

Spark大数据分析技术期末复习
source link: https://1905060202.github.io/2022/06/21/Spark%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90%E6%8A%80%E6%9C%AF%E6%9C%9F%E6%9C%AB%E5%A4%8D%E4%B9%A0/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Spark大数据分析技术期末复习
Spark大数据分析技术期末题型
作者:hyn
2022.6.25 于湘潭
选择:10 * 2’
简答:10 * 5’
编程:2 * 15’
- 1.1.2 Spark的优点
- 1.1.4 Spark的生态系统
- 1.2.3 Spark应用执行的基本流程
- 1.4 Spark编程
- 一道编程题
- 几道scala语法选择题
- 3.1 RDD创建
- 3.2 RDD操作(转换,行动操作的定义、区别,宽窄依赖)
- 3.4 RDD持久化
- (DataFrame、DataStream和RDD的联系与区别)
- DataFrame的常用操作
第六章(动、静态数据)
- 6.1 流计算
- 6.2 Spark Streaming运行原理
- 6.5 操作DStream
- 7.2.1 属性图
- 7.2.2 GraphX图存储模式
- Spark在ML上的优势
Spark的优点(简答题)
Spark是基于内存计算的大数据并行计算框架。
- 运行速度快
Spark的生态系统(选择题)
- 应用层:Spark SQL、Spark Streaming、Spark GraphX、Spark MLlib
- 数据处理引擎(核心层):Spark Core
- 资源管理层:MESOS、YARN、Standalone
- 数据储存层:HDFS、Amazon S3、Hbase、Hive
Spark core是Spark生态系统的核心组件,是一个分布式大数据处理框架。Spark core提供了多种资源调度管理,通过内存计算、DAG分布式并行计算等机制保证分布式计算的快速。并引入了RDD抽象数据类型保证数据的高容错性。
Spark应用执行的基本流程(简答题)
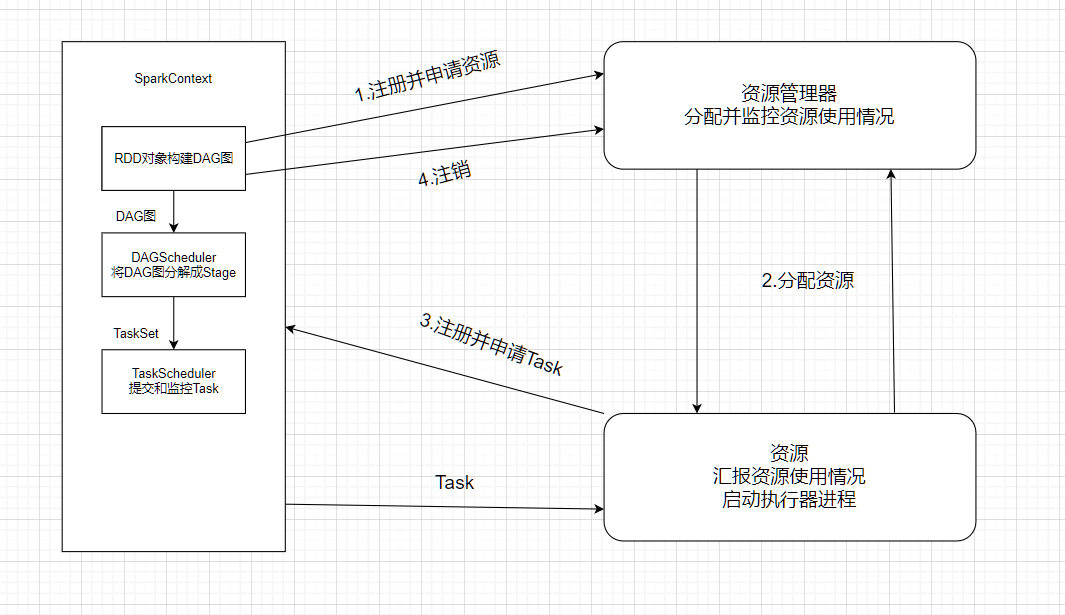
创建一个列表{1,7,9,8,0,3,5,4,6,2},将列表中每个元素乘以10后生成一个新的集合
- ~~~scala
val list1[Int] = List(1,7,9,8,0,3,5,4,6,2)
val list2[Int] = list1.map(_*10)
-
- 编写函数实现:输入一个数字,如果为正数,则他的signum为1;如果是负数,则他的signum为-1;如果为0,则他的signum为0.
- ~~~scala
def signum(n: Double): Double = {
if (n > 0) {
1
} else if (n < 0) {
-1
} else {
0
}
}
- ~~~scala
RDD创建(简答题/选择题)
RDD是Spark对数据进行的核心抽象,一个不可变的分布式对象集合。RDD本质上是一个只读的分区记录集合,每个分区就是一个数据集片段。Spark中的所有操作都是基于RDD进行的。一个Spark应用可以看作一个由RDD创建到一系列的RDD转化操作,再到RDD存储的过程。
RDD的创建可以分为:
- 使用程序中的数据集创建RDD:
- 通过并行化数据集合来创建RDD,就是通过调用SparkContext中的parallelize()方法并行化数据到集群的节点上形成一个分布式的数据集合,也就是一个RDD。
- 使用文本文件创建RDD
- 调用SparkContext的textFile()方法读取文件的位置即可创建RDD
- 使用JSON文件创建RDD
- 读取JSON文件创建RDD最简单的方法就是将JSON文件作为文本文件读取。即调用textFile()方法。
- 使用CSV文件创建RDD
- 依然是使用textFile()方法读取csv文件创建RDD
RDD操作(编程题)
RDD操作分为:
-
- RDD的转换操作是返回新的RDD的操作,RDD转换操作是惰性求值的,只有在行动操作中用到这些RDD时才会被转换。
-
- collect()行动操作方法可以将RDD类型的数据转化为Array数据并返回到Driver端
RDD实例解析1:找出文本文件中单行文本所包含的单词数量的最大值
~~~scala
scala> val lines = sc.textFile(“file:///D:/spark-2.4.5-bin-hadoop2.7/test/data.txt”)
scala> lines.map(line =>line.split(“”).size).reduce((a,b)=>if(a>b) a else b)
-
- 上面代码中lines是一个RDD,是String类型的RDD
- lines.map(),是一个转换操作,之前说过,map(func):将每个元素传递到函数func中,并将结果返回为一个新的数据集,所以,lines.map(line => line.split(” “).size)会把每行文本都传递给匿名函数,也就是传递给Lamda表达式line => line.split(” “).size中的line,然后执行处理逻辑line.split(” “).size。line.split(” “).size这个处理逻辑的功能是,对line文本内容进行单词切分,得到很多个单词构成的集合,然后,计算出这个集合中的单词的个数。因此,最终lines.map(line => line.split(” “).size)转换操作得到的RDD,是一个整型RDD,里面每个元素都是整数值(也就是单词的个数)。最后,针对这个RDD[Int],调用reduce()行动操作,完成计算。reduce()操作每次接收两个参数,取出较大者留下,然后再继续比较,例如,RDD[Int]中包含了1,2,3,4,5,那么,执行reduce操作时,首先取出1和2,把a赋值为1,把b赋值为2,然后,执行大小判断,保留2。下一次,让保留下来的2赋值给a,再从RDD[Int]中取出下一个元素3,把3赋值给b,然后,对a和b执行大小判断,保留较大者3.依此类推。最终,reduce()操作会得到最大值是5。
- RDD实例解析2:给定一组键值*(“spark”,2),(“hadoop”,6),(“hadoop”,4),(“spark”,6),键值对的key表示图书名称,value表示某天图书销量,请计算每个键对应的平均值,也就是计算每种图书的每天平均销量。
- ~~~scala
scala> val rdd = sc.paralelize(Array((("spark",2),("hadoop",6),("hadoop",4),("spark",6)))
scala> rdd.mapValues(x=>(x,1)).reduceByKey((x,y)=>(x._1+y._1,x._2+y._2)).mapValues(x=>(x._1/x._2)).collect()首先构建一个数组,数组里面包含了四个键值对,然后,调用paralelize()方法生成RDD。针对构建得到的RDD,我们调用mapValues()函数,把RDD中的每个键值对(key,value)的value部分进行修改,把value转换成键值对(value,1),其中,数值1表示这个key在RDD中出现了一次。
这里,必须要十分准确地理解reduceByKey()函数的功能。reduceByKey(func)的功能是使用func函数合并具有相同键的值。这里的func函数就是Lamda表达式(x,y) => (x._1+y._1,x._2 + y._2),这个表达式中,x和y都是value,而且是具有相同key的两个键值对所对应的value,比如,在这个例子中, (“hadoop”,(6,1))和(“hadoop”,(4,1))这两个键值对具有相同的key,所以,对于函数中的输入参数(x,y)而言,x就是(6,1),x._1表示这个键值对中的第1个元素6,x._2表示这个键值对中的第二个元素1,y就是(4,1),y._1表示这个键值对中的第1个元素4,y._2表示这个键值对中的第二个元素1,所以,函数体(x._1+y._1,x._2 + y._2),相当于生成一个新的键值对(key,value),其中,key是x._1+y._1,也就是6+4=10,value是x._2 + y._2,也就是1+1=2,因此,函数体(x._1+y._1,x._2 + y._2)执行后得到的value是(10,2),但是,要注意,这个(10,2)是reduceByKey()函数执行后,”hadoop”这个key对应的value,也就是,实际上reduceByKey()函数执行后,会生成一个键值对(“hadoop”,(10,2)),其中,10表示hadoop书籍的总销量,2表示两天。同理,reduceByKey()函数执行后会生成另外一个键值对(“spark”,(8,2))。
RDD属性(选择题)
RDD分区的一个分区原则是使得分区的个数尽量等于集群中的CPU核心数目。
- 宽依赖:父分区一对多子分区
- 窄依赖:父分区一对一子分区
RDD持久化(选择题)
在Spark中RDD采用惰性求值机制,每次遇到行动操作,都会从头开始执行计算。如果整个Spark程序中只有一次行动操作,这当然不会有什么问题。但是,在一些情形下,我们需要多次调用不同的行动操作,这就意味着每次调动行动操作,都会触发一次从头开始的计算,这对迭代计算而言,代价是很大的,迭代计算经常需要多次重复使用同一组数据。
RDD与DataFrame联系与区别(简答题)
- RDD、 DataFrame都是spark平台下的分布式数据集,为处理超大型数据提供便利;
- 都有惰性机制,在进行创建、转换时,不会立即执行,只有在遇到行动算子的时候才会开始计算;
- 都会根据Spark的内存情况进行自动缓存计算,这样即使数据量很大,也不会担心内存溢出;
-
- RDD 一般和spark MLlib同时使用
- RDD不支持spark sql操作
DataFrame
- DataFrame每一行的类型固定为Row,每一列的值无法直接访问,只有通过解析才能获取各个字段的值;
- DataFrame和DataSet一般不与spark mllib同时使用
- DataFrame和DataSet均支持sparksql操作
DataFrame的常用操作
- 汇总和聚合
流计算(选择题)
流数据是一组顺序、大量、快速、连续到达的数据序列,可被视为一个随时间延续而无限增长的动态数据集合。
Spark Streaming运行原理(简答题/选择题)
Spark Streaming的基本原理是将实时输入数据流以时间片为单位进行拆分,然后经Spark引擎以类似批处理的方式处理每个时间片数据。每个输入批次都会形成一个RDD,Spark以作业的方式处理和生成其他RDD,最终通过行动操作生成中间结果。
操作DStream(选择题/简答题)
对于从数据源得到的Dstream,用户可以在其上进行各种操作。这些方法主要分为三类:
- 无状态转换操作:每次对新的批次数据进行处理时,只会记录当前批次数据的状态,不会记录历史数据的状态信息。
- 有状态转换操作:当前批次的处理需要使用之前批次的数据或者中间结果。
- 基于滑动窗口的转换
- 追踪状态变化的转换
- 输出操作:外部系统经常需要使用到Spark DStream处理后的数据,因此,需要采用输出操作把DStream的数据输出到数据库或者文件系统中。
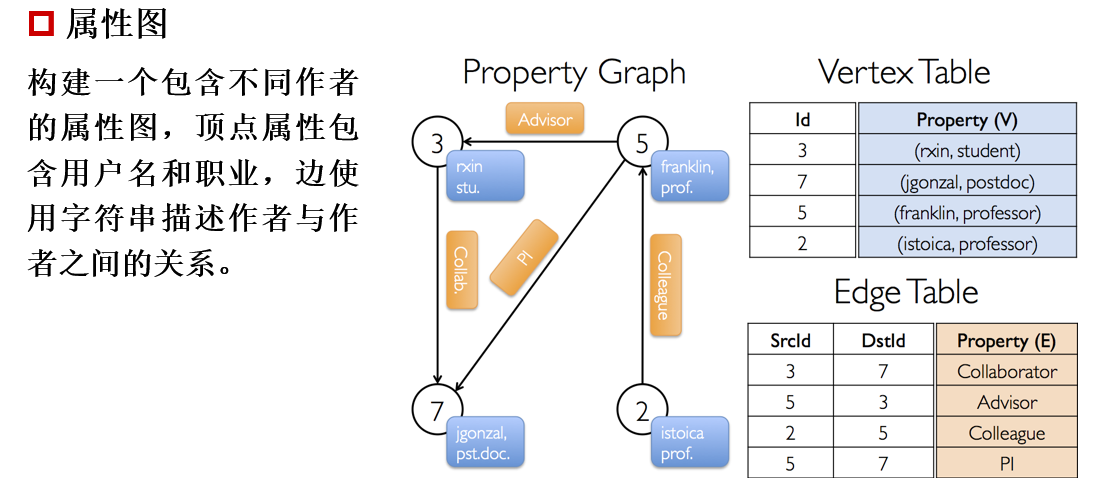
属性图(简答题)
GraphX的数据处理模型是弹性分布式属性图(Property Graph),属性图是由带有属性信息的顶点和边构成的图,这些属性主要用来描述节点和边的特征。
一个属性图具体包括:
- 顶点标识与顶点属性所组成的集合
- 边标识与边属性所组成的集合
属性图的例子:
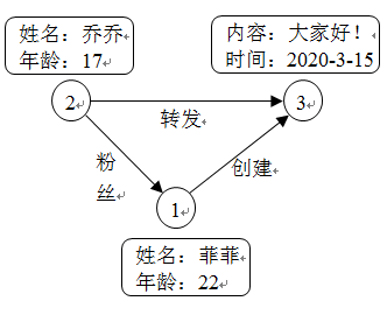
如微博社交网络图所示,图中顶点集Vertex={1, 2, 3}有3个顶点,图中边集Edge={“粉丝”, “创建”, “转发”}有3条边。
顶点1和顶点2分别表示用户菲菲和乔乔,顶点3表示发布的某条微博。表示用户的顶点可以具有姓名和年龄等属性信息,表示微博的顶点可以具有微博内容和发布时间等属性信息。顶点与顶点之间的关系用有向边表示,具体有粉丝关系、创建关系和转发关系。边的属性可以是具体的关系信息,也可以是具体的数值。
GraphX图存储模式(简答题)
在分布式环境下处理图数据,必须对图数据进行有效的图分割。图分割的分布式存储大致有两种方式,边分割(Edge Cut)存储,点分割(Vertex Cut)存储。
- 边分割模式:
- 边分割是保持图的顶点在各计算节点均匀分布,每个顶点都储存一次。
- 点分割模式:
- 点分割是保持各个边在各计算节点均匀分布,每条边只储存一次。
Spark在MLlib上的优势(简答题)
- Spark非常适合进行迭代计算,刚好能适应机器学习对迭代计算的需要。
- 从通信角度讲,Spark具有出色而高效的Akka和Netty通信系统,通信效率高
- MLlib基于RDD可以与Spark SQL、GraphX、Spark Streaming无缝集成
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK