

阿里一面:SQL 优化有哪些技巧?
source link: https://www.51cto.com/article/708494.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
大家好,我是 Tom哥
MySQL 相信大家一定都不陌生,但是不陌生不一定会用!
会用不一定能用好!
今天,Tom哥就带大家复习一个高频面试考点,SQL 优化有哪些技巧?
当然这个还是非常有实用价值的,工作中你也一定用的上。如果应用得当,升职加薪,指日可待。
1、创建索引
一定要记得创建索引,创建索引,创建索引
重要的事说三遍!
执行没有索引的 SQL 语句,肯定要走全表扫描,慢是肯定的。
这种查询毫无疑问是一个慢 SQL 查询。
那么问题来了,是不是要收集所有的 where 查询条件,然后针对所有的组合都创建索引呢?
答案肯定是否定的。
MySQL 为了提升数据查询速率,采用 B+ 树结构,通过空间换时间 设计思想。另外每次对表数据做更新操作时,都要调整对应的 索引树 ,执行效率肯定会受影响。
本着二八原则,互联网请求读多写少的特点,我们一定要找到一个平衡点。
阿里巴巴的开发者手册建议,单表索引数量控制在5个以内,组合索引字段数不允许超过5个。
其他建议:
- 禁止给表中的每一列都建立单独的索引
- 每个Innodb表必须有个主键
- 要注意组合索引的字段的顺序
- 优先考虑覆盖索引
- 避免使用外键约束
2、避免索引失效
不要以为有了索引,就万事大吉。
殊不知,索引失效 也是慢查询的主要原因之一。
常见的索引失效的场景有哪些?
- 以 % 开头的 LIKE 查询。
- 创建了组合索引,但查询条件不满足 '最左匹配原则'。如:创建索引 。idx_type_status_uid(type,status,uid),但是使用 status 和 uid 作为查询条件。
- 查询条件中使用 or,且 or 的前后条件中有一个列没有索引,涉及的索引都不会被使用到。
- 在索引列上的操作,函数 upper()等,or、!= (<>),not in 等。
3、锁粒度
MySQL 的存储引擎分为两大类:MyISAM 和 InnoDB 。
MyISAM 支持表锁;InnoDB 支持行锁和表锁。
更新操作时,为了保证表数据的准确性,通常会加锁,为了提高系统的高并发能力,我们通常建议采用 行锁,减少锁冲突、锁等待 的时间。所以,存储引擎通常会选择 InnoDB。
行锁可能会升级为表锁,有哪些场景呢?
- 如果一个表批量更新,大量使用行锁,可能导致其他事务长时间等待,严重影响事务的执行效率。此时,MySQL会将 行锁 升级为 表锁。
- 行锁是针对索引加的锁,如果 条件索引失效,那么 行锁 也会升级为 表锁。
注意:行锁将锁的粒度缩小了,进而提高了系统的并发能力。但是也有个弊端,可能会产生死锁,需要特别关注。
4、分页查询优化
如果要开发一个列表展示页面并支持翻页时,我们通常会这样写 SQL。
select * from 表 limit #{start}, #{pageSize};随着翻页的深度加大, start 值越来越大,比如:limit 10000 ,10。
看似只返回了 10 条数据,但数据库引擎需要查询 10010 条记录,然后将前面的 10000 条丢弃,最终只返回最后的 10 条记录,性能可想而知。
针对这个问题,我们通常有另一种解决方案:
先定位到上一次分页的最大 id,然后对 id 做条件索引查询。由于数据库的索引采用 B+ 树结构,这样可以一步到位。
select * from 表 where id > #{id} limit #{pageSize};任何事情,有利就有弊。
这种翻页方式只支持 上一页、下一页 ,不支持跨越式直梯翻页。
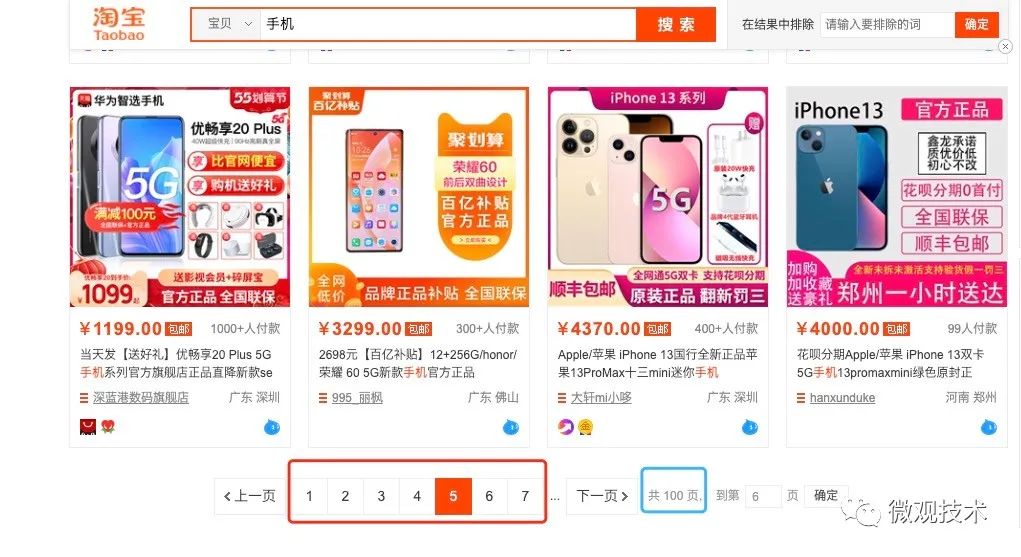
上图是淘宝的商品搜索列表,为了用户体验更好,采用的也是 直梯式翻页。
为了避免翻页过深,影响性能,产品交互上做了一些取舍,对总页数做了限制,最多支持 100 页。
方案二:采用子查询
select * from 表 where id > ( select id from 表 order by id limit 10000 1) limit 20;
将原来的单 SQL 查询拆成两步:
- 首先,查询出 一页数据中的最小 id。
- 然后,通过 B+ 树,精确定位到 最小id的索引树节点位置,通过 偏移量 读取后面的 20条 数据。
阿里的规约手册也有对应描述:

5、避免 select *
反面案例:
select * from 表 where buyer_id = #{buyer_id} 我们知道,MySQL 创建表后,具体的行数据存储在主键索引(属于聚簇索引)的叶子节点。
二级索引属于非聚簇索引,其叶子节点存储的是主键值。
select * 的查询过程:
- 先在 buyer_id 的二级索引 B+ 树,查出对应的 主键 id 列表
- 然后进行 回表 操作,在 主键索引中 查询 id 对应的行数据
所以,我们需要罗列清楚必须的查询字段,且字段尽量在 覆盖索引 中,从而减少 回表 操作。
6、EXPLAIN 分析 SQL 执行计划
授人以鱼不如授人以渔。
除了知晓常见的不规范 SQL 写法,在开发过程中,避免踩坑。
我们还应知道,出现了慢 SQL 该如何排查、优化。
实验安排起来。
CREATE TABLE `user` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '自增主键',
`income` bigint(20) NOT NULL COMMENT '收入',
`expend` bigint(20) NOT NULL COMMENT '支出',
PRIMARY KEY (`id`),
KEY `idx_income` (`income`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COMMENT='用户表';
CREATE TABLE `biz_order` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '自增主键',
`user_id` bigint(20) NOT NULL COMMENT '用户id',
`money` bigint(20) NOT NULL COMMENT '金额',
PRIMARY KEY (`id`),
KEY `idx_user_id` (`user_id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COMMENT='订单表';插入记录:
insert into user values(10,100,100);
insert into user values(20,200,200);
insert into user values(30,300,300);
insert into user values(40,400,400);
insert into biz_order values(1,10,30);
insert into biz_order values(2,10,40);
insert into biz_order values(3,10,50);
insert into biz_order values(4,20,10);比如下面的语句,我们看是否使用了索引,可以通过 explain 分析相应的执行计划。
explain select * from user where id<20;
接下来,我们来逐一来说明每个字段的含义
- id:每一次 select 查询都会生成一个 id,值越大,优先级越高,会被优先执行。
- select_type:查询类型,SIMPLE(普通查询,即没有联合查询、子查询)、PRIMARY(主查询)、UNION(UNION 中后面的查询)、SUBQUERY(子查询)等。
- table:查询哪张表。
- partitions:分区,如果对应的表存在分区表,那么这里就会显示具体的分区信息。
- type:执行方式,是 SQL 优化中一个很重要的指标,结果值从好到差依次是:system > const > eq_ref > ref > range > index > ALL。
system/const:表中只有一行数据匹配,此时根据索引查询一次就能找到对应的数据
eq_ref:使用唯一索引扫描,常见于多表连接中使用主键和唯一索引作为关联条件
ref:非唯一索引扫描,还可见于唯一索引最左原则匹配扫描
range:索引范围扫描,比如,<,>,between 等操作
index:索引全表扫描,此时遍历整个索引树
ALL:表示全表扫描,需要遍历全表来找到对应的行- possible_keys:可能用到的索引
- key:实际用到的索引
- key_len:索引长度
- ref:关联 id 等信息
- rows:查找到记录所扫描的行数,SQL 优化重要指标,扫描的行数越少,性能越高
- filtered:查找到所需记录占总扫描记录数的比例
- Extra:额外的信息
explain select * from user u , biz_order b where u.id=b.user_id and
u.id<20;
7、Show Profile 分析 SQL 执行性能
Show Profile 与 EXPLAIN 的区别是,前者主要是在外围分析;后者则是深入到 MySQL 内核,从执行线程的状态和时间来分析。
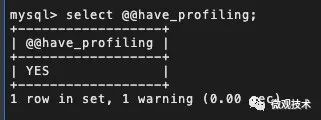
MySQL 是在 5.0.37 版本之后才支持 Show Profile ,select @@have_profiling 返回 YES 表示功能已开启。
mysql> show profiles;
Empty set, 1 warning (0.00 sec)显示为空,说明profiles功能是关闭的。
通过下面命令开启:
mysql> set profiling=1;
Query OK, 0 rows affected, 1 warning (0.00 sec)
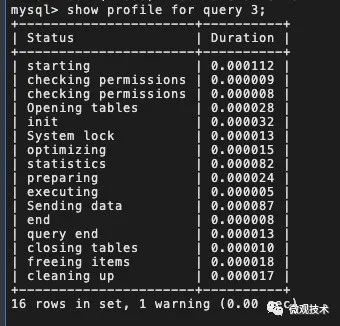
获取 Query_ID 之后,通过 show profile for query ID ,查看 SQL 语句在执行过程中线程的每个状态所消耗的时间。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK