

dubbo是如何实现可扩展的?(二) - 水木竹水
source link: https://www.cnblogs.com/shuimuzhushui/p/16320779.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
牛逼的框架,看似复杂难懂,思路其实很清晰。---me
上篇文章,在整体扩展思路上进行了源码分析,比较粗糙,现在就某些点再详细梳理下。
dubbo SPi的扩展,基于一类、三注解。
- 一类是ExtensionLoader类
- 三注解是@SPI、@Adaptive、@Activate
本文总结dubbo是如何使用ExtensionLoader实现扩展的,详细看看它是怎么设计的,为何这样设计?
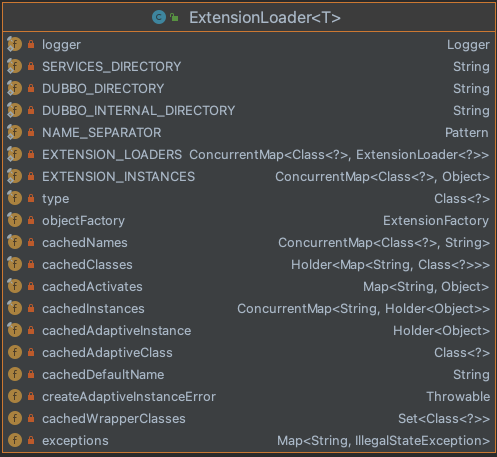
1. ExtensionLoader属性
首先是ExtensionLoader包含的属性,如下。
主要包含常量定义(如dubbo SPi路径META-INF/services/等)、加载的类型type、一系列缓存容器。
2. dubbo是如何加载SPI扩展类的呢?是一次性把所有的扩展都读到内存中吗?
当然不是,dubbo不是一次性把所有的SPI扩展文件都加载。而是根据类型,即type,进行加载。
可以看到上图中有两个关键字段,如下
private static final ConcurrentMap<Class<?>, ExtensionLoader<?>> EXTENSION_LOADERS = new ConcurrentHashMap<>(); private final Class<?> type;
其中 EXTENSION_LOADERS 是一个全局 扩展加载器 的容器,key为扩展接口,即type类型的SPI接口;value为接口对应的ExtensionLoader实例。
在上篇文章中说到,dubbo加载SPI与JDK加载SPI类似,读取指定路径文件中的定义。加载路径如下:
Map<String, Class<?>> loadExtensionClasses()
void loadDirectory(Map<String, Class<?>> extensionClasses, String dir, String type, boolean extensionLoaderClassLoaderFirst)
void loadResource(Map<String, Class<?>> extensionClasses, ClassLoader classLoader, java.net.URL resourceURL)
void loadClass(Map<String, Class<?>> extensionClasses, java.net.URL resourceURL, Class<?> clazz, String name)
在第二步loadDirectory时,传入路径和type(接口的全限定名),在方法内部拼出SPI路径,如下:
private void loadDirectory(Map<String, Class<?>> extensionClasses, String dir, String type, boolean extensionLoaderClassLoaderFirst) {
String fileName = dir + type;
.......
}
所以,得到的结论是:
- 每个类型对应一个ExtensionLoader加载器;
- 加载器加载扩展实现类时,只读取type对应的实现类。
3. 为何要设计自适应类?带来了什么好处?
dubbo官网这样解释:“在 Dubbo 中,很多拓展都是通过 SPI 机制进行加载的,比如 Protocol、Cluster、LoadBalance 等。有时,有些拓展并不想在框架启动阶段被加载,而是希望在拓展方法被调用时,根据运行时参数进行加载。这听起来有些矛盾。拓展未被加载,那么拓展方法就无法被调用(静态方法除外)。拓展方法未被调用,拓展就无法被加载。对于这个矛盾的问题,Dubbo 通过自适应拓展机制很好的解决了。自适应拓展机制的实现逻辑比较复杂,首先 Dubbo 会为拓展接口生成具有代理功能的代码。然后通过 javassist 或 jdk 编译这段代码,得到 Class 类。最后再通过反射创建代理类,整个过程比较复杂。”
dubbo扩展非常多,所有的底层关键接口都可以扩展,为了不在启动的时候加载所有类,而想在方法调用时加载,即懒汉方式。
所以引入了自适应扩展机制,它的好处:
- 封装所有扩展类,根据URL参数动态选择具体实现类
- 框架启动时,减少不必要扩展的加载损耗
自适应类分为两种,一种是动态生成的,一种是自定义。前者使用@Adaptive在方法上,后者使用该注解在类上。
区别就在于此,修饰在类上,表示该类为自适应类,无序dubbo再动态生成。
(1)自定义自适应类
这种方式的自适应类比较少,目前有ExtensionFactory、Compiler接口在使用。
AdaptiveExtensionFactory是ExtensionFactory的自适应类,它持有所有ExtensionFactory的实现,然后根据type和name遍历所有容器加载扩展类对象,上篇文章有介绍。
@Adaptive
public class AdaptiveExtensionFactory implements ExtensionFactory {
private final List<ExtensionFactory> factories;
public AdaptiveExtensionFactory() {
//持有ExtensionFactory所有接口实现类
ExtensionLoader<ExtensionFactory> loader = ExtensionLoader.getExtensionLoader(ExtensionFactory.class);
List<ExtensionFactory> list = new ArrayList<ExtensionFactory>();
for (String name : loader.getSupportedExtensions()) {
list.add(loader.getExtension(name));
}
factories = Collections.unmodifiableList(list);
}
@Override
public <T> T getExtension(Class<T> type, String name) {
for (ExtensionFactory factory : factories) {
T extension = factory.getExtension(type, name);
if (extension != null) {
return extension;
}
}
return null;
}
}
同理,AdaptiveCompiler是Compiler的自适应类,会根据name使用指定的编译器,默认情况使用JavassistCompiler。
@Adaptive
public class AdaptiveCompiler implements Compiler {
private static volatile String DEFAULT_COMPILER;
public static void setDefaultCompiler(String compiler) {
DEFAULT_COMPILER = compiler;
}
@Override
public Class<?> compile(String code, ClassLoader classLoader) {
Compiler compiler;
ExtensionLoader<Compiler> loader = ExtensionLoader.getExtensionLoader(Compiler.class);
String name = DEFAULT_COMPILER; // copy reference
if (name != null && name.length() > 0) {
compiler = loader.getExtension(name);
} else {
compiler = loader.getDefaultExtension();
}
return compiler.compile(code, classLoader);
}
}
(2)动态生成的自适应类
如上篇文章中,接口如下:
@SPI("human")
public interface HelloService {
String sayHello();
@Adaptive
String sayHello(URL url);
}
动态生成的自适应类,如下:
package com.lagou.service;
import org.apache.dubbo.common.extension.ExtensionLoader;
public class HelloService$Adaptive implements com.lagou.service.HelloService {
public java.lang.String sayHello() {
throw new UnsupportedOperationException("The method public abstract java.lang.String com.lagou.service.HelloService.sayHello() of interface com.lagou.service.HelloService is not adaptive method!");
}
public java.lang.String sayHello(org.apache.dubbo.common.URL arg0) {
if (arg0 == null) throw new IllegalArgumentException("url == null");
org.apache.dubbo.common.URL url = arg0;
String extName = url.getParameter("hello.service", "human");
if(extName == null) throw new IllegalStateException("Failed to get extension (com.lagou.service.HelloService) name from url (" + url.toString() + ") use keys([hello.service])");
com.lagou.service.HelloService extension = (com.lagou.service.HelloService)ExtensionLoader.getExtensionLoader(com.lagou.service.HelloService.class).getExtension(extName);
return extension.sayHello(arg0);
}
}
其中没有被@Adaptive修饰的方法,生成的方法只有一个异常语句。被修饰的方法会根据URL参数及ExtensionLoader扩展机制,动态获取使用的扩展实现类。
(3)dubbo是怎么区分是否要动态生成,还是直接使用定义好的自适应类呢?
这个涉及到ExtensionLoader中的属性cachedAdaptiveClass,其缓存了自定义的自适应类,在SPI扩展加载的时候进行识别并缓存。
如果没有自定义的自适应类,则不会用到该缓存。
涉及到自适应类的操作包含两个步骤:加载+使用
1)首先,加载。代码在loadClass方法中,如下:
private void loadClass(Map<String, Class<?>> extensionClasses, java.net.URL resourceURL, Class<?> clazz, String name) {
if (clazz.isAnnotationPresent(Adaptive.class)) {
cacheAdaptiveClass(clazz);
}
}
当类被Aaptive修饰时,则将加载的class缓存到cachedAdaptiveClass中,从源码中可以看到,只允许一个SPI接口具有一个自定义的自适应类。
private void cacheAdaptiveClass(Class<?> clazz) {
if (cachedAdaptiveClass == null) {
cachedAdaptiveClass = clazz;
} else if (!cachedAdaptiveClass.equals(clazz)) {
throw new IllegalStateException("More than 1 adaptive class found: "
+ cachedAdaptiveClass.getName()
+ ", " + clazz.getName());
}
}
2)其次是使用。获取自适应类的路径为:
public T getAdaptiveExtension()
private T createAdaptiveExtension()
private Class<?> getAdaptiveExtensionClass()
看看getAdaptiveExtensionClass的代码,你就明白原来这么简单。
private Class<?> getAdaptiveExtensionClass() {
getExtensionClasses();
if (cachedAdaptiveClass != null) {
return cachedAdaptiveClass;
}
return cachedAdaptiveClass = createAdaptiveExtensionClass();
}
该逻辑有三步:
- 加载对应type的SPI扩展类,包括自定义的自适应类,即上边描述的加载缓存过程
- 判断是否有自定义的自适应类,有则直接返回
- 没有,则动态生成
我们来看看是怎么动态生成的?源码写的也很清楚。
private Class<?> createAdaptiveExtensionClass() {
String code = new AdaptiveClassCodeGenerator(type, cachedDefaultName).generate();
ClassLoader classLoader = findClassLoader();
org.apache.dubbo.common.compiler.Compiler compiler = ExtensionLoader.getExtensionLoader(org.apache.dubbo.common.compiler.Compiler.class).getAdaptiveExtension();
return compiler.compile(code, classLoader);
}
总共四步:
- 生成自适应类的源代码code,通过字符串拼接,如package、import、class、method等,具体不在这展开
- 获取类加载器
- 获取编译器,此处会调用到Compiler的自定义的自适应类
- 对code进行编译,得到自适应类的class
4. 自动激活类是怎么回事?一般应用在什么地方?
自动激活,官网描述:“对于集合类扩展点,比如:Filter, InvokerListener, ExportListener, TelnetHandler, StatusChecker 等,可以同时加载多个实现,此时,可以用自动激活来简化配置”。
比如,过滤器Filter,可以使用@Activate,自动激活自定义的过滤器,以使与业务相关的控制能参与到dubbo的调用链中。如日志记录、方法执行时间等。
对ExtensionLoader来说,如何识别和使用自动激活类呢?
在ExtensionLoader中的cachedActivates属性,缓存了type 扩展类中被@Activate注解修饰的类信息。
Map<String, Object> cachedActivates = new ConcurrentHashMap<>();
key为定义在SPI文件中的key,Object为Activate注解的实例(注意这里不是存的被修饰类对应的实例,而是Activate注解本身)。
涉及到该缓存的操作有两处,一处是加载SPI文件时存入,一处是通过URL等信息判断是否需要激活对应的类。
(1)Activate类是如何识别并加载的?
在loadClass中,有一段涉及Activate的代码,如下:
private void loadClass(Map<String, Class<?>> extensionClasses, java.net.URL resourceURL, Class<?> clazz, String name) {
......
String[] names = NAME_SEPARATOR.split(name);
if (ArrayUtils.isNotEmpty(names)) {
//缓存具有Activate注解的扩展类
cacheActivateClass(clazz, names[0]);
}
......
}
其中name为SPi文件中定义的key,从下边源代码可以看出,cachedActivates map中存的是Activate实例。
private void cacheActivateClass(Class<?> clazz, String name) {
Activate activate = clazz.getAnnotation(Activate.class);
if (activate != null) {
cachedActivates.put(name, activate);
} else {
// support com.alibaba.dubbo.common.extension.Activate
com.alibaba.dubbo.common.extension.Activate oldActivate = clazz.getAnnotation(com.alibaba.dubbo.common.extension.Activate.class);
if (oldActivate != null) {
cachedActivates.put(name, oldActivate);
}
}
}
(2)Activate类又是如何使用的呢?
getActivateExtension方法是获取Activate类的具体实现(下方代码有省略),我们可以看到分为两步:
- 加载扩展类,并获取cacheActivates
- 根据URL参数与Activate声明的规则进行匹配
public List<T> getActivateExtension(URL url, String[] values, String group) {
List<T> exts = new ArrayList<>();
List<String> names = values == null ? new ArrayList<>(0) : Arrays.asList(values);
if (!names.contains(REMOVE_VALUE_PREFIX + DEFAULT_KEY)) {
//加载扩展类,获取到cachedActivates
getExtensionClasses();
//遍历cachedActivates,获取与URL、group等参数匹配的Activate类
for (Map.Entry<String, Object> entry : cachedActivates.entrySet()) {
String name = entry.getKey();
Object activate = entry.getValue();
String[] activateGroup, activateValue;
if (activate instanceof Activate) {
//Activate类声明的group
activateGroup = ((Activate) activate).group();
//Activate类声明的value
activateValue = ((Activate) activate).value();
} else {
continue;
}
//1.组匹配;2.value匹配
if (isMatchGroup(group, activateGroup)
&& !names.contains(name)
&& !names.contains(REMOVE_VALUE_PREFIX + name)
&& isActive(activateValue, url)) {
exts.add(getExtension(name));
}
}
exts.sort(ActivateComparator.COMPARATOR);
}
......
return exts;
}
以Filter为例,在ProtocolFilterWrapper.refer构造dubbo接口的invoker后,会对invoker增加过滤器,源码如下:
@Override
public <T> Invoker<T> refer(Class<T> type, URL url) throws RpcException {
if (UrlUtils.isRegistry(url)) {
return protocol.refer(type, url);
}
return buildInvokerChain(protocol.refer(type, url), REFERENCE_FILTER_KEY, CommonConstants.CONSUMER);
}
传给buildInvokerChain方法三个参数:
- 第一个是为dubbo接口生成的invoker
- 第二个是常量:reference.filter,对应URL中的某个key
- 第三个是常量:consumer,对应group
private static <T> Invoker<T> buildInvokerChain(final Invoker<T> invoker, String key, String group) {
Invoker<T> last = invoker;
List<Filter> filters = ExtensionLoader.getExtensionLoader(Filter.class).getActivateExtension(invoker.getUrl(), key, group);
if (!filters.isEmpty()) {
for (int i = filters.size() - 1; i >= 0; i--) {
final Filter filter = filters.get(i);
final Invoker<T> next = last;
last = new Invoker<T>() {
......
};
}
}
return last;
}
buildInvokerChain方法,构建过滤器链的逻辑比较简单:
- dubbo接口的invoker在过滤器链表的最后,即在执行的时候,最后执行实际接口调用
- 加载Filter对应的与group等参数匹配的自动激活类
- 构建过滤器链
(3)举个例子
比如我们自定义一个过滤器
@Activate(group = {CommonConstants.CONSUMER,CommonConstants.PROVIDER})
public class DubboInvokeTimeFilter implements Filter {
@Override
public Result invoke(Invoker<?> invoker, Invocation invocation) throws RpcException {
long startTime = System.currentTimeMillis();
try {
// 执行方法
return invoker.invoke(invocation);
} finally {
System.out.println("invoke time:"+(System.currentTimeMillis()-startTime) + "毫秒");
}
}
}
在META- INF.dubbo中增加org.apache.dubbo.rpc.Filter文件,内容如下:
timeFilter=com.lagou.filter.DubboInvokeTimeFilter
5. dubbo的包装器类是什么,有何用处?
dubbo中包装器是SPI扩展类的一种,准确的说是一个代理类,实现了对扩展类的AOP。
- 实现SPI接口
- 持有SPI接口的对象
如上文中的ProtocolFilterWrapper,就是protocol接口对应的一个包装器
public class ProtocolFilterWrapper implements Protocol {
private final Protocol protocol;
public ProtocolFilterWrapper(Protocol protocol) {
if (protocol == null) {
throw new IllegalArgumentException("protocol == null");
}
this.protocol = protocol;
}
......
@Override
public <T> Exporter<T> export(Invoker<T> invoker) throws RpcException {
if (UrlUtils.isRegistry(invoker.getUrl())) {
return protocol.export(invoker);
}
return protocol.export(buildInvokerChain(invoker, SERVICE_FILTER_KEY, CommonConstants.PROVIDER));
}
@Override
public <T> Invoker<T> refer(Class<T> type, URL url) throws RpcException {
if (UrlUtils.isRegistry(url)) {
return protocol.refer(type, url);
}
return buildInvokerChain(protocol.refer(type, url), REFERENCE_FILTER_KEY, CommonConstants.CONSUMER);
}
......
}
并且,该类也是定义在dubbo-rpc模块下的SPI org.apache.dubbo.rpc.Protocol文件中,如下:
filter=org.apache.dubbo.rpc.protocol.ProtocolFilterWrapper listener=org.apache.dubbo.rpc.protocol.ProtocolListenerWrapper mock=org.apache.dubbo.rpc.support.MockProtocol
在通过某Protocol实现类创建对象时,会自动为该对象封装该包装器。这样也就实现了对invoker的过滤拦截。
(1)dubbo是如何实现包装器类的识别和加载的呢?
要从ExtensionLoader的cachedWrapperClasses属性说起,该属性缓存了包装器类。
private Set<Class<?>> cachedWrapperClasses;
加载扩展类时,loadClass方法中会对class进行判断,如下:
private void loadClass(Map<String, Class<?>> extensionClasses, java.net.URL resourceURL, Class<?> clazz, String name) {
if (isWrapperClass(clazz)) {
cacheWrapperClass(clazz);
}
}
- 判断是否为包装器类
- 缓存包装器类
看isWrapperClass方法,调用的是Class获取构造函数的方法,如果不存在具有type类型参数的构造函数,则抛异常,通过拦截返回false。
private boolean isWrapperClass(Class<?> clazz) {
try {
clazz.getConstructor(type);
return true;
} catch (NoSuchMethodException e) {
return false;
}
}
缓存包装器类,代码很简单
private void cacheWrapperClass(Class<?> clazz) {
if (cachedWrapperClasses == null) {
cachedWrapperClasses = new ConcurrentHashSet<>();
}
cachedWrapperClasses.add(clazz);
}
(2)dubbo是如何对某实例进行包装的呢?
通过例子来说明,extensionLoader.getExtension(extension) 这句代码是根据扩展名获取对应的扩展类实例的,包装器就在这个过程中把原来的实例进行封装代理了。
public static void main(String[] args) {
// 获取扩展加载器
ExtensionLoader<HelloService> extensionLoader = ExtensionLoader.getExtensionLoader(HelloService.class);
// 遍历所有的支持的扩展点 META-INF.dubbo
Set<String> extensions = extensionLoader.getSupportedExtensions();
for (String extension : extensions){
String result = extensionLoader.getExtension(extension).sayHello();
System.out.println(result);
}
}
定义HelloWrapper类:
public class HelloWrapper implements HelloService {
private HelloService helloService;
public HelloWrapper(HelloService helloService) {
this.helloService = helloService;
}
@Override
public String sayHello() {
System.out.println("sayHello------>");
return helloService.sayHello();
}
@Override
public String sayHello(URL url) {
System.out.println("sayHello------>url");
return helloService.sayHello(url);
}
}
测试输出:
sayHello------>url wang url
dubbo如何对实例进行封装的呢?
核心逻辑在createExtension方法中,即根据传入的name创建扩展类实例的方法中。
private T createExtension(String name) {
Class<?> clazz = getExtensionClasses().get(name);
if (clazz == null) {
throw findException(name);
}
try {
T instance = (T) EXTENSION_INSTANCES.get(clazz);
if (instance == null) {
EXTENSION_INSTANCES.putIfAbsent(clazz, clazz.newInstance());
instance = (T) EXTENSION_INSTANCES.get(clazz);
}
injectExtension(instance);
//wrapper
Set<Class<?>> wrapperClasses = cachedWrapperClasses;
if (CollectionUtils.isNotEmpty(wrapperClasses)) {
for (Class<?> wrapperClass : wrapperClasses) {
//包装类的创建
instance = injectExtension((T) wrapperClass.getConstructor(type).newInstance(instance));
}
}
initExtension(instance);
return instance;
} catch (Throwable t) {
throw new IllegalStateException("Extension instance (name: " + name + ", class: " +
type + ") couldn't be instantiated: " + t.getMessage(), t);
}
}
从代码可以看出分为两步:
- getExtensionClasses方法加载扩展类,存到cachedWrapperClasses中
- 遍历cachedWrapperClasses,通过构造器实例化包装器,同时还为包装类进行依赖注入。(无论多少wrapper,都会一层一层进行封装)
这样返回给使用者的扩展实例,即为经过层层封装的扩展类。
- ExtensionLoader是实现dubbo可扩展的核心类,为各扩展点提供框架层面的支持,
- ExtensionLoader的逻辑看着复杂,其实思路比较简单,第一是扩展点加载,第二是创建指定的扩展点实例
- 从代码分析,可以看出该类包含了一系列缓存容器,这些缓存在扩展点加载的时候进行识别和存储
- 在扩展点实例创建时,会通过自适应类动态找到目标扩展;将自动激活类应用到扩展实例或dubbo的核心invoker上;并将实例封装到wrapper类中
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK