

二十分钟了解K8S网络模型原理
source link: https://developer.51cto.com/article/710970.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

对于好多刚接触K8S,甚至是接触K8S很长时间的同学,K8S网络模型可以说是个很神秘的东西。那么对于这部分同学,恭喜你发现了本文,只要你花二十分钟的时间,就保证你能轻松掌握K8S网络模型原理。
01知识储备
首先,我们提前热身一下,学一点网络基础知识。
1.1 网络命名空间
维基百科的定义是这样的“Network namespaces virtualize the network stack”,意思就是说linux network namespace对network stack做了虚拟化。什么是network stack呢?网络栈包括了网卡(network interface),回环设备(loopback device),路由表(routing tables)和iptables规则。打个比方,当你登录一台linux服务器时,你默认用的就是Host网络栈。
1.2 网桥设备
网桥是在内核中虚拟出来的,可以将主机上真实的物理网卡(如eth0,eth1),或虚拟的网卡桥接上来。桥接上来的网卡就相当于网桥上的端口,端口收到的数据包都提交给这个虚拟的“网桥”,让其进行转发。
1.3 对设备
Veth Pair设备被创建出来后,总是以两个虚拟网卡(Veth Peer)的形式成对出现,其中一张“网卡”发出的数据包可以直接在出现在对应的“网卡”上。Veth Pair常用作连接不同Network Namespace的网线。
1.4 VXLAN
VXLAN(Virtual extensible Local Area Network,虚拟扩展局域网),是由IETF定义的NVO3(Network Virtualization over Layer 3)标准技术之一,是对传统VLAN协议的一种扩展。VXLAN的特点是将L2的以太帧封装到UDP报文(即L2 over L4)中,并在L3网络中传输。
VXLAN本质上是一种隧道技术,在源网络设备与目的网络设备之间的IP网络上,建立一条逻辑隧道,将用户侧报文经过特定的封装后通过这条隧道转发。从用户的角度来看,接入网络的服务器就像是连接到了一个虚拟的二层交换机的不同端口上,可以方便地通信。
1.5 BGP(边界网关协议)
边界网关协议(Border Gateway Protocol,缩写:BGP)是互联网上一个核心的去中心化自治路由协议。它通过维护IP路由表或“前缀”表来实现自治系统(AS)之间的可达性,属于矢量路由协议。BGP不使用传统的内部网关协议(IGP)的指标,而使用基于路径、网络策略或规则集来决定路由。
02什么是微服务的可观测性单机容器网络
好了,经过上一章的热身,大家对网络基础知识应该有了大致的了解。那么咱们接下来先尝试探索一下单机容器网络模型,这也是docker默认使用的单机容器网络模型。
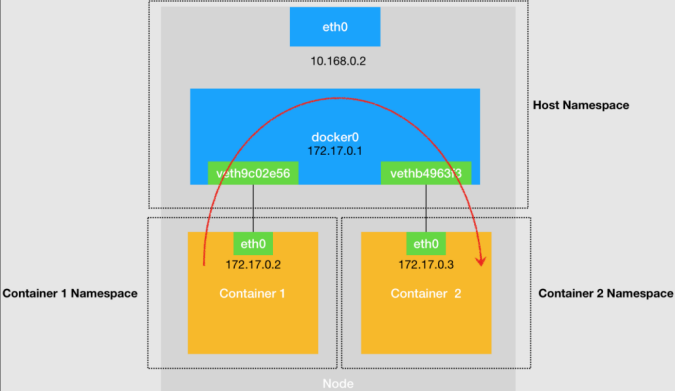
图1 宿主机上不同容器通过网桥进行互通
单机容器网络的示意图如图1,图中给出了如下几个关键点:
- 每个容器(Container)分别拥有自己的Network Namespace。
- 容器通过对设备,连接到宿主机的Host Network Namespace。对设备在容器Network Namespace这一端的“网卡”是eth0,eth0配置的ip即容器的ip。对设备连接Host Namespace的那一端挂载到网桥设备docker0。
- 网桥设备docker0,挂载着所有容器的对设备的Host Namespace这一端。并且,挂载在网桥上的设备,会被降级成网桥上的一个端口,端口的唯一作用就是转发网桥或另一端对设备的数据包。
- 从Container1发送到Container2的数据包,首先经过Container1中的eth0,到达docker0网桥,docker0网桥经过二层转发,将数据包发送到Container2对应的端口(Container2对设备的docker0网桥这一端),这样数据包就被直接送到Container2中了。
上述就是单机容器网络的基本原理,在对单机容器网络模型有了初步的认识后,接下来我们进入正题,开始对K8S网络模型的探索。
03K8S网络模型
接触过K8S的同学,大致都听说过Flannel和Calico两种网络模型。但是,这两种网络模型具体是什么样子,工作原理是什么,可能很多同学就比较困惑了。没关系,接下来我们就开始对k8S网络模型的探索吧!
3.1 Flannel网络模型
在上一章中,介绍了单机容器网络的原理。那么,要理解容器如何“跨主机通信”的原理,一定要从Flannel这个项目说起。Flannel项目是CoreOS公司推出的容器网络方案,目前它支持三种后端实现:
- VXLAN
- Host-gw
3.1.1 Flannel-UDP
UPD模式Flannel最早实现的一种方式,也是性能最差的,目前已被弃用。但是这种方式也是最直接,最容易理解的方式,所以我们从这种方式开始介绍。
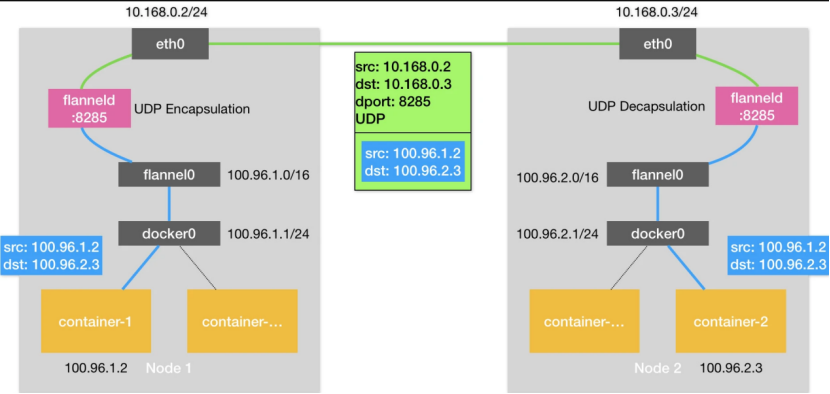
图2 Flannel-UDP模式跨主机通信示意图
图2是Flannel-UDP模式的原理图。与单机容器网络相比,这里新增了一个flannel0设备和flanneld进程。flannel0设备是一个TUN设备,它的作用非常简单,就是在系统内核和用户应用程序之间传包;flanneld进程的职责,就是封装和解封装。数据包是如何从Node1中的container-1容器发送到Node2的container-2容器的呢?
- 数据包从container-1,来到了网桥docker0上,由于数据包的目的地址不属于网桥的网段,所以数据包经由docker0网桥,出现在宿主机上。
- 在宿主机的路由表中,去往100.96.0.0/16网段的包经由flannel0处理。flannel0收到数据包之后,将数据包送到flanneld进程,flanneld进程会对数据包封装成一个UDP数据包,src和dst地址分别为两个容器对应的宿主机的地址。这样,数据包就可以到达Node2了。
- 数据包到达Node2的8285端口,即Node2上的flanneld进程,会被执行解封装操作,之后数据包被发送到TUN设备,即flannel0设备。剩下的事情就简单了,数据包经过docker0网桥到达container-2。
3.1.2 Flannel-VXLAN
经过上一小节的介绍,大家对Flannel-UDP模式大致了解了吧,那聪明的你们已经猜到为什么Flannel-UDP被弃用了吧?没错,因为效率太低了,数据包每次经过flannel0设备,都会经过内核态-用户态-内核态的这一顿折腾。
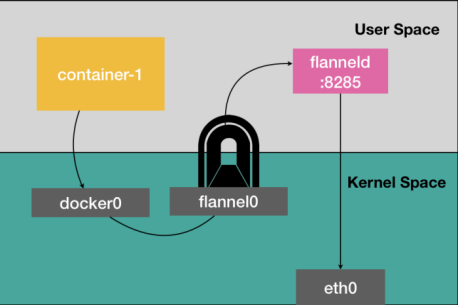
图3 TUN设备示意图
那有没有办法不要这么折腾呢?有,Flannel-VXLAN方案就解决了这个问题。Flannel-VXLAN方案用VXLAN技术替代了flannel0设备,让数据包能够在内核态上实现数据包的封装和解封装。
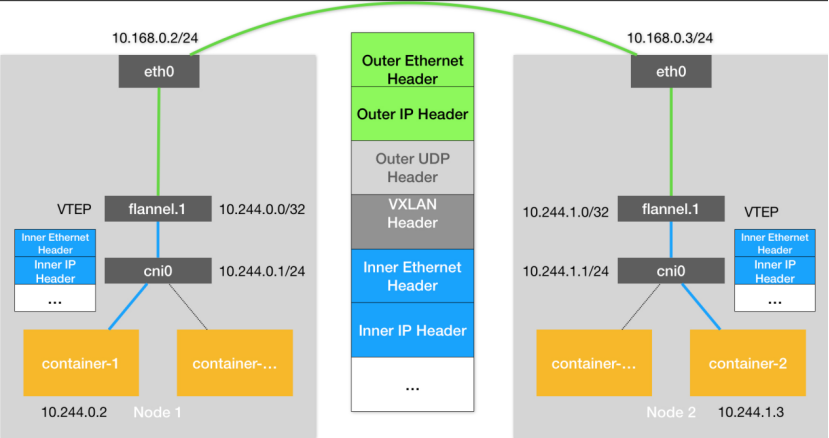
图4 Flannel-VXLAN网络模型示意图
Flannel-VXLAN网络模型的原理如图4所示,你会发现,这和Flannel-UDP基本上的是一样。事实也的确如此,Flannel-VXLAN是Flannel-UDP的升级版。这里需要交代一下他们之间的不同点。
- Flannel-UDP的TUN设备flannel0,升级成了VXLAN的VTEP设备。数据包的封装和解封装在内核态就能完成。
- 数据包的格式中,增加了VXLAN Header,这个Header的作用和Flannel-UDP的数据包中的dport:8285的作用是一样的,当数据包来到Node2时,操作系统能根据VXLAN Header,把数据包直接给到flannel.1设备。
3.1.3 Flannel-host-gw
此时,聪明的你肯定会说,Flannel-VXLAN虽然效率提高了,但是还是用到了隧道技术,效率还是会受到影响,能不能不用隧道技术呢?答案是能。接下来我们继续探索Flannel-host-gw网络模型,一个基于三层的网络方案。老规矩,上图。
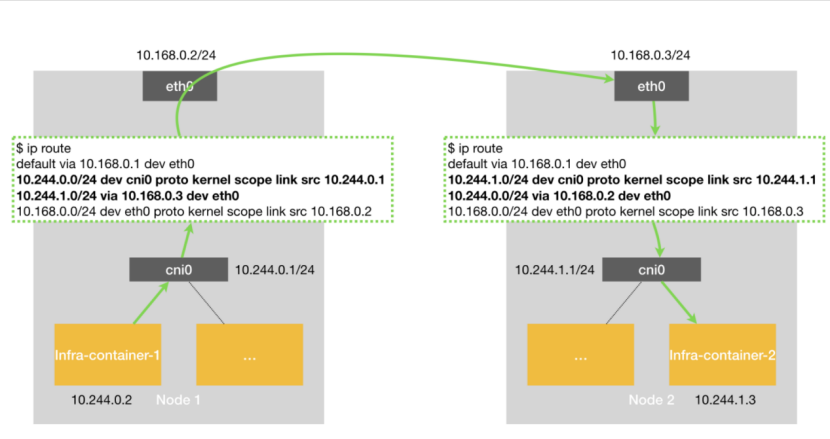
图5 Flannel-host-gw网络模型示意图
图5是Flannel-host-gw网络模型,相比较之前的两个网络模型,隧道设备确实没有了,取而代之的是一堆路由规则。那,数据包又是怎么从container1到container2的呢?
- 当数据包从container1到了网桥之后,通过Host网络栈的路由表,发现去container2的路已经指明,经由eth0,达到Node2(10.168.0.3/24)即可。
- 当数据包到了Node2之后,通过Host网络栈的路由表,找到cni0网桥,container2自然也就找到了。
肉眼可见,Flannel-host-gw的性能确实提高了很多,那为什么还要用Flannel-VXLAN呢?原因很明显,Flannel-host-gw只支持宿主机在二层连通的网络,并且,K8S的规模不能太大,否则每台机器的路由表就太多了。
3.2 Calico网络模型
经过上一小节的介绍,大家对Flannel应该有个大致的了解了。可能有人会问,除了Flannel,K8S还有别的网络模型么。当然有了,下面我们开始探索Calico网络模型。
3.2.1 Calico(非IPIP模式)
实际上Calico网络模型的解决方案,几乎和Flannel-host-gw是一样的。不同的是Flannel-host-gw使用etcd来维护主机的路由表,而Calico则使用BGP(边界网关协议)来维护主机的路由表。BGP协议的定义看着有点高深,换成通俗的说法,大家可以理解为在每个边界网关都会都运行着一个小程序,它们会交换各自的路由信息,将需要的信息更新到自己的路由表里。BGP这个能力正好可以取代Flannel-host-gw利用Etcd维护主机上路由表的功能,并且更为强大。
除了BGP之外,Calico另外一个不同之处就在于它不需要维护一个网桥,Calico网络模型如6所示:
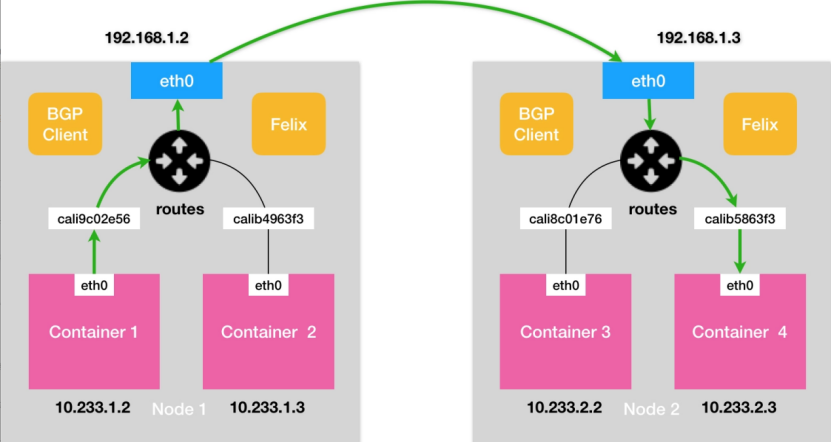
图6 Calico网络模型示意图
图6是Calico网络模型示意图,其中BGP Client和Felix的作用是和K8S集群其他节点交换路由信息,并更新Host网络栈的路由信息。
由于没有了网桥设备,每个对设备Host网络栈的这一端,需要配置一条路由规则,将目的地址为对应Container的数据包转入该对设备。对应的路由如下所示:
10.233.1.2 dev cali9c02e56 scope link数据包是如何从Container1走到Container3的呢?过程基本上和Flannel-host-gw无异了。唯一区别就是数据包进出容器,不再依赖网桥,而是直接通过宿主机路由表找到容器的另一端对设备。
3.2.2 Calico(IPIP模式)
Calico听着挺强大的,实则和Flannel-host-gw一样,只支持宿主机二层联通的情况。假设Container1和Container3的宿主机在不同的子网,那通过二层网络是无法将数据包传到下一跳的地址的。如图7所示,Calico会在Node1创建这样一条路由规则:
10.233.2.0/16 via 192.168.2.2 eth0此时问题就出现了,下一跳是192.168.2.2,和Node1不在一个子网里,根本就找不到。
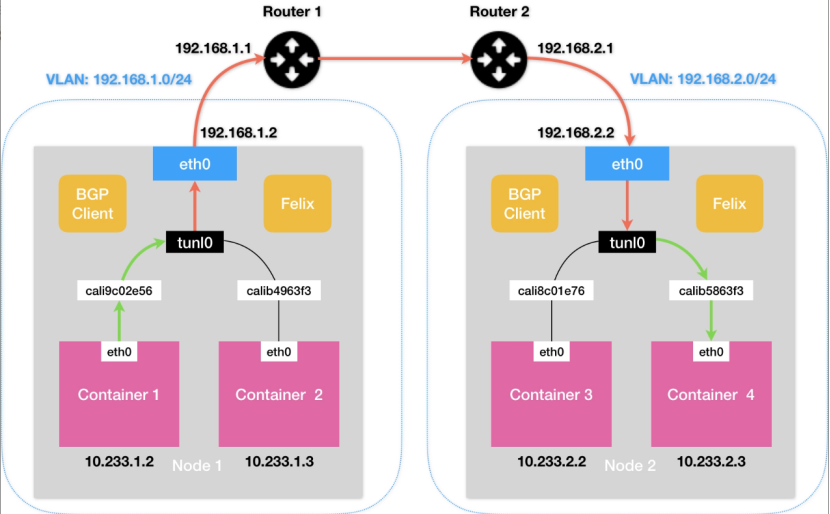
图7 Calico(IPIP模式)网络模型示意图
Calico的IPIP模式解决了上述问题,在每一台宿主机上,都会增加一个tunl0设备(IP隧道设备),并且会对应增加如下一条路由策略:
10.233.2.0/16 via 192.168.2.2 tunl0这样一来,Container1去往Container3的数据包就会经过tunl0设备的处理,tunl0设备会在源IP报头之外新增一个外部IP报头,拿本例来说,这个外部IP报头的src和dst分别为Node1和Node2的IP,这样,数据包就伪装成了从Node1发到Node2的数据包。当数据包到达Node2之后,Node2上的tunl0会把外部IP报头拿掉,从而拿到原始的IP包。
我知道,聪明的你此时肯定会有一个更好的想法,为什么不在Router1和Router2上也用BGP协议的方式,同步容器的IP路由信息呢?这样宿主机上不就可以不用tunl0设备了么。这个方法确实很好,并且在一些场景也得到了应用。
03CNI网络插件
最后,我再介绍一下CNI网络插件。CNI(Container Network Interface)顾名思义,是K8S的网络接口。这个接口的作用就是当K8S的 kubelet创建Pod时,dockershim会预先调用Docker API创建并启动Infra容器,执行SetUpPod的方法。这个方法会为CNI网络插件准备参数和环境变量,然后调用CNI插件为Infra容器配置网络。CNI网络插件仅需实现ADD和DEL两种方法,分别对应Pod加入K8S网络,以及Pod移出K8S网络。
用大白话再解释一遍,就是当Pod创建时,需要对网络进行一些设置,包括前边的提到的创建对设备,把对设备的一端挂载到网桥上,添加Pod以及主机的Network Namespace的路由规则等,这些操作当然可以由运维人员手动完成(不嫌累的话),CNI网络插件就是一个脚本,自动对网络进行设置。
Flannel和Calico各自都有专门的CNI插件,大家可以去Github上研究一下源码,并亲自部署一下试试。这里就不多介绍了,毕竟看再多的资料,都不如自己动手实践一遍理解得深刻。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK