

深入探索云原生流水线的架构设计
source link: https://blog.51cto.com/u_15269973/5285475
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
深入探索云原生流水线的架构设计
原创目前,市面上的流水线/工作流产品层出不穷,有没有一款工作流引擎,能够同时满足:
- 支持各种任务运行时,包括 K8s Job、K8s Flink、K8s Spark、DC/OS Job、Docker、InMemory 等?
- 支持快速对接其他任务运行时?
- 支持任务逻辑抽象,并且快速地开发自己的 Action?
- 支持嵌套流水线,在流水线层面进行逻辑复用?
- 支持灵活的上下文参数传递,有好用的 UI 以及简单明确的工作流定义?
- ······
那么,不妨试试 Erda Pipeline 吧~
Erda Pipeline 是一款自研、用 Go 编写的工作流引擎。作为基础服务,它在 Erda 内部支撑了许多产品:
- CI/CD
- 快数据平台
- 自动化测试平台
- SRE 运维链路
Erda Pipeline 之所以选择自研,其中最重要的三点是:
- 自研能更快地响应业务需求,进行定制化开发;
- 时至今日,开源社区还没有一个实质上的流水线标准,各种产品百花齐放;
- K8s、DC/OS 等的 Job 实现都偏弱、上下文传递缺失,无法满足我们的需求,更不用说灵活好用的 Flow 了,例如:嵌套流水线。
本文我们将主要从架构层面对 Pipeline 进行剖析,和大家一起来深入探索 Pipeline 的架构设计。主要内容包括以下几个部分:
- 分布式架构
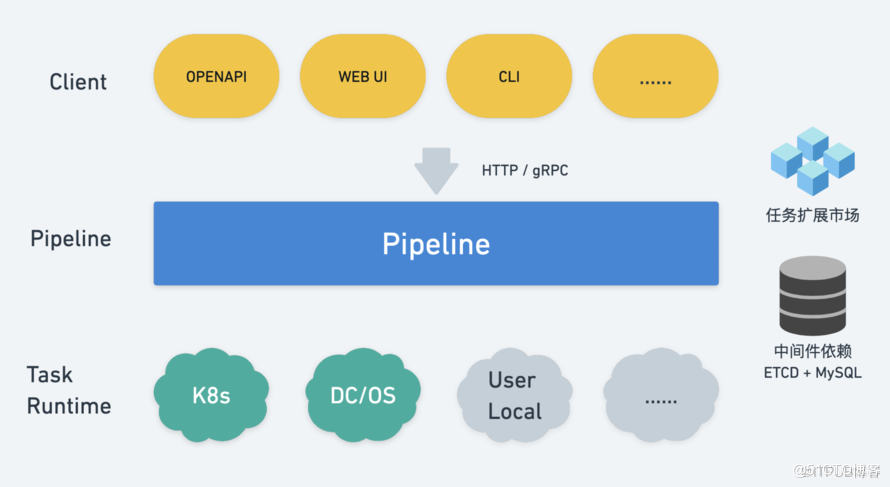
Pipeline 支持灵活的使用方式,目前支持 UI 可视化操作、OPENAPI 开放接口、CLI 命令行工具几种方式。
协议层面,在 Erda-Infra 微服务框架的加持下,以 HTTP 和 gRPC 形式对外提供服务:在早期的时候,我们只提供了 HTTP 服务,由于 Erda 平台本身内部是微服务架构,服务间调用就需要手动编写 HTTP 客户端,不好自动生成,麻烦且容易出错。后来我们改为使用 Protobuf 作为 IDL(Interface Define Language),在 Erda-Infra 中自动生成 gRPC 的客户端调用代码和服务端框架代码,内部服务间的调用都改为使用 gRPC 调用。
在中间件依赖层面,我们使用 ETCD 做分布式协调,用 MySQL 做数据持久化。ETCD 我们也有计划把它替换掉,使用 MySQL 来做分布式协调。
最关键的任务运行时(Task Runtime)层面,我们支持任务可以运行在 K8s、DC/OS(分布式云 OS,在 2017-2019 年非常火)、用户本地 Docker 环境等。
我们还有开放的任务扩展市场,在平台级别内置了非常多的流水线任务扩展,开箱即用。同时,用户也可以开发企业/项目/应用/个人级别的任务扩展,这部分功能在代码层面已经完全支持,产品层面正在开发中,在后续迭代中很快就可以和大家见面。
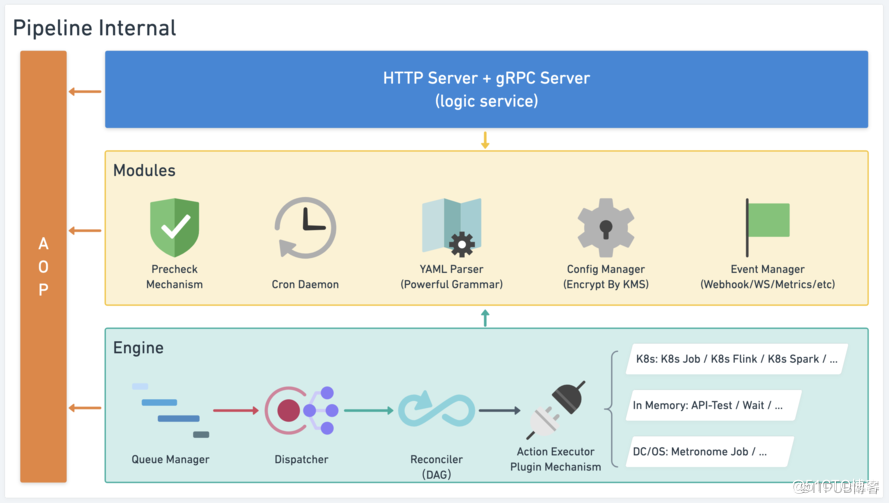
使用 Erda-Infra 微服务框架开发,功能模块划分清晰:
- Server 层包括业务逻辑,对 Pipeline 来说业务就是创建、执行、重试、重试失败节点等。
- Modules 层提供不含业务逻辑的公共模块,其余两层均可调用,包括预校验机制、定时守护进程、YAML 解析器、配置管理、事件管理等。
Erda Pipeline 一直在践行:“把复杂留给自己,把简单留给别人”。
在 Pipeline 中,我们对一个任务执行的抽象是 ActionExecutor。
- Engine 层负责流水线的推进,包括:
- Queue Manager 队列管理器,支持队列内工作流的优先级动态调整、资源检查、依赖检查等
- Dispatcher 任务分发器,用于将满足出队条件的流水线分发给合适的 Worker 进行推进
- Reconciler 协调器,负责将一条完整的流水线解析为 DAG 结构后进行推进,直至终态。
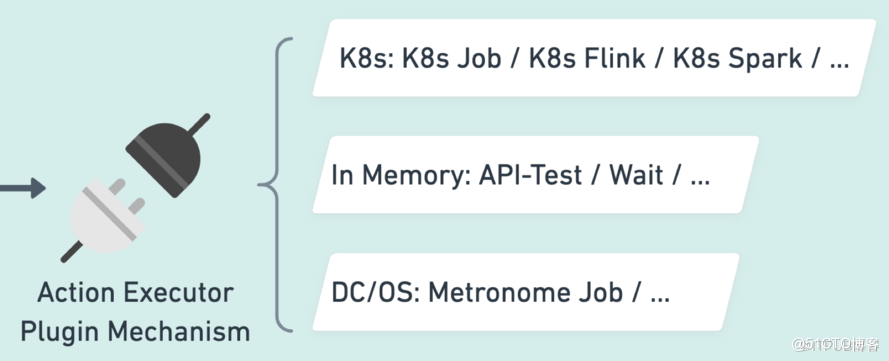
- 模块内部使用插件机制,对接各种任务运行时。
- AOP 扩展点机制(借鉴 Spring),把代码关键节点进行暴露,方便开发同学在不修改核心代码的前提下定制流水线行为。
- 目前已经有的一些扩展点插件,譬如自动化测试报告嵌套生成、队列弹出前检查、接口测试自动登录保持等。
- 这个能力后续我们还会开放给调用方,包括用户,去做一些有意思的事情。
- 统一使用 Event,封装了 WebHook / WebSocket / Metrics。
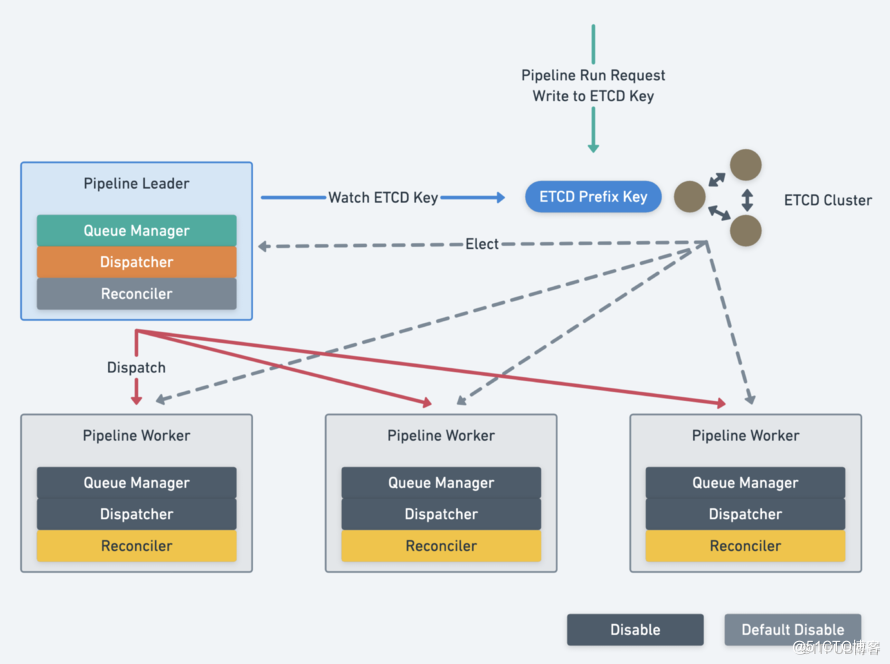
随着 Pipeline 需要支撑的业务场景和数据量与日俱增,单实例的 Pipeline 稳定性和推进性能面临着挑战。
Pipeline 的多实例方案如下:
- Leader & Worker 模式,两者在部署上不区分状态,仅为 Replicas 多实例:
- 使用 ETCD 选举,每个实例都可以是 Leader。
- 只有 Leader 开启 Queue Manager 和 Dispatcher,分发任务给 Worker。
- Leader 本身也可以作为 Worker,支持单节点部署模式,Leader 必须开启 Reconciler。
- Dispatch 使用有界负载的一致性哈希算法:
- 使用一致性哈希来分配任务。但一致性哈希会超载,例如某些热点内容会持续打到一个节点上。
- 有界负载算法(The bounded-load algorithm):
- 要服务器未过载,请求的分配策略与一致性哈希相同。
- 载服务器的溢出负载将在可用服务器之间分配。
- Pipeline 实例增减时,已经被分配的流水线不重新分配,尽可能减少切换成本,防止重复推进;新增的流水线使用一致性 Hash 算法进行分配。
在之前,我们使用过分布式锁的方案来做多实例协调。和选举比起来,竞争会更大,在具体实现里,如果想要多实例同时推进流水线,那竞争的资源就是流水线 ID。每个 ID 会请求一个分布式锁,而且这个分布式锁是阻塞性的,保证每个流水线 ID 一定会被推进,天然做了多节点重试。
分布式架构
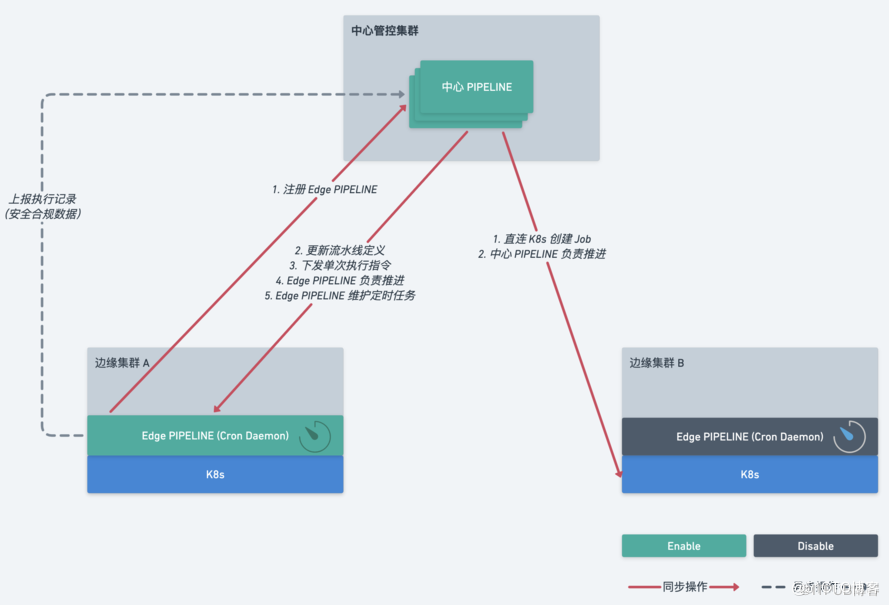
该分布式架构是典型的 AP 模型,数据层面遵循最终一致性。
这套分布式架构的核心目标(典型场景)是在网络分区的情况下,保证边缘集群的定时任务正常执行。
我们来对比一下原有部署架构(运行时以 K8s 为例):
- 中心 Pipeline 直接负责流程推进,调用边缘 K8s 创建 Job。
- 当网络分区时,原有部署架构下,定时任务无法正常执行。
分布式架构:
- 中心下发任务定义,由 Edge Pipeline 负责推进,直连 K8s,更加稳定。
- 在网络分区恢复时,主动上报执行数据,实现数据最终一致性。
在代码层面,我们使用同一份代码构建出同一个镜像,通过配置(不同的部署模式)使得各个实例各司其职。
另外,在数据同步时,我们遇到了前端 JavaScript Number 类型 53位最大值问题,对 SnowFlake ID 进行了 64bit -> 53bit 的改造,在保证唯一性的前提下,尽可能地增加可用性(生命周期约为 10 年,同时支持 4096 个分布式节点,每 10ms 可生成 64 个 ID)。
这里简单列举一些比较常见的功能特性:
- 配置即代码
- 扩展市场丰富
- 可视化编辑
- 支持嵌套流水线
- 灵活的执行策略,支持 OnPush / OnMerge 等触发策略
- 支持工作流优先队列
- 多维度的重试机制
- 定时流水线及定时补偿功能
- 动态配置,支持“值”和“文件”两种类型,均支持加密存储,确保数据安全性
- 上下文传递,后置任务可以引用前置任务的“值”和“文件”
- 开放的 OpenAPI 接口,方便第三方系统快速接入
一些实现细节
如何实现上下文传递(值引用)
在一条流水线中,节点间除了有依赖顺序之外,一定会有数据传递的需求。
值引用:
- 每个节点的特殊输出(按格式写入指定文件或者打印到标准输出)会被保存在 Pipeline 数据库中;
- 后续节点通过 outputs 语法声明的表达式会在节点开始执行前被替换为真正的值。
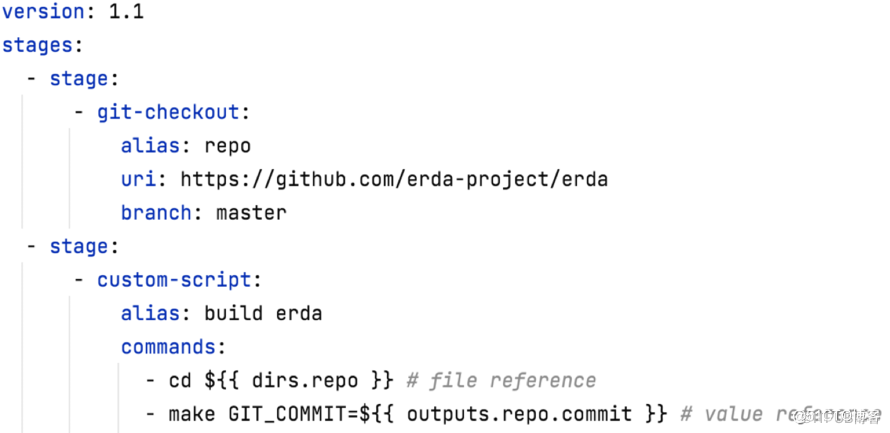
如图所示:第一个节点 repo 拉取代码;第二个节点 build erda 则是构建 Erda 项目。
在例子中,第二步构建时同时用到了 “值引用” 和 “文件引用” 两种引用类型,是进依次入代码仓库,指定 GIT_COMMIT 进行构建。
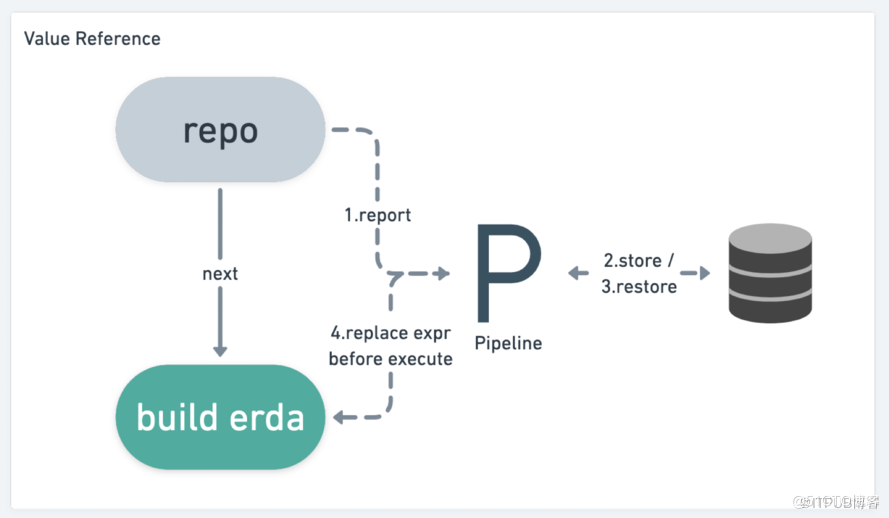
如何实现上下文传递(文件引用)
- 文件引用比值引用复杂,因为文件的数据量比值大得多,不能存储在数据库中,而是存储在卷中。
- 这里又根据是否使用共享存储而分为两种情况,两者的区别在于申请的卷的类型和个数。
- 对于流水线使用者而言,没有任何区别。
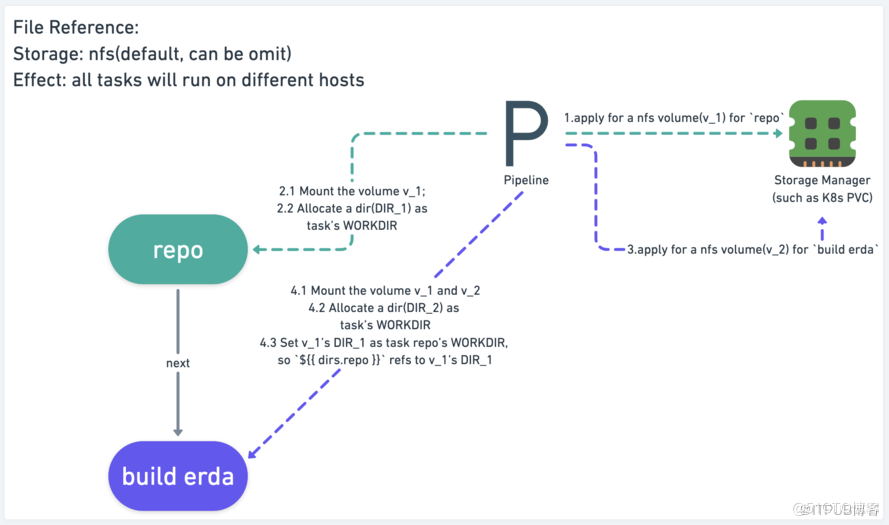
使用共享存储
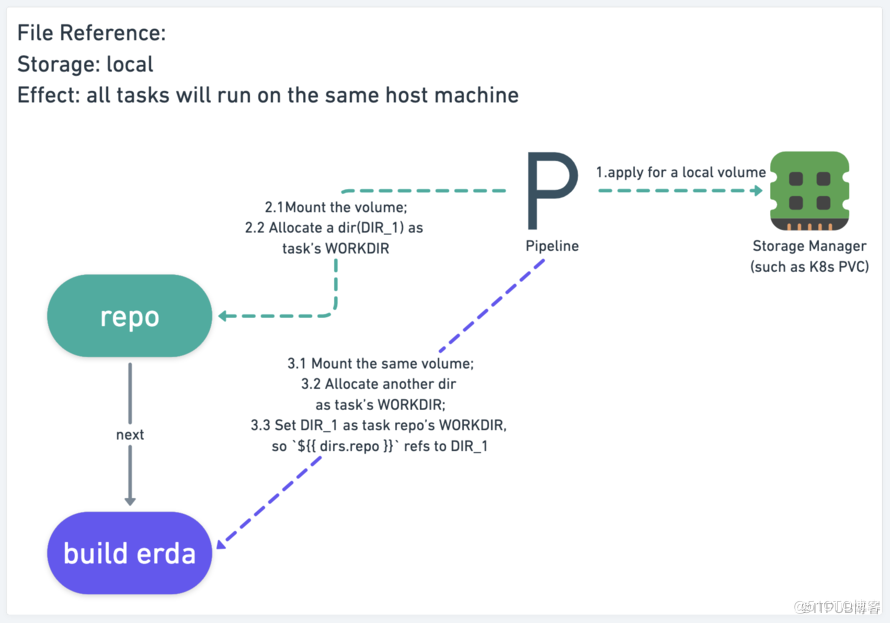
不使用共享存储
如何实现缓存加速
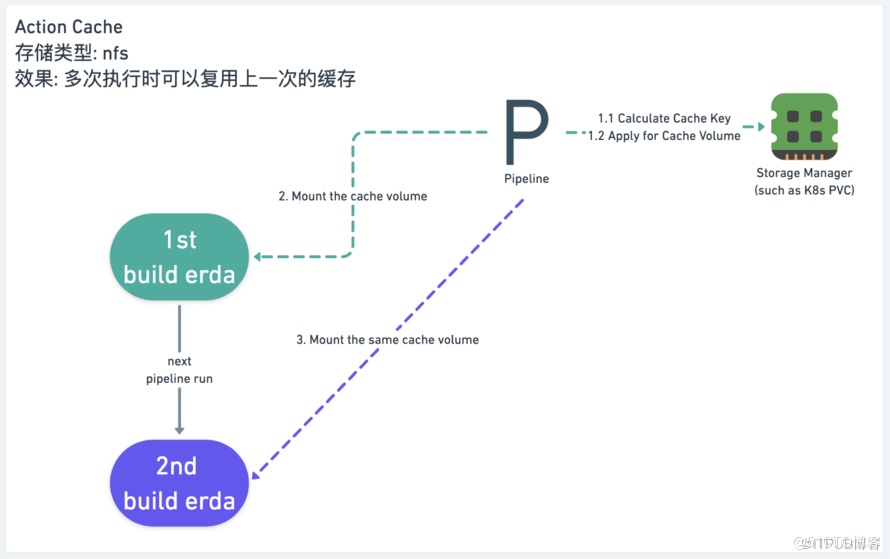
在许多流水线场景中,同一条流水线的多次执行之间是有关联的。如果能够用到上一次的执行结果,则可以大幅缩短执行时间。
典型场景是 CI/CD 构建,我们以 Java 应用 Maven 构建举例:不但同一条流水线不同的多次执行可以复用 ${HOME}/.m2 目录(缓存目录),甚至同一个应用下的多个分支之间都可以使用同一个缓存目录,就像本地构建一样~
举例:
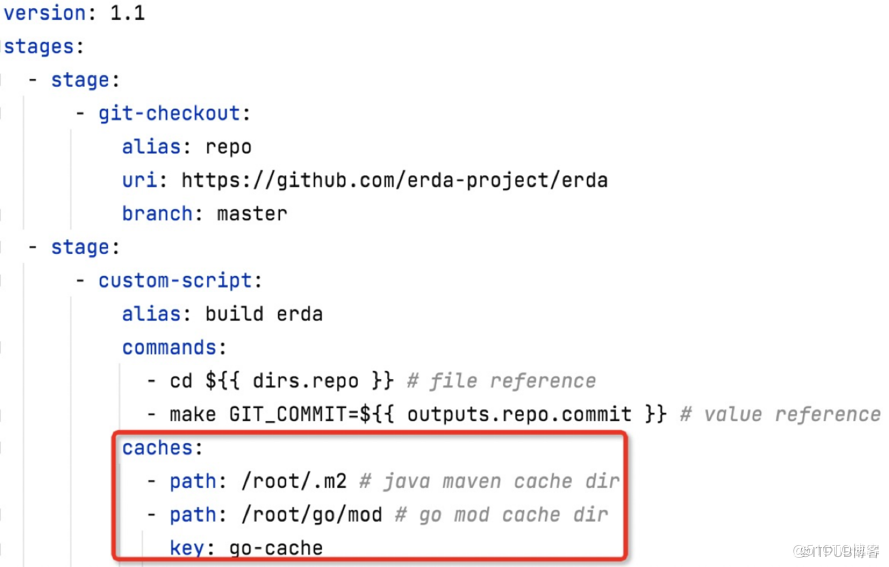
仍然使用前面的例子,在第二步 build erda 里加上 cache 即可。
Action Agent
在 Pipeline 里,每个节点都会对应一个 Action 类型,并且在扩展市场中都可以找到。为了更加方便 Action 开发者进行开发,我们提供了很多便捷的机制。如:
- 对敏感日志进行脱敏处理,保证数据安全
- 无感知的错误分析和数据上报
- 文件变动监听及实时上报
上述所有机制都是由 Action Agent 程序完成的,它是一个静态编译的 Go 程序,可以运行在任意 Action 镜像中。Agent 完整的执行链路如下:

Action Executor 扩展机制
Pipeline 之所以好用,是因为它提供了灵活一致的流程编排能力,并且可以很方便地对接其他单任务执行平台,这个平台本身不需要有流程编排的能力。
在 Pipeline 中,我们对一个任务执行的抽象是 ActionExecutor。一个执行器只要实现单个任务的创建、启动、更新、状态查询、删除等基础方法,就可以注册成为一个 ActionExecutor:
- 恰当的任务执行器抽象,使得 Batch/Streaming/InMemory Job 的配置方式和使用方式完全一致,流批一体,对使用者屏蔽底层细节,做到无感知切换。
- 在同一条流水线中,可以混用各种 ActionExecutor。
调度时,根据任务类型智能调度到对应的任务执行器上,包括 K8sJob、Metronome Job、Flink Job、Spark Job 等等。
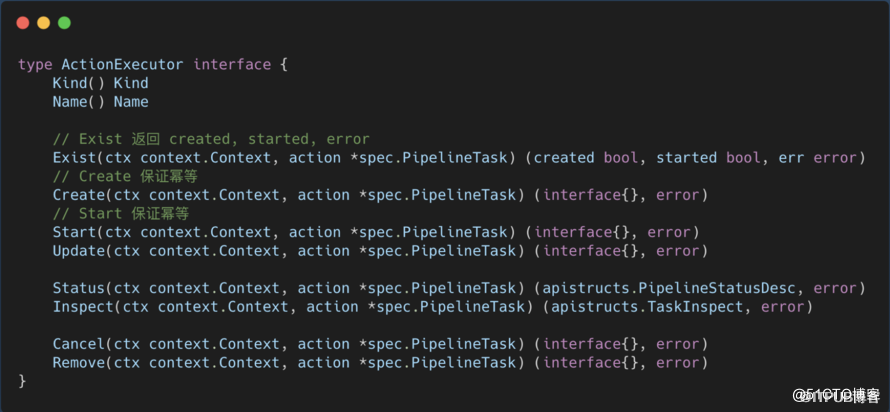
Go 接口定义
AOP 扩展点机制
AOP 扩展点机制是借鉴 Java 里 Spring 的概念应运而生的。
我们把代码关键节点进行暴露,方便开发同学在不修改核心代码的前提下定制流水线行为。AOP 扩展点机制已经使用 Erda Infra 的模块化思想重构,整个扩展点的插件开发和编排更为灵活,如下图所示:
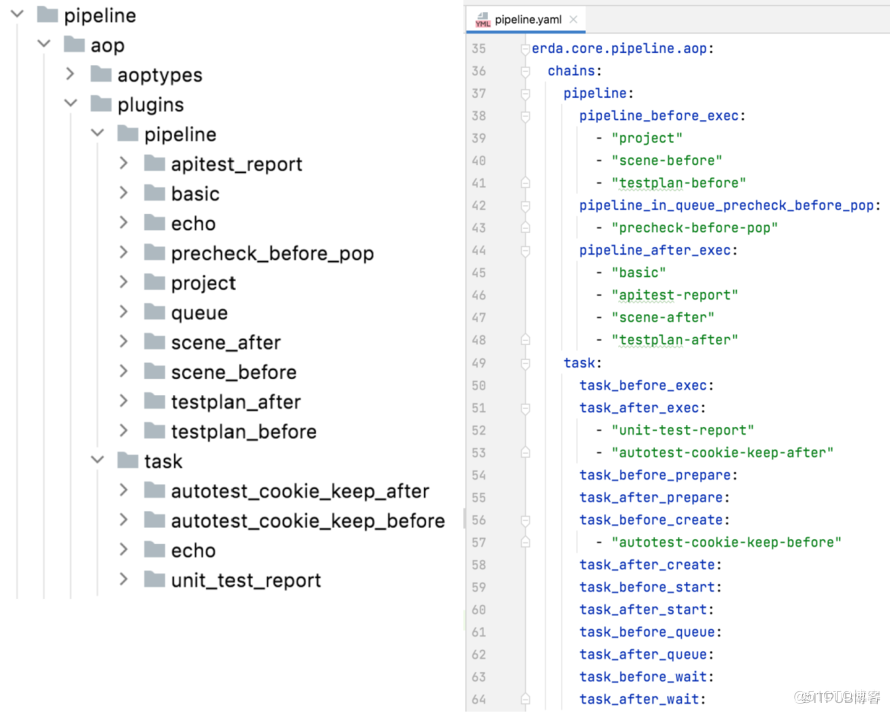
AOP 在 Pipeline 内部的使用
这个能力后续我们还会开放给用户,让用户可以在 pipeline.yaml 中使用编程语言声明和编排扩展点插件,更灵活地控制流水线行为。
我们致力于决社区用户在实际生产环境中反馈的问题和需求,
如果您有任何疑问或建议,
欢迎关注【尔达Erda】公众号给我们留言,
加入 Erda 用户群参与交流或在 Github 上与我们讨论!
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK