

数据采集之:巧用布隆过滤器提取数据摘要 - superpigwin
source link: https://www.cnblogs.com/superpigwin/p/16400145.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

数据采集之:巧用布隆过滤器提取数据摘要
在telemetry采集中,由于数据量极大,一般采用分布式架构;使用消息队列来进行各系统的解耦。有系统如下:
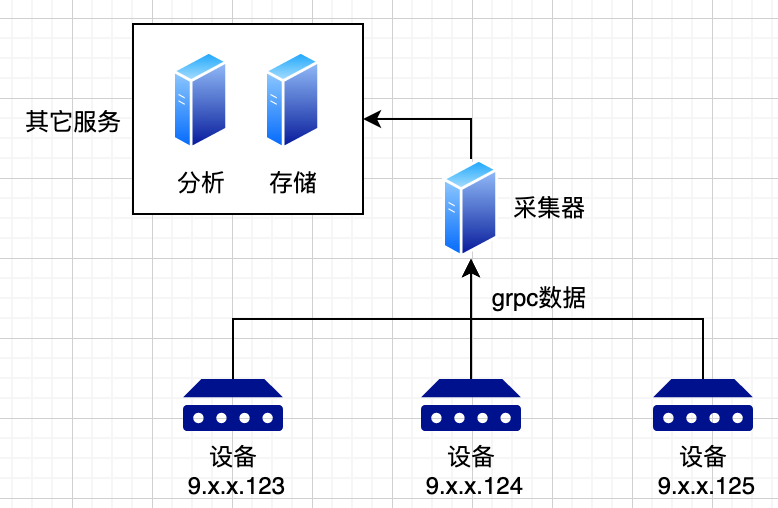
- 设备将各类数据上报给采集器,采集器充当格式转换的角色。将各类不同的设备数据转换为统一的格式。
- 采集器将数据写入到消息队列中,后端的其它服务,如“分析”,“告警”等服务从消息队列中取数据,进行相关的实际业务。
采集器转换后的的统一格式如下:
syntax = "proto3";
package talos.talosdata;
message Head {
uint64 time = 1;
string ip = 2; // 机器的IP
// .......
}
message TalosAttrData {
Head head = 1;
bytes data = 2;
}
其中,bytes data数据,可以再次解包为下列格式的数组:
message Data {
int32 attr_id = 1; // 申请的指标ID
string attr_name = 2; // 对应的指标名
float value = 3;
// ......
}
问题:后端分析系统资源浪费
因为是通用的采集系统,不方便感知具体的业务。所有类型的消息都会写入到同一个消息队列。
假设后端业务系统有告警服务,它只关注 attr_id = 10001的数据。它需要消费整个消息队列中的数据并对每条数据进行判断是否为目标数据。
伪代码如下:
kafkaMsg := kafka.Recv()
// 一次解包
baseData := new(TalosAttrData)
proto.Unmarshal(kafkaMsg.Bytes(), baseData)
// 二次解包
dataArr := make(DataArr, 0)
proto.Unmarshal(baseData.Data, &dataArr)
for _, data := range dataArr {
if data.AttrId == 10001{
// do sth
}
}
事实上,10001的消息,可能只占整个消息数的1%,但用户系统需要解出遍历所有数据。这显然不合理。
上述问题的产生,主要是两个原因:
- 所有类型的数据不区别的放在同一个消息队列topic中,这是主要矛盾。
- 关键信息
attr_id必须解出最深层次的包体才能获取。
解决第一个问题,实质上需要引入消息精细化分发的能力,也就是按需订阅系统。因为在实作中考虑到扩展性和运维,几乎不可能为每种类型的attr_id分配过于精细的消息队列topic。这个地方的细节很多,但不是本文重点,暂时不表。
要解决第二个问题,假设在不解析bytes data = 2;就能判定这个数据中是否有目标的数据,则可以避免第二次解包。
解法:为每条消息新增摘要字段
上文指出,每条消息还有一个head字段,在第一次解包时,就可解出:
message Head {
uint64 time = 1;
string ip = 2; // 机器的IP
// .......
}
如需判定某内容是否存在于一个集合,很显然应该使用布隆过滤器。
什么是布隆过滤器
布隆过滤器非常的简单,不了解的朋友需要先看看这篇文章:https://blog.csdn.net/zhanjia/article/details/109313475
假设使用8bit作为bloom filter的存储,有两个任意的hash函数(比如md5/sha256)
初始情况下,8位为0。
0000 0000
输入为hello,假设对hello取第一次hash: hash1("hello") % 8 = 7,将存储的第7位置1:
同样对hello取第二次hash:hash2("hello") % 8 = 3,将存储的第3位置为1:
如果要判定hello是否在bloom filter的存储中,则只需要检查第3/7位是否是1,因为hello的两次hash的结果是已知的:
assert bloomData & b10001000 == b10001000
显然:假设第3、7位都为1,则hello可能存在于bloom filter中,如果任意一位不为1,则hello一定不在bloom filter中。
bloom filter的优势在于:
- 使用很少的存储表示一个集合(在本例中是一个uint64)
- 判定(与bit位相比)较多的数据“一定不存在于”或“可能存在于”这个集合中。
一般布隆过滤器的用法是利用一个超大的集合来判定海量数据是否存在,比如爬虫使用一个N长的布隆过滤器,来判定海量的url是否已经遍历过。
但本文反其道而行之,为每条数据附加短小的消息摘要,然后在业务方判定摘要是否满足条件。
-
在
head消息体中,新增filter字段:message Head { uint64 time = 1; string ip = 2; // 机器的IP // ....... uint64 filter = 10; // bloom过滤字段 } -
有函数如下,可以将任意消息提取摘要,并放置在uint64中。在这里hash1是md5,hash2是sha256算法。用其它的hash算法也可。
// SetBloomUInt64 用一个uint64做bloom过滤器的存储,给msg做摘要提取并设置到origin中,返回值为被设置后的值 func SetBloomUInt64(origin uint64, msg []byte) uint64 { origin = origin | 1<<(hash1(msg)%64) origin = origin | 1<<(hash2(msg)%64) return origin } func hash1(msg []byte) uint32 { hash := md5.New() hash.Write(msg) bts := hash.Sum(nil) return crc32.ChecksumIEEE(bts) } func hash2(msg []byte) uint32 { hash := sha256.New() hash.Write(msg) bts := hash.Sum(nil) return crc32.ChecksumIEEE(bts) } -
在采集器格式转换的时候,将每条消息的
attr_id都提取摘要,循环放在head.filter字段中。这个摘要可以在后续被所有的业务用上。// 提取bloom摘要 var filter uint64 for _, v := range data { bs := make([]byte, 4) binary.LittleEndian.PutUint32(bs, uint32(v.AttrId)) filter = bloom.SetBloomUInt64(filter, bs) // bloom过滤器算法保证了设置重复的摘要不影响结果 } result.Head.Filter = filter -
关键步骤,后续的业务方可根据filter字段,在解析出head后,就粗略判定这条消息是否包含目标数据,这样就不需要进行二次的data解析和遍历:
func blAttrID(attrID uint32) uint64 { bts := make([]byte, 4) binary.LittleEndian.PutUint32(bts, uint32(attrID)) return bloom.SetBloomUInt64(0, bts) } var bl10001 = blAttrID(10001) // 将10001转换为origin为0的,经过bloom过滤器处理后的数据 // ... filter := talosData.Head.Filter if filter&bl10001 == bl10001{ //do sth }
为什么能这样
通过bloom过滤器,每条消息的head都包含了[]data的所有attr_id的摘要。这基于下面的假设:
- 同一个消息中包含的
attr_id的类型不能过多。根据文献,假设使用uint64作为过滤器的长度,当hash函数的个数为2,attr_id的种类为10,则误算率为0.08;如果种类为20,则误算率为0.2。 - 误算率指:判定数据包含在摘要中,但实际数据不存在。假设判定数据在摘要中不存在,则数据一定不存在。所以误算率并不会造成逻辑错误,充其量会多一些冗余的计算。
通过这一个小小的优化,在生产端增加一些计算,就可以为后续所有的业务提供服务。业务可以在一次uint64取或的时间内,判定整个数据是否符合要求。减轻业务系统的压力。
Recommend
-
76
作者:Soroush Khanlou, 原文链接 ,原文日期:2018-09-19 译者: WAMaker ;校对:
-
57
为什么引入 我们的业务中经常会遇到穿库的问题,通常可以通过缓存解决。 如果数据维度比较多,结果数据集合比较大时,缓存的效果就不明显了。 因此为了解决穿库的问题,我们引入Bloom Filter。 我们先看看一般业务缓...
-
56
-
59
为了解决布隆过滤器不能删除元素的问题,布谷鸟过滤器横空出世。论文《Cuckoo Filter:Better Than Bloom》作者将布谷鸟过滤器和布隆过滤器进行了深入的对比。相比布谷鸟过滤器而言布隆过滤器有以下不足:查询性能弱、空间利用效率低、不支持反向操
-
60
布隆过滤器是什么? 布隆过滤器可以理解为一个不怎么精确的 set 结构,当你使用它的 contains 方法判断某个对象是否存在时,它可能会...
-
47
公众号后台回复“ 学习 ”,获取作者独家秘制精品资料 推荐一个专栏: 《从 零 开始带你成为 JVM 实战 高手》...
-
52
作者:朱江,腾讯工程师。 | 导语 布隆过滤器是一种很实用的数据结构,能快速判断某个数据是否...
-
47
布隆过滤器、同态加密、PKI体系……一文告诉你密码学在区块链中能做什么区块链大本营2019-10-19理解为什么区块链可以防止消息被篡改、怎么进行数字身份认证
-
12
原文地址:码农在新加坡的个人博客 布隆过滤器是什么 本质上布隆过滤器(Bloom Filter)是一种数据结构,比较巧妙的
-
3
1.问题场景 有100亿个url被加入了黑名单,现在提供一个url要去判断是否属于黑名单。也就是一个很简单的一个东西是否属于一个集合的问题。 一般来说用set就能解决这种问题,但是由于url数目太多,内存中无法开辟一个这么大的空间去存放所有url,这个...
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK