

"一键脱衣"的DeepNude下架后,我在GitHub上找到它涉及的技术 | 程序师 - 程...
source link: https://www.techug.com/post/deepnude-an-image-to-image-technology__trashed/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

“一键脱衣”的DeepNude下架后,我在GitHub上找到它涉及的技术
前段时间,一名程序员开发出了一款名为 DeepNude 的应用软件。《技术无罪?AI脱衣App上线几个小时就被下线了》
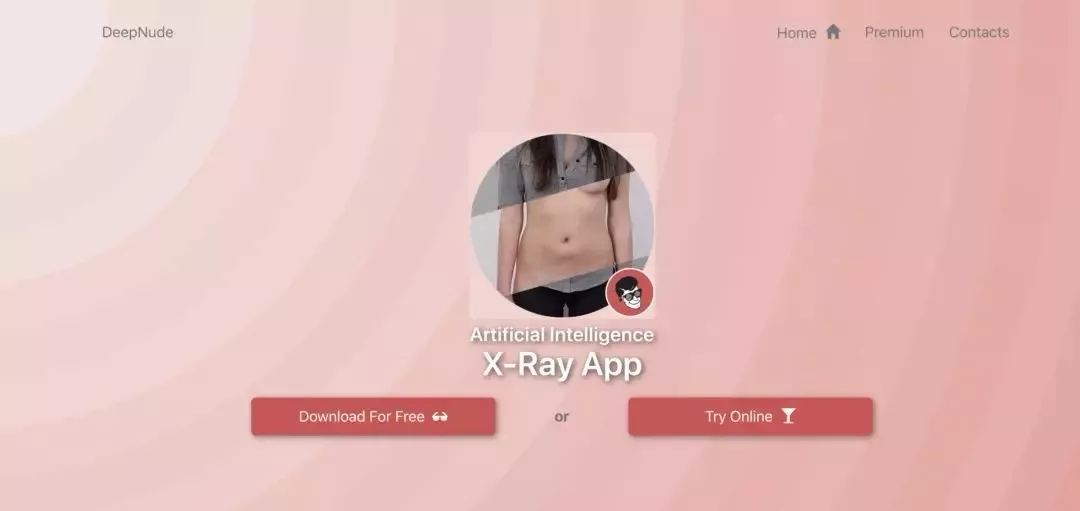
该APP的使用方法很简单,打开软件→转化→生成照片,从那个网上给出的生成结果来看,效果确实可以以假乱真,如下:

目前,这个程序已经被下线,不过,猿妹在Github上找到一个关于DeepNude使用的图像生成和图像修复相关技术项目,该项目由yuanxiaosc创建
这个仓库包含DeepNude的pix2pixHD(由英伟达提出)算法,更重要的是DeepNude背后的通用的Image-to-Image理论与实践研究。
Image-to-Image Demo
这一部分提供一个试玩的 Image-to-Image Demo:黑白简笔画到色彩丰富的猫、鞋、手袋。DeepNude 软件主要使用了Image-to-Image技术,该技术理论上可以把你输入的图片转换成任何你想要的图片。
在左侧框中按照自己想象画一个简笔画的猫,再点击process按钮,就能输出一个模型生成的猫。
体验地址:https://affinelayer.com/pixsrv/
DeepNude的技术堆栈
- Python + PyQt
- pytorch
- 深度计算机视觉
Image-to-Image Theoretical Research
这一部分阐述DeepNude相关的人工智能/深度学习理论(特别是计算机视觉)研究,
1. Pix2Pix
Pix2Pix是伯克利大学研究提出的使用条件对抗网络作为图像到图像转换问题的通用解决方案。(Github地址:https://github.com/phillipi/pix2pix)
2、Pix2PixHD

从语义图上获得高分辨率图片。语义图是一幅彩色图片,图上的不同色块代表不同种类物体,如行人、汽车、交通标志、建筑物等。Pix2PixHD将一张语义图作为输入,并由此生成了一张高分辨率的逼真的图像。之前的技术多数只能生成粗糙的低分辨率的图片,看起来也不真实。而这个研究却生成了2k乘1k分辨率的图像,已经很接近全高清的照片。(Github地址:https://github.com/NVIDIA/pix2pixHD)
3. CycleGAN
CycleGAN使用循环一致性损失函数来实现训练,而无需配对数据。换句话说,它可以从一个域转换到另一个域,而无需在源域和目标域之间进行一对一映射。这开启了执行许多有趣任务的可能性,例如照片增强,图像着色,样式传输等。您只需要源和目标数据集。
使用CycleGAN神经网络模型实现照片风格转换、照片效果增强、照片中风景季节变换、物体转换四大功能。
4. Image Inpainting 图像修复
在演示视频中,只需用工具将图像中不需要的内容简单涂抹掉,哪怕形状很不规则,NVIDIA的模型能够将图像“复原”,用非常逼真的画面填补被涂抹的空白。可谓是一键P图,而且“毫无ps痕迹”。该研究来自Nvidia的Guilin Liu等人的团队,他们发布了一种可以编辑图像或重建已损坏图像的深度学习方法,即使图像穿了个洞或丢失了像素。这是目前2018 state-of-the-art的方法。
事实上,可能不需要Image-to-Image。我们可以使用GAN直接从随机值生成图像或从文本生成图像:
1.Obj-GAN
微软人工智能研究院(Microsoft Research AI)开发的新AI技术Obj-GAN可以理解自然语言描述、绘制草图、合成图像,然后根据草图框架和文字提供的个别单词细化细节。换句话说,这个网络可以根据描述日常场景的文字描述生成同样场景的图像。
效果
模型
2.StoryGAN
微软新研究提出新型GAN——ObjGAN,可根据文字描述生成复杂场景。他们还提出另一个可以画故事的GAN——StoryGAN,输入一个故事的文本,即可输出连环画。
当前最优的文本到图像生成模型可以基于单句描述生成逼真的鸟类图像。然而,文本到图像生成器远远不止仅对一个句子生成单个图像。给定一个多句段落,生成一系列图像,每个图像对应一个句子,完整地可视化整个故事。
效果
现在用得最多的Image-to-Image技术应该就是美颜APP了,所以我们为什么不开发一个更加智能的美颜相机呢
技术无罪,但也别娱乐至死,什么能做什么不能做要领的清,希望以上这些技术,大家都能把它们用到正道上。
Recommend
-
48
IT之家6月28日消息此前,美国科技媒体Motherboard报道,Twitter用户@deepnudeapp最近开发出一款名叫DeepNude的应用,只要给DeepNude一张女性照片,借助神经网络技术,App可以自动“脱掉”女性身上的衣
-
37
近日一款名叫“DeepNude”的女性AI脱衣应用在互联网上引起了轩然大波,因为人们只需提交一张他人照片,即可通过算法来模拟出裸体的效果。与早前的DeepFakes换脸应用类似,DeepNude同样打开了AI工具的阴暗面,因为开发者很难确保其他人会恪守道德准则。
-
36
前段时间,一款名为「 DeepNude 」的「一键脱衣」APP 在社交网络上火了...
-
48
-
27
-
39
“一键脱衣”的DeepNude下架后,我在GitHub上找到它涉及的技术 前段时间,一名程序员开发出了一款名为 DeepNude 的应用软件。该APP的使用方法很简单,打开软件→转化→生成照片,从那个网上给出的生成结果来看,效果确实可以以假...
-
20
“一键脱衣”的DeepNude下架后,我在GitHub上找到它涉及的技术 231 前段时间,一名程序员开发出了一款名为 DeepNude 的应用软件。《技术无罪?AI脱衣App上线几个小时就被下线了》
-
7
女子地铁照被AI一键脱衣传播 网友:无下限的开发 2023-03-28 17:48 出处/作者:快科技 整合编辑:佚名 0
-
7
一键脱衣、换脸亲吻 AI让作恶成本更低 文/蒋菁 编辑/靖程 无论是爆火的ChatGPT,还是AI绘画、AI聊天等,都让人看...
-
8
《心灵奇旅》里说,寻找海洋之时,应该知道自己已经生活在水里。 AI 之于人类社会似乎也是这样。 今年以来,各行各业的「iPhone」时刻不断上演。Runway 化静为动,Pika 重绘局部,HeyGen 让老外说地道中文,舞台中央你方唱罢我登场。 在没有高...
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK