

My Big Fat Monolithic Alert
source link: https://cherkaskyb.medium.com/my-big-fat-monolithic-alert-498f21c1bb8a
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
photo source Unsplash by @sigmund
My Big Fat Monolithic Alert
In the last few years, the “micro-service” movement swept the software engineering landscape, becoming the de-facto standard for any modern SAAS (and any other) applications. Enormous amounts of materials were written on what monolithic systems are, their shortcomings, and how to decompose them into small, isolated units of computation power, called micro-services.
What should we do though, with the code that stays monolithic? the one that’ll take us years to decompose and decommission. Should we wait for it to rot? Or to make small incremental changes to try and save it even though this seems like a futile effort or sunken cost?
This will be about one such system, and to be more precise — This will be about the alerting layer of our monolith, and how we managed to distribute and “micro-service” it, de-facto reducing on-call fatigue, and routing alerts more effectively.
The Degradation of Our Oncall Rotation
To set the grounds, I’ll need to first explain the history of our on-call rotation: We had one, daily on-call rotation, that all developers participated in.
It worked very well for us for years, while the organization was small and most developers knew most of the codebase. At that time, the on-call rotation was just another opportunity to further learn about the system — since we had only one repo, and the domain knowledge was quite small and limited.
With time, our headcount grew, and with it — the scale, number, and complexity of our systems. We started to adopt the microservice approach to support our growth, and mitigate velocity and many other known issues of monolithic systems.
This amazing movement towards small, isolated, and explainable pieces of software though — hit us hard in the soft stomach of our on-call — shifters who no longer were familiar with the systems, and with the growth — it became worse! shifters were getting alerts on systems they never heard of nor contributed to its codebase.
Our on-call became glorified “NOC” that was routing alerts to the relevant teams.
What a Monolithic Alert Is? Why We Had It? and Why It Hurts Now?
The worst part of it all is that even within our monolithic codebase we had a huge amount of services we generally implemented a mono-repo.
In our single-on call days, with a limited number of services, we’ve created a reusable component in our monolithic codebase, a class called HandleRescue — it receives an exception and logs it with all relevant information, and reports the error to a NewRelic metric called rescues_total.
With this small design, we were able to onboard many services, use cases, and code flows of our monolith to be covered by our alerting mechanism, supporting our enormous growth safely.
Just three years later, this alert became the worst contributor to our alert fatigue! Anyone using it intentionally or unintentionally in any legacy or new flow to catch exceptions, in fact, was increasing the probability of an alert being triggered — And chances are, the shifter will have zero context to the alert, and how to mitigate it.
And since this alert was being used in many critical places in our systems — the alert thresholds were set quite low, causing a lot of noisy, self/fast resolving alerts caused by momentarily spikes and hiccups.
Technical Solution
Firstly — what’s our goal? We want the alerts to be routed to the relevant teams, and not to be caught by our “NOC” shift — only the person capable of fixing the issue should be alerted, all others are redundant nuances.
Secondly — we want to do this with minimal interruption and changes in the existing codebase. We want an easy win!
The solution to be honest — was quite simple. We’d like the rescues_total metric to include who’s the owner of the code originating the alert, in our case — since our k8s cluster namespaces are the teams, and our mono-repo deploys each service to its team’s namespace — we just made the namespace name available as an environment variable for the application and added it as a field to the metric.
After that — we’ve added a Pageduty RuleSet and integrated the alert to it. To start it just triggered the existing “NOC” Service, and shortly after we’ve added routing rules by namespace -> team.
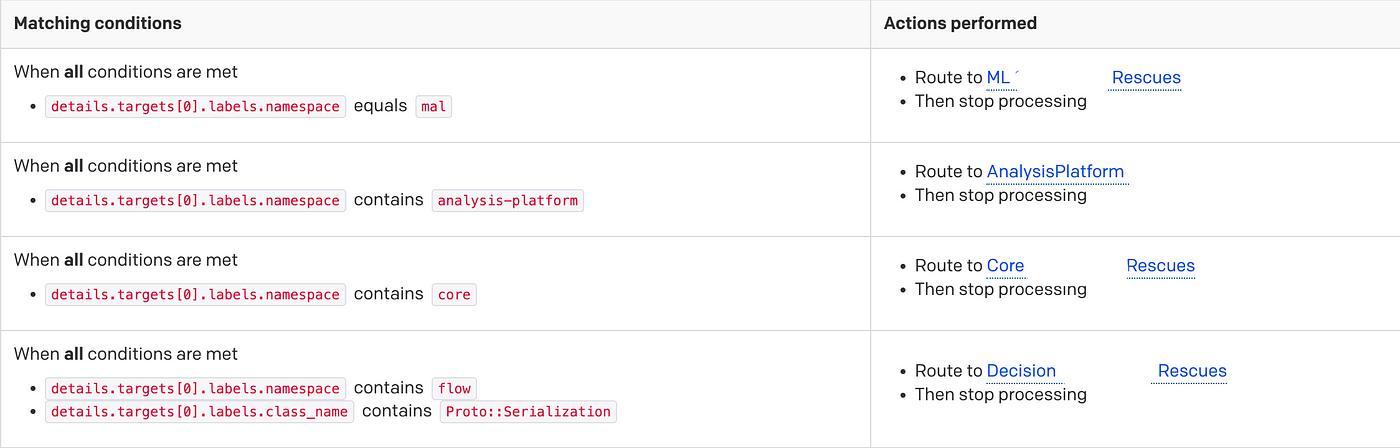
Alert routing RuleSet
This solved about 90% of the issues.
We were left with such services that are being hosted in one team’s namespace, and executed code owned by many — such as our asynchronous execution platform.
All alerts originating from this service were still routed to the “NOC”. On the next day though — each one was investigated, and one of the teams claimed (or was forced to take) responsibility for it. Then relevant specific routing rules were added.

Routing rules for the execution platform
About two months later — almost no alerts were getting to the “NOC”, and all that still was — it was the first time we’re seeing them since starting the process, and they were handled on the following day.
Communicating the change
Another challenge of this change surprisingly enough was getting our dev-org on board.
Devs were used to “NOC” getting the alert, some of the times it was auto resolved (this is a whole different issue not covered here), in other times the “NOC” shifter was capable to mitigate an issue even outside their domain, people were rightfully afraid that they’ll be flooded with pages (although in reality most of those issues would have been escalated to them anyhow).
For me though — it was all about ownership! Teams should own their production systems from top to bottom, all the time. We shouldn’t need a “NOC”.
We suspected one of the reasons those alerts are so noisy is that the one that’s being paged, is not the one that can fix the issue e2e on the next day — it was usually in a different’s teams domain.
So months before the actual change we started communicating the change, and how it’s gonna be made and left enough time for concerns to be heard and addressed. We shared a number of incidents and reassignments — proving the “NOC” was generally incapable of mitigating the issue, and it was escalating back to the teams anyhow.
We got the team leads on board, getting them to “champion” our change within their teams.
Bottom Line and Lessons Learned
Life is better now! Ownership is a good thing.
It was a slow and methodical process — although no single change was difficult or technically challenging, this change had the potential to impact people’s personal time, so we’ve addressed it with the utmost caution!
In my opinion, what made this change successful is:
- Good enough solution — our solution wasn’t perfect! It solved easily and fast 80% of the use cases, and we’ve manually tweaked and solved the remaining 20%.
- Communication is everything — we’ve started by communicating the change long before any line of code was written, we heard people’s concerns and adjusted our course of action.
By doing this, people got on board, and eventually even championed this change.
As always, waiting for your thoughts on Twitter @cherkaskyb.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK