

现代编程语言需要泛型
source link: https://www.fly63.com/article/detial/11583
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
扫一扫分享
几周前,我写了一篇关于编程语言 Hare 及其缺少泛型数据结构的文章。如今,我不想再讨论这个话题了,我想讨论一些更“泛型”的东西。在我看来,任何以高性能为目标的现代编程语言都应该支持某种形式的泛型,不支持泛型是一个重大错误,也是导致复杂性增加和性能损失的一大原因。与一次性实现相比,泛型数据结构得到了更多的优化,我已经在前一篇文章中谈到了这一点。
另外,如果不支持泛型,就会在优化方面面临巨大的障碍。你根本就无法构建某些辅助程序。举个例子,我们来谈谈我最关心的一个话题——排序。处理排序数据是数据库的一个重要任务,其他的东西都是以它为基础。我们来看看如何使用几种编程语言 (使用它们的定义) 对数据 (在内存中) 进行排序。
void qsort (void *array, size_t count, size_t size, comparison_fn_t compare);
int comparison_fn_t (const void *, const void *);
template <class RandomAccessIterator>
void sort (RandomAccessIterator first, RandomAccessIterator last);
Java:
public static void sort(int [] a);
public static void sort(long[] a);
public static void sort(Object[] a);
public static void Sort<T> (T[] array);Hare:
type cmpfunc = fn(a: const *void , b: const *void ) int ;
fn sort([]void , size, *cmpfunc) void ;
Rust:
impl<T> [T] {
pub fn sort(&mut self)
where
T: Ord,
}
pub fn sort(
comptime T: type,
items: []T,
context: anytype,
comptime lessThan: fn (context: @TypeOf(context), lhs: T, rhs: T) bool,
) void
我只看方法声明,而不是实现。事实上,我现在并不关心它们是如何实现的。假设我想对一个整数数组排序,使用这些语言会有怎样的结果?
它们可以分为以下几类:
C 语言和 Hare 会要求你这么写:
int cmp_asc_int(const void *a, const void *b) {
return *(int*)a > *(int*)b;
}
qsort(array, len, sizeof(int), cmp_asc_int);
也就是说,我们传了一个函数指针给排序例程,在每次比较时会调用它。
C++、C#、Rust、Zig 会对例程进行优化。在调用时,看起来是这样的:
std::sort(array.begin(), array.end());其原理是编译器能够针对调用发出(emit)代码。与每次调用都必须执行一次函数不同,比较操作通常是内联的,并且完全消除了调用成本。
Java 是这些语言当中唯一采用了不同方法的。它没有在编译时使用泛型,而是根据运行时类型将代码分派给优化的例程。当然,这意味着程序员必须多次编写相同的排序代码。
需要注意的是,这并不是什么新奇的东西。在 Go 语言增加泛型支持时就有过相关的讨论,从基准测试可以看出,泛型版本有了 20% 的性能提升。这是因为避免了调用开销,并为编译器提供了更多的优化机会。
我们可以看到,一个相对简单的决定 (让语言支持泛型) 是如何对性能产生巨大影响的。
相反的观点认为,我们总是可以根据需要专门化代码,对吧?但事实并非如此。如果有泛型,你就可以免费获得这种行为,但如果没有,就不是这么回事了。
我以开发数据库为生,我们通常会在汇编级别分析我们排序代码的性能。我相信,几乎每个数据库开发人员都会这么做。排序性能对数据库的一切行为来说都是非常关键的。我偶然看到一篇关于 Postgres 性能优化的文章,其中有一个有趣的话题讨论的就是这个问题。他们将排序的实现从使用函数指针改为直接调用。你可以在这里看到提交的代码。下面是代码截图:
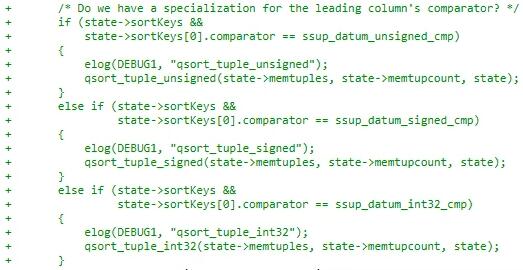
Postgres 已经 25 岁了,而这也是 C 语言相对于 C++ 的一个众所周知的弱点。Postgres 进行了很多排序调用,而这是一个很容易实现性能优化的地方。
至于优化效果,从这篇博文可以看出,优化让整体性能提高了 4% 到 6%。对于那些特定的例程来说,效果是相当惊人的。
对于一个拥有 25 年历史的代码库来说,一个相对简单的变更就可以带来大约 6% 的性能提升,这样的场景是非常少见的。
但是,我为什么要用这种方式说出来呢?
因为当我读到这篇博文时,它提及的优化手段与之前关于泛型的讨论产生了强烈的共振。这是针对这个问题的一个很好的研究案例,因为如果语言 (对 Postgres 来说是 C 语言) 没有以任何有意义的方式提供泛型支持,优化就很难进行,而且代价巨大。
以性能为目标的现代编程语言在进行语言设计时应该重视这一点。如果不这么做,用户将不得不做一些类似于 Postgres 正在做的事情。正如我们刚才看到的,这类事情是不完美的。
没有泛型意味着用户不得不将性能束之高阁。
实际上,几乎所有关心高性能的现代编程语言都有泛型。我能想到的一个例外是 Java,这是因为它在添加泛型时选择了向后兼容。
我将本文作为上一篇关于泛型数据结构的文章的补充结论,我认为最终的结果是显而易见的。如果你想要高性能的系统,就应该选择一种能让你简洁地表达逻辑的编程语言,而泛型是实现这种简洁性的必要工具。
原文链接:https://ayende.com/blog/197282-B/modern-programming-languages-require-generics
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK