

图解OneFlow的学习率调整策略
source link: https://blog.csdn.net/OneFlow_Official/article/details/125437976
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

图解OneFlow的学习率调整策略

撰文|李佳
1
背景
学习率调整策略(learning rate scheduler),其实单独拎出每一个来看都不难,但是由于方法较多,上来就看文档容易一头雾水, 以OneFlow v0.7.0为例,oneflow.optim.lr_scheduler模块中就包含了14种策略。
有没有一种更好的方法来学习呢?比如可视化出学习率的变化过程,此时,我脑海中突然浮现出Convolution Arithmetic这个经典项目,作者将各种CNN卷积操作以gif形式展示,一目了然。
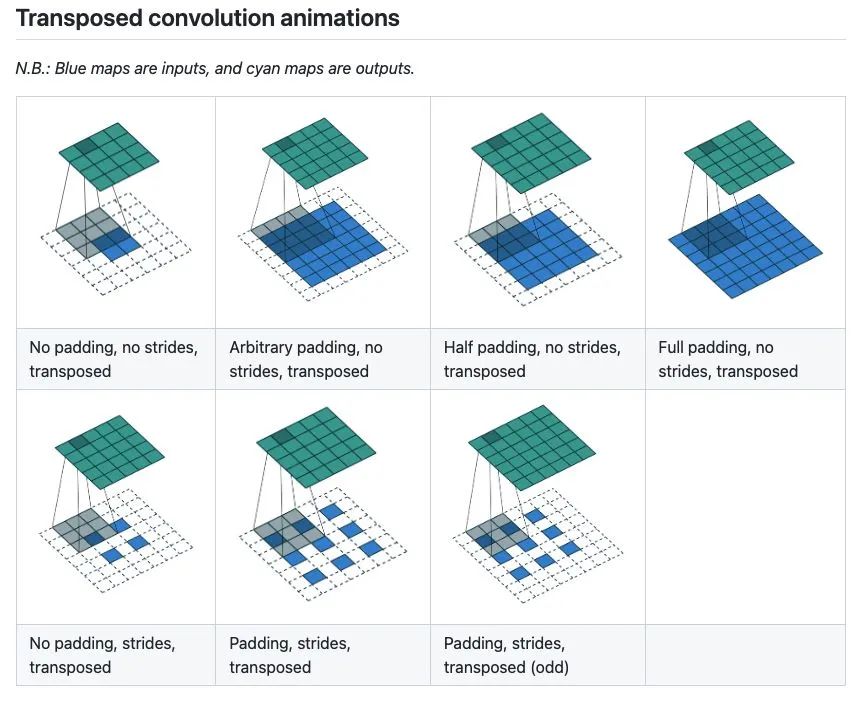
所以,就有了这篇文章,将学习率调整策略可视化出来,下面是两个例子(ConstantLR和LinearLR):
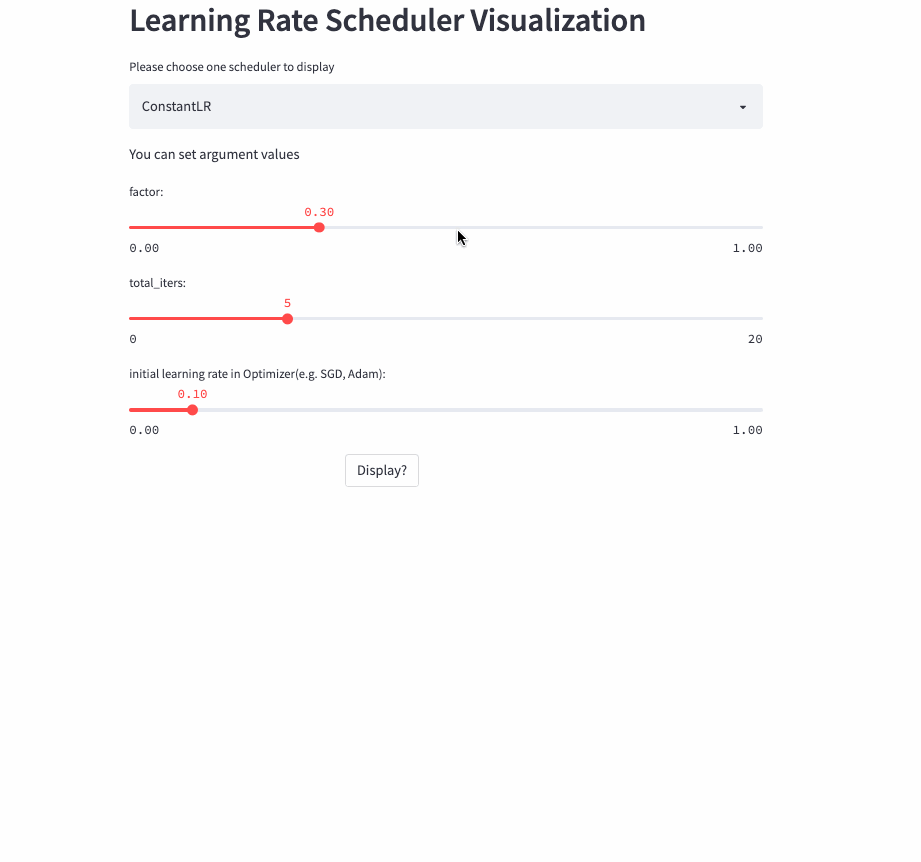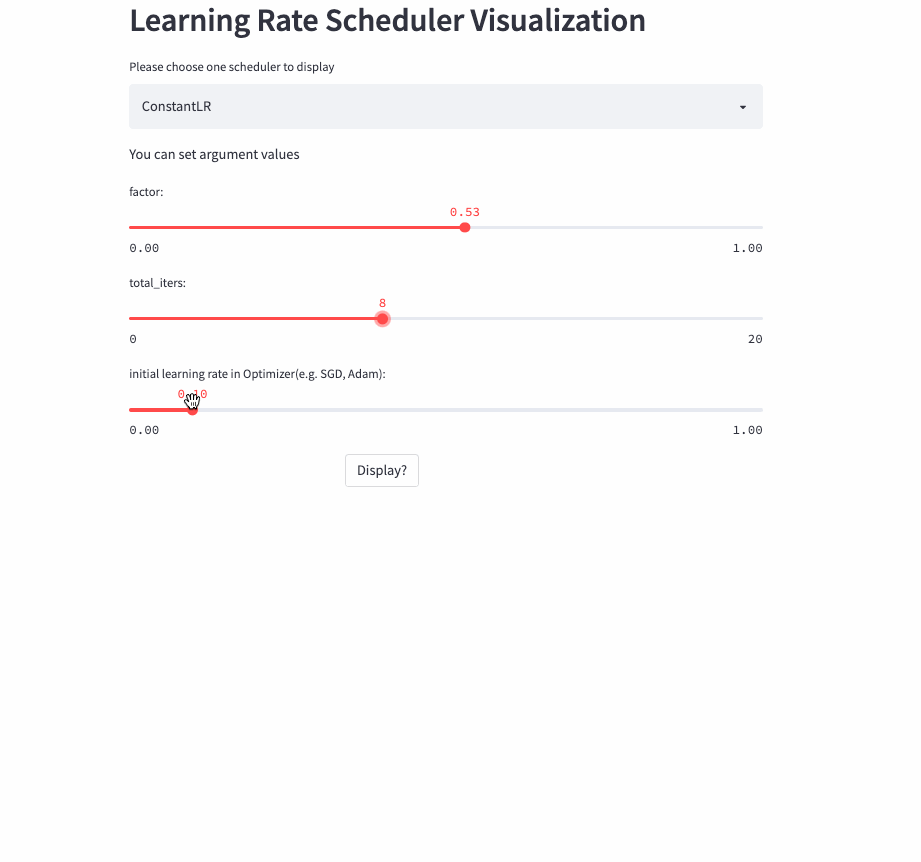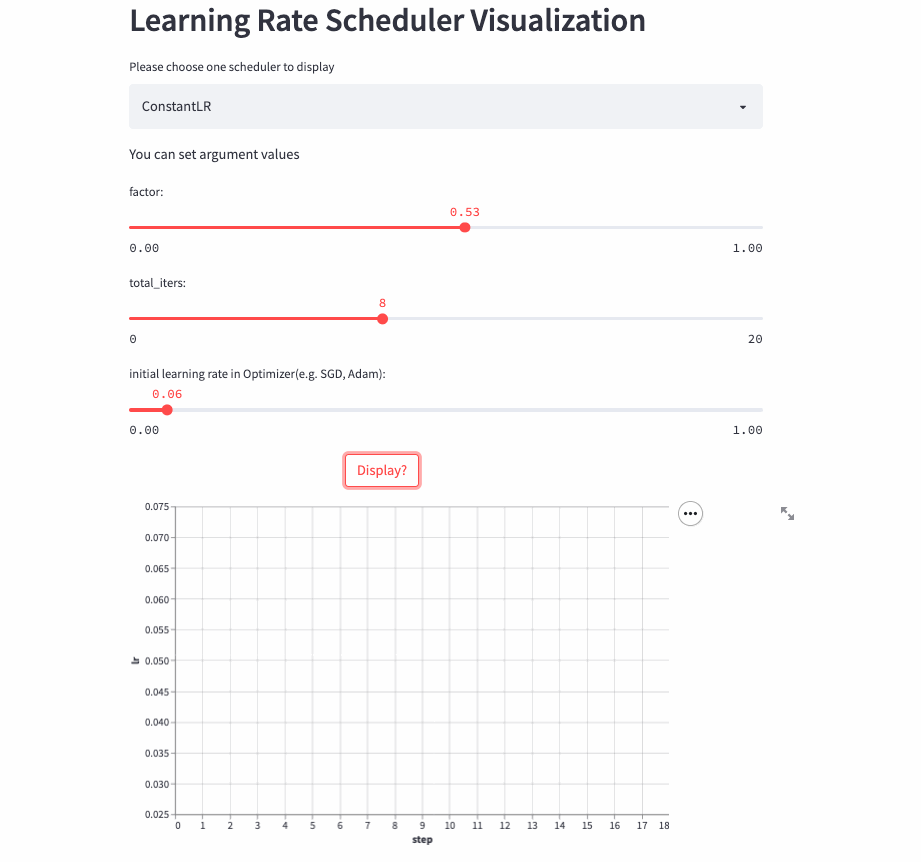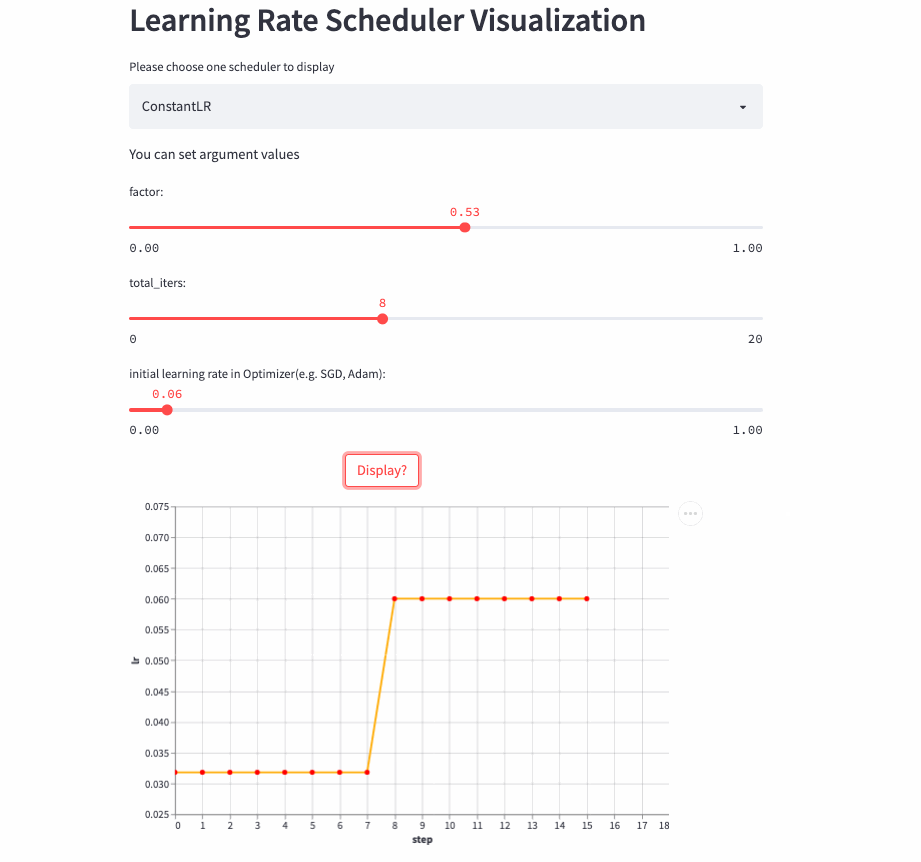
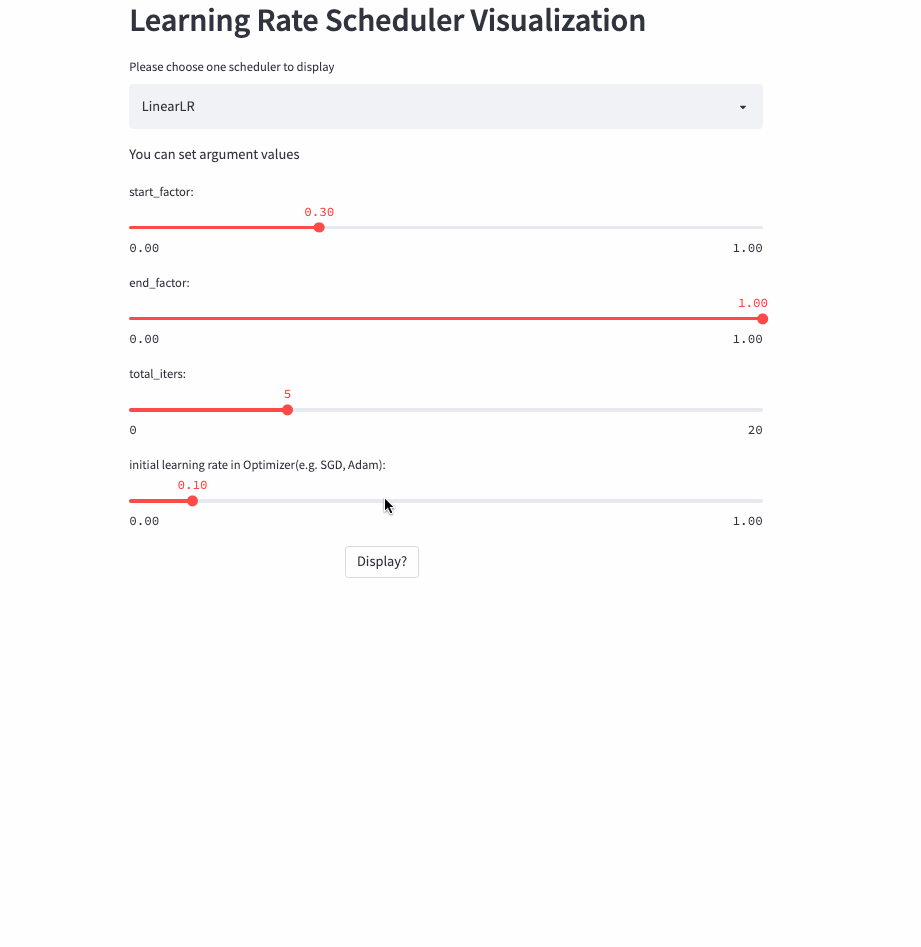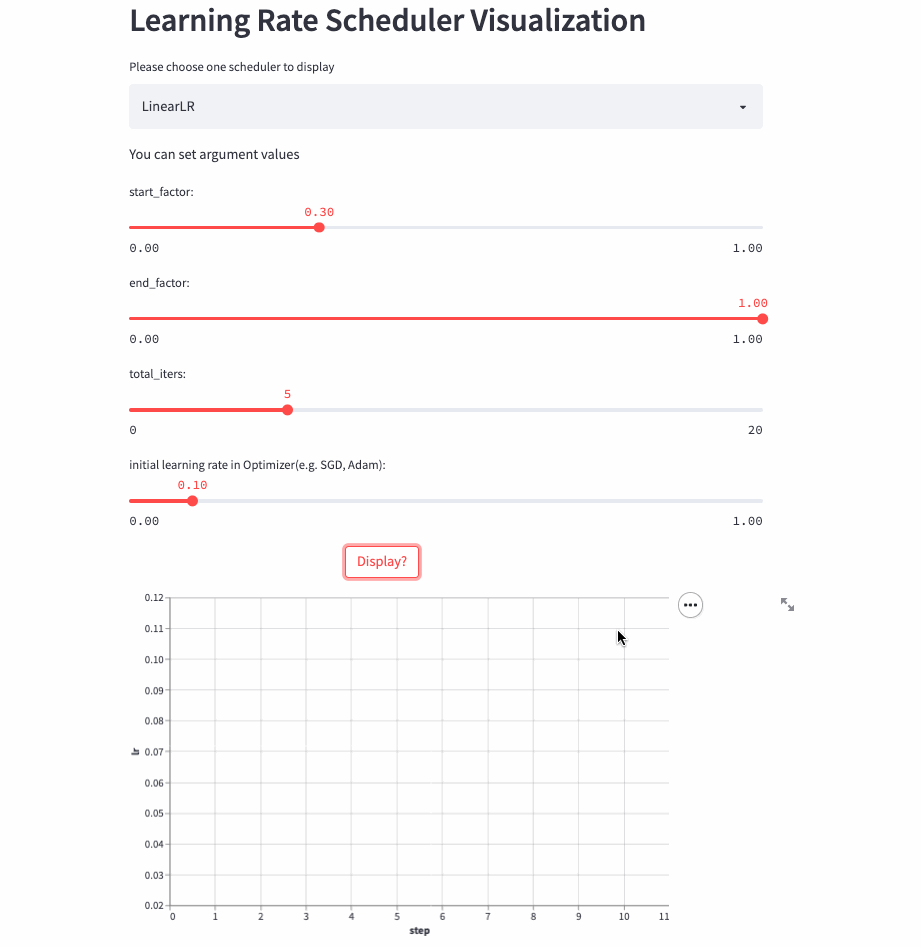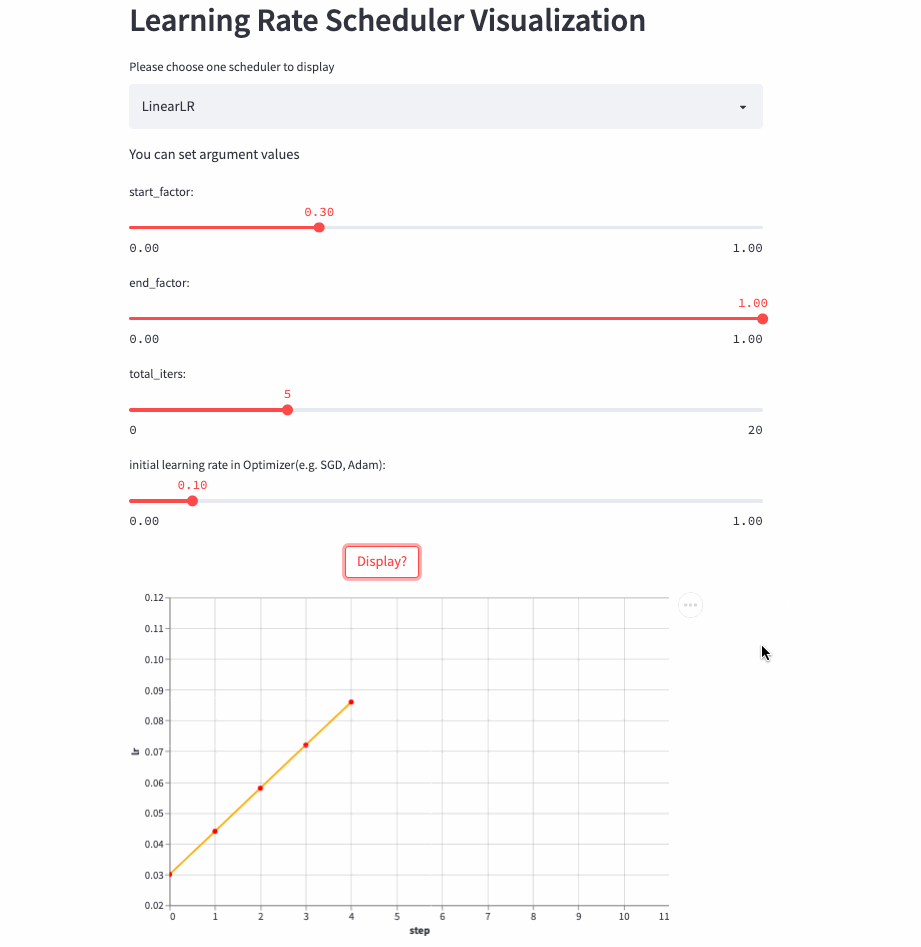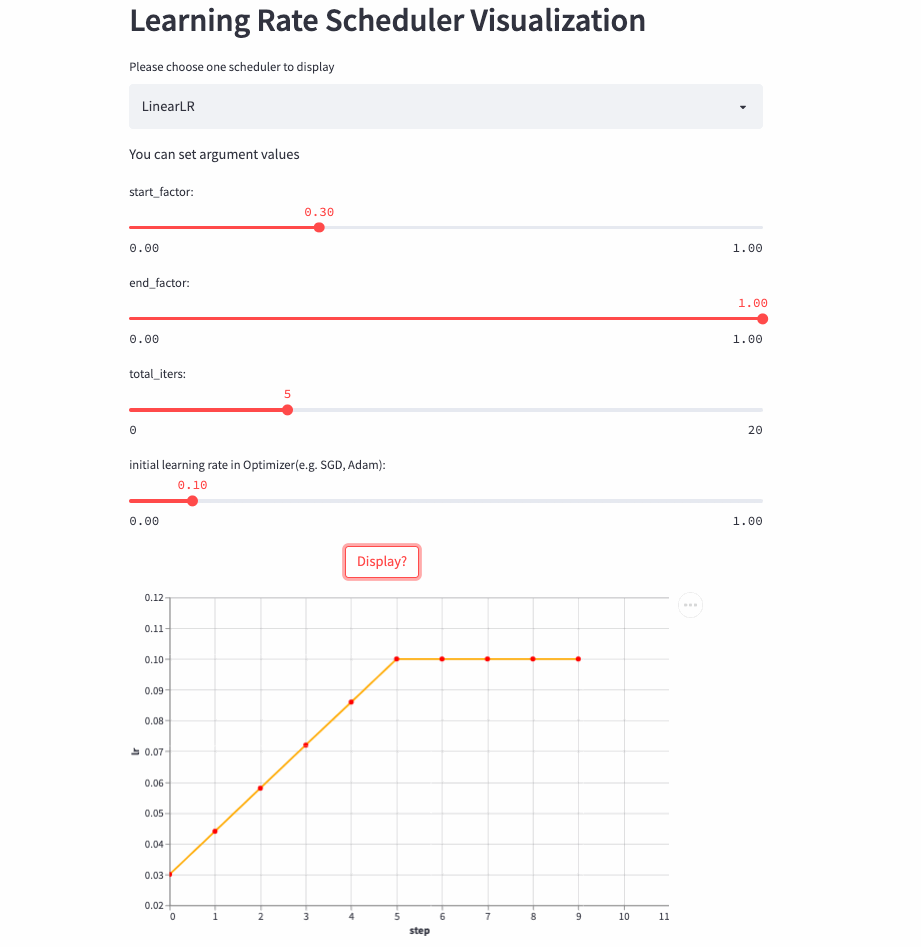
我将可视化代码分别托管在Hugging Face Spaces和Streamlit Cloud,大家可以任选一个链接访问,然后自由调节参数,感受学习率的变化过程。
-
https://huggingface.co/spaces/basicv8vc/learning-rate-scheduler-online
-
https://share.streamlit.io/basicv8vc/scheduler-online
2
学习率调整策略
学习率可以说是训练神经网络过程中最重要的参数(之一),目前大家都已接受用动态学习率调整策略来代替固定学习率,各种学习率调整策略层出不穷,下面我们就以OneFlow v0.7.0为例,学习下常用的几种策略。
基类LRScheduler
LRScheduler(optimizer: Optimizer, last_step: int = -1, verbose: bool = False)是所有学习率调度器的基类,初始化参数中last_step和verbose一般不需要设置,前者主要和checkpoint相关,后者则是在每次step() 调用时打印学习率,可以用于 debug。LRScheduler中最重要的方法是step(),这个方法的作用就是修改用户设置的初始学习率,然后应用到下一次的Optimizer.step()。
有些资料会讲LRScheduler根据epoch或iteration/step来调整学习率,两种说法都没问题,实际上,LRScheduler并不知道当前训练到第几个epoch或第几个iteration/step,只记录了调用step()的次数(last_step),如果每个epoch调用一次,那就是根据epoch来调整学习率,如果每个mini-batch调用一次,那就是根据iteration来调整学习率。以训练Transformer模型为例,需要在每个iteration调用step()。
简单来说,LRScheduler根据调整策略本身、当前调用step()的次数(last_step)和用户设置的初始学习率来得到下一次梯度更新时的学习率。
ConstantLR
ConstantLR和固定学习率差不多,唯一的区别是在前total_iters,学习率为初始学习率 * factor。
注意:由于factor取值[0, 1],所以这是一个学习率递增的策略。
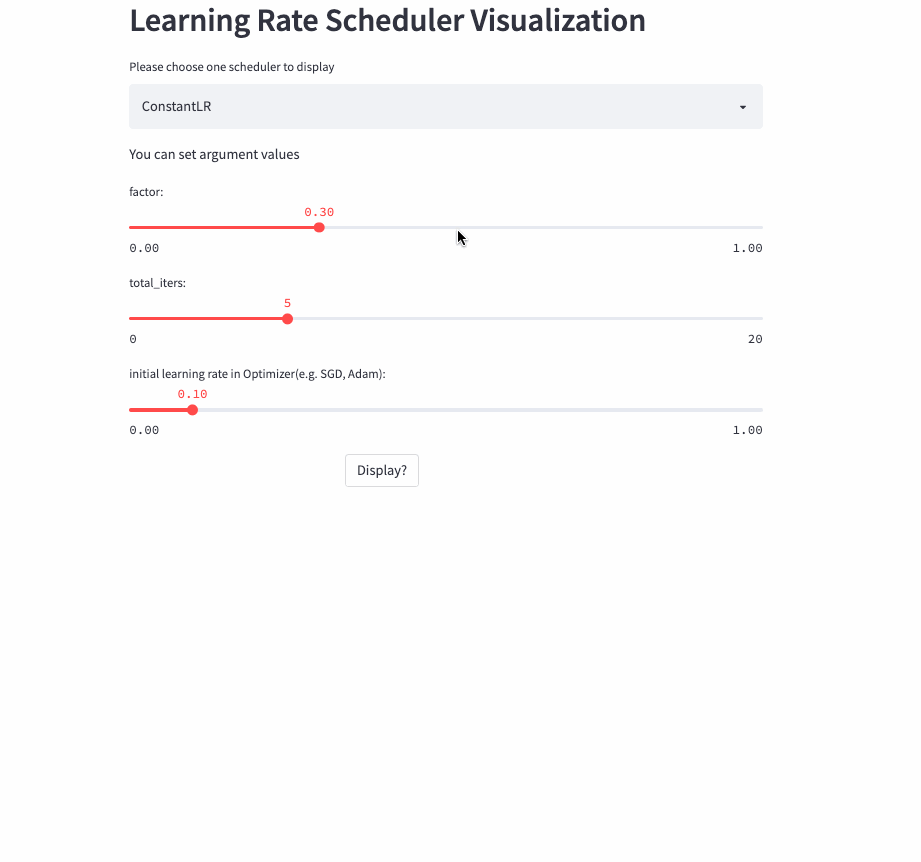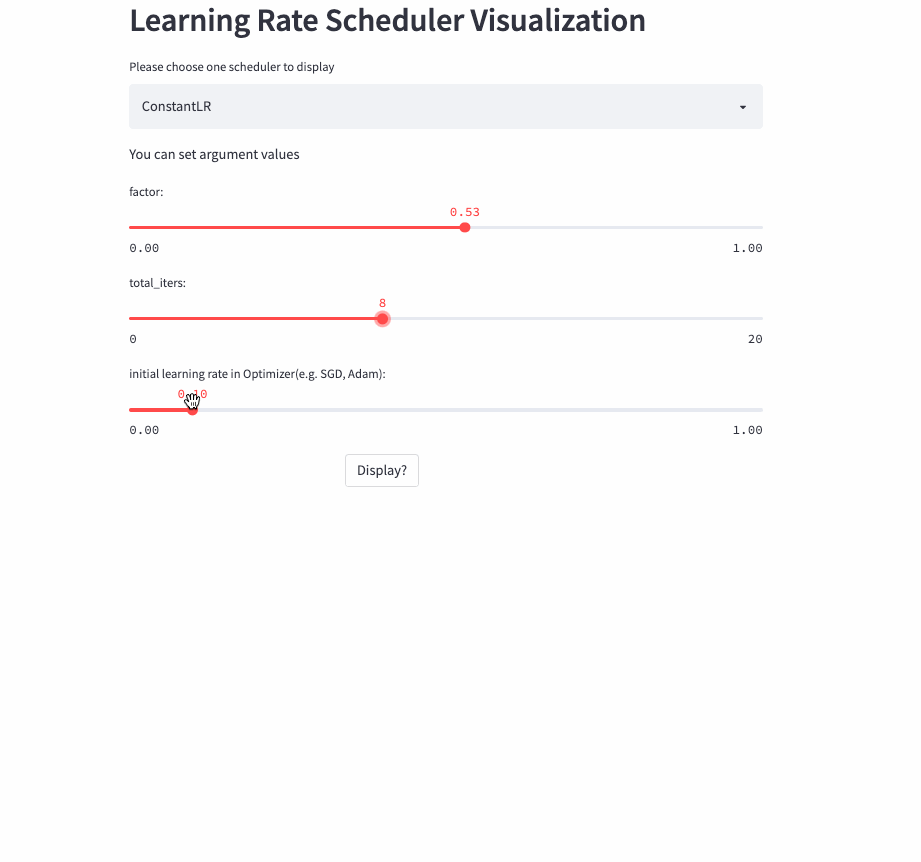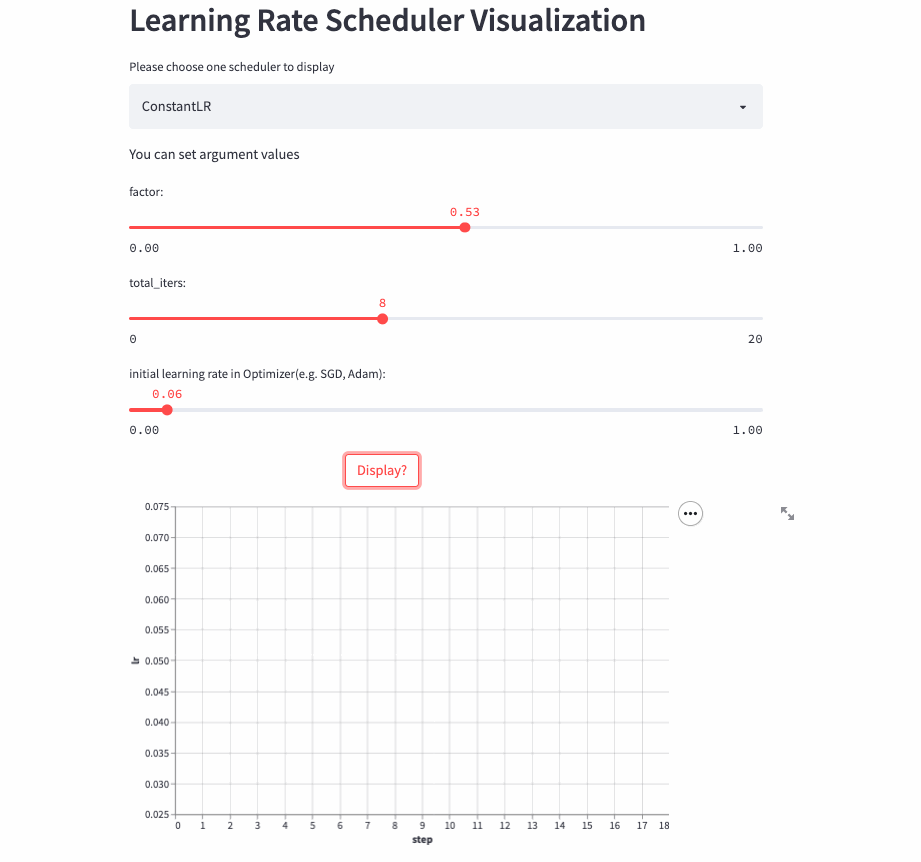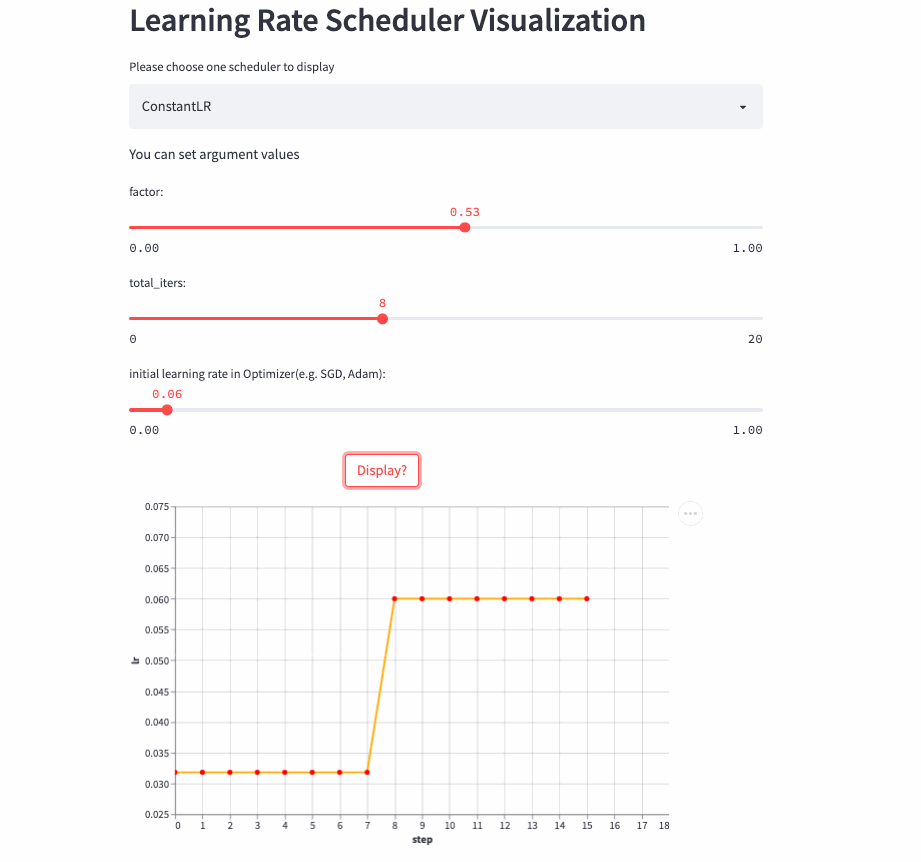
ConstantLR
LinearLR
LinearLR和固定学习率也差不多,唯一的区别是在前total_iters,学习率先线性增加或递减,然后再固定为初始学习率 * end_factor。
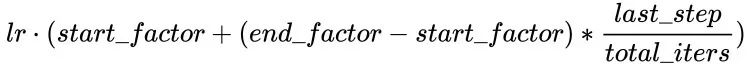
注意:学习率在前total_iters是递增or递减由start_factor和end_factor大小决定。
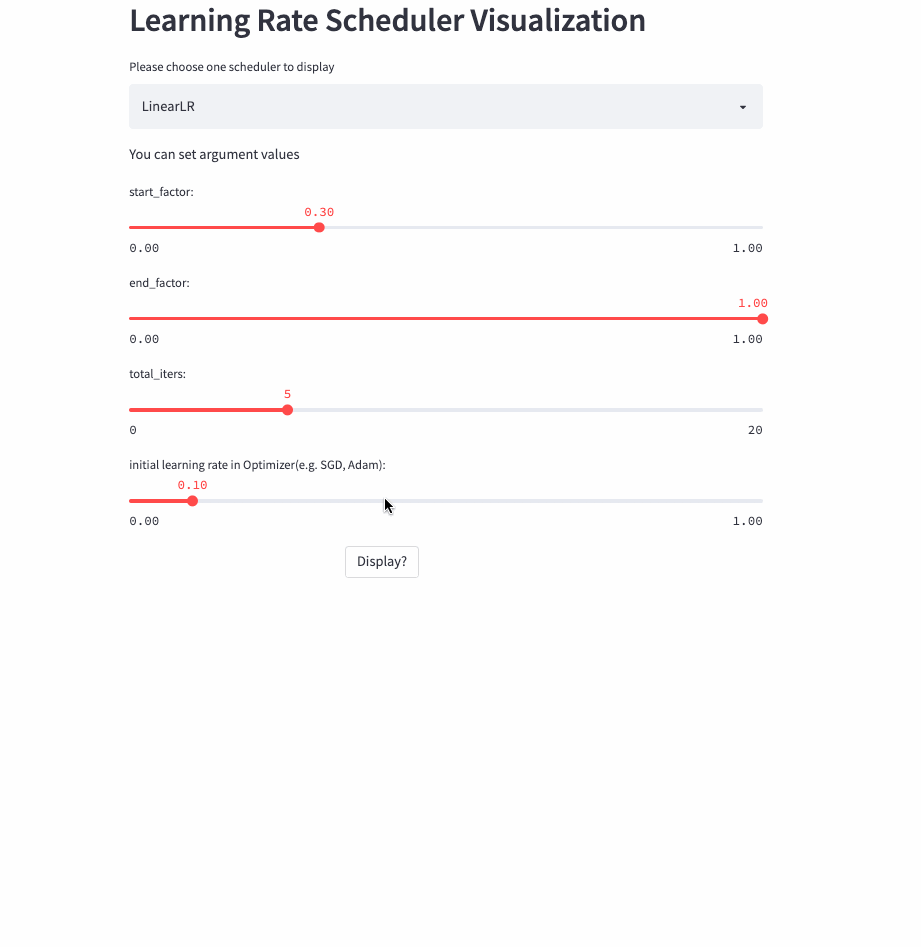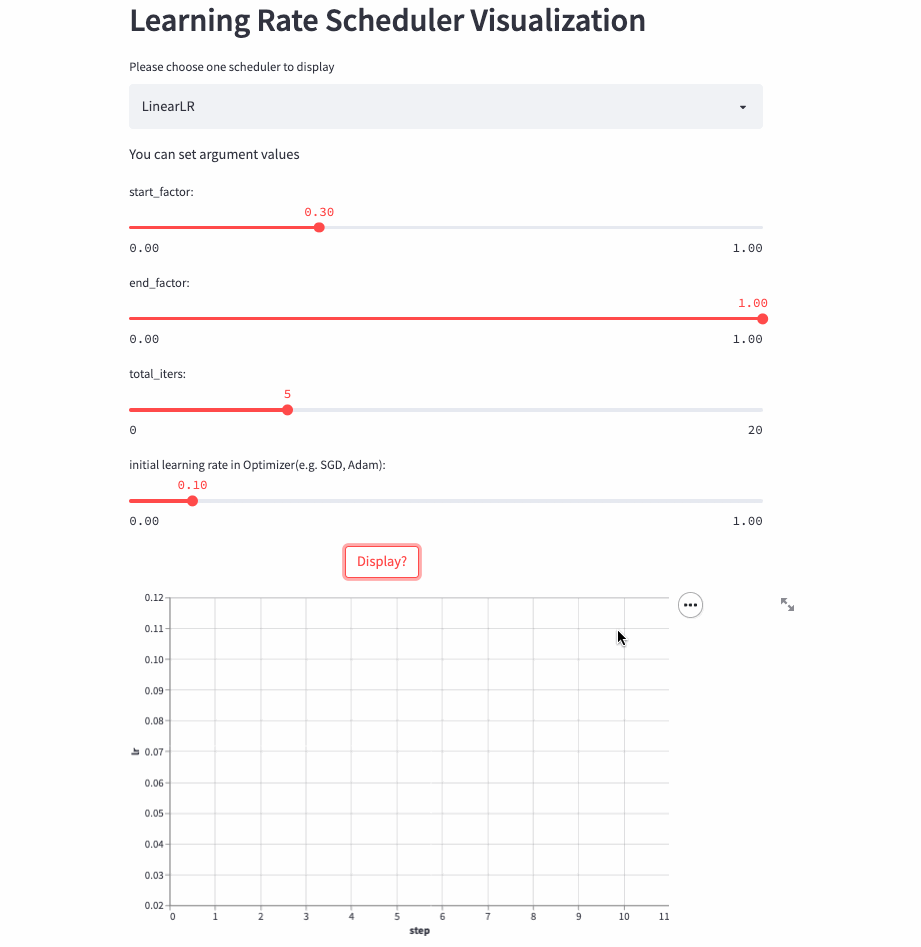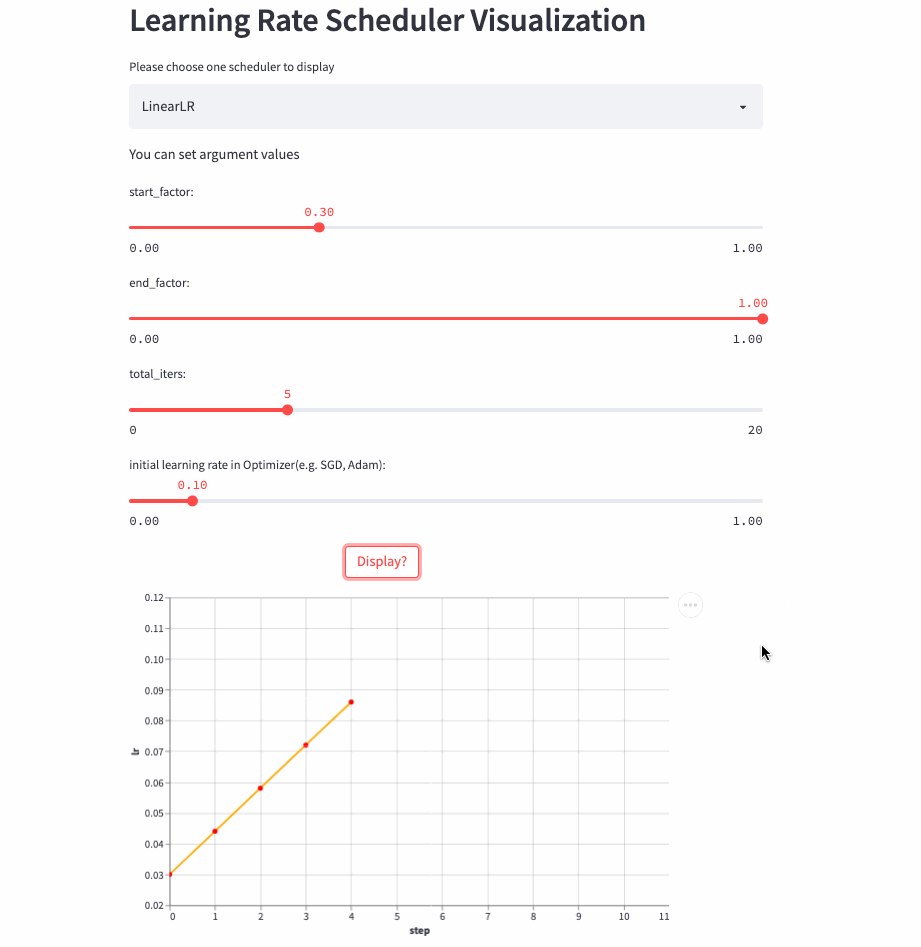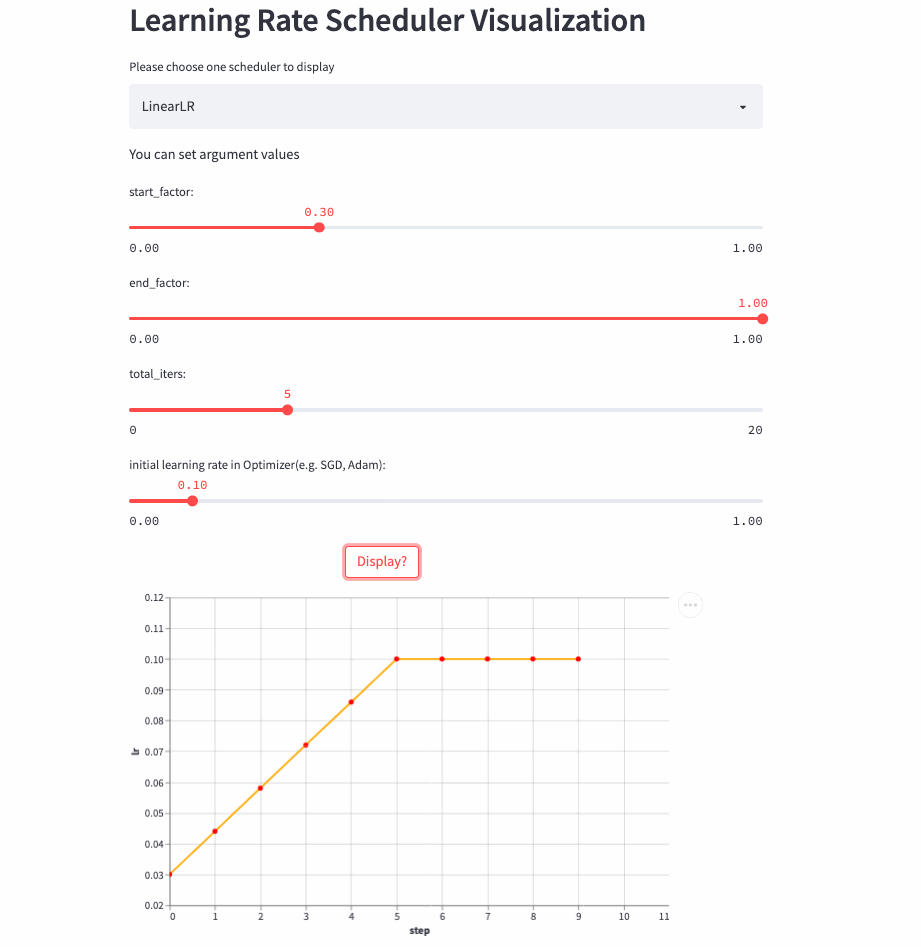
LinearLR
ExponentialLR
学习率呈指数衰减,当然也可以将gamma设置为>1,进行指数增加,不过估计没人愿意这么做。
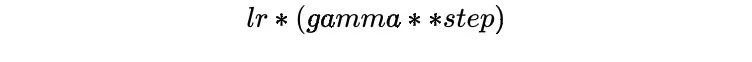
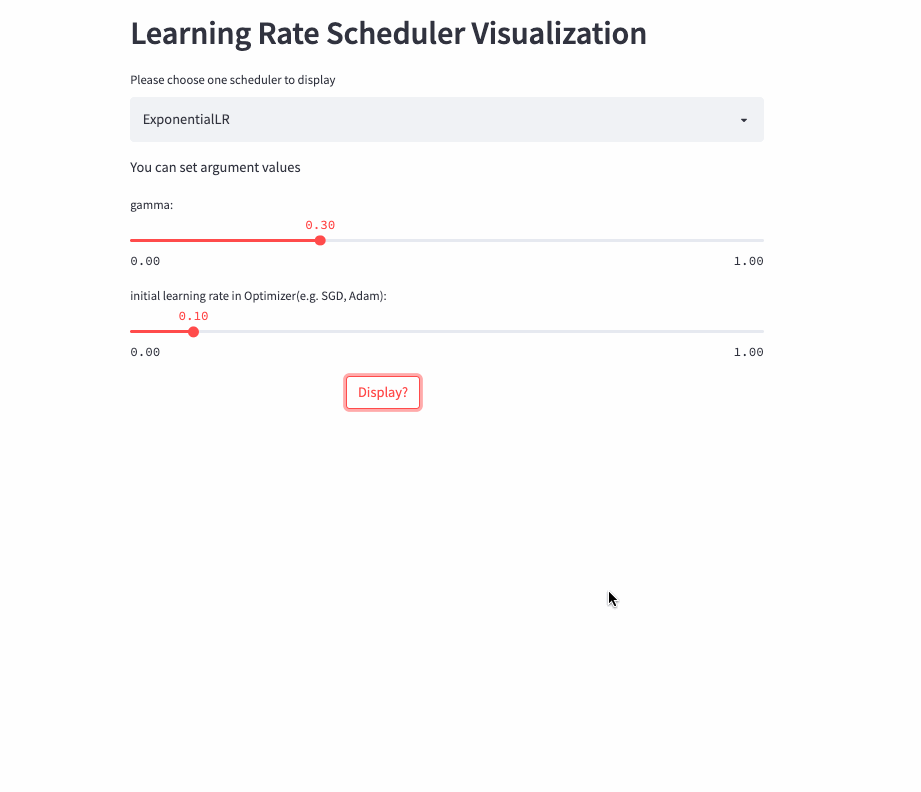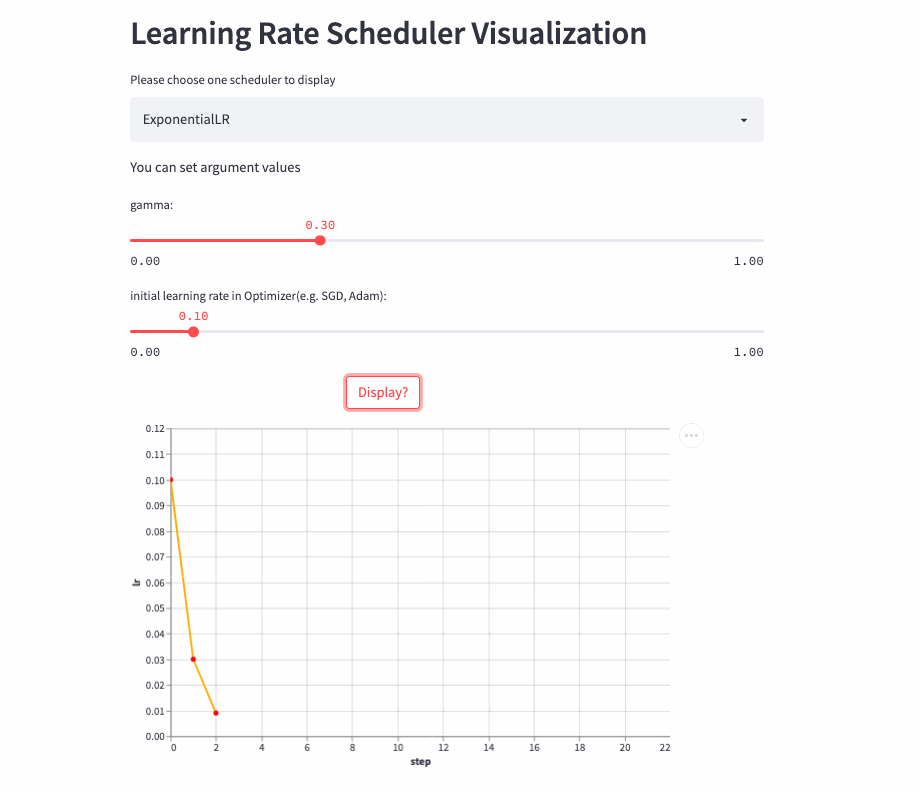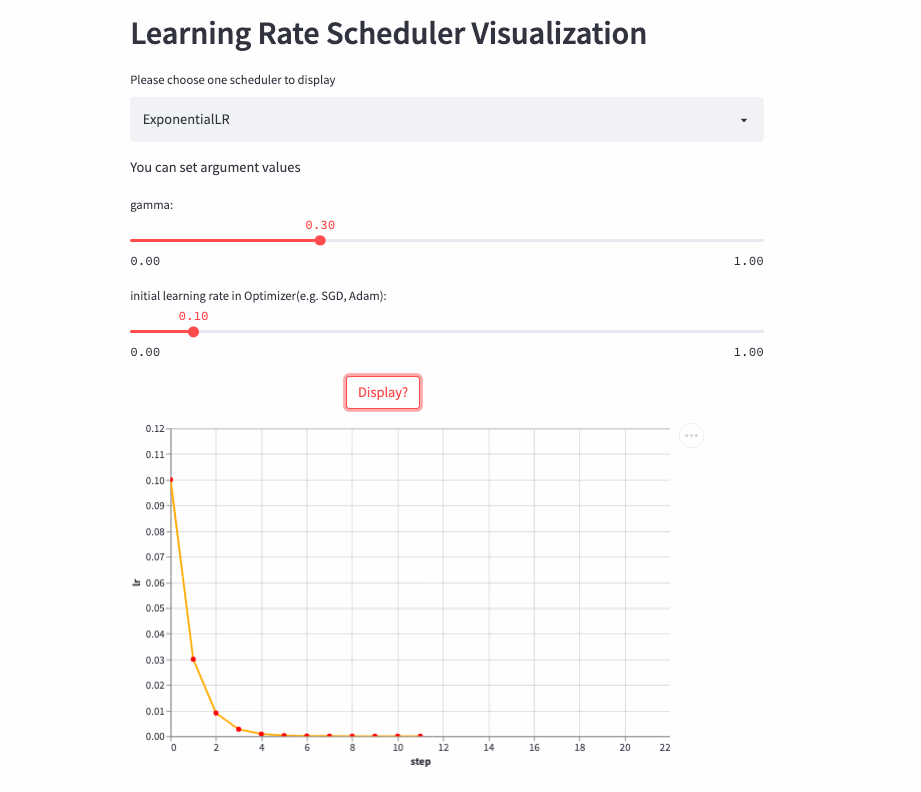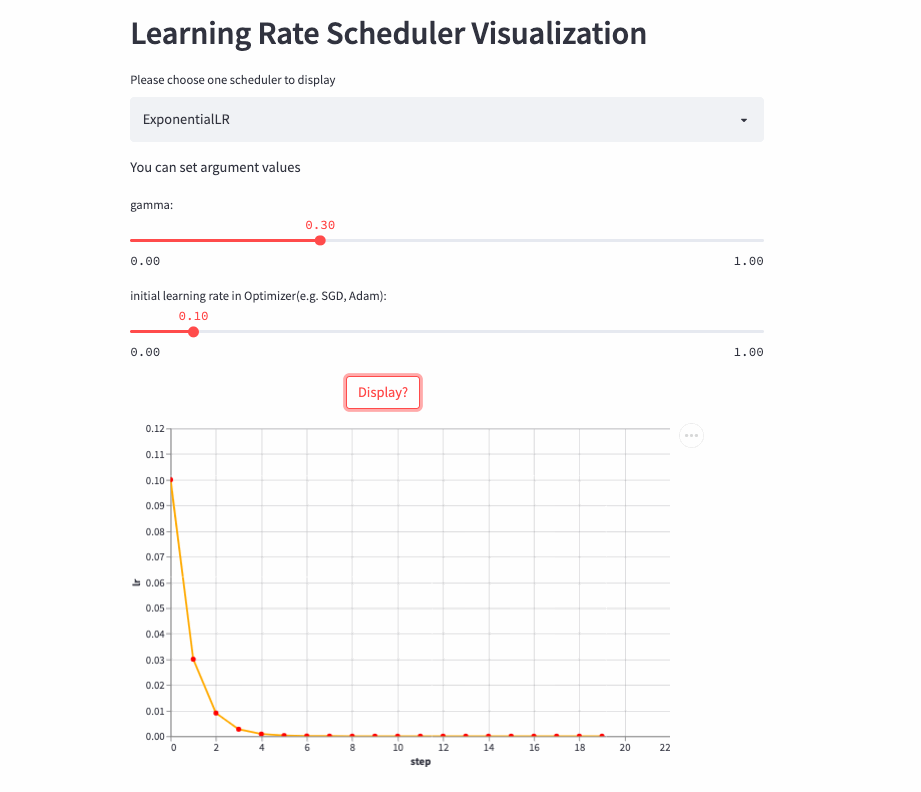
ExponentialLR
StepLR
StepLR和ExponentialLR差不多,区别是不是每一次调用step()都进行学习率调整,而是每隔step_size才调整一次。
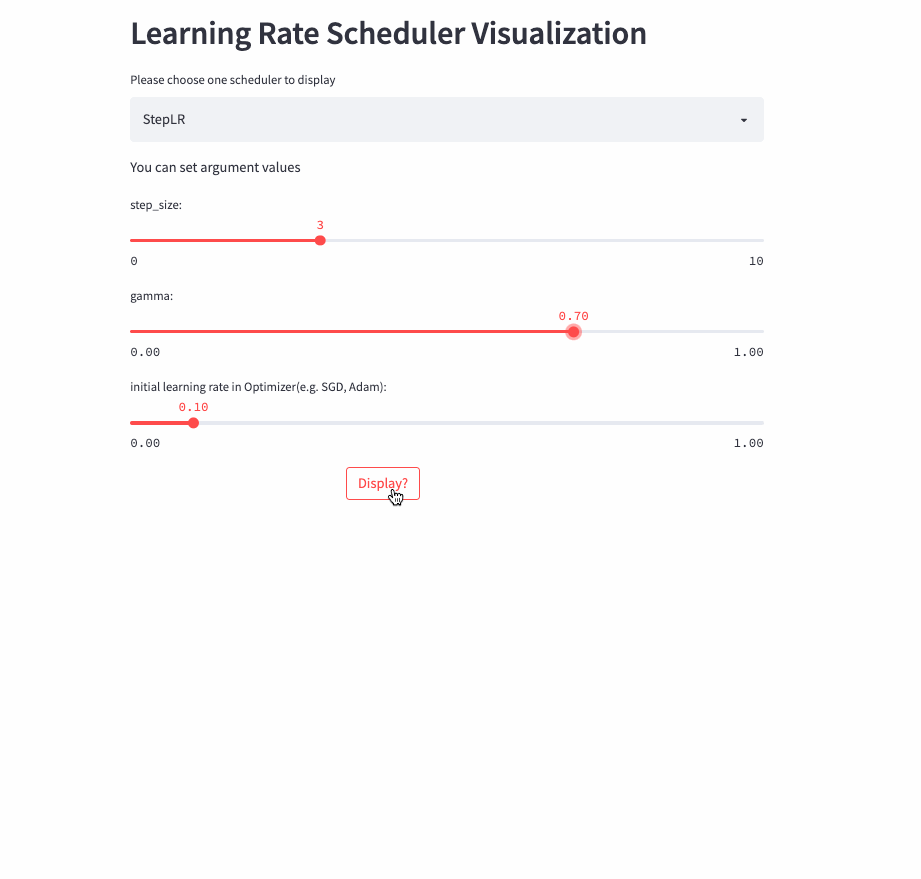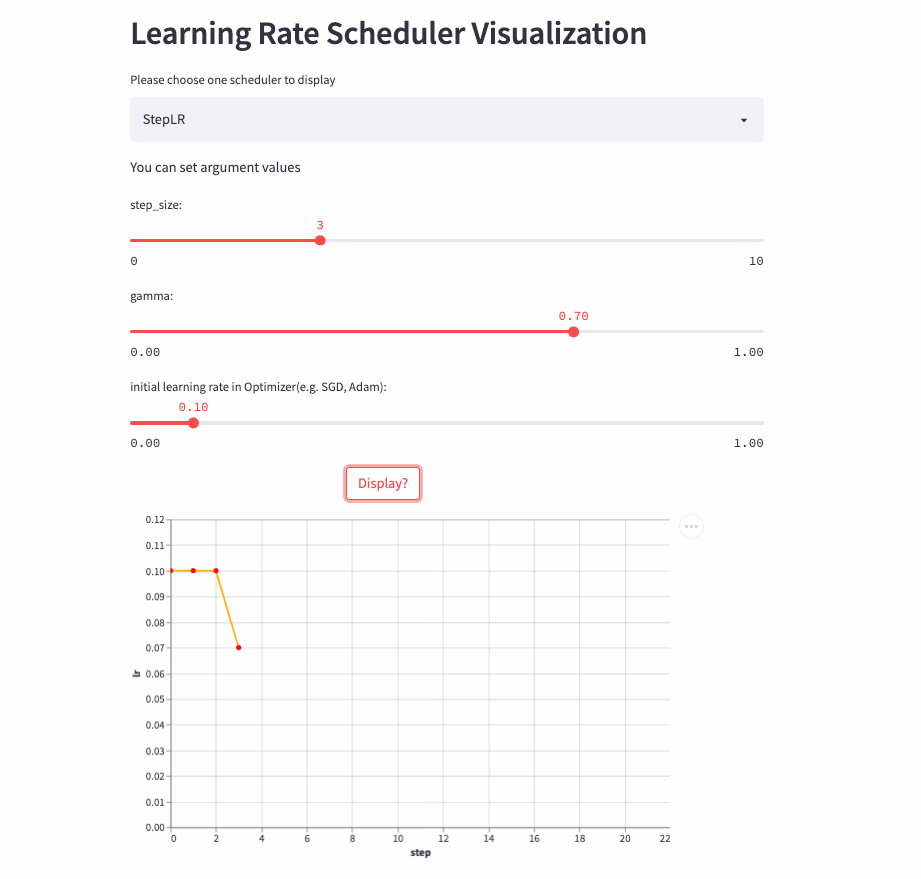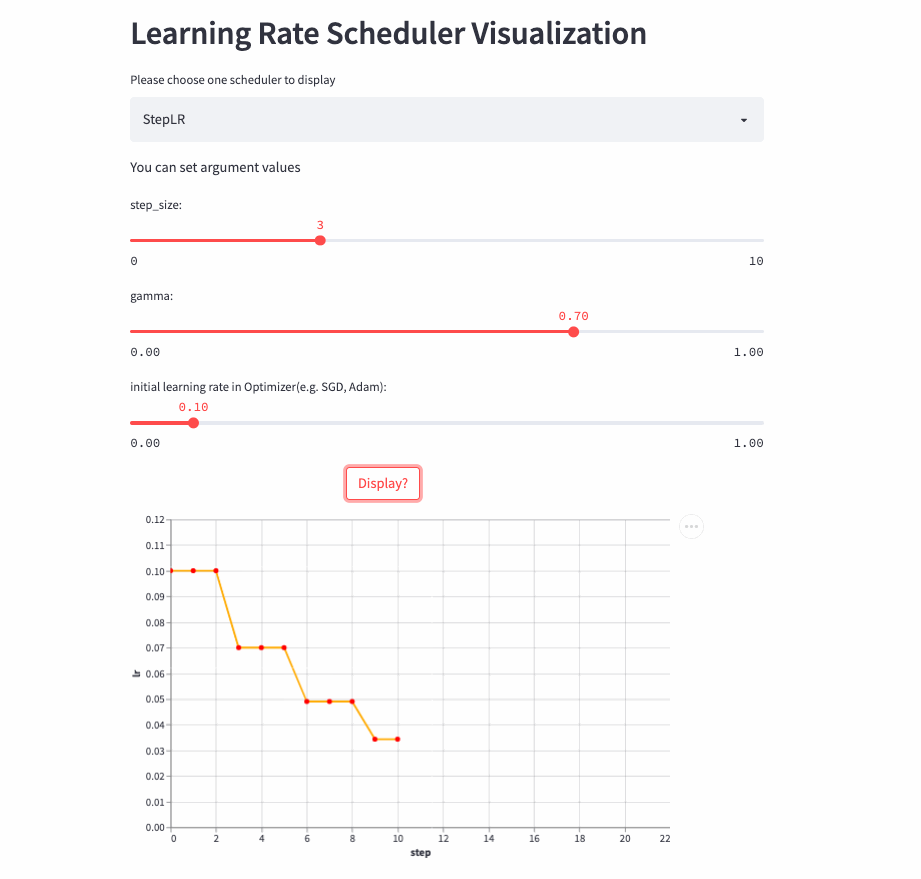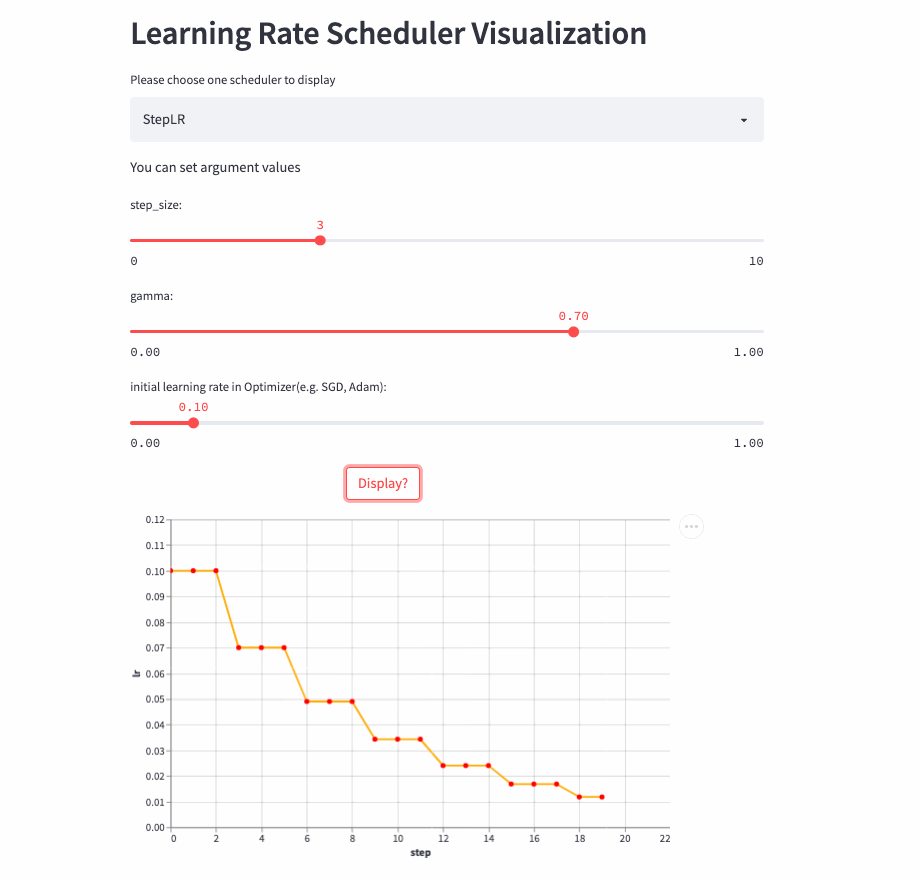
StepLR
MultiStepLR
StepLR每隔step_size就调整一次学习率,而MultiStepLR则根据用户指定的milestones进行调整,假设milestones是[2, 5, 9],在[0, 2)是lr,在[2, 5)是lr * gamma,在[5, 9)是lr * (gamma **2),在[9, )是lr * (gamma **3)。
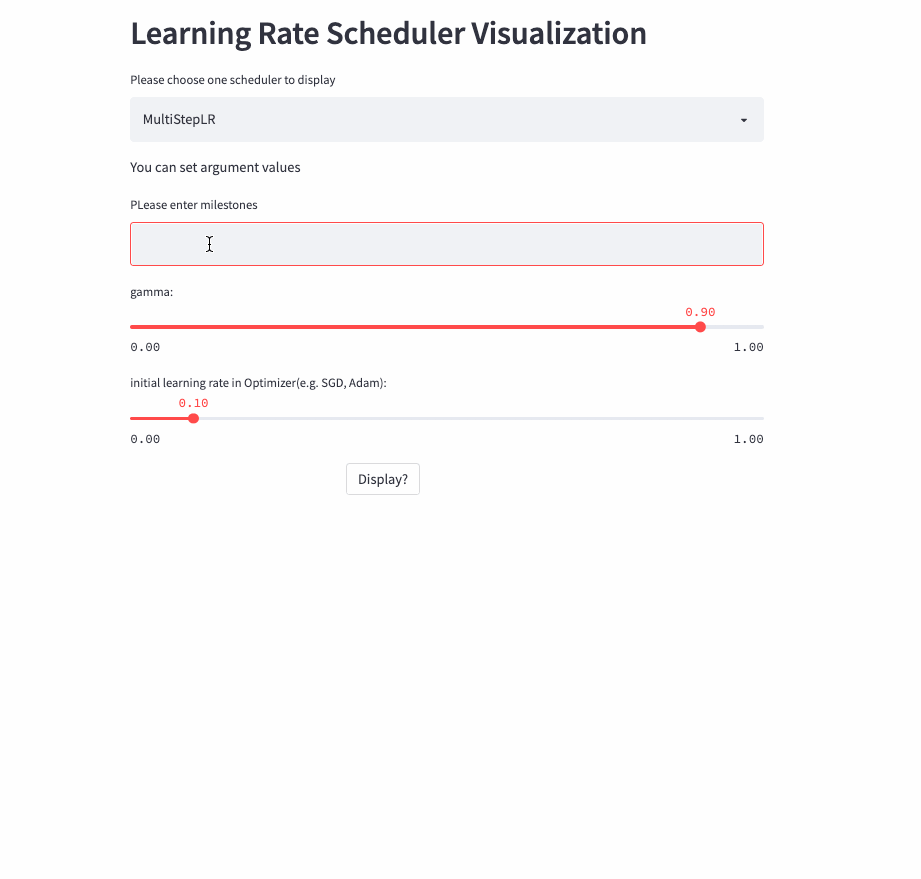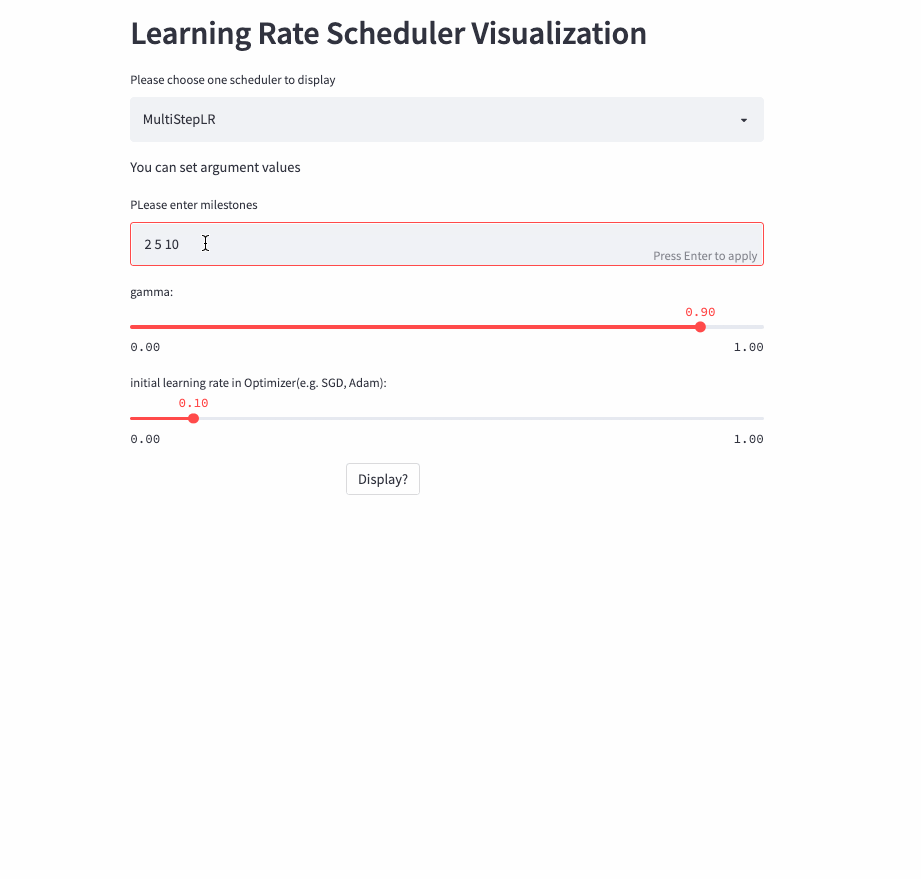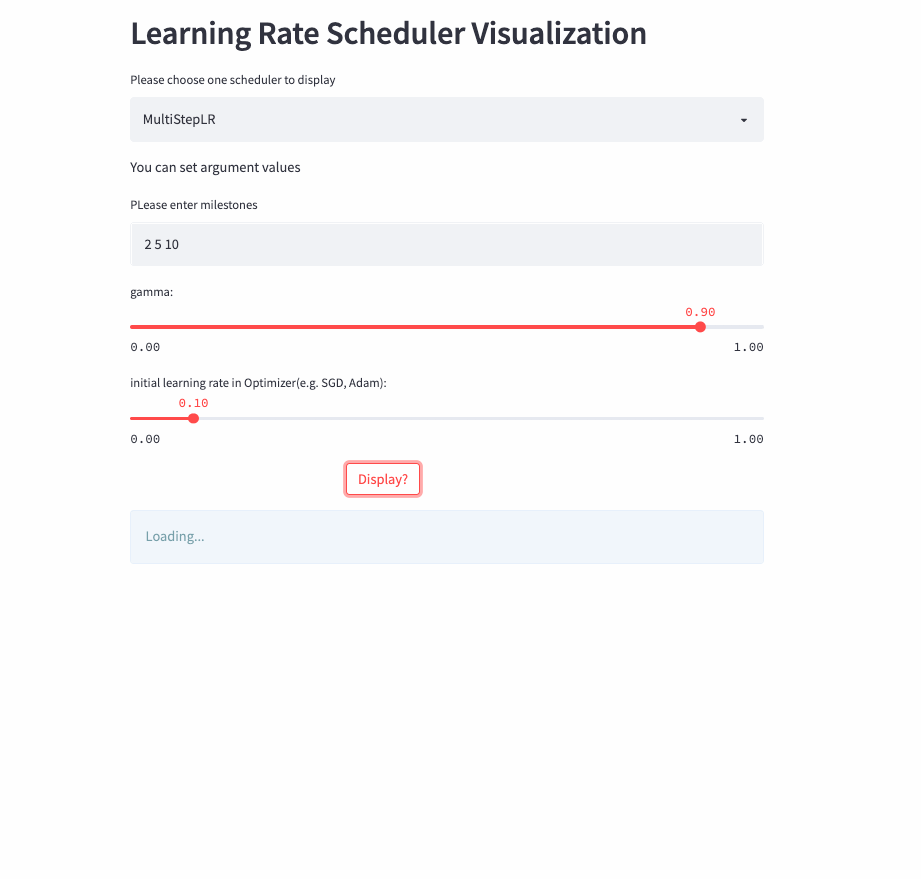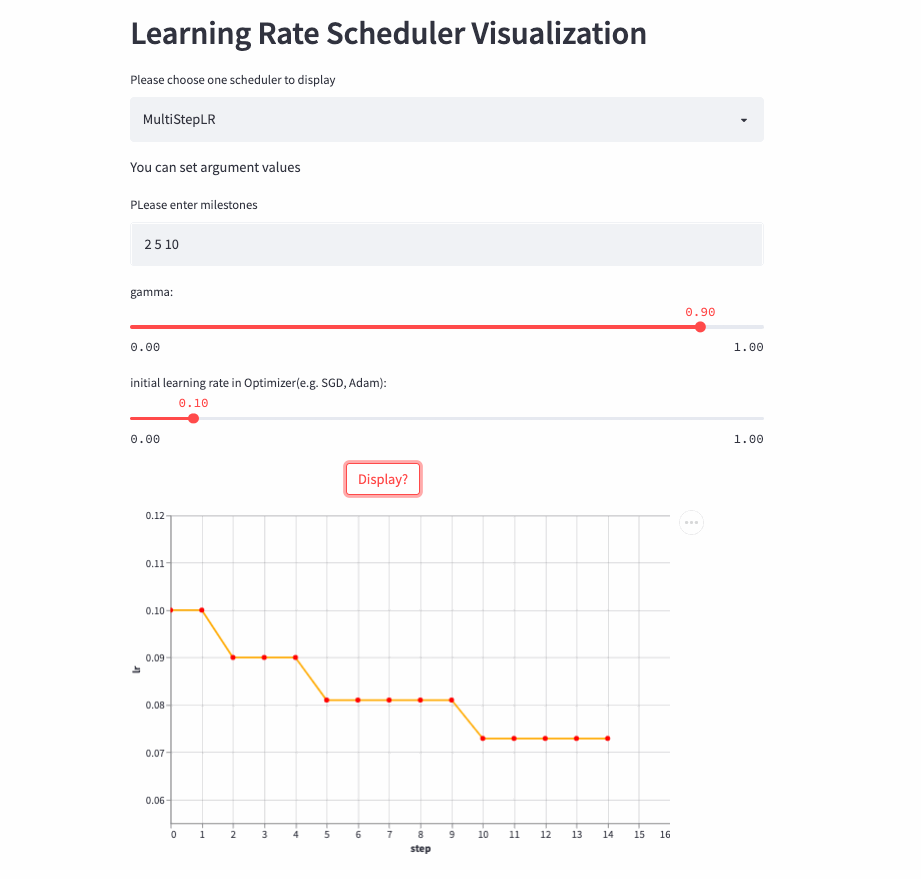
MultiStepLR
PolynomialLR
前面的学习率调整策略无非是线性或指数,PolynomialLR则根据多项式进行调整,先看cycle参数,默认是False,此时先根据多项式衰减然后再固定学习率,公式如下:
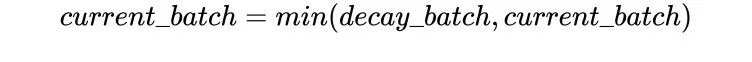
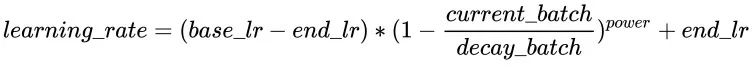
注:公式中的decay_batch就是steps,current_batch就是最新的last_step。
如果cycle是True,则稍微复杂点,类似于以steps为周期进行变化,每次从一个最大学习率衰减到end_learning_rate,每个周期的最大学习率也是逐渐衰减的,公式如下:
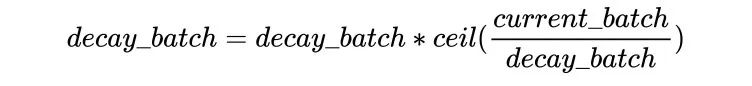
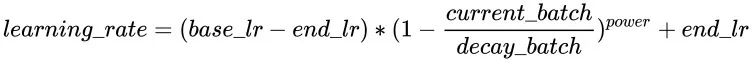
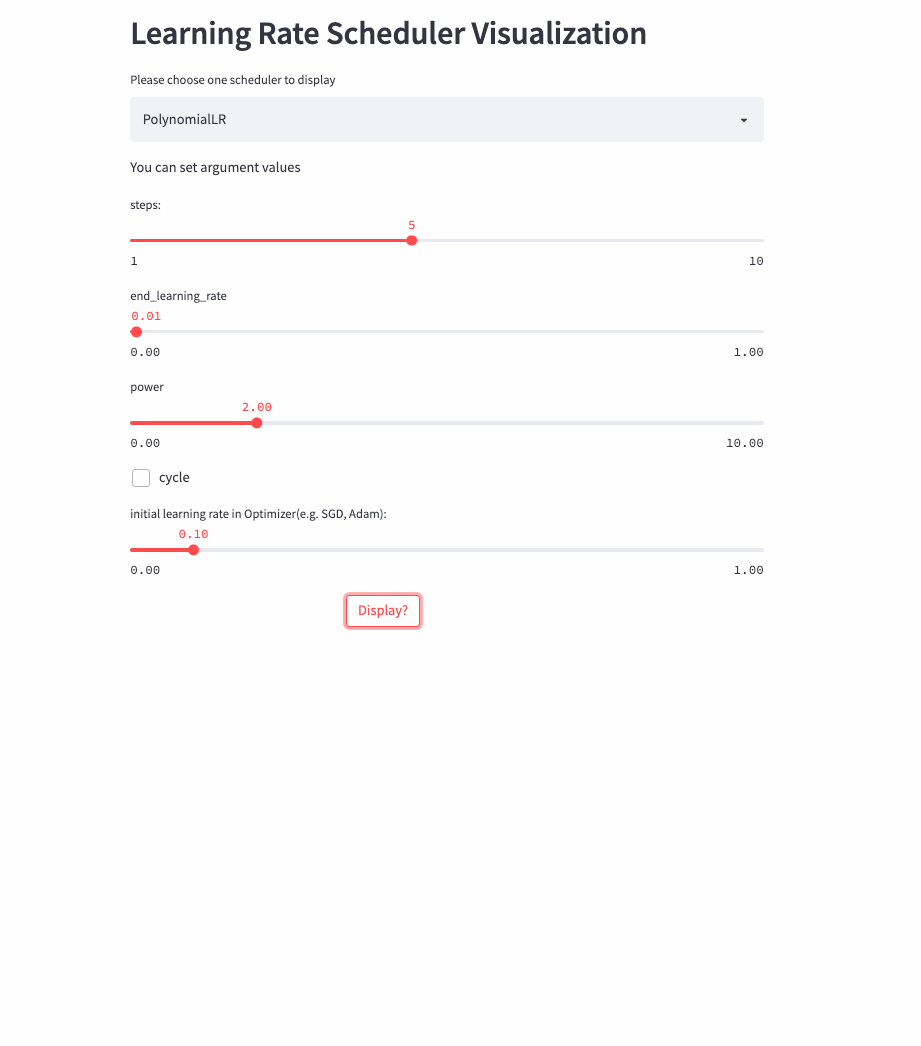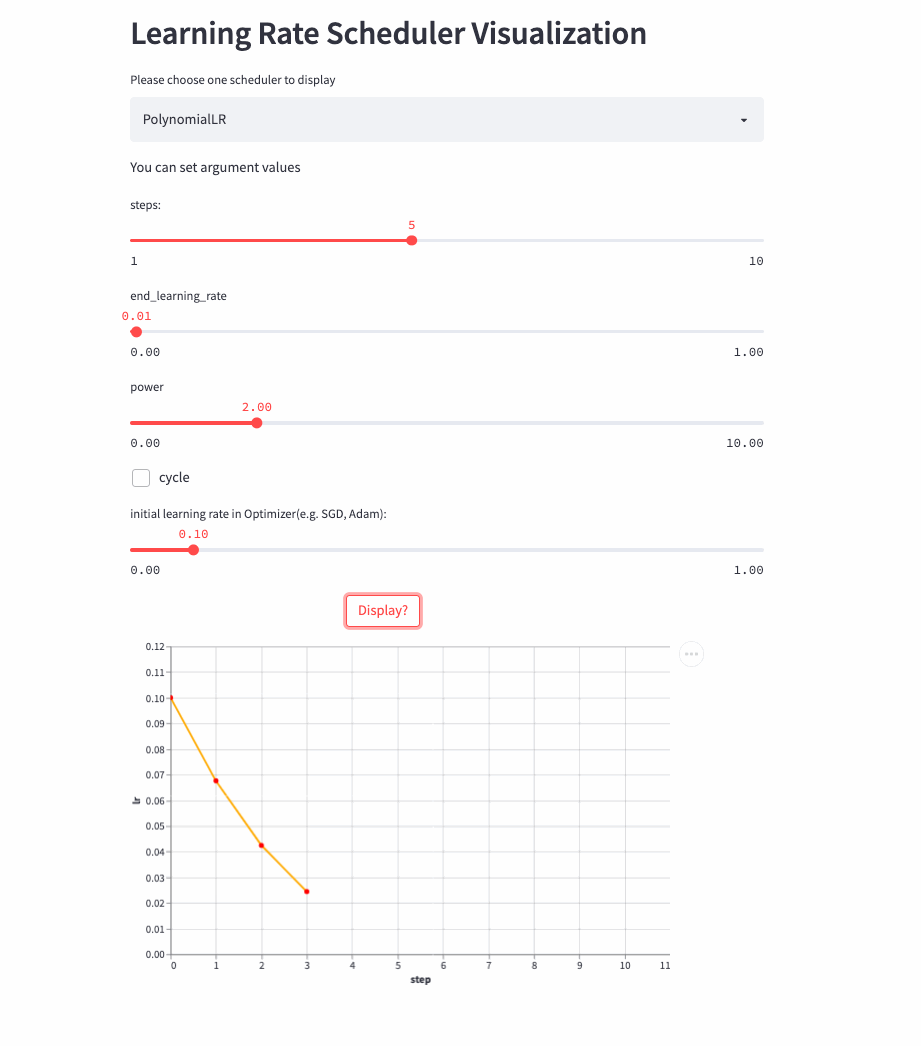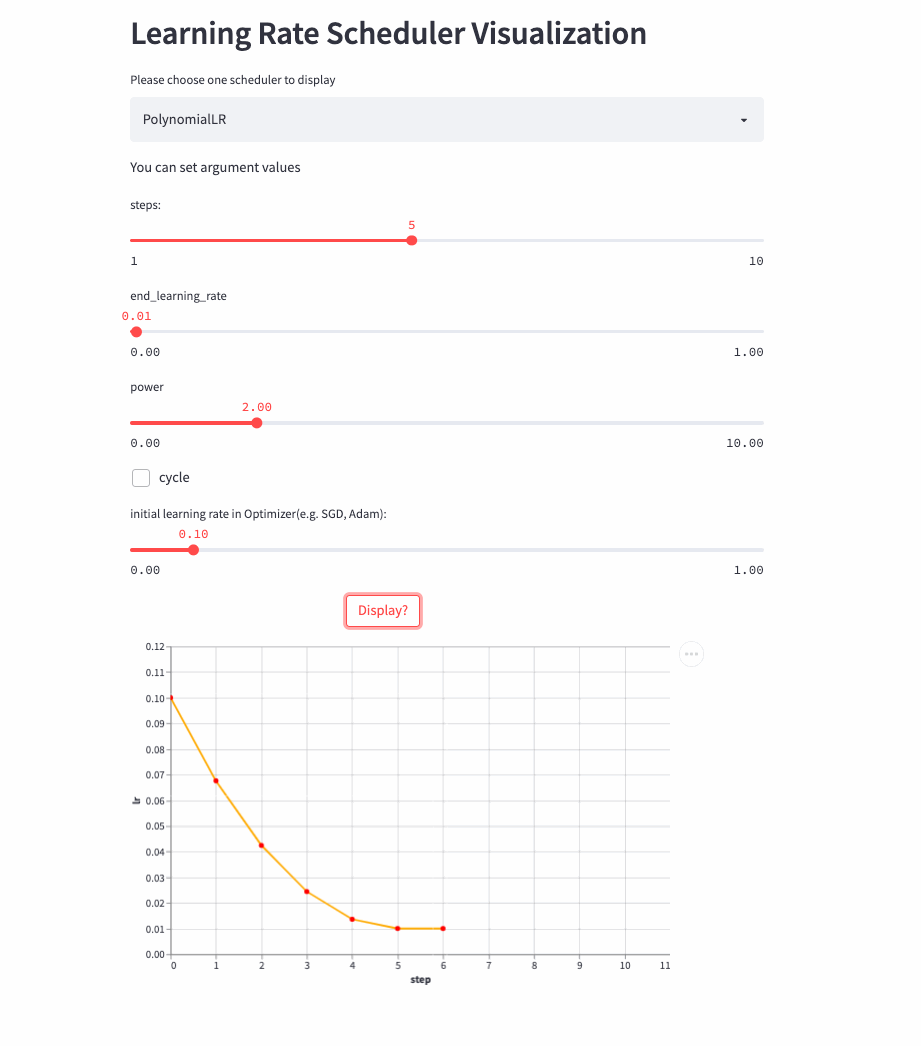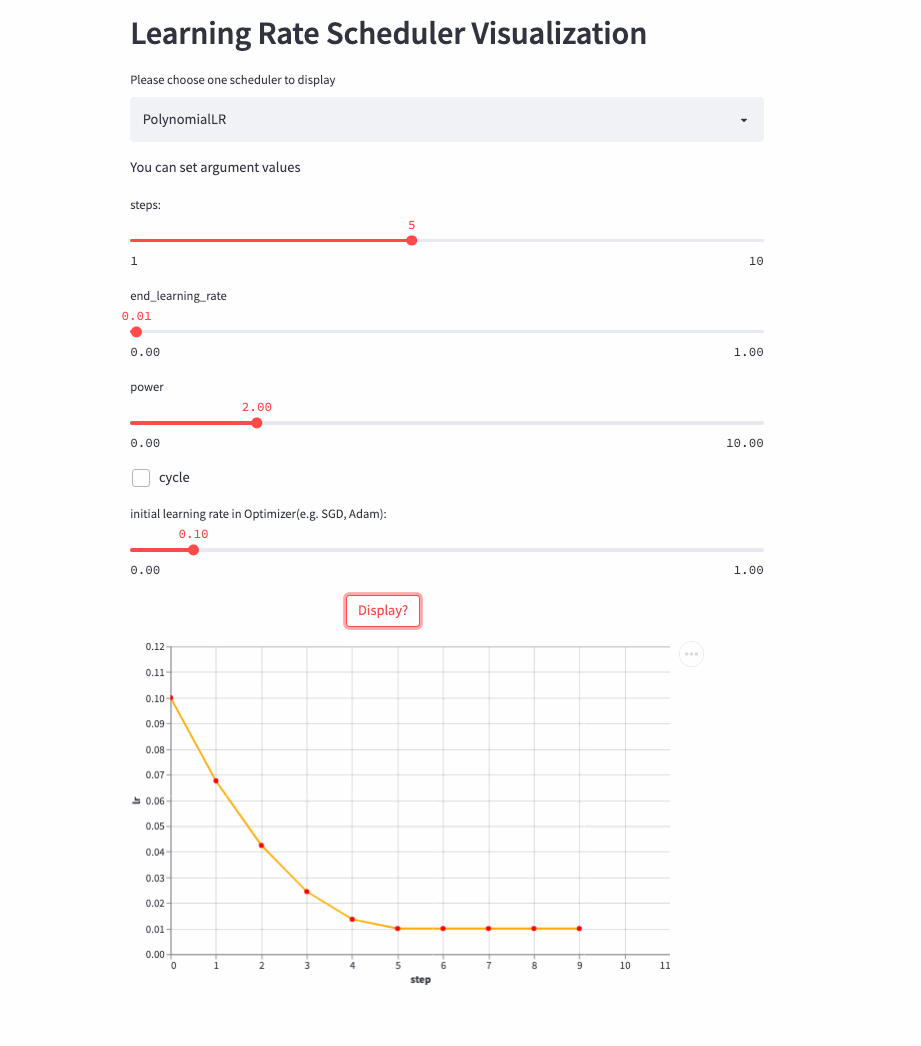
PolynomialLR
看下cycle=True的例子,
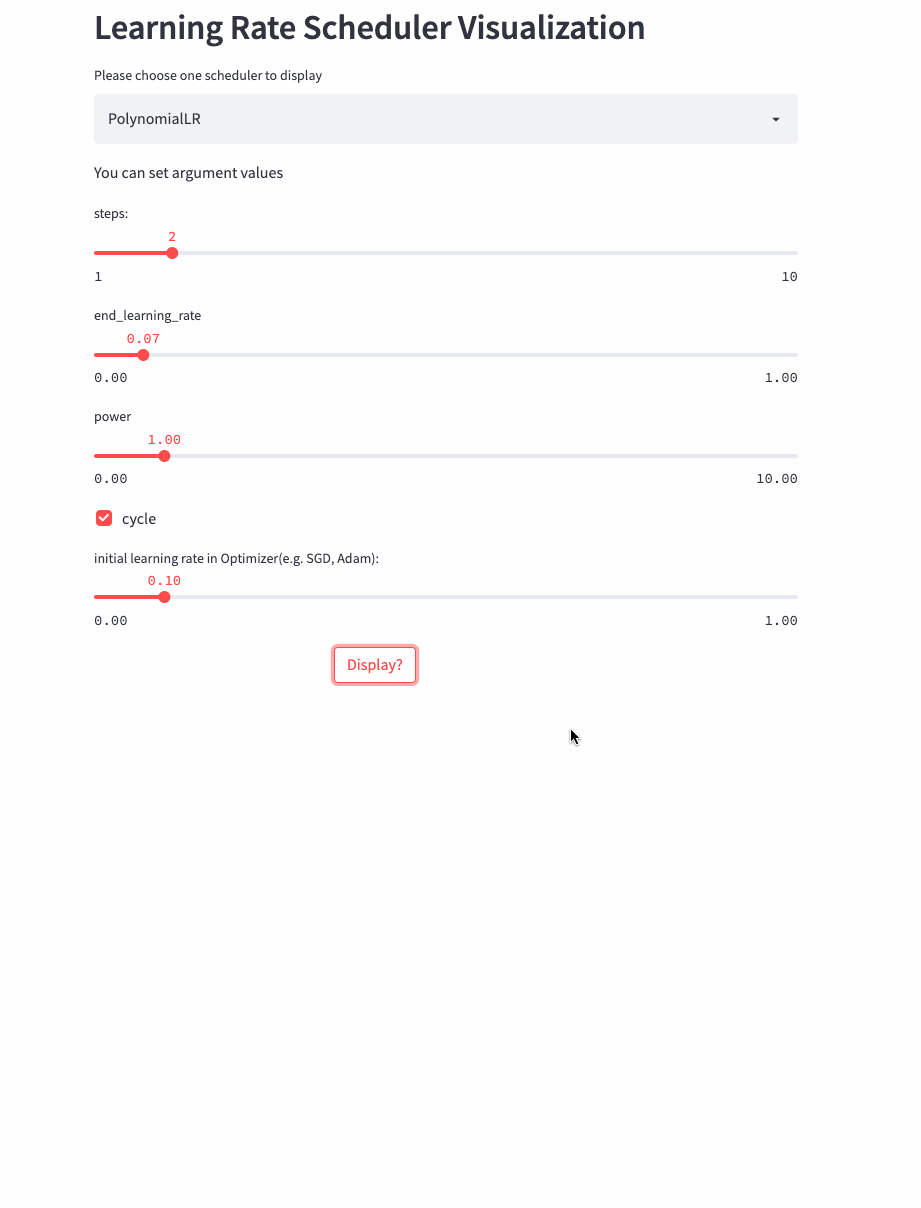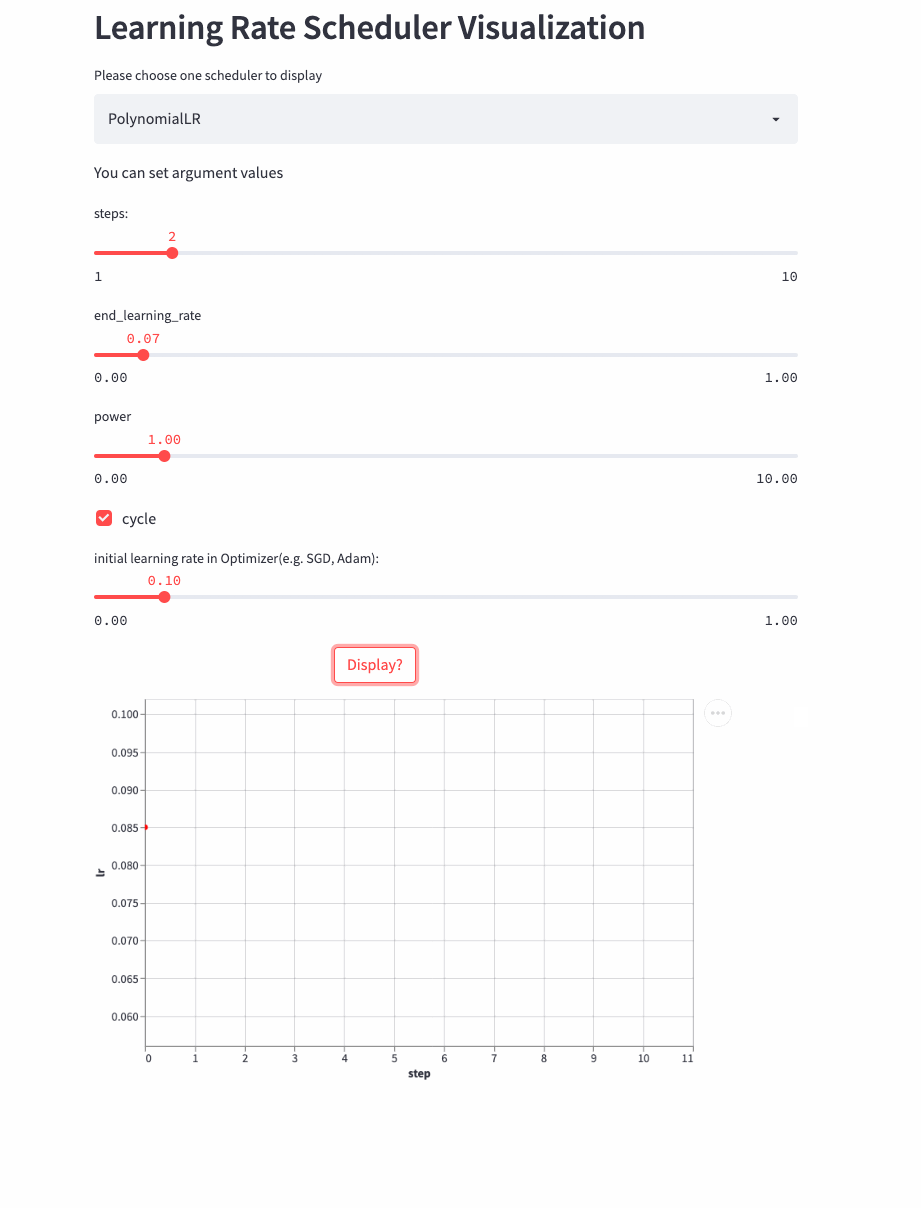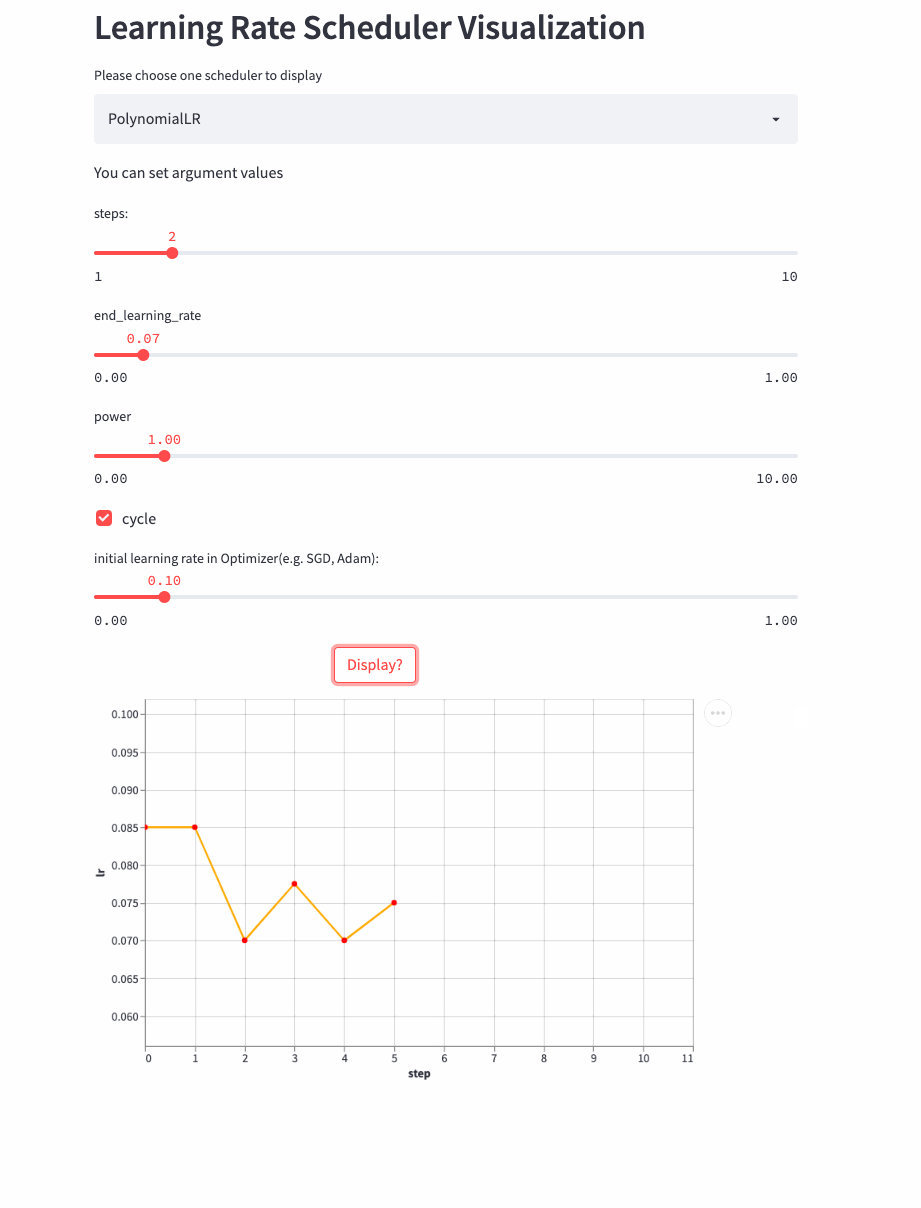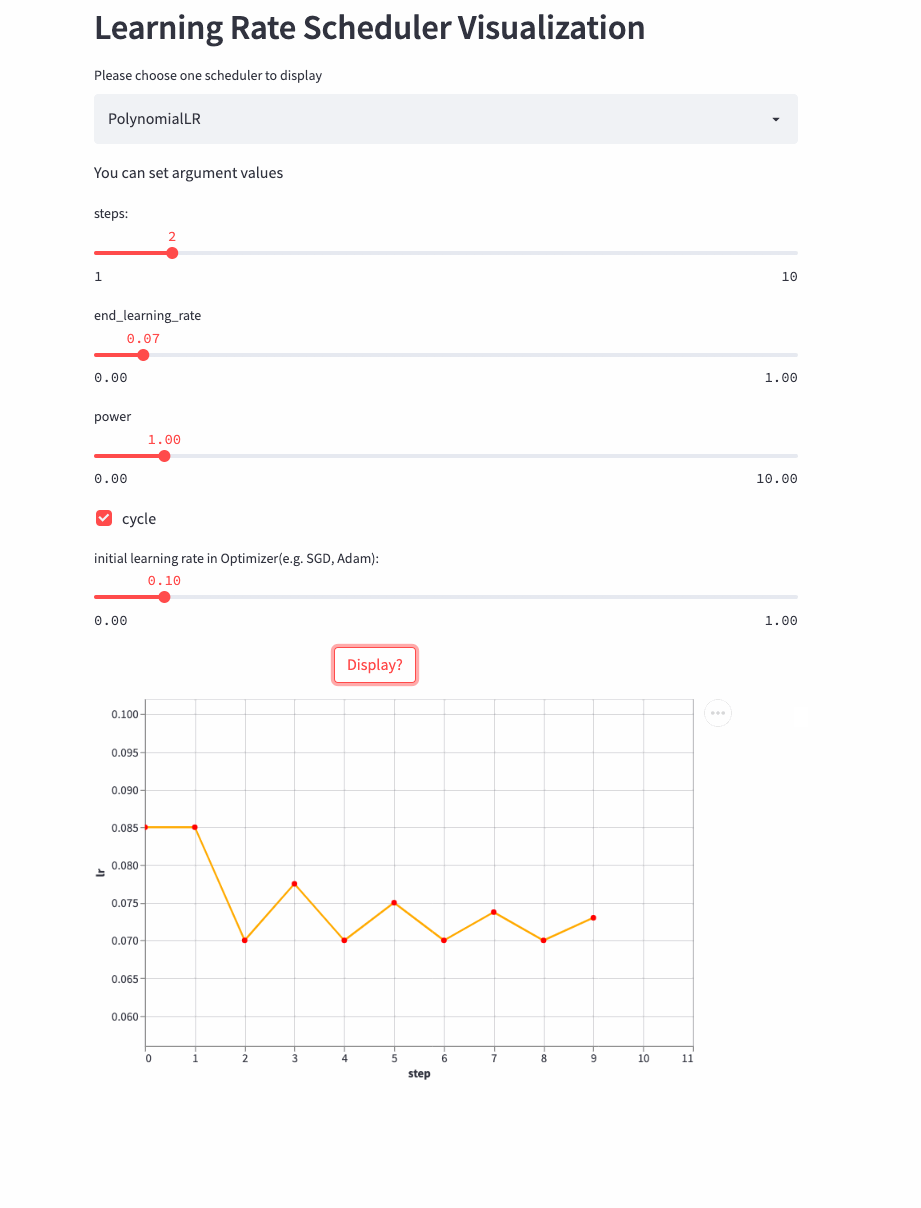
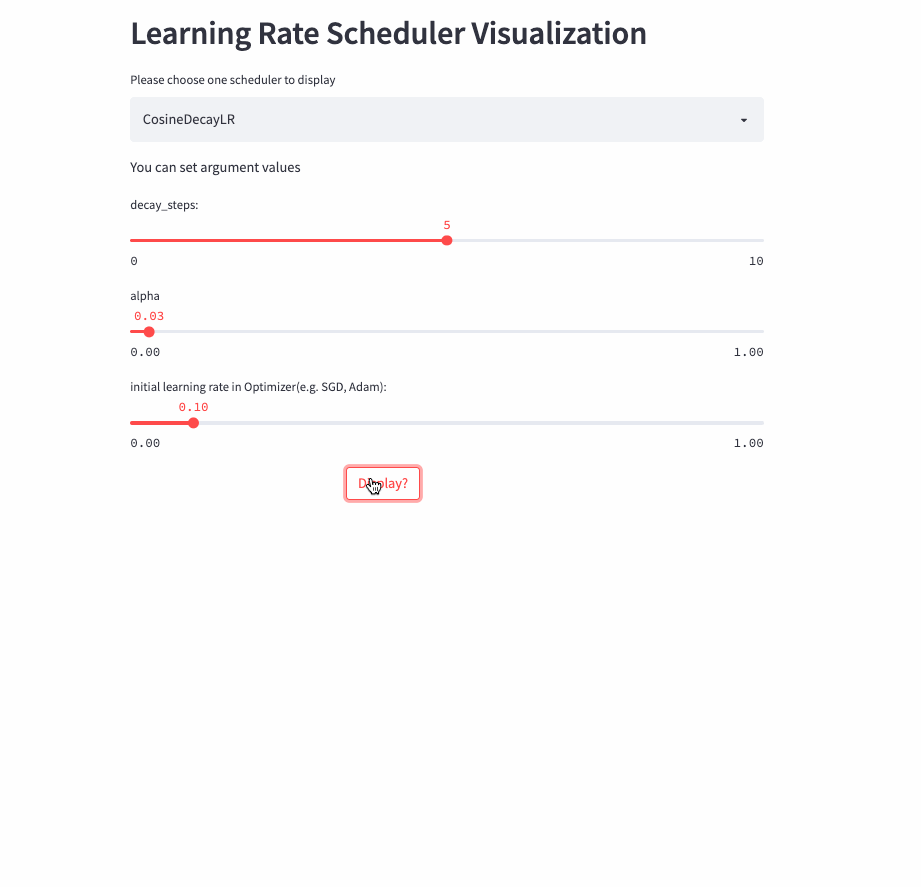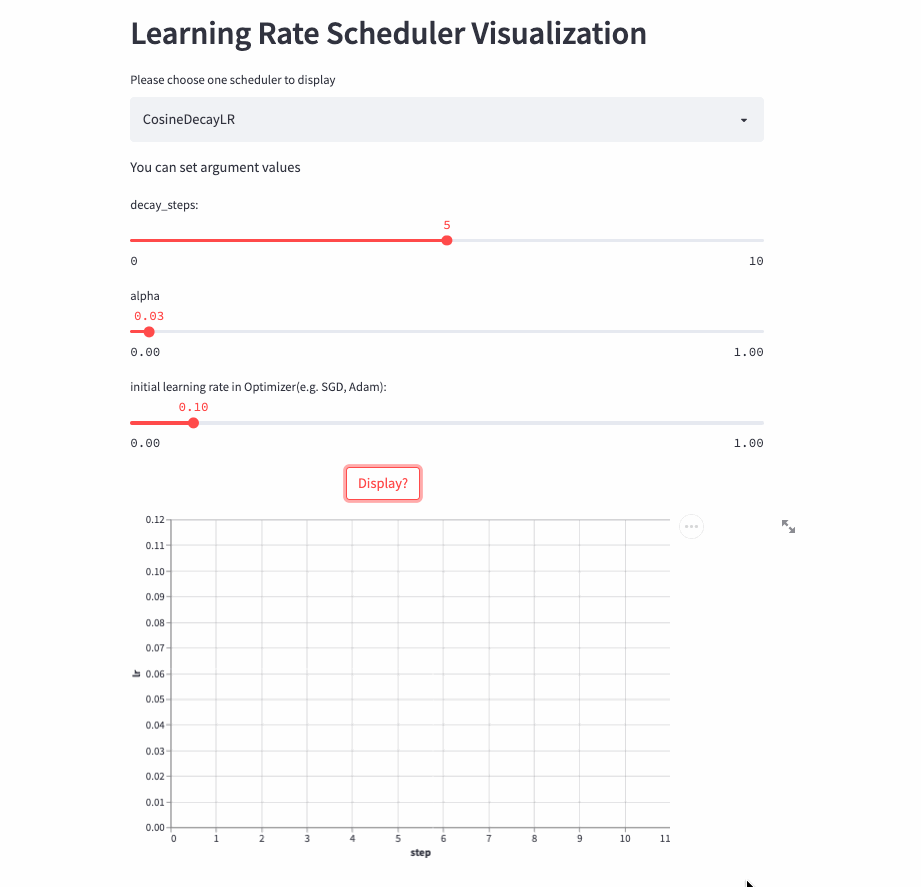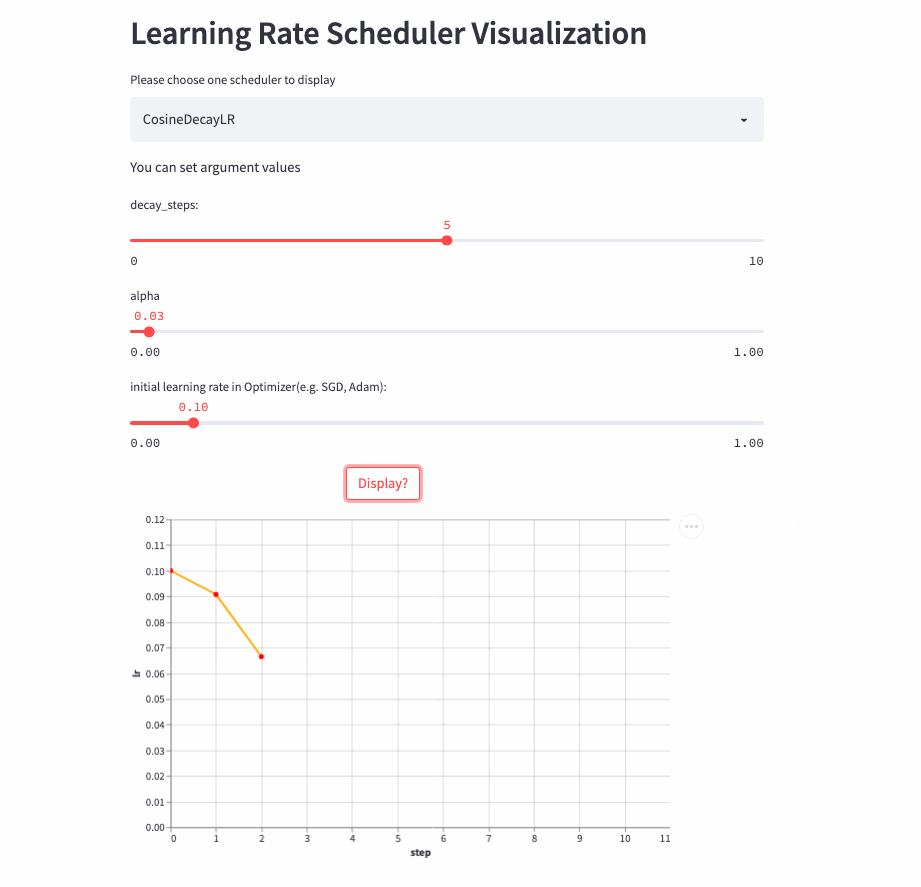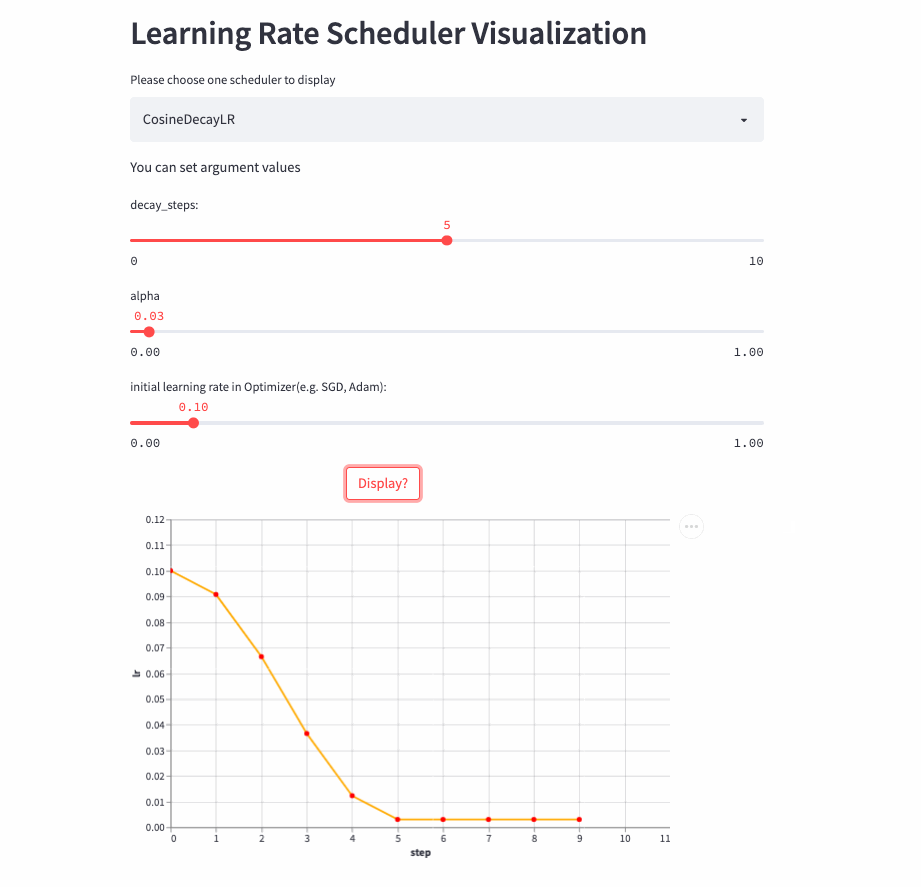
CosineDecayLR
在前decay_steps步,学习率由lr余弦衰减到lr * alpha,然后固定为lr*alpha。
注:CosineDecayLR是为了对齐TensorFlow中的CosineDecay。
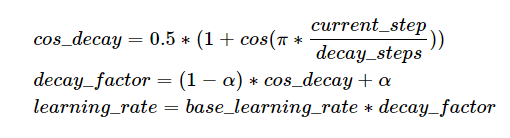
CosineAnnealingLR
CosineAnnealingLR和CosineDecayLR很像,区别在于前者不仅包含余弦衰减的过程,也可以包含余弦增加,在前T_max步,学习率由lr余弦衰减到eta_min, 如果cur_step > T_max,然后再余弦增加到lr,不断重复这个过程。
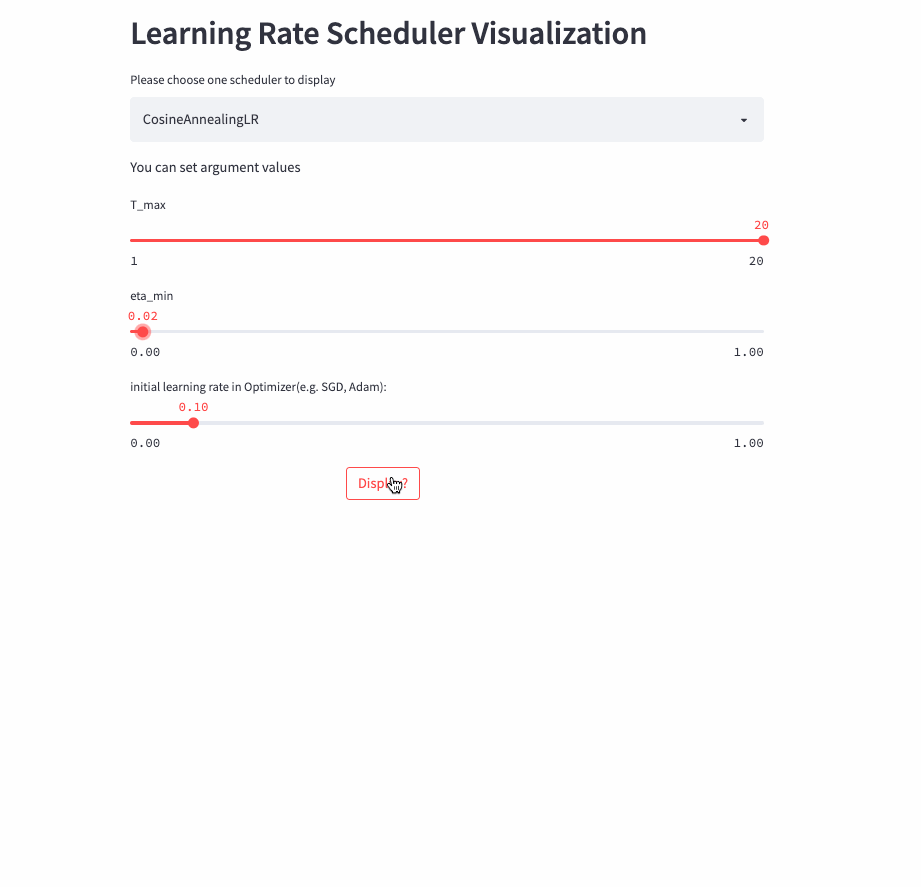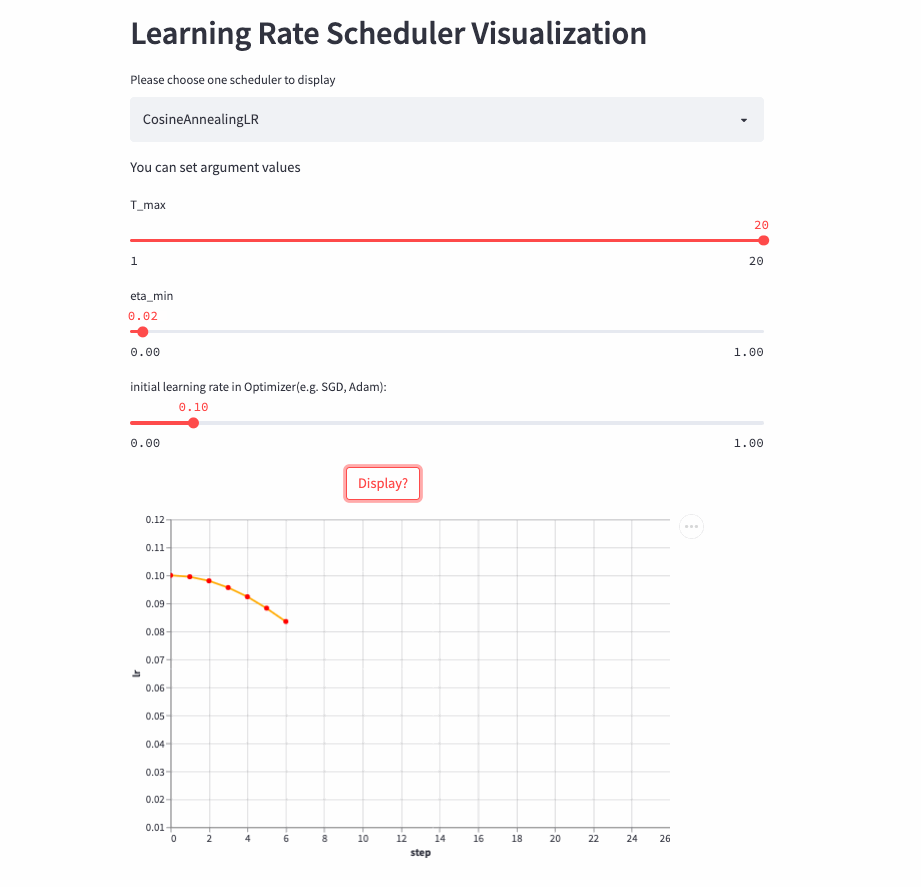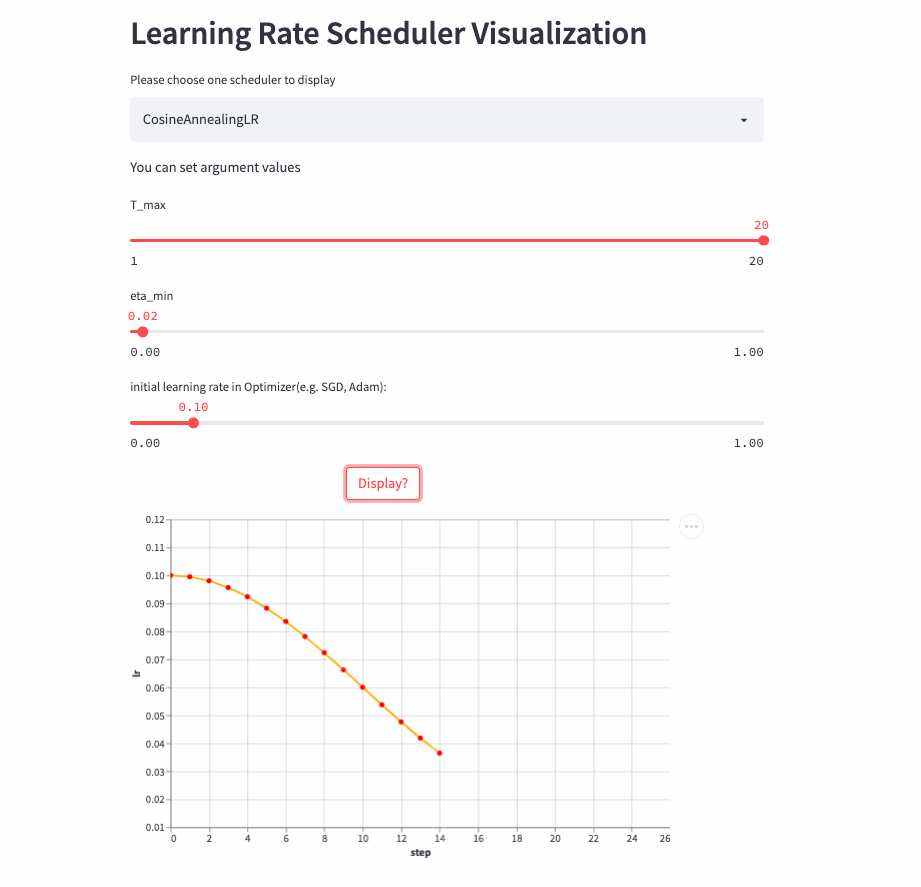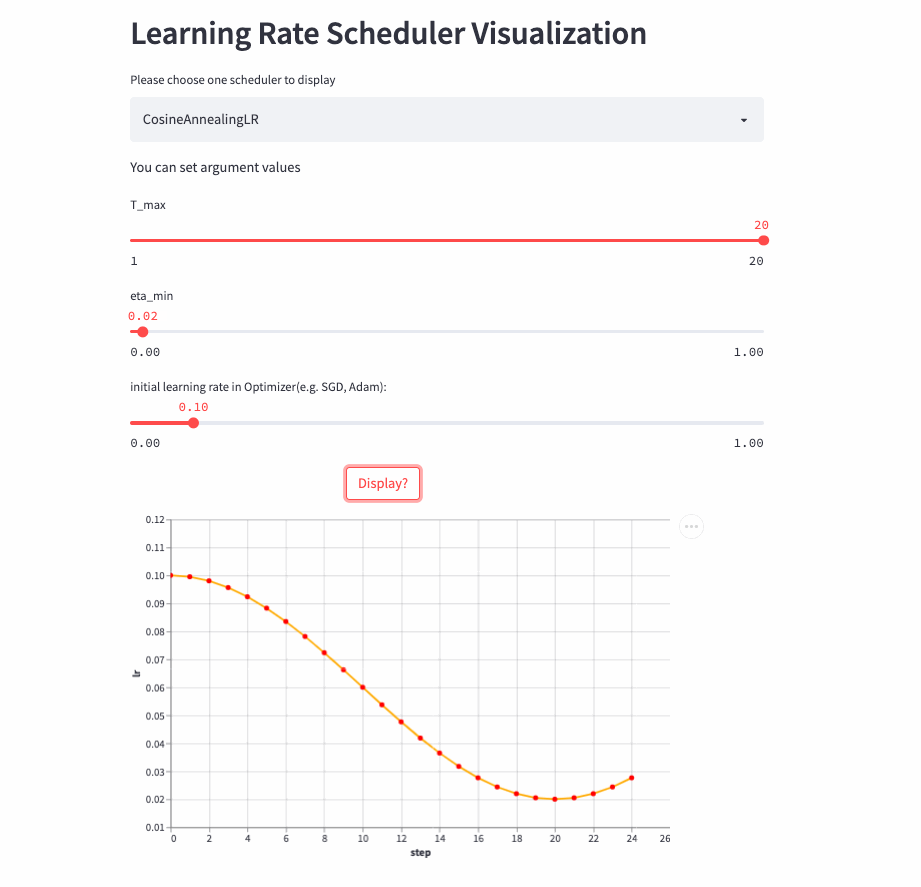
CosineAnnealingLR
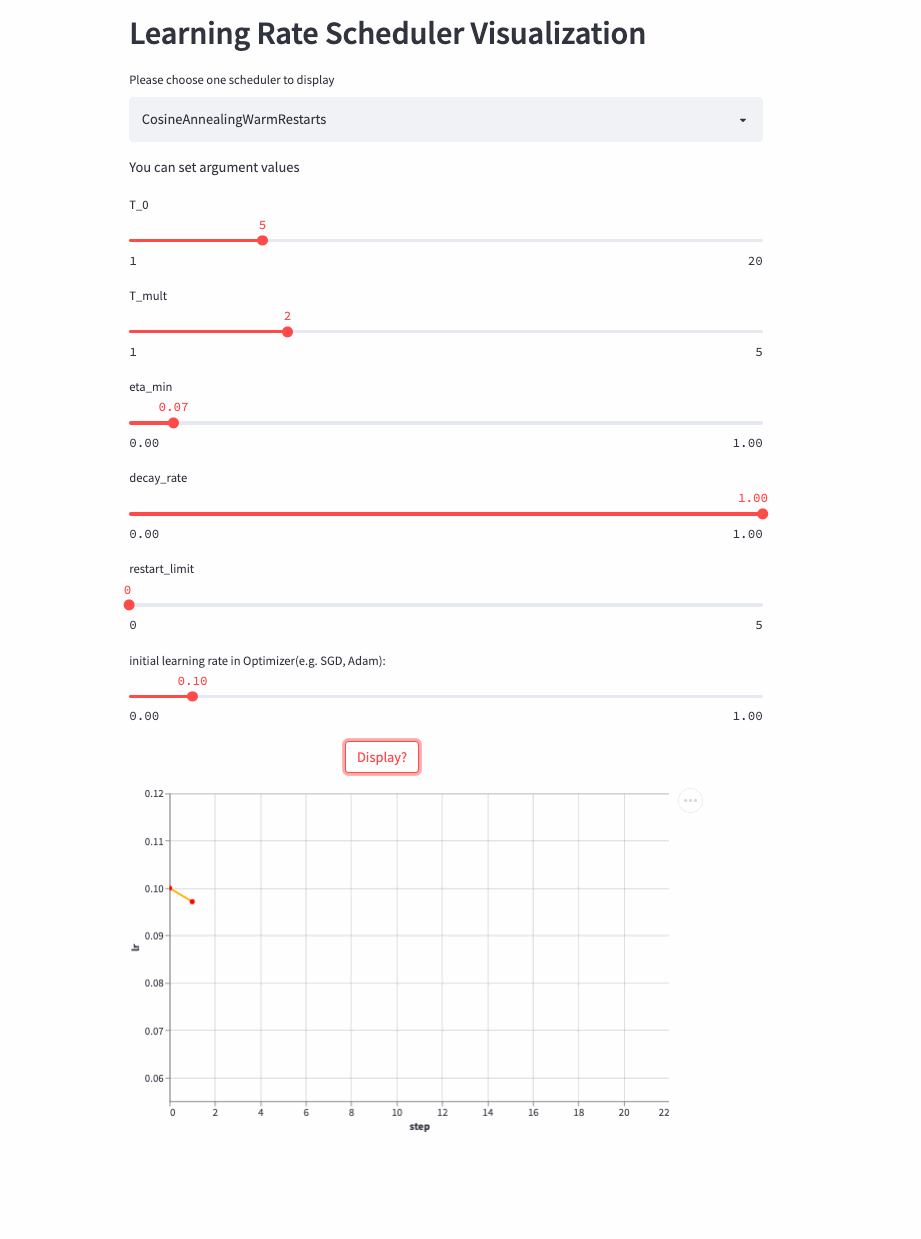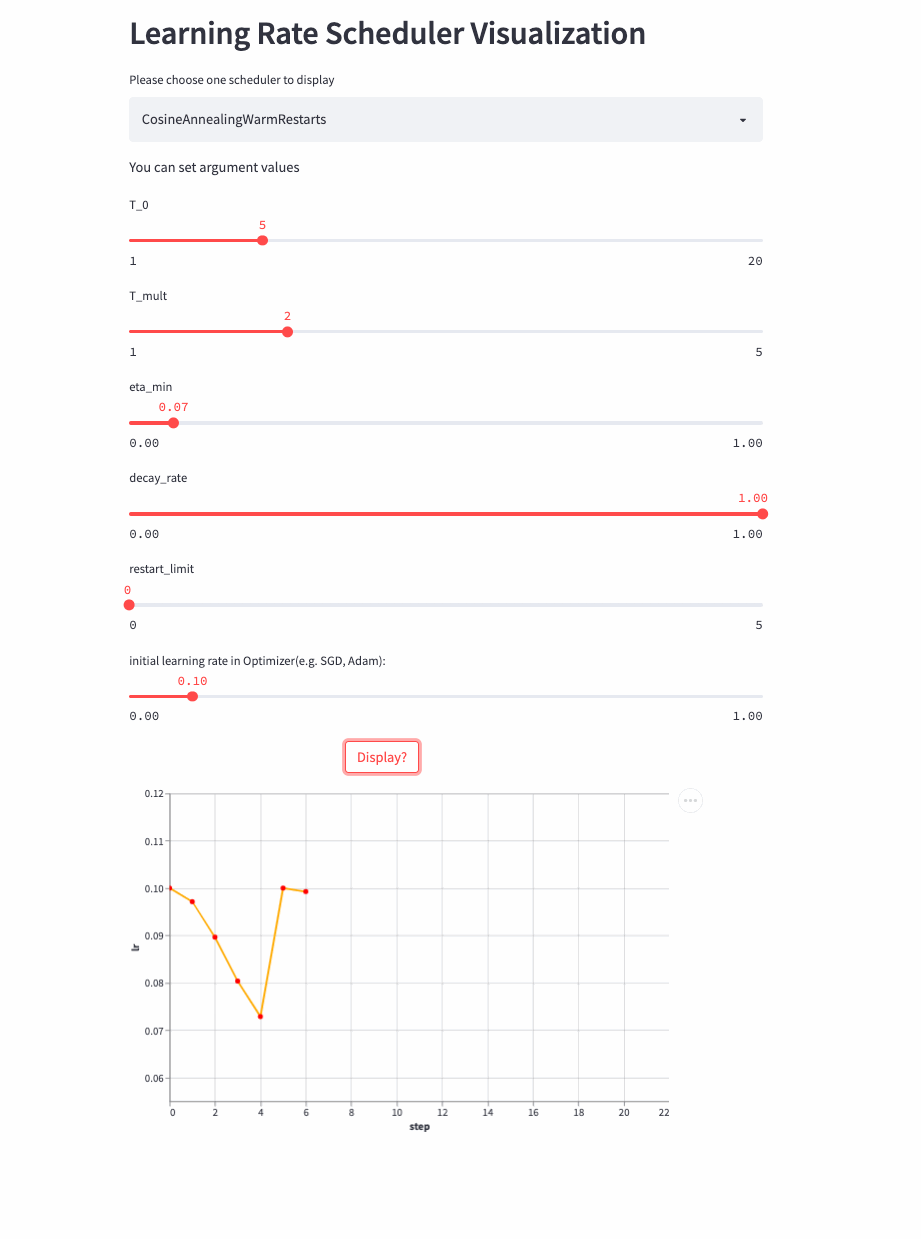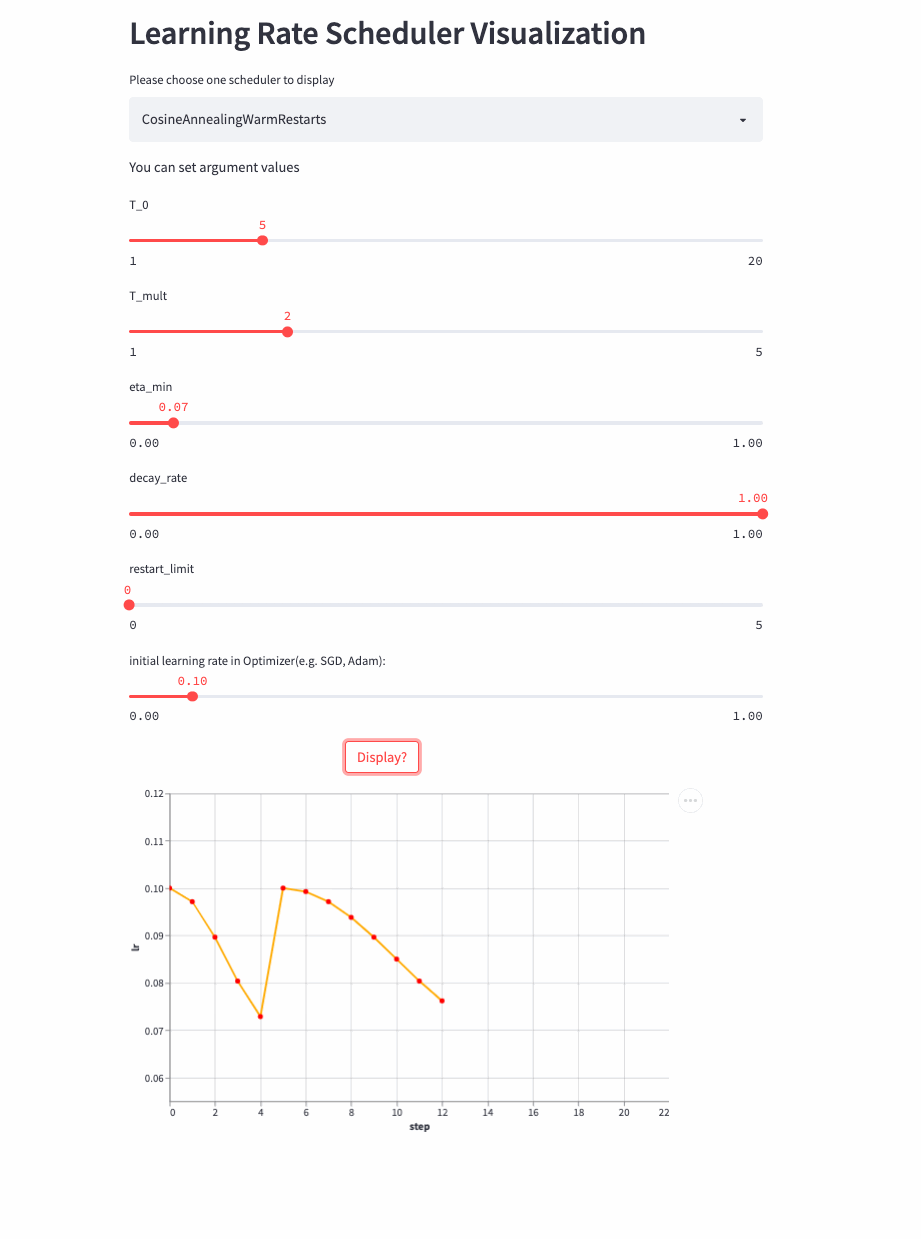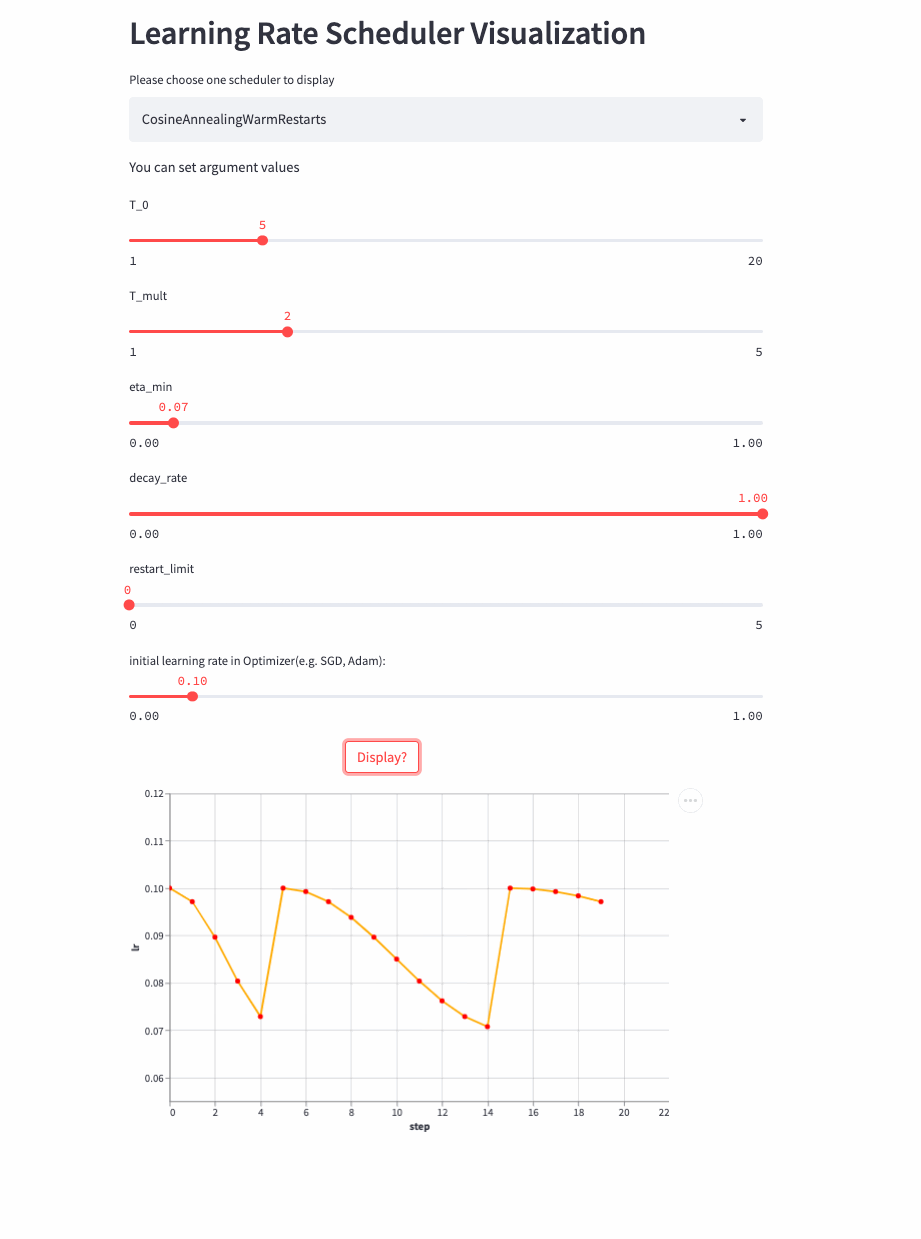
CosineAnnealingWarmRestarts
上面三个Cosine相关的LRScheduler来自同一篇论文(SGDR: Stochastic Gradient Descent with Warm Restarts),这个参数比较多,首先看T_mul,如果T_mul=1,则学习率等周期变化,周期大小就是T_0,也就是由最大学习率衰减到最小学习率的步数(steps),注意如果decay_rate<1,则每个周期的最大学习率和最小学习率都在衰减,第一个周期由lr开始衰减,第二个周期由lr * decay_rate开始衰减,第三个周期由lr * (decay_rate ** 2)开始衰减。
如果T_mult>1,则学习率不是等周期变化,每个周期的大小是上一个周期大小T_mult,第一个周期是T_0,第二个周期是T_0 * T_mult,第三个周期是 T_0 * T_mult * T_mult。
再来看restart_limit,默认值是0,就是上面的过程,如果>0,物理含义是周期数量,假设为3,则只有三次从最大衰减到最小,然后学习率一直是eta_min,不再周期变化了。
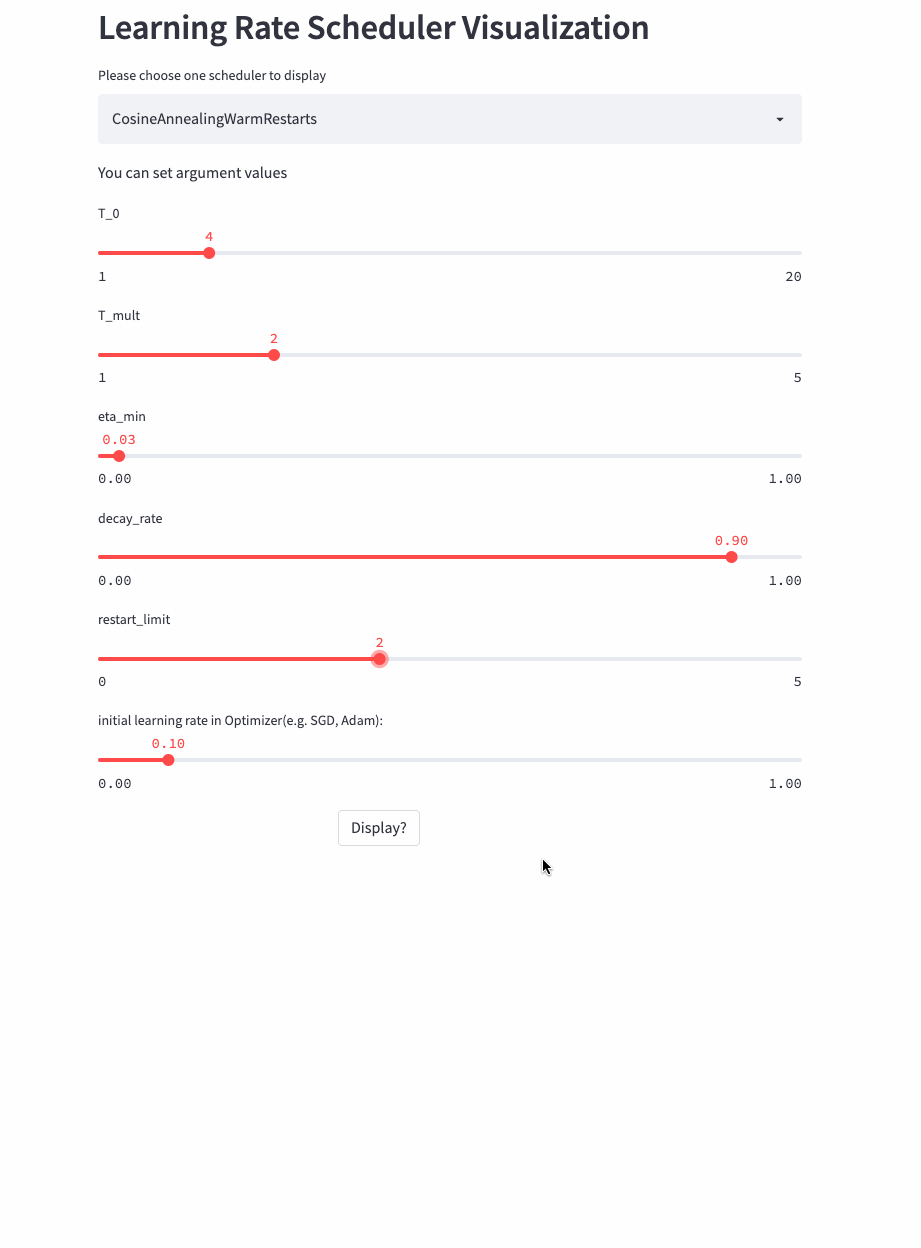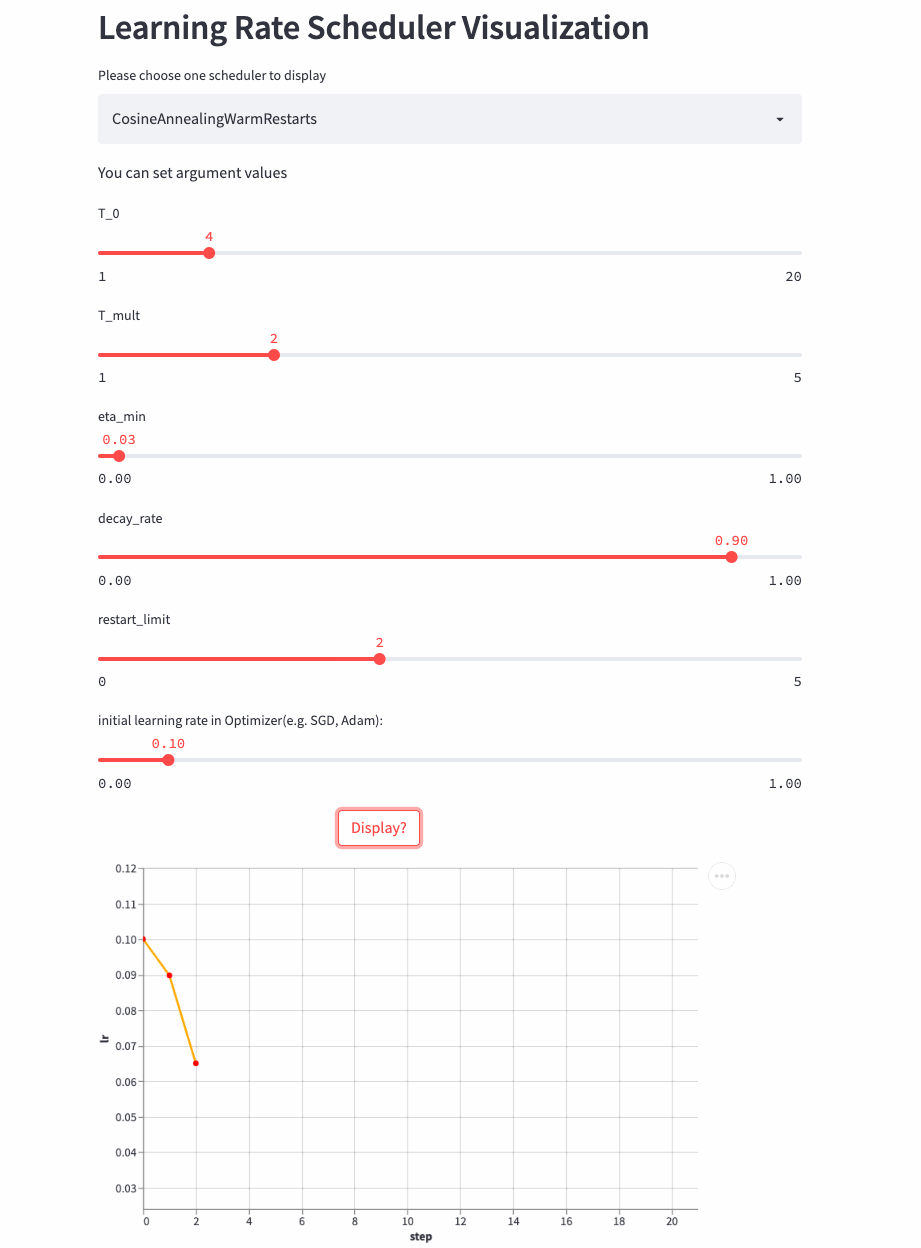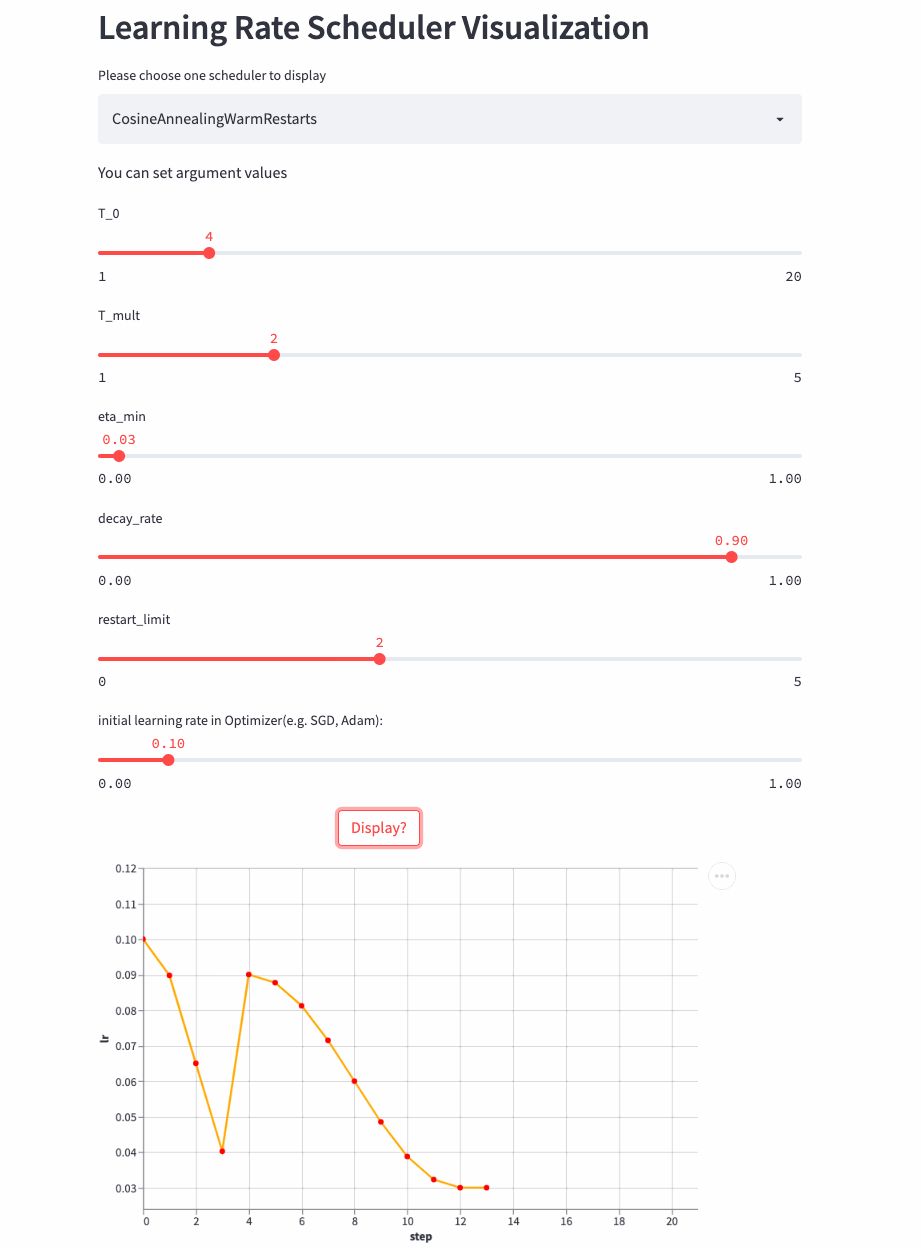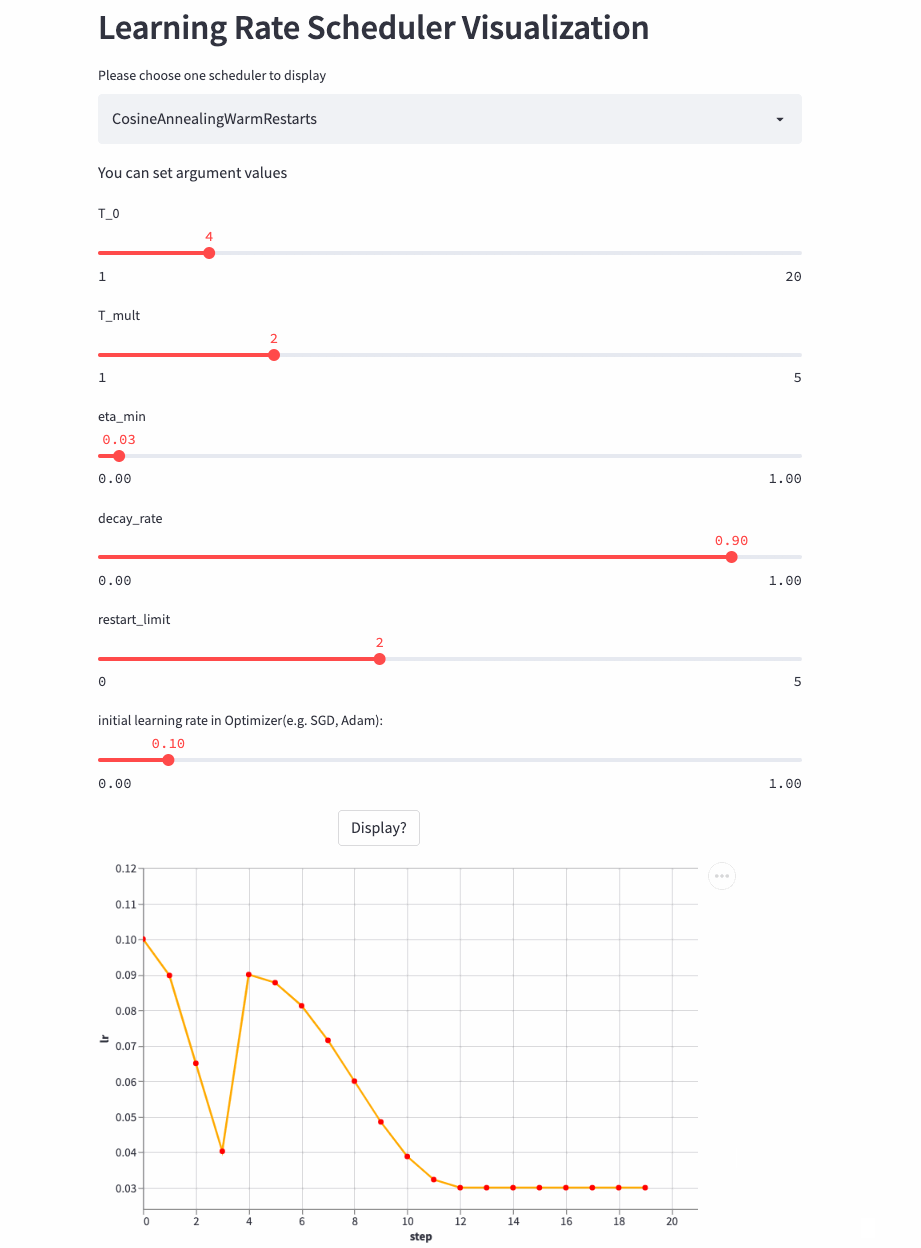
先看个T_mult=1的例子,此时decay_rate=1,
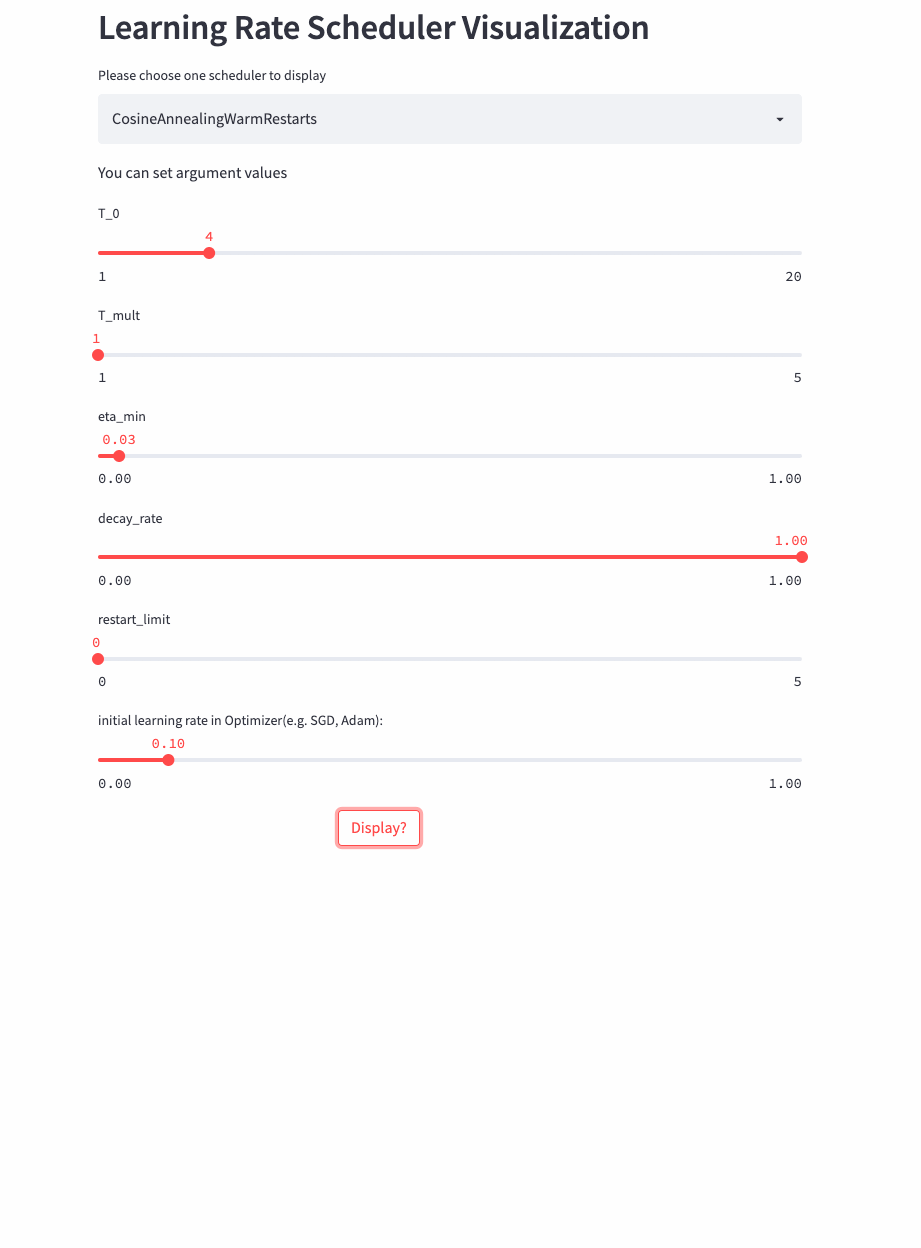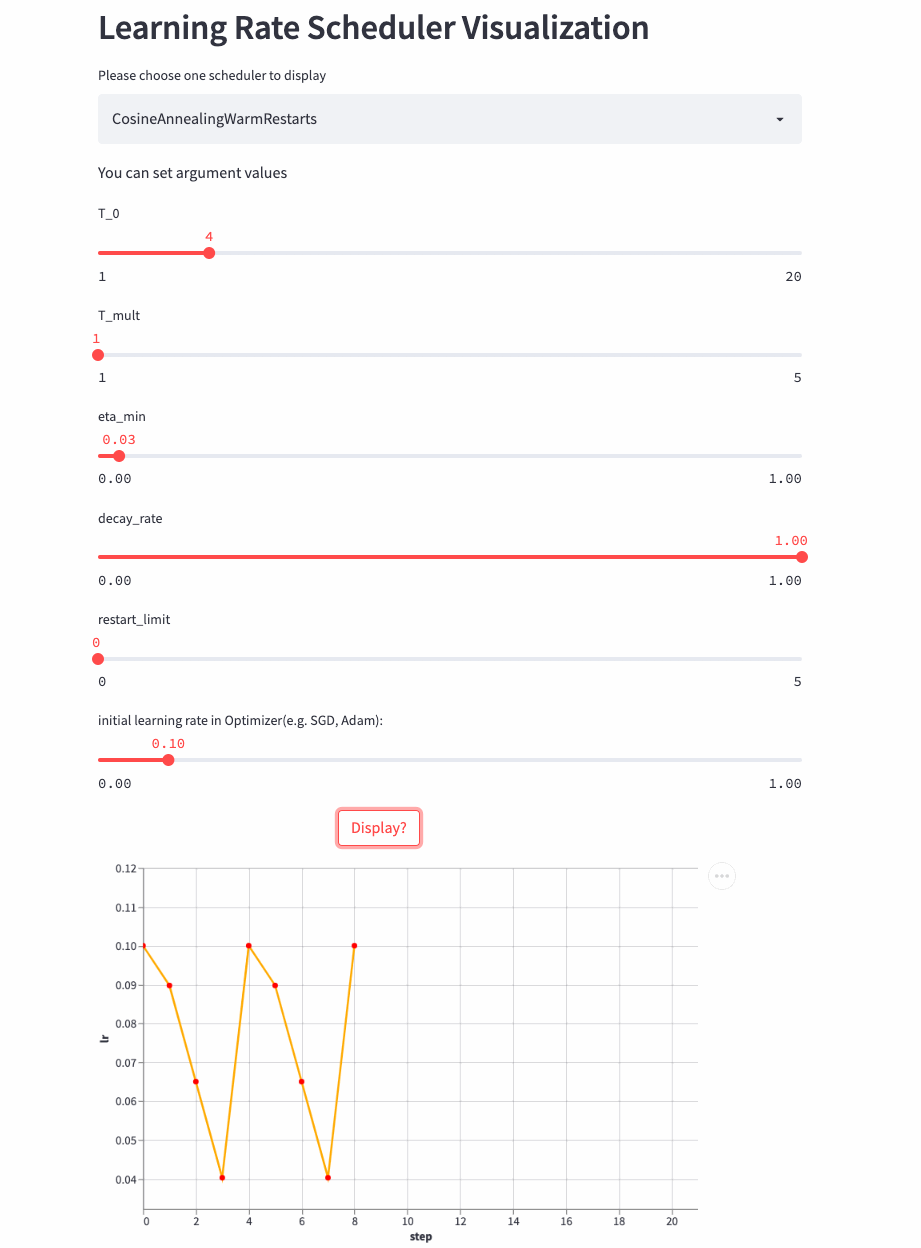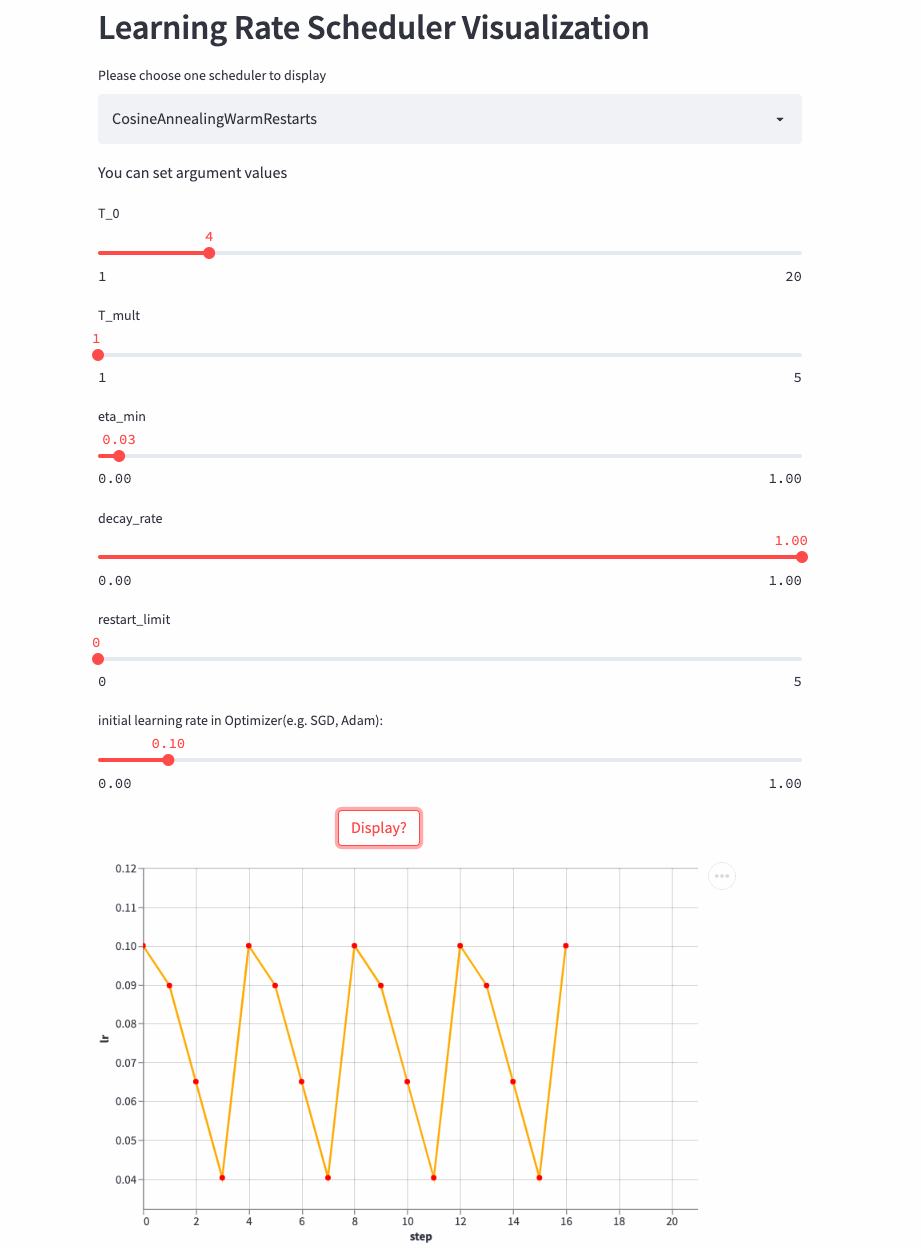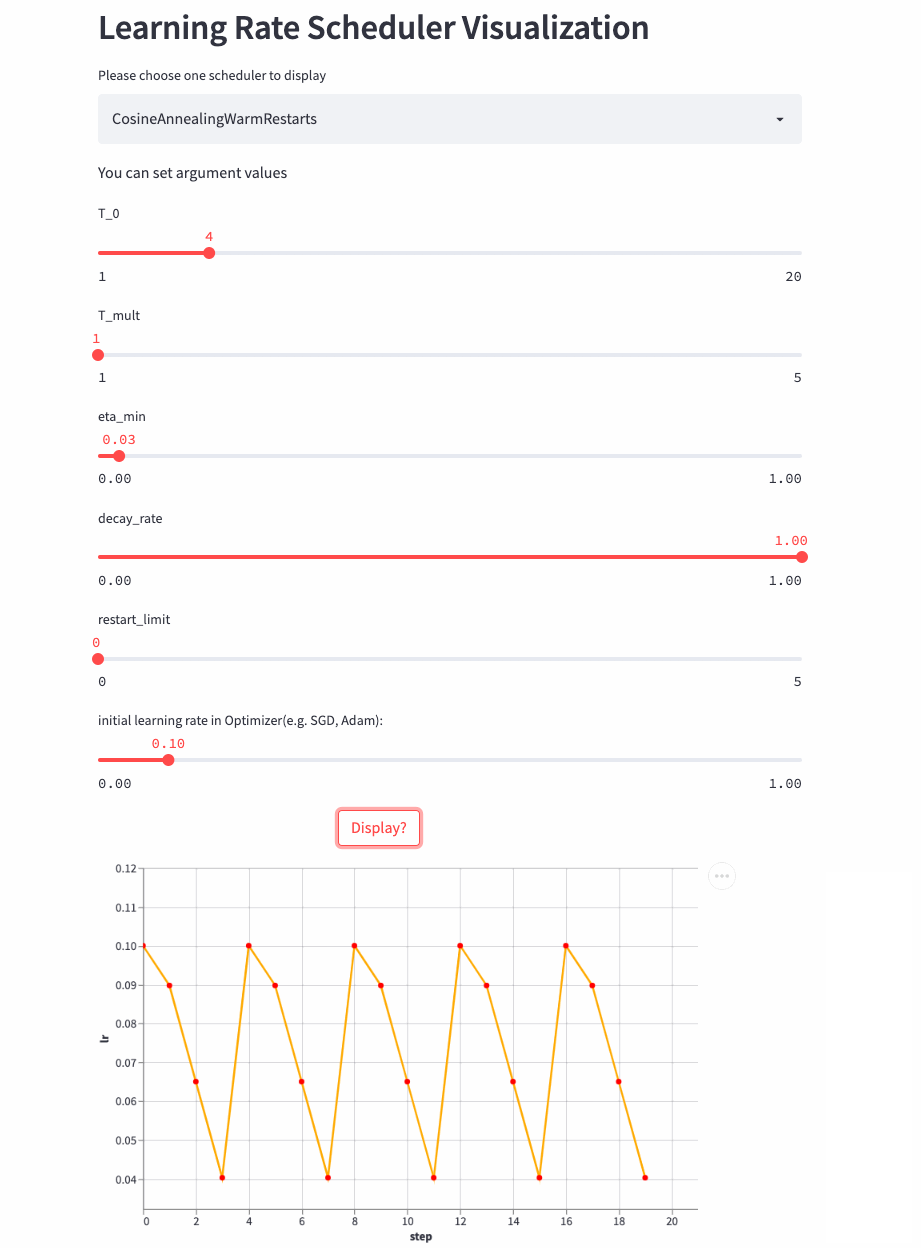
T_mult=1, decay_rate=1
再看个T_mult=1,decay_rate=0.5的例子,注意这种组合形式并不常用。
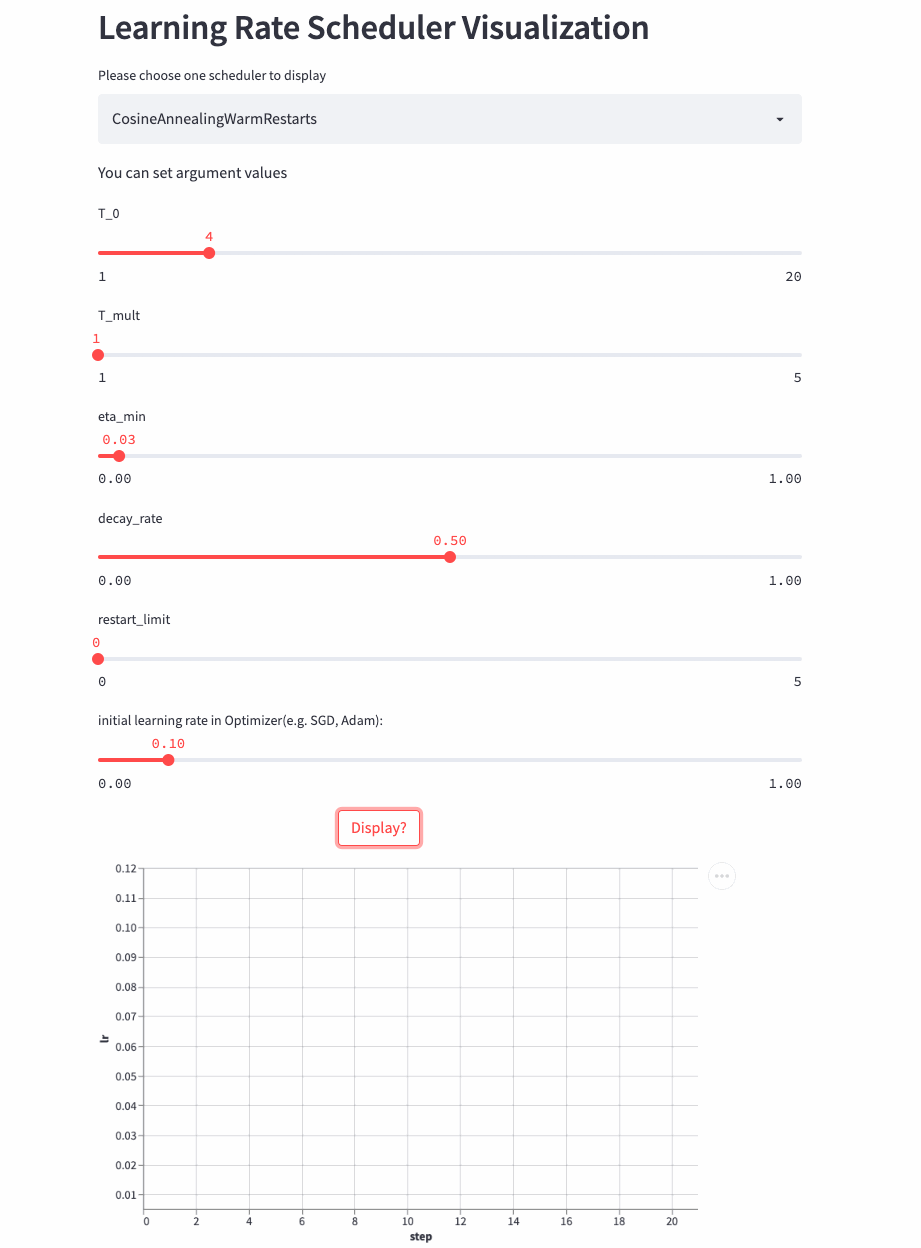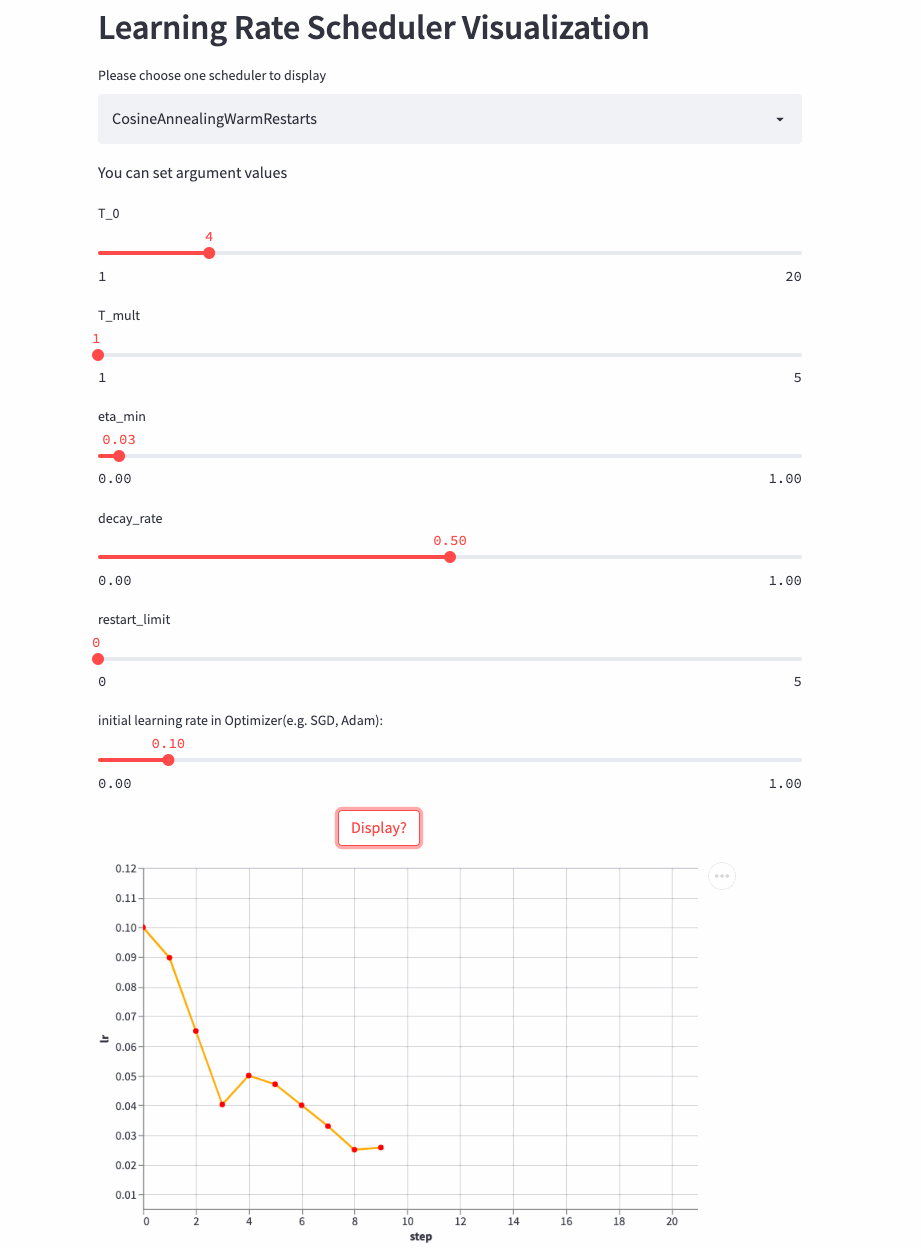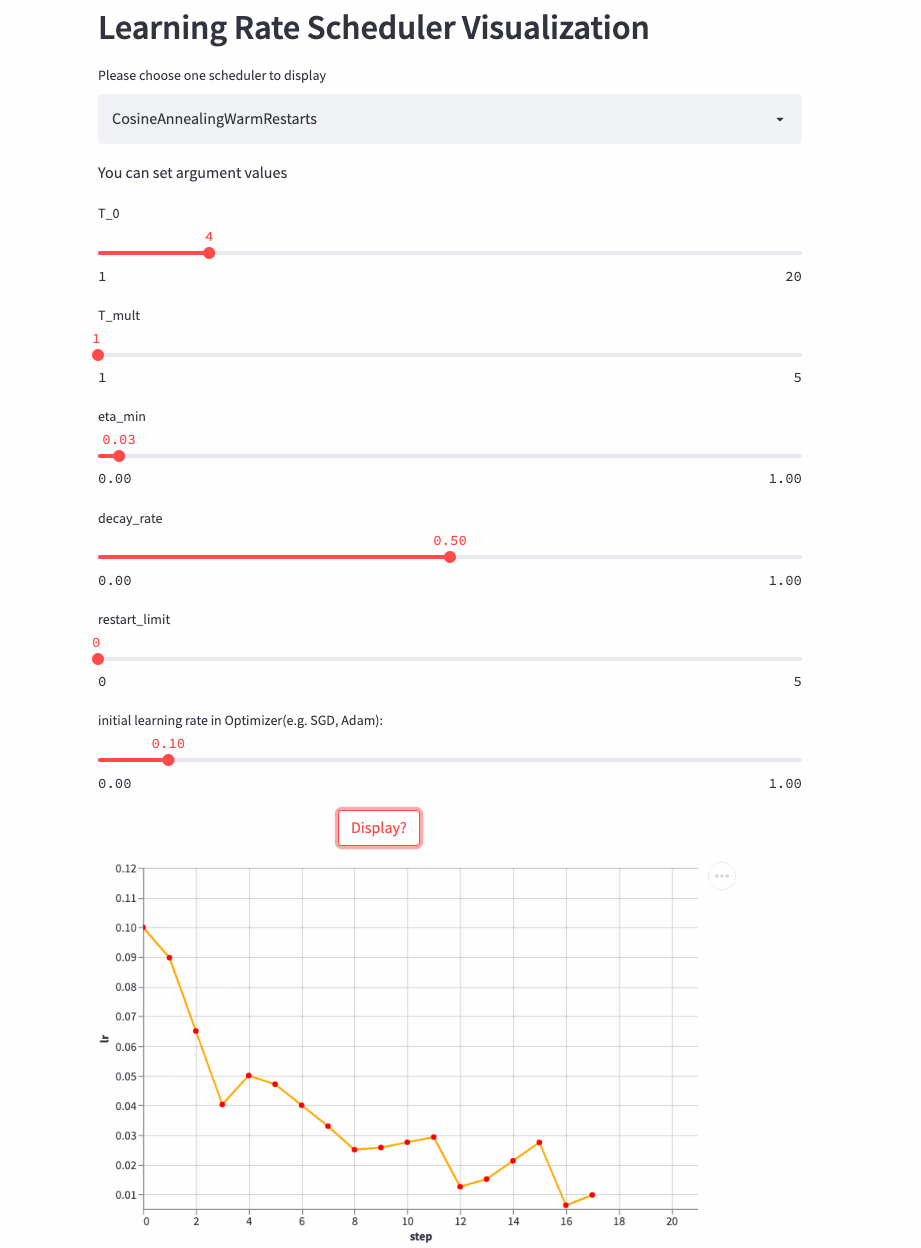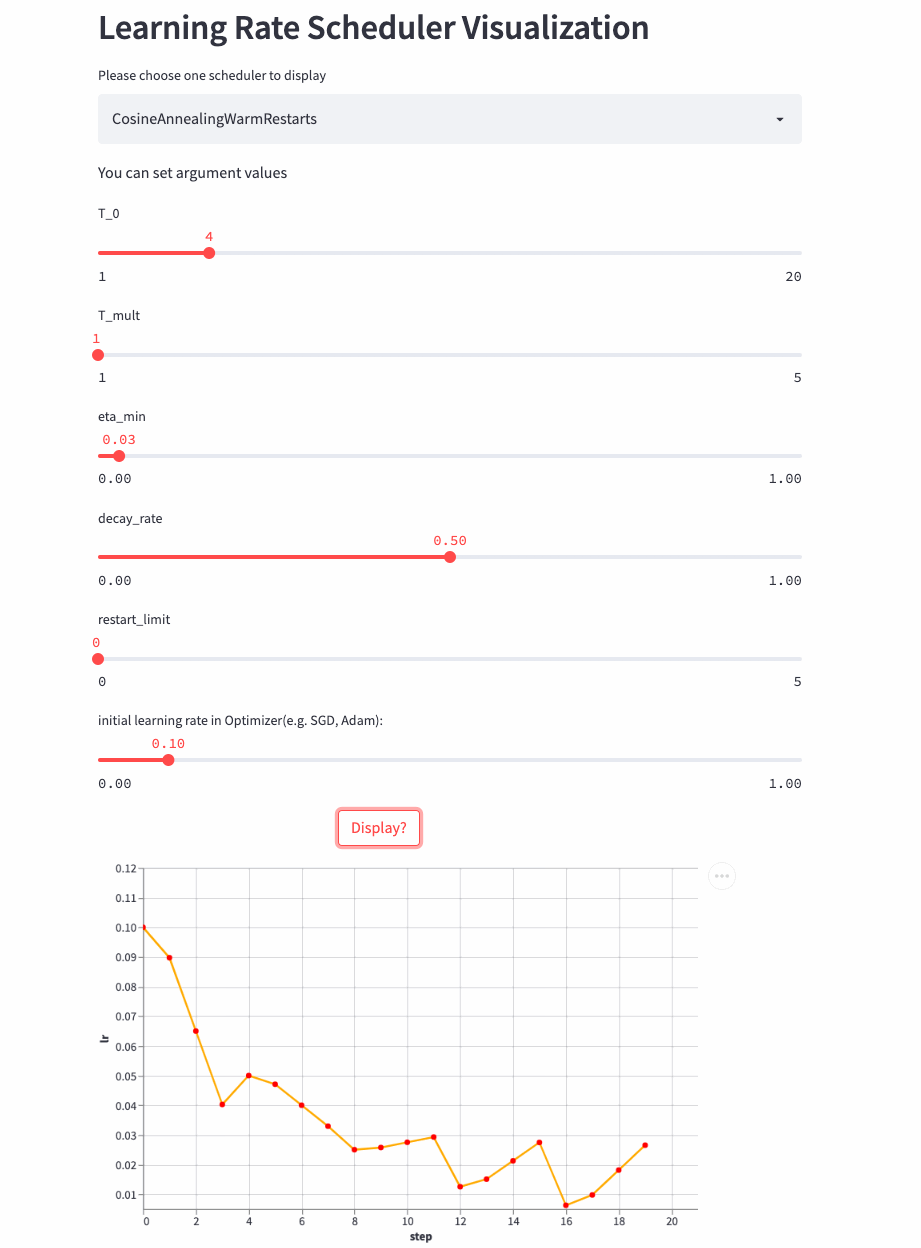
T_mult=1, decay_rate=0.5
再来看T_mult >1的例子,
最后,再看个restart_limit != 0的例子,
3
组合调度策略
上面讲的都是单个学习率调度策略,再来看几个学习率组合调度策略,比如训练Transformer常用的Noam scheduler就需要先线性增加再指数衰减,可以通过LinearLR和ExponentialLR组合得到。也可以直接使用LambdaLR传入学习率变化函数。
LambdaLR
oneflow.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda, last_step=-1, verbose=False)LambdaLR可以说是最灵活的策略了,因为具体的方法是根据函数lr_lambda来指定的。比如实现Transformer中的Noam Scheduler:
注意:OneFlow的Graph模式并不支持LambdaLR。
SequentialLR
支持传入多个LRScheduler,每个LRScheduler的作用范围(step range)由milestones指定,主要看下interval_rescaling这个参数,默认是False,目的是让相邻的两个scheduler在衔接时学习率比较平滑,比如milestones=[5],当last_step=5时,第二个schduler就从last_step=5开始计算新的学习率,这样和last_step=4(前一个scheduler计算学习率)得到的学习率不会有过大差异,而interval_rescaling=True时,则这个scheduler的last_step从0开始。
WarmupLR
WarmupLR是SequentialLR的子类,包含两个LRScheduler,并且第一个要么是ConstantLR,要么是LinearLR。
ChainedScheduler
oneflow.optim.lr_scheduler.ChainedScheduler(schedulers)前面讲的组合形式的调度策略,在每一个step,只有一个LRScheduler发挥作用,而ChainedScheduler,在每一个step计算学习率时,所有的LRScheduler都参与,类似于管道(pipeline)
lr ==> LRScheduler_1 ==> LRScheduler_2 ==> ... ==> LRScheduler_NReduceLROnPlateau
前面提到的所有LRScheduler都是根据当前的step来计算学习率,而在模型训练过程中,我们最关心的是训练集和验证集上面的指标,能不能利用这些指标来指导学习率变化呢?这时候可以用ReduceLROnPlateau,如果某项指标多个step都未发生显著变化,则学习率进行线性衰减。
4
实践
如果看到这里有点意犹未尽的感觉,不如动手实践一下,下面是我根据官方的图片分类实例改写的CIFAR-100例子,可以设置不同的学习率调度策略来感受下差异
-
https://github.com/basicv8vc/oneflow-cifar100-lr-scheduler
(本文经授权后发布,原文:
https://zhuanlan.zhihu.com/p/520719314 )
其他人都在看
欢迎体验OneFlow v0.7.0:OneFlow · GitHubOneFlow has 87 repositories available. Follow their code on GitHub. https://github.com/Oneflow-Inc/oneflow
https://github.com/Oneflow-Inc/oneflow
Recommend
-
51
-
61
训练神经网络受到几个问题的困扰。这些问题包括梯度消失、梯度爆炸 [7,3] 和过拟合。包括不同激活函数[14,17]、批归一化[12]、新颖的初始化方案 [9] 以及Dropout[26] 在内的多种进展都为这些问题提供了解决方案。 但是,一个...
-
49
译者 | 磐石 来源 | Medium 学习率是一个控制每次更新模型权重时响应估计误差而调整模型程度的超参数。
-
78
共发表: 第185篇 ...
-
42
无需预热 晓查 发自 凹非寺 量子位 报道 | 公众号 QbitAI Adam作为一种快速收敛的优化器被广泛采用,但是它较差的收敛性限制了使用范围,为了保证更优的结果,很多情况下我们还在使用SGD。 但SGD较慢...
-
17
封面图片:Photo by Ryunosuke Kikuno on
-
28
对于梯度惩罚,本博客已有过多次讨论,在文章 《对抗训练浅谈:意义、方法和思考(附Keras实现)》 和 《泛化性乱弹:从随机噪声、梯度惩罚到...
-
9
Logistic回归中学习率的最佳选择 fendouai...
-
6
学习率是深度学习训练中至关重要的参数,很多时候一个合适的学习率才能发挥出模型的较大潜力。所以学习率调整策略同样至关重要,这篇博客介绍一下Pytorch中常见的学习率调整方法。 import...
-
5
撰文 |
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK