

golang-memory-leak-failure
source link: https://yexingzhe54.github.io/passages/golang-memory-leak-failure/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
一次不成功的Golang内存溢出排查
我们的监控服务是以Prometheus加K8S为基础搭建的,运行一段时间后出现了内存溢出的现象,内存RSS占用高达9G,CPU占用60%。以下是整理的排查思路
PProf排查:
我们先查看了应用日志,这些日志内容不断重复,有一定规律,但是当时暂时没有发现特别之处。

接下来,针对Go应用的内存泄露问题,想到了通过官方PProf工具收集应用信息。幸好,Prometheus开启了PProf接口,因此我们可以很方便的得到协程与内存信息。具体过程不表,结果如下:
部分协程信息如下:
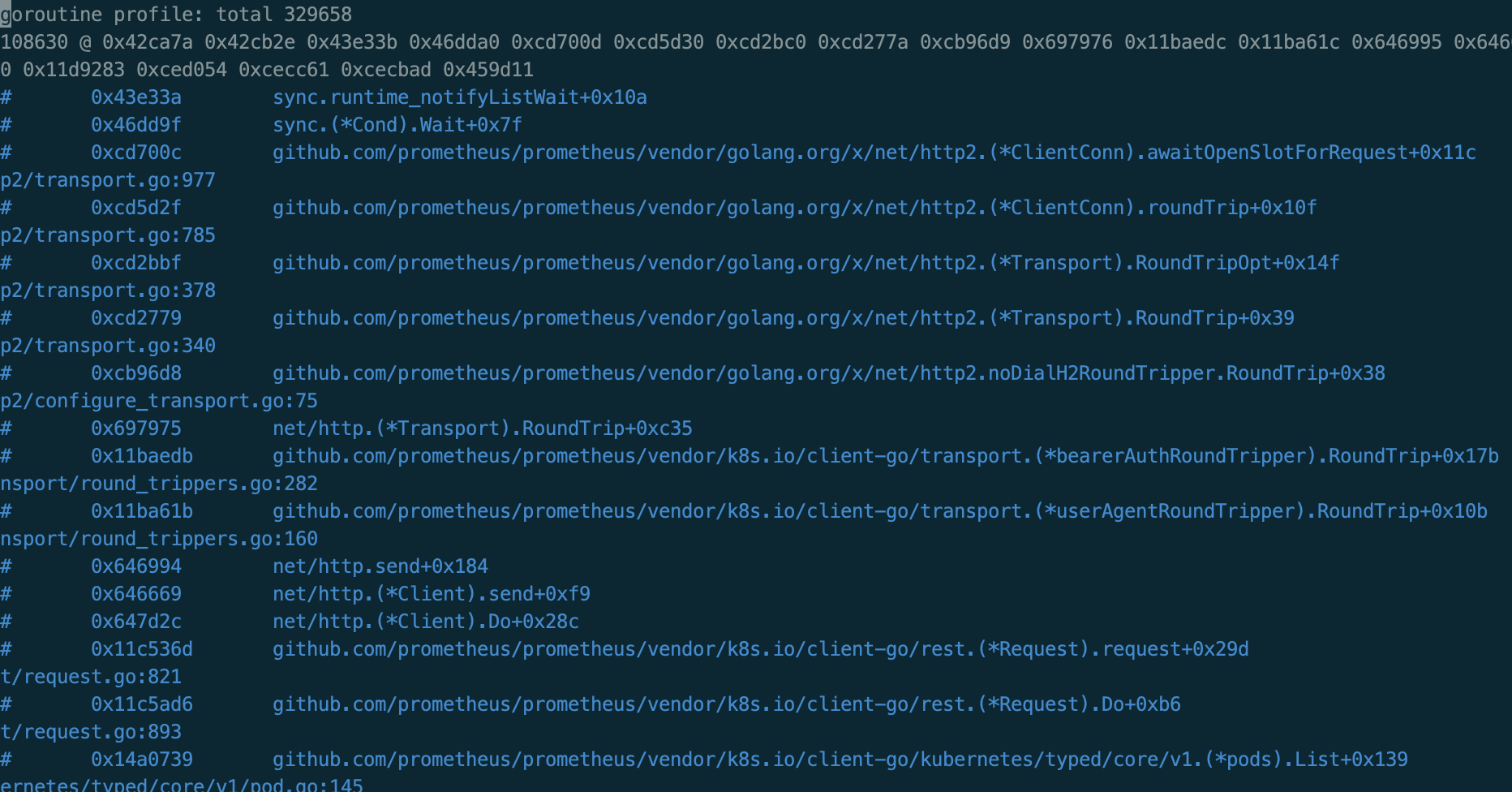
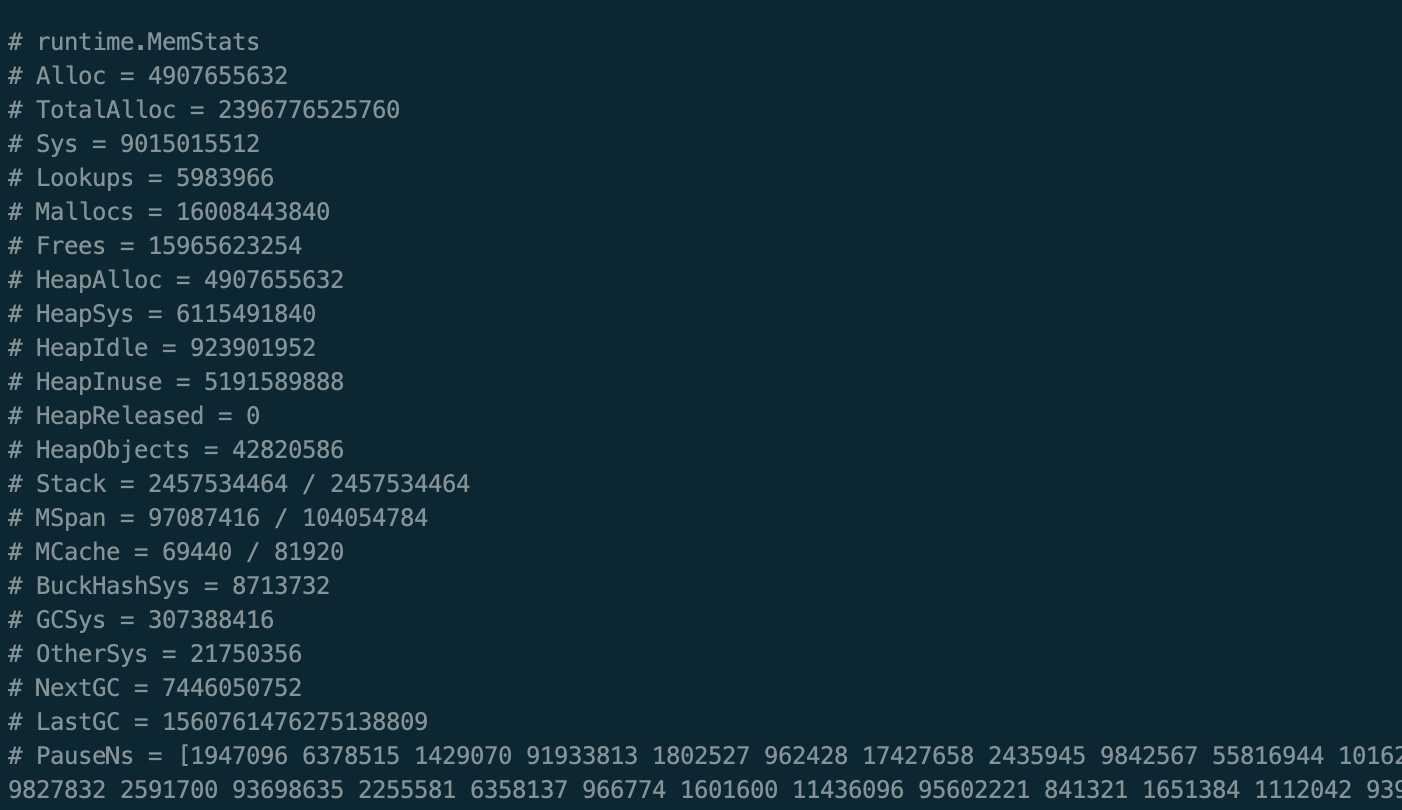
部分内存信息如下:
我们发现协程数量达到了恐怖的30万个,而且其中有10万处在调用K8S的POD API上,另外还有20万分别是SERVICE API和ENDPOINT API没有在图中列出。接着,再查看了容器环境(Prometheus运行在容器网络中)中与K8S API通信的连接个数,很少,只有一个。
我们知道,K8S API基于gRPC协议通信,GRPC又是基于HTTP2协议,支持在一个TCP连接上多路复用多个请求流。因此,只用少数连接就可以同时处理多个请求,这是没问题的。但是现在只有一个连接,这就有点诡异了,一般HTTP2对于最大并发请求数是有限制的,需要客户端与服务端协商,服务端不会允许这么大的单连接并发。
于是,我们顺着协程栈,逐个翻看相关代码,具体细节不表。从代码中了解到Go HTTP2库对最大并发数的默认限制为1000,超出部分将会等待,也就是说,在某种特殊情况下TCP连接上的等待处理请求数量超过了最大限制,导致后续的类似协程都阻塞在条件变量上,并且呈不断增长的趋势。
因此,协程问题变成了两个子问题:
- 什么情况下,会导致待处理请求数超限
- 不断增长的协程,是如何触发的
关于第一个问题,很遗憾没有找到原因,后来也没有复现。
关于第二个问题,从前面的日志里面找到了一丝端倪。通过在代码里搜索日志内容的方式,我们定位到,不断重复的日志的源头来自于:
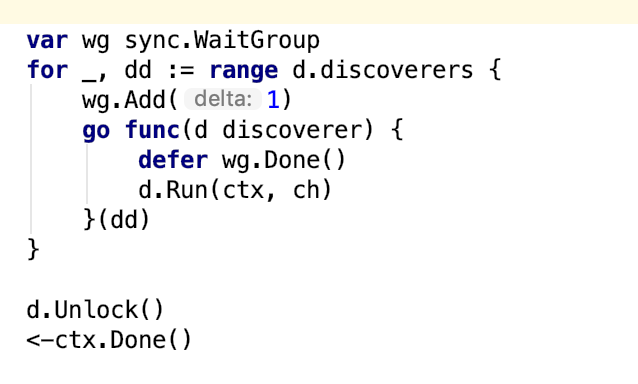
由于这段代码逻辑被反复执行,因此日志内容在不断重复输出。而更巧的是,这段代码所在函数还有另一部分功能,恰好就是启动新协程,通过K8S Client获取POD/SERVICE/ENDPOINT信息!
通过反向追述这段代码的调用源点,发现它会在Prometheus配置文件发生变化的时候被调用。
最后得出部分结论,由于配置文件的频繁更新触发Prometheus的自动加载机制,因此协程数量不断增长。在环境稳定的情况下,配置文件不会频繁变更,因此协程问题得以解决。
我们先照图回顾一下Go应用的内存布局:
Sys = HeapSys + StackSys + MspanSys + MCacheSys + BuckHashSys + GCSys + OtherSys
- Sys 代表了 RSS,也就是从操作系统的角度来看,Go进程(包括内部各个线程)总共占用的系统内存,也是此次关注的重点(9G)。从用途的角度来看,Go内存可以分为:堆,栈,内部数据结构,GC以及其他
这里面比较有意思的是HeapSys和StackSys,其他就不介绍了。
HeapSys == HeapIdle + HeapInuse 代表了作为堆用途的内存空间。堆内存以Span为单元进行管理,从Span中分配内存给对象,分为Idle(没有分配对象)和Inuse(有对象)两种类型。
HeapAlloc == Alloc 代表了堆上的未回收对象的实际占用空间(包括可回收部分)。注意,这和HeapInuse是有区别的。HeapInuse代表了分配对象的Span的大小,而HeapAlloc代表了实际对象的大小,因此可以认为一个是粗统计,一个是细统计,HeapAlloc <= HeapInuse
StackSys 代表协程栈大小,其实是Stack Span的大小,可以和Idle Span互相转换。不同版本Go语言的最小协程栈大小是不同的,这次问题里面的协程栈大小为8K,因此30万协程2.4G,和图中的Stack部分相符,但还不足以解释剩下6G的堆内存占用量。
从图中可以看出,6G堆内存中有接近1G处于Idle,剩下5G左右的实际对象占用量。
注意到堆上分配了4千多万个对象,如果每个对象都120B,几乎就可以解释5G大小的内存开销了。联想到Prometheus需要将近期指标加载到内存中,如果短时间内累计大量指标,确实有可能会导致这样的情况发生。
这次排查问题,还是有不完善之处。
时间不够,也没有思路完整解决协程问题。
对于指标过多的问题,解决方案只能是减少指标监控数据,治标不治本。
本文链接 http://yexingzhe54.github.io/passages/golang-memory-leak-failure/
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK