

rsync 的核心算法 -- 算法 -- IT技术博客大学习 -- 共学习 共进步!
source link: https://blogread.cn/it/article/5360?f=hot1
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
rsync 的核心算法
rsync是unix/linux下同步文件的一个高效算法,它能同步更新两处计算机的文件与目录,并适当利用查找文件中的不同块以减少数据传输。rsync中一项与其他大部分类似程序或协定中所未见的重要特性是镜像是只对有变更的部分进行传送。rsync可拷贝/显示目录属性,以及拷贝文件,并可选择性的压缩以及递归拷贝。rsync利用由澳洲电脑程式师Andrew Tridgell发明的算法。这里不介绍其使用方法,只介绍其核心算法。我们可以看到,Unix下的东西,一个命令,一个工具都有很多很精妙的东西,怎么学也学不完,这就是Unix的文化啊。
本来不想写这篇文章的,因为原先发现有很多中文blog都说了这个算法,但是看了一下,发现这些中文blog要么翻译国外文章翻译地非常料,要么就是介绍这个算法介绍得很乱让人看不懂,所以反而让我觉得我应该写下这篇文章,因为别人没搞好。(当然,我成文比较仓促,可能会有一些错误,请指正)
首先, 我们先来想一下rsync要解决的问题,如果我们要同步的文件只想传不同的部分,我们就需要对两边的文件做diff,但是这两个问题在两台不同的机器上,无法做diff。如果我们做diff,就要把一个文件传到另一台机器上做diff,但这样一来,我们就传了整个文件,这与我们只想传输不同部的初衷相背。
于是我们就要想一个办法,让这两边的文件见不到面,但还能知道它们间有什么不同。这就出现了rsync的算法。
rsync的算法如下:(假设我们同步源文件名为fileSrc,同步目的文件叫fileDst)
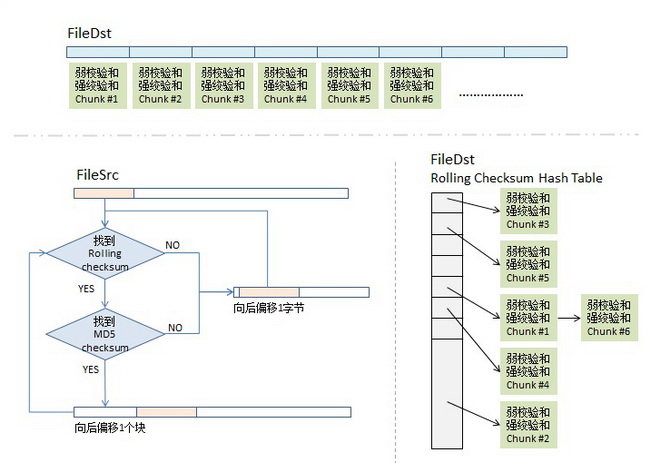
1)首先,我们会把fileDst的文件平均切分成若干个小块,比如每块512个字节(最后一块会小于这个数),然后对每块计算两个checksum,
一个叫rolling checksum,是弱checksum,32位的checksum,其使用的是Mark Adler发明的adler-32算法, 另一个是强checksum,128位的,以前用md4,现在用md5 hash算法。为什么要这样?因为若干年前的硬件上跑md4的算法太慢了,所以,我们需要一个快算法来鉴别文件块的不同,但是弱的adler32算法碰撞概率太高了,所以我们还要引入强的checksum算法。
2)CheckSum算法。同步目标端会把fileDst的一个checksum列表传给同步源,这个列表里包括了三个东西,rolling checksum(32bits),md5 checksume(128bits),文件块编号。
我估计你猜到了同步源机器拿到了这个列表后,会对fileSrc做同样的checksum,然后和fileDst的checksum做对比,这样就知道哪些文件块改变了。
但是,聪明的你一定会有以下两个疑问:
如果我fileSrc这边在文件中间加了一个字符,这样后面的文件块就完全和fileDst这边的不一样了,但理论上来说,我只需要传一个字符就好了。 如果这个checksum列表特别长,而我的两边的相同的文件块可能并不是一样的顺序,那就需要查找,线性的查找起来应该特别慢吧。3)checksum查找算法。同步源端拿到fileDst的checksum数组后,会把这个数据存到一个hash table中,用rolling checksum做hash,以便获得O(1)时间复杂度的查找性能。这个hash table是16bits的,所以,hash table的尺寸是2的16次方,对rolling checksum的hash会被散列到0 - 2^16 - 1中的某个值。(对于hash table,如果你不清楚,请回去看你大学时的数据结构那本教科书)
顺便说一下,我在网上看到很多文章说,“要对rolling checksum做排序”(比如这篇和这篇),这两篇文章都引用并翻译了原版的这篇文章,但是他们都理解错了,不是排序,就是把fileDst的checksum数据,按rolling checksum做存到2^16的hash table中,当然会发生碰撞,把碰撞的做成一个链接就好了。这就是原文中所说的第二步。
4)比对算法。这是最关键的算法,细节如下:
4.1)取fileSrc的第一个文件块(我们假设的是512个长度),也就是从fileSrc的第1个字节到第512个字节,取出来后做rolling checksum计算。计算好的值到hash表中查。
4.2)如果查到了,说明发现在fileDst中有潜在相同的文件块,于是就再比较md5的checksum,因为rolling checksume太弱了,可能发生碰撞。于是还要算md5的128bits的checksum,这样一来,我们就有 2^-(32+128) = 2^-160的概率发生碰撞,这太小了可以忽略。如果rolling checksum和md5 checksum都相同,这说明在fileDst中有相同的块,我们需要记下这一块在fileDst下的文件编号。
4.3)如果fileSrc的rolling checksum 没有在hash table中找到,那就不用算md5 checksum了。表示这一块中有不同的信息。总之,只要rolling checksum 或 md5 checksum 其中有一个在fileDst的checksum hash表中找不到匹配项,那么就会触发算法对fileSrc的rolling动作。于是,算法会住后step 1个字节,取fileSrc中字节2-513的文件块要做checksum,go to (4.1) - 现在你明白什么叫rolling checksum了吧。
4.4)这样,我们就可以找出fileSrc相邻两次匹配中的那些文本字符,这些就是我们要往同步目标端传的文件内容了。
怎么,你没看懂? 好吧,我送佛送上西,画个图给你看看。
这样,最终,在同步源这端,我们的rsync算法可能会得到下面这个样子的一个数据数组,图中,红色块表示在目标端已匹配上,不用传输(注:我专门在其中显示了两块chunk #5),而白色的地方就是需要传输的内容(注意:这些白色的块是不定长的),这样,同步源这端把这个数组(白色的就是实际内容,红色的就放一个标号)压缩传到目的端,在目的端的rsync会根据这个表重新生成文件,这样,同步完成。

最后想说一下,对于某些压缩文件使用rsync传输可能会传得更多,因为被压缩后的文件可能会非常的不同。对此,对于gzip和bzip2这样的命令,记得开启 “rsyncalbe” 模式。
(全文完,转载时请注明作者和出处)
建议继续学习:
扫一扫订阅我的微信号:IT技术博客大学习
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK