

Graviton2 outperforms x86 on Spark SQL - Infrastructure Solutions blog - Arm Com...
source link: https://community.arm.com/arm-community-blogs/b/infrastructure-solutions-blog/posts/spark-sql-on-aws-graviton2-demonstrates-up-to-49-performance-benefits-over-x86-697155095
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Introduction
Spark SQL is one of the most used Spark’s modules, providing a simplified programing interface to run Spark computations on a cluster. It comes with query optimizations that help Spark to run more efficiently. Since Spark requires lots of resources to run jobs on big data, performance and cost efficiency is of importance to users.
In a previous blog on Apache Spark, we ran several benchmarks (using HiBench) on a pseudo-distributed Spark cluster. One of the benchmarks was SQL aggregation which showed better performance when running the Spark cluster on AWS Graviton2-based instances. In this blog, we use similar cluster setup and run TPC-H and TPC-DS SQL benchmarks. We compare the performance of the benchmarks on the clusters of M6 (Graviton2) and M5 (x86) type of instances.
TPC-H Benchmarks
The Transaction Processing Performance Council (TPC) is a consortium that designs and measures benchmarks for transaction processing systems. TPC-H is one of the benchmarks specifically designed to model decision support workloads for ad hoc and concurrent data handling. It defines 22 complex SQL queries that simulate real-world business scenarios such as Online Transaction Processing (OLTP) transactions. The TPC-H metric is called Query-per-Hour Performance Metric (QphH@Size), which considers the database size and the query processing power for single stream and multiple concurrent user query submissions. Our Spark benchmarks do not simulate the scenario with concurrent users, so we only report runtimes for the TPC-H queries.
TPC-DS Benchmarks
TPC-DS is another common decision support benchmark specifically designed to model decision support workloads such as retail businesses. It simulates user queries that convert to business intelligence decisions, and data maintenance.
TPC-DS provides logical database design, and the database is required to have SQL interface. The benchmarks define 99 SQL queries to run against the database, which model complex business problems and use different access patterns.
TPC has provided the tools to generate data to be inserted into the database in different scale factors for both TPC-DS and TPC-H benchmarks. Each scale factor represents the amount of data in GB. For instance, the scale factor of 1000 generates approximately 1000GB of data.
Benchmark Environment
Benchmark tool
We use Spark SQL Performance Tests to run TPC-DS and TPC-H v2.4 benchmarks against Spark. This tools reports query runtimes for both the benchmarks. For this blog, we only demonstrate the result for the scale factor of 1000 (1000GB of data).
Spark cluster
We run the benchmarks against similar pseudo-distributed Yarn Hadoop cluster as in HiBench experiments, with the same Spark and Hadoop versions (Spark version 3.1.2 and Yarn Hadoop version 3.3.1). The instance types and sizes are m6gd.16xlarge and m5d.16xlarge with NVMe SSD partitions to be used for HDFS storage.
We use the following parameters to run the cluster on a single instance:
- Yarn executor cores: 5
- Number of executors: 12
- Executor memory: 16GB
Benchmark performance results
The charts in this section show benchmark results on 16xlarge instances. The left axis on each chart is query runtime in seconds. The axis on the right is M6gd performance improvements over M5d instances.
TPC-H benchmarks
The following chart shows TPC-H benchmark results on M6gd.16xlarge vs M5d.16xlarge instances sorted by the runtimes of the queries.
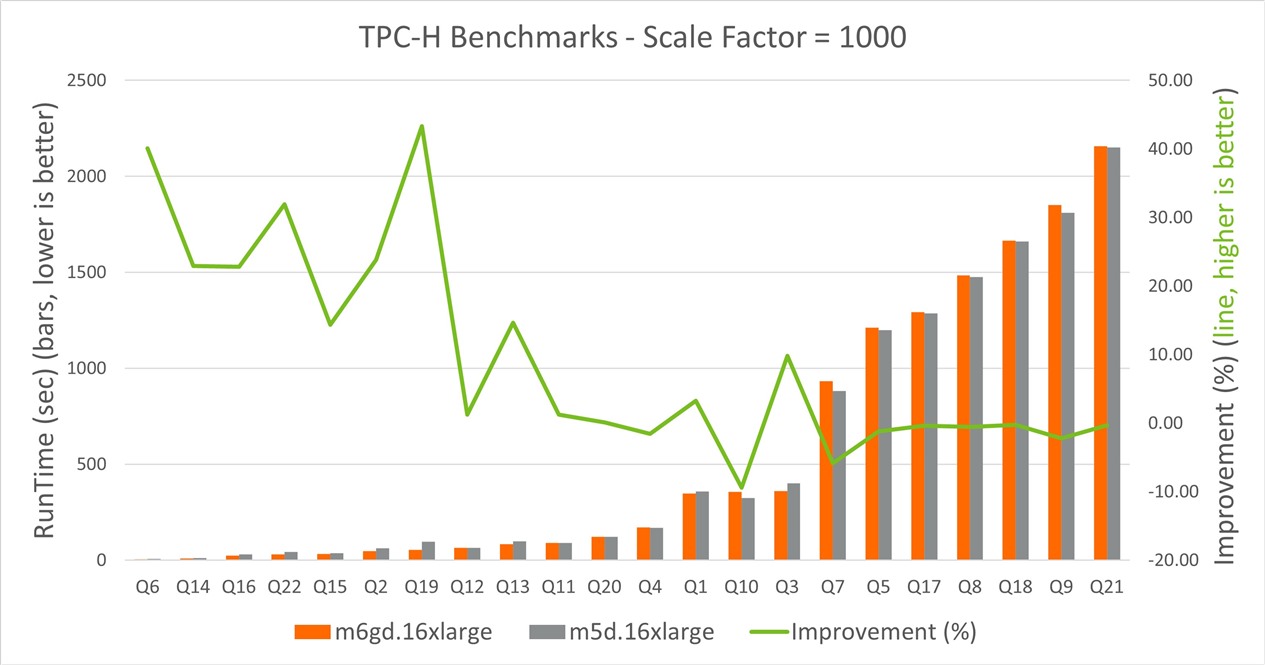
Figure 1. TCP-H SQL query runtime comparison on m6g and m5d instances
TPC-H benchmarks demonstrate that M6gd outperforms M5d in more than 60% of the queries with up to 43% improvement. Fewer than 40% of the queries have higher runtimes than the M5d counterpart, with the maximum of 9.4% lower performance.
TPC-DS benchmarks
The following chart shows TPC-DS benchmark results on M6gd.16xlarge vs M5d.16xlarge instances sorted by the runtimes of the queries.
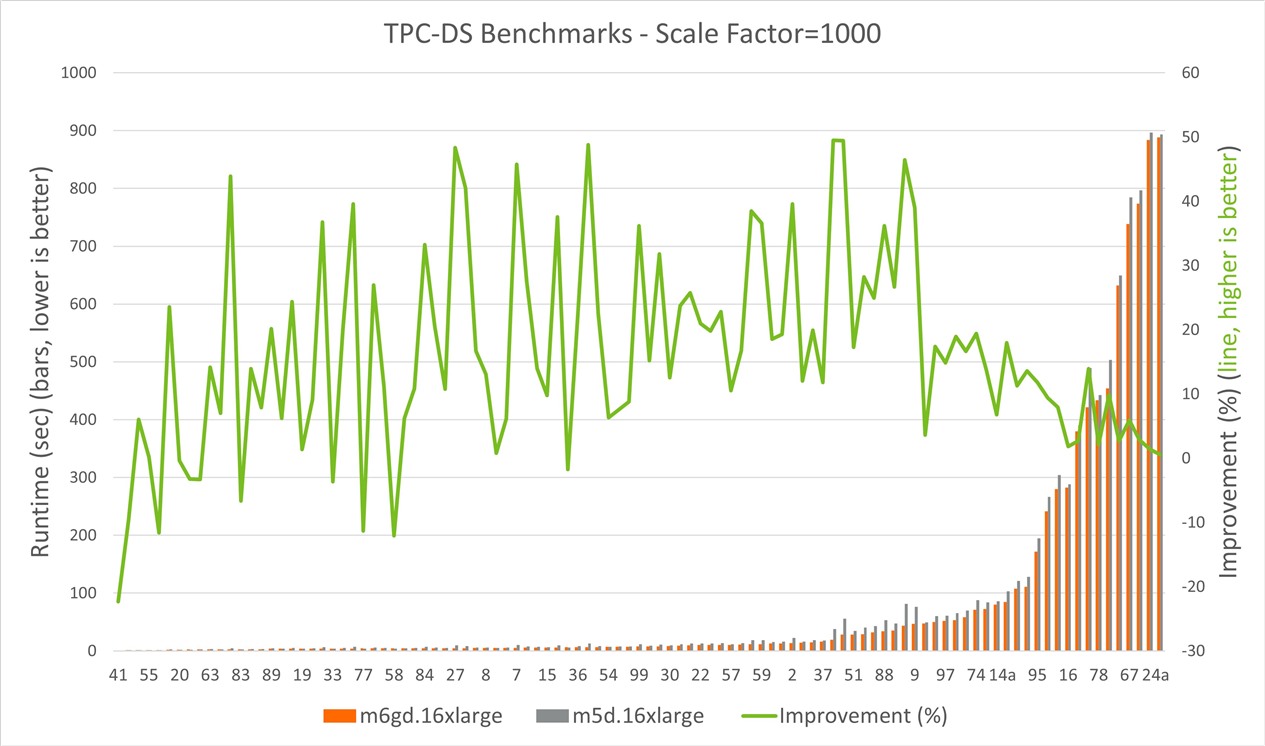
Figure 1. TCP-DS SQL query runtime comparison on m6g and m5d instances
Benchmarks contain 102 queries, including 99 TPC-DS queries and 3 query variants. From 102 queries, M6gd instances run about 90% of the queries faster than M5d counterparts with up to 49% improvement.
Conclusion
Our TPC-H benchmarks on a pseudo-distributed Spark cluster show that M6gd instances perform up to 43% better than M5d instances for most of the queries. Running TPC-DS benchmarks shows similar results, where M6gd instances perform up to 49% better than M5d instances for the majority (90%) of the queries. By running Spark jobs on Graviton2-based instances, consumers benefit further by the lower price per hour offered compared to x86-architecture ones.
Visit the AWS Graviton page for customer stories on adoption of Arm-based processors. For any queries related to your software workloads running on Arm Neoverse platforms, feel free to reach out to us at [email protected].
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK