

每个程序员都应该了解的内存知识-3
source link: https://lrita.github.io/2022/06/20/programmer-should-know-about-memory-3/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
5 NUMA 支持
在第2节中,我们看到,在一些机器上,访问特定物理内存区域的开销因访问来源的不同而不同。这类硬件需要操作系统和应用程序特别小心。我们将从NUMA硬件的一些细节开始,然后我们将介绍Linux内核为NUMA提供的一些支持。
5.1 NUMA 硬件
非统一存储体系结构(non-uniform memory architectures)正变得越来越普遍。在最简单的NUMA形式中,处理器访问本地内存(见图2.3)比访问其他处理器的内存的开销更低。
NUMA还特别适用于大型机器。我们已经描述过了让多个处理器访问同一个内存的问题。对于商业硬件,所有处理器都将共享同一个北桥(暂时忽略AMD Opteron NUMA节点,它们有自己的问题)。这使得北桥成为一个严重的瓶颈,因为所有内存访问都是通过它路由的。当然,大型机器可以使用定制硬件代替北桥,但是,除非使用的内存芯片有多个端口,即它们可以从多个总线使用,否则仍然存在瓶颈。多端口RAM的构建和支持既复杂又昂贵,因此几乎从未使用过。
复杂性的下一步是AMD使用的模型,其中互连机制为未直接连接到RAM的处理器提供访问。除非想要任意增加直径(即任意两个节点之间的最大距离),否则以这种方式形成的结构的尺寸是有限的。
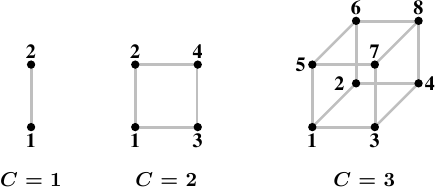
图 5.1: Hypercubes
一种有效的节点拓扑结构是超立方体,它将节点数量限制在2C,其中C是每个节点的互连接口数量。对于所有具有2nCPU的系统,超立方体的直径最小。图5.1显示了前三个超立方体。每个超立方体的直径为C,绝对最小值。AMD的第一代Opteron处理器每个处理器有三个超级传输链路。至少有一个处理器必须在一条链路上连接一个南桥,这意味着,目前可以直接高效地实现C=2的超立方体。下一代被宣布有四个链接,在这一点上C=3超立方体是可能的。
然而,这并不意味着无法支持更大的处理器堆积。有一些公司已经开发了横杆,允许使用更大的处理器集合(例如,Newisys的Horus)。但这些交叉链接增加了NUMA因子,但是在一定数量以上的处理器上不再高效。
下一步是连接多组CPU,并为它们实现共享内存。这样的设计存在多层复杂性。IBM x445和类似的机器仍然是一个非常接近商业级机器的系统。它们被设计成有x86和x86-64处理器的普通4U、8路机器。这些机器中的两台(有时多达四台)可以连接起来,作为一台具有共享内存的机器工作。所使用的互连引入了一个重要的NUMA因素,操作系统和应用程序都必须考虑到这一因素。
另一方面,像SGI Altix这样的机器是专门为互联而设计的,SGI的NUMAlink互连结构速度非常快和延迟很低;这两项都是高性能计算(HPC)的要求,特别是在使用MPI时。当然,缺点是这种复杂和专业化设计有非常高的代价。它们使NUMA系数合理较低成为可能,但由于这些机器可以拥有的CPU数量(数千)和互连的容量有限,NUMA系数实际上是动态的,并且可以达到不可接受的水平,具体取决于工作负载。
更常用的解决方案是使用高速网络连接商业机器集群。但这些不是NUMA机器;它们不实现共享地址空间,因此不属于本文讨论的任何类别。
5.2 支持NUMA的操作系统
为了支持NUMA机器,操作系统必须考虑内存的分布式特性。例如,如果一个进程在给定的处理器上运行,分配给该进程地址空间的物理RAM应该来自本地内存,否则,每条指令都必须访问远程内存以获取代码和数据。但是有一些情况需要在NUMA机器上特殊考虑。DSO的文本段通常在机器的物理RAM中只出现一次,但是,如果所有CPU上的进程和线程都使用该DSO(例如,基本的运行时库,如libc),这意味着除少数处理器外,所有处理器都必须具有远程访问。理想情况下,操作系统会将此类DSO“镜像”到每个处理器的物理RAM中,并使用本地副本。这是一种优化,不是一种要求,通常很难实现。
为了避免让情况变得更糟,操作系统不应该将进程或线程从一个NUMA节点迁移到另一个NUMA节点。操作系统应该已经尝试避免在普通多处理器机器上迁移进程,因为从一个处理器迁移到另一个处理器意味着缓存内容丢失。如果负载分配需要迁移处理器的进程或线程,操作系统通常可以选择一个具有足够剩余容量的任意新处理器。在NUMA环境中,新处理器的选择有点限制。新选择的处理器对进程正在使用的内存的访问成本不应高于旧处理器;这限制了目标列表。如果没有符合该标准的可用处理器,操作系统就别无选择,只能迁移到内存访问代价更高的处理器。
在这种情况下,有两种可能的方式进行(优化)。首先,我们可以希望这种情况是暂时的,并且可以将流程迁移回更适合的处理器。或者,操作系统也可以将进程的访问的内存迁移到最新访问它的处理器上。这是一个相当昂贵的操作。可能需要复制大量内存,尽管不一定是一步完成的。当这种情况发生时,必须停止该过程,至少是短暂地停止,以便正确迁移对旧页面的修改。要使页面迁移高效、快速,还有一系列其他要求。简而言之,除非真的有必要,否则操作系统应该避免它。
通常,不能假设NUMA机器上的所有进程都使用相同数量的内存,(不能假设)随着进程在处理器之间的分布,内存使用也会均匀分布。事实上,除非机器上运行的应用程序非常具体(在HPC世界中很常见,但在其他不常见),否则内存使用将非常不平均。一些应用程序将使用大量内存,而其他应用程序几乎没有。如果总是将内存分配给发出请求的处理器,这迟早会导致问题。系统最终将耗尽NUMA节点的本地内存。
作为对这些严重问题的响应,默认情况下,内存不是仅在本地节点上分配的。要利用系统的所有内存,默认策略是将内存条带化。这保证了系统所有内存的平等使用。作为一个副作用,可以在处理器之间自由迁移进程,因为平均而言,对所使用的所有内存的访问成本不会改变。对于较小的NUMA系数,条带化是可以接受的,但仍然不是最佳的(见第5.4节中的数据)。
这是一种悲观情绪,有助于系统避免严重问题,并使其在正常运行时更具可预测性。但在某些情况下,它确实会显著降低系统的整体性能。这就是为什么Linux允许每个进程选择内存分配规则。一个进程可以为自己及其子进程选择不同的策略。我们将在第6节介绍可用于此目的的接口。
5.3 公开的信息
这个章节感觉没有意思。
5.4 访问非本节点内存的开销
不过,NUMA节点距离是相关的。在[amdccnuma]AMD文档记录了四插槽机器的NUMA开销。对于写操作,如图5.3所示。
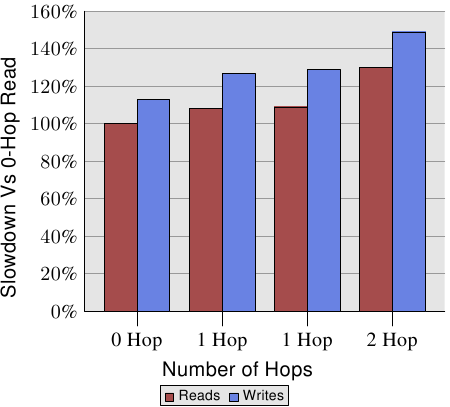
图 5.3: 多节点之上的读写性能
写比读慢,这并不奇怪。有趣的是单跳和两跳的开销。其中两个单跳场景的开销实际上略有不同。有关详细信息,请参见[amdccnuma]。从这个图表中我们需要记住的事实是,两跳读取和写入分别比0跳读取慢30%和49%。两跳写入比0跳写入慢32%,比单跳写入慢17%。处理器和内存节点的相对位置会产生很大的差异。AMD的下一代处理器将为每个处理器提供四条连贯的超级传输链路。在这种情况下,四CPU插座机器的直径为1(C=2)。对于八个CPU插座,同样的问题再次出现,因为有八个节点的超立方体的直径是3(C=3)。
所有这些信息都是可用的,但使用起来很麻烦。在第6.5节中,我们将看到一个接口,它有助于更轻松地访问和使用这些信息。
最后一些系统能够提供的信息是进程本身的状态。这些信息可以确定内存映射文件、写时拷贝(COW)页面和匿名内存如何分布在系统中的节点上。每个进程都有一个文件/proc/${PID}/numa_maps,其中PID是进程的ID,如图5.2所示。
00400000 default file=/bin/cat mapped=3 N3=3
00504000 default file=/bin/cat anon=1 dirty=1 mapped=2 N3=2
00506000 default heap anon=3 dirty=3 active=0 N3=3
38a9000000 default file=/lib64/ld-2.4.so mapped=22 mapmax=47 N1=22
38a9119000 default file=/lib64/ld-2.4.so anon=1 dirty=1 N3=1
38a911a000 default file=/lib64/ld-2.4.so anon=1 dirty=1 N3=1
38a9200000 default file=/lib64/libc-2.4.so mapped=53 mapmax=52 N1=51 N2=2
38a933f000 default file=/lib64/libc-2.4.so
38a943f000 default file=/lib64/libc-2.4.so anon=1 dirty=1 mapped=3 mapmax=32 N1=2 N3=1
38a9443000 default file=/lib64/libc-2.4.so anon=1 dirty=1 N3=1
38a9444000 default anon=4 dirty=4 active=0 N3=4
2b2bbcdce000 default anon=1 dirty=1 N3=1
2b2bbcde4000 default anon=2 dirty=2 N3=2
2b2bbcde6000 default file=/usr/lib/locale/locale-archive mapped=11 mapmax=8 N0=11
7fffedcc7000 default stack anon=2 dirty=2 N3=2
Figure 5.2: Content of /proc/PID/numa_maps
文件中的重要信息是N0到N3的值,它指示为节点0到3上的内存区域分配的内存页数。很可能该程序是在CPU核心被调度到节点3的上执行的。程序本身和脏页都分配在该NUMA节点上。只读映射,例如ld-2.4的第一个映射ld.so和libc-2.4.so。因此,共享文件区域设置归档文件也会分配到其他节点上。
如图5.3所示,对于单跳和双跳的读取,节点间的读取性能分别下降9%和30%。对于执行时,如果如果二级缓存miss,则需要调用这样的读取操作,则每个缓存线都会产生这些额外的开销。如果内存距离处理器较远,则超出缓存大小的大型工作负载的所有成本都必须增加9%/30%。
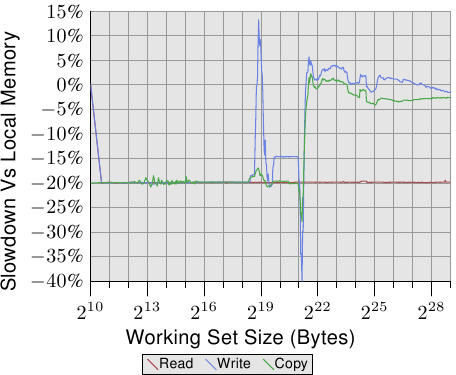
Figure 5.4: Operating on Remote Memory
要查看真实世界中的效果,我们可以按照第3.5.1节测量带宽,但这一次,内存位于远端NUMA节点上,单跳的距离。与使用本地内存的数据相比,该测试的结果如图5.4所示。这些数字在两个方向上都有一些大的尖峰,这是测量多线程代码问题的结果,可以忽略。此图中的重要信息是,读取操作总是慢20%。这比图5.3中的9%要慢得多,图5.3中的9%很可能不是uninterrupted读/写操作的数字,可能指的是较旧的处理器版本。只有AMD知道。
对于适合缓存的工作集大小,写入和复制操作的性能也会降低20%。对于超过缓存大小的工作集,写入性能不会明显低于本地节点上的操作。互连的速度足够快,可以跟上内存的速度。主要因素是等待主内存的时间。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK