

DAST 黑盒漏洞扫描器 第四篇:扫描性能 - huim
source link: https://www.cnblogs.com/huim/p/16398975.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
0X01 前言
大多数安全产品的大致框架
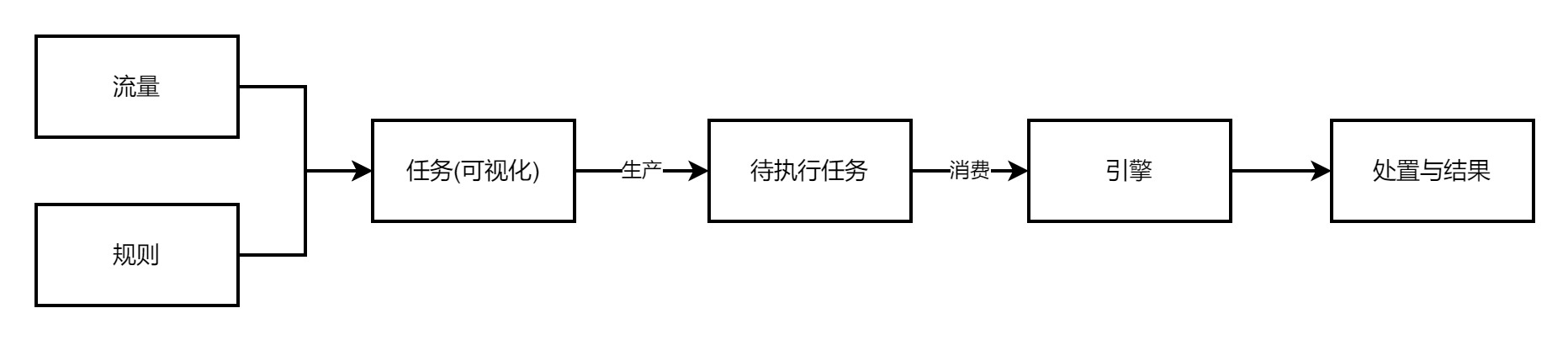
提高性能的目的是消费跟得上生产,不至于堆积,留有余力应对突增的流量,可以从以下几个方面考虑
- 流量:减少无效流量
- 规则:减少规则冗余请求
- 生产者:减少无效扫描任务
- 引擎:灵活扩缩容的分布式引擎节点
0X02 减少无效流量
2.1 URL
2.1.1 去重——去除重复流量
第三篇2.1.2 、2.1.3 说到去重、流量清洗服务,这里简单说一下去重:
同一个逻辑只有一条流量对于扫描器来说是有意义的,长得不同的流量扫描多了是浪费性能。
场景:有如第三篇 2.1.2 所说
(1) 预处理
过滤 CSS/JS/zip等静态资源文件,能过滤掉80%以上流量
(2) 归一化去重
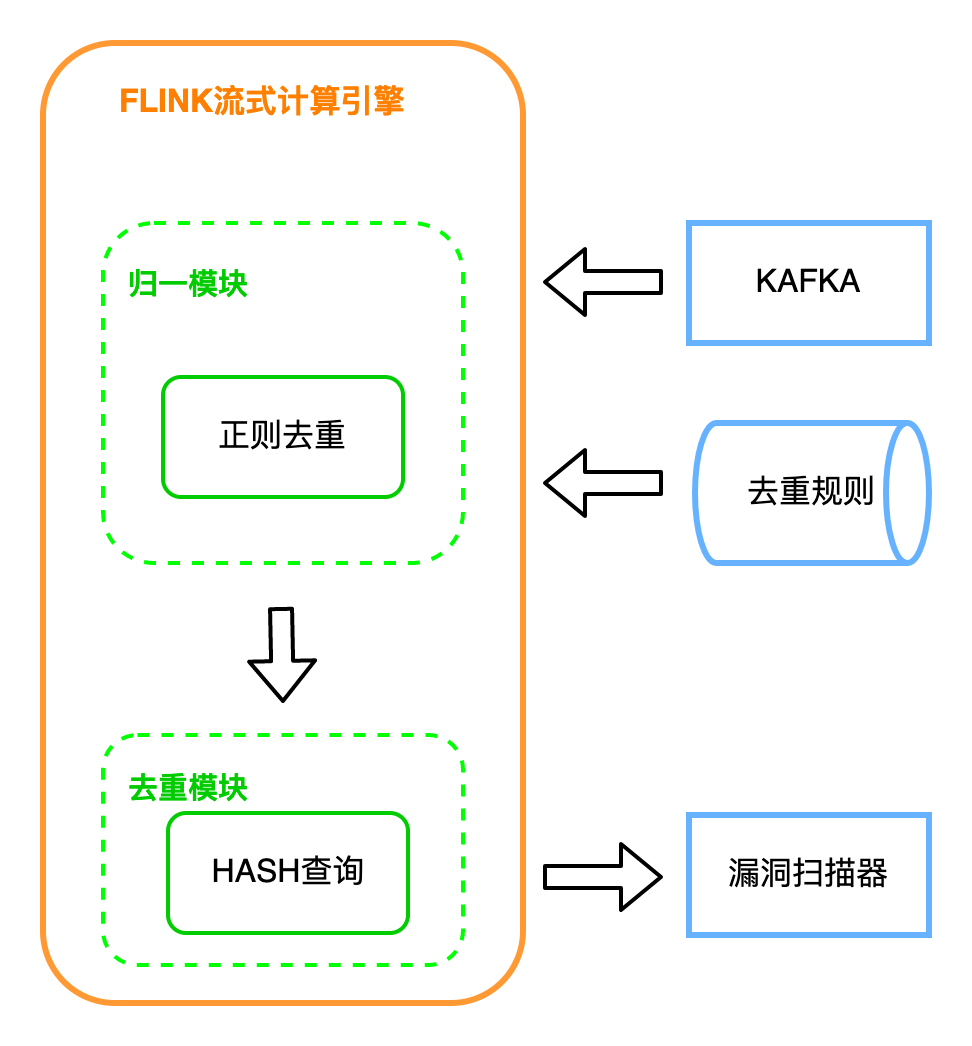
归一化,即用正则或其他方式,比如列表匹配,判断某一段路径或者域名是否在列表中,这种在 {city}.meituan.com中运用;
把URL中相似的部分替换成相同的字符串,最后根据归一化后的值是否相同来判断是否重复:
把 https://tieba.baidu.com/p/1000000001 替换为 https://tieba.baidu.com/p/1
把 https://bj.meituan.com/meishi/ 替换为 https://{city}.meituan.com/meishi/
再计算逐条规则替换后的url的hash,查询之前是否有过,没有该hash才输出
经过这一步,基本上 日均流量 百亿量级-> 百万量级。具体的设计实现方式不多赘述,挑战在于百亿级别的流量+几十上百的去重规则下的性能、上百万key的缓存交互。
还有其他细碎的优化,比如不同域名设置不同的规则,动态参数名怎么判断保留多少个,同一个参数名下保留多少个参数值,单个缓存key的有效时间等。
各类实现思路可以参考关键字“URL normalization”的论文,url去重其实已经学术界工业界已经研究了十几年,比较成熟了。
(3) 相似度去重
在百万量级的基础上,进行二次去重,基于页面相似度 simhash改进的算法,再将流量量级降到十万上下
SimHash算法是Google在2007年发表的论文《Detecting Near-Duplicates for Web Crawling》中提到的一种指纹生成算法,被应用在Google搜索引擎网页去重的工作之中。
也有很多其他优秀且性能更好的页面相似度算法
其实去重说起来也有些类似于搜索引擎的去重,而目前搜索引擎的去重算法都已经比较成熟了,可以搜索各种论文,找找这些去重算法。
这里需要注意json格式的响应虽然可能相似,但接口可能各不相同,可以结合URL相似度来做。
2.1.2 去除无效流量
引擎上进行流量格式化前后判断
(1 是不是40x/50x页面等不可访问页面,或者是集团内返回码200的404页面(自行收集)
往往有很多无效访问,因为导向返回码200的40x/50x页面,导致这一部分的流量漏去重。如果页面相似度去重已经上了,这一步也可以略过,用作召回去重程序的case。
(2) 排除找不到业务的流量: 镜像流量有时候会有奇怪的流量,比如对着nginx构造host等情况,需要排除掉找不到业务的流量。这部分流量即使有漏洞,漏洞找人也比较麻烦,后续无法实现全流程自动化。所以nginx无法解析的、domain没有记录的,过滤掉。再将这一部分流量定期汇总,做召回,看是否是nginx问题、或者是domain记录缺失。
(3) 排除掉恶意流量:流量镜像上收集到的流量,有很多是外部扫描器的,目录爆破/注入检测/CmsPoc/xss等等,这些没有意义,且一有就是大量的出现,即浪费了扫描性能、又占用了大量QPS,可以结合IDS/WAF过滤掉这一部分流量
2.2 HOST
扫描前对IP和端口做一次连接,再探测一遍端口连通性,以避免数据时间过长、端口早已关闭,但又浪费了一些资源去扫描。
IP端口往往无法及时更新,一小时扫一次全内网IP和端口已经是比较迅速了,但仍会有失效的端口,像JDWP这种,业务调试时开放、下班了关掉。
如果可以实时监控端口开放与关闭状态,开放了再进行指纹扫描,不必定时全量扫描,端口存活检测可只作为召回召回。但端口状态监控比较麻烦,比如http连接时客户端开放的端口,请求完就关闭,这种消息是无效的,拿去作端口指纹识别,海量的数据会浪费很多不必要的性能。
0X03 减少规则冗余请求
记录每个扫描规则的7*24平均请求量和运行时间,并设置阈值
请求量过大或者超过一定的运行时间,进行标记或给出告警,再对规则进行优化。
规则本身的性能优化:
比如通过侧信道方式检测注入,比单纯的sqlmap纯黑盒方式检测更准、更快,这是甲方优势(并不是说直接调sqlmap检测不准确,只是为了检测更全,risk和level得拉满,但是请求太多、时长太久);通过侧信道检测命令执行,大大略过了判断页面响应的步骤等等,更准更快。
0X04 减少无效扫描任务
端口指纹匹配,精准化扫描,不生产一些明显不会有结果的扫描任务,比如对着MySQL端口检测redis未授权。
在实践过程中,遇到的情况是端口指纹不明确,所以运营人员也不敢随便选二级指纹,很多情况都是规则没有选择具体框架/服务指纹,也就不管端口有没有指纹都扫描了,因为规则无具体指纹产出的漏洞占比较大,直接一刀切、产出骤降。所以只有遇到规则有指纹、端口也有指纹的时候,才进行匹配过滤。
规则指纹匹配,往往难点在于端口指纹打标的准确性。
端口打标流程有了之后,打标的召回、持续运营还是漫漫长路。
有很长一段时间,web的无效任务集中在qps超限后的操作,也就是第三篇 2.1.4的内容。qps控制不能单单的控制到任务、或者是域名层面,而是为了满足大流量情况,尽可能控制到接口层面,尽可能用可以用的、业务用剩下的qps,这就需要控制的单位往扫描引擎流程后移,尽可能的控制力度更细。
qps的控制最小单位在请求上,而不在任务调度上,这就导致qps控制程序需要应对同一个接口,在同一时间 有多个扫描子任务、多个规则、多个请求的情况。超过了限制,要么这个扫描子任务丢回队列等待下次重试,要么sleep等待可用。
sleep的方式会hang住节点,而重试浪费了大量的性能,甚至有的任务在某个接口超低的业务正常qps情况下是无法完成的。
出现过75%的扫描任务都是在重试和抛弃的路上。所以有了记录请求hash、从上次重试位置开始再次扫描的断点重扫功能。在减少无效扫描任务上效果极好。
0X05 分布式节点
分布式实现起来并没有太多难点,无非是生产者的子任务打到队列,用多个消费者先入先出式地读取待扫描的子任务并消费。
引擎节点应只做消费,消费上游生产的扫描任务(规则+流量),把结果打给下游处置队列。
节点分布式,可考虑redis/mq+celery的实现方式,也比较成熟。
但是用了那么久的celery,总觉得celery比较重,监控上虽然有flower,但是流量丢失、内存上涨、超时中断等问题总是排查成本较大。
所以改成上游生产者队列、下游处置队列都是kafka的形式。
如此分布式节点只需考虑消费kafka时不导致倾斜的问题即可,扩展起来方便,监控上对另外服务记录kafka日志,也跳过了celery本身内存的头疼问题,超时中断可自行实现。
celery的超时中断有软超时和硬超时两种;软超时即是超时的时候,在当前运行代码报错,但在规则运行时报错可能会被catch;硬超时直接中断任务,但没有日志,就相当于流量丢了,溯源/召回起来很不方便
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK