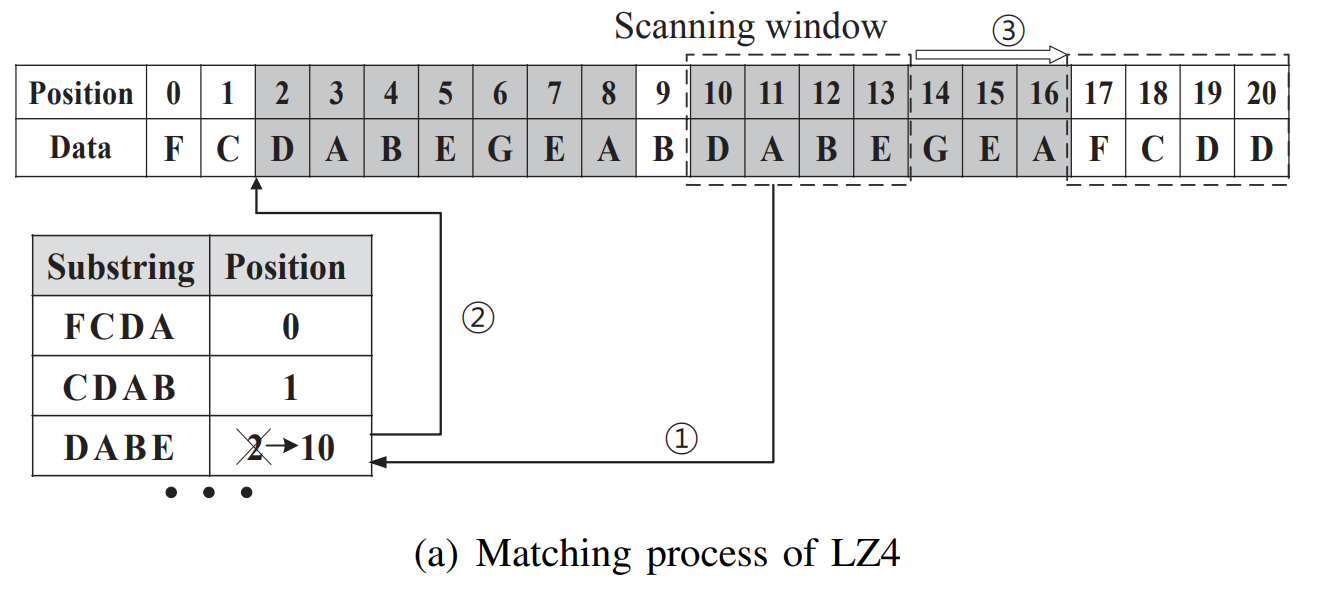
- LZ4 主要在其滑动窗口与哈希表部分,滑动窗口每次扫描 4 字节的输入流,并检查窗口中的字符串是否在之前出现过。
- 为了辅助匹配,LZ4 维护了一个哈希表,并将 4 字节的字符串从输入流开始的地方映射。
- 如果哈希表中包含当前滑动窗口中的字符串,那么将从当前扫描位置继续匹配字符串,前后两个具有相同前缀的子串能够匹配出一个最长子串,对应哈希表条目更新到当前起始扫描位置。
- 滑动窗口继续移动,不断更新哈希表中没有的子串的条目,直到滑动窗口达到结尾。
从结构上看
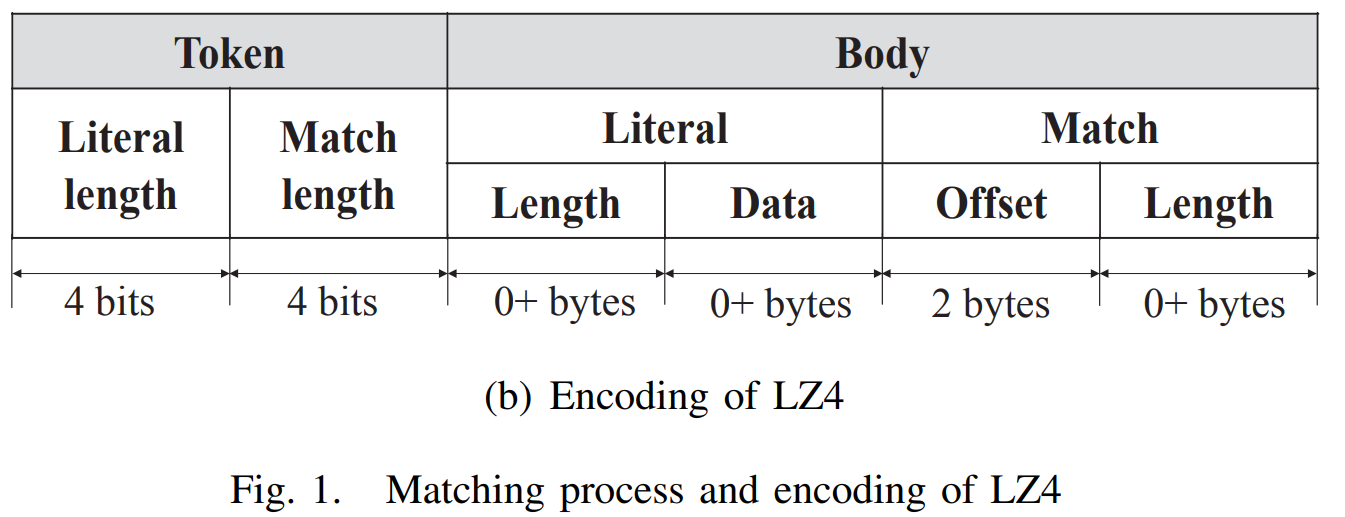
- 输入流被编码成了一个编码单元,一个编码单元(Encoding unit) 由首部(Token) 和主体(Body) 两个部分组成。
- 每个编码单元 都以 1 字节的首部开始,首部的前四位用来表示主体(Body) 的字面量长度 的大小,首部的后四位用来表示匹配长度 的大小。
- 如果字符串超过15字节,也就是首部的字面量长度的 4 位全为 1 时(1111),首部的字面量长度将减去 15 并放在首部后面的主体上。
- 主体(Body) 由字面量数据与匹配描述组成,其中匹配描述由向后的匹配偏移量与匹配长度 组成。
- 主体中偏移量由 2 字节编码,因此 LZ4 可以回溯到 64 KB(2^16/1024)来查找匹配。
- 紧跟在某个匹配(Match)之后的其他匹配(Match)以类似的方式编码,只是标记中的文字长度字段被设置为0000,并且主体(Body)省略了字面量(Literal)部分。
LZ4m 分析
由于 LZ4 是一种通用压缩算法,没有针对某个特定方面做了特别的优化,它的压缩比以及解压缩速度没有针对某一领域完全释放。因此,这里将利用内存中数据的特性来对 LZ4 进行修改。
其次来说说内存中的数据。内存中的数据由虚拟内存页组成,其中包含来自应用程序的堆和栈的数据。堆和栈中包含常量、变量、指针和基本类型的数组,这些数据通常是结构化的,并与系统的字边界对齐。
通过作者的观察,发现扫描匹配单词粒度中的数据可以在不显著损失压缩机会的情况下加速数据压缩。此外,由于 4 字节对其的缘故,更大的粒度可以用更少的位来表示长度和偏移量,子字符串可以用更简洁的形式编码。
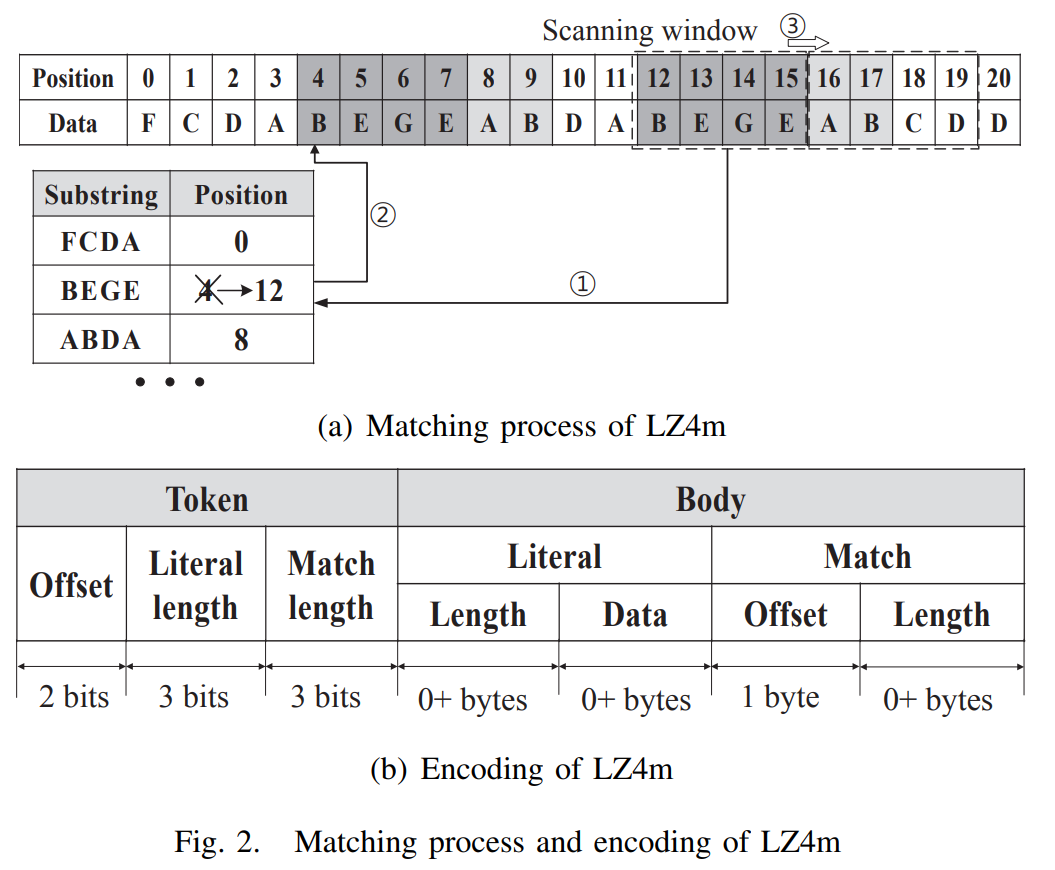
根据以上信息,作者提出了 LZ4m 算法,即用 LZ4 表示内存中的数据。下图中则是 LZ4 与 LZ4m 的区别的对比,乍一看可能看不出有什么区别,滑动窗口、哈希表,两者该有的都有;但是细看就会发现,LZ4m 的首部比 LZ4 多了偏移量(Offset),其它部分(包括首部的字面量长度,首部的匹配长度以及 主体的字面量的偏移量)也对内存大小方面做了改动。
由于 4 字节对齐,来获取结构中元素的偏移量,长度为 4 字节的倍数,两个最不重要的位总会是00(就像0,4,8,12 用 二进制表示为 0000、0100、1000、1100,后面两位总是0,我们便可以将其删掉来节省空间),这样 首部(Token) 的 字面量长度(Literal length)、匹配长度(Match length) 以及 主体(Body) 的 匹配偏移量(Match offset) 都可以缩短 2 位。
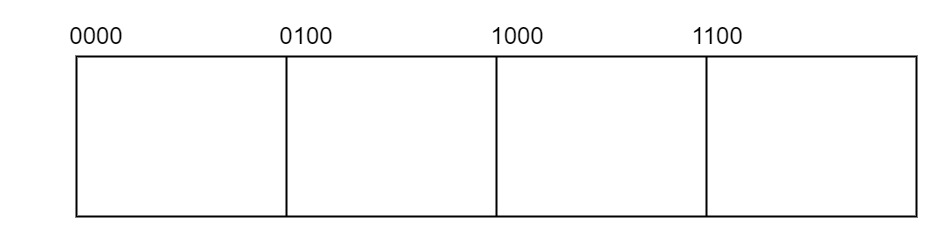
此外,由于 LZ4m 是以 4 字节粒度压缩 4KB 的页面,所以偏移量最多需要 10 位,因此将偏移量的 2 个最高有效位放在首部(Token) 中,将剩下的 8 位放在主体中。
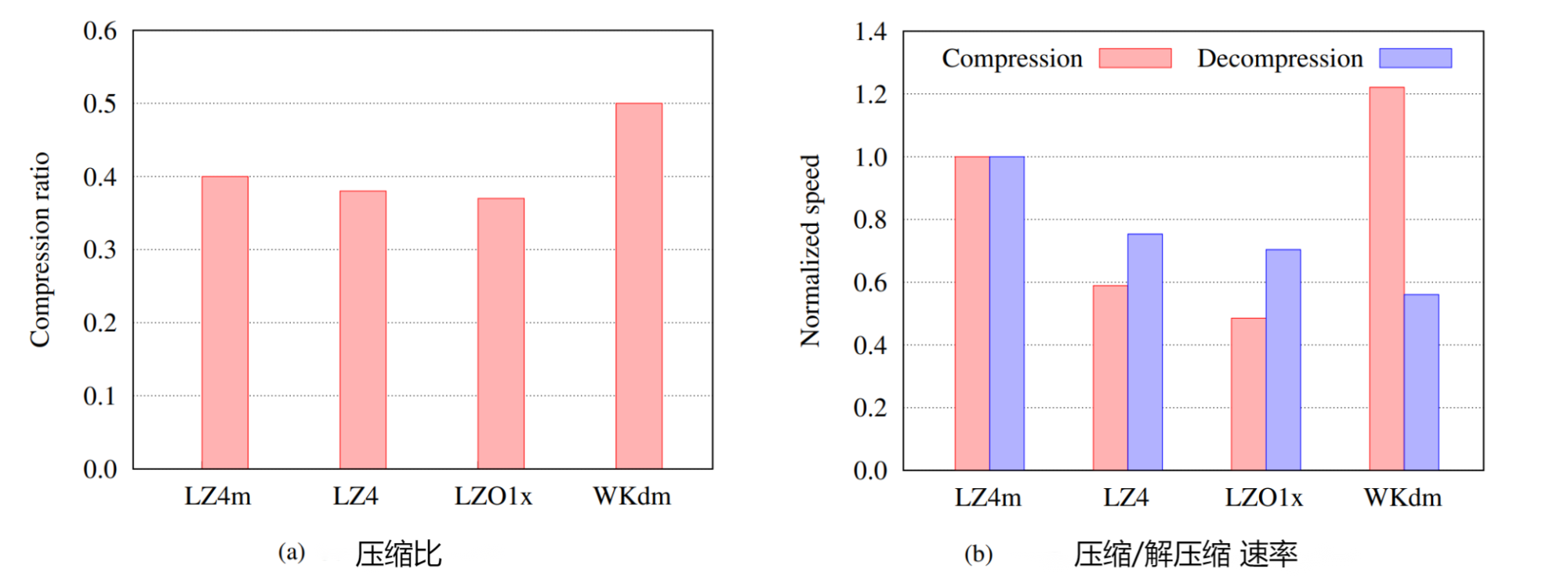
- 将 LZ4 和 LZO1x 评估为通用算法的代表,将 WKdm 评估为专业算法。论文收集了通过交换从主内存中清除的数据来收集内存数据。
- 压缩比是页面的平均值,压缩比越小意味着相同数据的压缩大小越小。WKdm的压缩比最大,其次是LZ4m,LZ4,最后是LZO1x,速度归一化为 LZ4m。与通用算法(即 LZ4 和 LZO1x)相比,LZ4m 显示出可比较的压缩比,仅降低了 3%。
- LZ4m 在速度上优于这些算法高达 2.1× 和 1.8× 分别用于压缩和解压缩。LZ4m 在压缩比和解压速度上高于 WKdm 许多,但代价是压缩速度下降了 21%。综上,LZ4m 在压缩比损失的情况下,大幅提高了 LZ4 的压缩/解压速度。
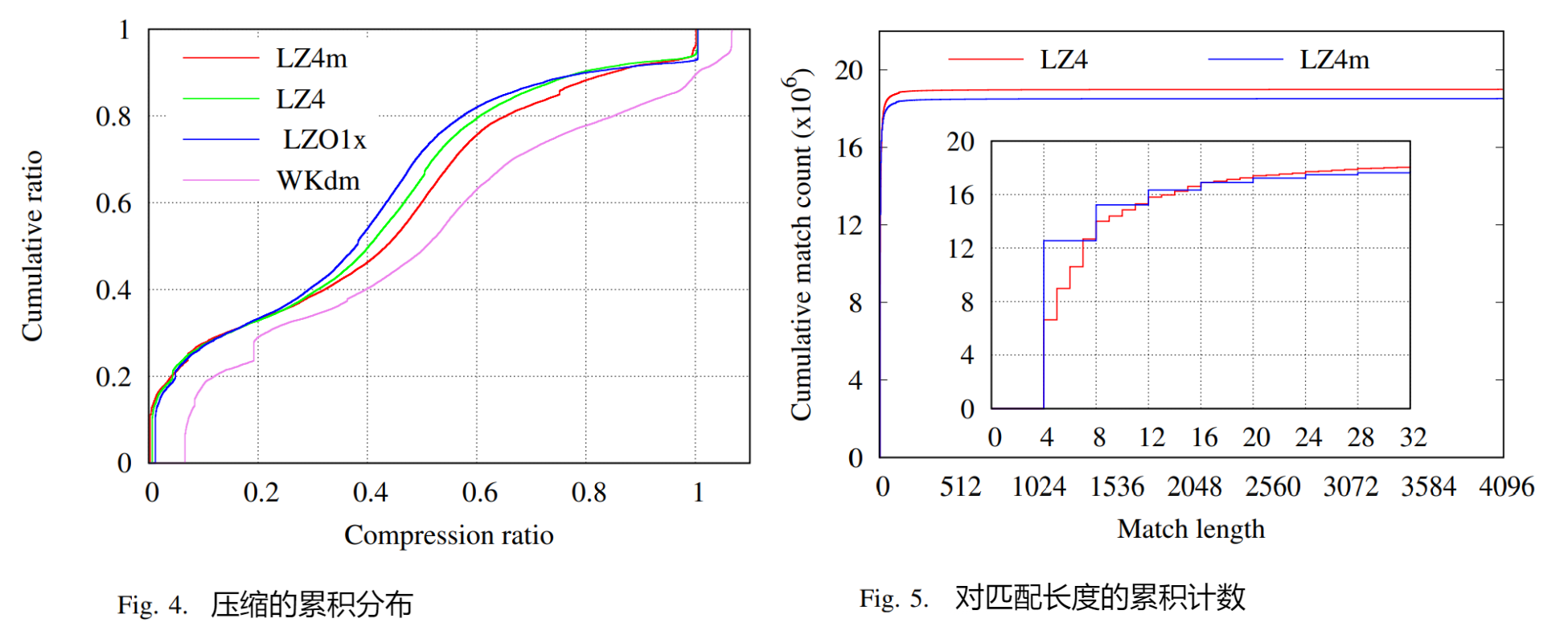
- 下图显示了页面压缩率的累积分布。LZ4m 的压缩比曲线仅次与于 LZO 和 LZ4 算法一些,没有很大差距。而 WKdm 显示出明显的压缩比曲线,远远落后于其他算法。并且 6.8% 的页面根本无法使用 WKdm 进行压缩,而使用其他页面的比例不到 1%。这表明 WKdm 的压缩加速可以通过其较差的压缩比来抵消
- 进一步比较 4 字节粒度的匹配偏移量和匹配长度的含义为目的,将从跟踪匹配长度入手,如图原始 LZ4 和 LZ4m 结果中计算匹配子串的长度,与累积匹配计数进行比较。放大了 LZ4 和 LZ4m 匹配长度在 0 到 32 之间的原始结果,增加的粒度只减少了总长度匹配的出现 2.5%,这意味着 4 字节粒度方案对找到匹配的机会影响很小,在匹配长度上的劣势也是微不足道的。
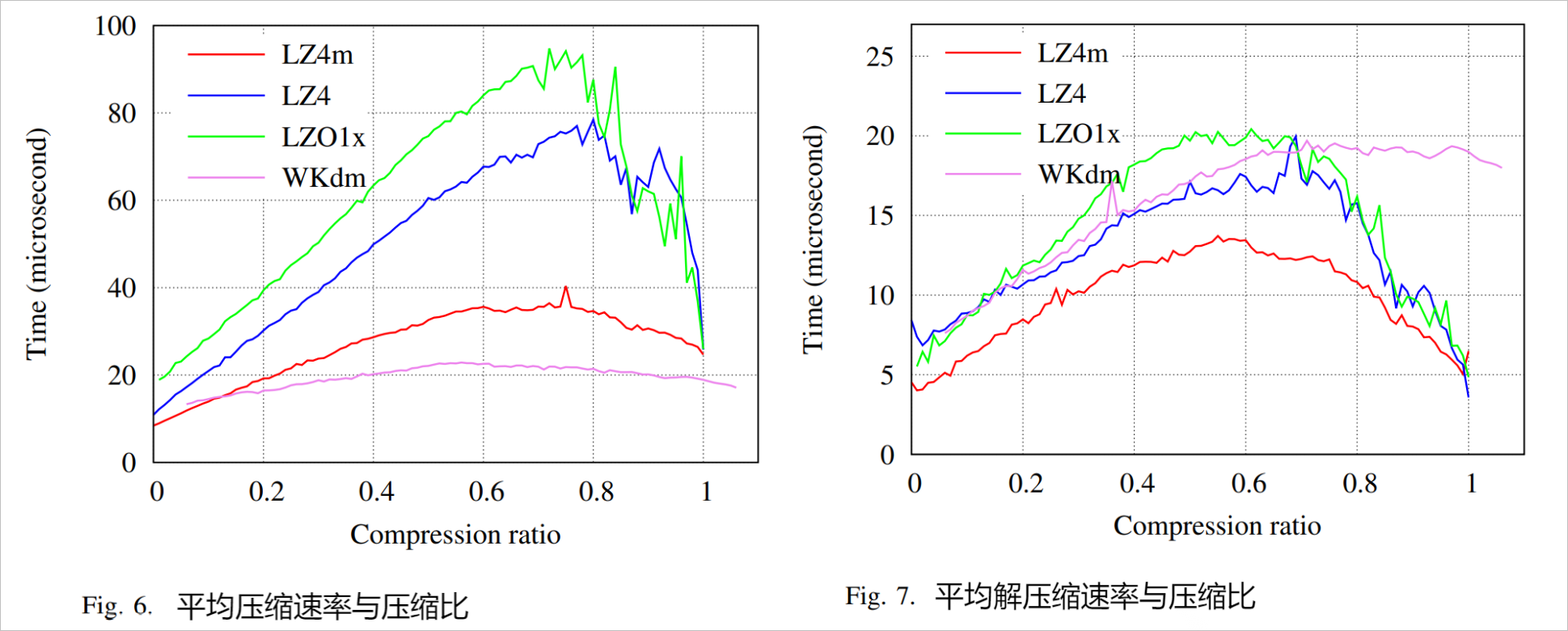
- 时间和压缩比之间的关系,通过测量每个页面的压缩时间并平均具有相同压缩比的页面的时间可以获得算法的压缩速度。压缩良好的压缩页面的时间在算法中是相似的。比起 LZ4 和 LZO1x,LZ4m 显示出了出色的压缩速度 。因为 LZ4m 的扫描过程,如果没有找到前缀匹配,扫描窗口会提前 4 个字节,从而在难以压缩的页面上提高四倍的扫描速度。
- 算法的解压缩速度与平均解压速度除以压缩比,速度的获得方式与平均压缩速度相同。 LZ4m 在几乎整个压缩比范围内的解压缩速度都优于其他算法。
- LZ4 是目前综合来看效率最高的压缩算法,更加侧重压缩解压速度,压缩比并不是第一。
- 利用内存数据的固有特性优化了一种流行的通用压缩算法,根据数据,LZ4m 能极大地提高了压缩/解压缩速度,而压缩比没有实质性损失。
- LZ4m 针对小块大小进行了优化。最大偏移量为 270(在 LZ4 中为 65535)。
- LZ4m 背后开发人员计划将这种新的压缩算法用于现实世界的内存压缩系统。但从2017年后找不到更多的代码。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK