

浅谈微服务的发展以及可观测性
source link: https://www.51cto.com/article/709085.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
浅谈微服务的发展以及可观测性-51CTO.COM
作者 | 陈亦帅,中国移动云能力中心PaaS产品部
近年来,“云原生”频繁出现在人们的视野中。随着云原生成为下一代云计算的技术“内核”,业界正在从关注“云原生概念”转变到关注“云原生落地实践”。云原生技术发展势不可挡,依然会是未来云计算领域的热门话题。
我们知道,现代”云原生”是一套符合云计算发展趋势的应用设计理念方法论,其关键技术中包含了微服务架构、容器、容器化编排、服务网格等技术。那么当我们把大型系统拆解成一个个独立部署的模块,进行容器化部署,得益于此团队可以更加快速、持续、规模快的进行开发和交付系统。但事物都有两面性,我们从方案或者技术“好”的一面中“获利”的同时,必须同时规避解决“坏”的一面带来的风险和后果,其中比较大一项就是微服务化后系统复杂性的成倍上升而带来运维和问题排查难度陡增的巨大挑战。
01微服务架构演进历史
在真正进入微服务可观测性这个话题之前,我们有必要了解下微服务架构的演进历史。从整体上看,整体架构的演变过程大致经历了单体应用架构、垂直应用架构、分布式SOA架构、微服务架构的演变。我们以一个电商系统举例(以下图片均来自网上),主要比较下各个架构之间在运维方面的区别。
举例的电商系统大致分为三个主体模块:主体业务模块(用户管理、商品管理、订单管理)、内容管理模块(CMS管理)、系统管理模块(后台管理)。
单体应用架构
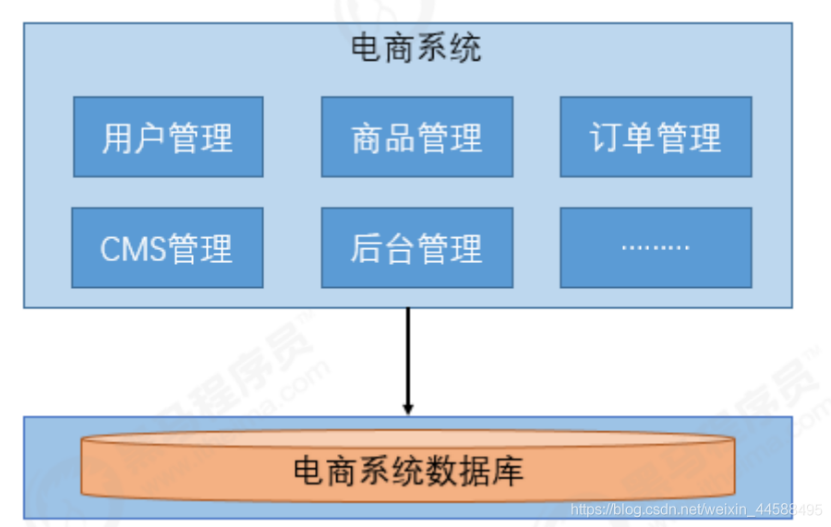
如图所示,单体应用架构把所有模块都揉进了一个应用内,所有模块均耦合在一起。系统的健康状况通常“所见即所得”(整体功能可用便表示应用处于健康状态),监测和告警指标通常由JVM的一些参数进行反馈,应用日志产生和收集比较统一集中,排查问题的链路通常比较短(大多问题可由日志直接定位到应用内的某行代码进而分析原因),维护和监控起来难度不大。但通常一个子模块的问题会导致整体项目出现不可用,无法水平扩展,过于臃肿无法适配大型项目和应用。之后便逐渐演变为垂直应用架构。
垂直应用架构
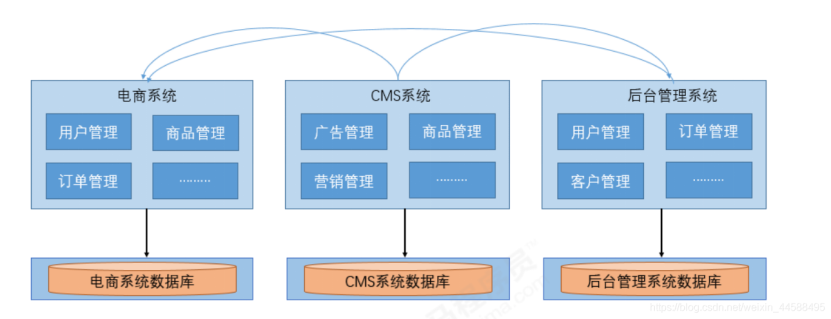
相比较于单体应用架构,我们对整体系统进行了拆分,优点是可以根据实际情况对某个子系统进行水平扩展,一个系统发生故障可以避免对其他系统产生影响。缺点是拆分后系统比较独立无法相互调用(不同于微服务,只是独立拆分)也导致了重复业务的开发,如图中箭头所示的订单管理、商品管理、用户管理部分,后期维护成本较高。运维方面,难度提升的地方主要在于日志的管理和问题发生点的增加,例如一个问题的发生可能同时由CMS和后台管理系统导致,需要同时解决两个系统的故障。但业务规模的扩大,会导致重复代码和重复修复工作的激增,我们需要将该部分的逻辑进行抽取,继而慢慢过渡到分布式SOA架构。
分布式SOA架构
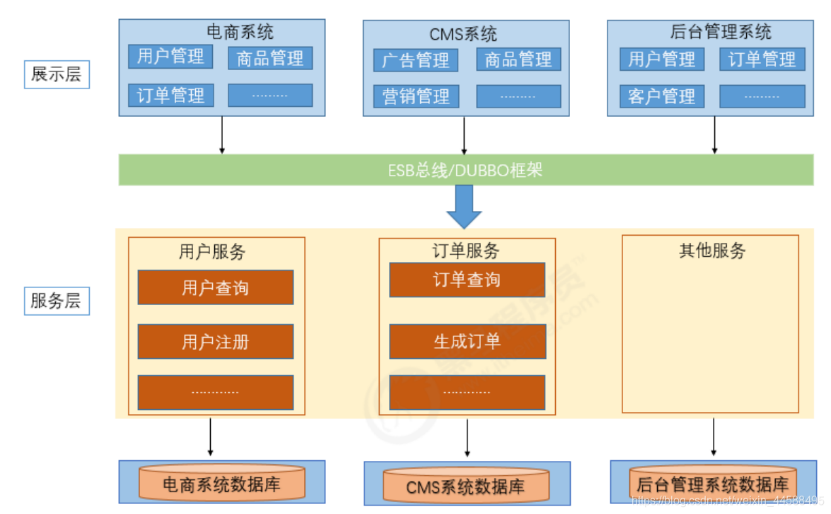
分布式SOA架构也可认为是微服务架构的雏形,其中展示层对应我们通常所说的消费者或者Controller层,负责控制页面操作需要调用服务层的哪些服务(例如:下单操作使用到用户、订单、商品三个服务,而这三个服务又是抽象在服务层独立存在的),而服务层是具体的业务逻辑实现供表现层调用,上图的服务层模块应该包括用户管理、商品管理、订单管理、CMS管理、后台管理等所有模块,并且基于SOA的分布式通常还会包含一个注册中心(例如:图中的ESB总线或者类似DUBBO这样的框架)。
作为微服务架构的雏形,在解决了水平扩展问题的同时,注册中心的加入既解决了服务之间的注册发现和调用,也使公共模块和逻辑服务得到了抽取独立。但同时也开始让运维监测压力有了比较大的增加,性能和告警关注的服务变多,同时还需要关注注册中心的健康,日志分布更加散乱,业务发生故障时,排查链路变得冗长,对于复杂业务问题我们通常需要同时获取从展示层、注册中心到服务层的日志,并分析其关系才能比较好的定位出问题,这无论对运维还是应用性能提升都是一个挑战。并且服务之间的依赖与调用关系复杂,服务提供方与调用方接口耦合,业务切分不够细的问题也让微服务架构登上舞台。
微服务架构
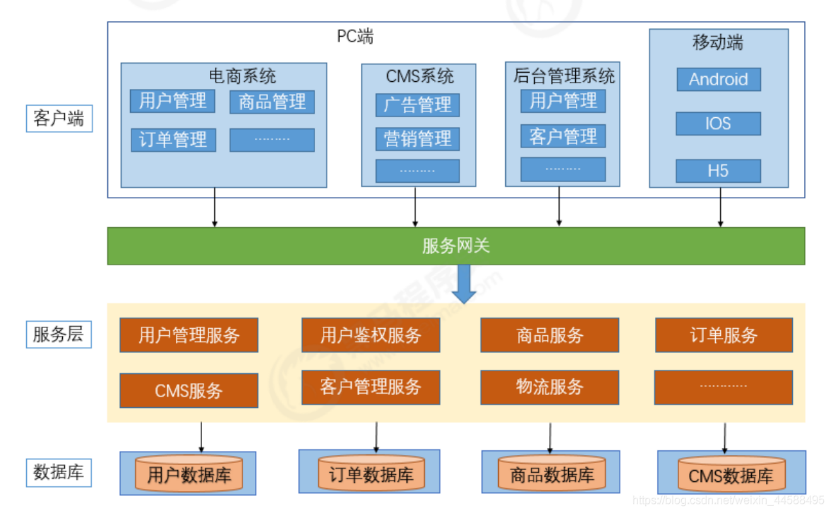
现在我们所属的微服务架构通常由一个网关以及各个功能独立的微小服务构成,服务之间的可以相互调用,它们的可用性可由容器和容器编排的能力提供。服务划分的更细、职责更加明确,服务之间可使用RPC、REST进行相互调用,同时为前端提供HTTP接口。
由于服务的彻底拆分,服务的开发可以分发给各个小团队进行独立开发、部署和升级。并且每个微服务可以根据业务实际运行情况进行水平扩容,但同时微服务过多,服务治理成本变得更高,同时还要考虑分布式事务、容错等技术。从运维方面看,服务日志变得更加分散,怎么对全局的微服务进行监控和告警难度更大了,最后出现业务问题进行排查时,链路变得非常冗长,若没有一个全局追踪id,只通过日志的时间戳,无论是业务性能优化还是故障排除都会变得十分困难。即业界不断在讨论研究的问题,微服务的可观测性。
02什么是微服务的可观测性
从上一节的架构的演变过程中,我们可以看出随着服务越拆越细,越拆越独立,运维的难度以及系统的复杂度都成倍的提升,我们不得不面对以下几个问题:
- 随着模块之间的调用关系由进程内函数的调用变为进程间通过网络的调用,如何检测和保证网络的可靠。
- 调用链路的时间越来越长,流量的走向变得越发不可控,如何高效的排查问题或者提升应用的性能。
- 现代微服务的实践和部署往往结合Kubernetes、Docker、Service Mesh等云原生技术,开发团队更加难感知其下的基础设施的状态了。
传统对于系统的监控,我们往往关注诸如CPU、内存、网络、应用接口的请求量、接口的响应量等,但这对于微服务系统来说,并不能帮助我们掌握整体系统的运行情况。这就像一条轮胎、一个水箱、一箱油,这些事物分开独立放置时我们能够比较简单的判定其状态,但当这些东西被组合进一个“系统”,例如一辆汽车后,如何在汽车运行过程中,观测到其状态,就变成了影响汽车稳定性的重要一环,这对微服务系统来说同样适用。
微服务的可观测性即是要解决数据流在客户端输入后,透明的知晓其在各个服务间进行采集、传输、存储的状态,进而解决预测系统运行过程中出现故障的问题。
为了保证这些数据流的状态被感知,业界普遍认为有几类数据可作为可观测性的支柱:Metrics、Logging、Tracing。
其中Metrics是在一段时间内组成单个逻辑测量、计数器或直方图的原子,例如,服务调用的QPS、响应时间、错误请求发生率,目的是为了创建集中式度量系统,侧重于技术指标的收集与观测;Logging用于记录离散的事件,例如,应用程序的调试信息或错误信息,目的是搭建集中式日志系统,侧重于统一采集、存储与检索各个微服务的日志;Tracing处理请求范围内的信息,例如,一次远程方法调用的执行过程和耗时,目的是形成分布式追踪系统,侧重于串联请求在微服务间的调用情况、继而进行追踪与APM分析。
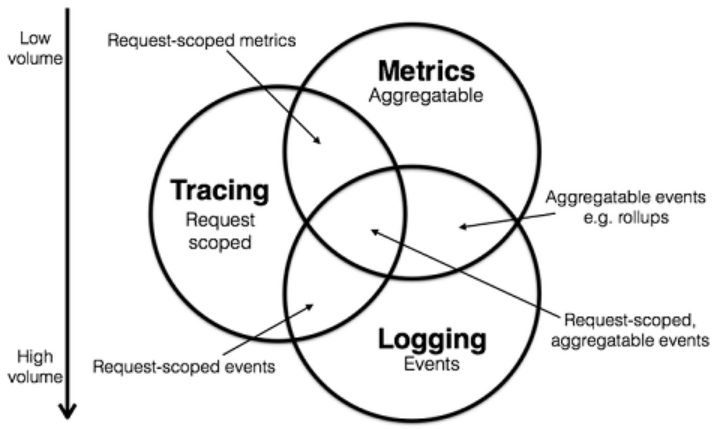
通过以上信息,我们可以对已有的系统进行分类。例如,ZipKin、Jaeger专注于Tracing领域,Prometheus专注于Metrics领域,ELK、Loki专注于Logging领域。但是各个系统也都在不断的集成其他领域的特性到自身系统中来,例如,Jaeger遵循的一些OpenTracing规范,但CNCF已经开始把OpenTracing和OpenCensus合并成 OpenTelemetry 项目,以后的会有更多即包含了一定Tracing能力同时又有Metrics的系统出现,Prometheus虽然一开始专注于指标的收集和管理,但也在开始集成一些Tracing的能力。
现在业界对于微服务可观测性的一种解决方案既是,首先使用loki + Grafana进行分布日志的统一收集与管理,使用Prometheus和Grafana对 Metrics 进行存储和展示,最后再使用诸如类似Jaeger的追踪系统做分布式追踪的存储和展示。基于此,我们可以大致获得如下的一个问题分析链路:
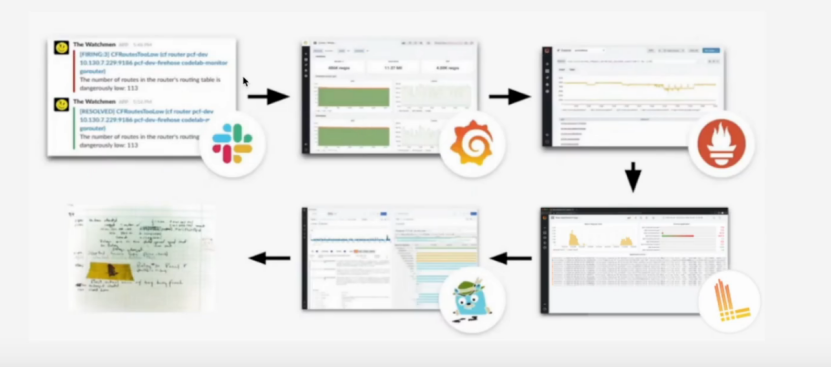
首先,我们通过Email或者某种方式收到一个告警信息,接着去Grafana的图表中看查看某一段时间的指标异常情况,再下钻就可以在Prometheus中查看到某一个异常指标的详细情况,就可以获得对应某个异常发生的时间或节点,根据时间和节点以及服务标签从Loki中捞取日志信息中的request id或者一个全局的trace id,然后再根据这个trace id去类似Jaeger这种满足OpenTelemetry 规范的系统中查找调用链,获得某个服务的异常或者性能响应详情,最终排除出问题记录issue。这是一个比较常规的微服务问题排查方法,虽然一定程度上解决了可观测性的问题,但是仍然比较冗长。业界也已经出现了类似exemplar这样的组件,能够串联各个割裂的组件,或者各个厂商也在尝试推出类似Erda Cloud这样的一站式解决方法,使上文提到的Logging、Tracing、Metrics不断的向中心圆靠拢。
微服务架构和云原生的发展使我们能够更加从容的面对大数据时代大型系统的开发,同时系统运维排查过程中问题链路追踪、应用日志的管理、故障的监控告警等也变得越发复杂,业界起初出现了针对各个问题的对应的独立解决方案,但慢慢也趋于集中提供能够串联和一站式的平台系统。微服务的可观测性问题一直都是困扰着整体应用稳定性的一环,在之后的文章中,我们也期待与大家分享更多相关技术细节和实战文章。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK