

K8S实战系列:2-Pod、工作负载与服务
source link: https://blog.csdn.net/fly910905/article/details/124369054
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
K8S实战系列:2-Pod、工作负载与服务_琦彦的博客-CSDN博客
容器,其实是一种特殊的进程而已。
现在,你应该可以理解,对 Docker 项目来说,它最核心的原理实际上就是为待创建的用户进程:
- 启用 Linux Namespace 配置;
- 设置指定的 Cgroups 参数;
- 切换进程的根目录(Change Root)
Kubernetes 是云原生时代的操作系统
Kubernetes 项目所做的,其实就是将“进程组”的概念映射到了容器技术中,并使其成为了这个云计算“操作系统”里的“一等公民”。
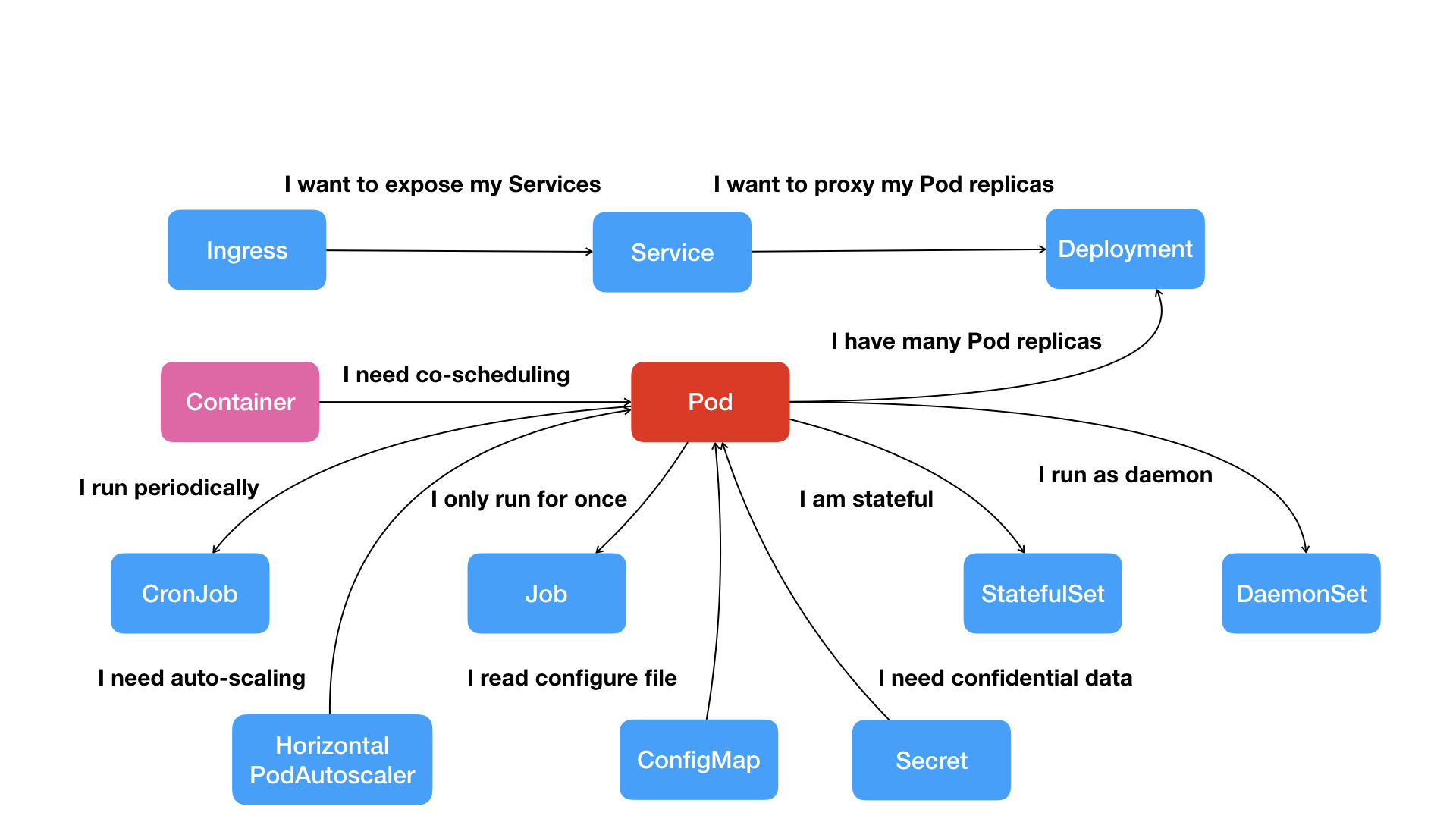
Pod 就是 Kubernetes 世界里的“应用”;而一个应用,可以由多个容器组成。
按照这幅图的线索,我们从容器这个最基础的概念出发,首先遇到了容器间“紧密协作”关系的难题,于是就扩展到了 Pod;
Pod 这个看似复杂的 API 对象,实际上就是对容器的进一步抽象和封装而已。
所以,Pod 对象,其实就是容器的升级版。它对容器进行了组合,添加了更多的属性和字段。这就好比给集装箱四面安装了吊环,使得 Kubernetes 这架“吊车”,可以更轻松地操作它。
在具体实现中,实际状态往往来自于 Kubernetes 集群本身。
比如,kubelet 通过心跳汇报的容器状态和节点状态,或者监控系统中保存的应用监控数据,或者控制器主动收集的它自己感兴趣的信息,这些都是常见的实际状态的来源。
而期望状态,一般来自于用户提交的 YAML 文件。
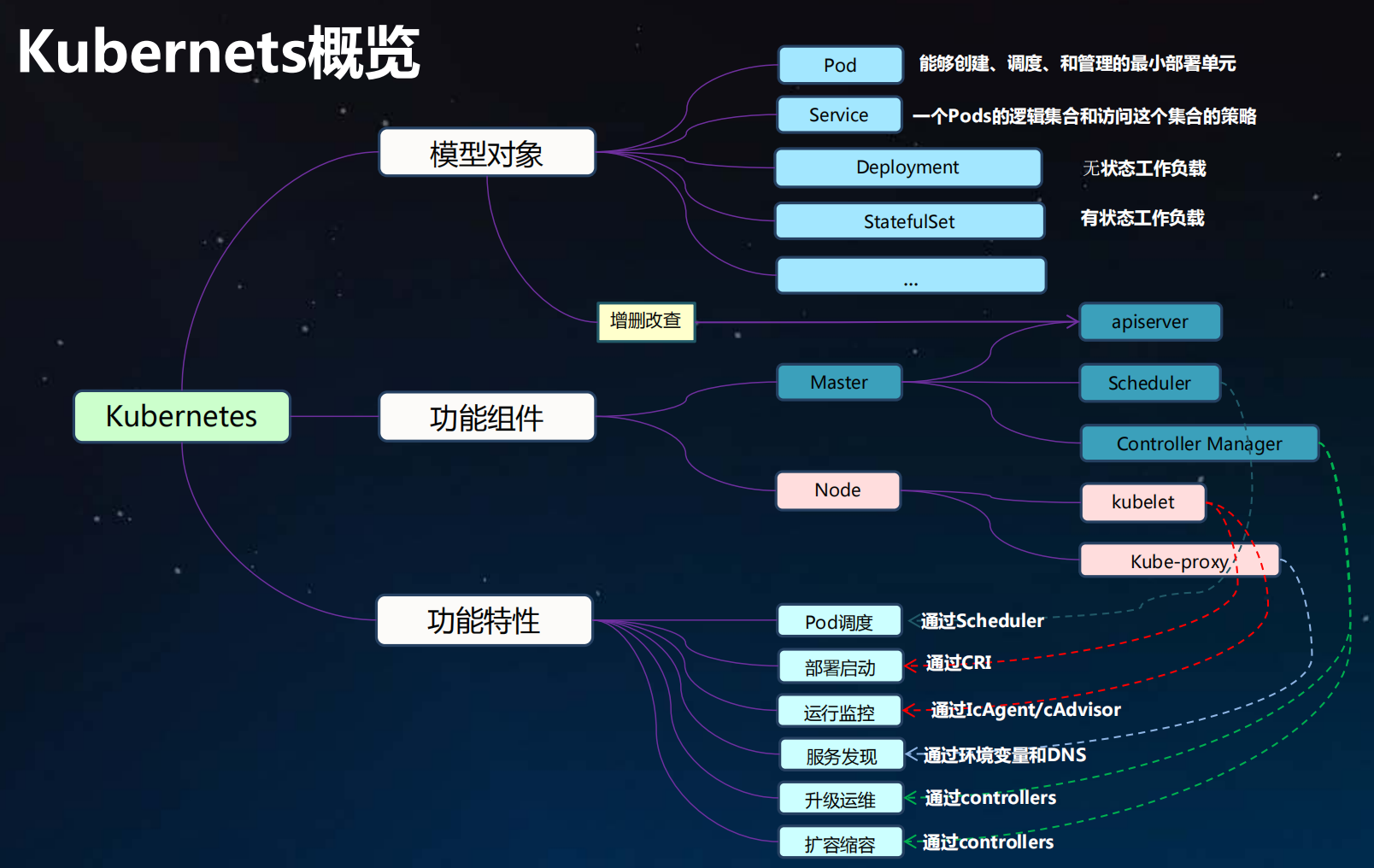
Kubernetes Pod详解
Kubernets概览
Kubernetes关键概念-Pod
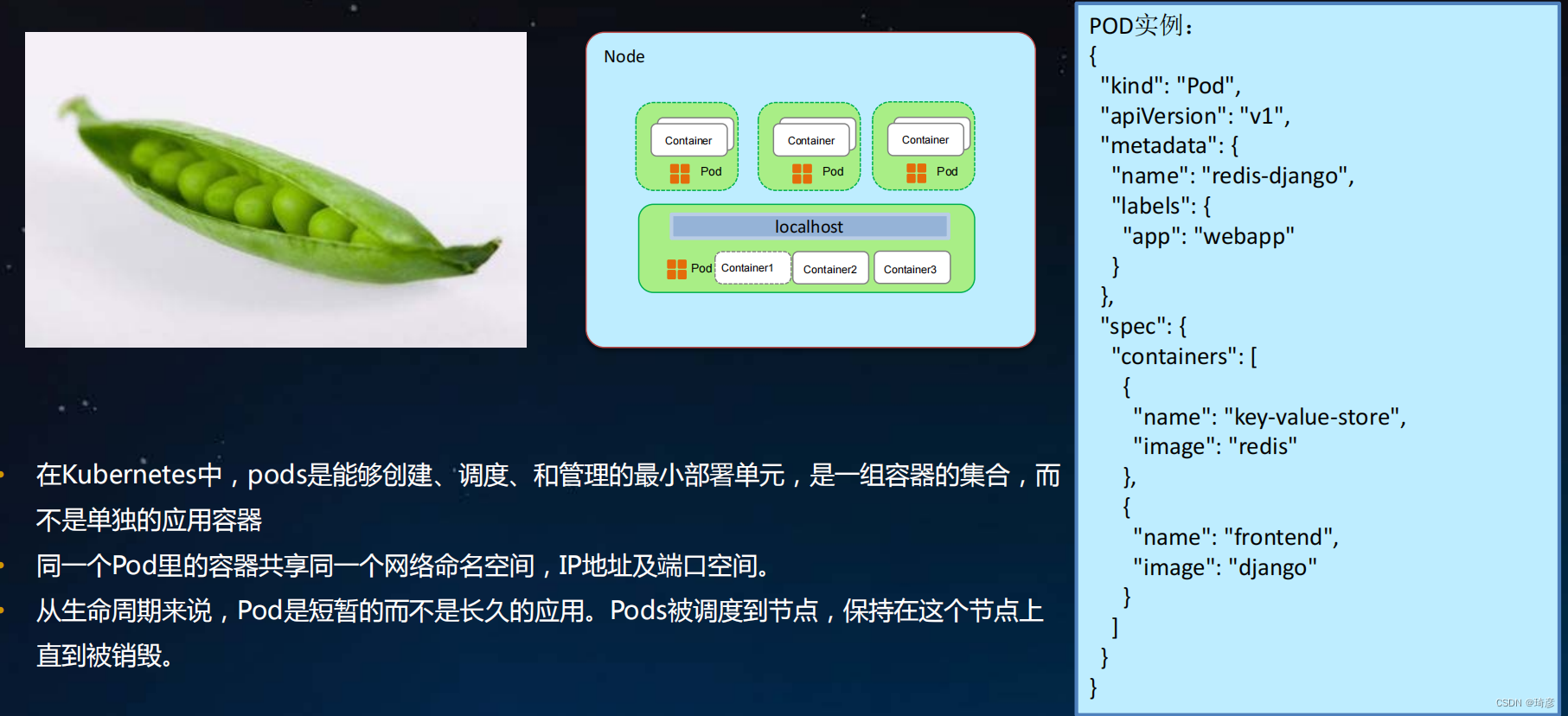
- 在Kubernetes中, pods是能够创建、调度、和管理的最小部署单元,是一组容器的集合,而不是单独的应用容器
- 同一个Pod里的容器共享同一个网络命名空间, IP地址及端口空间。
- 从生命周期来说, Pod是短暂的而不是长久的应用。 Pods被调度到节点,保持在这个节点上直到被销毁。
1. Pod详解-容器
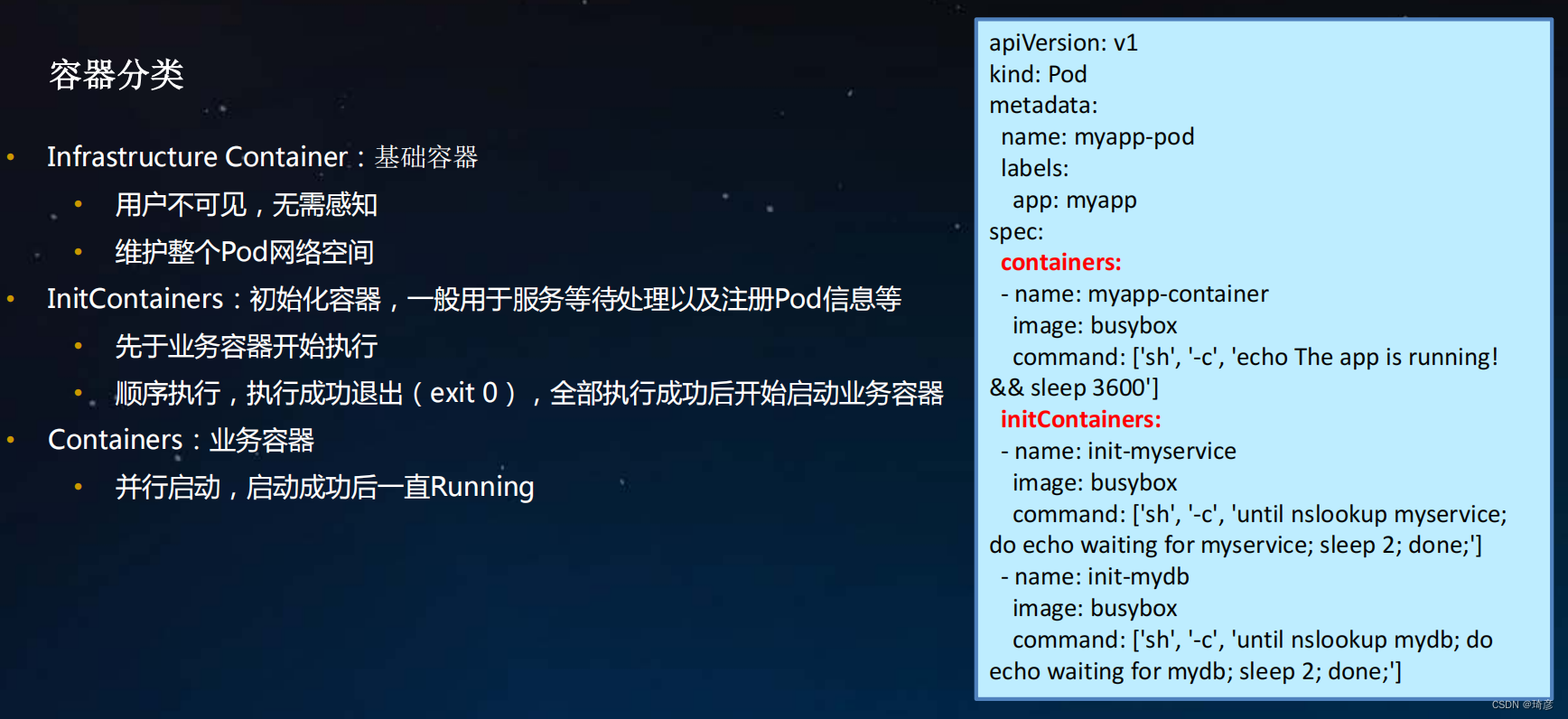
Infrastructure Container: 基础容器
- 用户不可见,无需感知
- 维护整个Pod网络空间
InitContainers:初始化容器,一般用于服务等待处理以及注册Pod信息等
- 先于业务容器开始执行
- 顺序执行,执行成功退出( exit 0),全部执行成功后开始启动业务容器
Containers:业务容器
- 并行启动,启动成功后一直Running
使用 Init 容器
因为 Init 容器具有与应用容器分离的单独镜像,其启动相关代码具有如下优势:
- Init 容器可以包含一些安装过程中应用容器中不存在的实用工具或个性化代码。 例如,没有必要仅为了在安装过程中使用类似
sed、awk、python或dig这样的工具而去FROM一个镜像来生成一个新的镜像。 - Init 容器可以安全地运行这些工具,避免这些工具导致应用镜像的安全性降低。
- 应用镜像的创建者和部署者可以各自独立工作,而没有必要联合构建一个单独的应用镜像。
- Init 容器能以不同于 Pod 内应用容器的文件系统视图运行。因此,Init 容器可以访问 应用容器不能访问的 Secret 的权限。
- 由于 Init 容器必须在应用容器启动之前运行完成,因此 Init 容器 提供了一种机制来阻塞或延迟应用容器的启动,直到满足了一组先决条件。 一旦前置条件满足,Pod 内的所有的应用容器会并行启动。
参考: https://kubernetes.io/zh/docs/concepts/workloads/pods/init-containers/
Init 容器示例
下面是一些如何使用 Init 容器的想法:
-
等待一个 Service 完成创建,通过类似如下 shell 命令:
for i in {1..100}; do sleep 1; if dig myservice; then exit 0; fi; done; exit 1 -
注册这个 Pod 到远程服务器,通过在命令中调用 API,类似如下:
curl -X POST http://$MANAGEMENT_SERVICE_HOST:$MANAGEMENT_SERVICE_PORT/register \ -d 'instance=$(<POD_NAME>)&ip=$(<POD_IP>)' -
在启动应用容器之前等一段时间,使用类似命令:
sleep 60 -
克隆 Git 仓库到卷中。
-
将配置值放到配置文件中,运行模板工具为主应用容器动态地生成配置文件。 例如,在配置文件中存放
POD_IP值,并使用 Jinja 生成主应用配置文件。
容器基本组成

2. Pod详解-资源需求和QoS
资源请求和限制的原理
- spec.containers[].resources.requests.cpu 作用在CpuShares,表示分配cpu 的权重,争抢时的分配比例
- spec.containers[].resources.requests.memory 主要用于kube-scheduler调度器,对容器没有设置意义
- spec.containers[].resources.limits.cpu 作用CpuQuota和CpuPeriod,单位为微秒,计算方法为:CpuQuota/CpuPeriod,表示最大cpu最大可使用的百分比,如500m表示允许使用1个cpu中的50%资源
- spec.containers[].resources.limits.memory 作用在Memory,表示容器最大可用内存大小,超过则会OOM
以下面定义的cpu-mem-request-limit.yaml为例,研究下pod中定义的requests和limits应用在docker生效的参数:
apiVersion: v1
kind: Pod
metadata:
name: cpu-mem-request-limit
namespace: fly-test
labels:
name: cpu-mem-request-limit
spec:
containers:
- name: cpu-mem-request-limit
image: nginx:1.7.9
imagePullPolicy: IfNotPresent
ports:
- name: nginx-port-80
protocol: TCP
containerPort: 80
resources:
requests:
cpu: 0.25
memory: 128Mi
limits:
cpu: 500m
memory: 256Mi
1、获取容器的id号,可以通过kubectl describe pods cpu-mem-request-limit的containerID获取到容器的id,或者登陆到node-3节点通过名称过滤获取到容器的id号,默认会有两个pod:一个通过pause镜像创建,另外一个通过应用镜像创建
[root@gv41New95 2-pod-resource]# docker container list | grep cpu-mem-request-limit
d9b2a8b67fea 84581e99d807 "nginx -g 'daemon of…" About a minute ago Up 59 seconds k8s_cpu-mem-request-limit_cpu-mem-request-limit_fly-test_3cd9ea76-259b-4b64-98f2-ff61c8965cb5_0
ec09131f6e05 registry.aliyuncs.com/google_containers/pause:3.2 "/pause" About a minute ago Up 59 seconds k8s_POD_cpu-mem-request-limit_fly-test_3cd9ea76-259b-4b64-98f2-ff61c8965cb5_0
2、查看docker容器详情信息
[root@node-3 ~]# docker container inspect d9b2a8b67fea
[
{
"Image": "sha256:84581e99d807a703c9c03bd1a31cd9621815155ac72a7365fd02311264512656",
"ResolvConfPath": "/var/lib/docker/containers/2fe0498ea9b5dfe1eb63eba09b1598a8dfd60ef046562525da4dcf7903a25250/resolv.conf",
"HostConfig": {
"Binds": [
"/var/lib/kubelet/pods/66958ef7-507a-41cd-a688-7a4976c6a71e/volumes/kubernetes.io~secret/default-token-5qwmc:/var/run/secrets/kubernetes.io/serviceaccount:ro",
"/var/lib/kubelet/pods/66958ef7-507a-41cd-a688-7a4976c6a71e/etc-hosts:/etc/hosts",
"/var/lib/kubelet/pods/66958ef7-507a-41cd-a688-7a4976c6a71e/containers/ cpu-mem-request-limit/1cc072ca:/dev/termination-log"
],
"ContainerIDFile": "",
"LogConfig": {
"Type": "json-file",
"Config": {
"max-size": "100m"
}
},
"UTSMode": "",
"UsernsMode": "",
"ShmSize": 67108864,
"Runtime": "runc",
"ConsoleSize": [
0,
0
],
"Isolation": "",
"CpuShares": 256, CPU分配的权重,作用在requests.cpu上
"Memory": 268435456, 内存分配的大小,作用在limits.memory上
"NanoCpus": 0,
"CgroupParent": "kubepods-burstable-pod66958ef7_507a_41cd_a688_7a4976c6a71e.slice",
"BlkioWeight": 0,
"BlkioWeightDevice": null,
"BlkioDeviceReadBps": null,
"BlkioDeviceWriteBps": null,
"BlkioDeviceReadIOps": null,
"BlkioDeviceWriteIOps": null,
"CpuPeriod": 100000, CPU分配的使用比例,和CpuQuota一起作用在limits.cpu上
"CpuQuota": 50000,
"CpuRealtimePeriod": 0,
"CpuRealtimeRuntime": 0,
"CpusetCpus": "",
"CpusetMems": "",
"Devices": [],
"DeviceCgroupRules": null,
"DiskQuota": 0,
"KernelMemory": 0,
"MemoryReservation": 0,
"MemorySwap": 268435456,
"MemorySwappiness": null,
"OomKillDisable": false,
"PidsLimit": 0,
"Ulimits": null,
"CpuCount": 0,
"CpuPercent": 0,
"IOMaximumIOps": 0,
"IOMaximumBandwidth": 0,
},
}
]
CPU period 则是默认的 100 ms(100000 us)
CPU quota 如果没有任何限制(即:-1)
CPU和内存请求和限制的目的
通过为集群中运行的容器配置CPU和内存请求和限制,你可以有效利用集群节点上可用的CPU和内存资源。 通过将 Pod 的CPU和内存请求保持在较低水平,你可以更好地安排 Pod 调度。 通过让CPU和内存限制大于CPU和内存请求,你可以完成两件事:
- Pod 可以进行一些突发活动,从而更好的利用可用CPU和内存。
- Pod 在突发活动期间,可使用的CPU和内存被限制为合理的数量。
如果你没有指定CPU和内存限制
如果你没有为一个容器指定内存限制,则自动遵循以下情况之一:
- 容器可无限制地使用CPU和内存。容器可以使用其所在节点所有的可用CPU和内存, 进而可能导致该节点调用 OOM Killer。 此外,如果发生 OOM Kill,没有资源限制的容器将被杀掉的可行性更大。
- 运行的容器所在命名空间有默认的CPU和内存限制,那么该容器会被自动分配默认限制。 集群管理员可用使用 LimitRange 来指定默认的内存限制。
如果你设置了 CPU 限制和内存但未设置 CPU 请求和内存
如果你为容器指定了 CPU 限制值但未为其设置 CPU 请求,Kubernetes 会自动为其 设置与 CPU 限制相同的 CPU 请求值。
类似的,如果容器设置了内存限制值但未设置 内存请求值,Kubernetes 也会为其设置与内存限制值相同的内存请求。
https://kubernetes.io/zh/docs/tasks/configure-pod-container/assign-memory-resource/
https://kubernetes.io/zh/docs/tasks/configure-pod-container/assign-cpu-resource/
QoS 类为 Guaranteed的 Pod
- Pod 中的每个容器都必须指定内存限制和内存请求。
- 对于 Pod 中的每个容器,内存限制必须等于内存请求。
- Pod 中的每个容器都必须指定 CPU 限制和 CPU 请求。
- 对于 Pod 中的每个容器,CPU 限制必须等于 CPU 请求。
limits:
memory: "200Mi"
cpu: "700m"
requests:
memory: "200Mi"
cpu: "700m"
QoS 类为 Burstable 的 Pod
-
Pod 不符合 Guaranteed QoS 类的标准。
-
Pod 中至少一个容器具有内存或 CPU 请求。
resources:
limits:
memory: "200Mi"
requests:
memory: "100Mi"
QoS 类为 BestEffort 的 Pod
没有设置内存和 CPU 限制或请求
不同的 QoS 表现
不同的 Qos 在调度和底层表现有什么样的不同?

不同的 Qos,它其实在调度和底层表现上都有一些不一样。比如说调度表现, 调度器只会使用 request 进行调度,也就是不管你配了多大的 limit,它都不会进行调度使用,它只会使用 request 进行调度。
在底层上,不同的 Qos 表现更不相同。比如说 CPU,它其实是按 request 来划分权重的,不同的 Qos,它的 request 是完全不一样的,比如说像 Burstable 和 BestEffort,它可能 request 可以填很小的数字或者不填,这样的话,它的权重其实是非常低的。像 BestEffort,它的权重可能是只有 2,而 Burstable 或 Guaranteed,它的权重可以多到几千。
另外,当我们开启了 kubelet 的一个特性,叫 cpu-manager-policy=static 的时候,我们 Guaranteed Qos,如果它的 request 是一个整数的话,比如说配了 2,它会对 Guaranteed Pod 进行绑核。也就是具体像下面这个例子,它分配 CPU0 和 CPU1 给 Guaranteed Pod。
https://www.yuque.com/u974625/ogyvd1/oh9igq
QoS 应用场景之一:Eviction
Kubernetes 为 Pod 设置这样三种 QoS 类别,具体有什么作用呢?
实际上,QoS 划分的主要应用场景,是当宿主机资源紧张的时候,kubelet 对 Pod 进行 Eviction(即资源回收)时需要用到的。
具体地说,当 Kubernetes 所管理的宿主机上不可压缩资源短缺时,就有可能触发 Eviction。比如,可用内存(memory.available)、可用的宿主机磁盘空间(nodefs.available),以及容器运行时镜像存储空间(imagefs.available)等等。
目前,Kubernetes 为你设置的 Eviction 的默认阈值如下所示:
memory.available<100Mi
nodefs.available<10%
nodefs.inodesFree<5%
imagefs.available<15%
当然,上述各个触发条件在 kubelet 里都是可配置的。比如下面这个例子:
kubelet --eviction-hard=imagefs.available<10%,
memory.available<500Mi,
nodefs.available<5%,
nodefs.inodesFree<5%
--eviction-soft=imagefs.available<30%,nodefs.available<10%
--eviction-soft-grace-period=imagefs.available=2m,nodefs.available=2m
--eviction-max-pod-grace-period=600
在这个配置中,你可以看到Eviction 在 Kubernetes 里其实分为 Soft 和 Hard 两种模式。
其中,Soft Eviction 允许你为 Eviction 过程设置一段“优雅时间”,比如上面例子里的 imagefs.available=2m,就意味着当 imagefs 不足的阈值达到 2 分钟之后,kubelet 才会开始 Eviction 的过程。
而 Hard Eviction 模式下,Eviction 过程就会在阈值达到之后立刻开始。
Kubernetes 计算 Eviction 阈值的数据来源,主要依赖于从 Cgroups 读取到的值,以及使用 cAdvisor 监控到的数据。
当宿主机的 Eviction 阈值达到后,就会进入 MemoryPressure 或者 DiskPressure 状态,从而避免新的 Pod 被调度到这台宿主机上。
而当 Eviction 发生的时候,kubelet 具体会挑选哪些 Pod 进行删除操作,就需要参考这些 Pod 的 QoS 类别了。
- 首当其冲的,自然是 BestEffort 类别的 Pod。
- 其次,是属于 Burstable 类别、并且发生“饥饿”的资源使用量已经超出了 requests 的 Pod。
- 最后,才是 Guaranteed 类别。并且,Kubernetes 会保证只有当 Guaranteed 类别的 Pod 的资源使用量超过了其 limits 的限制,或者宿主机本身正处于 Memory Pressure 状态时,Guaranteed 的 Pod 才可能被选中进行 Eviction 操作。
当然,对于同 QoS 类别的 Pod 来说,Kubernetes 还会根据 Pod 的优先级来进行进一步地排序和选择。
资源配额的工作方式:
- 不同的团队可以在不同的命名空间下工作,目前这是非约束性的,在未来的版本中可能会通过 ACL (Access Control List 访问控制列表) 来实现强制性约束。
- 集群管理员可以为每个命名空间创建一个或多个 ResourceQuota 对象。
- 当用户在命名空间下创建资源(如 Pod、Service 等)时,Kubernetes 的配额系统会 跟踪集群的资源使用情况,以确保使用的资源用量不超过 ResourceQuota 中定义的硬性资源限额。
- 如果资源创建或者更新请求违反了配额约束,那么该请求会报错(HTTP 403 FORBIDDEN), 并在消息中给出有可能违反的约束。
- 如果命名空间下的计算资源 (如
cpu和memory)的配额被启用,则用户必须为 这些资源设定请求值(request)和约束值(limit),否则配额系统将拒绝 Pod 的创建。 提示: 可使用LimitRanger准入控制器来为没有设置计算资源需求的 Pod 设置默认值。
如何满足 Pod 资源要求?
上面介绍完了基础资源的使用方式,也就是我们做到了如何满足 Pod 资源要求。下面做一个小结:
-
Pod 要配置合理的资源要求
-
CPU/Memory/EphemeralStorage/GPU
- 第一类是 CPU 资源;
- 第二类是 memory;
- 第三类是 ephemeral-storage,一种临时存储;
- 第四类是通用的扩展资源,比如说像 GPU
**在扩展资源上,Kubernetes 有一个要求,即扩展资源必须是整数的,所以我们没法申请到 0.5 的 GPU 这样的资源,只能申请 1 个 GPU 或者 2 个 GPU。**可以借助社区方案。
-
-
通过 Request 和 Limit 来为不同业务特点的 Pod 选择不同的 QoS
-
Guaranteed:敏感型,需要业务保障;
是一类高的 Qos Class,一般用 Guaranteed 来为一些需要资源保障能力的 pod 进行配置;
-
Burstable:次敏感型,需要弹性业务
中等的一个 Qos label,一般会为一些希望有弹性能力的 pod 来配置 Burstable;
-
BestEffort:可容忍性业务(尽力而为)
是一种尽力而为式的服务质量
-
资源请求和限制的生产建议
- requests和limits资源定义推荐不超过1:2,避免分配过多资源而出现资源争抢,发生OOM;
- pod中默认没有定义resource,推荐给namespace定义一个limitrange,确保pod能分到资源;
- 防止node上资源过度而出现机器hang住或者OOM,建议node上设置保留和驱逐资源,如保留资源–system-reserved=cpu=200m,memory=1G,驱逐条件–eviction hard=memory.available<500Mi。
3. Pod详解-健康检查

三种探针Probe
应用在运行过程中难免会出现错误,如程序异常,软件异常,硬件故障,网络故障等,kubernetes提供Health Check健康检查机制,当发现应用异常时会自动重启容器,将应用从service服务中剔除,保障应用的高可用性。k8s定义了三种探针Probe:
- liveness probes 在线检查机制,检查应用是否可用,如死锁,无法响应,异常时会自动重启容器; 用于存活检查,检查容器内部运行状态
- readiness probes 准备就绪检查,通过readiness是否准备接受流量,准备完毕加入到endpoint,否则剔除; 用于健康检查和服务探测机制
- startup probes 启动检查机制,应用一些启动缓慢的业务,避免业务长时间启动而被前面的探针kill掉
三种健康检查方法
每种探测机制支持三种健康检查方法,分别是命令行exec,httpGet和tcpSocket,其中exec通用性最强,适用与大部分场景,tcpSocket适用于TCP业务,httpGet适用于web业务。
- exec 提供命令或shell的检测,在容器中执行命令检查,返回码为0健康,非0异常
- httpGet http协议探测,在容器中发送http请求,根据http返回码判断业务健康情况
- tcpSocket tcp协议探测,向容器发送tcp建立连接,能建立则说明正常(端口存在,不应当服务正常,此时可能是处于Listen状态,可以借助httpGet判断业务健康情况 )
exec:在容器内执行命令,如果命令的退出状态码是 0 表示执行成功,否则表示失败
lifecycle:
postStart:
exec:
command:
- cat
- /tmp/healthy
httpGet:向指定 URL 发起 GET 请求,如果返回的 HTTP 状态码在 [200, 400) 之间表示请求成功,否则表示失败
lifecycle:
postStart:
httpGet:
path: /login # URI地址
port: 80 # 端口号
host: 192.168.126.100 # 主机地址
scheme: HTTP # 支持的协议,http或https
TCPSocket:在容器尝试访问指定的socket
lifecycle:
postStart:
tcpSocket:
port: 8080
配置探测器
Probe 有很多配置字段,可以使用这些字段精确地控制活跃和就绪检测的行为:
initialDelaySeconds:容器启动后要等待多少秒后才启动存活和就绪探测器, 默认是 0 秒,最小值是 0。periodSeconds:执行探测的时间间隔(单位是秒)。默认是 10 秒。最小值是 1。timeoutSeconds:探测的超时后等待多少秒。默认值是 1 秒。最小值是 1。successThreshold:探测器在失败后,被视为成功的最小连续成功数。默认值是 1。 存活和启动探测的这个值必须是 1。最小值是 1。failureThreshold:当探测失败时,Kubernetes 的重试次数。 对存活探测而言,放弃就意味着重新启动容器。 对就绪探测而言,放弃意味着 Pod 会被打上未就绪的标签。默认值是 3。最小值是 1。
我们应该怎么做?
- 对于提供 HTTP 协议(REST 服务等)的微服务,
始终定义一个ReadinessProbe,用于检查的应用程序(Pod)是否已准备好接收流量。 - 对于
慢启动的应用,我们应该使用StartupProbe,来防止容器没有启动,就被LivenessProbe杀死了。 - 如果
服务是多端口的,请确保ReadinessProbe覆盖了所有的端口。例如:为readinessProbe使用“admin”或“management”端口(例如
9090)时,请确保端点仅在主要 HTTP 端口(例如 8080)准备好接受流量时才返回 success. - 使用httpGet对服务端口与路径(例如 /health)进行就绪探测。
我们不应该怎么做?
不要依赖外部依赖项(如数据存储)进行就绪/探活检查,因为这可能会导致级联故障
- 假如10 个pod的服务,数据库使用Postgres,缓存使用redis:当你的探针的路径依赖于工作的redis连接时,如果出现redis/网络故障,则所有 10 个 Pod 都将“重启”——这通常会产生影响比它应该的更糟。因为服务还能到Postgres拿去数据。
- 服务最好不要与数据库做强依赖。
- 只探测自己内部的端口,不要去探测外部pod的端口。探测器不应依赖于同一集群中其他 Pod 的状态,以防止级联故障。
需要明确知道使用 Liveness Probe 的原因,否则不要为 Pod 使用 Liveness Probe。
- Liveness Probe
可以帮助恢复“卡住”的容器,但是当我们能控制我们的应用程序,出现意料之外的“卡住”进程和死锁之类的故障,更好的选择是从应用内部故意崩溃以恢复到已知良好状态。 -
失败的 Liveness Probe 将导致容器重启,从而可能使与负载相关的错误的影响变得更糟:容器重启将导致停机(至少的应用程序的启动时间,例如
30s+),从而导致更多错误并为其他容器提供更多流量负载,导致更多失败的容器,等等 -
Liveness Probes 与外部依赖相结合是导致级联故障的最坏情况:单个环境的小问题将重新启动所有容器。
如果使用 LivenessProbe,请不要为LivenessProbe和ReadinessProbe设置相同的规范
- 可以使用具有相同运行状况检查但具有更高failureThreshold的 Liveness Probe (例如,在 3
次尝试后标记为未就绪,在 10 次尝试后将 Liveness Probe 标记为失败)
不要使用“exec”探测器,它们存在导致僵尸进程的。因为我们写的应用进程很大一部分不会解决依附在主进程上的进程的
- 为 Web 应用程序使用ReadinessProbe来决定 Pod 何时应接收流量 不正确
- 使用Readiness/LivenessProbes可能导致可用性降低和级联故障
- 对于慢启动 的应用,我们应该使用StartupProbe
参考:https://kubernetes.io/zh/docs/tasks/configure-pod-container/configure-liveness-readiness-startup-probes/
4. Pod详解-配置文件
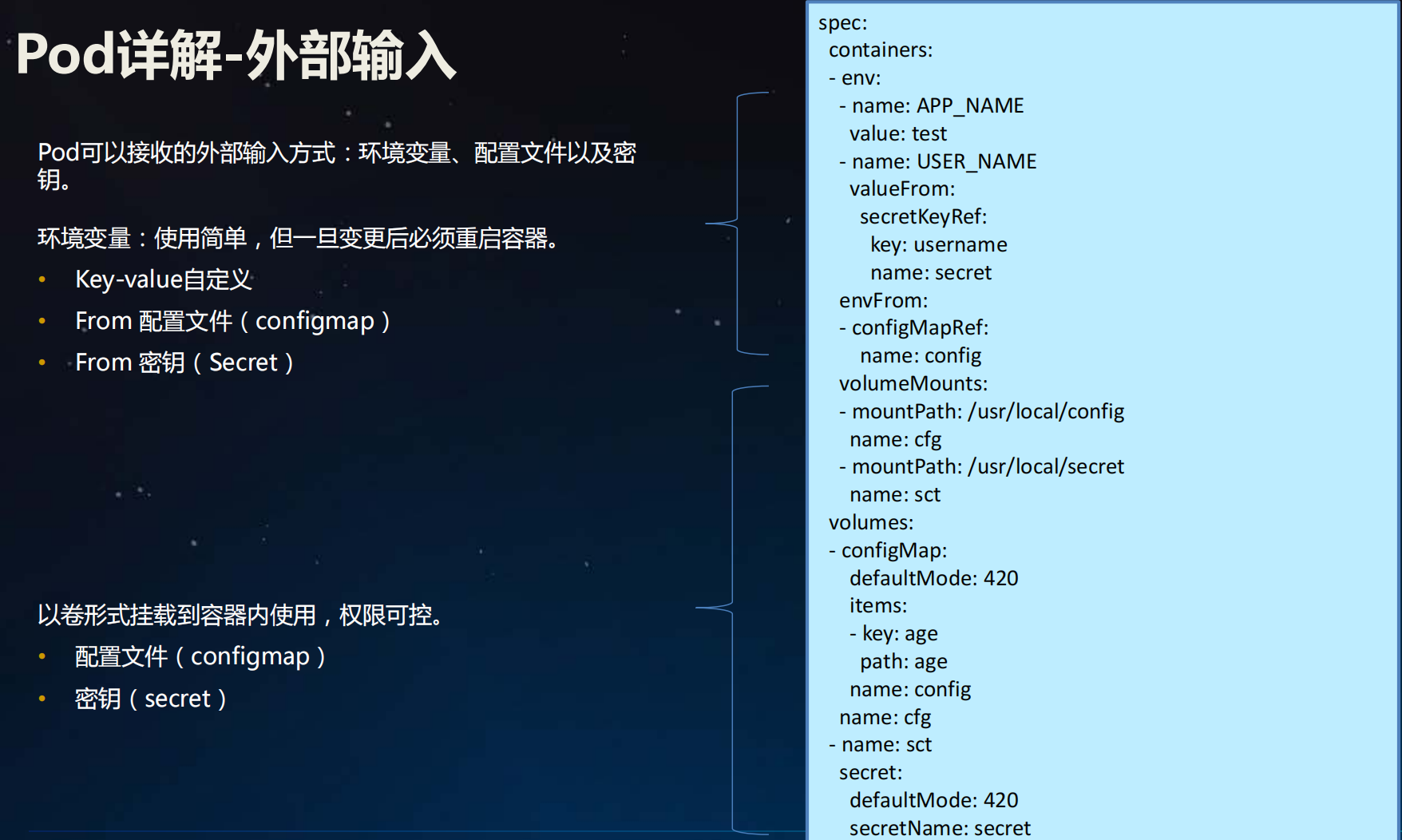
配置文件( ConfigMap)及密钥( Secret)介绍

配置文件( ConfigMap)
cat game.properties
#configmap from file
#
kubectl create configmap game-config --from-file=game.properties
kubectl create configmap game-env-config --from-env-file=game.properties
kubectl get configmap -oyaml game-config
在使用 --from-file 参数时,你可以定义在 ConfigMap 的 data 部分出现键名, 而不是按默认行为使用文件名:
kubectl create configmap game-config-3 --from-file=<我的键名>=<文件路径>
当 kubectl 基于非 ASCII 或 UTF-8 的输入创建 ConfigMap 时, 该工具将这些输入放入 ConfigMap 的 binaryData 字段,而不是 data 中。 同一个 ConfigMap 中可同时包含文本数据和二进制数据源。 如果你想查看 ConfigMap 中的 binaryData 键(及其值), 你可以运行 kubectl get configmap -o jsonpath='{.binaryData}' <name>。
使用 --from-env-file 选项从环境文件创建 ConfigMap,例如:
Env 文件包含环境变量列表。其中适用以下语法规则:
- Env 文件中的每一行必须为 VAR=VAL 格式。
- 以#开头的行(即注释)将被忽略。
- 空行将被忽略。
- 引号不会被特殊处理(即它们将成为
- ConfigMap 值的一部分)。
ConfigMap from literal
kubectl create configmap special-config --from-literal=special.how=very --from-literal=special.type=charm
#downward api pod
kubectl create -f downward-api-pod.yaml
kubectl get po downward-api-pod
kubectl logs -f downward-api-pod
密钥( Secret)
被挂载的 ConfigMap 内容会被自动更新
当卷中使用的 ConfigMap 被更新时,所投射的键最终也会被更新。 kubelet 组件会在每次周期性同步时检查所挂载的 ConfigMap 是否为最新。 不过,kubelet 使用的是其本地的高速缓存来获得 ConfigMap 的当前值。 高速缓存的类型可以通过 KubeletConfiguration 结构. 的 ConfigMapAndSecretChangeDetectionStrategy 字段来配置。
ConfigMap 既可以通过 watch 操作实现内容传播(默认形式),也可实现基于 TTL 的缓存,还可以直接经过所有请求重定向到 API 服务器。 因此,从 ConfigMap 被更新的那一刻算起,到新的主键被投射到 Pod 中去, 这一时间跨度可能与 kubelet 的同步周期加上高速缓存的传播延迟相等。 这里的传播延迟取决于所选的高速缓存类型 (分别对应 watch 操作的传播延迟、高速缓存的 TTL 时长或者 0)。
以环境变量方式使用的 ConfigMap 数据不会被自动更新。 更新这些数据需要重新启动 Pod。
Note: 使用 ConfigMap 作为 subPath 卷挂载的容器将不会收到 ConfigMap 的更新。
挂载的 Secret 是被自动更新的
当卷中包含来自 Secret 的数据,而对应的 Secret 被更新,Kubernetes 会跟踪到这一操作并更新卷中的数据。更新的方式是保证最终一致性。
Note: 对于以 subPath 形式挂载 Secret 卷的容器而言, 它们无法收到自动的 Secret 更新。

https://kubernetes.io/zh/docs/tasks/configure-pod-container/configure-pod-configmap/
https://kubernetes.io/zh/docs/tasks/configmap-secret/managing-secret-using-config-file/
5. Pod详解-持久化存储
volume存储

kubernetes容器中的数据是临时的,即当重启重启或crash后容器的数据将会丢失,此外容器之间有共享存储的需求,所以kubernetes中提供了volume存储的抽象,volume后端能够支持多种不同的plugin驱动,通过.spec.volumes中定义一个存储,然后在容器中.spec.containers.volumeMounts调用,最终在容器内部以目录的形式呈现。
kubernetes内置能支持多种不同的驱动类型,大体上可以分为四种类型:
公/私有云驱动接口,如awsElasticBlockStore实现与aws EBS集成,
开源存储驱动接口,如ceph rbd,实现与ceph rb块存储对接
本地临时存储,如hostPath,
kubernetes对象API驱动接口,实现其他对象调用,如configmap,每种存储支持不同的驱动,
如下介绍:
1. 公/私有云驱动接口
| 类型 | 说明 |
|---|---|
| awsElasticBlockStore | AWS的EBS云盘 |
| azureFile | 微软NAS存储 |
| gcePersistentDisk | google云盘 |
| cinder | openstack cinder云盘 |
| vsphereVolume | VMware的VMFS存储 |
| scaleIO | EMC分布式存储 |
2. 开源存储驱动接口
| 类型 | 说明 |
|---|---|
| ceph rbd | ceph块存储 |
| cephfs | glusterfs存储 |
| nfs | nfs文件 |
| flexvolume | 社区标准化驱动 |
| csi | 社区标准化驱动 |
3. 本地临时存储
| 类型 | 说明 |
|---|---|
| hostpath | 宿主机文件 |
| emptyDir | 临时目录 |
emptyDir是host上定义的一块临时存储,通过bind mount的形式挂载到容器中使用,容器重启数据会保留,容器删除则volume会随之删除。
hostPath与emptyDir类似提供临时的存储,hostPath适用于一些容器需要访问宿主机目录或文件的场景,对于数据持久化而言都不是很好的实现方案。
4. kubernetes对象API驱动接口
| 类型 | 说明 |
|---|---|
| configMap | 调用configmap对象,注入配置文件 |
| secrets | 调用secrets对象,注入秘文配置文件 |
| persistentVolumeClaim | 通过pvc调用存储 |
| downloadAPI | |
| projected |
PV,PVC和StorageClass
- Volume 存储卷,独立于容器,后端和不同的存储驱动对接
- PV Persistent Volume持久化存储卷,和node类似,是一种集群资源,由管理员定义,对接不同的存储
- PVC PersistentVolumeClaims持久化存储声明,和pod类似,作为PV的使用者
- StorageClass 动态存储类型,分为静态和动态两种类型,通过在PVC中定义存储类型,自动创建所需PV
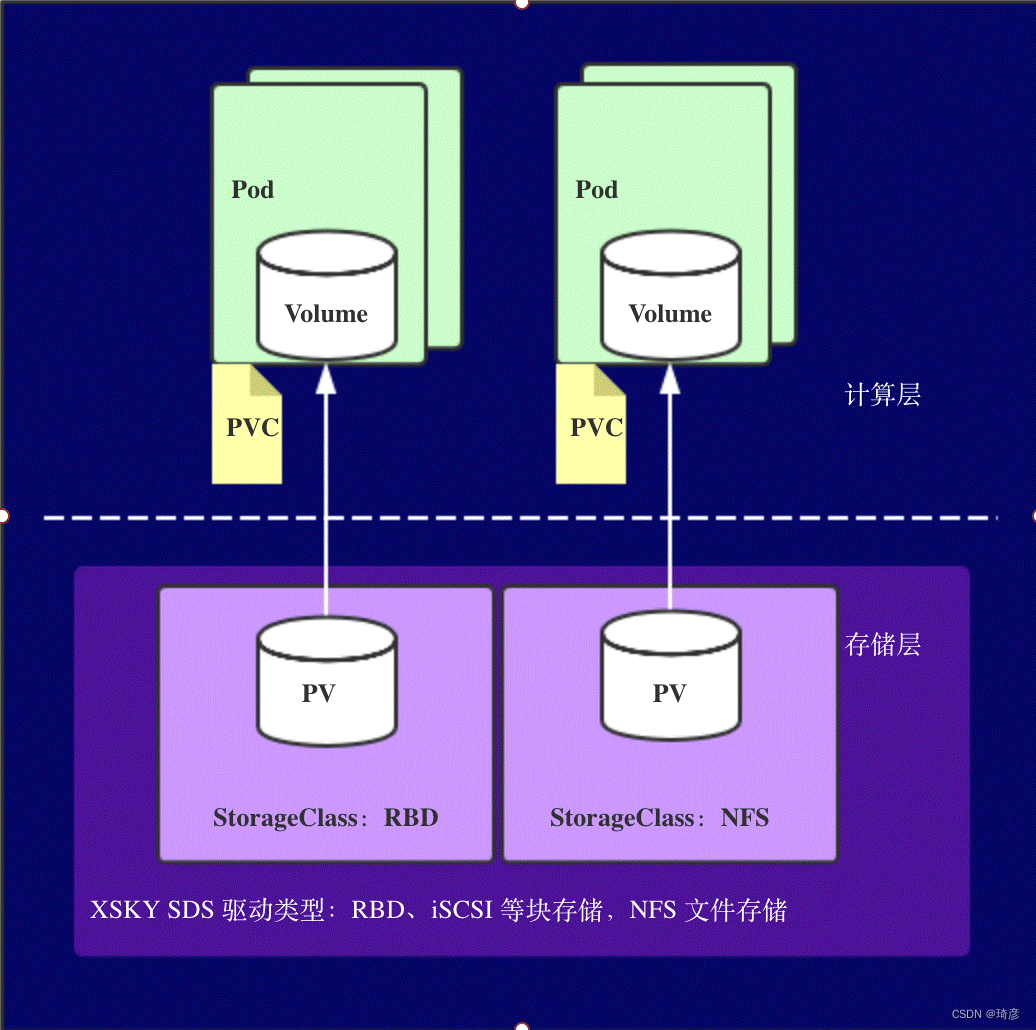
用户创建的 PVC 要真正被容器使用起来,就必须先和某个符合条件的 PV 进行绑定。这里要检查的条件,包括两部分:
- 第一个条件,当然是 PV 和 PVC 的 spec 字段。比如,PV 的存储(storage)大小,就必须满足 PVC 的要求。
- 而第二个条件,则是 PV 和 PVC 的 storageClassName 字段必须一样。
在成功地将 PVC 和 PV 进行绑定之后,Pod 就能够像使用 hostPath 等常规类型的 Volume 一样,在自己的 YAML 文件里声明使用这个 PVC 了

PV 这个对象的创建,是由运维人员完成的。但是,在大规模的生产环境里,这其实是一个非常麻烦的工作。
这是因为,一个大规模的 Kubernetes 集群里很可能有成千上万个 PVC,这就意味着运维人员必须得事先创建出成千上万个 PV。更麻烦的是,随着新的 PVC 不断被提交,运维人员就不得不继续添加新的、能满足条件的 PV,否则新的 Pod 就会因为 PVC 绑定不到 PV 而失败。在实际操作中,这几乎没办法靠人工做到。
所以,Kubernetes 为我们提供了一套可以自动创建 PV 的机制,即:Dynamic Provisioning。
相比之下,前面人工管理 PV 的方式就叫作 Static Provisioning。
Dynamic Provisioning 机制工作的核心,在于一个名叫 StorageClass 的 API 对象。
从图中我们可以看到,在这个体系中:
- PVC 描述的,是 Pod 想要使用的持久化存储的属性,比如存储的大小、读写权限等。
- PV 描述的,则是一个具体的 Volume 的属性,比如 Volume 的类型、挂载目录、远程存储服务器地址等。
- 而 StorageClass 的作用,则是充当 PV 的模板。并且,只有同属于一个 StorageClass 的 PV 和 PVC,才可以绑定在一起。
当然,StorageClass 的另一个重要作用,是指定 PV 的 Provisioner(存储插件)。这时候,如果你的存储插件支持 Dynamic Provisioning 的话,Kubernetes 就可以自动为你创建 PV 了。
如果你在 PV 和 PVC 里都声明了 storageClassName=manual。但在集群里,实际上并没有一个名叫 manual 的 StorageClass 对象。
这完全没有问题,这个时候 Kubernetes 进行的是 Static Provisioning,但在做绑定决策的时候,它依然会考虑 PV 和 PVC 的 StorageClass 定义。
而这么做的好处也很明显:这个 PVC 和 PV 的绑定关系,就完全在我自己的掌控之中。
这里,你可能会有疑问,我在之前讲解 StatefulSet 存储状态的例子时,好像并没有声明 StorageClass 啊?
实际上,如果你的集群已经开启了名叫 DefaultStorageClass 的 Admission Plugin,它就会为 PVC 和 PV 自动添加一个默认的 StorageClass;否则,PVC 的 storageClassName 的值就是“”,这也意味着它只能够跟 storageClassName 也是“”的 PV 进行绑定。
容器持久化存储涉及的概念比较多,试着总结一下整体流程。
用户提交请求创建pod,Kubernetes发现这个pod声明使用了PVC,那就靠PersistentVolumeController帮它找一个PV配对。
没有现成的PV,就去找对应的StorageClass,帮它新创建一个PV,然后和PVC完成绑定。
新创建的PV,还只是一个API 对象,需要经过“两阶段处理”变成宿主机上的“持久化 Volume”才真正有用:
- 第一阶段由运行在master上的AttachDetachController负责,为这个PV完成 Attach 操作,为宿主机挂载远程磁盘;
- 第二阶段是运行在每个节点上kubelet组件的内部,把第一步attach的远程磁盘 mount 到宿主机目录。这个控制循环叫VolumeManagerReconciler,运行在独立的Goroutine,不会阻塞kubelet主循环。
完成这两步,PV对应的“持久化 Volume”就准备好了,POD可以正常启动,将“持久化 Volume”挂载在容器内指定的路径。
简而言之:
StorageClass (SC):存储类,类似存储池的概念,包括了存储池的一些信息;
PersistenVolume (PV):持久卷,独立的存储资源对象,其生命周期与Pod无关;
PersistenVolumeClaim (PVC): 声明,代表计算任务对存储资源的需求。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VJ7NwOQB-1651725737445)(https://cdn.jsdelivr.net/gh/Fly0905/note-picture@main/img/202204231918291.gif)]
这种存储结构是为了解决
- 有状态的容器实例需要持久化卷;
- 容器实例动态提供新卷;
- 不同类型的应用需要不同访问模式的存储卷;
- 解耦计算资源和存储资源。
6. Pod详解-服务域名发现
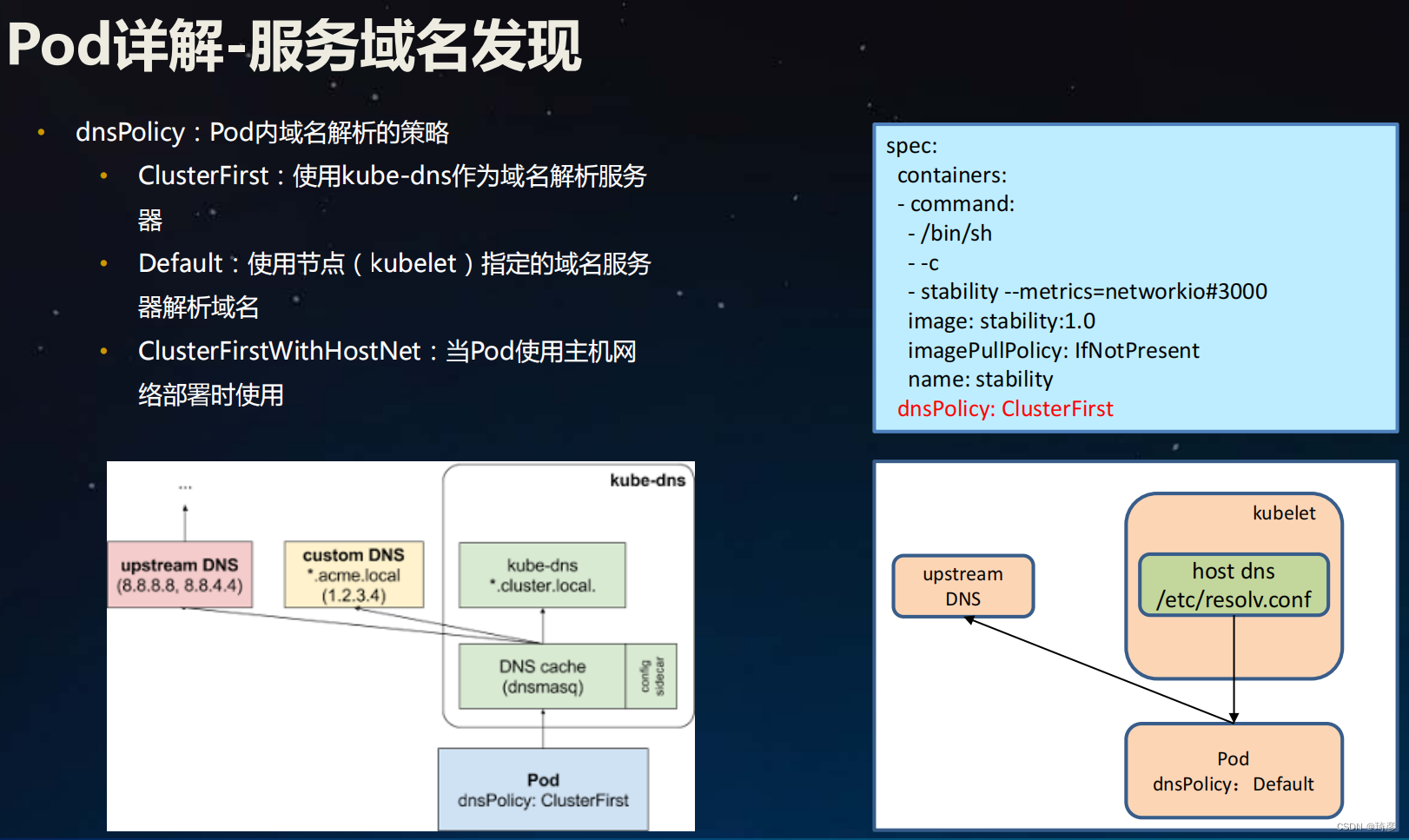
Pod 的 DNS 策略
DNS 策略可以逐个 Pod 来设定。目前 Kubernetes 支持以下特定 Pod 的 DNS 策略。 这些策略可以在 Pod 规约中的 dnsPolicy 字段设置:
- ClusterFirst:使用kube-dns作为域名解析服务器
- **Default:**使用节点( kubelet)指定的域名服务器解析域名
- **ClusterFirstWithHostNet:**当Pod使用主机网络部署时使用
- “
None”: 此设置允许 Pod 忽略 Kubernetes 环境中的 DNS 设置。Pod 会使用其dnsConfig字段 所提供的 DNS 设置。- Note: “Default” 不是默认的 DNS 策略。如果未明确指定
dnsPolicy,则使用 “ClusterFirst”。
Pod 的 DNS 配置
FEATURE STATE: Kubernetes v1.14 [stable]
Pod 的 DNS 配置可让用户对 Pod 的 DNS 设置进行更多控制。
dnsConfig 字段是可选的,它可以与任何 dnsPolicy 设置一起使用。 但是,当 Pod 的 dnsPolicy 设置为 “None” 时,必须指定 dnsConfig 字段。
用户可以在 dnsConfig 字段中指定以下属性:
-
nameservers:将**用作于 Pod 的 DNS 服务器的 IP 地址列表。 最多可以指定 3 个 IP 地址。**当 Pod 的dnsPolicy设置为 “None” 时, 列表必须至少包含一个 IP 地址,否则此属性是可选的。 所列出的服务器将合并到从指定的 DNS 策略生成的基本名称服务器,并删除重复的地址。 -
searches:**用于在 Pod 中查找主机名的 DNS 搜索域的列表。**此属性是可选的。 指定此属性时,所提供的列表将合并到根据所选 DNS 策略生成的基本搜索域名中。 重复的域名将被删除。Kubernetes 最多允许 6 个搜索域。 -
options:可选的对象列表,其中每个对象可能具有name属性(必需)和value属性(可选)。 此属性中的内容将合并到从指定的 DNS 策略生成的选项。 重复的条目将被删除。ndots意思就是 点号. (dot) 的个数ndots: 5就是 5个点号5个点号的意思就是说
对于一个 域名, 如果不是完全限定名(即某个域名不是以.结尾,a.com不是,a.com.是)
且点号数量少于5个, 那么就按照search的顺序,依次解析
如果点号大于或者等于5, 直接解析
以下是具有自定义 DNS 设置的 Pod 示例:
apiVersion: v1
kind: Pod
metadata:
namespace: default
name: dns-example
spec:
containers:
- name: test
image: nginx
dnsPolicy: "None"
dnsConfig:
nameservers:
- 1.2.3.4
searches:
- ns1.svc.cluster-domain.example
- my.dns.search.suffix
options:
- name: ndots
value: "2"
- name: edns0
创建上面的 Pod 后,容器 test 会在其 /etc/resolv.conf 文件中获取以下内容:
# 如果是ClusterFirst模式,nameserver对应的就是kube-dns的ClusterIP
nameserver 1.2.3.4
search ns1.svc.cluster-domain.example my.dns.search.suffix
options ndots:2 edns0
对于 IPv6 设置,搜索路径和名称服务器应按以下方式设置:
kubectl exec -it dns-example -- cat /etc/resolv.conf
输出类似于
nameserver fd00:79:30::a
search default.svc.cluster-domain.example svc.cluster-domain.example cluster-domain.example
options ndots:5
https://kubernetes.io/zh/docs/concepts/services-networking/dns-pod-service/
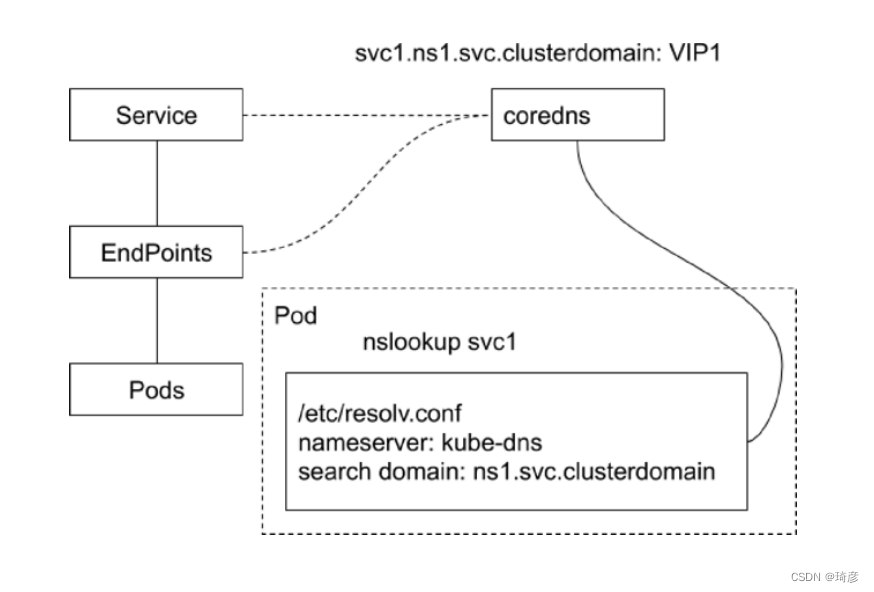
在 Kubernetes 中,Service 和 Pod 都会被分配对应的 DNS A 记录(从域名解析 IP 的记录)。
对于 ClusterIP 模式的 Service 来说(比如我们上面的例子),它的 A 记录的格式是:…svc.cluster.local。当你访问这条 A 记录的时候,它解析到的就是该 Service 的 VIP 地址。
而对于指定了 clusterIP=None 的 Headless Service 来说,它的 A 记录的格式也是:…svc.cluster.local。但是,当你访问这条 A 记录的时候,它返回的是所有被代理的 Pod 的 IP 地址的集合。当然,如果你的客户端没办法解析这个集合的话,它可能会只会拿到第一个 Pod 的 IP 地址。
此外,对于 ClusterIP 模式的 Service 来说,它代理的 Pod 被自动分配的 A 记录的格式是:…pod.cluster.local。这条记录指向 Pod 的 IP 地址。
而对 Headless Service 来说,它代理的 Pod 被自动分配的 A 记录的格式是:…svc.cluster.local。这条记录也指向 Pod 的 IP 地址。
但如果你为 Pod 指定了 Headless Service,并且 Pod 本身声明了 hostname 和 subdomain 字段,那么这时候 Pod 的 A 记录就会变成:<pod 的 hostname>…svc.cluster.local
7. Pod详解-优雅启动和终止
你可能会遇到需要Kubernetes 仅在满足条件时启动 Pod 的情况,例如依赖项正在运行或sidecar 容器已准备就绪。同样,你可能希望在 Kubernetes 终止 pod 之前执行命令,以释放正在使用的资源并优雅地终止应用程序。
你可以使用两个容器生命周期事件轻松完成此操作:
-
PostStart:这个事件在容器创建后立即执行。事件处理程序不能接受任何参数。 然而,postStart处理函数的调用不保证早于容器的入口点(entrypoint) 的执行。postStart 处理函数与容器的代码是异步执行的,但 Kubernetes 的容器管理逻辑会一直阻塞等待 postStart 处理函数执行完毕。 只有 postStart 处理函数执行完毕,容器的状态才会变成 RUNNING。这个钩子和主进程是并行执行的。钩子的名称或许有误导性,因为它并不是等到主进程完全启动后(如果这个进程有一个初始化的过程,Kubelet显然不会等待这个过程完成,因为它并不知道什么时候会完成)才执行的。
即使钩子是以异步方式运行的,它确实通过两种方式来影响容器。
- 在钩子执行完毕之前,容器会一直停留在Waiting状态,其原因是ContainerCreating。因此,pod的状态会是Pending而不是Running。
- 如果钩子运行失败或者返回了非零的状态码,主容器会被杀死。
-
PreStop: 这个事件在容器因任何原因终止之前立即执行,例如资源争用、活性探测失败等。你不能向处理程序传递任何参数,无论处理程序的结果如何,容器都将被终止。除非 Pod 宽限期限超时,Kubernetes 的容器管理逻辑 会一直阻塞等待 preStop 处理函数执行完毕。
下面是包含两个容器的pod 的 生命周期事件的说明,从你指示 Kubernetes 创建它的那一刻开始,到它们都运行的那一刻:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EfNUE2Jk-1651725737447)(https://cdn.jsdelivr.net/gh/Fly0905/note-picture@main/img/202204240653207.png)]
你可以将3种类型的处理程序附加到生命周期事件:
- exec: 它在容器的主进程中执行指定的命令。该命令与容器的ENTRYPOINT指令并行执行。如果事件耗时过长或失败,kubelet 进程将重启容器。
- httpGet或tcpSocket:它针对容器上的特定端点发送 HTTP 请求或建立 TCP 连接。与exec由容器执行的不同,此处理程序由 kubelet 进程执行。
事件至少执行一次,对于 HTTP 处理程序,除非 kubelet 在发送请求的过程中重新启动,否则 kubelet 只会发送一次请求。
以下是一个部署示例,包括一个运行NGINX的主容器和一个运行busybox的sidecar容器。
- 主容器提供文件index.html。
- Sidecar 容器将预定日志写入主容器提供的同一个文件index.html。
- 只有当主容器准备好时,sidecar容器才会启动。
apiVersion: v1
kind: Pod
metadata:
name: sidecar-container-demo
spec:
containers:
- image: busybox
command: ["/bin/sh"]
args:
[
"-c",
"while true; do echo echo $(date -u) 'Written by busybox sidecar container' >> /var/log/index.html; sleep 5;done",
]
name: sidecar-container
resources: {}
volumeMounts:
- name: var-logs
mountPath: /var/log
lifecycle:
postStart:
httpGet:
path: /index.html
port: 80
host: localhost
scheme: HTTP
- image: nginx
name: main-container
resources: {}
ports:
- containerPort: 80
volumeMounts:
- name: var-logs
mountPath: /usr/share/nginx/html
dnsPolicy: Default
volumes:
- name: var-logs
emptyDir: {}
Warning FailedPostStartHook 7s kubelet, gv41new95 Http lifecycle hook (/index.html) for Container “sidecar-container” in Pod “sidecar-container-demo_default(bf6a184b-576f-4137-8958-99017ab704f7)” failed - error: Get http://localhost:80//index.html: dial tcp [::1]:80: connect: connection refused, message: “”
直到postStart执行事件失败,sidecar容器将不断重启。你可以通过修改生命周期检查,来强制 sidecar 容器失败:
lifecycle:
postStart:
httpGet:
path: /index.html
port: 5000
host: localhost
scheme: HTTP
你可以通过运行以下命令来查看 kubelet 生成的事件:
kubectl describe pod/sidecar-container-demo
这是命令的输出:
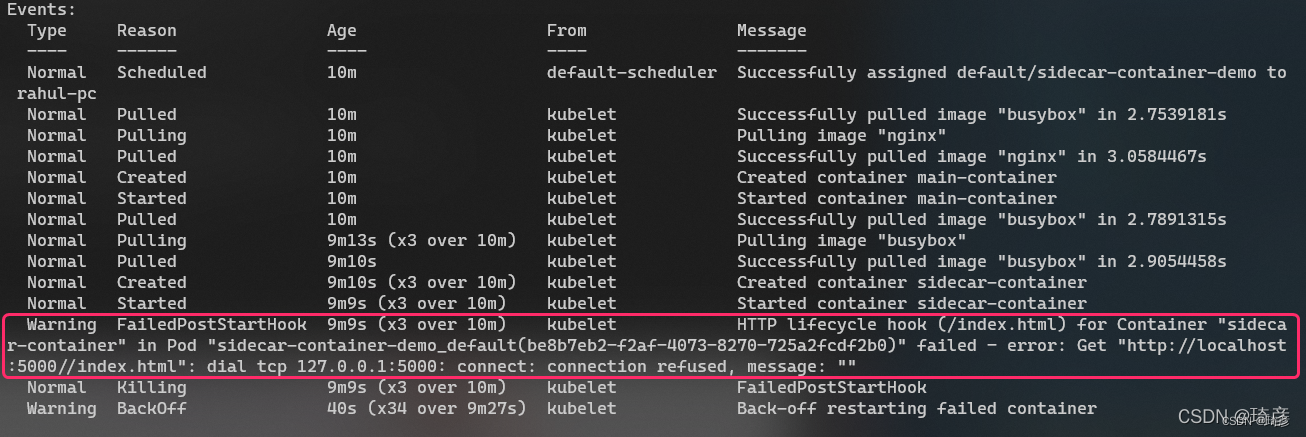
让我们实现下一个事件,preStop。以下命令将打印一条日志消息并确保 pod 正常关闭:
💡 提示:你可以将preStop输出直接输出到 PID 1 标准输出,它最终会出现在应用程序日志中。接下来我们将使用这个技巧来跟踪 pre-stop 事件的执行。
apiVersion: v1
kind: Pod
metadata:
name: prestop-demo
spec:
containers:
- image: nginx
name: nginx-container
resources: {}
ports:
- containerPort: 80
lifecycle:
preStop:
exec:
command:
- sh
- -c
- echo "Stopping container now...">/proc/1/fd/1 && nginx -s stop
dnsPolicy: Default
当使用 pre-stop 事件的容器终止时,nginx -s quit在 kubelet 向SIGTERM主进程发送信号之前,在容器中执行命令。
如果你在监视 NGINX 容器日志的同时删除 pod,你将看到以下输出:
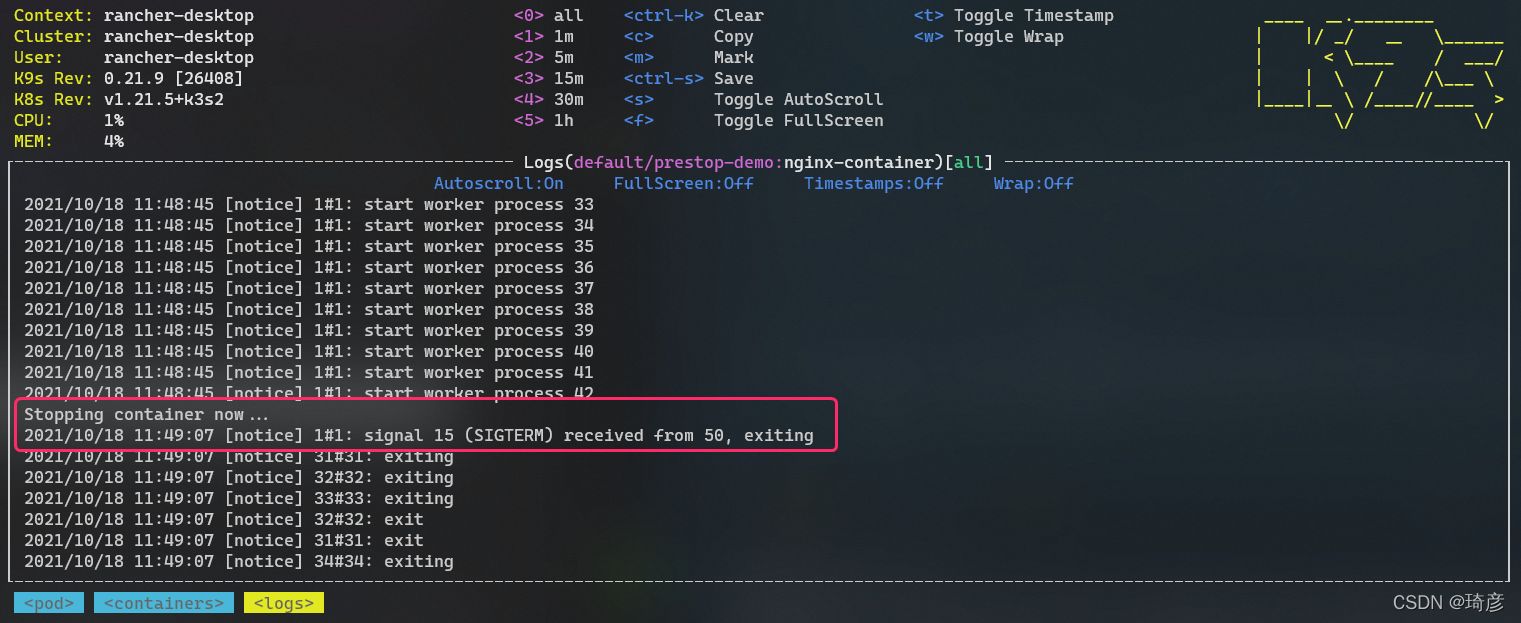
容器终止流程
- Pod 被删除,状态置为 Terminating。
- kube-proxy 更新转发规则,将 Pod 从 service 的 endpoint 列表中摘除掉,新的流量不再转发到该 Pod。
- 如果 Pod 配置了 preStop Hook ,将会执行。
- kubelet 对 Pod 中各个 container 发送
SIGTERM信号以通知容器进程开始优雅停止。 - 等待容器进程完全停止,如果在
terminationGracePeriodSeconds内 (默认 30s) 还未完全停止,就发送SIGKILL信号强制杀死进程。 - 所有容器进程终止,清理 Pod 资源。
- 当你删除一个 pod 对象时,它的所有容器都会并行终止。你可以通过设置deletionGracePeriodSeconds容器规范中的属性,为每个容器授予以秒为单位的宽限期。
- 使用TERM处理信号比缩短或删除宽限期要好。
SIGTERM & SIGKILL
9 - SIGKILL 强制终端
15 - SIGTEM 请求中断
容器内的进程不能用SIGTEM中断的,都不能算优雅中止,所以这里有个常见问题,为什么有些容器SIGTEM信号不起作用。
如果容器启动入口使用了 shell,比如使用了类似 /bin/sh -c my-app 或 /docker-entrypoint.sh 这样的 ENTRYPOINT 或 CMD,这就可能就会导致容器内的业务进程收不到 SIGTERM 信号,原因是:
-
容器主进程是 shell,业务进程是在 shell 中启动的,成为了 shell 进程的子进程。
-
shell 进程默认不会处理 SIGTERM 信号,自己不会退出,也不会将信号传递给子进程,导致业务进程不会触发停止逻辑。
-
当等到 K8S 优雅停止超时时间 (terminationGracePeriodSeconds,默认 30s),发送 SIGKILL 强制杀死 shell 及其子进程。
https://blog.csdn.net/fly910905/article/details/121704030
https://kubernetes.io/zh/docs/tasks/configure-pod-container/attach-handler-lifecycle-event/
魔法小工具(提高生产力)
1. 如何快速编写yaml文件
1.1 通过定义模版快速生成
设置
dryRun查询参数来触发空运行
通过定义模版快速生成,kubectl create apps -o yaml --dry-run的方式生成,–dry-run仅仅是试运行,并不实际在k8s集群中运行,通过指定-o yaml输出yaml格式文件,生成后给基于模版修改即可,如下:
[root@node-1 demo]# kubectl create deployment demo --image=nginx:latest --dry-run -o yaml
apiVersion: apps/v1
kind: Deployment
metadata:
creationTimestamp: null
labels:
app: demo
name: demo
spec:
replicas: 1
selector:
matchLabels:
app: demo
strategy: {}
template:
metadata:
creationTimestamp: null
labels:
app: demo
spec:
containers:
- image: nginx:latest
name: nginx
resources: {}
status: {}
1.2 explain命令
explain命令堪称是语法查询器,可以查到每个字段的含义,使用说明和使用方式,如想要查看Pod的spec中containers其他支持的字段,可以通过kubectl explain Pod.spec.containers的方式查询,如下:
[root@node-1 demo]# kubectl explain Pods.spec.containers
KIND: Pod
VERSION: v1
RESOURCE: containers <[]Object>
DESCRIPTION:
List of containers belonging to the pod. Containers cannot currently be
added or removed. There must be at least one container in a Pod. Cannot be
updated.
A single application container that you want to run within a pod.
FIELDS:
args <[]string> #命令参数
Arguments to the entrypoint. The docker image's CMD is used if this is not
provided. Variable references $(VAR_NAME) are expanded using the
container's environment. If a variable cannot be resolved, the reference in
the input string will be unchanged. The $(VAR_NAME) syntax can be escaped
with a double $$, ie: $$(VAR_NAME). Escaped references will never be
expanded, regardless of whether the variable exists or not. Cannot be
updated. More info:
https://kubernetes.io/docs/tasks/inject-data-application/define-command-argument-container/#running-a-command-in-a-shell
image <string> #镜像定义
Docker image name. More info:
https://kubernetes.io/docs/concepts/containers/images This field is
optional to allow higher level config management to default or override
container images in workload controllers like Deployments and StatefulSets.
ports <[]Object> #端口定义
List of ports to expose from the container. Exposing a port here gives the
system additional information about the network connections a container
uses, but is primarily informational. Not specifying a port here DOES NOT
prevent that port from being exposed. Any port which is listening on the
default "0.0.0.0" address inside a container will be accessible from the
network. Cannot be updated.
readinessProbe <Object> #可用健康检查
Periodic probe of container service readiness. Container will be removed
from service endpoints if the probe fails. Cannot be updated. More info:
https://kubernetes.io/docs/concepts/workloads/pods/pod-lifecycle#container-probes
resources <Object> #资源设置
Compute Resources required by this container. Cannot be updated. More info:
https://kubernetes.io/docs/concepts/configuration/manage-compute-resources-container/
...省略部分输出...
volumeMounts <[]Object> #挂载存储
Pod volumes to mount into the container's filesystem. Cannot be updated.
workingDir <string>
Container's working directory. If not specified, the container runtime's
default will be used, which might be configured in the container image.
Cannot be updated.
关于explain内容解释说明
<string>表示后面接一个字符串<[]Object>表示后面是一个列表的对象,列表需要以-开始,且可以写多个<Object>表示一个对象,对象内部包含多个属性
2. Kubectl接口调试
[root@10 ~]# kubectl get pod --v=0
NAME READY STATUS RESTARTS AGE
api-demo-56db594ddf-rc5jf 1/1 Running 1 29d
busybox 1/1 Running 0 22h
busybox-6f88f747db-c5pdn 0/1 CrashLoopBackOff 3597 21d
busybox-deployment-7d8b8f459f-5c26l 1/1 Running 0 21h
busybox-deployment-7d8b8f459f-6m27f 1/1 Running 0 21h
busybox-deployment-7d8b8f459f-7xq5q 1/1 Running 0 21h
busybox-deployment-7d8b8f459f-ck4ff 1/1 Running 0 21h
busybox-deployment-7d8b8f459f-gq5fs 1/1 Running 0 21h
busybox-deployment-7d8b8f459f-vfxvc 1/1 Running 0 21h
ds.kusc00201-5b6hn 1/1 Running 1 20d
ds.kusc00201-9jqmt 1/1 Running 0 20d
ds.kusc00201-bf6tx 1/1 Running 0 20d
ds.kusc00201-c8rxh 1/1 Running 0 20d
ds.kusc00201-cgjzz 1/1 Running 1 20d
ds.kusc00201-gpstf 1/1 Running 0 20d
ds.kusc00201-js47m 1/1 Running 0 20d
falco-daemonset-2hg9w 1/1 Running 0 32h
falco-daemonset-68sc9 1/1 Running 1 32h
falco-daemonset-944zb 1/1 Running 1 32h
falco-daemonset-d8dnh 1/1 Running 0 32h
falco-daemonset-db7vg 1/1 Running 1 32h
falco-daemonset-kr8wj 1/1 Running 0 32h
falco-daemonset-vdsb6 1/1 Running 2 32h
lumpy--koala 0/1 Init:CrashLoopBackOff 3695 20d
nginx-864459b57d-zqgjt 1/1 Running 0 21h
single-nginx-deployment-69dd5c845f-5znk9 1/1 Running 0 44d
single-nginx-deployment-69dd5c845f-85vvr 0/1 ContainerCreating 0 21h
single-nginx-deployment-69dd5c845f-cdkfc 1/1 Running 0 21d
test 1/1 Running 1 19d
[root@10 ~]# kubectl get pod --v=2
I0108 19:16:05.058744 409257 get.go:558] no kind is registered for the type v1beta1.Table in scheme "k8s.io/kubernetes/pkg/api/legacyscheme/scheme.go:29"
NAME READY STATUS RESTARTS AGE
api-demo-56db594ddf-rc5jf 1/1 Running 1 29d
busybox 1/1 Running 0 22h
busybox-6f88f747db-c5pdn 0/1 CrashLoopBackOff 3597 21d
busybox-deployment-7d8b8f459f-5c26l 1/1 Running 0 21h
busybox-deployment-7d8b8f459f-6m27f 1/1 Running 0 21h
busybox-deployment-7d8b8f459f-7xq5q 1/1 Running 0 21h
busybox-deployment-7d8b8f459f-ck4ff 1/1 Running 0 21h
busybox-deployment-7d8b8f459f-gq5fs 1/1 Running 0 21h
busybox-deployment-7d8b8f459f-vfxvc 1/1 Running 0 21h
ds.kusc00201-5b6hn 1/1 Running 1 20d
ds.kusc00201-9jqmt 1/1 Running 0 20d
ds.kusc00201-bf6tx 1/1 Running 0 20d
ds.kusc00201-c8rxh 1/1 Running 0 20d
ds.kusc00201-cgjzz 1/1 Running 1 20d
ds.kusc00201-gpstf 1/1 Running 0 20d
ds.kusc00201-js47m 1/1 Running 0 20d
falco-daemonset-2hg9w 1/1 Running 0 32h
falco-daemonset-68sc9 1/1 Running 1 32h
falco-daemonset-944zb 1/1 Running 1 32h
falco-daemonset-d8dnh 1/1 Running 0 32h
falco-daemonset-db7vg 1/1 Running 1 32h
falco-daemonset-kr8wj 1/1 Running 0 32h
falco-daemonset-vdsb6 1/1 Running 2 32h
lumpy--koala 0/1 Init:CrashLoopBackOff 3695 20d
nginx-864459b57d-zqgjt 1/1 Running 0 21h
single-nginx-deployment-69dd5c845f-5znk9 1/1 Running 0 44d
single-nginx-deployment-69dd5c845f-85vvr 0/1 ContainerCreating 0 21h
single-nginx-deployment-69dd5c845f-cdkfc 1/1 Running 0 21d
test 1/1 Running 1 19d
[root@10 ~]# kubectl get pod --v=8
I0108 19:16:08.907946 409391 loader.go:359] Config loaded from file /root/.kube/config
I0108 19:16:08.912806 409391 loader.go:359] Config loaded from file /root/.kube/config
I0108 19:16:08.924331 409391 loader.go:359] Config loaded from file /root/.kube/config
I0108 19:16:08.947717 409391 loader.go:359] Config loaded from file /root/.kube/config
I0108 19:16:08.948706 409391 round_trippers.go:383] GET https://10.10.101.170:6443/api/v1/namespaces/default/pods?limit=500
I0108 19:16:08.948739 409391 round_trippers.go:390] Request Headers:
I0108 19:16:08.948755 409391 round_trippers.go:393] Accept: application/json;as=Table;v=v1beta1;g=meta.k8s.io, application/json
I0108 19:16:08.948771 409391 round_trippers.go:393] User-Agent: kubectl/v1.12.3 (linux/amd64) kubernetes/435f92c
I0108 19:16:08.989401 409391 round_trippers.go:408] Response Status: 200 OK in 40 milliseconds
I0108 19:16:08.989454 409391 round_trippers.go:411] Response Headers:
I0108 19:16:08.989471 409391 round_trippers.go:414] Content-Type: application/json
I0108 19:16:08.989485 409391 round_trippers.go:414] Date: Wed, 08 Jan 2020 11:16:08 GMT
I0108 19:16:08.990879 409391 request.go:942] Response Body: {"kind":"Table","apiVersion":"meta.k8s.io/v1beta1","metadata":{"selfLink":"/api/v1/namespaces/default/pods","resourceVersion":"53664878"},"columnDefinitions":[{"name":"Name","type":"string","format":"name","description":"Name must be unique within a namespace. Is required when creating resources, although some resources may allow a client to request the generation of an appropriate name automatically. Name is primarily intended for creation idempotence and configuration definition. Cannot be updated. More info: http://kubernetes.io/docs/user-guide/identifiers#names","priority":0},{"name":"Ready","type":"string","format":"","description":"The aggregate readiness state of this pod for accepting traffic.","priority":0},{"name":"Status","type":"string","format":"","description":"The aggregate status of the containers in this pod.","priority":0},{"name":"Restarts","type":"integer","format":"","description":"The number of times the containers in this pod have been restarted.","priority":0},{"name":"Age","type":"str [truncated 24720 chars]
I0108 19:16:09.005556 409391 get.go:558] no kind is registered for the type v1beta1.Table in scheme "k8s.io/kubernetes/pkg/api/legacyscheme/scheme.go:29"
NAME READY STATUS RESTARTS AGE
api-demo-56db594ddf-rc5jf 1/1 Running 1 29d
busybox 1/1 Running 0 22h
busybox-6f88f747db-c5pdn 0/1 CrashLoopBackOff 3597 21d
busybox-deployment-7d8b8f459f-5c26l 1/1 Running 0 21h
busybox-deployment-7d8b8f459f-6m27f 1/1 Running 0 21h
busybox-deployment-7d8b8f459f-7xq5q 1/1 Running 0 21h
busybox-deployment-7d8b8f459f-ck4ff 1/1 Running 0 21h
busybox-deployment-7d8b8f459f-gq5fs 1/1 Running 0 21h
busybox-deployment-7d8b8f459f-vfxvc 1/1 Running 0 21h
ds.kusc00201-5b6hn 1/1 Running 1 20d
ds.kusc00201-9jqmt 1/1 Running 0 20d
ds.kusc00201-bf6tx 1/1 Running 0 20d
ds.kusc00201-c8rxh 1/1 Running 0 20d
ds.kusc00201-cgjzz 1/1 Running 1 20d
ds.kusc00201-gpstf 1/1 Running 0 20d
ds.kusc00201-js47m 1/1 Running 0 20d
falco-daemonset-2hg9w 1/1 Running 0 32h
falco-daemonset-68sc9 1/1 Running 1 32h
falco-daemonset-944zb 1/1 Running 1 32h
falco-daemonset-d8dnh 1/1 Running 0 32h
falco-daemonset-db7vg 1/1 Running 1 32h
falco-daemonset-kr8wj 1/1 Running 0 32h
falco-daemonset-vdsb6 1/1 Running 2 32h
lumpy--koala 0/1 Init:CrashLoopBackOff 3695 20d
nginx-864459b57d-zqgjt 1/1 Running 0 21h
single-nginx-deployment-69dd5c845f-5znk9 1/1 Running 0 44d
single-nginx-deployment-69dd5c845f-85vvr 0/1 ContainerCreating 0 21h
single-nginx-deployment-69dd5c845f-cdkfc 1/1 Running 0 21d
test
2.1 Kubectl 日志输出详细程度和调试
-v, --v Level
number for the log level verbosity (日志级别的数值)
Kubectl 日志输出详细程度是通过 -v 或者 --v 来控制的,参数后跟了一个数字表示日志的级别。Kubernetes 通用的日志习惯和相关的日志级别在 这里 有相应的描述。
| 详细程度 | 描述 |
|---|---|
| –v=0 | 默认,始终对运维人员可见。 |
| –v=1 | 如果您不想要详细程度,则为合理的默认日志级别 |
| –v=2 | 有关服务的有用稳定状态信息以及可能与系统中的重大更改相关的重要日志消息。这是大多数系统的建议默认日志级别。 |
| –v=3 | 有关更改的扩展信息。 |
| –v=4 | Debug 级别 |
| –v=6 | 显示请求的资源。 |
| –v=7 | 显示 HTTP 请求头 |
| –v=8 | 显示 HTTP 请求内容 |
| –v=9 | 显示 HTTP 请求内容而不截断内容 |
注意:也可以输入大于9的数值,输出的结果会更详细
3. 自定义列输出格式
kubectl get命令的默认输出格式(用于读取资源)如下:
$kubectl get pods
NAME READY STATUS RESTARTS AGE
engine-544b6b6467-22qr6 1/1 Running 0 78d
engine-544b6b6467-lw5t8 1/1 Running 0 78d
engine-544b6b6467-tvgmg 1/1 Running 0 78d
web-ui-6db964458-8pdw4 1/1 Running 0 78d
这对于人类而言,是一种很好的可读格式,但它只包含有限的信息。如您所见,每个资源只显示一些字段(与完整资源定义相比)。
这就是自定义列输出格式的用武之地。它允许您自由定义要显示在其中的列和数据。您可以选择要在输出中显示为单独列的资源的任何字段
自定义列输出选项的用法如下:
-o custom-columns=<header>:<jsonpath>[,<header>:<jsonpath>]...
JSONPath表达式
选择资源字段的表达式基于JSONPath。
JSONPath是一种从JSON文档中提取数据的语言(类似于XPath for XML)。选择单个字段只是JSONPath的最基本用法。它有很多功能,如列表选择器,过滤器等。
但是,kubectl explain仅支持JSONPath功能的一部分。以下通过示例用法总结了这些支持的功能:
# Select all elements of a list
$kubectl get pods -o custom-columns='DATA:spec.containers[*].image'
# Select a specific element of a list
$kubectl get pods -o custom-columns='DATA:spec.containers[0].image'
# Select those elements of a list that match a filter expression
$kubectl get pods -o custom-columns='DATA:spec.containers[?(@.image!="nginx")].image'
# Select all fields under a specific location, regardless of their name
$kubectl get pods -o custom-columns='DATA:metadata.*'
# Select all fields with a specific name, regardless of their location
$kubectl get pods -o custom-columns='DATA:..image'
特别重要的是[]操作符。Kubernetes资源的许多字段都是列表,此运算符允许您选择这些列表中的项目。它通常与通配符一起使用,[*]以选择列表中的所有项目。
您将在下面找到一些使用此表示法的示例。
示例应用程序
使用自定义列输出格式的可能性是无穷无尽的,因为您可以在输出中显示资源的任何字段或字段组合。以下是一些示例应用程序,但您可以自己探索并找到对您有用的应用程序!
提示:如果您经常使用其中一个命令,则可以为其创建shell别名。
显示Pods的容器镜像
$kubectl get pods \
-o custom-columns='NAME:metadata.name,IMAGES:spec.containers[*].image'
NAME IMAGES
engine-544b6b6467-22qr6 rabbitmq:3.7.8-management,nginx
engine-544b6b6467-lw5t8 rabbitmq:3.7.8-management,nginx
engine-544b6b6467-tvgmg rabbitmq:3.7.8-management,nginx
web-ui-6db964458-8pdw4 wordpress
此命令显示每个Pod的所有容器镜像的名称。
请记住,Pod可能包含多个容器。在这种情况下,单个Pod的容器镜像在同一列中显示为逗号分隔列表。
显示节点的可用区域
$kubectl get nodes \
-o custom-columns='NAME:metadata.name,ZONE:metadata.labels.failure-domain\.beta\.kubernetes\.io/zone'
NAME ZONE
ip-10-0-118-34.ec2.internal us-east-1b
ip-10-0-36-80.ec2.internal us-east-1a
ip-10-0-80-67.ec2.internal us-east-1b
如果您的Kubernetes群集部署在公共云基础架构(例如AWS,Azure或GCP)上,则此命令非常有用。它显示每个节点所在的可用区域。
可用区域是云的概念,表示地理区域内的一个可复制点。
每个节点的可用区域通过特殊标签failure-domain.beta.kubernetes.io/zone获得。如果集群在公共云基础结构上运行,则会自动创建此标签,并将其值设置为节点的可用区域的名称。
标签不是Kubernetes资源规范的一部分,因此您无法在API参考中找到上述标签。但是,如果将节点输出为YAML或JSON,则可以看到它(以及所有其他标签)
Volcano PodGroup认识
Kubernetes工作负载与服务
Pod是谁控制的
https://kubernetes.io/zh/docs/concepts/workloads/pods/#pods-and-controllers
查看ownerReferences
ownerReferences:
- apiVersion: apps/v1
blockOwnerDeletion: true
controller: true
kind: ReplicaSet
name: nginx-deployment-59d674869
uid: fda06915-bb48-441e-bb35-044cb5101869
resourceVersion: "93344"
uid: d22eeb53-a0cb-47f7-abc2-bb2afc4667e0
Pod与工作负载的关系
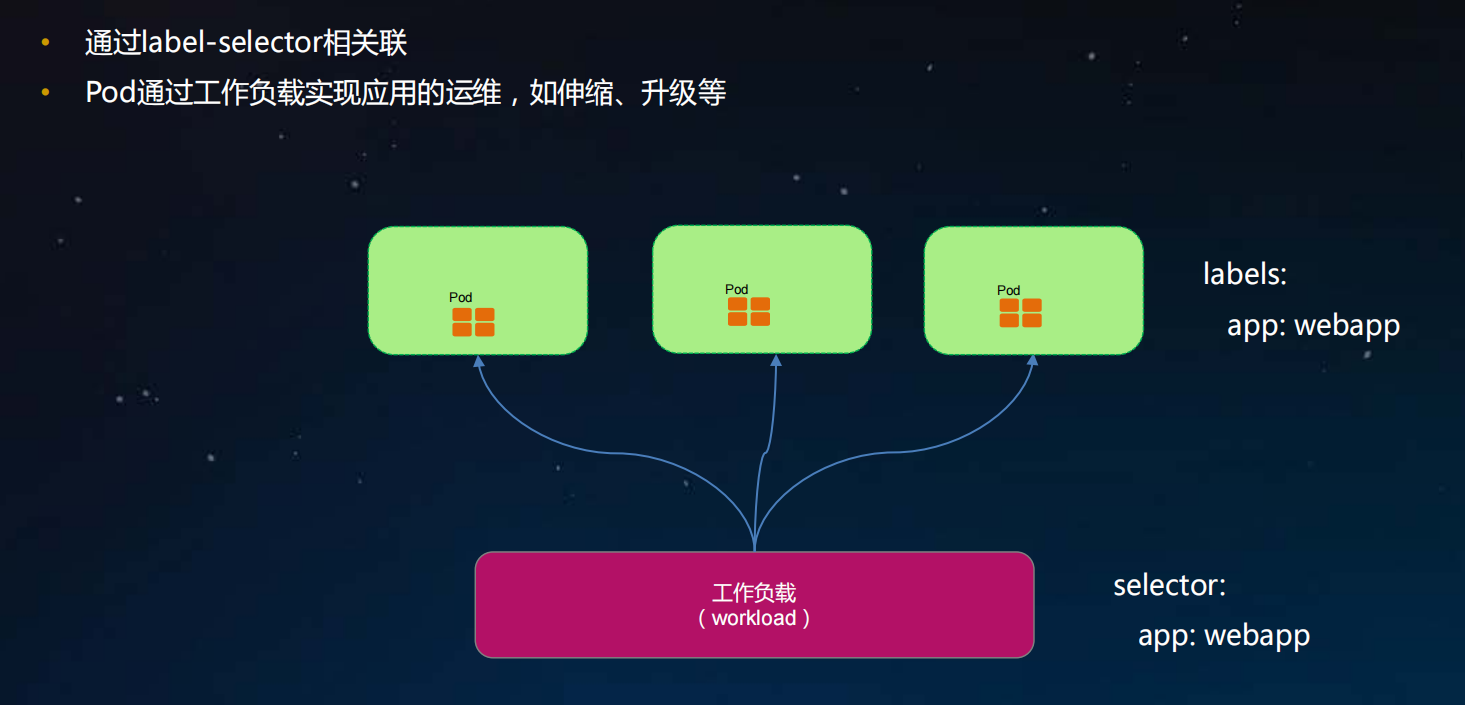
ReplicaSet(容器副本)

- ReplicaSet用于解决pod的扩容和缩容问题。
- 通常用于无状态应用
Deployment

Kubernetes Deployment提供了官方的用于更新Pod和Replica Set(下一代的ReplicationController)的方法,您可以在Deployment对象中只描述您所期望的理想状态(预期的运行状态),Deployment控制器为您将现在的实际状态转换成您期望的状态;
Deployment集成了上线部署、滚动升级、创建副本、暂停上线任务,恢复上线任务,回滚到以前某一版本(成功/稳定)Deployment等功能,在某种程度上, Deployment可以帮我们实现无人值守的上线,大大降低我们的上线过程的复杂沟通、操作风险。
Deployment的典型用例:
- 使用Deployment来启动(上线/部署)一个Pod或者ReplicaSet
- 检查一个Deployment是否成功执行
- 更新Deployment来重新创建相应的Pods(例如,需要使用一个新的Image)
- 如果现有的Deployment不稳定,那么回滚到一个早期的稳定的Deployment版本
关键工作负载-StatefulSet

StatefulSet—有状态应用
用于解决各个pod实例独立生命周期管理,提供各个实例的启动顺序和唯一性
- 稳定,唯一的网络标识符。
- 稳定,持久存储–StatefulSet:每个pod对应一个pv
- 有序的,优雅的部署和扩展。
- 有序,优雅的删除和终止。
- 有序的自动滚动更新。
关键工作负载-DaemonSet
DaemonSet能够让所有(或者一些特定)的Node节点运行同一个pod。当节点加入到kubernetes集\群中, pod会被( DaemonSet)调度到该节点上运行,当节点从kubernetes集群中被移除,被( DaemonSet)调度的pod会被移除,如果删除DaemonSet,所有跟这个DaemonSet相关的pods都会被删除。
在使用kubernetes来运行应用时,很多时候我们需要在一个区域( zone)或者所有Node上运行同一个守护进程( pod),例如如下场景:
- 每个Node上运行一个分布式存储的守护进程,例如glusterd, ceph
- 运行日志采集器在每个Node上,例如fluentd, logstash
- 运行监控的采集端在每个Node,例如prometheus node exporter, collectd等
关键工作负载-Job
CustomResourceDefinition
Pod与服务的关系
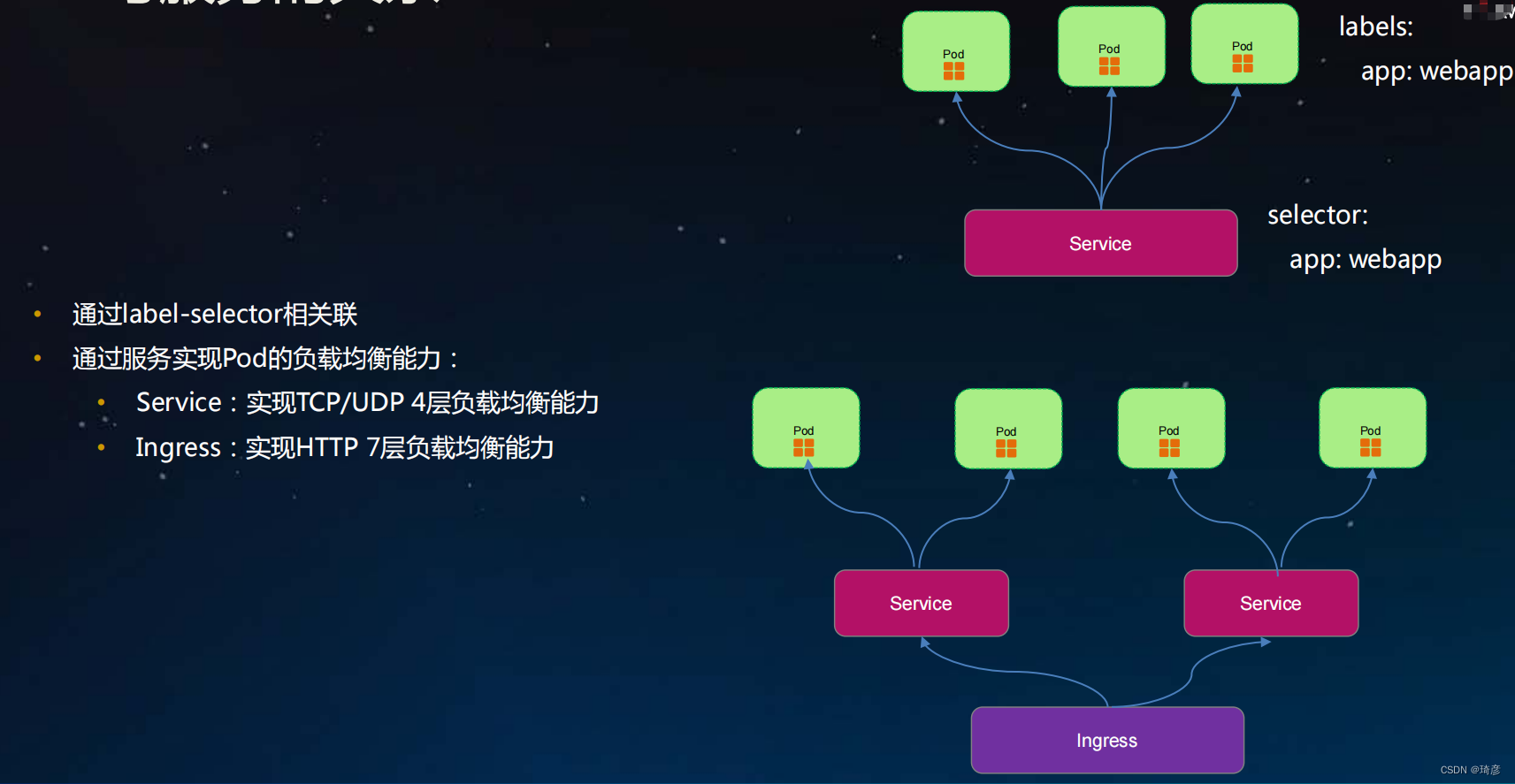
- 通过label-selector相关联
- 通过服务实现Pod的负载均衡能力:
- Service:实现TCP/UDP 4层负载均衡能力
- Ingress:实现HTTP 7层负载均衡能力
Service

- Service定义了pods的逻辑集合和访问这个集合的策略。 Pods集合是通过定义Service时提供的Label选择器完成的
- Service的引入旨在保证pod的动态变化对访问端透明,访问端只需要知道service的地址,由service来提供代理
- Service的抽象使得前端客户和后端Pods进行了解耦
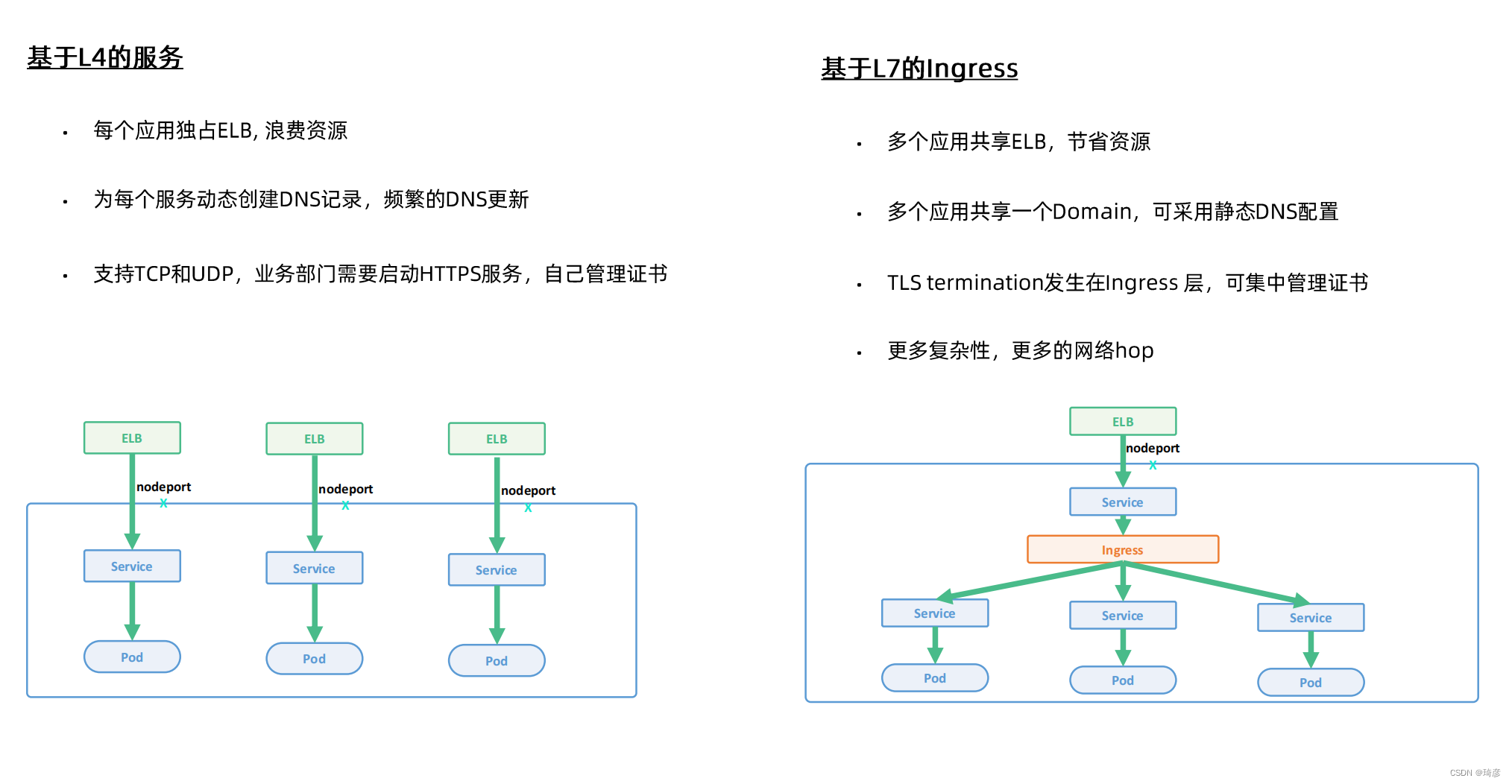
- 支持ClusterIP, NodePort以及LoadBalancer三种类型
- Service的底层实现有userspace、 iptables和ipvs三种模式
kube-proxy 、kube-dns和 CoreDNS
kube-proxy主要是处理集群外部通过nodePort访问集群内服务,通过iptables规则,解析cluterIP到PodIp的过程,并提供服务的负载均衡能力。
kube-proxy还可以提供集群内部服务间通过clusterIP访问,也会经过kube-proxy负责转发。
kube-dns主要处Pod内通过serviceName访问其他服务,找到服务对应的clusterIP的关系,和一些基本的域名解析功能。
kube-dns是和kube-proxy协同工作的,前者通过servicename找到指定clusterIP,后者完成通过clusterIP到PodIP的过程。
kube-dns是早期方案
coredns中运行着内存态的域名服务器和控制器,控制器负责往域名服务器中刷记录
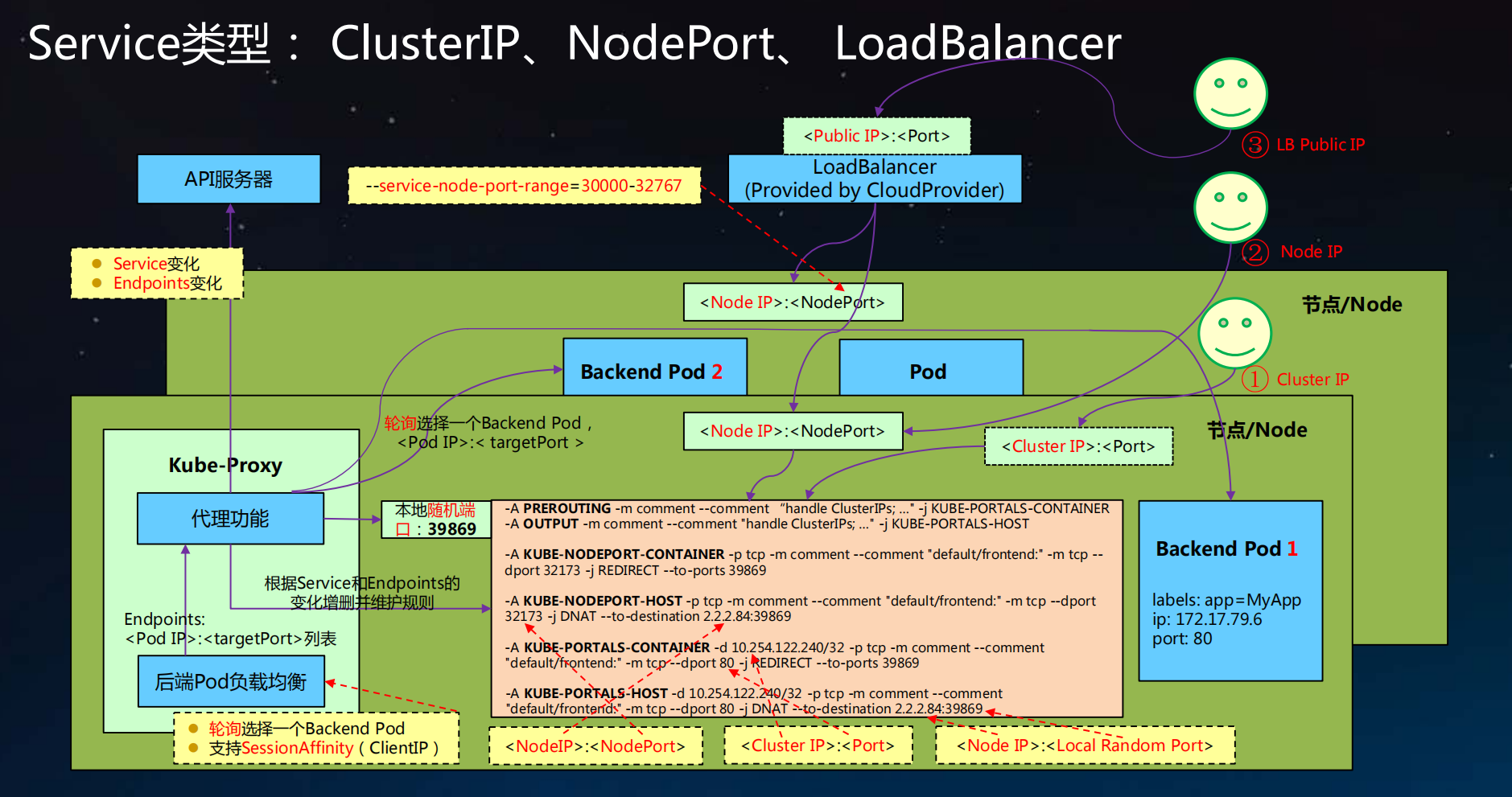
ClusterIP 模式的 Service 为你提供的,就是一个 Pod 的稳定的 IP 地址,即 VIP。并且,这里 Pod 和 Service 的关系是可以通过 Label 确定的。
而 Headless Service 为你提供的,则是一个 Pod 的稳定的 DNS 名字,并且,这个名字是可以通过 Pod 名字和 Service 名字拼接出来的。
kubeadm 更改NodePort端口范围
kubernetes默认端口号范围是 30000-32767 ,如果期望值不是这个区间则需要更改。
1.找到配置文件里,一般的在这个文件夹下: /etc/kubernetes/manifests/
2.找到文件名为kube-apiserver.yaml 的文件,也可能是json格式
3.编辑添加配置 service-node-port-range=30000-49999
ClusterIP 不可以ping,但可以Curl
对于iptables:
ClusterIP没有绑定在任何设备上,他只是iptables中的一条规则,他是虚的,没有任何设备响应。
Curl 是有一个真实的数据包(如TCP)交给内核,然后由内核真正去做匹配,做dnat,转发到后端的pod
对于ipvs:
ClusterIP绑定当前节点上面的一个Dummy设备上
切换iptables到ipvs
# 1.修改kube-proxy的配置文件,添加mode 为ipvs。
kubectl edit configmap kube-proxy -n kube-system
set mode: "ipvs"
# 2.ipvs模式需要注意的是要添加ip_vs相关模块:
cat > /etc/sysconfig/modules/ipvs.modules <<EOF
#!/bin/bash
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack_ipv4
EOF
chmod 755 /etc/sysconfig/modules/ipvs.modules && bash /etc/sysconfig/modules/ipvs.modules && lsmod | grep -e ip_vs -e nf_conntrack_ipv4
# 3.重启kube-proxy 的pod
kubectl get pod -n kube-system | grep kube-proxy |awk '{system("kubectl delete pod "$1" -n kube-system")}'
# 4.验证: ip addr 会多一个kube-ipvs0的设备,
# 集群内部可以ping通,外部不可以,因为他是一个一个Dummy设备,不会相应外部的ARP请求,没有路由信息
跨namespace访问
enableServiceLinks作用
Ingress
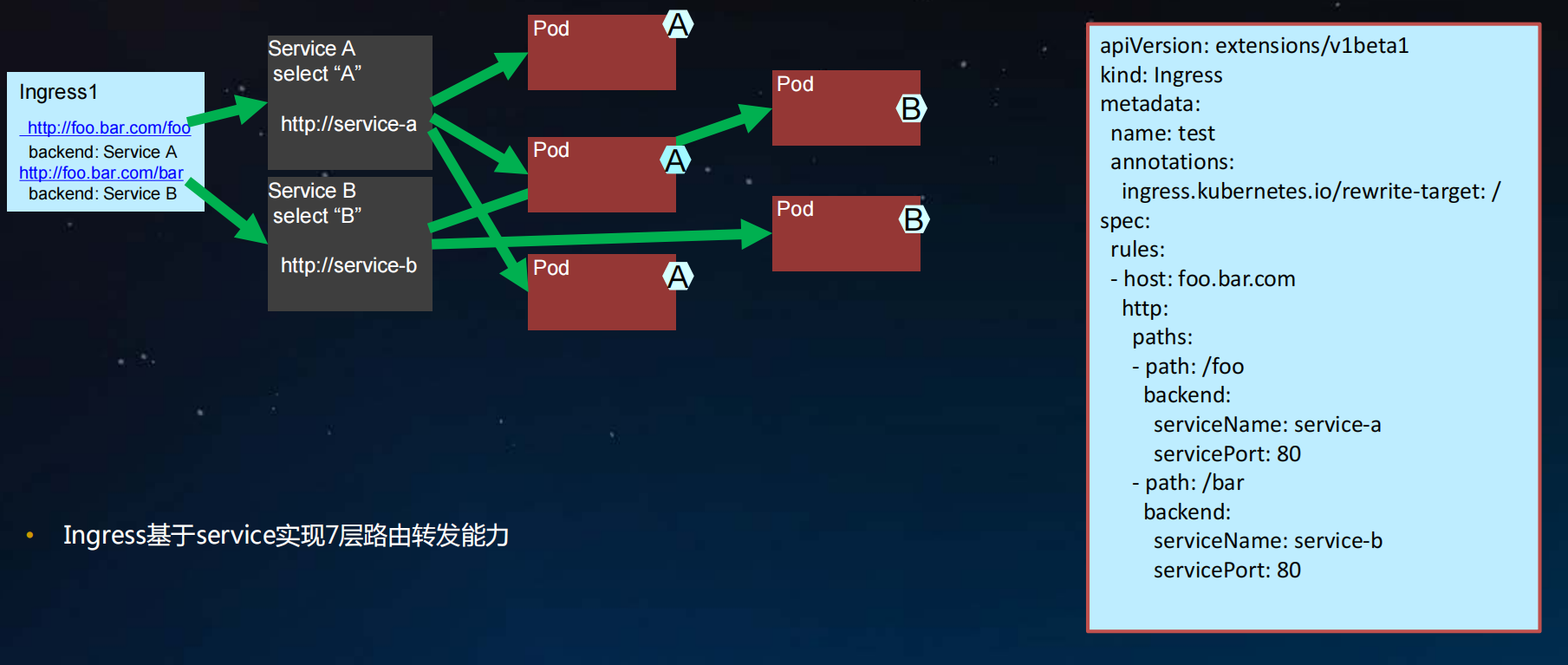
- Ingress基于service实现7层路由转发能力
参考链接:
https://blog.csdn.net/fly910905/article/details/103758149
https://mp.weixin.qq.com/s/dG5EYOJqe8N1T9u6Xjw7tQ
https://kubernetes.io/zh/docs/concepts/workloads/
https://edu.aliyun.com/lesson_1651_18354#_18354
https://edu.aliyun.com/lesson_1651_18353#_18353
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK