

五年谷歌ML Infra生涯,我学到最重要的3个教训
source link: https://blog.csdn.net/OneFlow_Official/article/details/124642603
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

五年谷歌ML Infra生涯,我学到最重要的3个教训

近期,ML/AI Infra行业的发展引发了业内人士的热烈讨论。其中,硅谷创业公司Bluesky创始人Mingsheng Hong分享了他在这一领域的心路历程,总结了ML Infra发展的经验教训。他本人此前曾在Google的Data Infra工作,而后转向ML Infra,2022年初,他和Zheng Shao一起创立Bluesky Data (getbluesky.io),再度回归Data Infra。
以下是他的讲述,OneFlow社区做了不改变原意的编译。
撰文|Mingsheng Hong
翻译|周亚坤、张雨珊
1
从Data Infra到ML Infra
2017年,我在Google建立了一个全新的列存储索引,并且把所有的核心商业分析工作负载(比如AdWords和Display Ads)都移到了这个新系统里(但迁移过程本身也有几百个步骤,很复杂)。
我花了两个季度的时间来确保生产的稳定性(从来没有掉线过,考虑到这是存储格式的迁移,也算是个大工程了)。在这期间,我还带领团队让列存储在新一代系统Napa和F1 Lightning中能正常运作。
一天,我在Google Brain发现了一个由Chris Lattner发起的新的TensorFlow项目,将一个编译器+运行时方法应用于构建ML Infra。我很感兴趣,不仅仅因为Chris本人(LLVM、Swift等项目的负责人)的号召力,还因为我认为SQL查询优化器和存储/执行引擎是一个专用的编译器/运行时系统,这个领域我已经研究了十年。
我很好奇构建Data Infra的哪些经验可以应用到ML Infra上,这两者也都可以从通用编译器/运行时上学到一些东西。
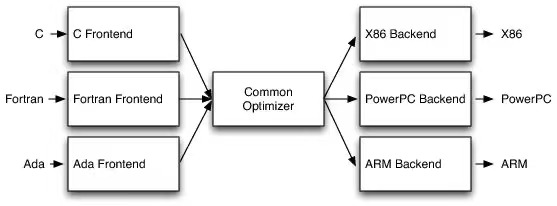
比如,尽管上图所展示的内容不是在数据库背景下创建的,但它立刻引起了我的共鸣,因为Data Infra行业拥有SQL和JDBC/ODBC这样强大的标准,使许多前端可以和一个共同的后端数据库“交流”,这反过来也可以部署到不同的硬件环境中。
同时,我也对这些新的学习机会感到很兴奋。就这样,我决定冒险一试。几年下来,这次合作产生了如下成果:
1. 一个新的ML/TensorFlow runtime(TFRT)
2. 一个新的AI Infra公司Modular AI
3. 一个实验性的ML框架Swift for TensorFlow
2
三条经验教训
虽然我有很多技术、领导力和战略方面的经验教训可以分享,但我挑选了以下3条,可能会引起广大受众的共鸣。
1. 标准的力量
在ML之前,我主要做的是Data Infra工作,当时身处SQL和JDBC/ODBC这样的标准中,它们无处不在,但我并没有真正感受到它们的力量。
在ML中,Python或多或少已经成为了“标准主机语言”,但它的各种ML编程框架和API,如PyTorch、TensorFlow(有或没有Keras)、Jax和MxNet,都有某些不同的编程模型和抽象(例如PyTorch支持可变张量,而Jax是面向函数式编程设计的),这使得用户很难从一个框架迁移到另一个框架。
不仅仅是面向用户编程ML模型的API,还有其他重要的API,例如用于再训练或服务(比如TF SavedModel) 的可序列化的、经过训练的抽象模型,还有让硬件供应商将加速器集成到ML框架中的API,都非常需要标准。虽然你可能听说过ML中的标准,但它们看起来更像是这样:

我亲身经历过这种痛苦,因为我的一些项目(例如TFRT)使TensorFlow变得更好,但这并没有自动将其优势扩展到PyTorch和其他工作中,因为缺乏标准和框架之间的互通性。作为跨框架标准,ONNX设定了一些目标,希望其利益相关者可以继续推进。
如果没有强大的ML标准,我担心现在蓬勃发展的ML Infra初创公司无法长期繁荣——AWS的SageMaker这类集成平台本来可以更好地向用户销售他们的垂直集成。由AlphaZero和GPT-3等引人注目的人工智能突破/里程碑(还有那些热门的风投资金)推动的“拆分时代(Era of Unbundling)”可能不会持续太久。
相比之下,Data Infra也在进行拆分,但由于它有强大的标准,我希望看到更多成功的BI工具、ETL提供商、计算引擎和存储产品。在涉足ML之后,我重新爱上了SQL。
2.了解并聚焦客户
深度学习是助推市场的重要ML分支,直到最近都在快速发展(在我看来,它的发展逐渐趋于平稳,关于这一点欢迎讨论)。因此,ML从业者的角色在Data Infra中非常重要。
然而,对于ML Infra供应商来说,明确他们的目标用户至关重要。例如:他们的目标是否是模型研究人员,正要撰写关于新神经网络体系结构的研究论文?如果是的话,那就不要吹捧ML Infra产品是多么“封装良好”和“一键启用”。许多研究人员本身也是强大的软件黑客,他们善于发现新的、有趣的使用(或“滥用”)低层级Infra的方法,以实现他们的创新(例如AlexNet就源自一个聪明的GPU黑客)。
相反,如果他们针对生产ML模型的工程师(也叫“ML Eng”),那么尽量不要暴露太多的低级“旋钮”,因为这会使产品难以使用,并且难以扩展/维护。同样,缺乏标准往往会让事情变得更加困难。
3. 加速ML执行
以下加速ML执行的示例技术很有趣,并且与其他领域(如数据库查询优化)相关:
a) 使用像“Eigen”这样的软件库(https://eigen.tuxfamily.org/)实现繁重的代码,以优化CPU执行,或调用硬件供应商库(如CuDNN)来执行加速器。
b) 执行Python生成“计算图”(类似于SQL查询计划),对其进行优化,然后执行。它还有其他技术名称,比如“跟踪jit(tracing jit)”和“惰性张量(lazy tensors)”。
c) 在ML模型服务时使用特殊的背景知识,如模型权重为常数,这样就可以在模型执行之前进一步优化模型(类似于SQL优化,如果我们知道FK-PK约束,可以将一些LEFT JOINs转化为INNER JOINs)。
3
为什么回归Data Infra
有人问我,为什么要从ML回归Data Infra?Data Infra不是更老派,而AI才是未来吗?
听上去有道理,AI看起来更耀眼。但我认为,这一转变是职业发展的一个“进步”。当我转向ML Infra时,我主要是受到构建更广泛技术基础的思想欲望的驱使,想弄清楚如何使用编译器/运行时框架在数据和ML中构建大规模系统。
我曾经是一个快乐的工程师,满足于我的白板讨论,解决前沿技术问题,在公司自助餐厅享用美味的午餐,但是,我没有深入思考“影响力”(比如我的工作将如何改变世界)。
现在,我已经完成了上述思考任务,并从谷歌这个神奇的地方毕业,我觉得我“不在堪萨斯”了。我的下一个职业选择不仅是看什么东西比较酷,而更看重什么东西具有影响力。生命短暂,是时候追求最大的影响力了。
未来几年,我相信我对Data Infra的关注会在ML Infra上产生更大的影响,主要有三点原因:
1. 时机
从我自己与不同行业、规模的公司研究性交流来看,几乎每个人都会遇到数据问题(通常都比较紧迫),尽管许多人“希望”有ML问题,但他们还没到那个地步。为了开发ML能力,他们首先需要稳定数据流水线,有高质量的数据,还需要雇佣ML人才来训练和部署模型。
如果不是行业还不成熟,我就会想要创建一个基于优化运行时(如TFRT)的公司。话虽如此,虽然整个行业的ML实践仍然是一个利基市场,但我相信世界将更多地接受ML,包括关心如何让ML更快、更便宜。
2. ML缺乏标准
如果没有强大的ML标准,基于ML Infra产品来建立大规模业务将具有挑战性。相比之下,像Cresta这样的e2e AI产品是我心中的一种优越商业模式。
3. 合作者
除了与Zheng Shao合作,我们的网络数据云用户、投资者、顾问、朋友和过去的同事也热情地支持我们,目前我们还是比较顺利的。
最后还有一些注意事项:
a) ML Infra是一个很酷的领域,具有强大的长期潜力——以上想法仅仅是我自己的职业规划。我将继续支持在这一领域工作的企业家朋友们。我相信他们的一些公司可以在他们的领域建立真正的标准,比如在ML服务中的BentoML,以及在ML编译器/运行时Infra中的Modular AI。
b) 一旦我们让Bluesky的数据云更快、更便宜、更智能(通过在适当的时候使用ML),还计划让ML工作负载运行得更好。
c) Data Infra仍然有很多问题。下面是一个值得思考的例子:一个不谨慎的数据云用户可能很容易花费100美元进行一次查询提交,但没有产生任何业务价值,那么,应该如何设计产品来调整定价模式,避免这种可怕的情况?
(本文经授权后编译发布,原文:
https://www.linkedin.com/feed/update/urn:li:activity:6921260000837320704/)
其他人都在看
欢迎下载体验OneFlow v0.7.0最新版本:GitHub - Oneflow-Inc/oneflow: OneFlow is a performance-centered and open-source deep learning framework.![]() https://github.com/Oneflow-Inc/oneflow/
https://github.com/Oneflow-Inc/oneflow/
Recommend
-
33
-
48
身为开发者的你是否思考过这个问题:在编程过程中,到底什么才是最重要的? 本文 作者的编程生涯始于 2012,到今年正好 7 年的时间。面对“七年之痒”...
-
60
程序员 - @ngzhio2ex - 就在五一劳动节的前一天,我辞去了工作,窝在深圳市宝安区的某个角落里做起了速卖通。我感觉到,我的持续了五年的程序员生涯算是画上一个句号了。我之前还发过一个[帖]( https://www.v2e
-
25
程序员 - @ngzhio2ex - 之前我发过一篇[《开始五年的程序员生涯》]( https://www.v2ex.com/t/674812),这次我又憋了几天憋出了下半篇:- [《结束五年的程序员生涯》]( https://n
-
12
你在人生当中,太晚学到的教训是什么? 至尊六神
-
5
直播+实战+社群 一年免费回看,不断巩固知识 建议每周学习 1-2 节课 ...
-
2
做了五年的产品,这十种产品思维最重要 稻田上的少年 2022-11-09 0 评论...
-
11
藏民18小时前1172FTX 崩盘给整个加密行业带来了巨大的冲击,同时经历过这件事之后,也使得我对加密行业的看法产生了永久性的改变。以下是我从这次崩盘中学到的 10 个教...
-
7
教训惨痛!谷歌如何从AI老大哥一步步跌落神坛? 作者:新智元 2023-02-17 14:52:59 谷歌早已成为部署高度专业化AI任务模型的专家,但当涉及到大动作时,停留在舒适圈让他们得到了惨痛的代价。
-
6
从谷歌 20 年的站点可靠性工程(SRE)中学到的 11 个经验教训 作者 | Adrienne Walcer, Kavita Guliani, Mikel Ward, Sunny Hsiao, and Vrai Stacey 译者 | 刘雅梦 策划 | Tina
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK