

Multi-Network ns在Underlay下的应用-妙手篇
source link: https://www.51cto.com/article/711496.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

大家好,我是二哥。接着上篇《multi-network ns在Underlay下的应用-本手篇》,我们来聊聊基于 multiple network ns 的妙手级应用:Underlay 。上一篇包含 multi network ns 的基础概念,建议没有读过的小伙伴先看一遍。毕竟高考作文题说了:对于初学者而言,应该从本手开始,本手的功夫扎实了,棋力才会提高。一些初学者热衷于追求妙手,而忽视更为常用的本手。本手是基础,妙手是创造。
1、从 multi-VM 到 multi-network ns
为了能显示出 multi network ns 的重大作用,二哥想借另外一张图来做个对比,让小伙伴们看看从原先的 multi-VM 进化到 multi-network ns 是多么的必要。在图 1 里,物理机器上创建了若干个 VM 。由 VMM 向 VM 虚拟出 CPU / Memory / Disk / 网卡等设备。每个 VM 的 OS 部分会创建一个 net_device ,它是一个数据结构,用来对这个VM所拥有的网卡进行软件层次的抽象,尽管这个网卡本身也是虚拟的,但只要 VM 觉得它是一张实实在在的网卡,那就够了。实际上这些网卡只是 tap 设备,它连接到物理机的 Open vSwitch 上,我们大致可以将 vSwitch 粗略地理解为一个 bridge 。
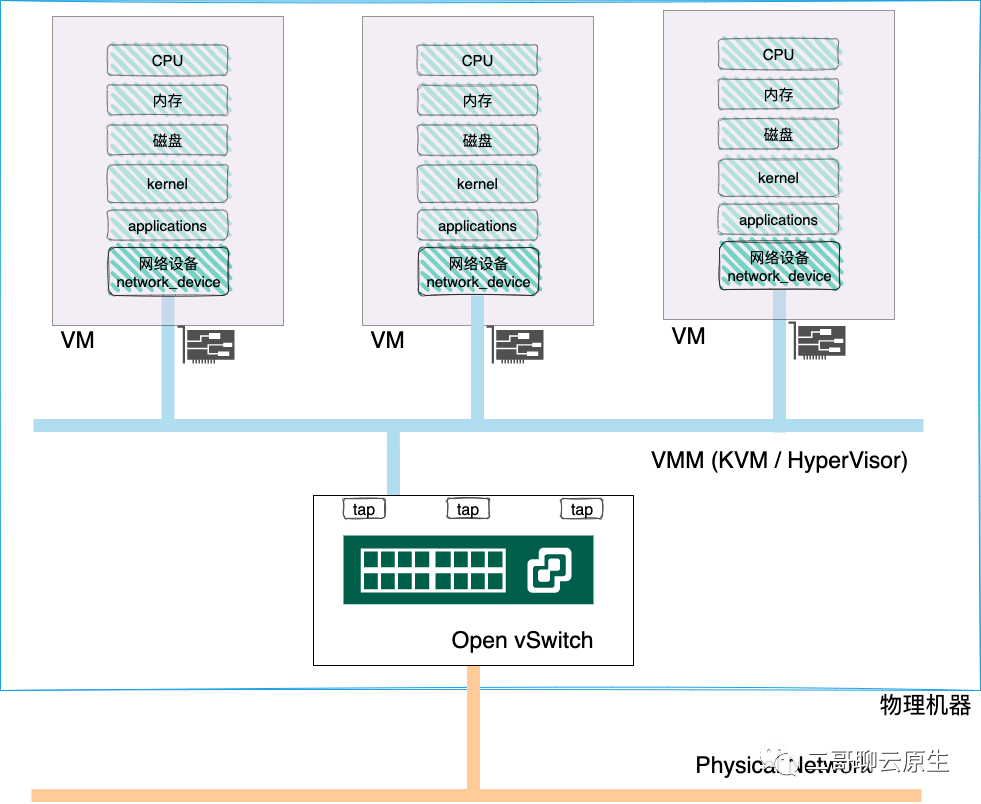
图 1:multi-VM
熟悉 ECS 或者在阿里云/腾讯云上购买过云服务器的同学一定知道通常一台 VM 上只会跑一个或极少量的应用(Workload),大部分情况下这个 VM 上的 CPU / Mem / Disk 等资源都是处于闲置状态,更别提会使用多个 network ns 这种技术来隔离多个应用了。 无论是个人还是公司,大家的钱都不是天上掉下来的,降本增效是永恒的目标。一旦有更节省资源的方式出现,大家一定会趋之若鹜。基于 multi namespace 的 Docker 的出现给云计算机市场所带来的几乎是颠覆性改变就很好地证明了这一点。图 2:一个包含 multi network namespace 的环境
看过《蚁人2:黄蜂女现身》吗?皮姆博士瞬间把整栋大楼缩小成了一个拉杠箱,是不是帅呆了?如果将 图 1 中的 vSwitch 缩小到图 2 中 bridge 大小,或者将其放置到 bridge 的位置,那么连接在 vSwitch 上的这些 VM 其实也就一下子缩小到了连接在 bridge 上的属于多个 network ns 的 Pod 。也很帅,有没有?以图 2 为基础:
- 加上 VTEP 就搭建了 Overlay 的基本盘
- 加上 flanneld 这样的设施,搭配下面这样的路由设置就改造成 host-gw 了一个 Work Node 上面运行有一个 bridge ,每个 bridge 组成一个子网。在所有 Work Node 的路由表上均添加一条记录:通往一个子网(比如:10.244.1.0/24)的 “下一跳”为运行有该 bridge 的 Work Node 的 IP 地址。也就是说这台 “主机”(Host)会充当通往这条容器通信路径里的“网关”(Gateway)。Host-gateway 得名于此。
看起来好像挺不错,将 Workload 所用资源从 VM 粒度缩小到 Pod 粒度所节省的资源确实非常的感人。按照二哥的经验,对于一个像 Web server 这样的 I/O 型的 Workload ,原先的 VM 粒度是 2 core + 4 GB Memory 的话,可以缩小到 0.5 core + 200 MB 这样的 Pod 粒度(假设 Pod 里只有一个 container)。不过好像有哪里不太对劲:图 2 中 bridge 是组成了一个子网,但看起来子网内每个 Pod 想要访问子网外的资源,网络流量就得从 root ns 走一圈。能不能既保留图 2 这样的细粒度资源虚拟化和分配方式,网络流量又能像图 1 的 VM 那样大路朝天,各走各边?
2、Underlay
群众的呼声就是容器云产商前进的动力。这不,以 AWS ENI 为代表的,利用弹性网卡来实现的 Underlay 完美地解决了图 2 的弊端。既然图 2 所示弊端的根源在于所有的 Pod 共享了 VM 所拥有的这一张网卡,那能不能给图 2 中每个 Pod 配备一张单独的网卡呢?比如像图 3 这样,去掉 bridge ,人手一个网卡。豪横的感觉出来了,有没有?图 3:抛掉 bridge ,给每个 Pod 装上一个网卡示意图
(1)新加网卡
这个想法看起来非常不错,但前提是这台 VM 上得有多余的网卡,另外还能把网卡插入到 Pod 中去。其实给一个 VM 添加一张新网卡这事,像 VMWare 公司的 vSphere 这样的工具就可以方便地做到。比如在图 4 里,二哥用鼠标点了几下就手动给一台 VM 添加了一个新的网卡。
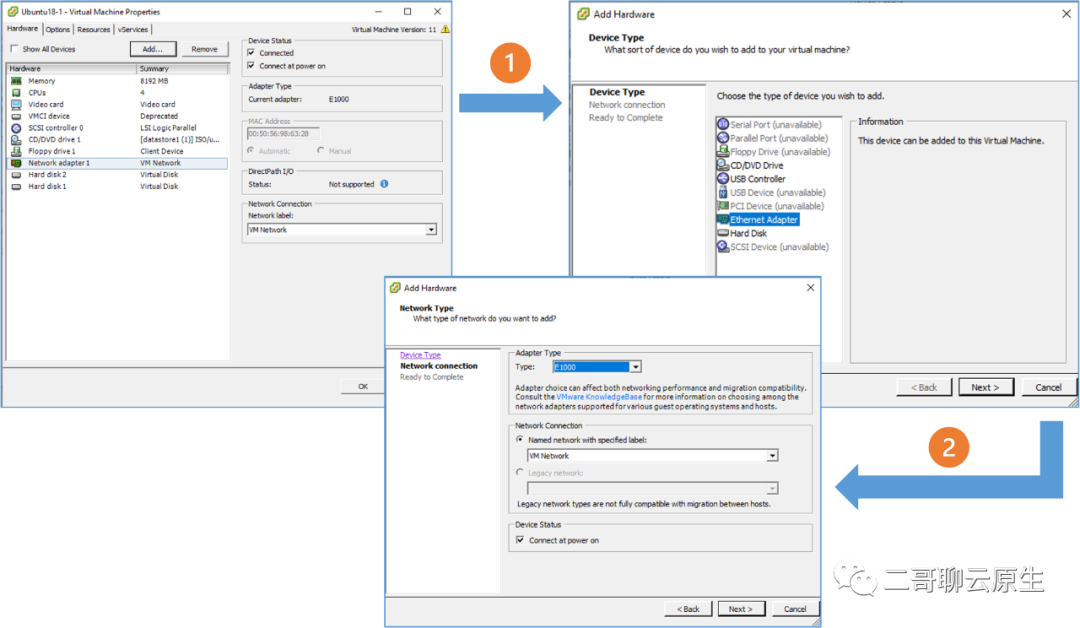
图 4:给 VM 手动添加一张新网卡
当然,我们也可以通过 API 的方式自动完成这样的网卡创建工作。像 AWS / 阿里云都支持通过 API 的方式给 ECS 动态创建弹性网卡(ENI)。但一台 ECS 所能绑定的 ENI 数量是有限制的,比如 AWS 上根据 ECS 实例的配置,最高可以绑定 15 个弹性网卡,阿里云也有类似的限制。弹性网卡是独立的虚拟网卡,可以在多个云服务器之间迁移,实现业务的灵活扩展和迁移。可以随 ECS 实例创建并绑定弹性网卡,也可以单独创建辅助弹性网卡再绑定到 ECS 实例上。弹性网卡具备以下功能特点:
- 除了随 ECS 实例一起创建的主网卡外,一台 ECS 实例支持绑定多个辅助网卡。这些辅助网卡和 ECS 实例必须属于同一专有网络VPC和同一可用区,可以分属于不同虚拟交换机和不同安全组。
- 每个弹性网卡根据随绑定的实例规格不同,可以分配相应的多个辅助私网IP地址。
- 将一个辅助弹性网卡从一个实例解绑,再重新绑定到另一个实例时,网卡的属性不会发生变化,网络流量将直接切换到新的实例。
- 弹性网卡支持热插拔,可以在ECS实例之间自由迁移,切换弹性网卡绑定的实例时无需重启实例,不影响实例上运行的业务。
(2)将新网卡插入到容器中
Um... NICE. 看起来新建网卡有门路了,那又该如何将其插入到 Pod 里面去呢?二哥以 Docker 来做个示意吧,将新建的一个名为 eth10 网卡插入到容器里面。首先启动一个容器,假如这个容器的 PID 是 2022。
~# docker run -itd --net none ubuntu:16.04在宿主机环境执行下面的命令,将 eth10 放到容器中,并重命名为 eth0 ,上电启动再开启 DHCP 。
~# mkdir /var/run/netns
~# ln -sf /proc/2022/ns/net /var/run/netns/2022
~# ip link set dev eth10 netns 2022
~# ip netns exec 2022 ip link set eth10 name eth0
~# ip netns exec 2022 ip link set eth0 up
~# ip netns exec 2022 dhclient eth0一通猛如虎的操作后,宿主机上就再也看不到这个 eth10 了。而如果在容器内执行这条命令,你会发现它多了一个网卡。
~# ifconfig -a其实准确地说,上面的操作是将 eth10 插入到容器的 network ns 中去的。一个 Pod 本质上是共享相同 network ns 的多个容器的集合,所以你可以想象得出将这些操作应用到 Pod 中发生了什么。
我们将图 2 和图 3 重新整理一下。图 5 就是我们心心所念的,结合了图 1 和图 2 优势的新方案:既保留图 2 这样的细粒度的资源虚拟化方式,网络流量又能像图 1 的 VM 那样大路朝天,各向天涯。图 5:支持 multi NIC 的 Underlay
(3)Performance
二哥在之前的文章中提到过,如以 VM 为 benchmark 来做对比的话,在传输性能方面:
- Overlay 模式的传输性能会有 20-30% 左右的下降。因为隧道带来了解/封装损耗,另外进出 Pod 的 traffic 要穿越两次网络栈(如图 6 所示,进两次,出也是两次)。解/封装的代价显而易见,而两次网络栈的穿越所付出的代价却很容易让人忽略。图 6 中用红色标示出了 "iptables overhead",意思是这部分是额外的工作量,言下之意是其实这部分工作量可以去掉。
- host-gw 模式大概有 10% 左右的性能损耗。原因是和 Overlay 模式一样,主机间路由同样会出现两次穿越网络栈的问题。
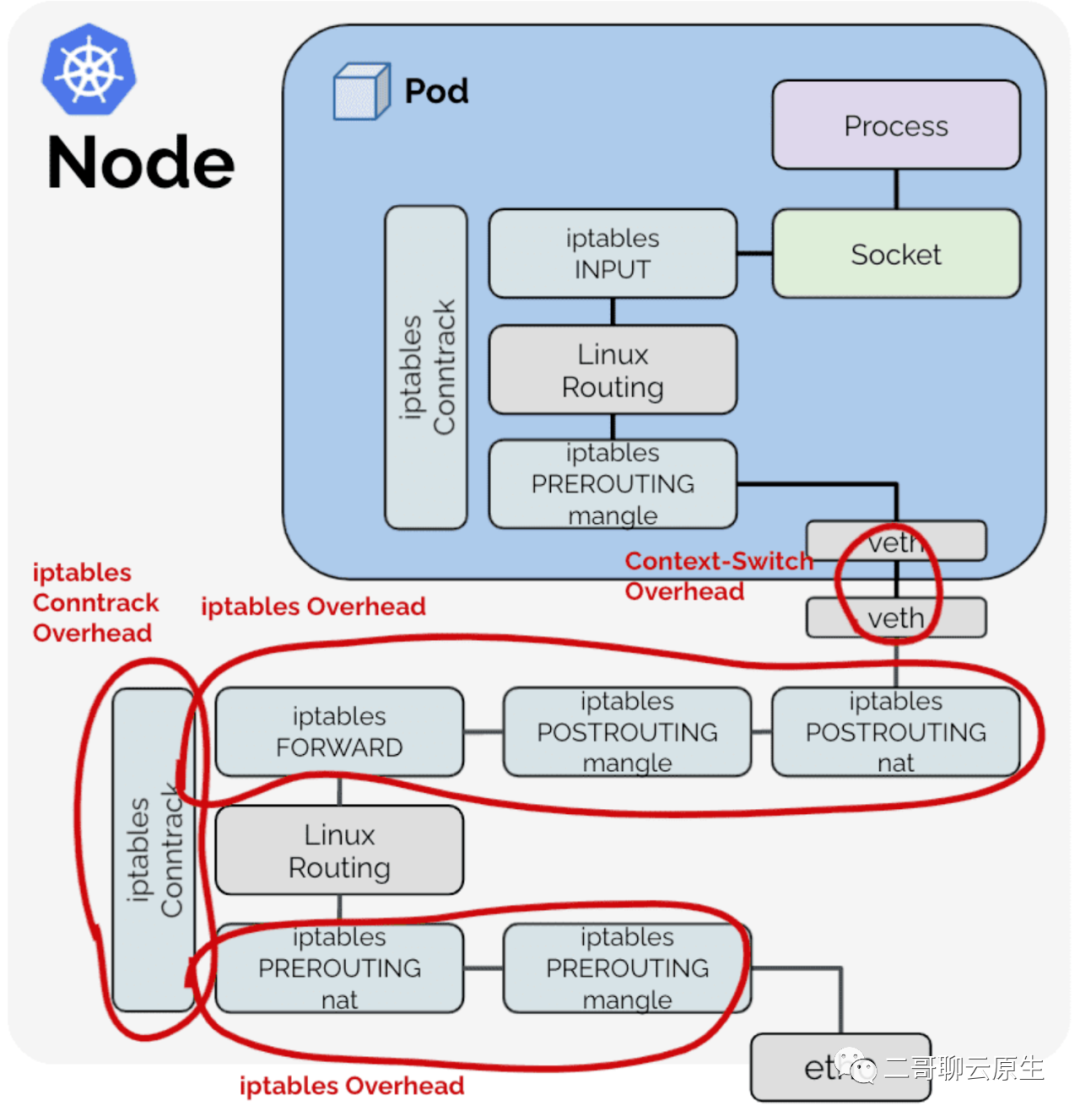
图 6:进出 Pod 的 traffic 多次穿越网络栈
那 Underlay 的性能损耗如何?它和 benchmark 相比,几乎没有任何性能损耗。原因也很容易找到:既没有解/封装,也不需要两次网络栈的穿越。我们再给大家附上一个性能测试对比报告,报告是阿里云团队公布在他们的网站上的。报告链接 我放在这里,感兴趣的同学可以自己去研究。
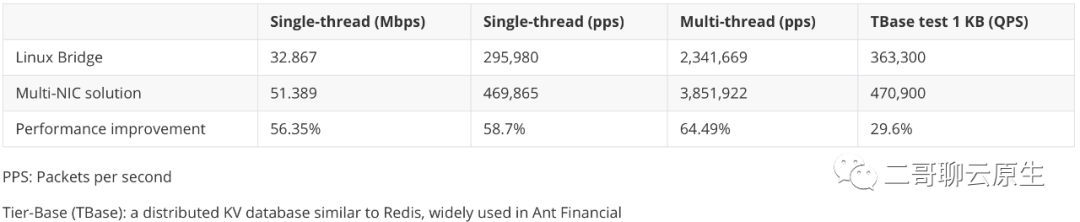
图 7:performance 对比
其实 K8s 的 Overlay / host-gw / Underlay 网络模式的实现都离不开 multi network ns 。但 Underlay 对其利用得更干净、更直观、更高效,不过也更贵。周志明老师在《凤凰架构》一书中说:对于真正的大型数据中心、大型系统,Underlay 模式才是最有发展潜力的网络模式。这种方案能够最大限度地利用硬件的能力,往往有着最优秀的性能表现。但也是由于它直接依赖于硬件与底层网络环境,必须根据软、硬件情况来进行部署,难以做到 Overlay 网络那样开箱即用的灵活性。大家看完这两篇文章,不知道是否对周老师这番话有了更深刻的理解呢?对于《multi-network ns在Underlay下的应用-本手篇》文首所提的 3 个问题,你是不是有了答案呢?
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK