

高级数据库-事务
source link: https://jasonxqh.github.io/2022/05/11/%E9%AB%98%E7%BA%A7%E6%95%B0%E6%8D%AE%E5%BA%93-%E4%BA%8B%E5%8A%A1/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

高级数据库-事务
首先,我们来复习一下事务的概念:ACID,(其实在sql中已经学过了)
- 原子性(Atomicity): 一个事务要么没有开始,要么全部完成,不存在中间状态
- 一致性(Consistency): 事务的执行不会破坏数据的正确性,即符合约束
- 隔离性(Isolation): 多个事务不会相互破坏
- 持久性(Durability): 事务一旦提交成功,对数据的修改不会丢失
事务面向的负载在于查询和更新。其主要特征是:
- 查询:较大数据集合的计算
- 更新:通常是小部分数据,点数据的更新
事务的实现
- 实现并发控制:隔离性
- 实现日志:原子性,持久性
- 一致性:应用或其他实现保证
并发控制的主要内容
并发控制的意思就是在有多个并发的事务的情况下怎么保持数据库的一致的状态。这个状态有不同的层次,这些层次就是隔离级别。隔离级别越高,并发能力越弱;隔离级别越低,并发能力越强。比如说,可串行化是最高的隔离级别。
接下来,我们就要着重了解可序列化这个隔离等级
首先给出调度(shedule)的定义:a sequence of (important) steps taken by one or more transactions
那么这些重要的步骤是什么?在并发控制中,往往是对于某一个值的读写操作:
read operation(Read(X))
write operations(Write(X))
我们给一个例子
现在有两个数据库中的值:A和B,它们相等
A = 25
B = 25
然后有两个事务,第一个事务负责把A和B各加上100,第二个事务负责把A和B各乘以2

那么其中的一个可能的调度如下:
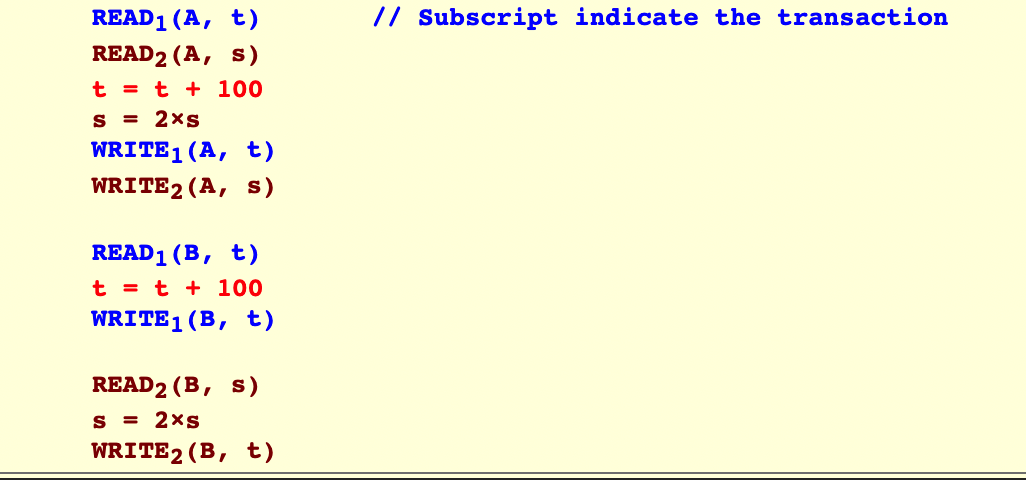
当然,T1,T2可能是串行的,也就是先做完T1再做T2

在了解可序列化之前,我们先看看顺序执行是怎么做的。顺序执行非常好理解——它是单线程调度的,做完事务1之后才能做事务2.
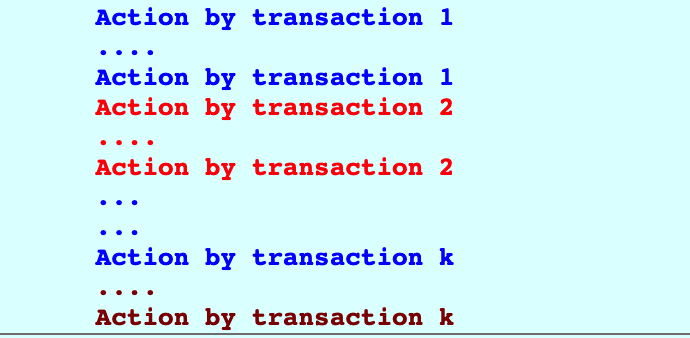
这是事务执行最理想的状态,但同时由于是单线程调度,其没有并发能力
可串行化(Serializable)
那么,可串行化的意思说,具有一定的并发能力,但同时让事务的调度结果和串行化是等价的。
比如说还是用上面那个例子,可串行化的调度如下:我们发现,这样的调度和串行化的调度是等价的,最终都能达到 A = B = 250的效果。

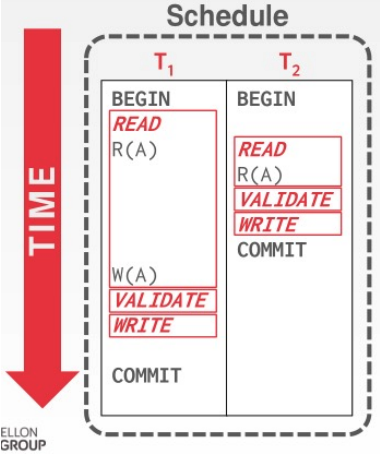
那么非可串行化的调度是怎么样的呢?我们看看下图:得到的结果是 A=250,B=150,和串行化调度不等价
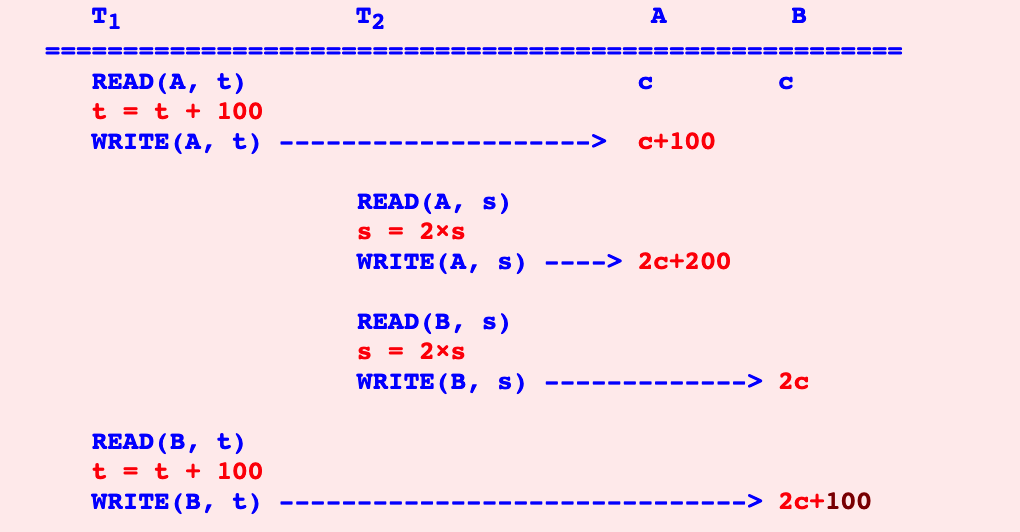
可串行化对事务的执行先后没有要求,但是最后结果需要和串行化调度的结果达成一致
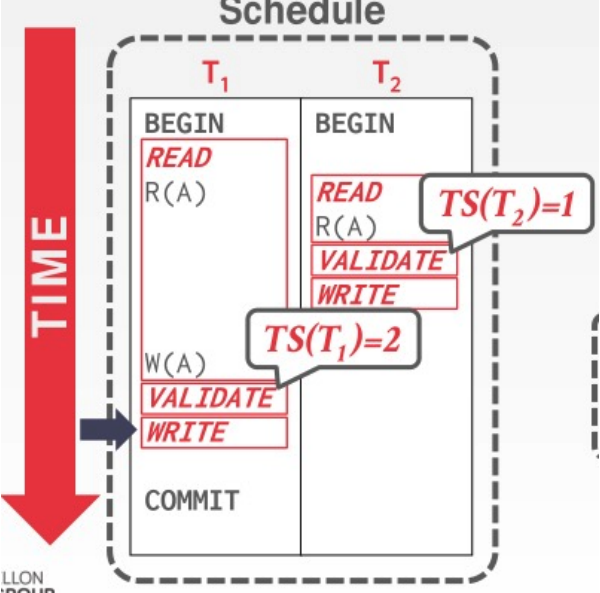
冲突可串行化调度(Conflict-serializable)
冲突操作指的是不同事务对于同一数据的读写操作与写写操作。但是有些冲突操作是可以交换次序的(non-conflicting swaps),有些冲突操作不能交换次序(conflicting swaps)。
不能交换位置的次序为:
- 不同事务对同一个对象的冲突操作
- 同一事务对同一个对象的两个操作(如读写)
定义冲突等价:
如果两个Schedule S1和S2 , S1可以通过 non-conflicting swaps 转换成 S2的话,那么S1和S2就是冲突等价的
比如说, 现在有这样一个调度,我们将其分为四个色块,分别标记为A,B,C,D
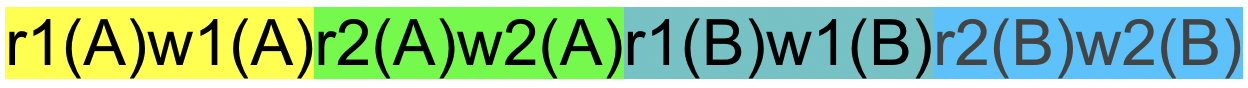
从块与块之间的角度来看,显然A和B是冲突操作,C和D是冲突操作,因为都涉及到不同事务修改同一个值。所以AB不能交换,CD不能交换
从块内角度分析:A内部$r_1(A)w_1(A)$ 是冲突的,因为这属于同一事务对同一个值的冲突操作。同理BCD也是这样,因此色块内部的顺序也不能调整
但是,我们可以打破块的舒服,从整体来看,下图绿色块跟青色块可以交换次序,因为这两个操作不冲突,不符合第三条的任意一种情况。
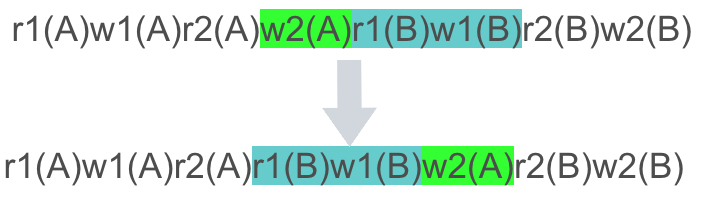
再看新的绿色块与青色块,如果交换它俩也不会发生冲突:
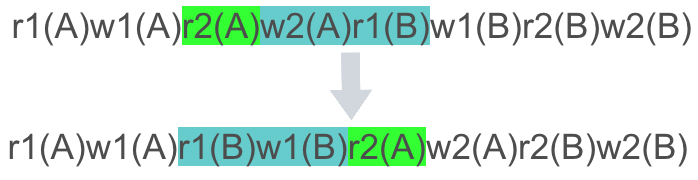
那么我们说,原调度和这些变化都是冲突等价的
冲突可串行化
一个调度Schedule1在保证冲突操作次序不变的情况下,通过交换两个事务不冲突操作的次序得到另外一个调度Schedule2,如果Schedule2与串行化等价,那么称调度Schedule1是冲突可串行化的调度。同时称Schedule1和Schedule2是冲突等价的
我们还是拿刚才那个调度为例,经过了两次交换顺序之后, 经过了如下变化:
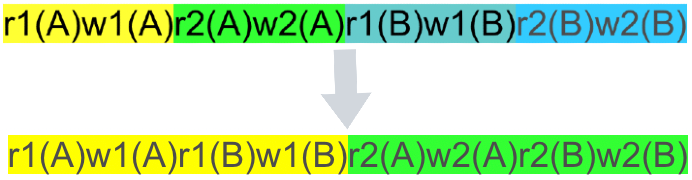
最终结果是我们发现T1和T2被串行起来了,这和串行化是等价的。因此我们称原调度是冲突可串行化的
此外隔离等级还有Read Uncommitted,Read Commited, Repeatable Read 等
冲突可串行化的性质
然后我们要介绍冲突可串行化的一个性质:冲突可串行化永远是可串行化的. 因为如果调度是冲突可串行化的,那么必定可以通过交换non-conflicting operations的方法,得到一个新的调度,这个调度是串行化的。因此根据可串行化的定义,冲突可串行化也是可串行化的
但是要注意,可串行化的调度,不一定是冲突可串行化的,我们来举一个例子:现在有三个事务如下
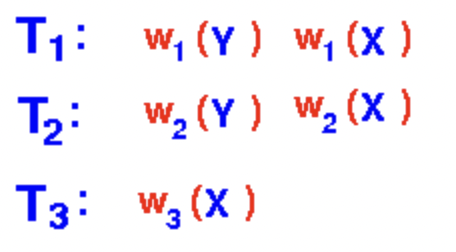
有两个Schedule如下:其中S2是串行的调度
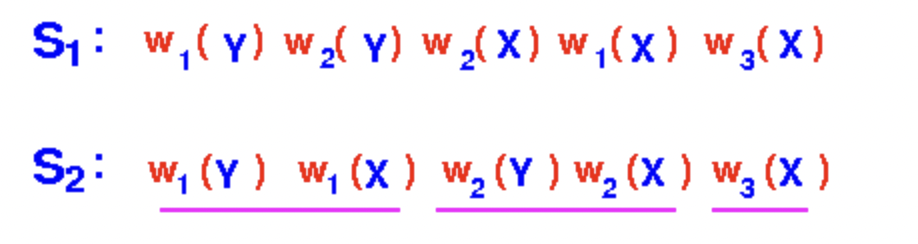
显然,S1和S2最终达到的效果是一样的,因此S1是可串行化的。但是S1却不是冲突可串行化的。因为没有办法通过non-conflicts swap将S1转换为S2

Recoverble Schedule
可恢复的调度(recoverable schedule):是指已提交的事务不应该发生回滚的调度。我们用一张图来说明:如果Tk需要读取T1、T2、T3的写,那么T1、T2、T3就需要在Tk之前提交。
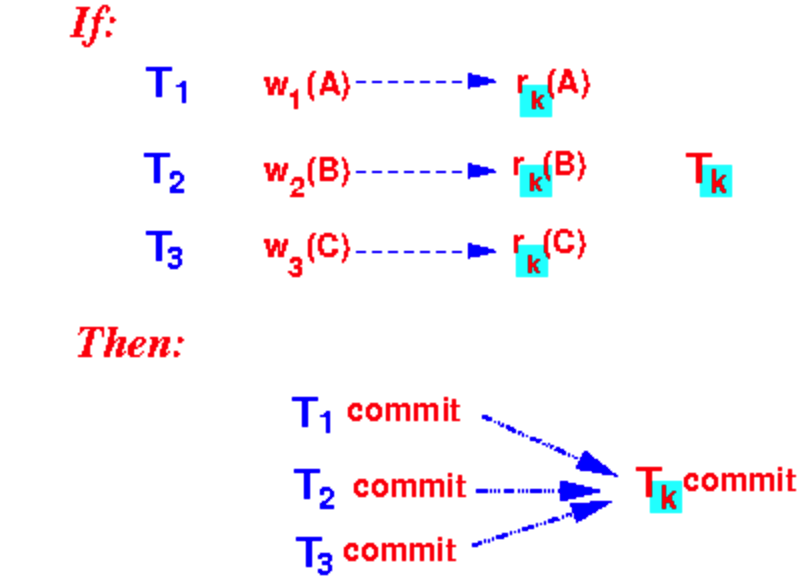
可恢复的调度分为以下几类:
- 层联回滚(Cascading rollback)调度:未提交的事务从未提交的(失败)事务中读取了错误的数据(Dirty Read ),必须回滚。
- 无层联回滚的:事务只读取已提交事务写的数据(Read Commited)。
- 严格调度(Strict Schedule):在写数据项的最后一个事务提交之后事务才能开始读/写该数据项。
为什么要有这个概念呢?如果不是recovery的调度的话,一旦系统发生了故障,就无法恢复。试想,如果T1写了A,然后Tk读取了A,并先于T1提交了。那么假设在Tk提交到T1提交这个时间段出现了系统故障,那么当系统重启之后按道理来说需要回滚到T1写A之前,但是T1并没有提交,系统只会回滚到Tk读取A的那个状态。因此丢失了A原来的值。
Read Uncommitted
是最低级别的隔离等级。它什么都不会做,漏洞最多。会出现上面所说的所有问题。因为事务之间没有互相隔离,他们可以读取互相做出的未提交修改。在这种情况下不允许发生脏写,但是可能发生脏读、不可重复读、幻读。
Read Committed.
当我们使用这个隔离级别时,事务只能读取已经提交了的数据。如果我们需要在事务中进行商务上的计算,我们的决定是基于有效的、已经提交的数据。事务运行之后有数据发生了变化,事务也不会去关注这个问题。这个隔离级别可以避免Dirty Read这个问题
Repeatable Read:
在这种级别下,读取的内容是可重复的,就算是数据被其他的事务修改了也没事。我们看到的只是第一次读取时就生成的快照。这个级别可以避免 Lost Updates, Dirty Reads 和 Non-repeating Reads这三个问题
Dirty Writes
两个事务在没提交的情况下去更新同一行数据的值
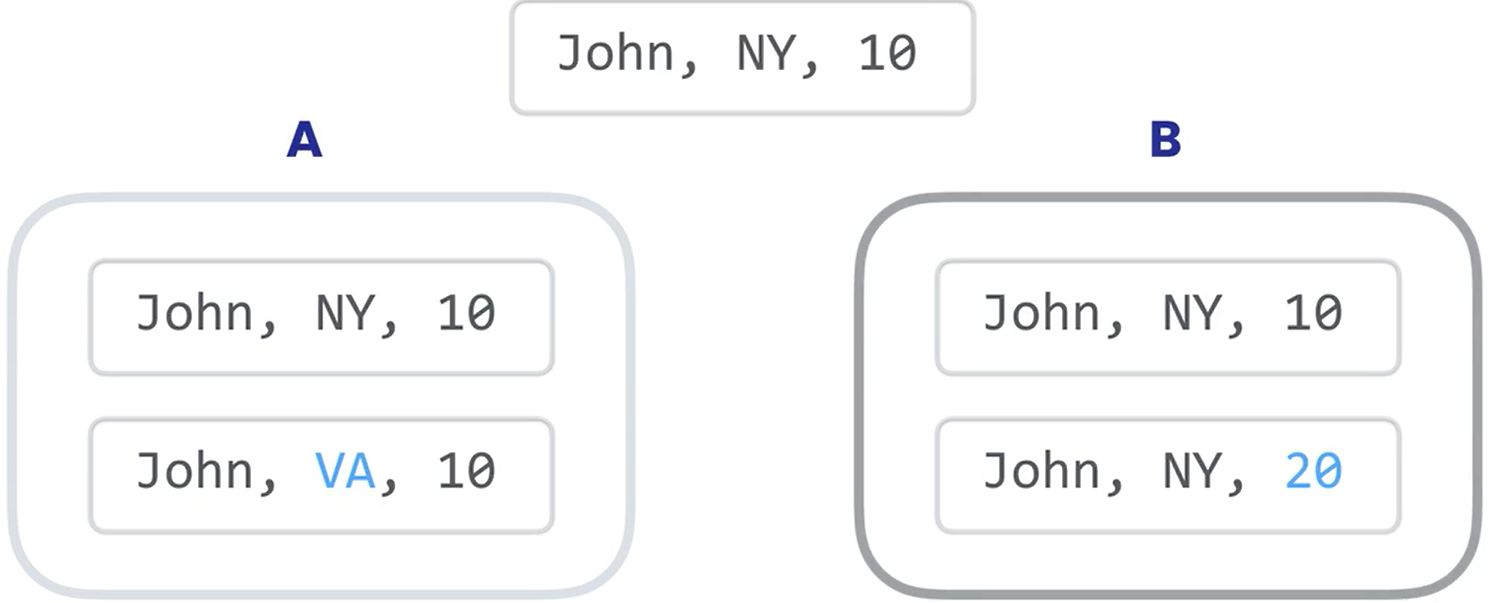
我们对一条数据进行两次更新,一次更改洲名,一次更改积分,但是这样一来,如果B是后更新的,那么B中的数据会覆盖掉A中更新的数据,造成更新丢失。我们这时候就需要Locks来规避这种情况的发生,默认情况下,Mysql使用了锁定机制以防止两个事务同时更新相同的数据,他们在一个队列中,按照顺序进行。
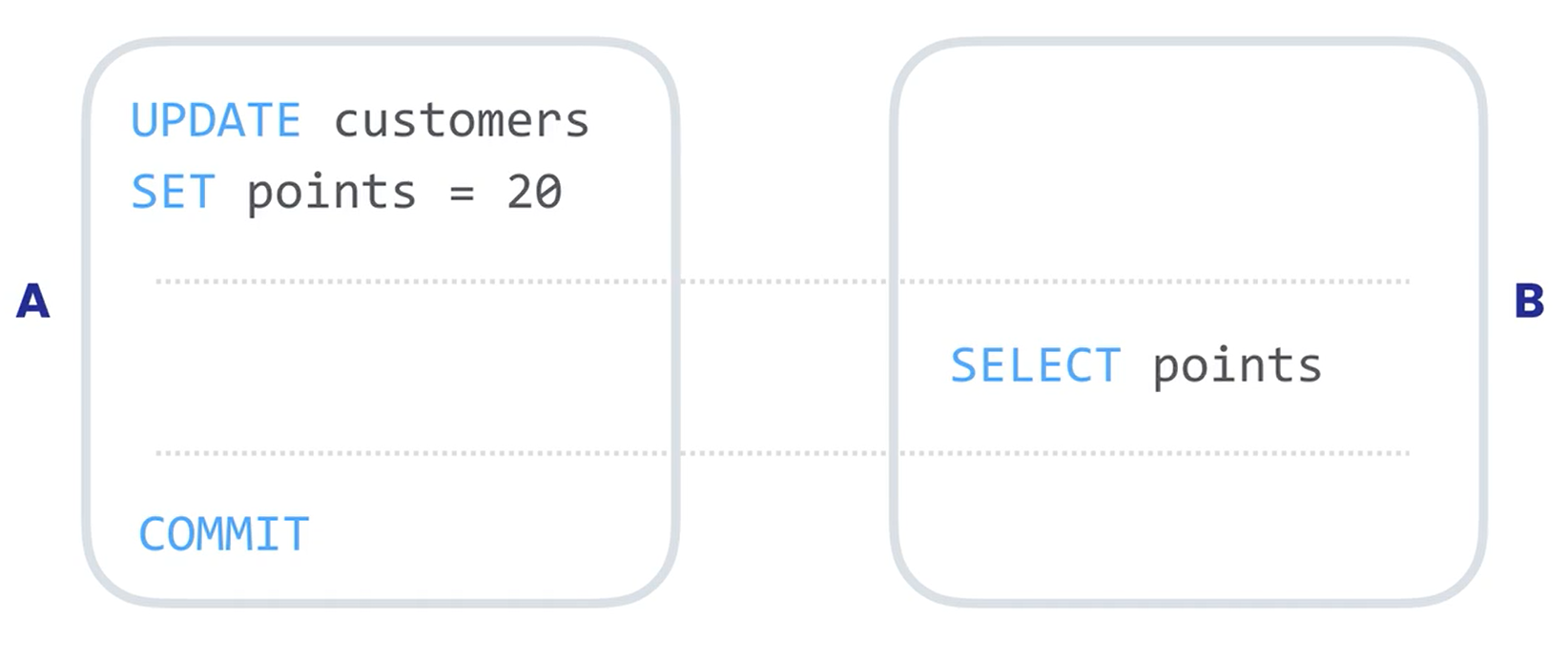
Dirty Reads
Dirty Reads 发生在事务读取还没有提交的数据时,比如下图。事务A想把顾客的分设置为20,在还没有提交的时候,事务B读取了表中更新过后的数据。如果每一分代表优惠一元,那么这位顾客可以优惠20元。但是事务A在提交前发生回滚。这时候事务B还没结束,所以事务B读取的数据是非法的。也就是说,在这种情况下,白给了顾客20元的优惠,因为事务B中读取了未提交的数据 。这就是 Dirty Reads,很形象。因为我们读取了污染的数据。
为了解决这个问题,我们需要围绕事务提供一定程度的隔离度。所以事务修改的数据并不会立刻被其他事务读取到。标准的SQL定义了四个事务隔离级别
Non-repeating Reads
如果在事务进行过程中,我们读取了两次、得到了不一样的结果怎么办.比如下图。事务A中选择了数据表中一条值为10的信息,但是这时候,B把这条信息的数据改成了0,现在A中的子查询又想读取这条信息,发现这时候其值已经变成0了。对于这种不重复读取的异常,我们可以将隔离级别从 read committed(读已提交)提升到repeatable read(可重复读)。

Phantom Reads
假设有个事务A,我们查询了所有积分大于10的客户,发给他们额外的打折券。这时候,一个事务B修改了一位顾客甲,把他的分从0修改到了20。但这时候事务A已经完成查询,甲并不在查询结果当中。这就是我们说的Phantom Read,数据有时候会像幽灵一样突然冒出来。是否解决这个问题要看我们的业务、以及把这个客户纳入我们的事务中的重要性。
事实上,隔离等级是根据异常等级的不同而划分的。我们可以用一张表来总结:

实现隔离级别
首先我们来介绍几种锁
- 读锁 shared lock : 所有读操作
- 写锁 exclusive lock: 所有写操作
- Short duration lock: 短锁,动作完成前申请,完成后立即释放锁
- Long duration lock: 长锁, 动作完成前申请,直到Commit之后才会释放锁
我们可以用锁来定义不同的隔离级别:
| Consistency Level = Locking Isolation Levo | Read Locks on Data Items and Predicates | Write Locks on Data Item and Predicates |
|---|---|---|
| Degree 0 | 没有要求 | Well-formed Writes |
| Degree1 READ UNCOMMITED |
没有要求 | Well-formed Writes Long duration Write locks |
| Degree2 READ COMMITED |
Well-formed Reads Short duration Read locks(both) |
Well-formed Writes Long duration Write locks |
| REPEATED READ | Well-formed Reads Long duration data-item Read locks Short duration Read locks(both) |
Well-formed Reads Short duration Read locks(both) |
| SERIALIZABLE | Well-formed Reads Long duration Read locks(both) |
Well-formed Reads Short duration Read locks(both) |
思考题:下面的调度至高是在那种隔离级别下产生的调度?
R1(x)W2(x)C2 W1(x)C1
首先,不可能是Repeated Read,因为这种情况会给读操作上长锁,因此不可能在 R1(x)之后就发生W2(x)
那么可能是Read Commited吗? 在R1(x)处读上了短读锁,释放后在W2(x)上了一个长写锁,在C2结束后释放。然后在W1(x)处上了长写锁,在C1结束后释放。因此,Read Commited是可能发生的
2PL是事务的悲观并发控制,悲观的意思是说,冲突是很容易产生的,因此在事务的运行过程中就需要去检测冲突
TO(Timestamp Ordering)
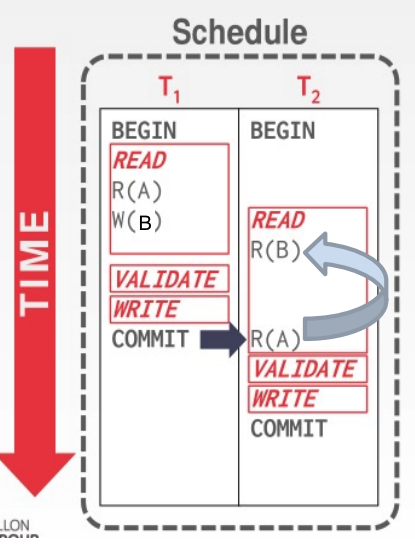
OCC(Optimistic Concurrency Control) 是事务的乐观并发控制,乐观是说冲突没那么容易产生,因此只在事务要提交的时候去检测冲突。现在有很多内存数据库中采用这种机制,因为数据所有的操作都在内存里完成,事务的运行时间会缩短,因此出错的概率也会变小。从理论上来说,内存数据库中最佳的并发控制策略就是OCC。但是OCC也存在一些问题,比如说事务会经常重启(遇到错误时),很多事务会一直达不到结束的条件,导致无法完成。
OCC的基本思路是:每个事务会产生一个私有空间,并在里面维护事务中的读写集合。在事务提交的时候,验证读写集合是否与其他事务冲突,如果没有,则将写集合应用于数据;否则就把事务abort掉,再重做
另外,OCC为每个事务分配了一个时间戳,反映了事务的可串行化顺序,以方便验证
OCC的三个阶段
- 读阶段
- 执行事务,并在事务的私有空间生成事务的读写集合
- 验证阶段
- 提交之前,通过读写集合验证是否有冲突。这是整个策略的重点
- 写阶段
- 将写集合应用到数据,commit or abort
OCC例子
读阶段生成读集合。 此时所有事务都是并发的
- T1 有两步:
T1.ReadSet={A},T1.WriteSet={A} - T2有一步:
T2.ReadSet={A}
在最原始的OCC中,只有读阶段是并发的,验证阶段和写阶段是阻塞的,因此当一个事务在验证或者写的时候,另外的事务是无法运作的。现在有些研究速度更快、并行度更高的验证规则。
一般来说,现在都会在验证阶段给事务分配时间戳,如下:
验证阶段的目标就是要保证事务的可串行化,即Ti需要和其他事务是否有读写冲突和写写冲突。
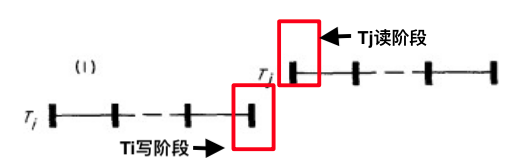
在验证的时候主要要关注三个时间点:事务开始(读阶段)时间、事务结束(写阶段)时间,验证阶段开始时间。由于…导致会有不同情况的出现,接下来我们来介绍几种在满足Ti<Tj之后可以提交事务Ti的情况
Case1
- 要求:Ti在Tj事务开始之前完成写阶段
这很容易理解,时间戳示意图如下:
事务调度顺序如下:
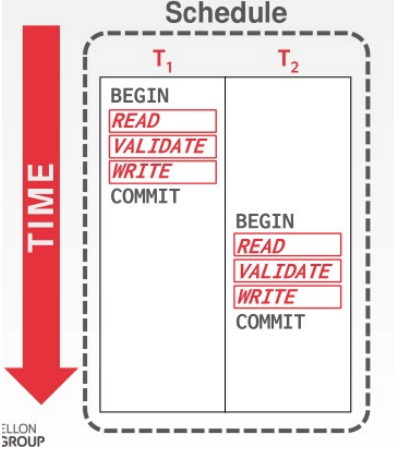
这很容易理解,此时Ti和Tj是没有冲突的
Case2
- 要求: Ti 在 Tj的验证阶段开始前完成写阶段, 并且 $\text{WriteSet}(T_i)\cap \text{ReadSet}(T_j)=\empty$
第二种情况,相当于在Case1的基础上,将 tj事务左移了一段距离,如下:
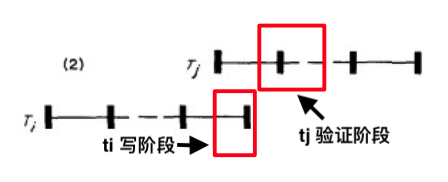
注意,Ti的写集合和Tj的读集合的交集必须为空,否则会发生读写冲突。如下所示:我们看到,T1还没有提交关于B的修改,T2就开始读取B了,这时候就不是可串行化了。
那么有人要问了,如果T1的写集合是A,且在T1提交时T2才刚好读取A,看起来不会有问题,可行吗?其实这种也会被abort掉,因为毕竟是小概率事件,为了方便都会中止事务
Case3
- 要求:Ti 在 Tj的读阶段结束前开始验证阶段, 并且
- $\text{WriteSet}(T_i)\cap \text{ReadSet}(T_j)=\empty$
- $\text{WriteSet}(T_i)\cap \text{WriteSet}(T_j)=\empty$
示意图如下:
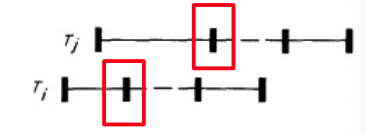
OCC基本实现
事实上,在设计OCC的时候我们设计了 验证阶段+写阶段的临界区
- 在临界区中,只能让一个事务的读阶段去和另外一个事务的读/写阶段去并行。
- 因为临界区只能允许一个事务进入,因此所有事物之间的验证阶段和写阶段是互斥的
- 因此,Case3实际不会出现
总结一下Case1和Case2:
- Case1:
Finish(Ti)<Start(Tj) - Case2:
Start(Tj)<Finish(Ti)<Validation(Tj),且对Tj的读集合,需要验证他和所有满足上面范围的Ti的写集合是否有交集,这样就意味着只需要维护每个事物的写集合即可。- 这里不用写集合去和别人的读集合做验证的原因是,维护读集合的难度要比维护写集合要大得多
思考算法是如何巧妙利用时间戳实现Case1 和Case2的?
- Case1, 事务开始获得当前时间戳
start tn,在 比较时从start tn+1开始的事务去验证,因为 start tn之前的事务已经完成。 - Case2, 事务再次获取当前时间戳
finish tn, 因此所有在start tn与finish tn之间的事务都是满足 case2的。
伪代码如下:
thegin = {
create set := empty;
read set := empty;
write set := empty;
delete set := empty;
start tn := tnc //tnc是一个单调递增公共时间戳,事务一开始时就获取
}
// 临界区
tend = {
< finish tn := tnc;
valid := true;
// 满足case2的条件的事务t(当前事务开始到上个事务结束这段时间)
for t from start tn+1 to finish tn do
// 这边用当前事务的读集合去和满足条件的t的写集合去做检查,即case2
if(write set of transaction with transaction number t intersects read set)
then valid := false;
if valid
then((write phase); tnc := tnc + 1; tn = tnc)>;
if valid
then (clean up);
else (backup)
}
多版本并发控制
多版本是指:对某一数据项,数据库中存储其多个不同时间点上的状态(一次修改看做是一次状态)。不同的状态存储在链上
- 每次写操作,创造一个新的版本
- 每个读操作,通常事务开始时获取一个版本,读取小于等于该版本的最新数据,因此可以避免不可重复读的错误
多版本能实现读写分离(优点):
- 读不阻塞写
- 写不阻塞读
SnapShot Isolation
SI既是一种实现,也是一种隔离级别(快照隔离级别),为什么是快照?因为SnapShot读取的是数据库中的旧版本
SI流程如下:
- 事务开始:
- – Get snapshot 定义快照时间点
- 事务执行:
- Reads from snapshot 从快照中读取
- Writes to private workspace
- 事务提交:
- Check for write-write conflicts
- 如果有abort到只有一个事务提交
- Install updates
- Check for write-write conflicts
例子:SI的版本变化
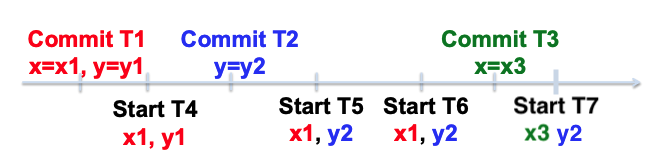
如上图,已知有三个提交: Commit T1,T2,T3,每次都会生成一个时间戳
首先,我们先学习ACID与日志的关系——ACID那些性质与日志存在关系呢?显然是原子性和持久性
从单机数据库角度来说,需要使用日志的地方有很多——各种故障
- 存储介质故障
- 灾难性故障
- 系统故障
- 操作系统中止
不管是什么故障,有日志的存在,就能是数据库恢复到一致的状态,已经提交的事务就是持久化了,还没有提交的事务需要回滚
缓冲区策略与日志的关系
之前我们学过数据库中有个缓冲区,还写了一个BPManager的程序来进行lru调度。
现在我们来讨论一下事务、脏页、日志三者之间的关系,来看下图
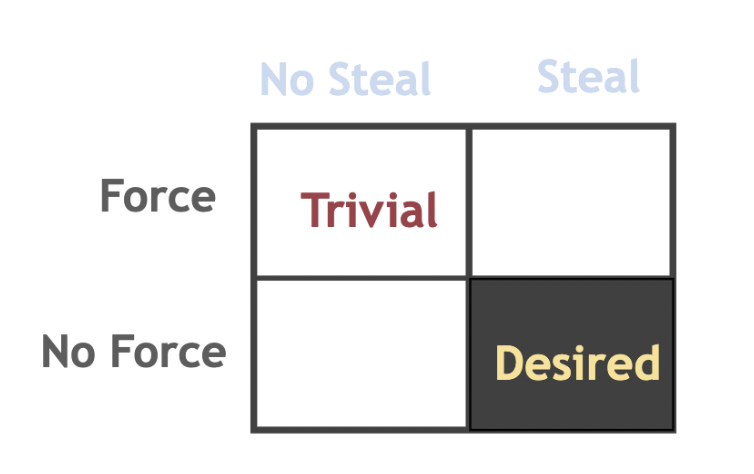
- Steal: 允许未提交事务刷入磁盘
- Force: 只有事务的所有数据都刷入磁盘,事务才能提交
Steal/ No-Steal
现在来定义 No-Steal 策略,No-Steal是说在事务提交之前,页面不能被写入磁盘。这去报了我们不会让数据库处于一个中间状态——因为如果该事务没有完成,那么它的任何变化也不应该被持久化。但这个策略的缺陷在于它舒服了我们使用内存的方式,我们必须把每个脏页保留下来,直到一个事务完成——可能会占用大量内存空间
因此我们提出Steal策略,即允许在事务完成之前将修改过后的脏页写回到磁盘上。
Steal的例子如下,我们看到,在把A从100改为90的之后,还未提交就把A刷入了磁盘。就好像偷偷摸摸的把页给写到磁盘里去了
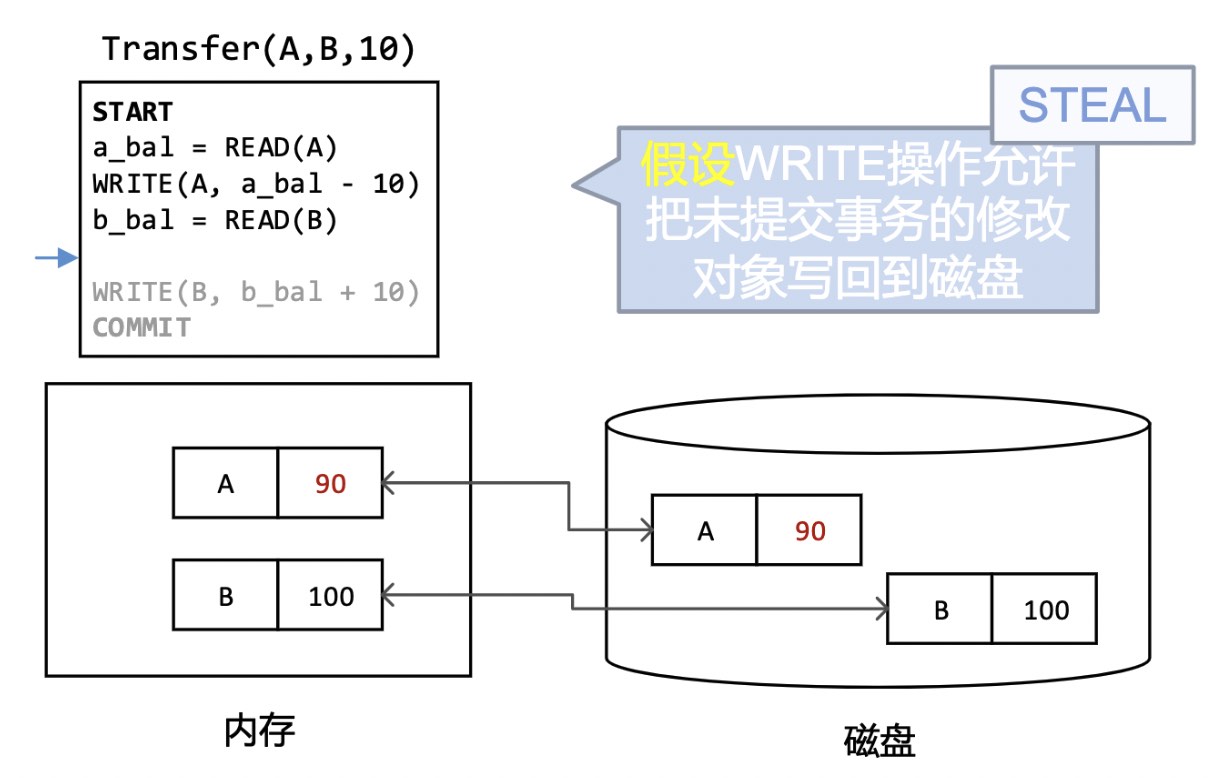
那么显然这种方法是有问题的,比如在这里修改了A,然后直接把A写回磁盘,这时候突然发生了系统故障。由于B还没有被修改,因此数据库需要回滚到A被修改前的状态。因此,这里需要用到Undo日志,记录修改前的状态。
Force/No Force
force是说在事务提交前强制所有修改过的数据页到磁盘, 这将确保耐久性。但是这种方法的缺点是性能不足,最终我们会做很多不必要的写操作。
因此No Force策略更加常用。这种策略是说,只在脏页要被从缓冲区删除的时候再写回磁盘。这样可以减少不必要的写入,但它是的数据库的持久性变得复杂。因为可能没有把脏页刷回磁盘,发生故障之后可能会导致数据丢失,因此需要Redo日志。
也就是说,日志需要记录修改后的值,这样一旦发生故障,可以通过Redo日志将数据库改为日志提交过后的状态,体现了数据库的持久性。
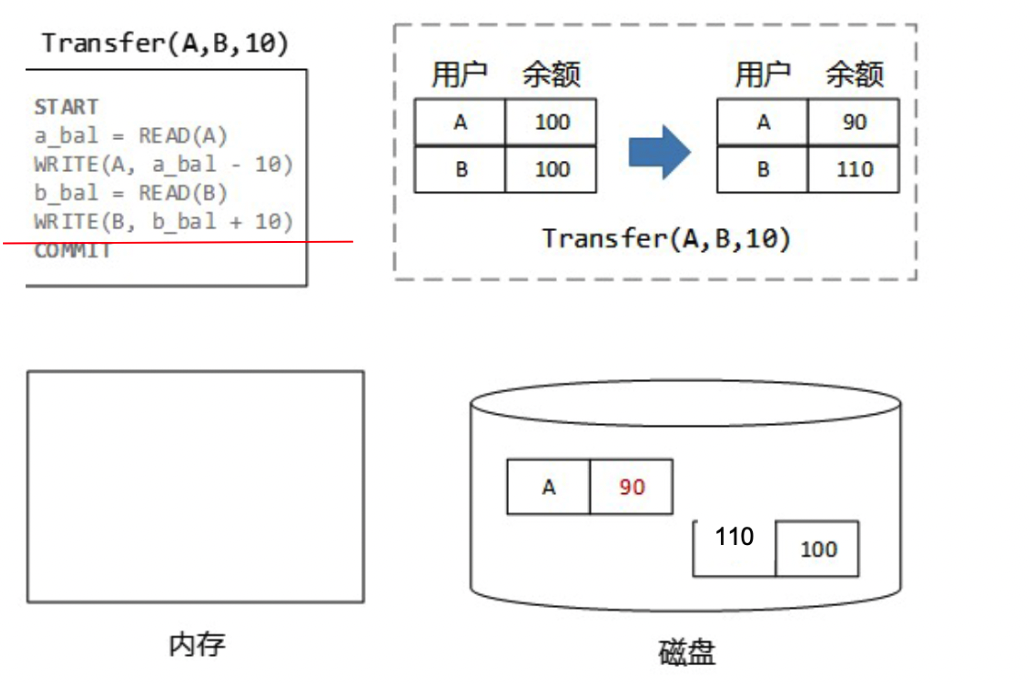
再回到上面那个四宫格,我们看到Force+No Steal策略是最方便的,最容易实现的。但是我们还是选择No Force+Steal策略,虽然仅用这个策略无法满足持久性和原子性,但是可以获得最好的功能。至于如何实现原子性和持久性,我们就需要靠undo+redo日志来帮忙了
WAL日志
先写日志 WAL(write-ahead logging),即在写数据之前先写日志。
- 将对数据库的修改记录在单独的存储空间中(日志缓冲区) 日志缓冲区和数据缓冲区是两回事
- 日志只支持追加操作(顺序I/O)
- 修改的数据对象持久化之前,需要保证其对应的修改已记录在日志文件中(WAL)
- 日志落盘后事务即可提交 S2PL释放锁的时间呢?
日志生成的主要步骤:
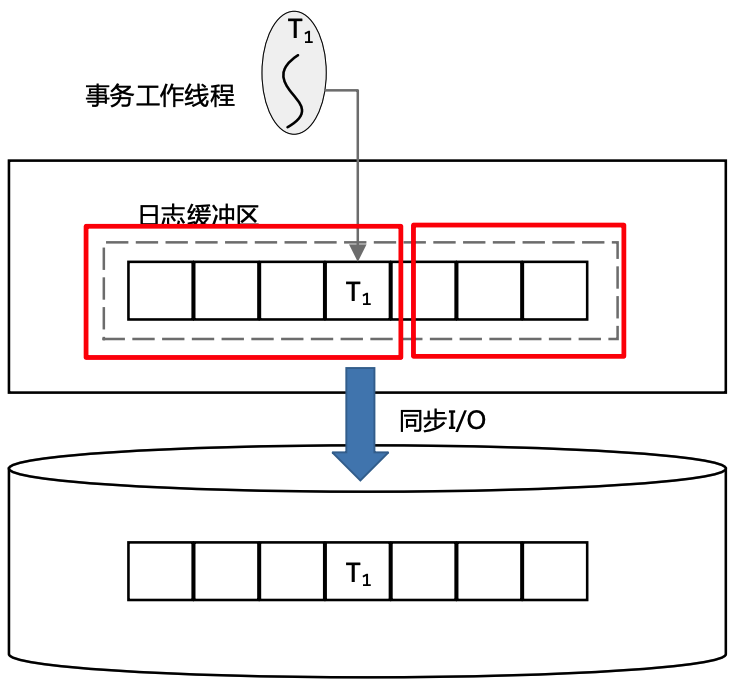
- 事务提交(可以理解为返回客户端,事务修改 对外部可见)
WAL实现
为了实现 WAL策略,我们需要在日志记录中添加一个字段——LSN。它代表了日志序列号,LSN是一个唯一的递增的数字,它有助于标志着操作的顺序(如果你看到一条LSN=20的日志记录,那么该操作一定是发生在LSN=10的记录之后的)。我们还将为每条日志记录添加一个prevLSN字段,该字段存储了同一事务的最后一次操作,这对撤销一个交易来说是很有用的。
数据库还将跟踪存储在RAM中的flushedLSN。flushedLSN追踪最后一条被刷入磁盘的日志记录的LSN,它意味着该页已经被写入磁盘,也意味着在内存中我们不再需要这个页了。
我们还将为每个数据页添加一段元数据,称为pageLSN。pageLSN存储了最后修改该页的操作的LSN。我们将用它来告诉我们哪些操作的操作,以及哪些操作必须重做。
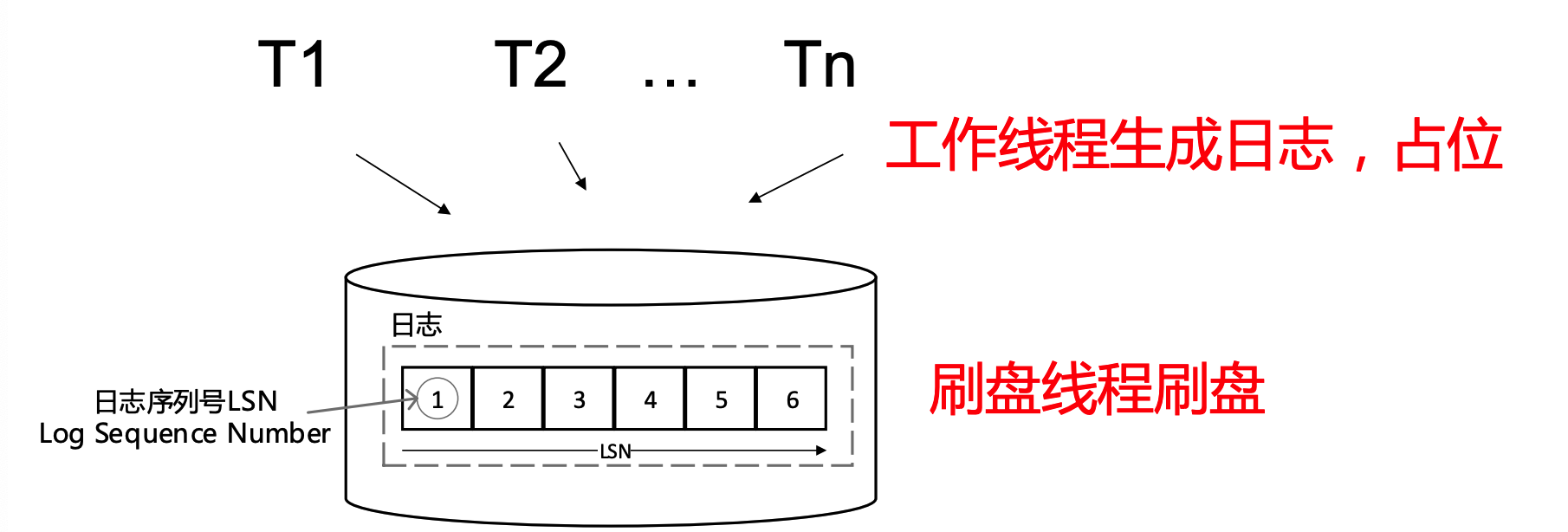
ARIES Recovery Algorithm
当数据库系统崩溃之后,我们只能获得数据库写到磁盘中去的数据页和日志。在重启之后,我们要对数据库进行恢复,达到两个目标:
- 所有已经提交的事务,都要恢复到提交事务之后的状态(持久性)
- 所有未提交的事务,都要恢复到事务执行之前的状态(原子性)
这个算法就是说在No Force和Steal的情况下,如何将数据库日志恢复到上面两个状态.这个算法主要分为三个阶段:
Analysis Phase: 重新构建 Xact table 和 DPT
Redo Phase: 重复提交后却未写回的操作,以实现持久性
- Undo Phase:撤销未提交但已写回的事务操作,以保证事务的持久性
首先我们来说说 Xact table 和 DPT是什么:
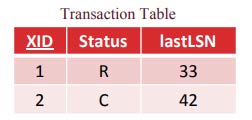
transaction table
Transaction table 记录了活跃的事务的相关信息,它有三个字段。活跃事务表示用来做undo的,因为
- XID: 事务 ID
- status: either running, committing, or aborting
- lastLSN: the LSN of the most recent operation for this transaction
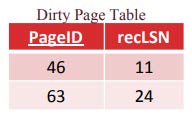
Dirty Page Table (DPT)
DPT记录了那些页是脏页(被修改过后的), 它有两个字段。脏页表主要是用来做Redo的
Page ID
recLSN: 第一个产生这个脏页的LSN
Analyse phase
Analyse phase 就是把系统crush的那一瞬间的两张表给重构出来。为了实现这个操作,我们需要扫描所有的日志记录。下面是遇到各种日志的处理方法
- 任何只要不是END的记录,就说明该事务尚未结束,就需要将其加入到Xact Table中,同时设置LSN为当前记录的LSN
- 如果该记录是COMMIT或者是ABORT,那么就修改相应transaction在Xact Table中的记录(修改状态)
- 如果该记录是UPDATE,而且日志中对应的页不再DPT当中,说明发现了一个新的脏页。那么就要把这页加到DPT中并设置recLSN=该日志的LSN
- 如果该记录是END,那就从Xact表中删除该事务
在Analyse phase的最后阶段,对于任何正在COMMIT的事务,他只是在等待提交罢了,对数据的修改、更新操作都已经做完了(相当于END),因此我们需要把 END记录到日志中,并从Xact表中删除该事务。最终只会让ABORT或者RUNNING的事务留在Xact表中
如果我们按照上面的操作,老老实实得把数据库日志从头到尾扫描一遍,显然这样的性能很低,不切实际。因此我们可以用到checkpoint,它像一个快照一样,每隔一段时间会把Xact Table和DPT记录在日志中。
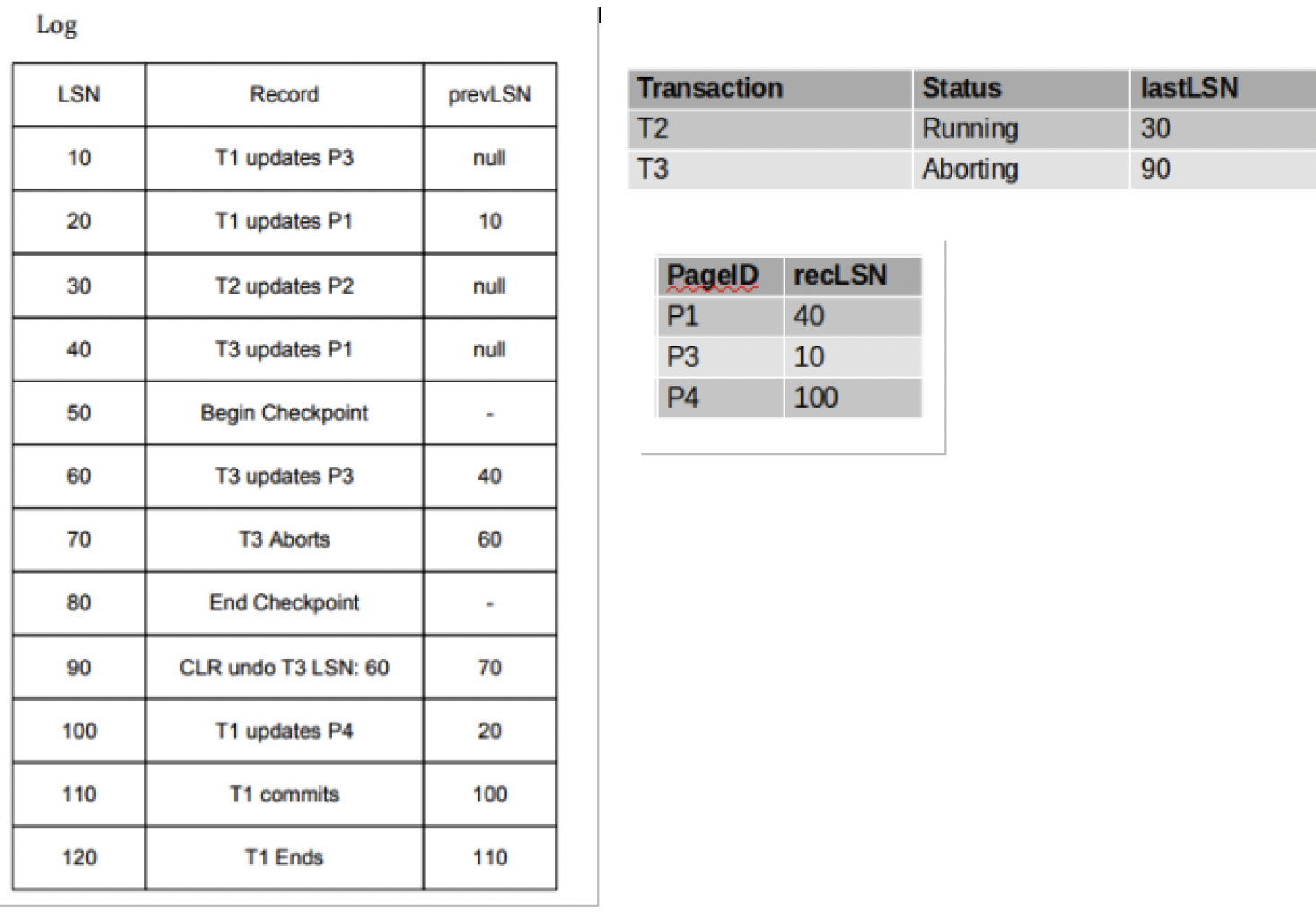
我们来举一个例子:
下面这张图是我们要恢复数据库时从磁盘中提出来的数据,左侧是日志,看到LSN50是Begin Checkpoint,说明在这一时刻开始形成一个快照,LSN50之前的Xact Table和DPT都会保存下来。检查点在LSN80处生成结束。
右侧就是从检查点提出的Xact Table和DPT,但是这两张表记录的信息时不全的,我们要从LSN60处开始复原重构两张表
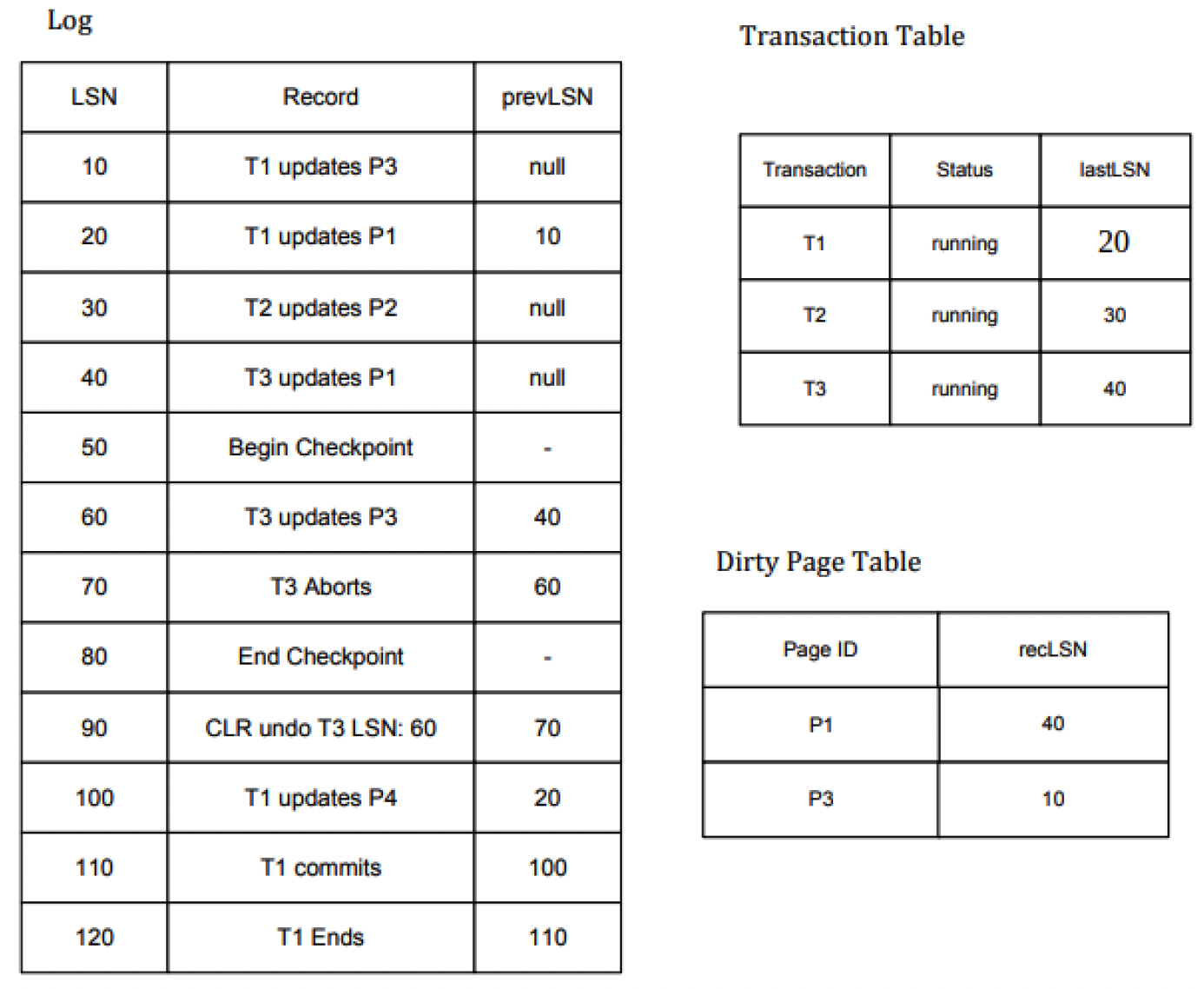
- 首先,我们从LSN60开始构建,它记录了T3事务对P3页进行了update。因为P3已经在DPT中,因此不用改。但是它更新了Xact Table中的T3记录,需要将字段lastLSN改为当前LSN(即60)

- LSN70是 T3的 Aborts,因此修改 Xact Table中的T3记录,将Status改为Aborts即可

- LSN90是也是一条动作,就是把T3 Update P3给撤销了,因此需要更新Xact Table中的T3记录,将lastLSN改为90

- LSN100是T1事务对P4页做的Update操作,DPT中没有P1,因此需要把P4加入DPT;同时要更新Xact Table的T1记录,将lastLSN更新为100

- LSN110是T1事务的提交,因此更新Xact Table T1记录,将Status改为 Committing

- LSN120是T1事务的结束,因此可以从Xact Table中删除T1记录

Redo phase
Redo phase使用来保证持久化的,我们从DPT中最小的recLSN记录开始,因为那是时可能还没有进行第一个刷盘的操作。
我们将会redo所有的Update操作和CLR操作 ,如果某一个LSN符合下面三条中的一条,那么就跳过:
- 该页不再DPT中,意味着所有对该页修改都已经持久化到磁盘了
- 如果 recLSN > LSN, 因为正常情况下LSN是大于等于 recLSN的,如果recLSN > LSN,说明污染该页的第一个动作要比当前的LSN发生的更晚,因次当前LSN并不需要被redo
- pageLSN(disk) >= LSN, 因为pageLSN记录了最后修改该页的操作日志,如果大于LSN的话,那说明并不需要redo当前的LSN
现在复原了两张表,Xact Table是要做Undo操作的,DPT是要做Redo的。
那么,应该从哪里开始恢复操作呢?DPT中最小的recLSN是 10,因此我们从LSN10开始看。
- LSN10 : 更新 P3
- LSN20 :P1.recLSN=40 > 20, 跳过
- LSN30: Page2不再DPT中,因此跳过
- LSN40: P1.recLSN=40 = 40 , 执行update p1操作
- LSN50: 跳过
- LSN60:符合条件,更新P3
- LSN70: 只redo Update操作和CLR操作
- LSN80: 跳过
- LSN90: 执行CLR操作
- LSN100: P4.recLSN=100==LSN,因此执行更新P4操作
- LSN110-LSN120: 跳过
Undo phase
Undo 阶段和Redo阶段的起始位置不同 ,Undo是从日志表中的最后一行开始向前推进的。
我们要做的是吧Xact Table中没有完成的事务给回滚掉。其具体操作就是:撤销所有在Xact Table中所有事务的Update操作。使数据其从中间态恢复到事务执行前的状态
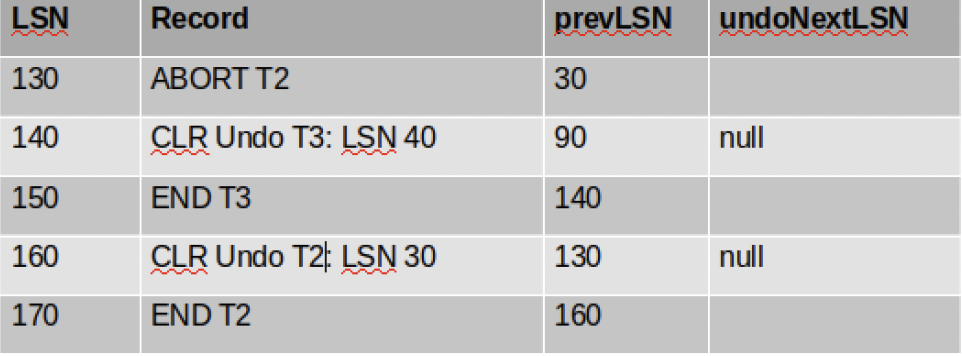
还是以上图为例,我们看到Xact Table中有T2和T3是需要回滚的。对于每个需要回滚的事务,直接从lastLSN开始。
- 对于T2,我们可以直接从LSN30开始回滚
- 对于T3,我们可以从LSN90 开始回滚
注意,回滚也会记录日志:
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK