

基于ES的开源分布式SQL数据库,CrateDB适用于哪些场景? - 分布式 - dbaplus社群:围...
source link: https://dbaplus.cn/news-159-4502-1.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
基于ES的开源分布式SQL数据库,CrateDB适用于哪些场景?
本文根据许鹏老师在〖deeplus直播:开源分布式数据库CrateDB在携程的最佳实践〗线上分享演讲内容整理而成。(文末有回放的方式,不要错过)

今天的分享主要包含以下几个方面的内容:
-
CrateDB介绍
-
CrateDB在携程的实践
-
CrateDB在携程的优化
一、CrateDB介绍
1、CrateDB
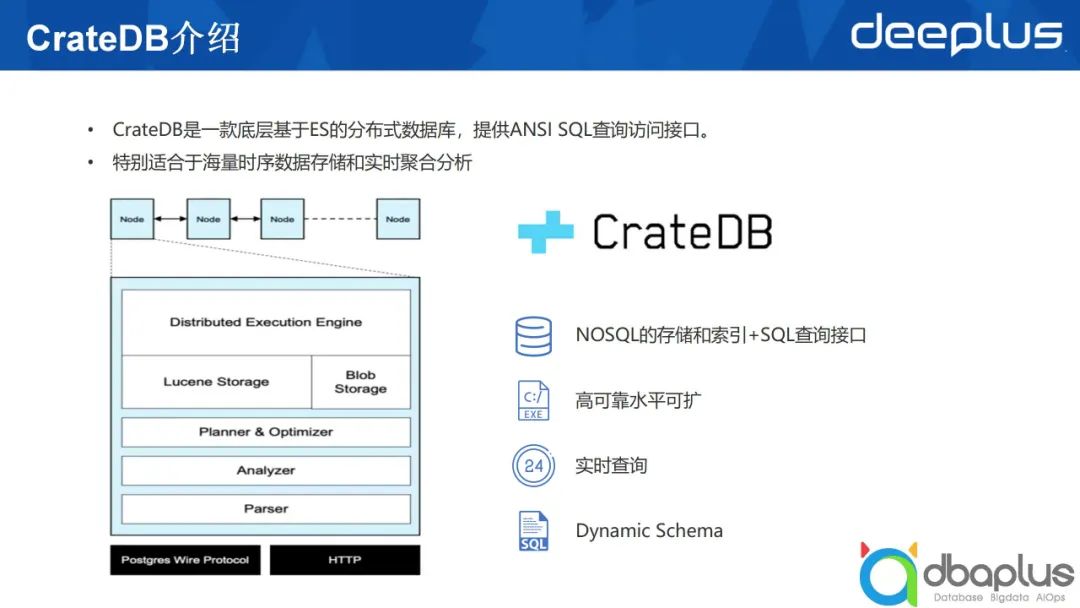
CrateDB是一款基于ElasticSearch的分布式数据库,它与ElasticSearch最大的区别是提供了ANSI SQL查询访问接口。ElasticSearch在6.X版本以后,也开始提供SQL的查询,但CrateDB与ElasticSearch相比,能够支持多索引之间的关联查询,针对某些聚合函数,它返回的是精确的查询结果,而ElasticSearch返回的是近似值。
2、CrateDB的特性
-
适用于海量时序数据存储
CrateDB适用于海量时序数据存储,需要频繁更改的数据使用CrateDB存储效果较差。因为CrateDB基于ElasticSearch,频繁的删改操作会使它的性能大大受损。
-
高可靠水平可扩
CrateDB继承了ElasticSearch设计中高可靠的优点,集群较方便实现扩容,对于一些点查询或复杂度中等的查询均能够较为实时地返回结果。
-
支持Dynamic Schema
CrateDB支持Dynamic Schema,其最新版本能够支持json数据格式,写入数据更加方便。
我认为CrateDB的初衷是用SQL的方式查询访问基于ElasticSearch存储的数据。基于这一概念,我们可以看到它大概的分层(如上图所示),从外部访问从下到上依次到达最终的存储,其最外一层提供了PostgresSQL兼容的访问协议和REST API的访问协议,接下来对语句进行解析,然后执行,获取存储在各个节点上的数据。
3、海量数据存储对比
因为类似技术较多,这里只对比几个典型的技术,CrateDB、ElasticSearch以及MongoDB,这三者都可以归类于Nosql。下文将从7个维度对三者进行对比。
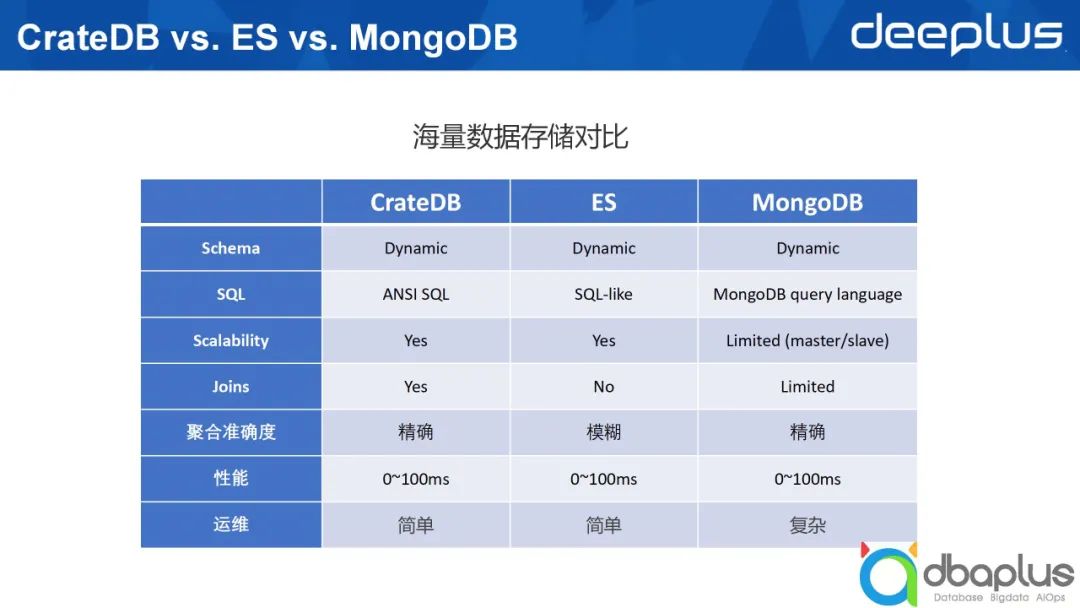
1)Schema支持类型
这三个数据库均支持Dynamic Schema。但在现实的生产环境下,我们推荐采用Struct Schema,因为Dynamic Schema可能会带来种种问题。
仅代表个人观点,并非适用于所有场景。
2)是否支持SQL访问
SQL诞生四十多年,已成为非常成熟的语言,具有极强的表达能力。同时SQL具有通用性,被大家普遍接受。CrateDB基于SQL的通用性不断发展,其支持ANSI SQL,并且采用了PostgreSQL协议。
ElasticSearch起初只支持类json格式的查询语法,之后开始提供针对单索引的一些SQL语句支持函数,并不断丰富。MongoDB据我所知并未直接支持SQL,如果写入SQL语句,需要通过第三方插件才能够被MongoDB识别,这在一定程度上会影响查询性能。
3)可扩展性
从可扩展性角度出发,CrateDB和ElasticSearch采用gossip协议组建集群,简单来说节点之间相应对等。在一个ElasticSearch集群中,节点可分Master、Coordinator,以及承载数据的Data,一个节点可以同时扮演三个不同的角色,因此它们是对等的。
MongoDB则不同,如果用它来构建一个分布式集群,最起码有三个不同的Host,分别是Config Server、Mongos以及Data,为了实现高可靠,一个分片还需要分成相应的Master或Slave。
综上所述,从可扩展角度来看,ElasticSearch和CrateDB更好。
4)对于关联分析的支持程度
CrateDB支持跨索引之间的关联分析,而ElasticSearch则使用一些变通的方式支持此类关联查询,这意味着在写入数据时需要做相应变更。MongoDB在4.X版本时不支持关联查询,之后的版本未及时关注,如描述有误,欢迎大家指正。
5)聚合准确度
CrateDB和MongoDB返回精确值,ElasticSearch则是返回近似值,虽然返回近似值执行速度快,但其计算的准确度会受到一定影响。
6)性能
在查询性能方面, CrateDB和ElasticSearch都能够较好地返回查询结果,上图中列出的耗时为100毫秒。对于较为简单的查询,100毫秒算是较高的消耗,事实上可以在更短的时间内返回结果。后文中会提到我们自己质量环境下的实际耗时。
7)运维
引入一项新技术后,其带来的运维复杂度十分关键。CrateDB和ElasticSearch相较于MongoDB运维复杂度更低。
4、CrateDB系统架构及节点类型
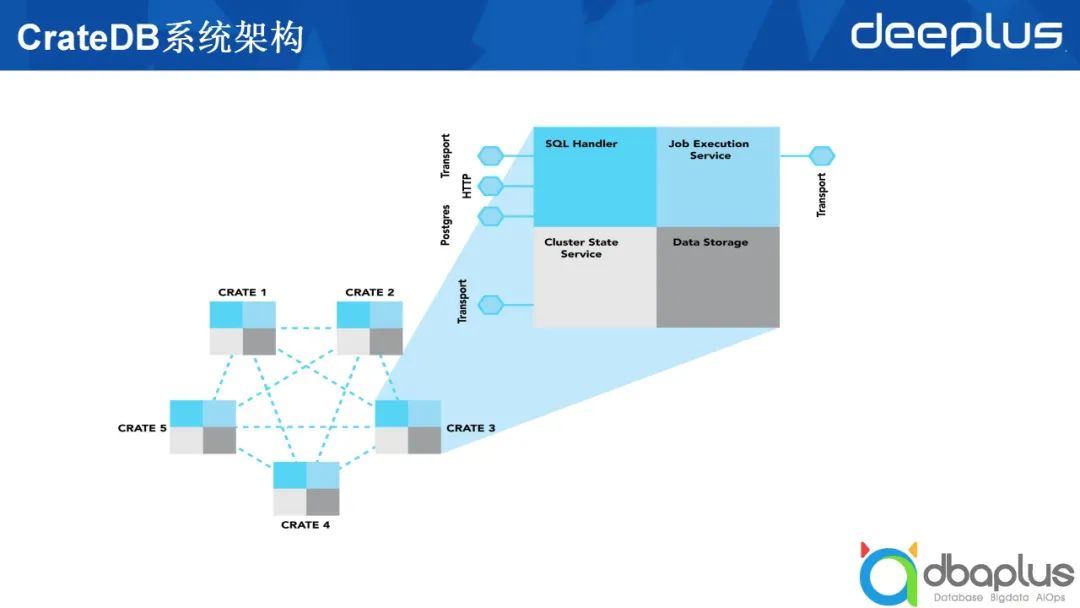
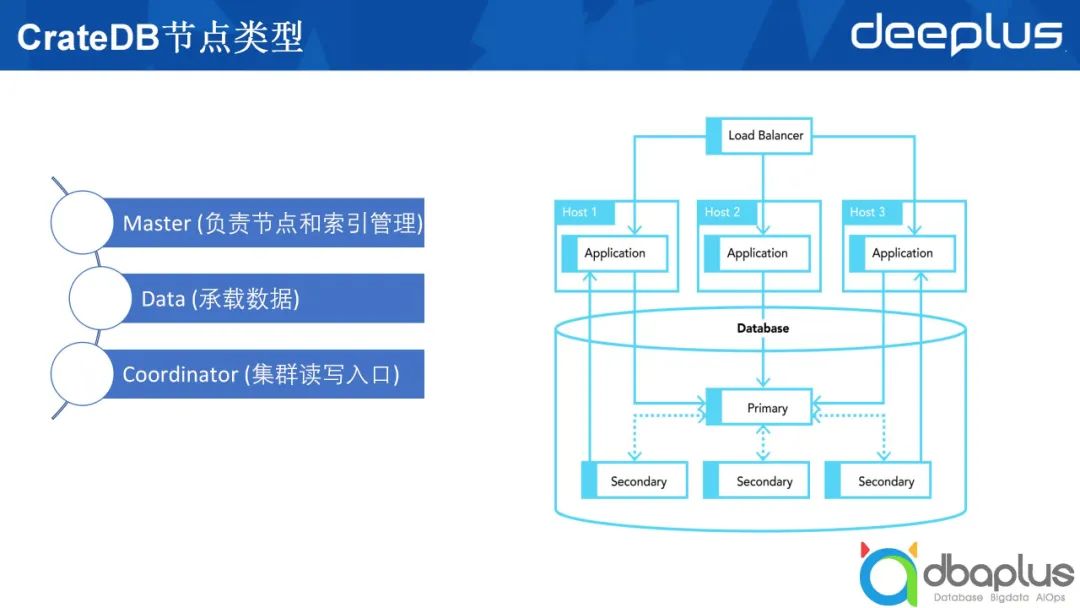
上文中提到在CrateDB和ElasticSearch中节点之间相互对等。以ElasticSearch举例,由5个节点构成的ElasticSearch集群中起码有两个不同的角色。
-
Master
该角色需要负责两个方面的工作,分别是管理节点和管理索引。节点加入集群,在集群中创建了多少个不同的索引,这些索引的分片分布在哪些机器上,这些信息都由 Master来管理。
-
数据节点
我们创建好的索引,数据最终要落到一个具体的ElasticSearch节点上,这些最终承载数据的就是数据节点。
上图右半部分所示为在生产上部署一个CrateDB或ElasticSearch集群。最上方的负载均衡部分可有可无。除上文提到的两种节点类型外,还有一种叫做Coordinator的节点类型,它既不承载具体的数据,也不扮演Master的角色,只接受外部的请求,并将外部请求路由到数据节点上做具体查询,然后在Coordinator节点做一些汇总,最后返回给应用程序。除此之外,ElasticSearch中可能还会有一个叫Ingest的节点类型,这里不进行过多阐述。
综上所述,一个CrateDB的表类似于一个ElasticSearch的索引,ElasticSearch中索引由多个不同的分片组成,每一个分片可能会落到某一个数据节点上。为了实现高可靠,一个分片又分成主分片和副本分片,即图中列出的Primary和Secondary。
5、CrateDB具体操作
1)表创建
这个操作和我们平时用PostgreSQL或MySQL创建一张表并无很大差别。
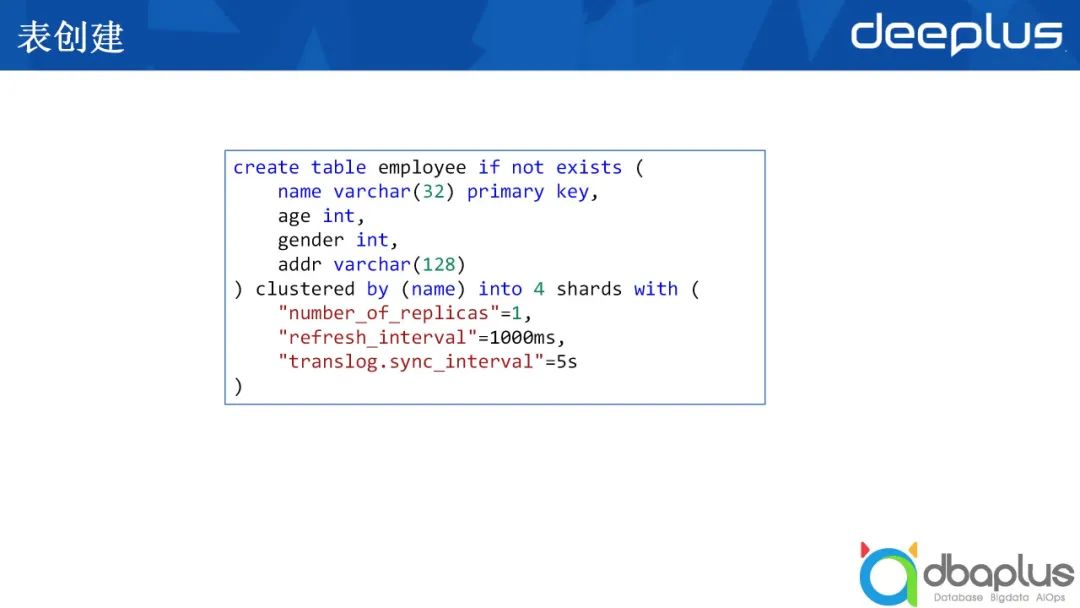
创建一张职工的表(如上图所示),其中包括姓名、年龄、性别以及住址。这张表根据姓名来进行哈希,哈希的结果分到4个不同的分片中,with后面跟着一些针对索引层面的配置,它的配置项多达几十项。我们最主要关注以下几点:
-
分片的副本数
如果只有主分片,replica数为0。如果在主分片之外,还有别的副本分片,增加相应的replica数即可。
-
refresh_interval
ElasticSearch进行刷新数据会从内存刷新到磁盘,不断刷新会降低性能。为了保证更多数据留在内存中,减少刷新的次数,我们可以调节刷新间隔,具体调整根据对数据的新鲜度要求而定。数据只有被刷新后才能被搜索到。
-
translog.sync_interval
ElasticSearch采用的是write ahead log的方式,这意味着有大量的translog。translog同样将数据从内存写到磁盘,这当中有一个sync的间隔,如果调高这一间隔,可能会加快写入速度,但也有可能带来容错方面的问题。
2)乐观并发控制
CrateDB是基于ElasticSearch的数据库,其在ElasticSearch基础上进行了叫做乐观并发控制的演变。我们将数据写入到某一张表时,有两个隐藏的列,一个是sequence_number,即这一列的版本号,另一个为primary_term,二者联合使用可以实现某一版本的数据只更新一次,避免频繁更新。
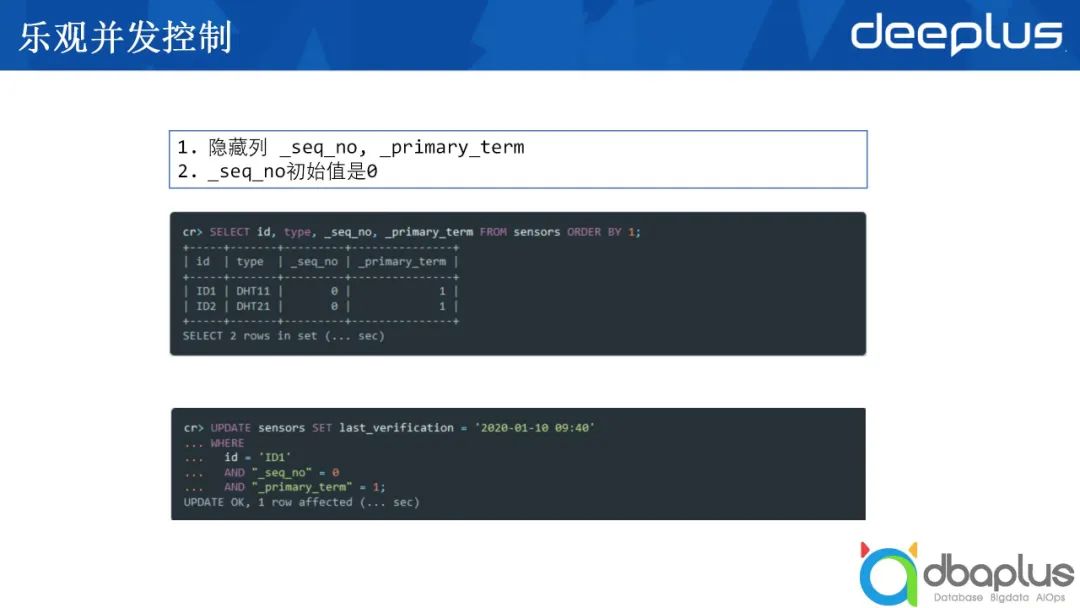
以上图中的语句为例,对sequence_number等于0进行更新,当这条语句执行成功后,它的sequence_number会自动跳到1,每更新一次,这个值就会递增。如果有两个不同的进程或两个不同的外部访问,试图来更新同一条语句,那么只有一条会被执行成功,这就做到了乐观并发控制。
3)Partitioned Table
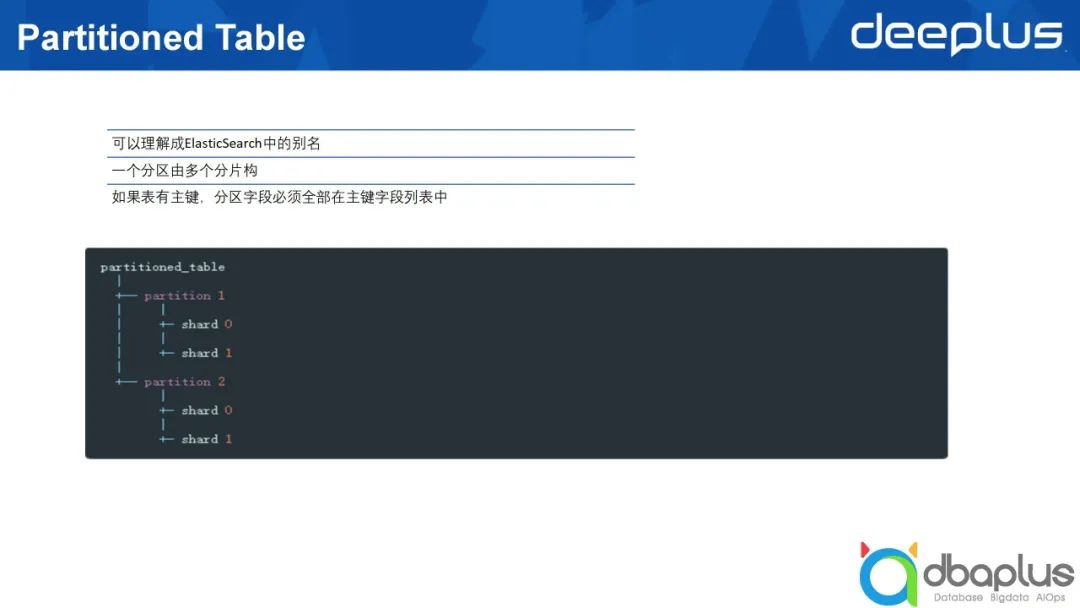
CrateDB与ElasticSearch不同,它引入了Partitioned Table的概念,即所谓的分区表。
上文中讲到一个表存在多个分片承载数据,即ElasticSearch的一个索引有多个不同的分片,对应到CrateDB中是分区,CrateDB中的分区可以与ElasticSearch中的别名相对应。
如果我们要查询或写入表的数据量达几十亿或上百亿,将这些表都放到同样一个索引当中,可能会导致查询与写入的速度变慢,我们其实可以把这些数据分成多个不同的分区。
在我们实际的生产中有这样一种情况,一些坐过飞机的用户可能希望查看自己的飞行足迹,如果将所有用户的历史数据都放在同一个索引中,经过查询最后在前端展现的话,速度可能会较慢,因为这一操作对接口的要求较高。
例如要求在50毫秒内返回结果,如果不把这些数据做分区的话,查询会很慢。此处的慢是99%line的情况,在此情况下,我们要达到满足性能指标,其中一个变通方法就是把它拆成多个不同的分区,每个uid进入后只需要到对应的分区表查询即可。
在做分区的时候有一点需要注意,如果表已经创建了组件,分区的字段必须都属于组件字段的列表,因为这个组件可以由一个列或多个列组成,也可能是一种复合的组件,分区的字段必须在组件的字段列表当中。
二、CrateDB在携程的实践
1、实时聚合分析
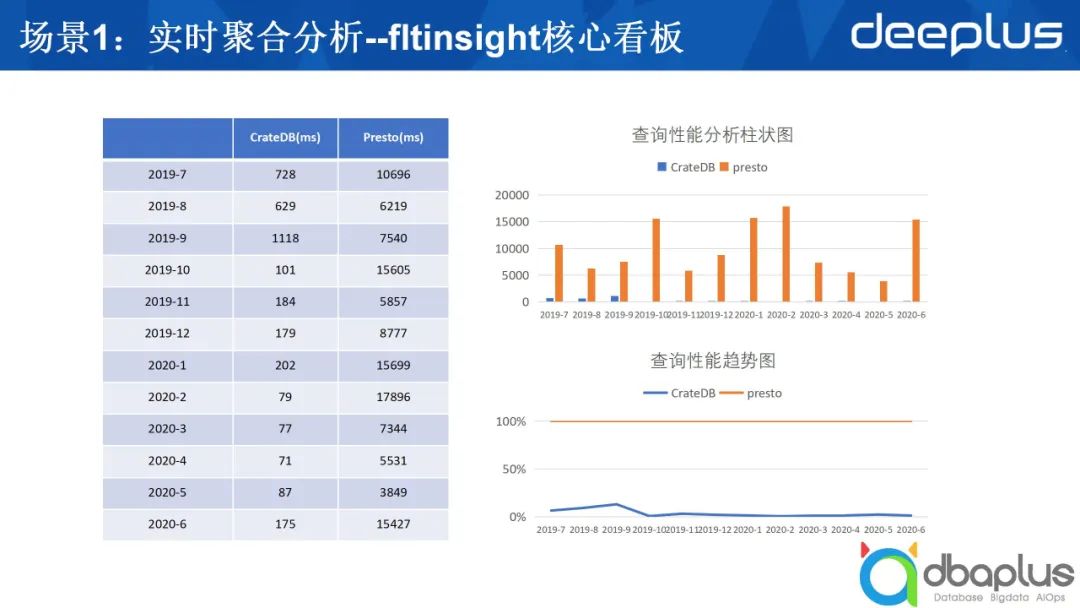
上图是我们使用CrateDB之后进行的比较,图中只比较了CrateDB和Presto,我们当时的场景如下。
我们有不少的表,每张表的数据量都有几千万条,有的甚至上亿条,需要对数据做比较复杂的聚合。原来是用Presto查询,因为它是一个看板,每次刷新的间隔延迟较大,为了解决这个问题,我们尝试了一些方法,后来发现用CrateDB效果较好,右侧是性能对比,收益十分明显。
1)具体分析场景
-
国内产品/业务/收益数据分析;
-
主要对常用产量收益(多维度)进行监控;
-
进行拆分下钻分析;
-
进行了sum、between、groupby、case when、left join、union all等操作。
在性能对比方面,采用CrateDB后,我们基本上能够在1~2秒之内返回结果。
2、海量数据存储以及实时查询
在我们实际的生产中有不少实时数据聚合分析的调用。
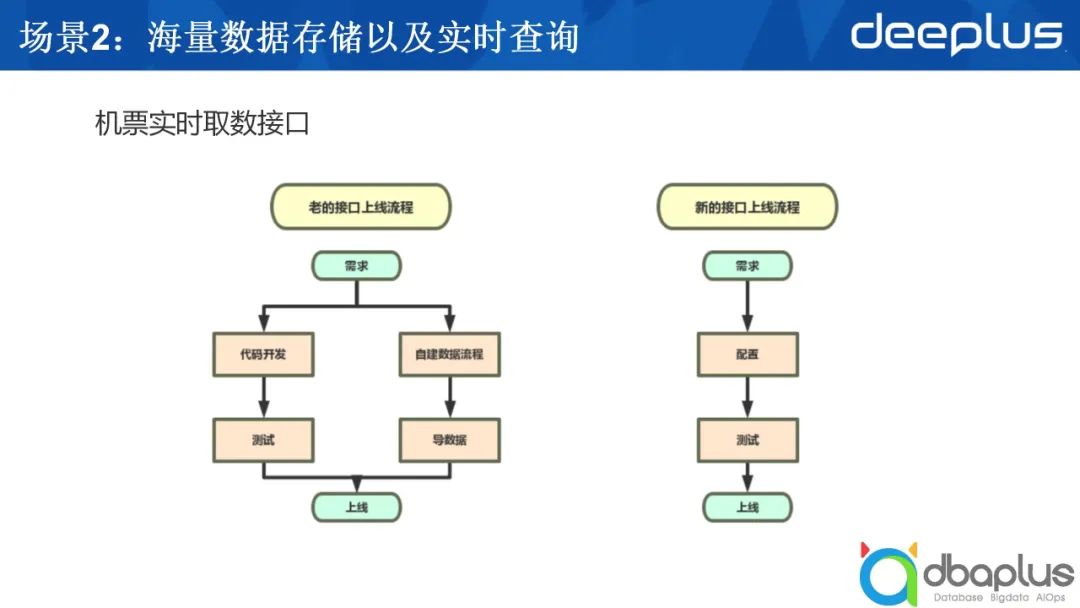
起初,我们是将数据放入Redis中,每收到一次取数请求,我们都会进行相应的代码开发,把取出的数据进行相应解析,处理之后返回给调用方。这个需求虽然不复杂,但是因为我们没有办法注入数据分析的逻辑,所以不得不进行代码工作。
引入CrateDB后,我们可以将分析工作采用SQL的方式来实现,对于那些用SQL分析不能完全解决掉的剩余部分,则联合一些Groovy脚本完成。
基于这样的理念,我们开发了一个模板,我们将SQL写入模板中,指定从哪个表中取数,如何分析,决定取完数后是否需要进行定制的后续处理,如果需要,则执行相应的Groovy的脚本,最后返回结果。这一套流程大大节省了开发的周期,提升了开发的效率。
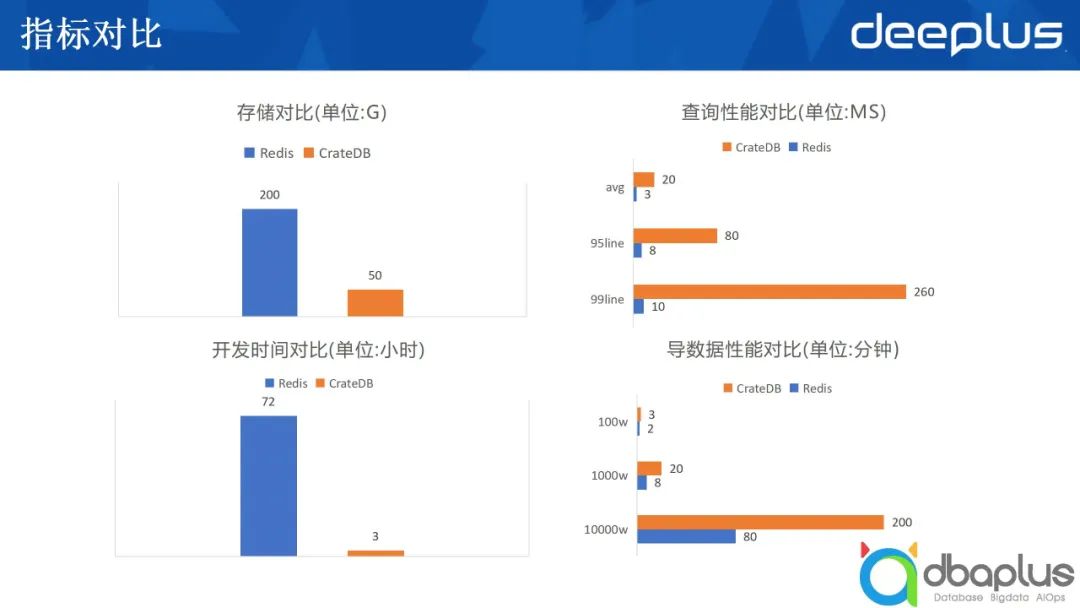
除开发周期对比外,存储方面的对比也十分显著。例如数据放入到Redis中,需要200g内存,用CrateDB来存,可能只需要50g,这不仅是数据量上的减少,同时意味着成本的大大缩减。在携程,有基于RocksDB的存储,它开发有Redis兼容协议,可以做到把数据存储到磁盘上,同时可以用Redis的接口访问。
我们将数据存入了磁盘,分别从均线、95%line、99%line三方面对比性能。均线方面还在可以忍受的范围内,当然CrateDB不可能比Redis更快。从上图中可以看出,除99.9%line的时候差距大一点,其他均在可接受的范围内。在数据导入耗时方面,我们运用Spark将数据导入CrateDB,两者差距不是特别大。
三、CrateDB在携程的优化
1、落地时的调优
当我们将CrateDB引入整体的技术方案中时,还需要进行一些调优。
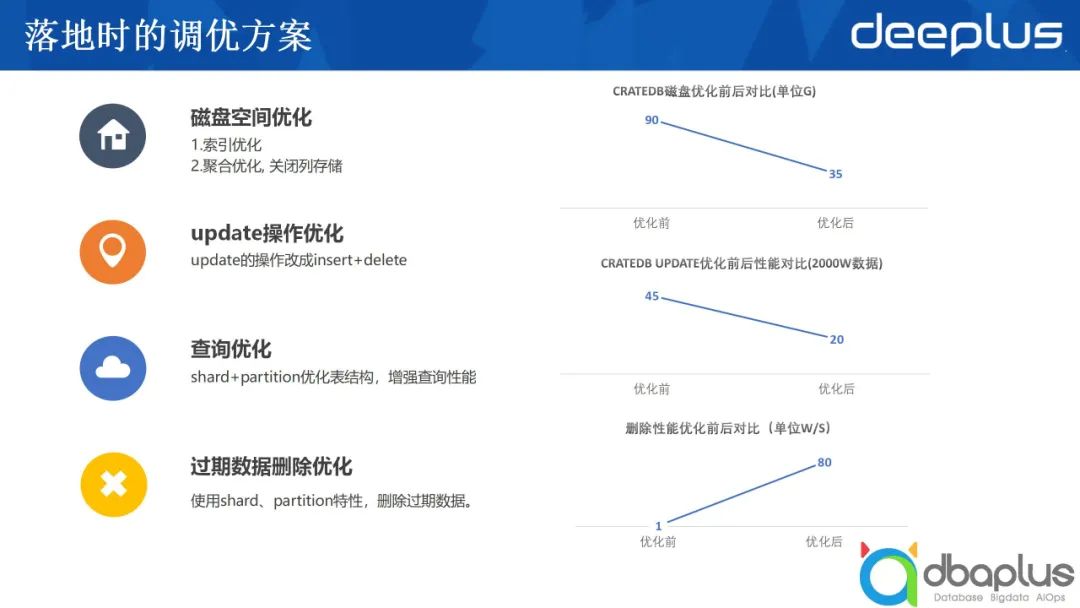
1)磁盘空间调优
为了避免大量磁盘空间的消耗,需要对索引层面进行优化。除此之外,还可以进行聚合优化,关闭列存储。
2)update操作优化
为了提升 update操作的性能,我们建议先insert,然后再删除已有的数据。为了达到目的,可以加上相应的版本号,每次只取最新版本的数据。对于在线更新的需求需要做转换,这也意味着采用CrateDB所能够支持的场景是有受限的,对于严格要求一致,或更新频繁的场景,CrateDB不是很好的选择。
3)查询优化
上文中提到采用分区加多个分片的方式优化表结构的存储,使得每一次查询只需要去查尽可能少的分区或分片,查的数据越少、越精准,时间消耗就越短。
4)过期数据删除优化
2、Spark数据导入
在数据导入CrateDB时,我们可能会用 Spark进行操作,此处向大家分享这一过程中的一个细节点。

此处用分区举例,如果有一个十几亿或几亿的用户ID,还有一些关联数据,要把它均匀地落到每个分区上,有一种比较简单的方法。我们把 uid(一串字符)进行相应的MD5,MD5之后,取前两位或后两位,就可以得到256个分片。256分片显然太多了,可以再除以一个系数,减少分片数,就可以让这些数据均匀分布,这样可以做到分片上承载的数据量是差不多的。
这样做的挑战是在写Spark程序时,怎样让每一个partition当中的数据都是落入同一个分片的内容,大家可能会想到repartition函数,但repetition是对某个字段进行哈希,并不能保证落到同一个 partition的数据,这时我们就需要去制定 partition。上图右侧写出了一些伪码,我们在spark中定义一个repartition,然后重载,显示这里可能会有多少个不同的分片。
假设我们刚才取前两位或取后两位,然后除以4得到64个分片的话,那么我们把传进来的数字跟64取模就对应到某一个具体的partition的位置。在Spark中有partitionBy,partitionBy只支持rdd算子,DataFrame中没有partitionBy的算子,所以我们需要先把DataFrame或者DataSet转成rdd,通过组成一个 key键值对的方式进行partitionBy操作。之后还需要将相应的rdd转换回DataFrame,这样就可以得到一个分布很均匀的 DataFrame,再将其写入CrateDB中,就能达到很快的写入速度。
3、运维自动化尝试
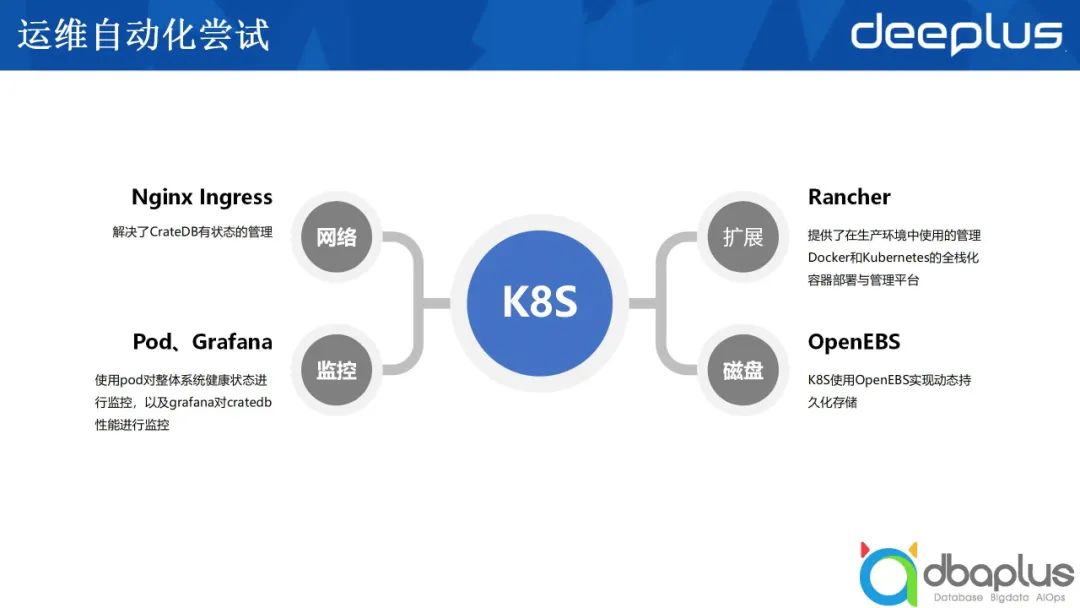
我当时是用 Rancher、OpenEBS,以及Nginx Ingress实现了一个在K8S上的CrateDB集群,这使得我们在云环境去部署CrateDB成为一种可能,部署到云上,即便是私有云上,也可以提高硬件使用率,这也是我的初衷。
4、CrateDB admin UI
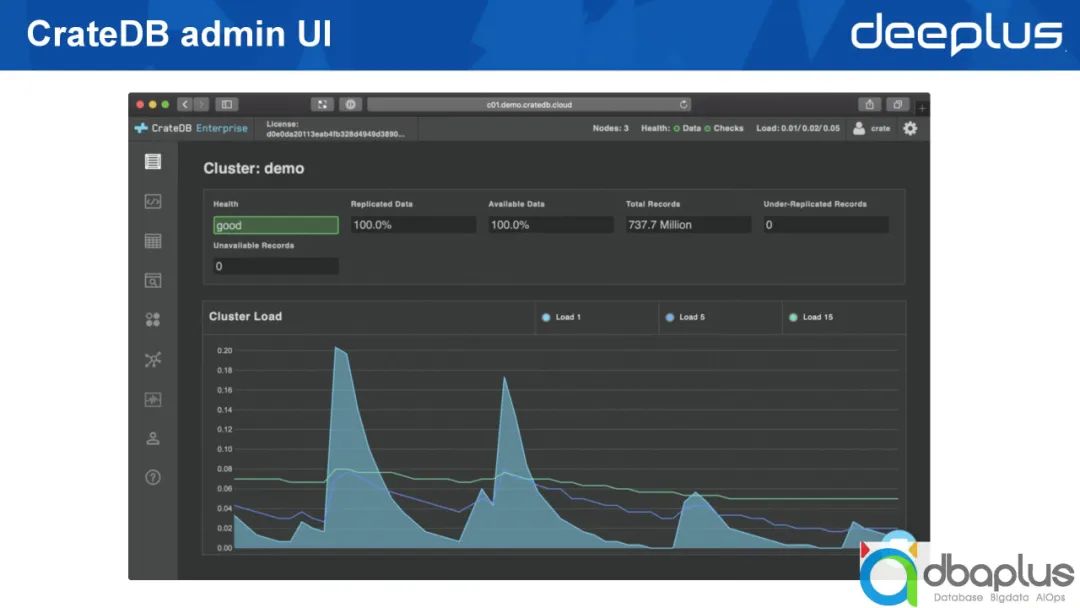
CrateDB安装完成后,会打开上图所示的操作界面,我们能够直接写入查询语句,也可以方便地观测到整个集群的状况。
四、总结
1、CrateDB的适用场景
-
写入少,查询多
-
时序数据存储
-
全文本查询
2、CrateDB的不足
-
Upsert性能较低
-
仅支持NRT查询
-
高阶SQL函数有待实现
-
不支持事务
Q&A
Q1:CrateDB有解决ES字段类型无法修改、写入性能较低和高硬件资源消耗等痛点吗?
A1:首先,CrateDB支持修改字段类型,这个字段类型的修改和PostgreSQL中相同,可以将varchar改成text,但将varchar类型直接改成time stamp可能就会有问题,这时就不得不从重写或者是进行转换。其次,写入性能高低分场景,如果只是单独insert的话,它的性能还是很高的,如果是upsert,或delete与insert掺杂在一起的话,这种混杂这种模式的话,写入性能就会有一些问题,需要进行相应的变通。变通的方式有两种,第一种是先把新数据insert,再把老数据delete。第二种方式是新数据较小的话,可以写入一张另外的临时表中,临时表和新的表进行关联,再做相应的update。
Q2:CrateDB 相比于 Elasticsearch 和 MongoDB ,备份和恢复能力如何?
A2:CrateDB和Elasticsearch在备份和恢复能力层面一样,但是和MongoDB相比,可能更加直观和容易,这是我个人的理解。恢复方面,如果你要求写入时所有数据都吐到磁盘之后才返回,那么所有数据应该都是全部无丢失的。
Q3:CrateDB运行一段时间性能会明显降低,除了重启还有什么方案?
A3:CrateDB在实际运维中确实会碰到一些问题,但是我没有碰到性能明显下降的情况。如果有的话,你可以进行索引级别的重建,而不是整个集群的重启,因为集群重启带来的成本较高。
Q4:CrateDB日志分析能力如何,有继承ES的ELK能力吗?
A4:在与Logstash和Kibana搭配这一层面,还是ES能力更强。从整个生态圈的角度来看,CrateDB还是不能和Elasticsearch相比的,因为Elasticsearch的发展时间久,然后有Logstash和Kibana的加持,在数据的可视化还有分析展现层面确实很强,但是CrateDB可以和另外几个开源的产品搭配使用,比如说Apache Superset但是肯定没有Kibana那种原生定制的强大。
Q5:如果把CrateDB部署在k8s上,数据存储应该怎么存放,是分布存储,本地存储,还是集中存储?
A5:上文中提到需要和OpenEBS或Rancher结合,它是分布式处理的,你的节点要附着于相应的存储机器上面,即使Docker挂了,数据是不会丢失掉的。
Q6:CrateDB贵司用在TP场景多还是AP场景多?
A6:我们用到的是 AP场景,实时数据的聚合返回结果的,当然每一次查询所命中的数据集并不是特别大,我们要查询的数据集可能是很大的,但是真正被查询条件所命中的还是比较少的,可能是几十万。
Q7:CrateDB 的对标竞品是什么,和大数据生态圈比如hadoop有互补吗 ?
A7:CrateDB不是跟Hadoop相竞争,它们两个应该在不同的层面,因为Hadoop是进行离线数据存储的,而CrateDB是做数据分析的。如果要寻找对标竞品的话,我个人认为TimescaleDB是一个很强的竞品,因为它们都号称是时序数据库,同时也提供ANSI SQL的查询标准。从现在的态势来看,可能TimescaleDB获得的用户群更多一点。
活动推荐
2022 Gdevops全球敏捷运维峰会·广州站将于6月17日举办,精选数据库热门议题,共同探讨数据库走向技术融合及国产化下的挑战和突破,部分议题抢先剧透:
-
【平安银行】数据库智能化运维实践之故障自愈
-
【哔哩哔哩】B站大型活动背后的数据库保障
-
【浙江移动】“AN”浪潮下数据库智能运维的实践与思考
-
【vivo】万级实例规模下的数据库可用性保障实践
-
【快手】快手在NewSQL数据库的探索与实践
-
(持续更新……)
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK