

CMU213-CSAPP-Virtual-Memory-Concepts
source link: https://greenhathg.github.io/2022/05/18/CMU213-CSAPP-Virtual-Memory-Concepts/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

CMU213-CSAPP-Virtual-Memory-Concepts
17-Virtual-Memory-Concepts
Physical and Virtual Addressing
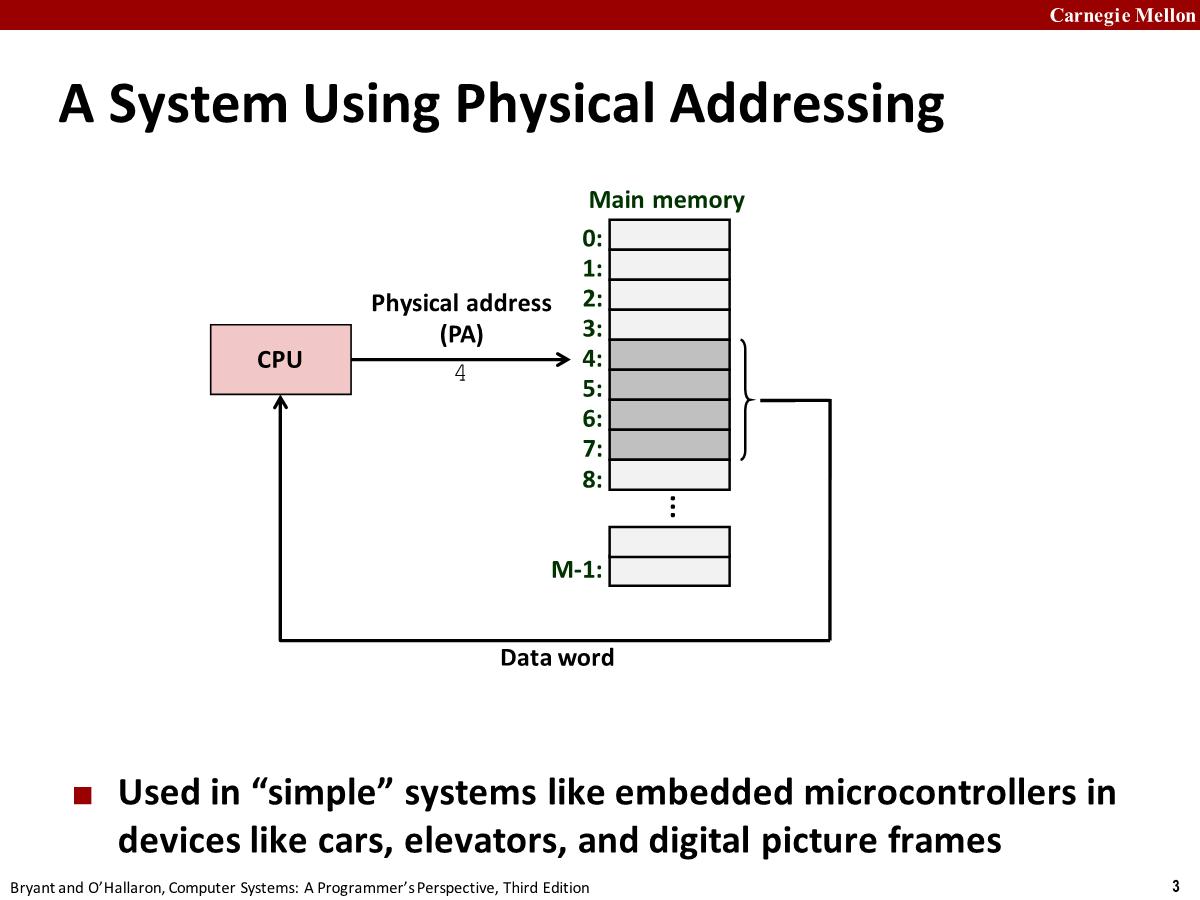
Main memory: an array of M contiguous(连续的) byte-size cells(单元). Each byte has a unique physical address (PA)
{0, 1, 2, 3 … }The most natural way for a CPU to access memory would be to use physical addresses. We call this approach physical addressing.
When the CPU executes the load instruction, it generates an effective physical address and passes it to main memory over the memory bus. The main memory fetches the 4-byte word starting at physical address 4 and returns it to the CPU, which stores it in a register.
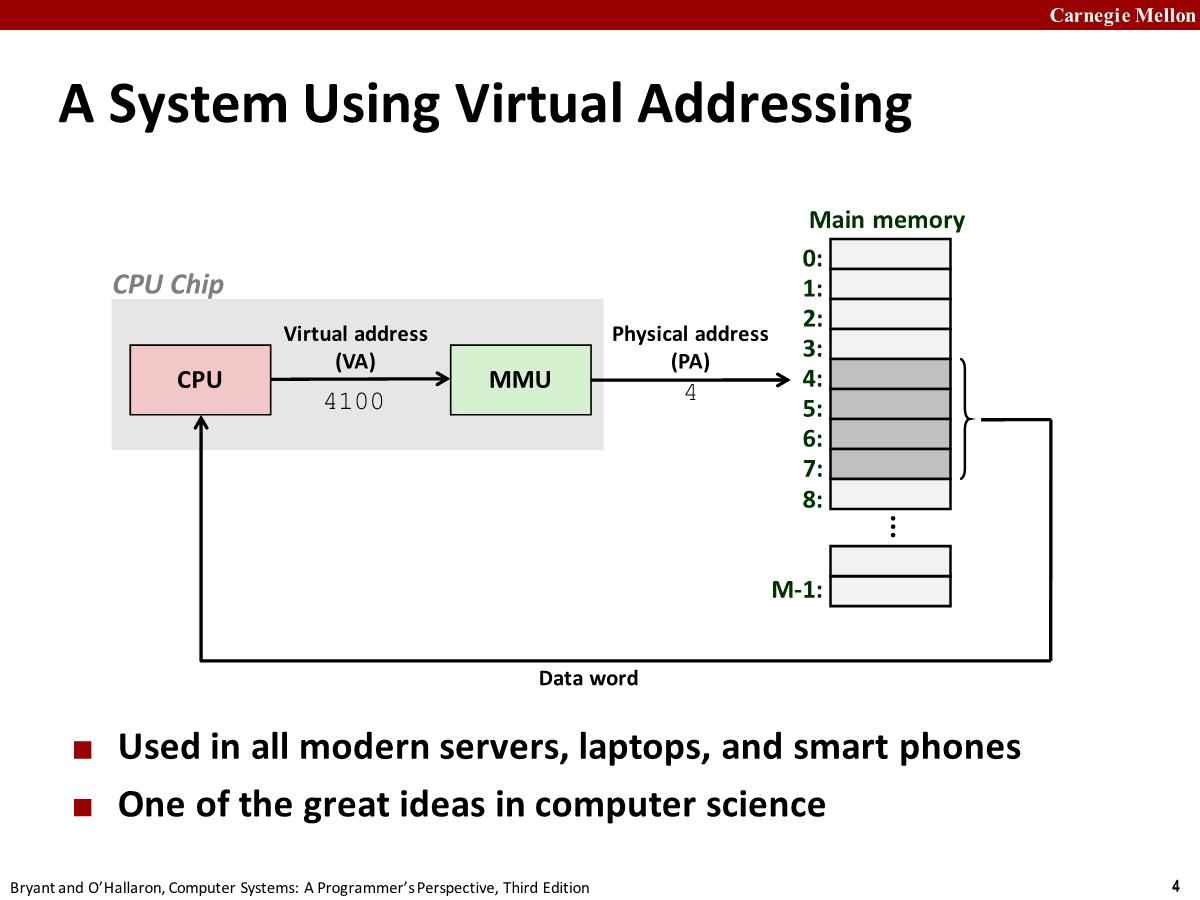
Modern processors use a form of addressing known as virtual addressing
The CPU accesses main memory by generating a virtual address (VA), which is converted to the appropriate physical address before being sent to main memory.
Address Spaces
- An address space is an ordered set of nonnegative integer addresses.(一个非负整数的有序集合)
- Linear address space: Ordered set of contiguous non-negative integer
addresses{0, 1, 2, 3 … }。为了简化讨论,后面均采用线性地址空间。 - Virtual address space: Set of N = 2^n virtual addresses
{0, 1, 2, 3, …, N-1} - Physical address space: Set of M = 2^m physical addresses
{0, 1, 2, 3, …, M-1}
(N 通常大于 M) - 地址空间明确区分了数据对象 data objects (bytes) 和它们的 attributes (addresses)。
- Basic idea of virtual memory: allow each data object to have multiple independent addresses, each chosen from a different address space.
- Each byte of main memory has a virtual address chosen from the virtual address space, and a physical address chosen from the physical address space.
Why Virtual Memory
- It uses main memory efficiently by
- treating it as a cache for an address space stored on disk
- keeping only the active areas in main memory
- transferring data back and forth between disk and memory as needed.
- It simplifies memory management by providing each process with a uniform address space.
- Isolates address spaces
- One process can’t interfere(干涉) with another’s memory
- User program cannot access privileged kernel information and code
虚拟地址为应用程序提供的功能:
- create and destroy chunks of memory
- map chunks of memory to portions of disk files
- read or modify the contents of a disk file by reading and writing memory locations
- load the contents of a file into memory without doing any explicit copying
- share memory with other processes
VM as a Tool for Caching
- Virtual memory is an array of N contiguous(连续的) bytes stored on disk. Each byte has a unique virtual address that serves as an index into the array. The contents of the array on disk are cached in physical memory (DRAM cache)
- The data on disk is partitioned into blocks that serve as the transfer units between the disk and the main memory.
- VM systems handle this by partitioning the virtual memory into fixed-size blocks called virtual pages. Similarly, physical memory is partitioned into physical pages.
- virtual page 有三种
- Unallocated: have not yet been allocated (or created) by the VM system, do not occupy(占用) any space on disk.
- Cached. Allocated pages that are currently cached in physical memory.
- Uncached. Allocated pages that are not cached in physical memory.
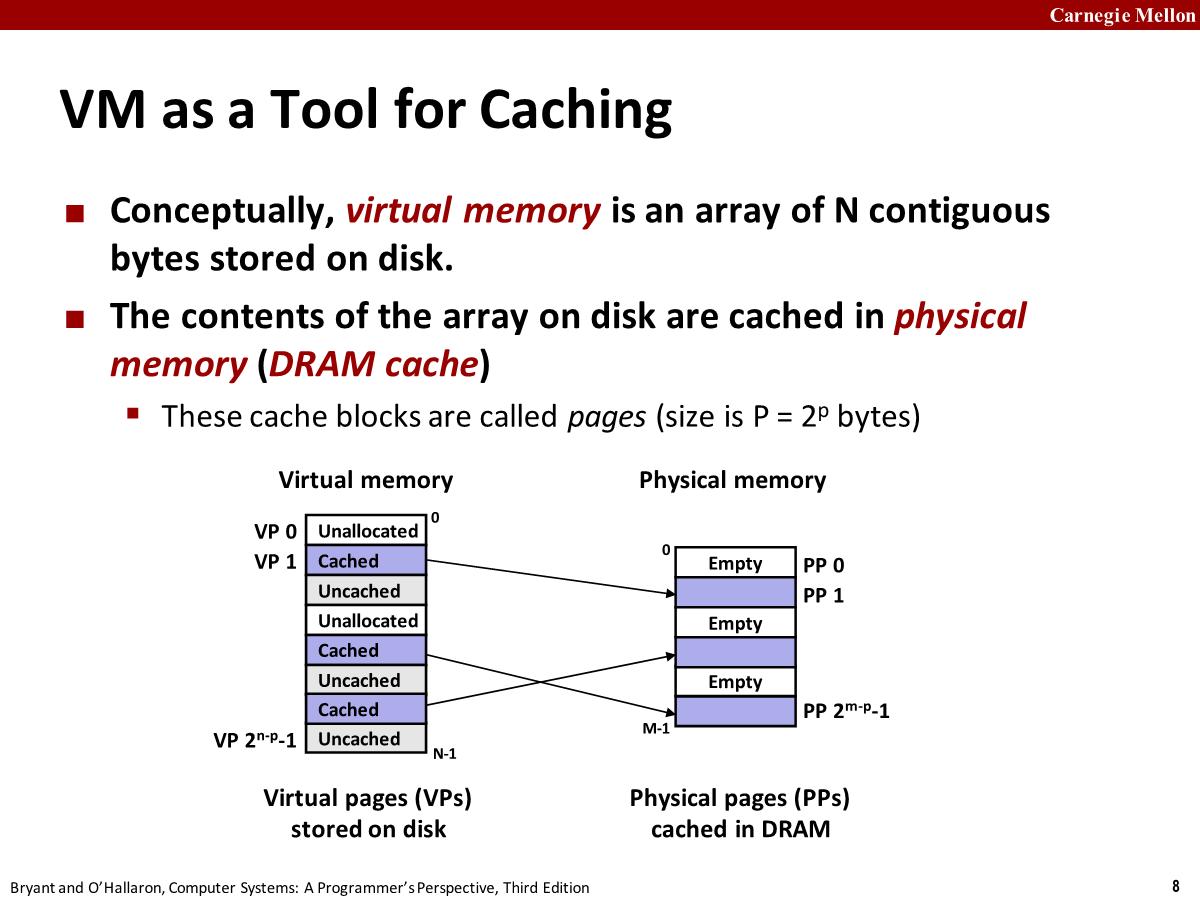
在 DRAM 的某处缓存了三个 virtual page,一些 page 没有被缓存依旧存储在磁盘上 (比如 vp2),有些 page 甚至没有分配,所以在磁盘上不存在。
DRAM Cache Organization
若未命中 DRAM cache,从磁盘中获取数据的代价是非常大的。
- DRAM is about 10x slower than SRAM.
- Disk is about 10,000x slower than DRAM.
造成的影响:
- Large page (block) size: typically 4 KB, sometimes 4 MB
- Fully associative
- Any VP can be placed in any PP.
- Requires a “large” mapping function – different from cache memories.
- 更复杂的替换算法(替换 page),无法在硬件中实现,而替换算法相对简单的 cache memory 则利用了硬件并行查找。替换失误造成未命中的成本远远大于复杂算法执行的成本。
- Write-back rather than write-through
Page table
A page table(页表) is an array of page table entries (PTEs) that maps virtual pages to physical pages.
内核会将它作为每一个进程上下文的一部分进行维护,所以每个进程都有自己的页表。
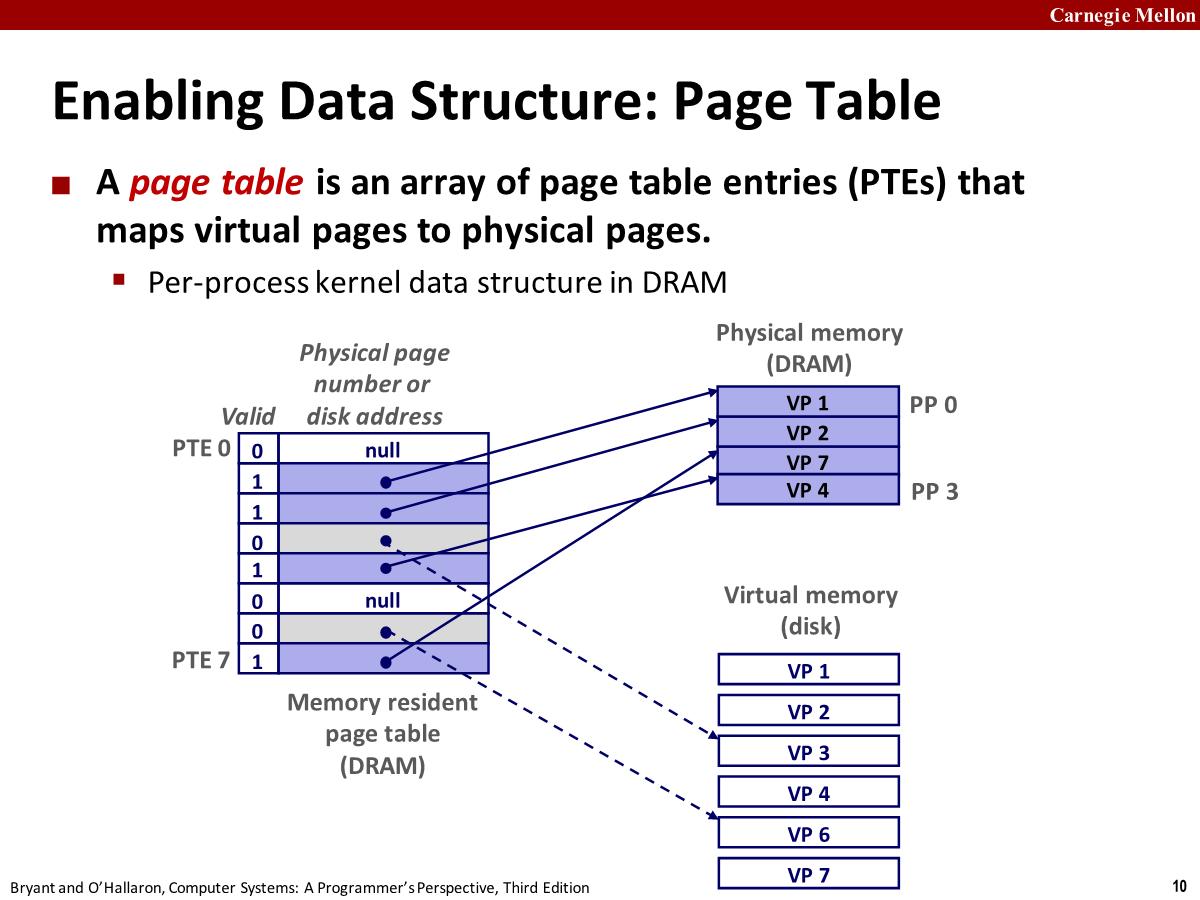
valid: 1 代表当前 vp 在 DRAM 中,0 且地址不为空代表在磁盘上,0 且地址为 null 代表 unallocated page。
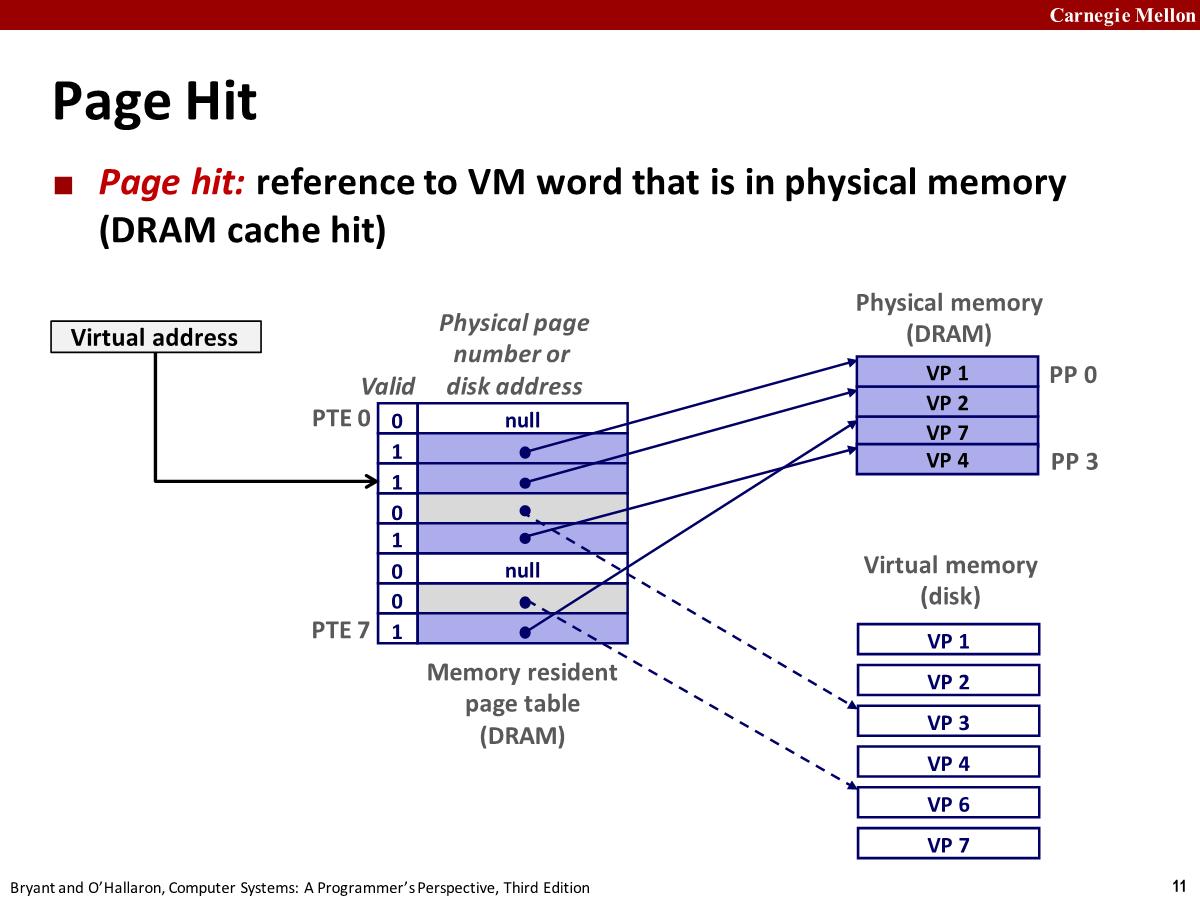
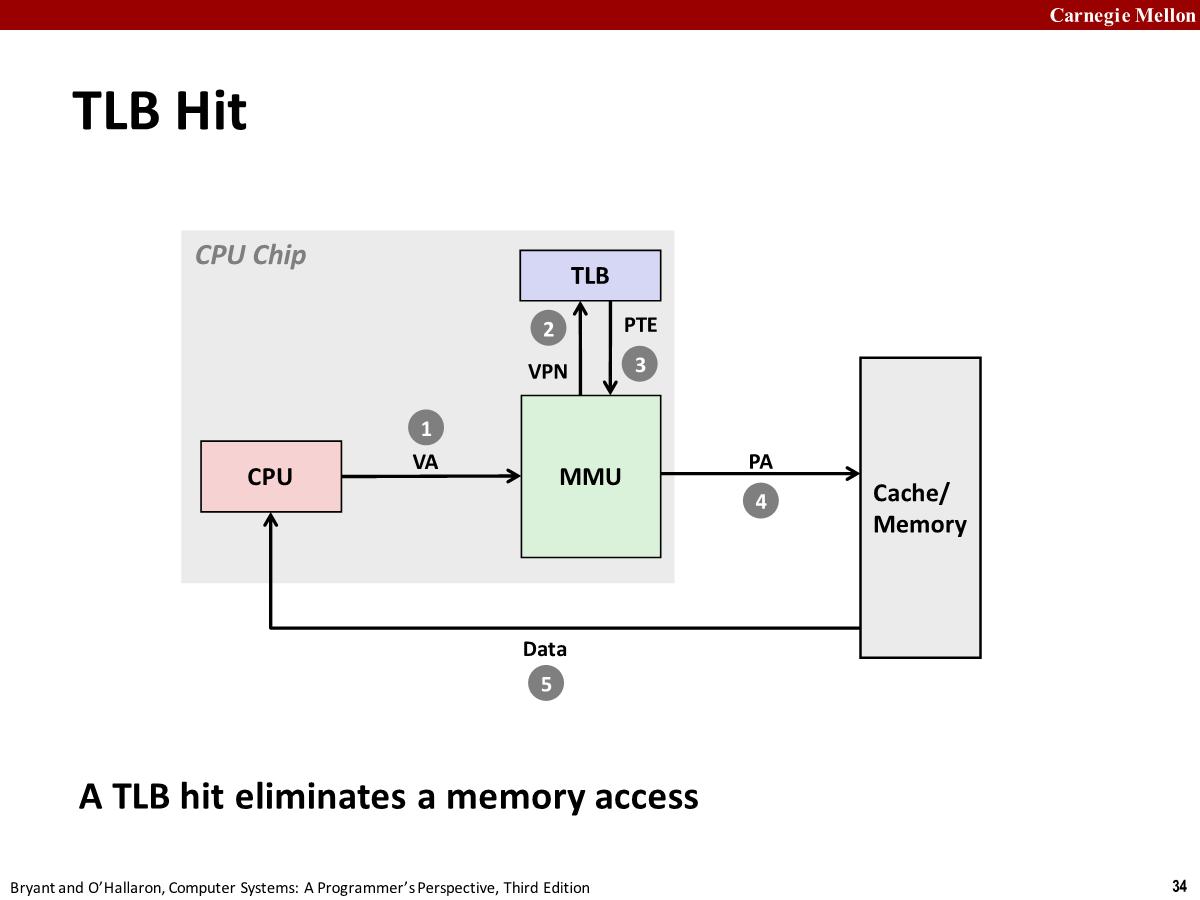
Page hit
CPU 执行 move 指令、call 指令、ret 指令、或者任何类型的控制转移指令,会生成一个虚拟地址。MMU (Memory Management Unit) 会在页表中查找。
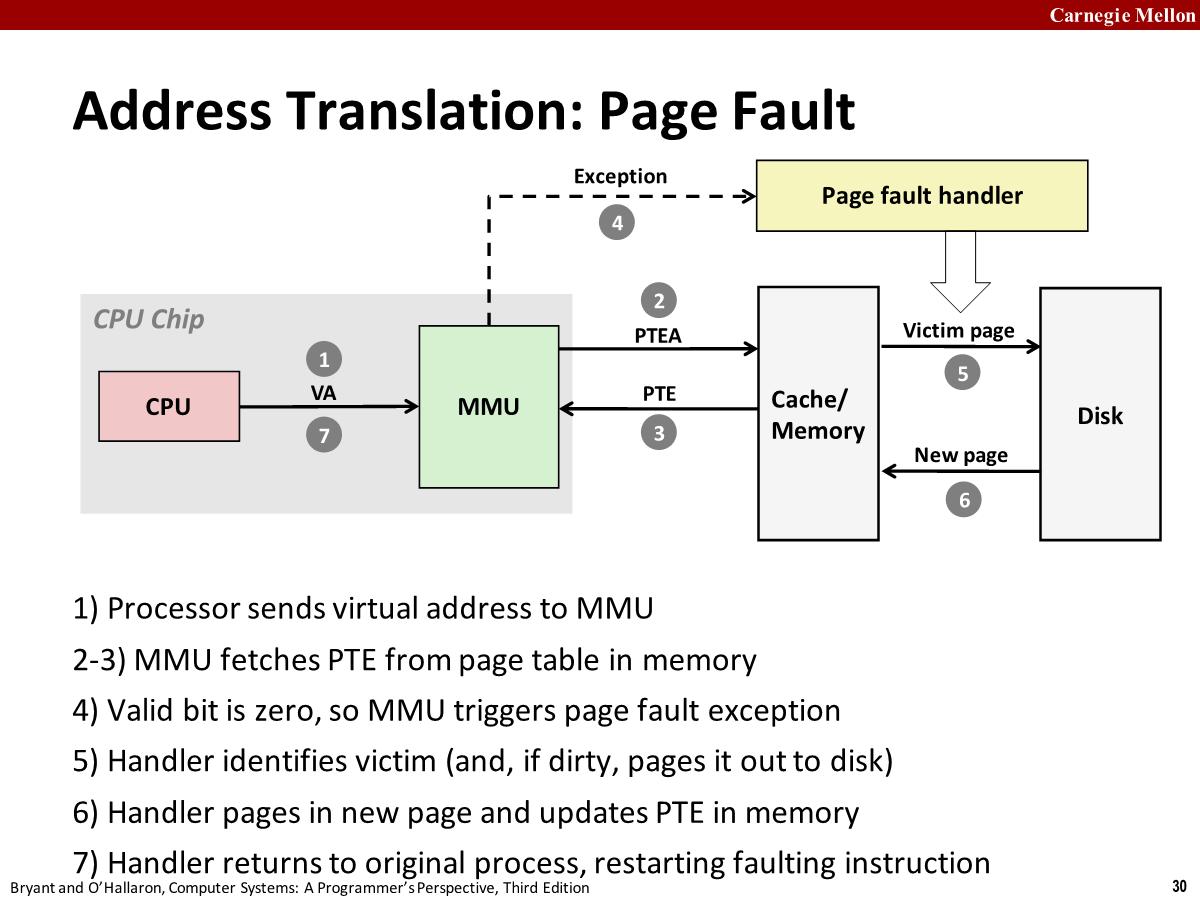
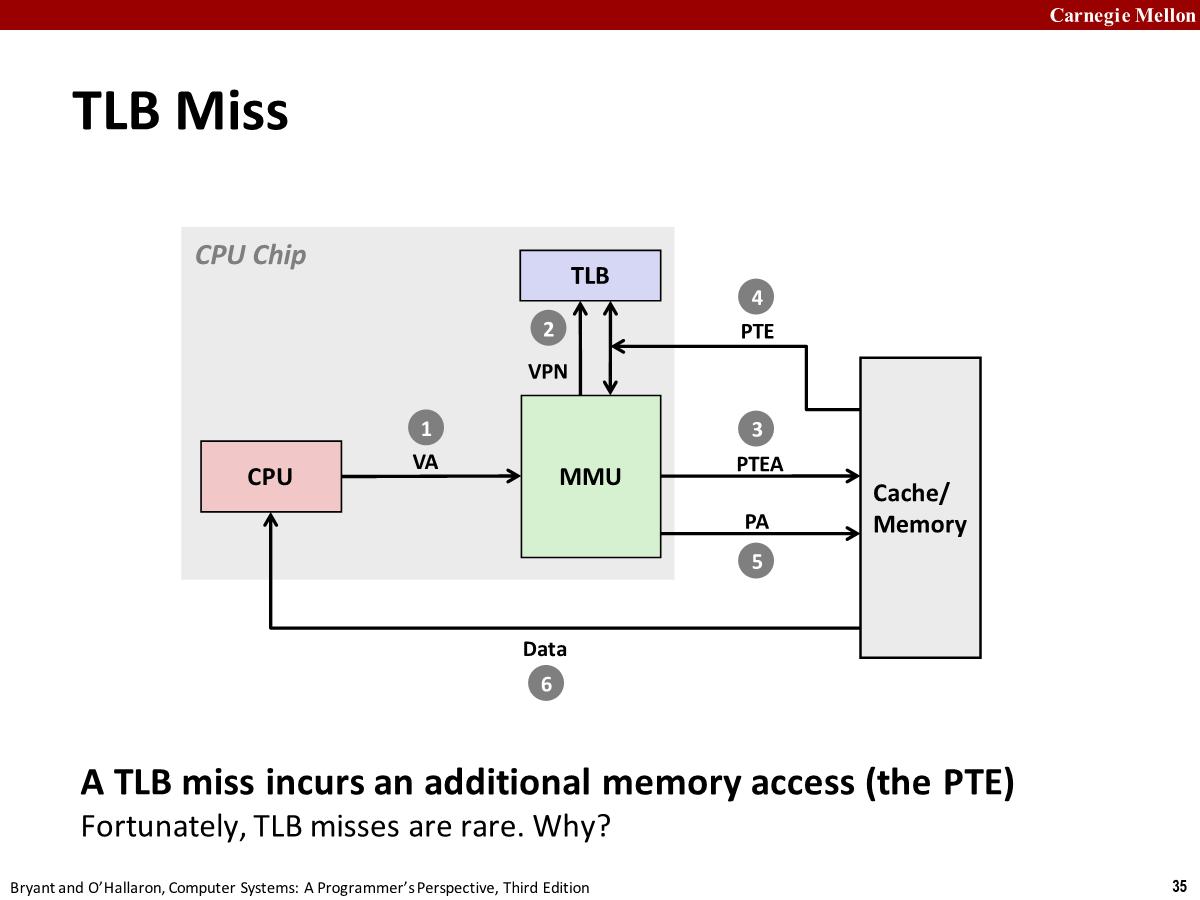
Handling Page Fault
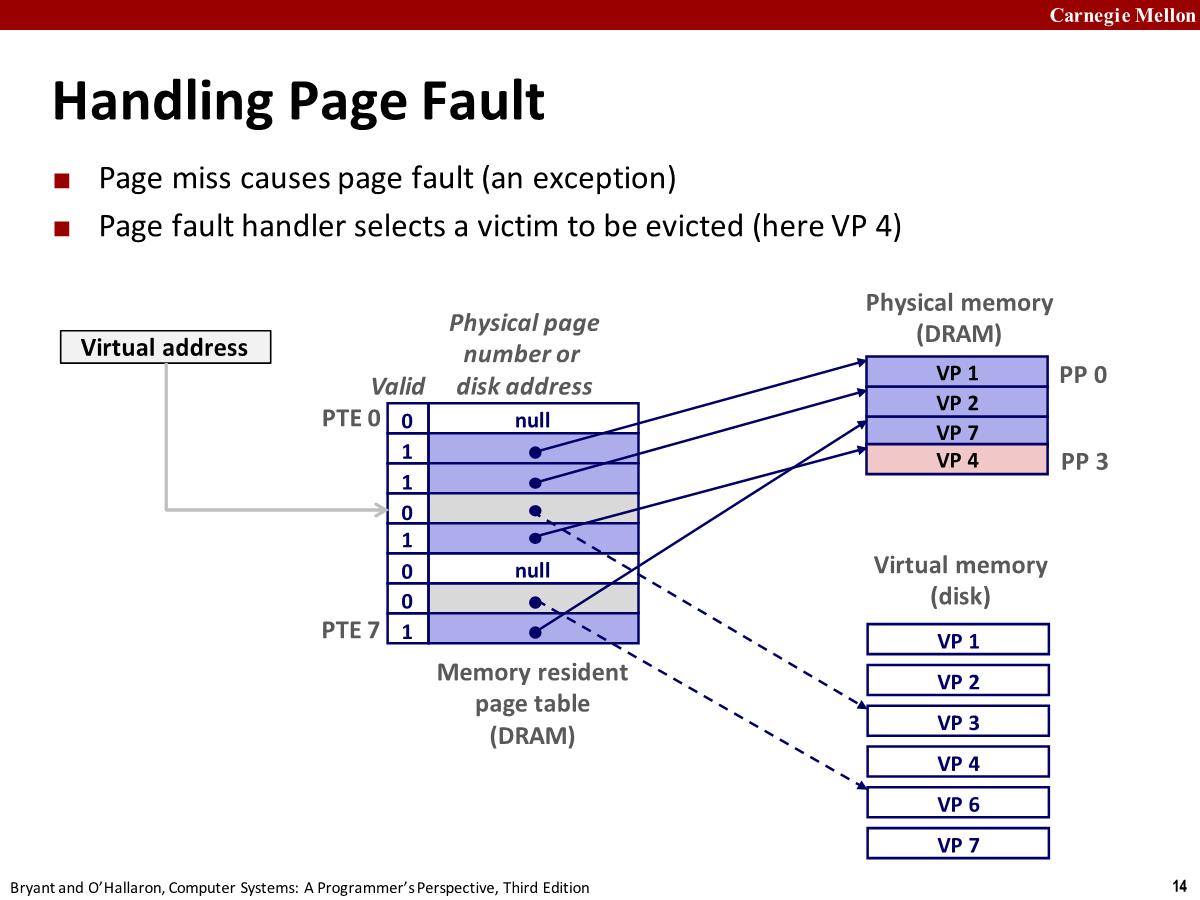
- Page fault: reference to VM word that is not in physical memory (DRAM cache miss)
- Page miss causes page fault (an exception)。硬件触发异常。
- 导致控制权转移到内核中的 page fault handler 的代码块
- 从 Physical memory 选择出一个 page 需要被替换,比如 pp4。如果 vp4 被修改过,内核还需要将数据写回到磁盘。
- 内核从磁盘上获取 vp3 加载到内存中,并更新 Physical memory 和页表
- 当内核中的 Page fault handler 返回时,它返回到导致错误的指令位置,然后重新执行该指令,page hit。
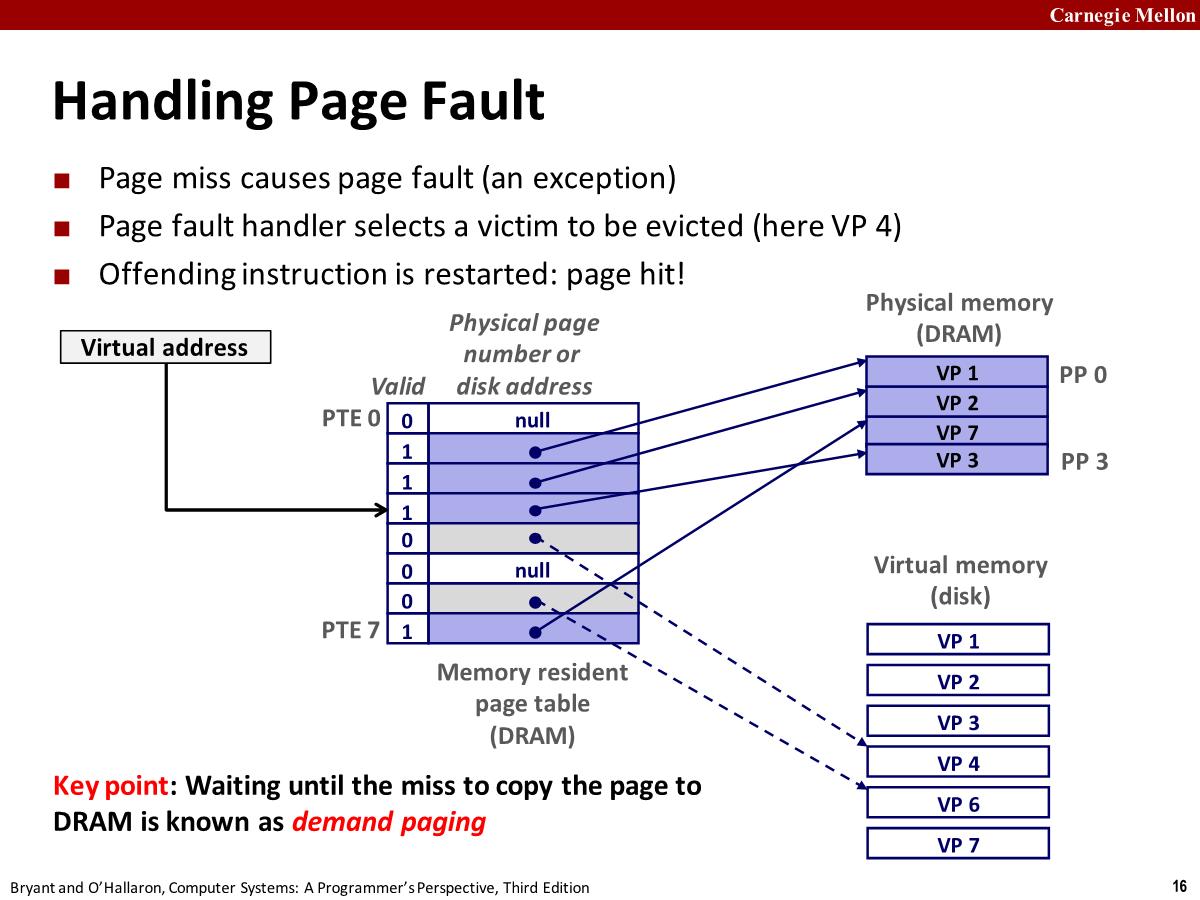
- The activity of transferring a page between disk and memory is- known as swapping or paging.
- All modern systems use demand paging.
Allocating Pages
page table 中的 PTE5 还没有分配,如果需要分配则要调用 malloc 函数:先在磁盘上分配这个 page (vp5),PT5 指向 vp5。并不会一开始就存放在 DRMA 缓存中,直到被使用到为止。所谓的分配只是修改 PTE 而已。
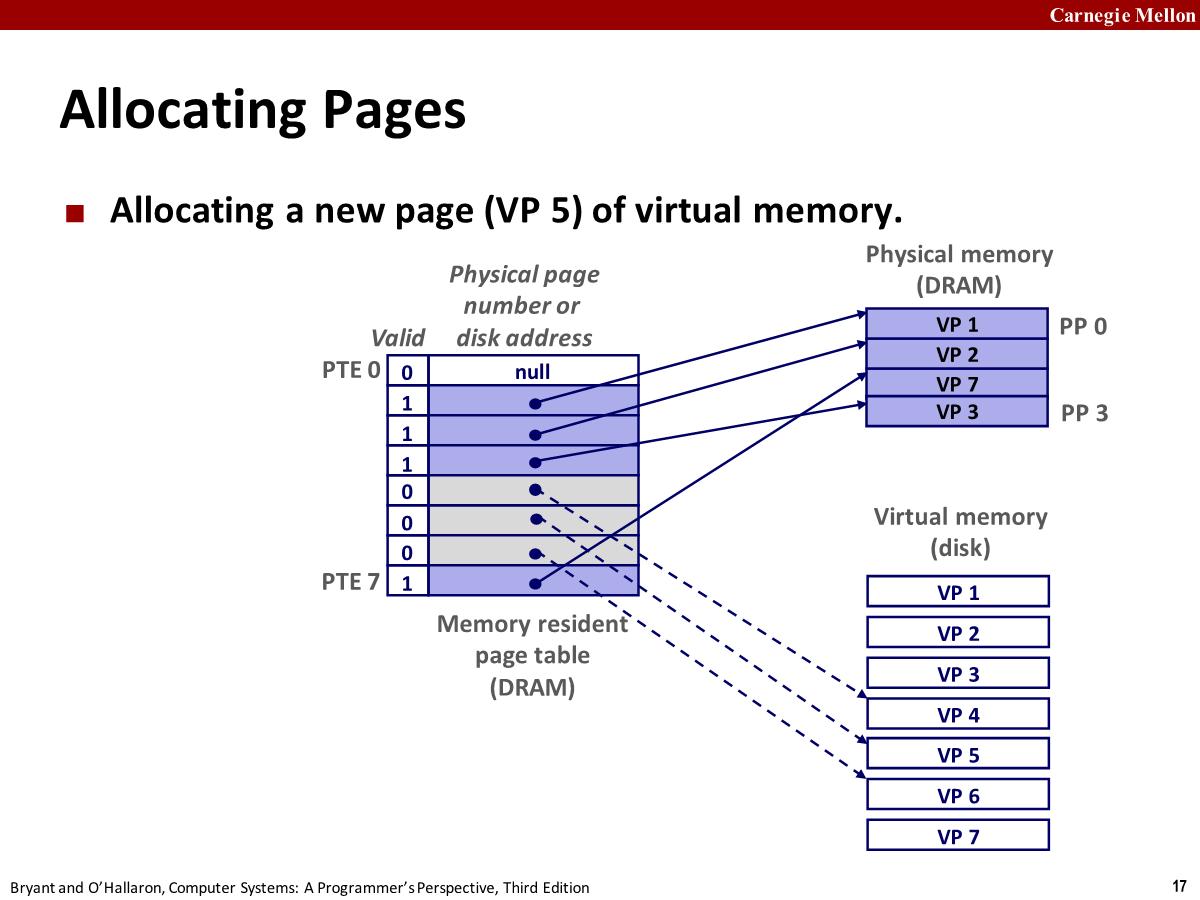
分配新 page 的时候大多是都会有一个选项,可以分配全为 0 的 page,这样的 page 不需要存储在磁盘上,它会在内存中,就好像它是在磁盘上创建然后加载到内存中一样,磁盘上不存在这些全为零的 pages。page 可以映射到文件,code 对应的 page 实际上映射到二进制文件中包含 code 的部分,当未命中 page 时候,会将这些 code pages 加载进来。
Locality to the Rescue Again
虚拟内存因为要复制数据、分配内存、修改页表,甚至可能会出现大量的 cache miss 而导致 swapping,看起来很低效,但是因为局部性原理并不会上面讲的那样低效。
在任何时间点,程序因为局部性倾向于在 working set (set of active virtual pages) 上工作,具有更好的时间局部性程序的 working set 会更小。一般来讲,开销比较大的情况只有初始化 working set 时候将在磁盘的 page 加载到内存的时候,后续使用 working set 将会是 page hit。
只要程序具有良好的局部性,虚拟内存系统就可以很好地工作,但并不是所有的程序都这样,可能会出现 thrashing (抖动) 的情况:
- If (working set size < main memory size): 当前所有的 page 都在主存
- If (SUM (working set sizes) > main memory size)。当所有进程的 working set 之和大于主存大小,就会导致 Thrashing:页面不断的在内存和磁盘之间来回复制。
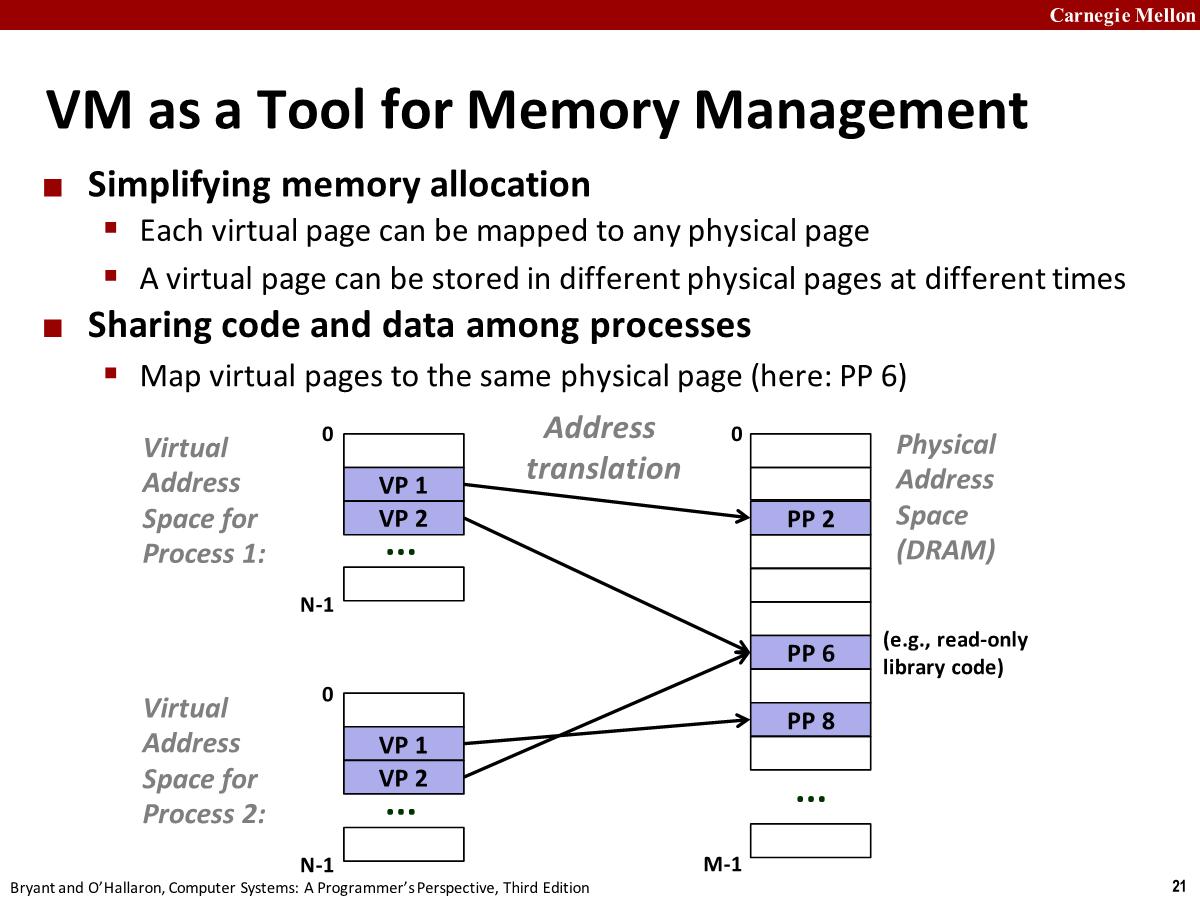
VM as a Tool for Memory Management
- Key idea: each process has its own virtual address space。
- It can view memory as a simple linear array.
- 内核通过为每个进程的上下文中提供属于自己的单独页表来实现。
- Simplifying memory allocation
- Each virtual page can be mapped to any physical page
- 每个进程的页表映射了该进程的虚拟地址空间,虚拟地址空间中的 page 可以映射到物理地址空间 (DRAM) 中的任何位置。不同的虚拟页 (vp) 和不同的进程可以映射到不同的物理页 (pp)。
- 相同的虚拟页也可以在不同的时间存储在不同的物理页中。
- 每个进程都有一个非常相似的虚拟地址空间,相同大小的地址空间、code 和 data 都从相同的位置开始,但是随后进程使用的 page 可以分散在内存中,以最有效的方式使用内存。
- 没有虚拟内存以前,是按物理内存分区的形式为进程分配内存,增加进程及其麻烦,无法知道物理空间位于内存中的哪个地方,需要重新定位等。
- Sharing code and data among processes
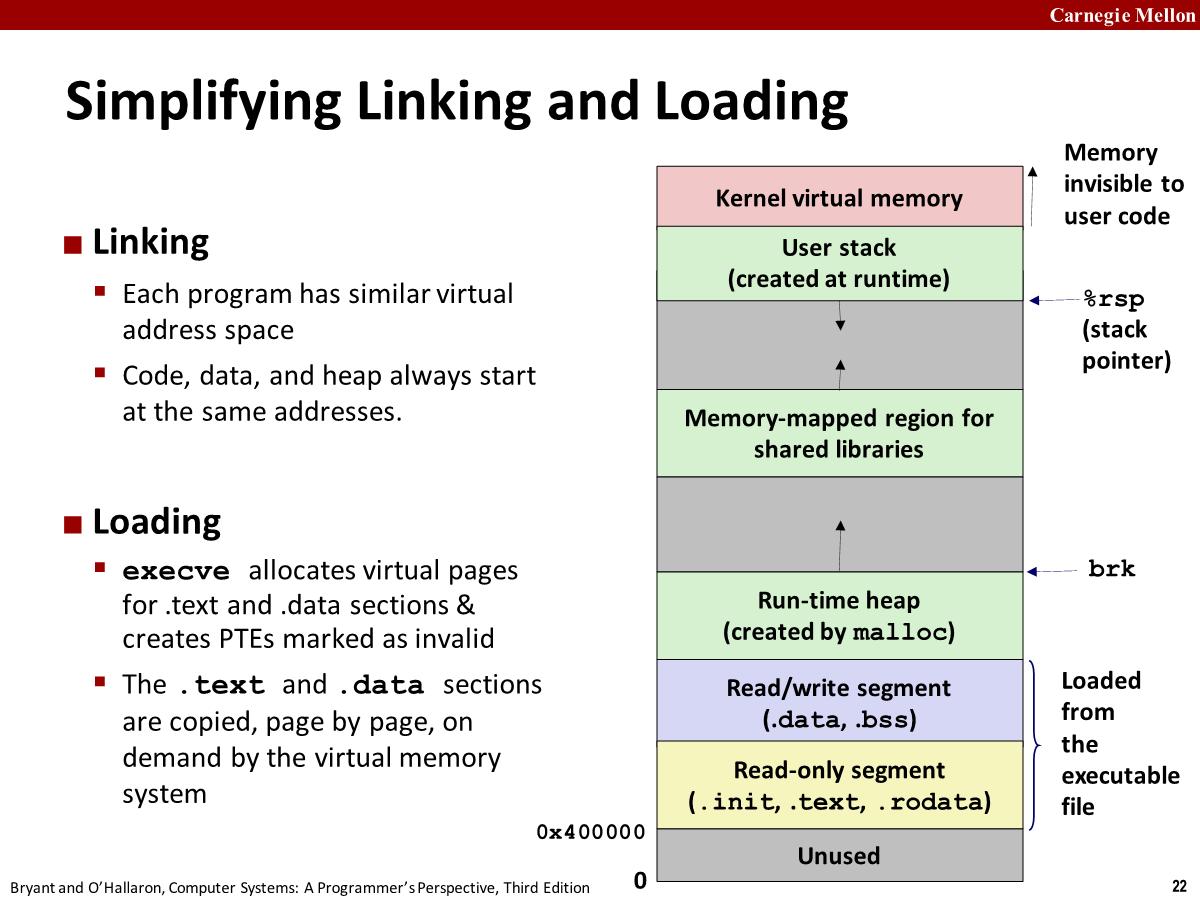
Simplifying Linking and Loading
程序代码和数据一开始没有被加载到内存,只有出现未命中才会进行真正的加载,demand paging。
loading 其实是一个非常有效率的机制,可能有一个包含大型数组的程序,但是只访问数组的一部分,延迟加载可以提高性能。
VM as a Tool for Memory Protection
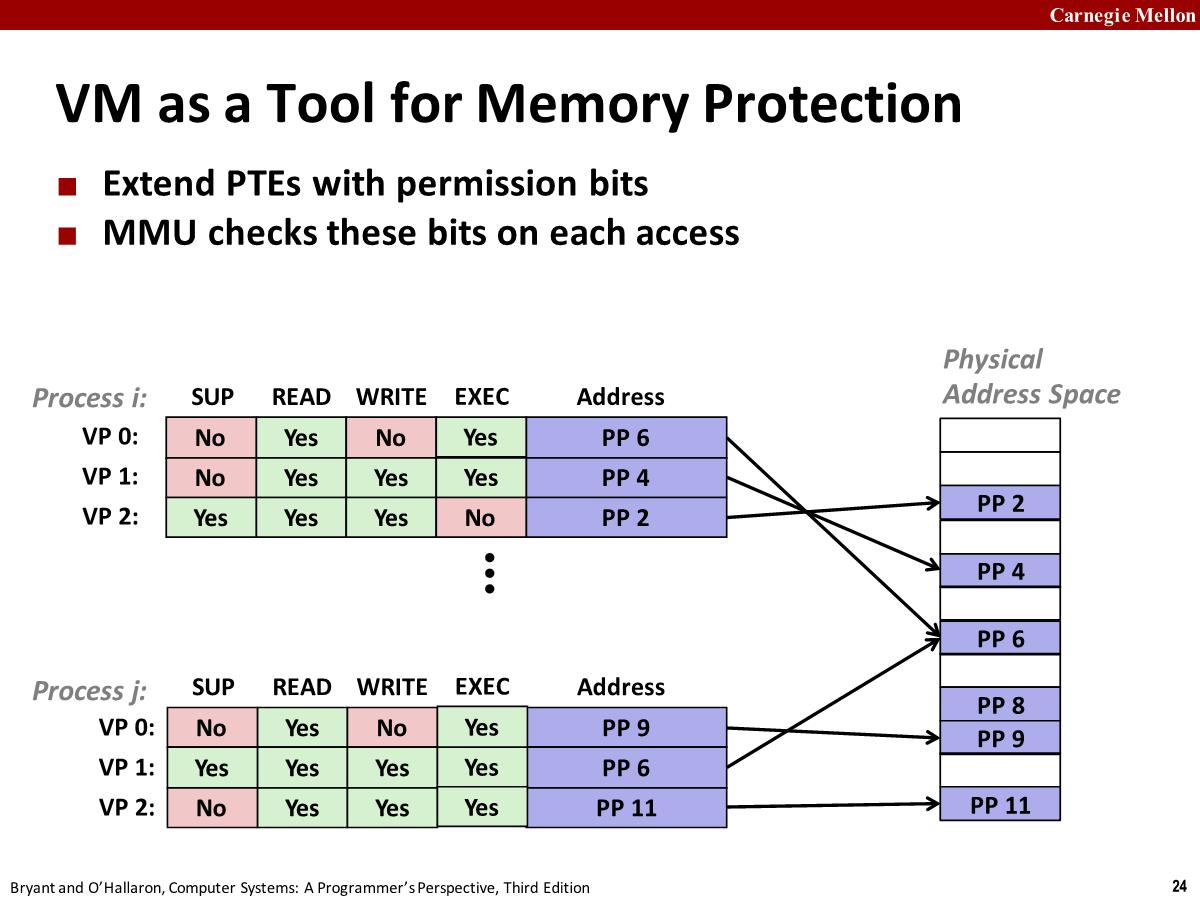
- sup: supervisor. Processes running in kernel mode can access any page, but processes running in user mode are only allowed to access pages for which SUP is 0.
- READ and WRITE: control read and write access to the page (i.e., process i is running in user mode:
r: vp0/1, rw: vp1, not allowed: vp2) - 如果一条指令违背了这些权限,CPU 将触发一个 exception (通常是 segmentation fault),将控制权转向 exception handler,该 handler 将发送 SIGSEGV 信号给该进程
在 x86-64 系统上,指针和地址都是 64 位的,但是虚拟地址空间则是 48 位的,超过 48 位的 bit 要么全是 0 要么全是 1,这是 intel 制定的规则,高位全为 1 的地址为内核保留(地址指向内核中的代码或者数据),高位全为 0 的地址为用户代码保留。
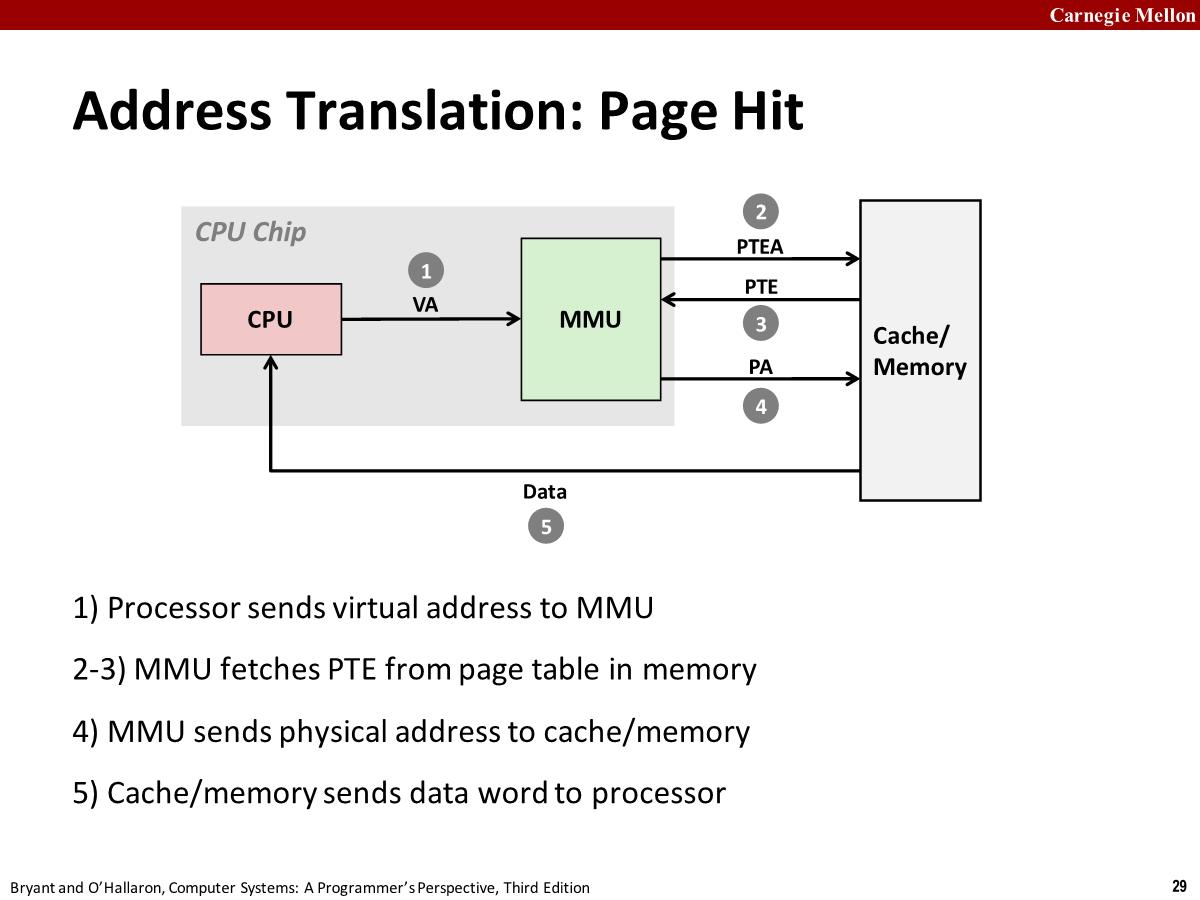
VM Address Translation
Address Translation With a Page Table
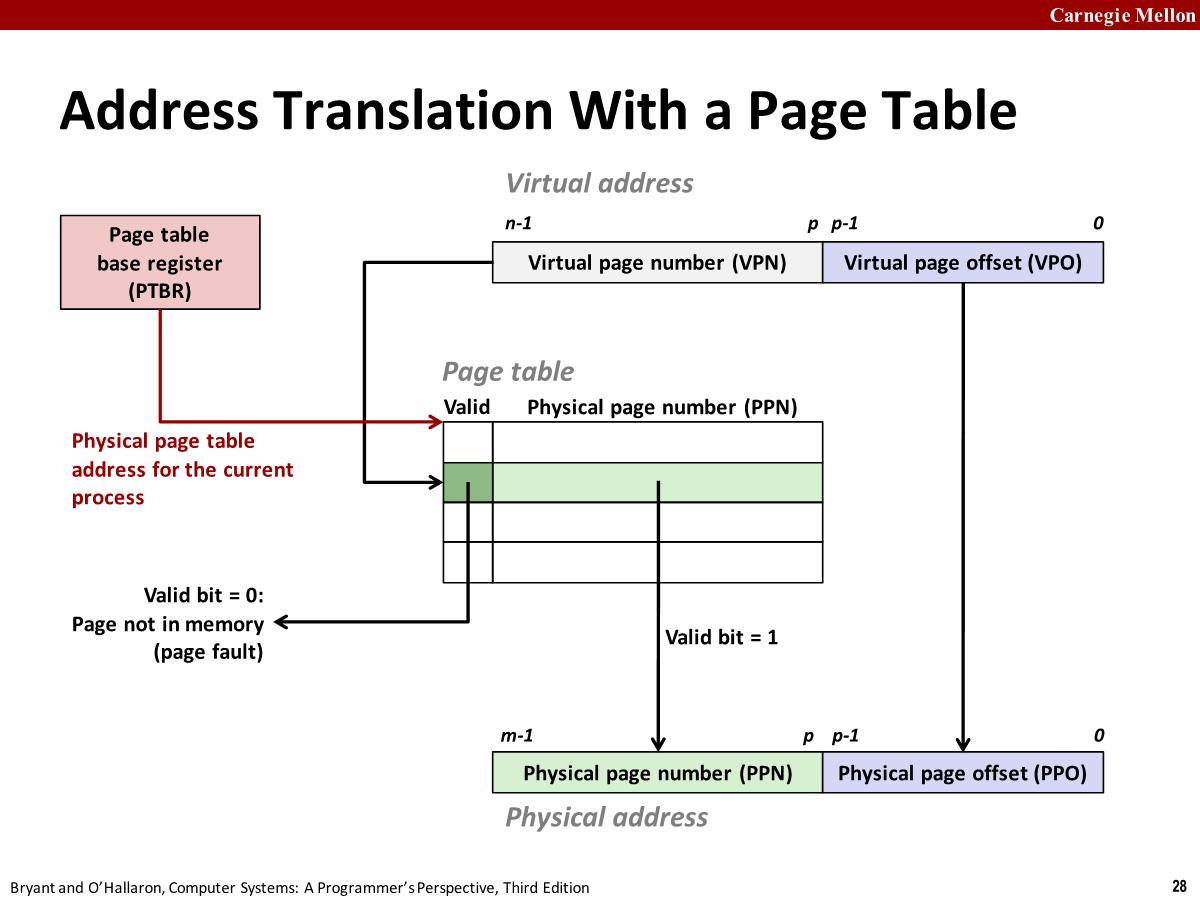
在 intel 系统中,页表的起始地址 (物理地址) 保存在一个特殊的 CPU 寄存器页表基址寄存器 (Page Table Base Register,PTBR) 中,它被称为 CR3 (control register 3:控制寄存器 3)
虚拟块中的 offset 与物理块中的 offset 相同
Speeding up Translation with a TLB
Page table entries (PTEs) are cached in SRAM(L1/L2/L3) like any other memory word
- PTEs may be evicted(驱逐) by other data references
- PTE hit still requires a small L1 delay
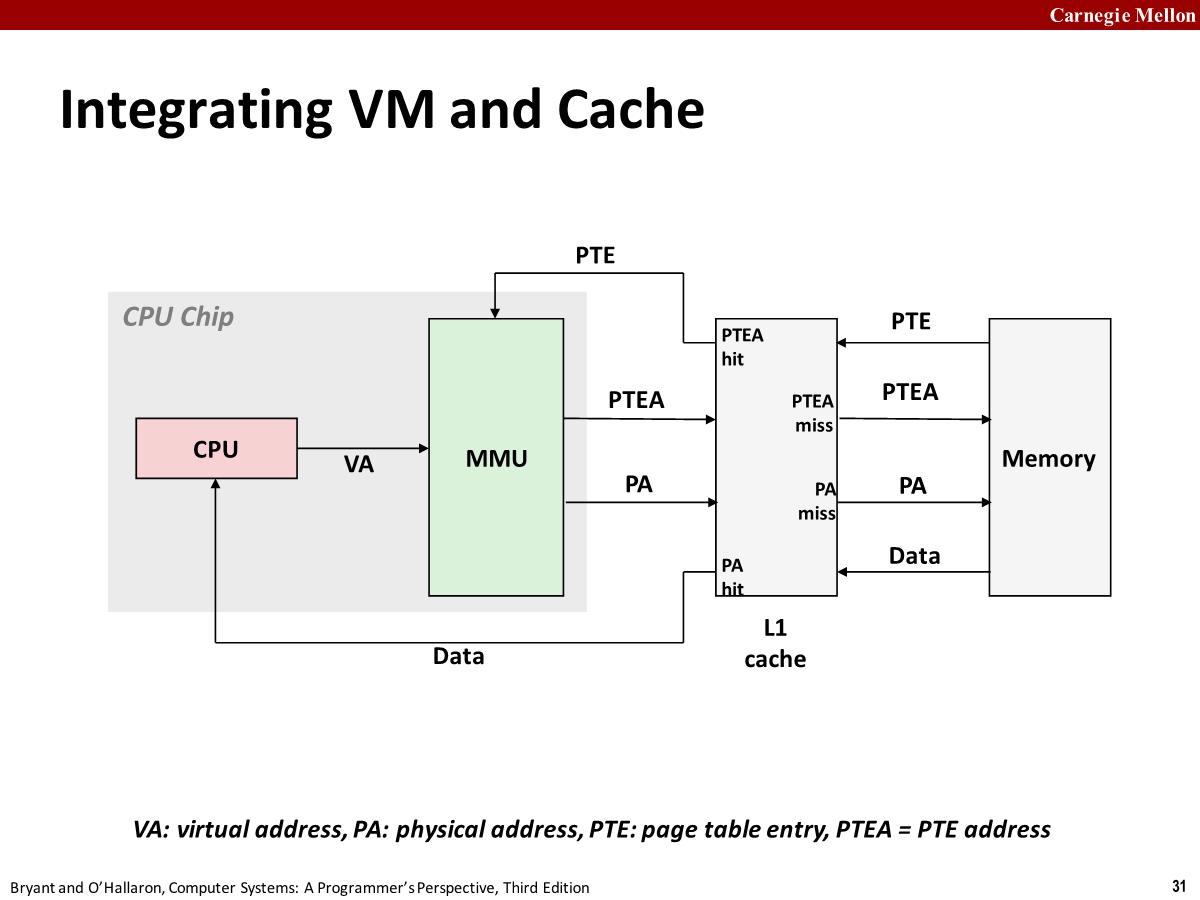
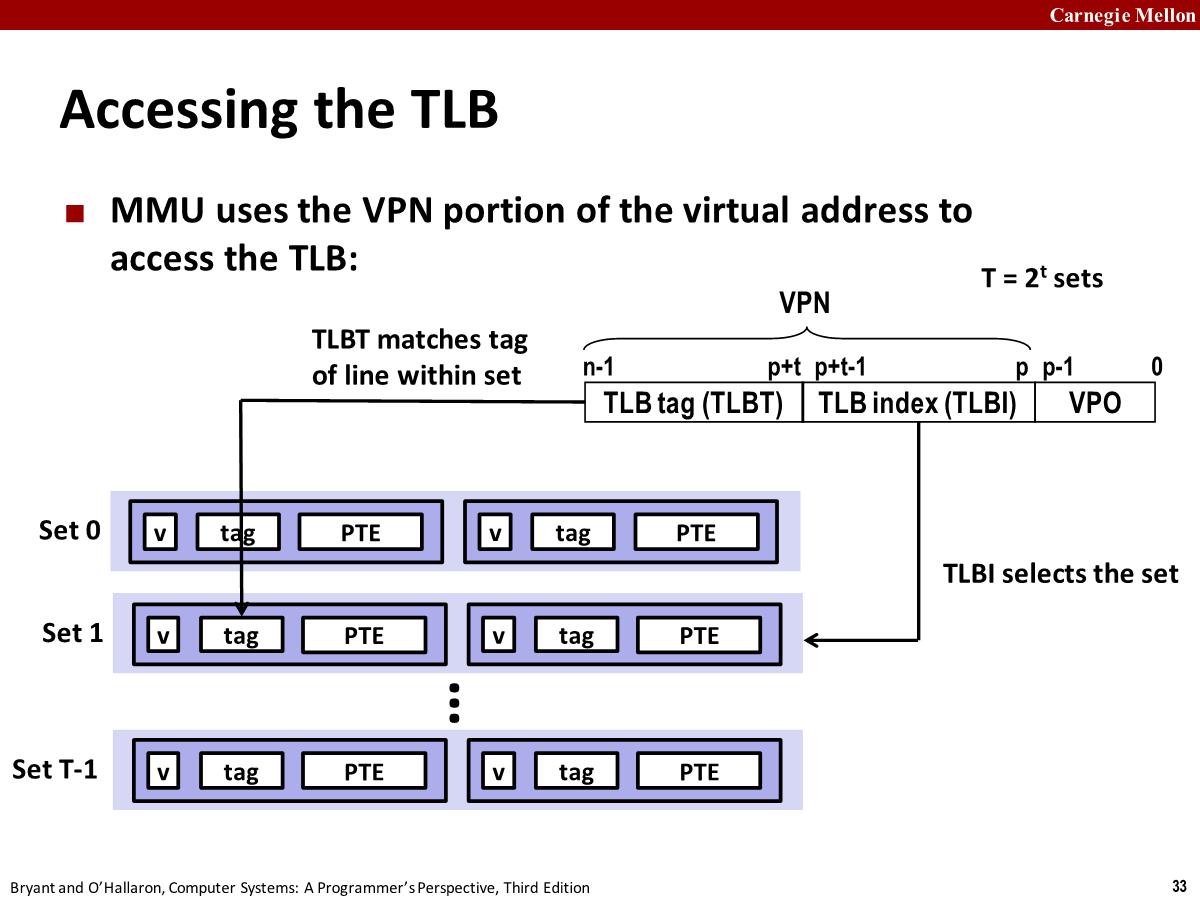
(In any system that uses both virtual memory and SRAM caches, there is the issue of whether to use virtual or physical addresses to access the SRAM cache. Most systems opt for physical addressing.)Solution: Translation Lookaside Buffer (TLB)
- Small set-associative hardware cache in MMU
- Maps virtual page numbers to physical page numbers
- Contains complete page table entries for small number of pages
Multi-Level Page Tables

一个页表需要的空间很大,见图,需要 512GB,因为如果想用一个页表映射虚拟地址空间,需要为每个 page 的地址提供一个 PTE,不管 page 有没有被使用过,因为不确定这些地址空间哪些需要被覆盖,比如 48 位地址空间,则需要 512GB,但是很多都没有使用到,为此使用多级页表可以避免创建不必要的页表。
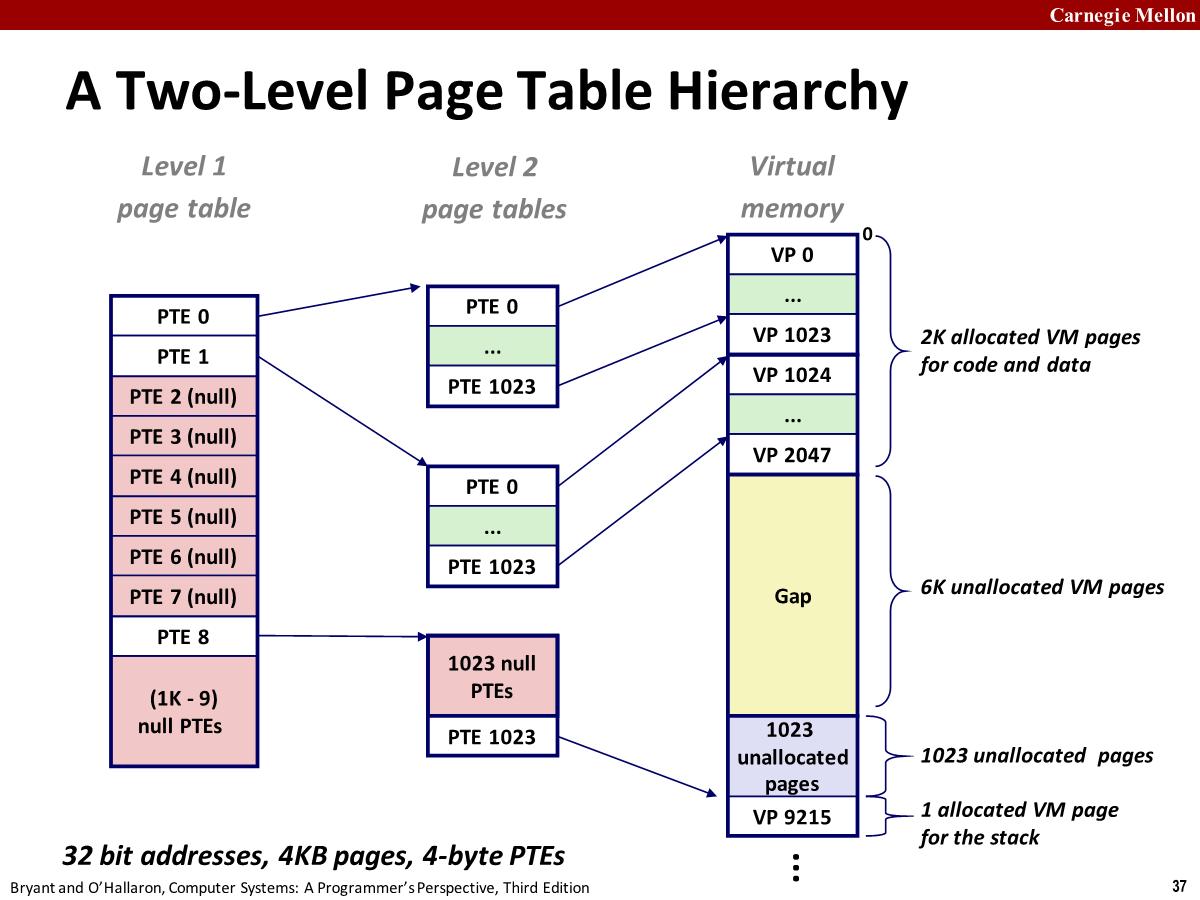
上图已经为这个程序的代码和数据分配了 2k 个 page,还有 6 个没有分配的 page,底下有一个为栈分配的 1024 个 page,但是大部分没有使用,只为栈顶分配了一个 page。
2 个 level 2 的页表覆盖了这分配的 2k 个 page,1 个 level 2 页表覆盖栈 page (1023 个 null PTEs,因为大部分没有使用到),1 个 level 1 页表,共需要 4 个页表。
足够的 level 2 的页表就能覆盖实际使用的虚拟地址空间部分。没有用到的 page 就放到 Gap 区域,无需为它搞一个页表。
reduces memory requirements in two ways
- if a PTE in the level 1 table is null, then the corresponding level 2 page table does not even have to exist.
- The level 2 page tables can be created and paged in and out by the VM system as they are needed, which reduces pressure on main memory. Only the most heavily used level 2 page tables need to be cached in main memory.
Translating with a k-level Page Table
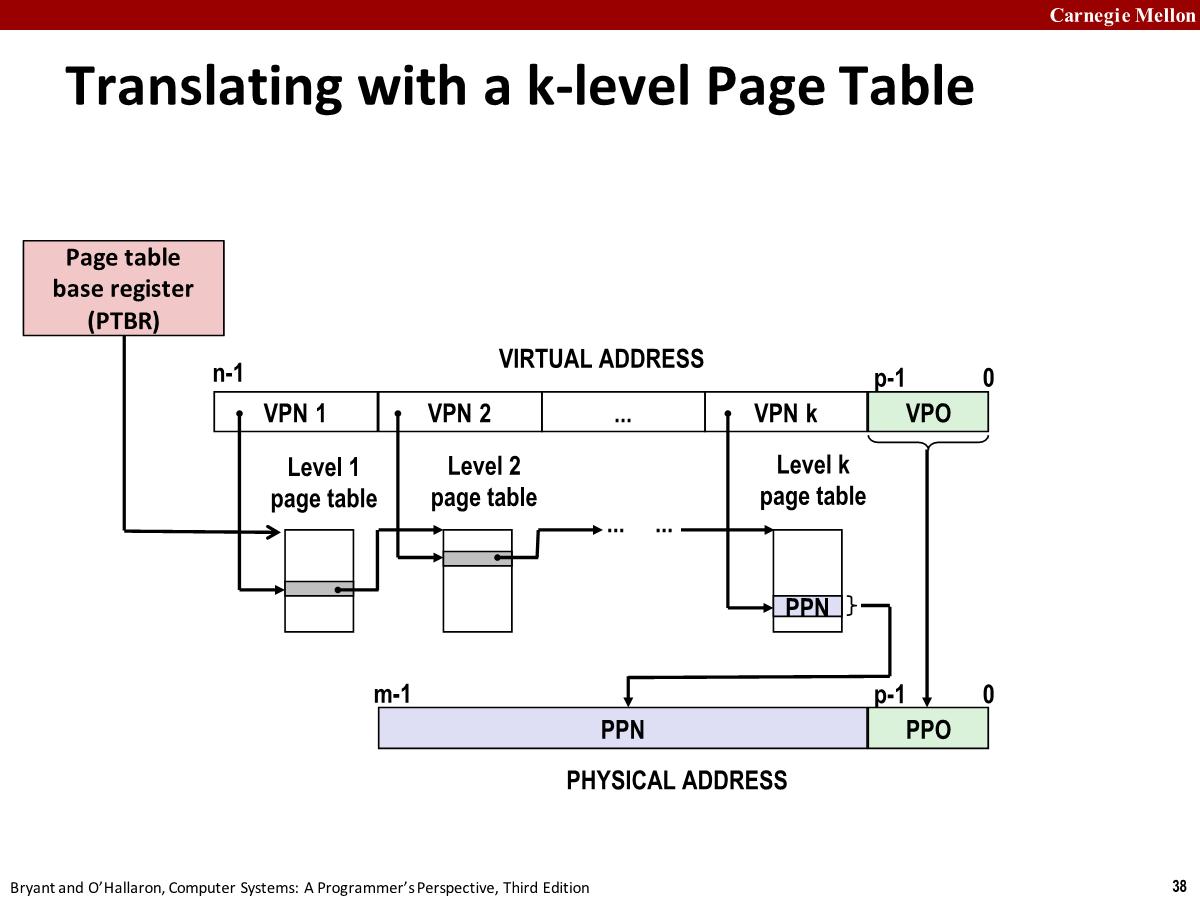
MMU 做的这些都是硬件逻辑,包括有多少级页表,由硬件架构定义。
Recommend
-
11
-
13
《深入理解计算机系统》(CSAPP)实验四 —— Attack Lab ...
-
9
WWWW!!!CSAPP学习笔记(1) - SegmentFault 思否Copyright © 2011-2021 SegmentFault. 当前呈现版本 21.06.30浙ICP备15005796号-2
-
9
程序的执行 虽然我们日常使用的编程语言多种多样,但对于计算机来说,其唯一能理解的无非就是二进制,即0和1而已。 CPU的工作流程基本可以看作为控制器从计数器(PC)取出下一条指令并执行,同时更新程序计数器的值。 C语言的编译过程 ...
-
5
在前面简单介绍了一些常见的汇编指令,接下来我们谈一下在程序执行中一个非常重要的概念:过程 过程是软件工程中一种重要的抽象。它使得我们可以复用之前的代码,隐藏具体...
-
11
csapp之lab:shell lab发布于 2 月 2 日shell lab主要目的是为了熟悉进程控制和信号。具体来说需要比对16个test和rtest文件的输出,实现五个函数:void ev...
-
4
CSAPP第九章笔记之虚拟内存 2022-02-15 编程 一个系统有很...
-
7
本文首发于我的知乎专栏:https://zhuanlan.zhihu.com/p/484657229 1|0实验概览Cache Lab 分为两部分,编写一个高速缓...
-
7
DataLab近来开始读 CS:APP3e 第二章,但干看书做课后题太乏味,于是提前把 DataLab 拉出来练练。不一定是优解,趁热记录一下思路吧。 如果读者是那种还没做完 lab 就想借鉴答案的,还请收手,坚持独立完成吧,正如课程作者所说...
-
5
GreenHatHG の BlogCMU213-CSAPP-Virtual-Memory-Systems发表于 2022-05-18...
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK