

大数据平台迁移实践 | 海豚调度在当贝大数据环境中的应用-开源基础软件社区-51CTO.COM
source link: https://ost.51cto.com/posts/13895
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

大家下午好,我是来自当贝网络科技大数据平台的基础开发工程师 王昱翔,感谢社区的邀请来参与这次分享,关于 Apache DolphinScheduler 在当贝网络科技大数据环境中的应用。
本次演讲主要包含四个部分:
-
平台建设的背景
-
大数据平台重构
-
大数据调度平台建设
-
下一步规划

当贝大数据平台基础开发工程师
毕业于电子科技大学,主要是做大数据平台的构建、集成及组件的运维的工作。
在当贝网络科技使用 Apache DolphinScheduler 作为大数据调度平台之前,我们在平台、测试环境和调度环境中都面临着不少问题需要解决。
02 大数据平台架构
这次我将从架构重构的目标、ClickHouse 迁移、大数据平台成功迁移、计算分离,以及大数据平台监控架构设计等几个方面给大家进行分享。

平台重构目标
- 打造一个高效稳定的大数据平台,这是平台的首要目标;
- 实现数据的海量存储;
- 实现平台的安全高可用架构;
- 实现计存分离;
- 环境可视化操作;
- 监控即时告警。
- 大数据平台重构架构设计
我们对大数据平台进行了重构设计。
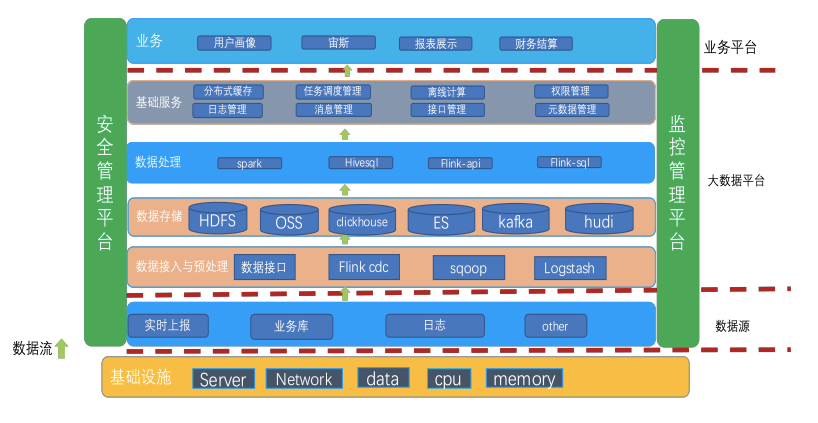
最下面是基础环境,中间是数据源,再向上是数据的预处理,即CDC,数据导图工具。以及数据存储。平台基于 HDFS、OSS、 ClickHouse、ES、Kafka 和 Hudi 进行存储,向上是数据处理的计引擎,再向上是任务调度权限管控,接口管理等基础服务管理,架构的最上层是在此之上进行的公司业务处理。
大数据平台需求分析
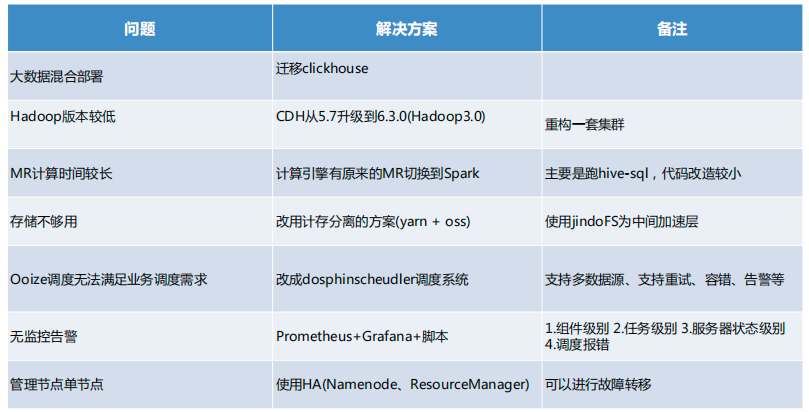
此前,公司的大数据平台存在一些问题。从平台环境来说,主要存在的问题包括版本较低,服务部署混乱,计算引擎 MR速度比较慢,存储不足,而且扩容较难,服务缺乏高可用的架构,服务挂掉之后数据缺失;缺少可视化的操作,需要后台操作;还缺乏报警机制,任务挂掉之后没有通知;运维起来也很困难,需要人肉运维。
在测试环境上,缺少测试环境,本地开发完后直接提交代码上生产,没有经过测验证,导致晚上任务异常报错。
调度环境上,我们原来使用的是 Ooize调度,其系统配置比较复杂,可视化效果较差,没有补数,不支持权限管理,不支持多租户,还容易出现死锁。另外,运维监控能力不足,可视化效果差,无法在线查看日志,故障排除进入后台排错,流程复杂。
大数据平台问题调研分析
经过调研分析,我们找到了大数据平台的主要问题在于几个方面:OS 版本低,组件部署混乱,多系统数据磁盘共用,磁盘空间不足也是一大问题,导致每天晚上零点之前需要把昨天的数据删掉,来保证有 T+1 数据的存储空间。
大数据平台问题及解决方案
针对大数据平台混合部署的问题,我们历时一个半月的时间迁移了 ClickHouse。
关于版本过低的问题,我们把 CDH 从 5.7 升级到 6.3.0(Hadoop 3.0)重构了一套集群。
MR 计算引擎计算时间较长,我们将计算引擎从 MR 切换带 Spark,主要是跑hive-sql,代码改造较少。
针对存储不足的问题,我们采用了计存分离的方案,使用 yarn+oss,并用 jindoFS 作为中间加速层。
原来的 Ooize 调度无法满足我们现有的业务调度的需求,于是我们就改用 Apache DolphinScheduler 进行调度。后者的好处包括是支持多数据源,支持容错告警,以及相当有用的多租户功能。
针对无监控告警这一点,我们采用 Prometheus+Grafana,以及 Python脚本去做监控,分为组件级别、任务级别、服务器状态级别,以及调度报错。
最后,我们使用 HA (Namenode、ResourceManager) 管理单节点,进行故障转移。
ClickHouse 迁移方案
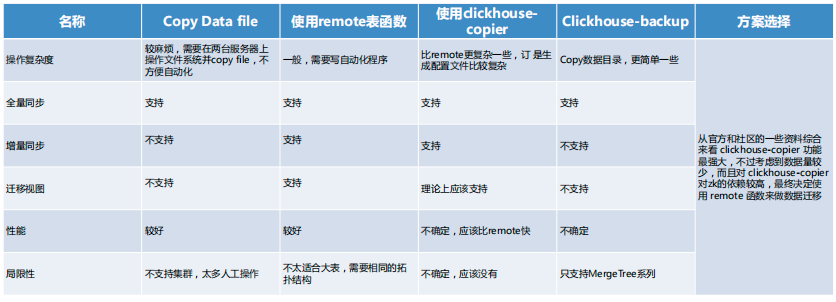
在迁移 ClickHouse 时,我们多种备选方案,分别是直接停机进行 copy,使用 Remote 表函数,使用 Clickhouse copier,以及 更简单的 copy 数据目录的方法。
但是从操作复杂度、全量同步、增量同步、性能等多方面考虑,我们选用了第二种方案。此方案支持全量同步和增量同步,潜意识图,性能也较好,但局限性在于不太适合达标,需要相同的拓扑结构。
ClickHouse 迁移方案&迁移过程
迁移执行过程:
一、找出原来建表语句
select database,create_table_query from system.tables where database in(‘athena’,‘dmp’,‘sony’);
二、在新的clickhouse创建databases和table
创建数据库
create database dmp ON CLUSTER cluster_clickhouse; 创建表:导出后搞成自动化脚本去执行
三、数据迁移语句(可以用python写成脚本的方式去执行,可以线下交流)
insert into dmp.dws_dmp_user_local ON CLUSTER cluster_clickhouse SELECT * FROM remote(‘192.168.1.1:9000’, dmp, dws_dmp_user, ‘default’, ‘’);
四、数据迁移前的注意事项
1.cluster_5shards_1replicas–>cluster_clickhouse
2.表名后面添加 ON CLUSTER cluster_clickhouse
大数据平台迁移升级方案
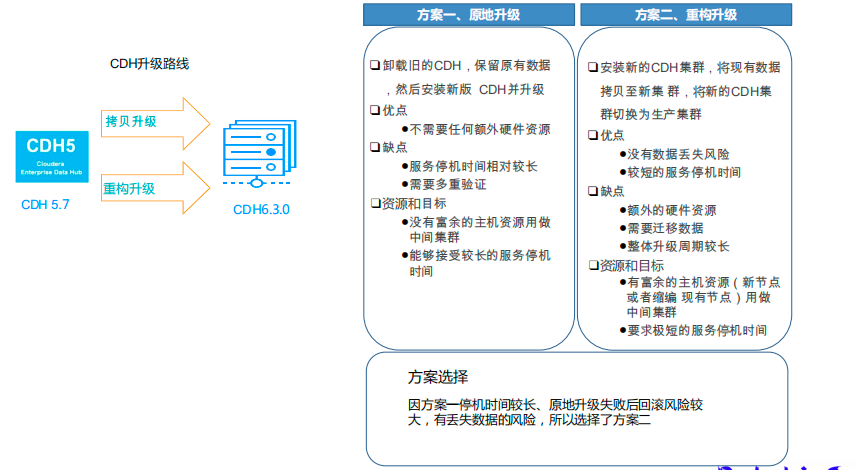
在迁移 ClickHouse 为平台提供了足够空间后,我们设计了平台的迁移和升级方案。有两种备选方案:
方案一、原地升级
这种方案是卸载旧的 CDH,保留原来数据,安装新版 CDH 并升级。其优点是不需要任何额外硬件资源,但缺点是停机时间较长,需要多种验证。
方案二 、重构升级
第二种方案是安装新的 CDH 集群,将现有数据拷贝到新集群,切换为生产集群。其优点是没有数据丢失的风险,停机时间较短,缺点是需要额外的硬件资源,需要迁移数据,以及 整体升级周期较长。
由平台建议,一个实施流程基本上分为三个阶段:一个是预备期,第二个是并行期,第三个是运行期。预备期是在测试搭建一道测试环境,然后进行方案验证,验证通过后在新建一套生产集群。并行期的两个集群,老集群数据和服务的迁移到新的集群上,然后对数据和服务进行验证。就是迁移的时候要考虑到两个集群增量的数据的持平这一块。运行期新老集群割接.因方案一停机时间较长、原地升级失败后回滚风险较大,有丢失数据的风险,所以我们选择了方案二。
任务迁移流程
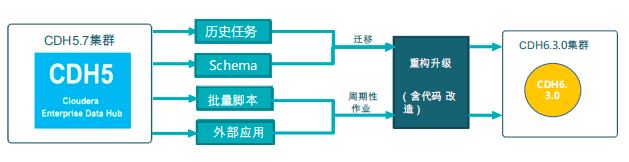
平台迁移流程主要包括对历史任务、Schema、批量脚本和外部应用的数据迁移。
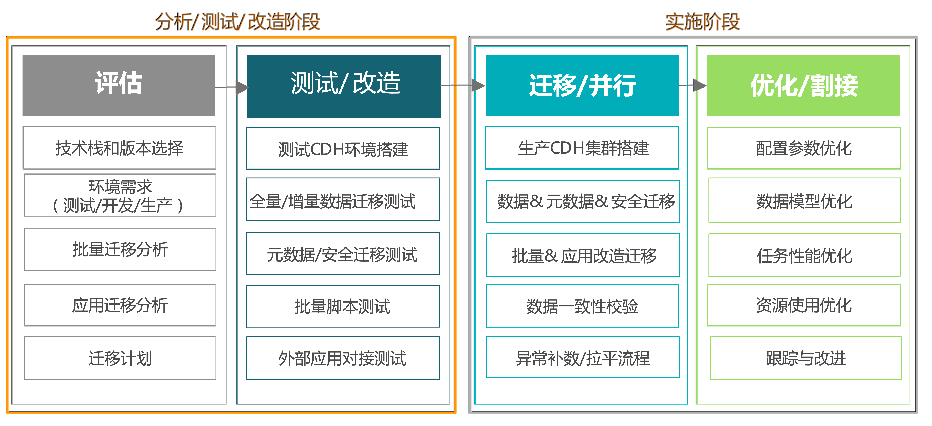
平台迁移任务主要分为评估、测试/改在、迁移/并行、优化/割接四个阶段。
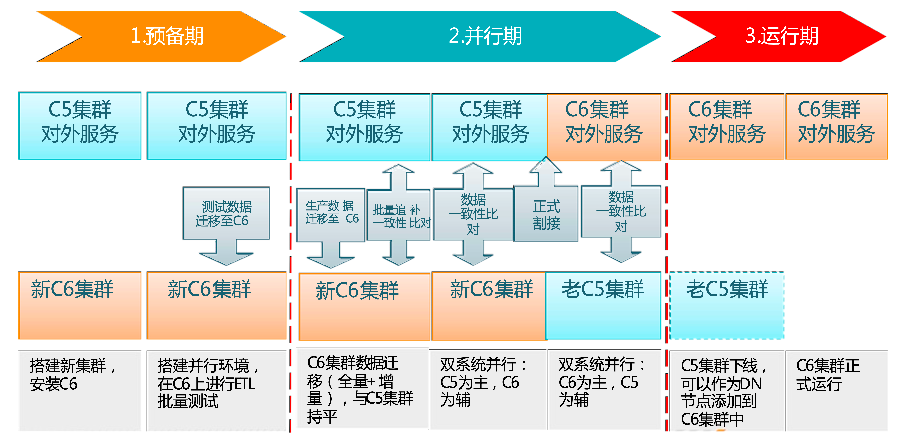
经过搭建新集群,数据迁移,旧集群下线和新集群切换,新集群正式运行。
此外,为了进行大数据平台构建和迁移,我们还进行了数据一致性校验,Hive 元数据迁移等一系列工作。
计存分离架构
并采用计存分离的存储架构,实现数据更高效的存储。
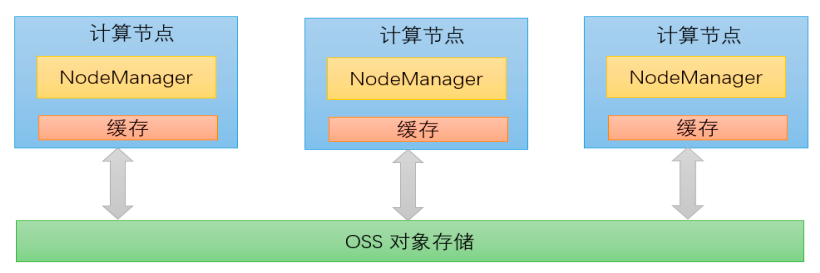
集成 jindoFS
我们还将阿里的 jindoFS 和 CDH 集成,实现了高效的数据分析、数据加速和数据存储。
计存分离数据效果图
监控平台设计
我们设计的大数据监控主要包括两部分,一是平台资源监控,一个是任务运行状态监控。
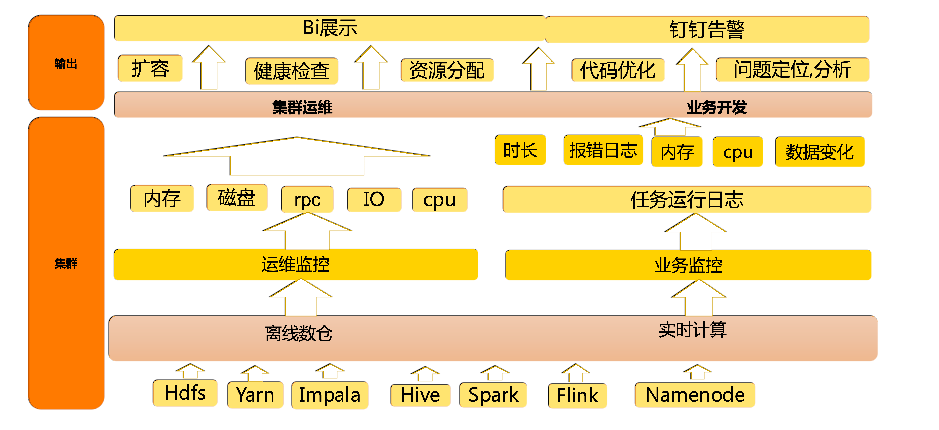

监控 BI 展示
03 调度系统迁移
调度系统调研
在调度系统上,我们原来采用的是 Oozie,但是在使用过程中发现其缺点不可忽视,比如可视化的界面差;缺乏补数、重试功能;严重依赖当前集群版本,二开难度大;配置复杂、调度任务时出现死锁;不支持租户、权限,管控能力差。
于是我们进行了调度系统重新选型。在调研过程中,我们对比了主流的调度系统工具,并决定采用 Apache DolphinScheduler。
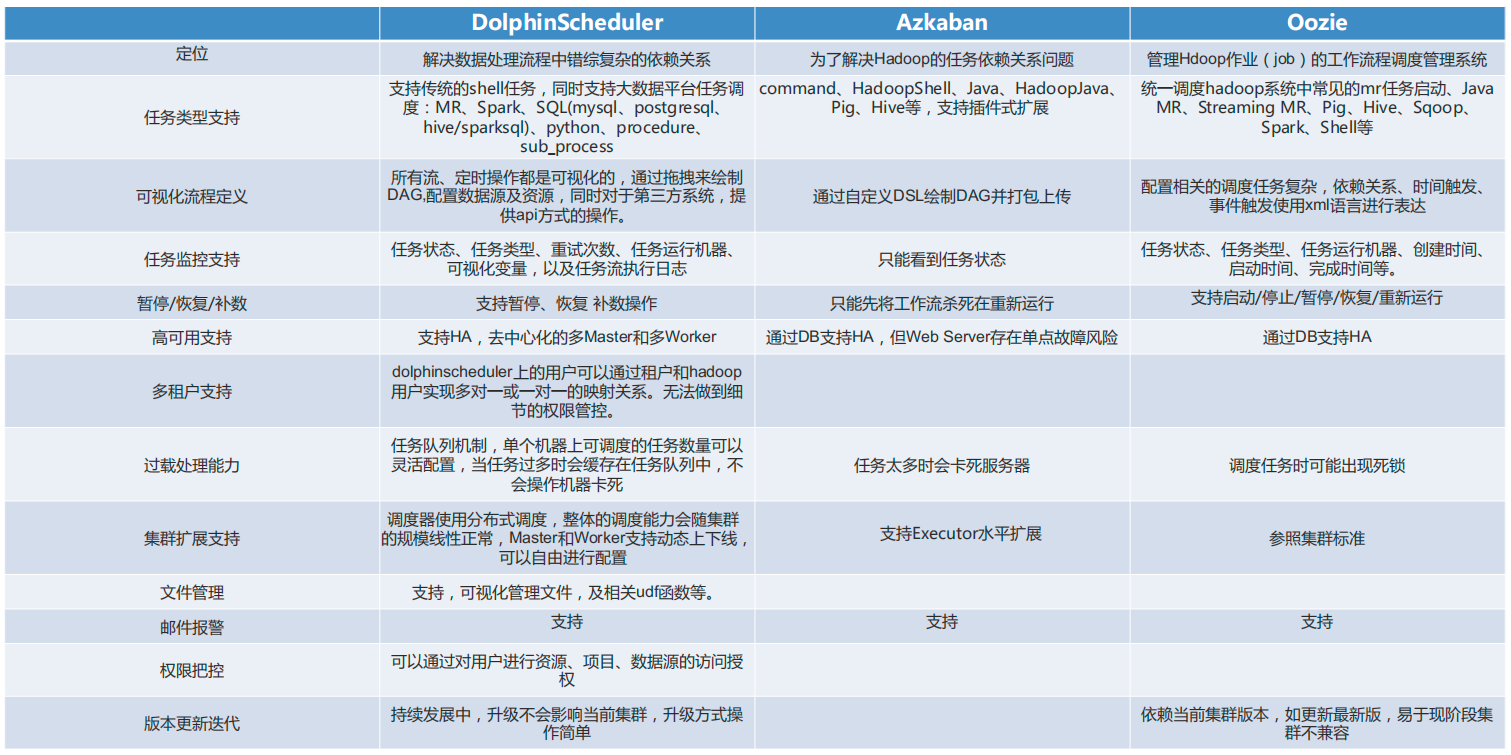
为什么选择 Apache DolphinScheduler ?
经过对比,我们发现 Apache DolphinScheduler 的以下特性非常符合我们的业务需求:
-
通过拖拽任务绘制工作流DAG
-
任务支持动态暂停/停止/恢复操作
-
支持失败重试/告警、容错、补数等操作
-
支持全局参数及节点自定义参数设置
-
支持集群HA,集群去中心化
-
支持运行历史树形/甘特图展示
-
丰富的任务类型支持
调度系统支撑的业务架构
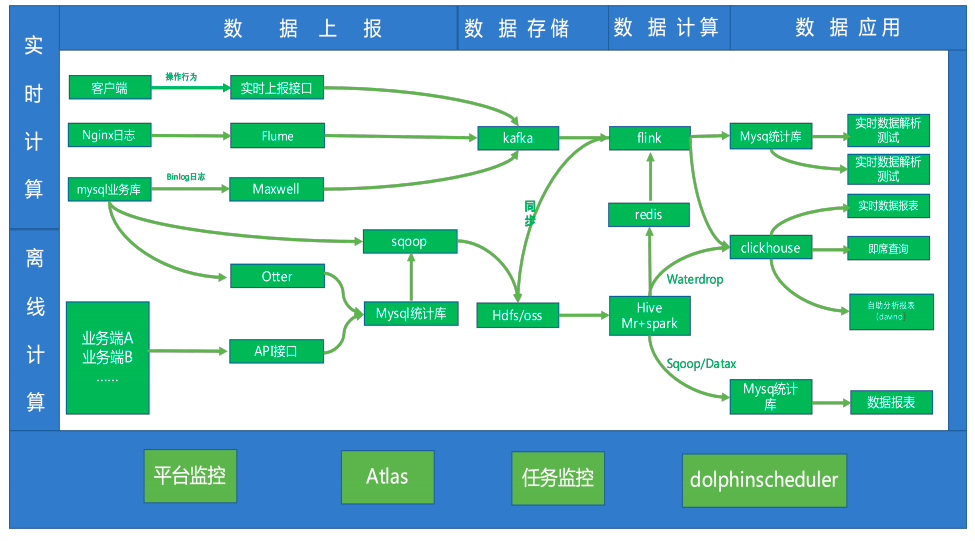
我们使用 ApahceDolphinScheduler 的 1.3.8 版本,2 个 Master节点和 7 个Worker 节点,1个 API 节点,日调度流程 200+,日调度任务 5000+,服务 20+ 业务线,处理 T+1 任务场景,组件主要使用到了 Shell、Spark、Hive、Sqoop、Datax、SeaTunnel(原Waterdrop) 和 MR。
01 迁移方案&流程
迁移方案上,我们采用边运行边迁移,循形渐进的方式,由易到难,按业务分批迁移,验证通过后老系统任务下线。

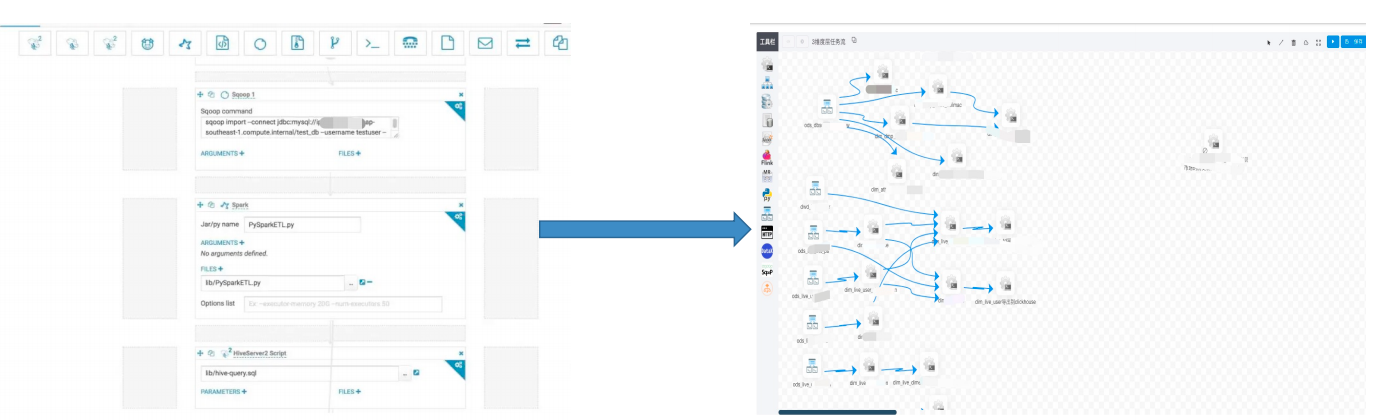
通过迁移前后对比,我们可以看到系统管理更加便捷,系统更稳定,开发也更高效了。
我们选择使用 Shell节点作为项目代码的一部分,可以在 Git 上直接维护,将代码下载到服务器上使用。
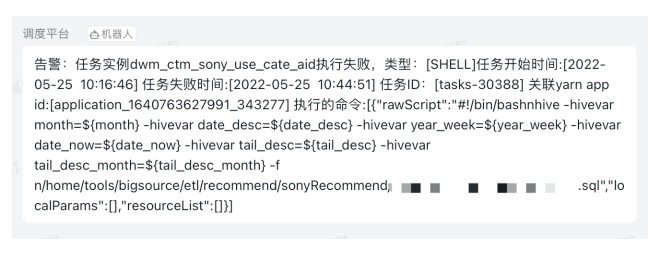
02 调度系统监控
我们还自己开发了调度监控系统,特点是包含任务实例和任务类型,以及任务开始时间和结束时间,并对任务和 ID 进行关联,可以看到报错的语句。
03 调度系统存在的问题
因为我们使用的是原生的 1.3.8 版本,没有进行二开,但是任务多了以后发现存在以下问题:
- Master调度工作流时依赖分布式锁,导致调度工作流吞吐量难以提升,极端情况下调度可能出现高延迟;
- Master资源利用率低
- Master创建大量线程池,导致线程上下文切换频繁,大量线程处于轮询数据库状态,线程利用率低;
- 数据库压力大
- Master通过轮询数据库来查询任务状态,任务数多的时候导致数据库压力大;
- 各组件存在耦合情况
-
注册中心耦合Zookeeper
-
Worker耦合任务,需要打入许多依赖jar包
04 下一步计划
-
升级到2.0架构 ,解决1.3架构存在的问题;
-
定制开发与公司的多个平台集成;
-
实现跨集群任务调用,测试和生产环境共用一套任务调度;
-
完善监控告警。
05 拥抱开源
后续,我们还计划参与到更多 Apache 开源项目中。
01 为什么参与开源?
- 提升技术功底:学习源码里的优秀设计思想,比如疑难问题的解决思路,一些优秀的设计模式,整体提升自己的技术功底;
- 深度掌握技术框架:源码看多了,对于一个新技术或框架的掌握速度会有大幅提升 ;
- 快速定位线上问题:遇到线上问题,特别是框架源码里的问题(比如bug),能够快速定位;
- 拥抱开源社区:参与到开源项目的研发,结识更多大牛,积累更多优质人脉看源码。
02 参与开源的方法
- 先使用:先看官方文档快速掌握框架的基本使用;
- 抓主线:找一个demo入手,顺藤摸瓜快速看一遍框架的主线源码,画出源码主流程图,切勿一开始就陷入源码的细枝末节,否则会把自己绕晕,凭经验猜;
- 画图做笔记:总结框架的一些核心功能点,从这些功能点入手深入到源码的细节,边看源码边画源码走向图,并对关键源码的理解做笔记,把源码里的闪光点都记录下来,后续借鉴到工作项目中,理解能力强的可以直接看静态源码,也可以边看源码边debug源码执行过程,观察一些关键变量的值;
- 整合总结:所有功能点的源码都分析完后,回到主流程图再梳理一遍,争取把自己画的所有图都在脑袋里做一个整合。
这就是我分享的全部内容,感谢聆听!
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK