

elasticSearch(6) - 高级检索
source link: https://blog.51cto.com/arch/5262022
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
一、基础知识
ES的搜索由两部分组成:1、查询;2、获取 ;一般来讲,ES很少用match_all查询,正常是通过查询+过滤器组合的方式来完成;后者不计算得分,且结果可被缓存,性能会更好。具体采用哪种查询类型取决于数据在索引中是如何存储的;
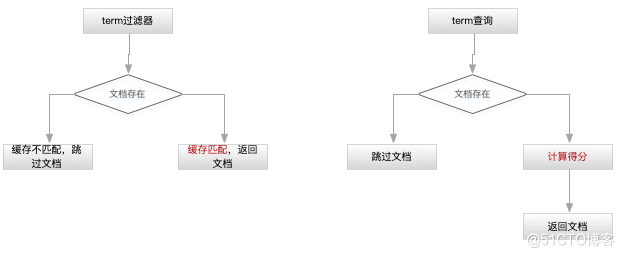
查询过滤器
用于过滤查询结果用,一般用在查询和聚合查询的body条件中。
match_all | match_all:{} | 匹配所有文档 | 全文检查,不太建议用 |
query_string | query_string:{} | 相当于es中开放的由用户自己发挥的通用API,支持+-号等语言 | |
terms | terms:{tags:{}} | 相当于同时查多个词条 | 关键词匹配,在搜索时不进行分析 |
term:{tags:{}} | 只查一个词条 | 关键词匹配,在搜索时不进行分析 | |
match | match:{name:{}} | ||
match:{ name:{ query:"", operator:"and" | 它带了一个operator属性,用于指定词条的组合关系,相当于or或and | ||
phrase | match:{ name:{ query:"", slop:1, type:"phrase" | 适用于多关键字and查询,通过slop来指定关键字的距离,比如只记得某个句子中2个单词,但中间的记不住了,就可以用这个查询 | 查询相似的词组,这里的slop不宜过大,会影响性能。但可以通过query_weight和rescore_query_weight限定评分范围进行二次打分来减少这个影响。 |
phrase_prefix | match:{ name:{ query:"", max_expansion:1, type:"phrase_prefix" | 最后一个词条的前缀匹配,比如输入liudong he可以匹配liudong hemin | |
multi | must、must_not、should | must=and must_not=not should=or | |
range | filter:{range:"time": gt:"", lt:"" | 范围,相当于between | 范围查询,比如时间或数值和字符串 |
prefix | query:{prefix:{}} | 相当于like前缀查询,相当于like aaa% | |
wildcard | query:{wildcard:{}} | 正则表达式,通配符可以用*和% | |
exists | 只查询有特定字段的文档 | ||
missing | 查询没有指定字段的文档,包括null。 |
二、通用用法
es的搜索就是由两部分组成:查询和过滤。
"query": {
"bool": {
"must": [ //1、
{"match": {"field": "sss"}} //2、
],
"filter": [ //3、
{"term": {"status":"published" }},
{"term": {"date":{"gte": "2015-12-21"} }} //4、可选term, range
]
}
}
}
精确匹配-match
"query": {
"match": {
"message": "this ia a test"
}
}
}
模糊匹配-operator
这个是默认生效的,同时也允许换位比如ab--ba。通过fuzzy_trans_positions=false可关闭这个换位功能。
{"query":{
"match":{
"textField":{
"query":"this ia a test",
"operator":"and" //or
}
}
}
}
短语匹配-match_phrase
也可以自定义解析器,在下列第5行message后面再加上"analyzer":"my_analyzer"。
{
"query": {
"match_phrase": {
"message": "this ia a test"
}
}
}
字符串查询
query_string查询解析输入并围绕运算符拆分文本,每个文本部分都是独立解析的, query属性相当于sql的where语句,其中and , or 为关键字。
"query": {
"query_string": {
"default_field": "fieldName",
"query":"this AND that OR thus"
}
}
}
"query": {
"query_string": {
"default_field": "fieldName",
"query":"(new york city) OR (big apple)"
}
}
}
指定匹配多个字段
"query": {
"query_string": {
"fields": ["fieldName1", "fieldName2"], //这里可以用通配符,比如"city.*"
"query":"(new york city) OR (big apple)"
}
}
}
"query": {
"query_string": {
"fields": ["fieldName1", "fieldName2"],
"query":"(new york city) OR (big apple) AND date:[2021 TO 2022]"
}
}
}
"query": {
"query_string": {
"fields": ["fieldName1", "fieldName2"],
"query":"(order_type:100 AND pay_time:[22312312 TO *] AND (store_code:(1001) AND goods_no:(0000 OR p33432) ) )"
}
}
}
三、特殊用法
这里需要设置关键字查询,如果没有query指定的关键字则不会显示高亮结果,有三种高亮器:unified(默认)、plain、fvh。这个功能还有很多其它特性,但用到最基本的就可以了。
"from": 0,
"size": 2,
"query": {
"match": {"firstname": "Hattie"}
},
"highlight": {
"fields": {
"firstname": {}
}
}
}
//返回结果如下
, "highlight": {
"firstname": [
"<em>Hattie</em>"
]
}
//上面的em是默认的,可以通过以下方式自定义
"highlight": {
"pre_tags": ["<tage1>"],
"post_tags": ["</tage1>"],
"fields": {
"firstname": {}
}
这个功能在有时做扩容时会用,即多个索引存储同样的内容,毕竟主分片是不能修改的。下例中的通配符很重要,如果匹配了多个则默认选择第一个,如果一个索引同时存在在多个索引里面,则使用权重高的那个。
"indices_boost": [
{"alias1": 1.4},
{"index*": 1.3}
]
}
不适合实时用户请求,适用于处理大量数据。
{
"size": 100
}
//返回的结果中多了一个,这个值适合传递给下一次的查询,直到没有结果返回
"_scroll_id": "FGluY2x1ZGVfY29udGV4dF91dWlkDXF1ZXJ5QW5kRmV0Y2gBFEc1bDNRSUFCQWh1VUxxTFZ1XzJsAAAAAAAAACsWSi1Jc3M2NnNTbWVkN3dkLVZqVC1sZw==",
{
"size": 100,
"_scroll_id": "FGluY2x1ZGVfY29udGV4dF91dWlkDXF1ZXJ5QW5kRmV0Y2gBFEc1bDNRSUFCQWh1VUxxTFZ1XzJsAAAAAAAAACsWSi1Jc3M2NnNTbWVkN3dkLVZqVC1sZw=="
}
//scroll=1m是有成本的,所以最后一次请求最好手工删除上下文,其中_scroll_id值可为[],多个值用逗号分隔。
DELETE /_search?scroll
{
"_scroll_id": "FGluY2x1ZGVfY29udGV4dF91dWlkDXF1ZXJ5QW5kRmV0Y2gBFEc1bDNRSUFCQWh1VUxxTFZ1XzJsAAAAAAAAACsWSi1Jc3M2NnNTbWVkN3dkLVZqVC1sZw=="
}
或 DELETE /_search?scroll/_all 清除所有上下文
如果滚动查询返回的结果过多,可以用切片并行查询,上滚动查询每次查询的基础上都添加,但这个操作由于会使用缓存,所以使用时需仔细规划下切片的数量。
"id":1,
"max":2 //最大切片数量
}
"slice":{
"id":2,
"max":2 //最大切片数量
}
当数据量过多时,分页搜索性能会各不相同,ES中存在三种分页形式:
- 标准模式:应用于数量量不大的情况,query&from&size。其原理是搜索前from+size条数量,然后返回size条数据,支持排序,但数量量大于性能超差;
- scan模式:search_type=scan&scan=1m&size=100,其原理是按分片轮询scan时间间隔检索直到数据量达到size,因为不是搜索所有分片,所以不支持排序;
- scroll模型:scroll=1m。在所有分片上轮询scroll时间间隔来查询数量,支持排序。但如果数量太多时性能也很差,这一般用于知道分页大小的情况。一个滚屏搜索允许我们做一个初始阶段搜索并且持续批量从Elasticsearch里拉取结果直到没有结果剩下。这有点像传统数据 库里的cursors(游标)。
综上,可以采用几种解决方案来达到深分页效果:1、采用scan方案然后页面排序;2、根据count值来区别使用scan和scroll方案,以及标准模式,但取决于数据量的多少;
search_after
在深分页时可以滚动API,但由于上下文会有大量开销。但可以用以上参数来解决,即用上一页的结果来帮助检索下一页,这个属性必须与sort一起使用。
{
"size": 2,
"sort": [
{"account_number": "asc"}
]
}
//会返回两条数据,其_id值分别为0,和2,然后第二次查询时用
{
"size": 2,
"search_after":[0,2],
"sort": [
{"account_number": "asc"}
]
}
默认是存储在source中的,
查看当前记录的版本信息
验证查询的有效性
{
"_shards": {
"total": 1,
"successful": 1,
"failed": 0
},
"valid": true
}
四、性能相关
Explain参数
"explain":true
"query": {
"match_all": {}
}
}
//其返回数据会写在结果的details字段里

- <1> honeymoon 相关性评分计算的总结
- <2> 检索词频率
- <3> 反向文档频率
- <4> 字段长度准则
refresh参数
此参数可在api索引、更新、删除和批量API中使用,当值为true时,则表示操作发生后立即执行刷新相关的主副分片。这个操作比较影响性能,但在有些场合中比较有用。还有另一个参数index.max_refresh_listeners来设置强制刷新。默认为1000,表示当某个分片上等待刷新的请求有1000个时将强制刷新,批量请求视为一次。
调优hot_threads命令
- 慢查询:用户可设置时间,返回的搜索语句,index.search.slowlog.fetch.query.warn
- 慢索引:用户可设置时间,返回的索引语句,index.search.slowlog.threshold.query.warn
- 热API:即ES的线程工作类型,比如搜索、合并等;
五、关联查询
在分布式系统中跨表查询的代价是非常大的。所以此部分需要专门设计。这一般没有标准,需要和数据存储结构以及架构设计相关。使用哪种查询需要知道数据是如何存储的,否则会出现意外的情况。在mapping时使用type来区分
底层Lucene的数据全是扁平的存储,如果是对象型的JSON对象也会拉平,数组等同样的处理;
对象类型-1对1
一对一,type=object,把对象以JSON的方式存储,比如address,这种存储方式适合单个条件查询,当单条件查询时都可以定位到准确的字段,当两个条件混查时 ,上面的例子可能就匹配不到数据或匹配到两条数据。另一个缺点时更新文档时要重新索引整篇文档,单查询条件时是否使用这种方式取决于文档的大小和操作的频度。
name:"denver technology group", event:[ {date:2015, title:"hadoop"}, {date:2016, title:"spring"} | name:"denver technology group", event.date:[2015, 2016], event.title:["hadoop", "spring"] |
嵌套文档-1对N
一对多,type=nested。其查询时可以用nested过滤器,对象问题的解决方案,就是采用嵌套存储,把同一条数据采用位置相邻的方式存储。就是去掉上面的数组结构,全部打平。但这种方式的问题是把所有的数据存放在了现一个文档中,一旦数据发生变化时性能会比较差。但是否使用这种方式取决于文档的大小和操作的频度。
存储结构,默认会索引成相邻的三块 | 指定include_in_parent属性后 | 指定include_in_root属性后 | |
name:"denver technology group", event:[ {date:2015, title:"hadoop"}, {date:2016, title:"spring"} | name:"denver technology group" date:2015 title:"hadoop" date:2015 title:"spring" | name:"denver technology group" date:2015 title:"hadoop" name:"denver technology group", date:2015 title:"spring" name:"denver technology group", | date:2015 title:"hadoop" date:2015 title:"spring" name:"denver technology group", event.date:[2015, 2016], event.title:["hadoop", "spring"] |
父子关系-1对N
一对多,用_parent属性来定义,采用分组方式,再用映射指定父子关系。当子类查询有数据时就返回其父类。可以使用has_child和has_parent过滤器来查询。这种存储的好像是文档分离存储,不会发生全部需要重新索引的情况发生。缺点是会占用更多的资源。
{name:"denver technology group", _id:1} {date:2015, title:"hadoop", _parent:1} {date:2016, title:"spring", _parent:1} |
反规范化-N对N
多对多,type=group,同一数据多处复制,优点是采用 冗余数据的方式能保证数据保存在同一个分片中,省去了跨表查询以及应用端连接的网络开销问题。缺点是要更新多次副本。所以在设计时要考虑到实际的更新场景,是子复制主,还是子复制主,即复制方向问题。另外一个缺点是进行索引、更新和删除时要处理冗余数据问题。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK