

一日一技:使用Python翻译HTML中的文本字符串
source link: https://www.kingname.info/2022/06/20/translate-html/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
一日一技:使用Python翻译HTML中的文本字符串
相信大家都用过浏览器的翻译网页功能,例如对于下图这个英文网页:
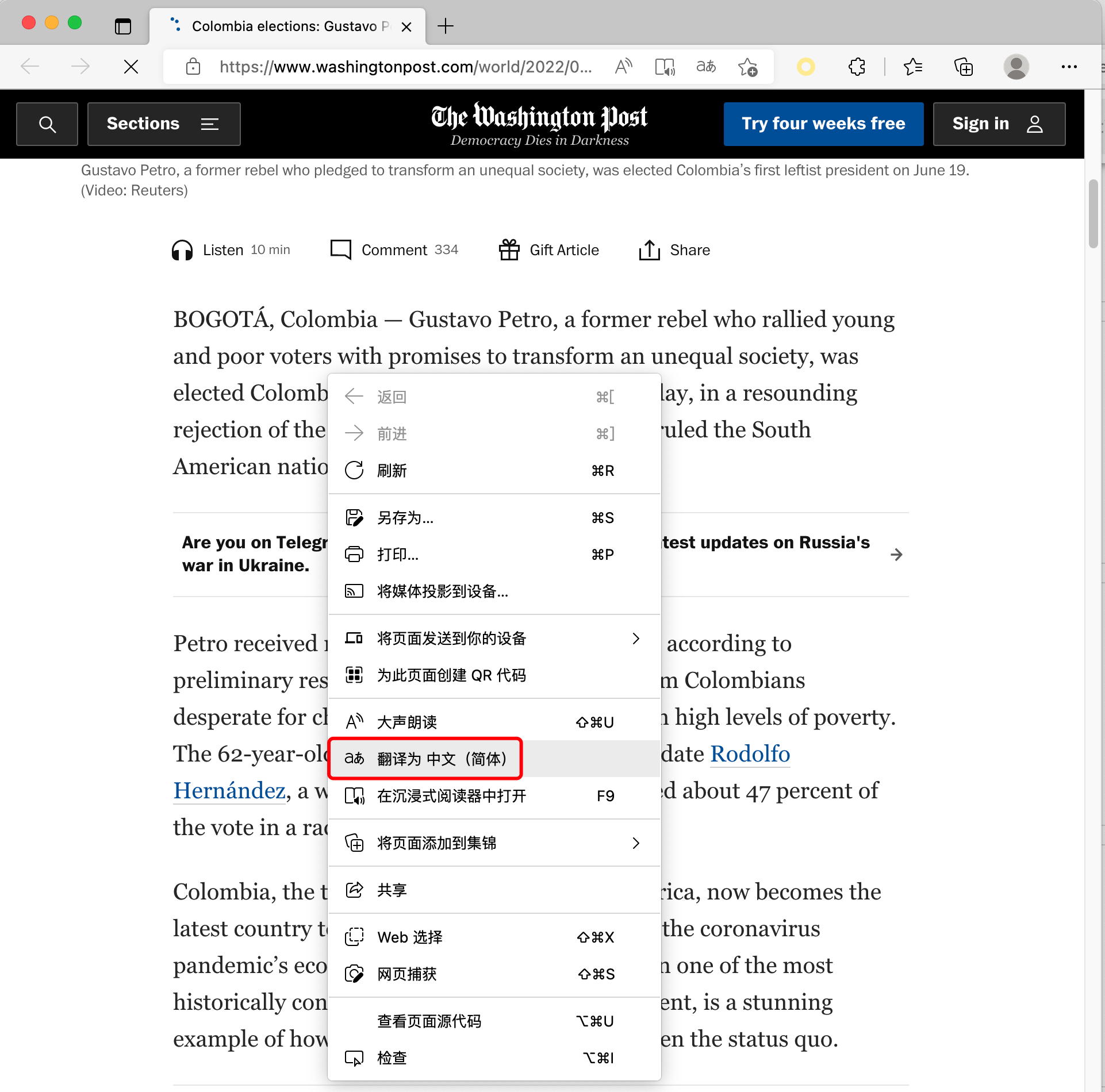
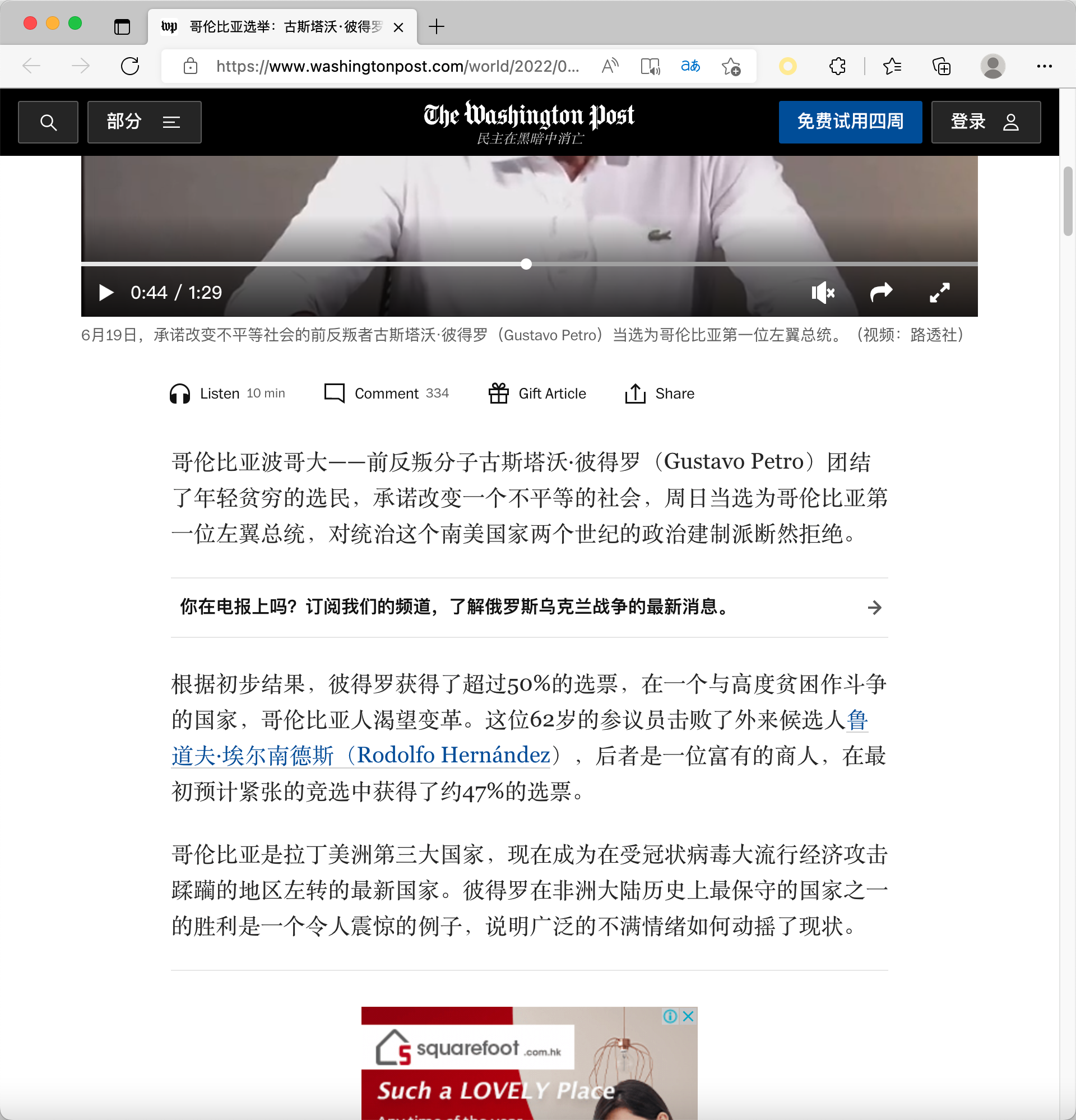
一键翻译成中文以后是这样的:
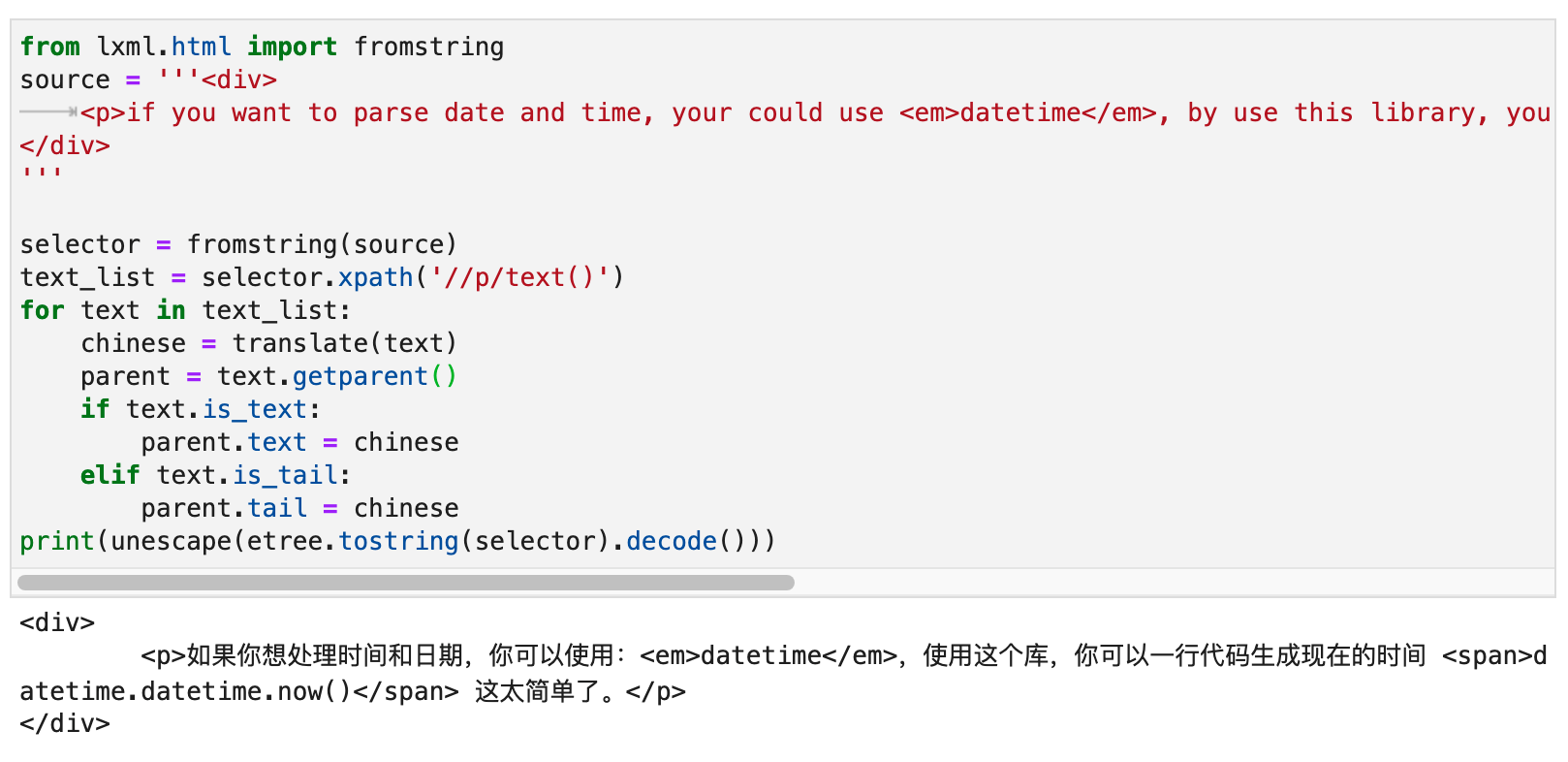
你可能会觉得这个功能很简单,不就是字符串替换吗?那你可以试一试把下面这个HTML片段中的<p>标签下面的英文翻译成中文。其它标签中的不要改动:
<div>
<p>if you want to parse date and time, your could use <em>datetime</em>, by use this library, you can generate now time by one line code <span>datetime.datetime.now()</span> this is so easy.</p>
</div>
在<em>标签中的datetime和<span>标签中的datetime.datetime.now()不需要翻译。
你一拍脑袋,马上写出了下面这几行代码(假设你已经有了一个现成的translate()函数,传入英文,输出中文):
from lxml.html import fromstring
source = '''<div>
<p>if you want to parse date and time, your could use <em>datetime</em>, by use this library, you can generate now time by one line code <span>datetime.datetime.now()</span> this is so easy.</p>
</div>
'''
selector = fromstring(source)
text_list = selector.xpath('//p/text()')
for text in text_list:
chinese = translate(text)
...
当你写到这里,你应该会愣一下。因为你突然发现一个问题,怎么把中文替换回去?
不用尝试去百度了。在今天(2022-06-20)之前,整个中文网络里面,你找不到解决方法。
一个比较笨的办法是直接对原始的HTML字符串进行文本替换:
for text in text_list:
chinese = translate(text)
source = source.replace(text, chinese)
但这样做,效率非常低。因为你要不停扫描整个HTML字符串。一般一个中型网站的HTML就有几千上万行,十几二十万个字符。你每翻译一小段就全文替换一次,这个时间会非常漫长。
那有没有办法只对当前这一个<p>标签里面的文本进行替换呢?关键的问题来了,你替换可以,但是怎么才能不影响这个<p>标签下面的两个子标签?要保证文本和子标签的相对位置不改变。
如果<p>标签下面只有一段文本,没有子标签,那么非常简单,如下图所示:
但现在的问题是,<p>标签下面有三段文本。每段文本之间还插入了其它的子标签。我们怎么样对每一段文本进行替换,但是又保持文本的相对顺序,并且还不能影响子标签?
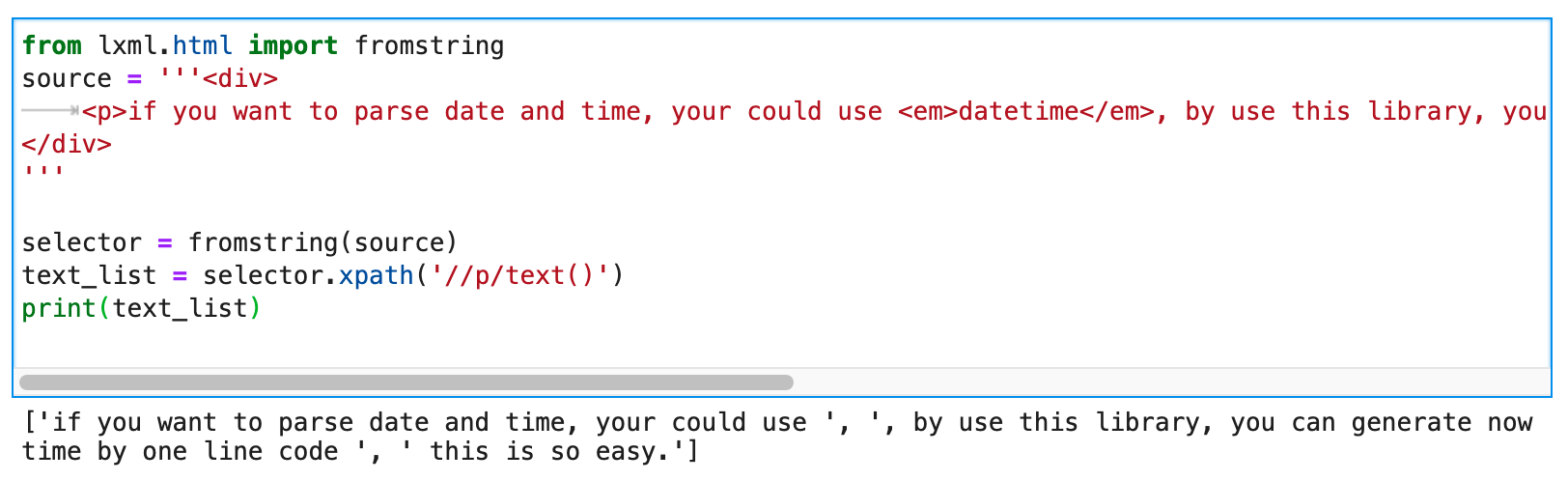
p.text这种写法首先就可以排除了,因为它没有办法指定替换第几段文本。
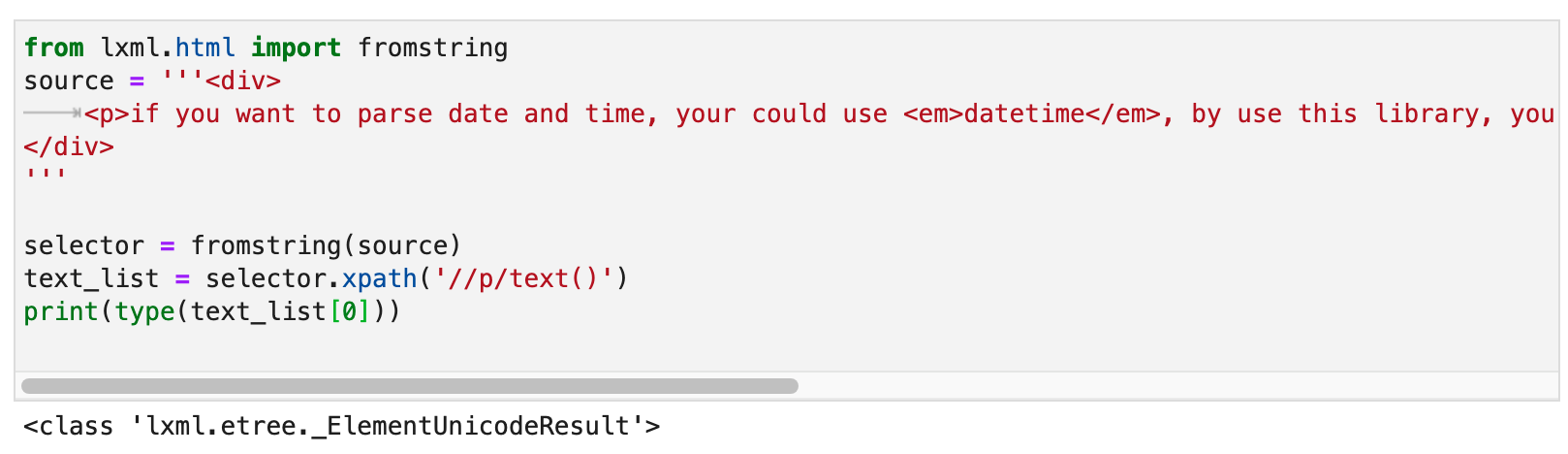
你之所以会觉得这个问题很难解决,是因为你有一个错觉,请看上面这张截图,我打印了text_list。打印出来是一个包含字符串的列表。所以你可能会觉得。使用lxml写Xpath的时候,/text()返回的总是包含字符串的列表。
但实际上,返回的列表里面的元素并不是字符串,而是_ElementUnicodeResult对象。如下图所示:
不是字符串就简单了,那么我们可以获取每一个文本对象的父标签。然后修改父标签下面的文本就可以了。
看到这里,你肯定会问,这三个文本节点的父标签,不都是同一个<p>吗?如果你觉得是,那你就犯了想当然的错误。我们用代码来看看:
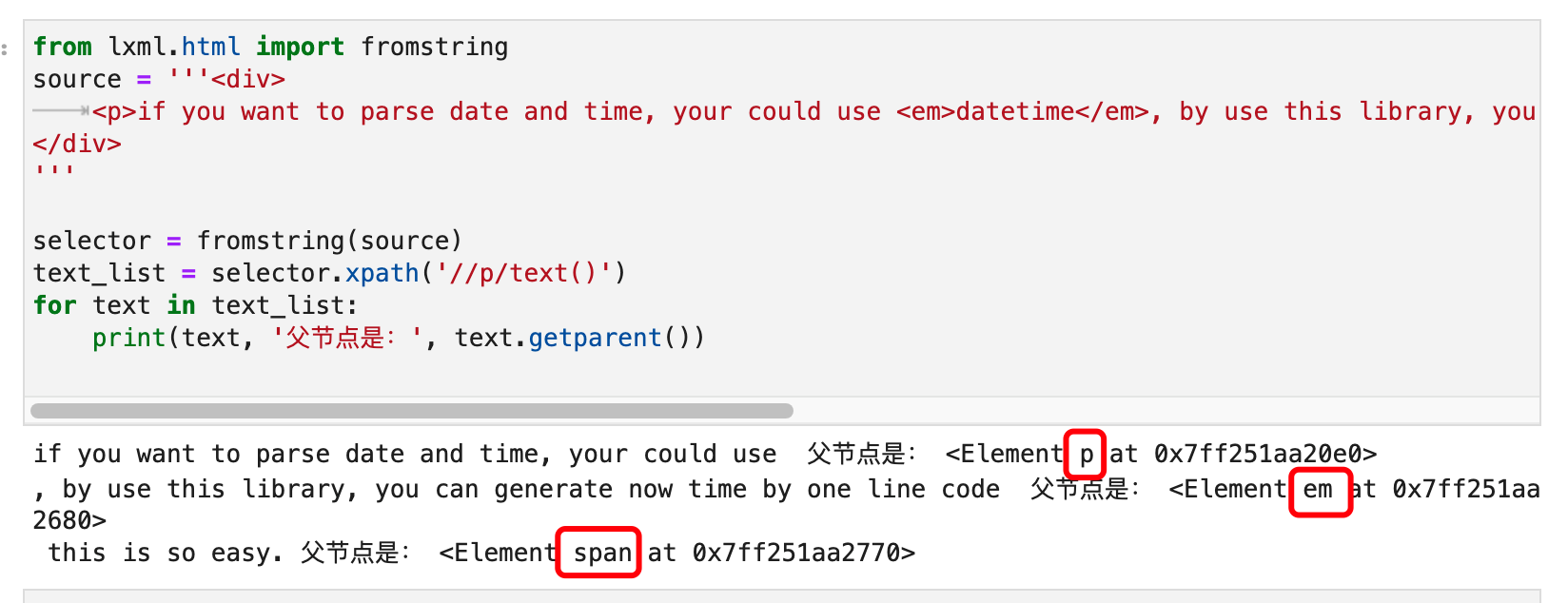
其实只有第一段文本的父标签是<p>。第二段文本的父标签,竟然是<p>的子标签<em>。第三段文本的父标签,是<span>。
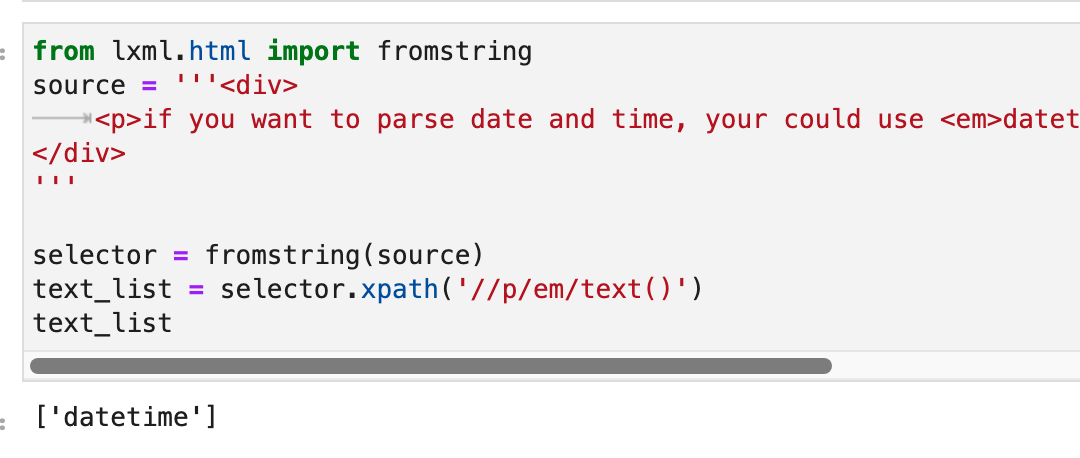
等等,如果第二段文本的父标签是<em>,那么<em>datetime</em>里面的datetime的父标签是什么?它的父标签也是<em>!那么问题来了,<em>的text()文本节点,怎么可能又是datetime,又是<p>下面的第二段文本呢?
实际上,<em>的text()始终都是datetime。如下图所示:
那么,<p>的第二段文本跟这个<em>标签是什么关系?实际上,这个关系叫做tail。如下图所示:
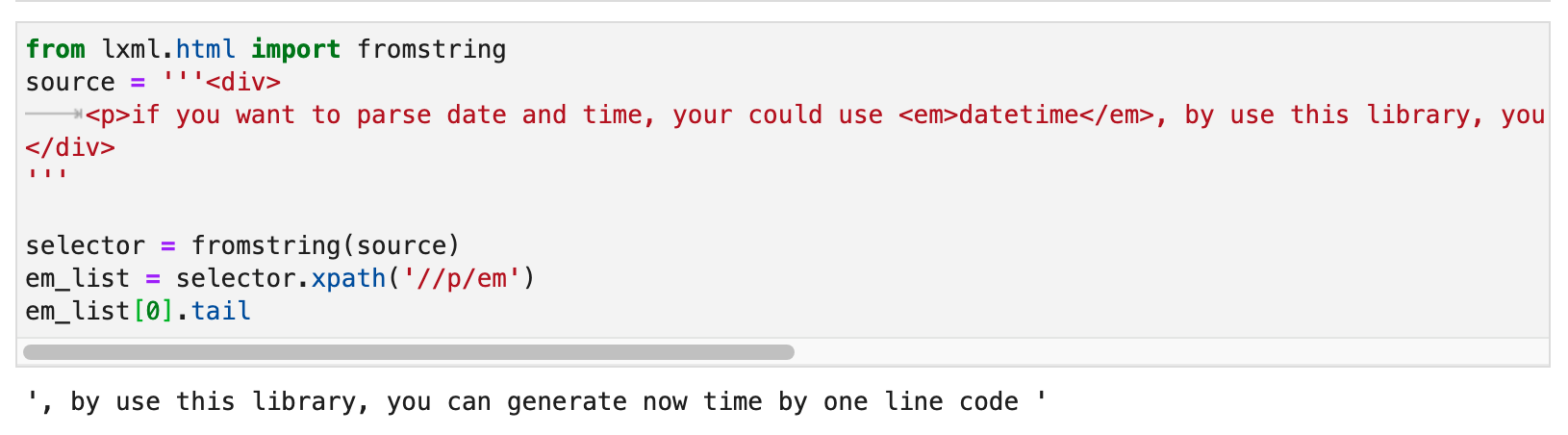
在一个标签里面,只有第一段text是它真正的text(),如果这个标签有子标签,那么位于子标签后面的文本,是这个子标签的tail。只不过当我们在正则表达式里面写/text()的时候,lxml会帮我们把所有子标签的tail都算作当前标签的text。
我们可以使用文本节点的.is_text和.is_tail来判断它属于哪种文本。最终运行效果如下图所示:
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK