

容器网络和kube-proxy笔记整理
source link: https://ninokop.github.io/2018/01/21/kube-proxy/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
前段时间作死把hexo的图片显示搞崩了,长时间不想写东西,也不知道自己在瞎忙什么。为了重新进入学习状态,还是老老实实把以前写过的东西汇总一下吧。
写了一半发现容器网络的内容太多太杂 挖个坑 以后填
Linux Bridge
第一次对Linux Namespace有了解是看了这篇博客,按照博客介绍的方法模拟了docker0网桥来隔离两个网络命名空间。docker run一个容器之后,docker会创建称为docker0的linux bridge,而且还有一个veth5e66437的类似于虚拟网卡的东西。
物理的网桥是一个标准的二层网络设备,一般它只有两个网口,连接两个物理网络,起到基本的隔离冲突域的作用。网桥通过MAC地址学习的方式实现二层上相对高效的通信。目前标准网桥设备大概已经被淘汰了,替代者是二层交换机,可以算是多口网桥。
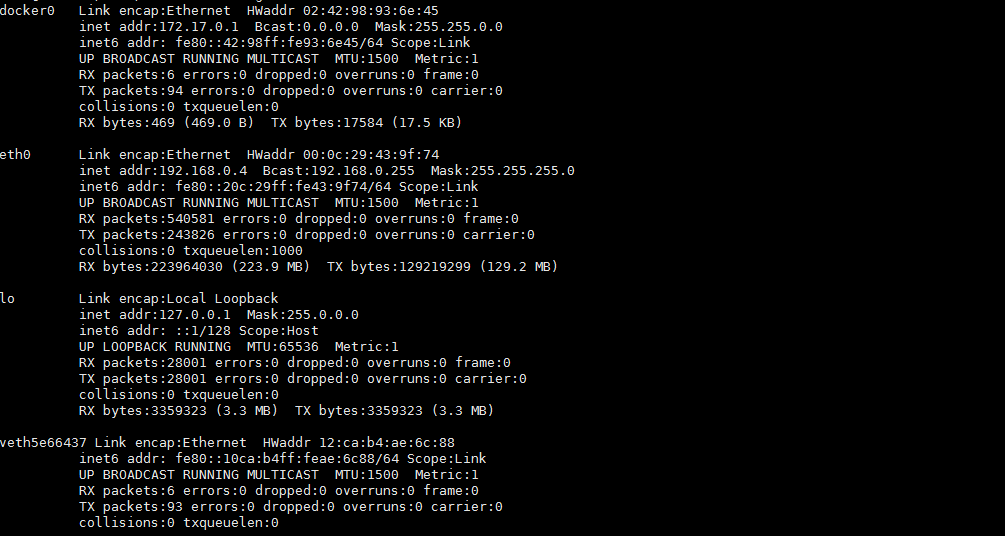
之前一直有个疑问,为什么docker0转发的时候会经过iptables,为什么不在二层通过MAC学习直接转发了。后来找到一种比较能理解的说法是:linux bridge可以在二层转发,docker run之后docker daemon打开了以下参数,使bridge的Netfilter可以复用IP层的Netfilter代码,如果关掉这个参数,其实可以通过二层直达的包就不会在iptables日志里看到了。
/proc/sys/net/bridge/bridge-nf-call-iptables
还有一个问题是,bridge本身是个带IP的有三层属性的设备,它本身是有ip包forward能力的,前提是打开了ip_forward参数。不然可能出现docker0拒绝掉发往容器的ip包。
创建net命名空间模拟docker0
以下记录创建网桥并且配置网桥的地址和网段。
brctl addbr lxcbr0
brctl stp lxcbr0 off
ifconfig lxcbr0 172.17.20.1/24 up
创建一个net namespace,激活其的loopback设备。创建一对虚拟网卡veth-ns2和veth-ns1,并把veth-ns2这个网卡按进ns2中,将ns2中这个网卡设为eth0,并且配置ip地址和激活。
ip netns add ns2
ip netns exec ns2 ip link set dev lo up
ip link add veth-ns2 type veth peer name veth-ns1
ip link set neth-ns2 netns ns2
ip netns exec ns2 ip link set dev veth-ns2 name eth0
ip netns exec ns2 ip ifconfig eth0 172.17.20.11/24 up
把这一对虚拟网卡的另一个veth-ns1添加到lxcbr0这个网桥当中,并为ns2添加一个路由规则,让ns2可以通过默认路由访问到lxcbr0。
brctl addif lxcbr0 veth-ns1
ip netns exec ns2 ip route add default via 172.17.20.1
ip link set veth-ns1 up
添加路由后可以从ns2 ping 主机IP,最终会会通过默认路由发到lxcbr0,即主机上。

在docker0添加网卡
当主机上跑了多个容器时,会发现vethxxxx这种虚拟网卡对变多,这意味着每docker run一个容器都会创建一个虚拟网卡,其中peerA连接到docker0网卡并启动,peerB则放入另一个隔离的netns,设置它的名字为eth0,配置ip地址并启动。最后在内外添加路由就可以互相通信了。那对以有的容器,如何在容器里动态添加另一块网卡eth1,操作很类似,只是首先要找到这个容器对应的ns是什么。

正常情况下我们创建一个ns空间会在/var/run/netns下看到对应的描述符,然后通过ip netns exec nsx这种命令去另一个net命名空间执行命令。但docker可能为了不让用户误操作吧,把这个netns隐藏了。可以通过以下方式去找到这个空间并挂到/var/run/netns目录下。
pid=`docker inspect -f '{{.State.Pid}}' $container_id`
ln -s /proc/$pid/ns/net /var/run/netns/$container_id
在这个docker0添加一对网卡的方式也跟上面差不多。
ip link add peerA type veth peer name peerB
brctl addif docker0 peerA
ip link set peerA up
ip link set peerB netns ${container_ip}
ip netns exec ${container_ip} ip link set dev peerB name eth1
ip netns exec ${container_ip} ip link set eth1 up
ip netns exec ${container_ip} ip addr add ${br_ip} dev eth1
iptables
通常所说iptables是Linux内置的防火墙,由netfilter和iptables两部分组成。netfilter在内核空间,是内核的一部分,它包含N张数据的过滤表,这些数据表描述了内核控制数据过滤的规则。iptables是个用户空间的工具来修改这些过滤表的规则。

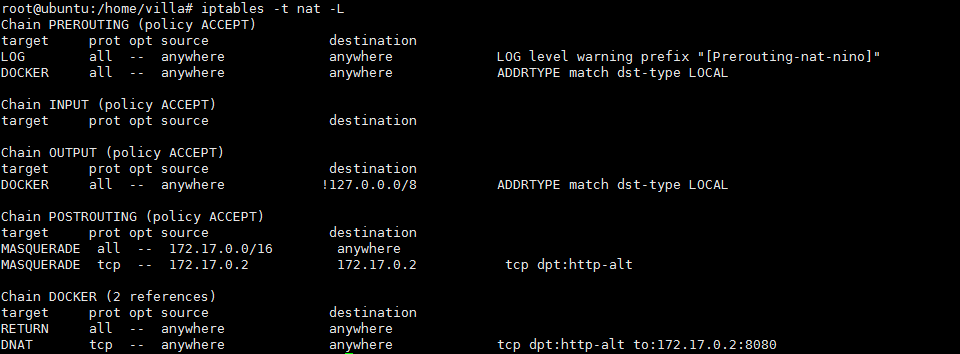
netfilter主要涉及4个表和5个链,四个表的优先级为raw->manage->nat->filter。
- filter表专门用来过滤表,它内建了三个链。如上图所示INPUT链是在路由后针对那些目的地是本地的包的过滤,FORWARD链过滤所有源和目的都不是本地的包,OUTPUT链过滤所有本地产生的包。
- nat表用来做地址转换。在路由前会经过PREROUTING链修改包的目的地址(DNAT),OUTPUT链会改变本地产生的包的目的地址(DNAT),POSTROUTING链则是在包离开前改变其源地址(SNAT)。
- manage表用来修改数据包,可以改变包和包头的内容,比如TTL、TOS、MARK等。
- raw表暂时理解为可以跳过netfilter的一些tracing过程。
iptables log
ubuntu14.04的iptables日志可以在/var/log/syslog里查看,前提是在iptables规则里设置了日志等级。比如说通过以下命令可以给nat表的prerouting链添加日志级别为4,且带有相关prefix标记的日志。这个日志也可以通过-D命令删除或者换位。
iptables -t nat -I PREROUTING -j LOG --log-level 4 --log-prefix "[Prerouting-nat-nino]"
iptables -t nat -D PREROUTING 2
可以通过-t指定表来查看对应规则。
docker网络
四种原生网络模式
bridge模式表示将一个主机上的docker容器连接到一个虚拟网桥上。none模式表示docker容器拥有自己的netns,但并不为docker容器配置任何网络,也就是它没有网卡、ip和路由信息,需要自己去配置好。host模式是容器不会获得独立的netns,而是和宿主机公用一个netns,容器继续使用宿主机的IP和端口。container模式指新创建的容器和已经存在的一个容器共享一个netns。
这里公用netns的意思是,其他linux 命名空间是隔离的。
容器到容器
从容器172.17.20.11访问同主机上的另一个容器172.17.20.13,因为他们都挂在同一个docker0上,所以容器会发现目的地址在route的172.17.20.0/24这个网络内,且网络是U直达的,所以直接把包发到容器内eth0上。这个eth0网卡就是通过vethpair挂在docker0上的网卡的一端,于是包直接发到了docker0。主机从docker0网卡收到包,发现mac地址不是本机,于是网桥开始转发可以在FORWARD链上看到记录。
容器中查了下arp缓存,发现有172.17.20.13的mac地址,所以试了下去掉主机route发现仍然是可以通的。
容器到主机
在容器中curl host肯定是走默认路由的,包会带上Gateway的mac地址,即包通过eth0发到docker0。docker0收到包后发现mac地址就是自己,于是包开始往上层协议栈走。这时可以分别在NAT的PREROUTING链、FILTER的INPUT链上看到数据包。

当主机上层处理完数据发给容器时会走docker0这个直连网络,通过二层的arp缓存找到容器对应的mac地址,通过linux bridge上与之对应的veth设备发出。
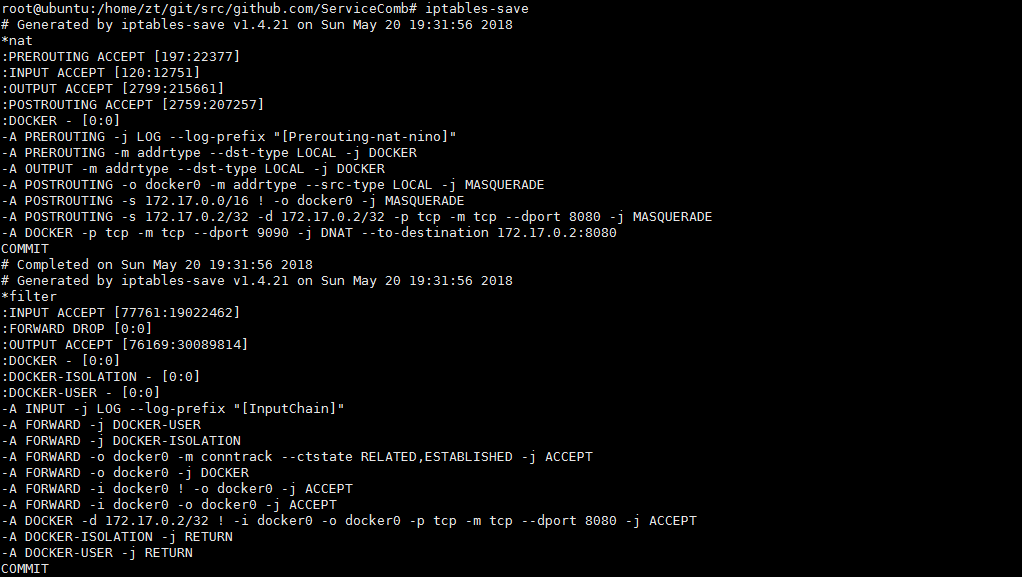
如果是从容器发往同一个网络中别的主机,在发出之前会做SNAT(MASQUERADE),将源地址换为主机IP发送。看到NAT表的POSTROUTING链刚好有这个SNAT的规则,即把所有源地址是容器的数据全都改成网卡地址。
Chain POSTROUTING (policy ACCEPT)
target prot opt source destination
MASQUERADE all -- 172.17.0.0/16 anywhere
MASQUERADE tcp -- 172.17.0.2 172.17.0.2 tcp dpt:http-alt
数据回到主机之后不是用DNAT回到容器的,而是通过filter表的这条规则处理的,即conntrack模块记录了连接的四种状态,内核负责把包发到原来的连接上,最终回到容器内部。
Chain FORWARD (policy DROP)
target prot opt source destination
ACCEPT all -- anywhere anywhere ctstate RELATED,ESTABLISHED
端口映射有两种方式,默认的是docker-proxy+iptables DNAT的方式。当通过docker run -p指定了host port和对应容器端口的映射关系后,会启动对应的docker-proxy进程来处理转发。如果docker启动带上--userland-proxy=false就不会有这个proxy。
docker-proxy -proto tcp -host-ip 0.0.0.0 -host-port 8080
-container-ip 172.17.0.2 -container-port 8080
不论哪种方式,最终NAT的PREROUTING链会处理dst-type为local的请求。把所有目的端口为9090的请求转给容器对应端口,完成端口映射。
Chain PREROUTING (policy ACCEPT)
target prot opt source destination
DOCKER all -- anywhere anywhere ADDRTYPE match dst-type LOCAL
Chain DOCKER (2 references)
target prot opt source destination
DNAT tcp -- anywhere anywhere tcp dpt:9090 to:172.17.0.2:8080
kube-service
就不写概念了,总结来说service解耦了后端提供服务的pod和用户的访问,它本身是个逻辑概念,用户只要访问service的clusterIP和clusterPort就可以轮询的访问到后端关联到这个service的pod。具体完成这个负载均衡的就是kube-proxy,它是运行在每个node节点上的简单的网络代理和负载均衡器。
service的三种方式:clusterIP nodePort和Loadbalancer
kube-proxy有三种转发流量的方式,包括userspace、iptables、ipvs。userspace这种模式涉及到数据包从内核态到用户态的拷贝,然后做代理和转发。iptables模式下kube-proxy直接修改iptables规则来转发包。ipvs模式是内核基于netfilter实现的L4负载均衡,还没用过,以后再说。
iptables
环境上部署了hello-node这个应用对应后端两个pod,分别对应172.31.0.3:80和172.31.0.18:80。这个Service以NodePort的形式发布,对应的nodePort为30012。
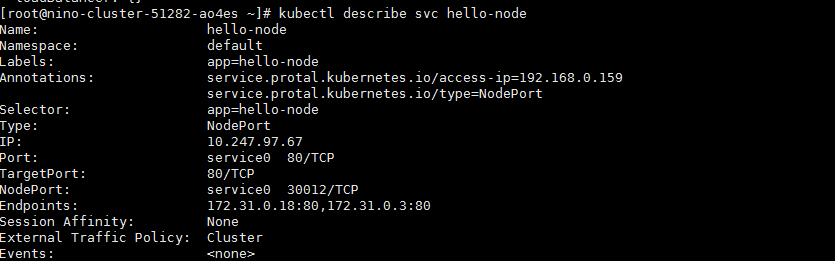
如下所示的两条iptables规则将访问本机nodePort的请求转发给KUBE-SVC-D4CJ3Y6U24W4OUPV链。除了nodePort这种方式外,在集群内部访问时通过ClusterIP访问最后发现也定向到这个D4CJ3Y6U24W4OUPV链。
-A KUBE-NODEPORTS -p tcp -m comment --comment "default/hello-node:service0"
-m tcp --dport 30012 -j KUBE-SVC-D4CJ3Y6U24W4OUPV
-A KUBE-SERVICES -d 10.247.97.67/32 -p tcp -m comment --comment "default/hello-node:service0 cluster IP"
-m tcp --dport 80 -j KUBE-SVC-D4CJ3Y6U24W4OUPV
这个D4CJ3Y6U24W4OUPV链对应的规则为50%的流量进入B6YQYXVNZHOCD2LT链,另外50%进入进入另一链。这两个链分别指向两个后端pod。
-A KUBE-SVC-D4CJ3Y6U24W4OUPV -m comment --comment "default/hello-node:service0"
-m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-B6YQYXVNZHOCD2LT
-A KUBE-SVC-D4CJ3Y6U24W4OUPV -m comment --comment "default/hello-node:service0"
-j KUBE-SEP-IV46MKISZCOZ32CD
B6YQYXVNZHOCD2LT规则表示做DNAT,将目的地址改为容器地址172.31.0.18:80。IV46MKISZCOZ32CD表示做DNAT将目标地址改为172.31.0.3:80。
-A KUBE-SEP-B6YQYXVNZHOCD2LT -p tcp -m comment --comment "default/hello-node:service0"
-m tcp -j DNAT --to-destination 172.31.0.18:80
-A KUBE-SEP-IV46MKISZCOZ32CD -p tcp -m comment --comment "default/hello-node:service0"
-m tcp -j DNAT --to-destination 172.31.0.3:80
userspace
这个跟iptables规则不同的是,kube-proxy为每个service都监听一个随机端口,流量最终是转给kube-proxy的,由它做用户空间的代理和转发。这种模式下会在iptables nat表的PREROUTING和OUTPUT链上捕捉发给本机nodePort的数据,并DNAT到本机的36463随机端口。
-A KUBE-NODEPORT-CONTAINER -p tcp -m comment --comment "default/hello-node:service0"
-m tcp --dport 30012 -j REDIRECT --to-ports 36463
-A KUBE-NODEPORT-HOST -p tcp -m comment --comment "default/hello-node:service0"
-m tcp --dport 30012 -j DNAT --to-destination 10.120.195.2:36463
同理访问到ClusterIP的数据也会转发到本机的36463随机端口。其中前者是捕获了从容器发起的访问ClusterIP的流量,REDIRECT是DNAT的一种,意思是把数据包的目的地址转为该数据包进来时的网络接口的IP地址。
-A KUBE-PORTALS-CONTAINER -d 10.247.97.67/32 -p tcp -m comment --comment "default/hello-node:service0"
-m tcp --dport 80 -j REDIRECT --to-ports 36463
-A KUBE-PORTALS-HOST -d 10.247.97.67/32 -p tcp -m comment --comment "default/hello-node:service0"
-m tcp --dport 80 -j DNAT --to-destination 10.120.195.2:36463
kube-proxy
简单来说kube-proxy不论工作在哪种模式,它代理和转发的规则都是通过service和endpoint这两种资源的变化配置的。以下是proxy启动部分的代码。
func (s *ProxyServer) Run() error {
...
informerFactory := informers.NewSharedInformerFactory(s.Client, s.ConfigSyncPeriod)
serviceConfig := config.NewServiceConfig(
informerFactory.Core().InternalVersion().Services(), s.ConfigSyncPeriod)
serviceConfig.RegisterEventHandler(s.ServiceEventHandler)
go serviceConfig.Run(wait.NeverStop)
endpointsConfig := config.NewEndpointsConfig(
informerFactory.Core().InternalVersion().Endpoints(), s.ConfigSyncPeriod)
endpointsConfig.RegisterEventHandler(s.EndpointsEventHandler)
go endpointsConfig.Run(wait.NeverStop)
go informerFactory.Start(wait.NeverStop)
// Birth Cry after the birth is successful
s.birthCry()
// Just loop forever for now...
s.Proxier.SyncLoop()
return nil
}
kube-proxy分了三类proxy,iptables就是根据service和endpoint的变化更新缓存,然后队列循环去刷新iptables。userspace是根据service和endpoint来创建proxySocket,并开始ProxyLoop。对每个service都创建一个proxySocket。
func (tcp *tcpProxySocket) ProxyLoop(service proxy.ServicePortName,
myInfo *ServiceInfo, loadBalancer LoadBalancer) {
for {
inConn, err := tcp.Accept()
if err != nil {
...
continue
}
outConn, err := TryConnectEndpoints(service,
inConn.(*net.TCPConn).RemoteAddr(), "tcp", loadBalancer)
if err != nil {
inConn.Close()
continue
}
go ProxyTCP(inConn.(*net.TCPConn), outConn.(*net.TCPConn))
}
}
获得后向转发地址是通过loadBalancer模块实现的,然后通过dial获取后向的connection。代理的过程直接用的copyBytes也是简单粗暴。
func TryConnectEndpoints(service proxy.ServicePortName, srcAddr net.Addr, protocol string,
loadBalancer LoadBalancer) (out net.Conn, err error) {
sessionAffinityReset := false
for _, dialTimeout := range EndpointDialTimeouts {
endpoint, err := loadBalancer.NextEndpoint(service, srcAddr, sessionAffinityReset)
....
glog.V(3).Infof("Mapped service %q to endpoint %s", service, endpoint)
outConn, err := net.DialTimeout(protocol, endpoint, dialTimeout)
if err != nil {
...
sessionAffinityReset = true
continue
}
return outConn, nil
}
return nil, fmt.Errorf("failed to connect to an endpoint.")
}
func ProxyTCP(in, out *net.TCPConn) {
var wg sync.WaitGroup
wg.Add(2)
glog.V(4).Infof("Creating proxy between %v <-> %v <-> %v <-> %v",
in.RemoteAddr(), in.LocalAddr(), out.LocalAddr(), out.RemoteAddr())
go copyBytes("from backend", in, out, &wg)
go copyBytes("to backend", out, in, &wg)
wg.Wait()
}
func copyBytes(direction string, dest, src *net.TCPConn, wg *sync.WaitGroup) {
defer wg.Done()
n, err := io.Copy(dest, src)
if err != nil {
if !isClosedError(err) {
glog.Errorf("I/O error: %v", err)
}
}
dest.Close()
src.Close()
}
在kubernetes网络模型中每个Pod拥有独立的IP,Pod内的容器共享一个网络命名空间,对比下单机运行docker的情况,后者是每个容器container都是个独立的netns。k8s中通过infra容器或者叫pause容器来实现在pod中所有容器共享一个linux命名空间,不只是网络命名空间。pause相当于是这个命名空间的init进程,后续pod中的容器只是依次加入到这个命名空间。
同一个集群内所有pod之间以及pod与node之间都可以通过ip直接访问,不需要经过NAT。
CNI是CoreOS发起的容器网络规范,是k8s网络插件的基础。接口简单就AddNetWork和DelNetWork,他们负责给容器配置网络。常见的CNI插件有Bridge、PTP、IPVLAN、MACVLAN、vLAN、PORTMAP。Bridge就是最常用和最简单的CNI,之前写过相关原理,这种模式下多主机网络通信需要配置主机路由或者是用overLay网络。
- kubelet先创建pause容器,和对应的netns
- 调用CNI driver,根据配置调用具体的CNI 插件,给pause容器配置网络
- pod中其他容器都是用这个pause容器的网络
flannel
这部分的图转自理解Kubernetes网络之Flannel网络。在默认的docker配置中,每个节点上的docker负责各自节点容器的ip分配,这导致不同主机的ip地址可能相同。flannel的设计目的是为集群中所有节点重新规划ip地址的使用规则,使得这些不同主机的容器能够获得同属一个内网且不重复的ip地址,并使这些容器可以通过内网ip进行通信。flannel是一种overlay网络,就是将tcp数据包装在另一种网络包里进行路由转发和通信,民居前支持UDP VxLAN等方式。
- 为集群内每个节点分配子网,容器将自动从该子网中获取ip地址
- 当有新的节点加入到网络时,为每个node增加路由配置
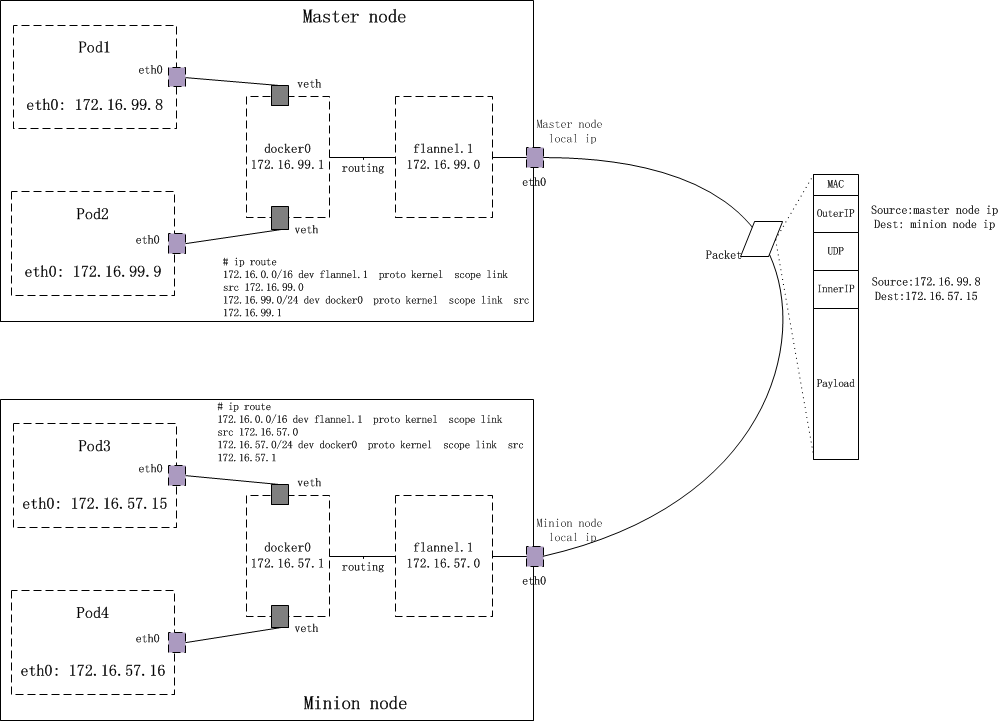
不同节点docker怎么使用不同ip地址
flannel通过etcd分配了每个节点可用的ip地址段,修改了docker的启动参数,通过–bip限制了docker0分配的容器ip范围,flannel确保给每个节点的ip地址段是不重复的。
路由表怎么改
通常flannel跟docker的网络段是包含关系,所以发到docker0的数据查询route就会发现跟flannel0对应的网络是直连,因此发到flannel0。如果发现网段不匹配,重启docker和flanneld。
overlay的转发方式 udp vxlan
如果是VxLAN的方式,则flannel0收到后不会转发给eth0,因为它是个vxlan设备,即virtual tunnel end point。flannel0发现目的地址不是自己,但在直连网络中。这时并不会arp直接问mac地址,内核会为vxlan设备引发一个L3 miss事件,并把arp请求发到用户空间的flanned进程。
flanneld会从etcd当中找子网对应的vxlan对端vtep设备的mac地址,并写入节点的arp缓存,然后内核就用这个mac地址封装以太帧。这个帧实际是vxlan隧道上的包,不能在物理网络传输。内核会再次封包,向flanneld发起L2 miss事件,通过etcd获取vtep设备对应的node的IP,并注册到fdb。
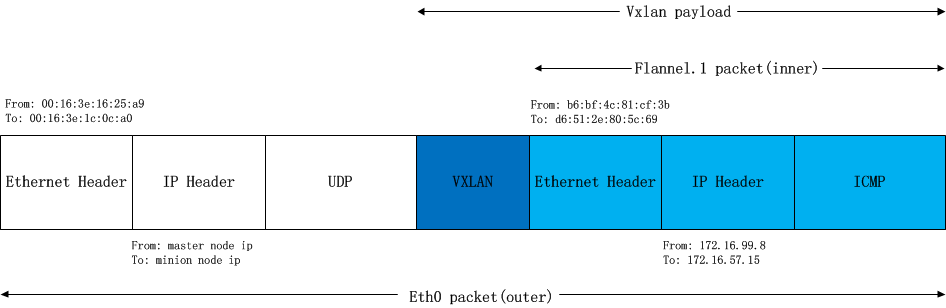
最后这个包把整个上面的以太包封城了udp包,然后再IP+mac封好,发到对端节点上。对端节点揭开udp包发现时vxlan包,于是拆包后将这个包发给本机的flannel0设备。
calico & weave & canal
calico是个纯三层的数据中心网络方案,不需要overlay。每个容器都分配了一个可路由的ip,通信时不需要解包和封包网络性能损耗小。weave是去中心化的方案,通过每个host运行wRouter,并保持TCP连接。我们貌似用的是cannel,结合了flannel和calico。采用flnnael的vxlan实现host2host的通信,同时基于calico的网络策略能力实现了pod之间的网络隔离。
问题分析和解决
这个是同事前两年写的,几个容器网络相关问题的分析和解决总结。居然在论坛上找到了,转载一下。
能跨host访问docker0,而无法访问pod ip
检查ip_forward参数是否为1,若不为1则内核收到来自docker0的非本地地址的数据包会丢弃,而不会转发出去。
flannel隧道内部payload的源地址改变为flannel0设备的地址
iptables规则有一条,所有从docker0地址发出的数据修改为出站时的地址。
-A POSTROUTING -s 10.1.15.0/24 ! -o docker0 -j MASQUERADE
如果容器可以ping通host,但ping不通别的host ip
可能是缺少从容器出去做SNAT的iptables规则
iptables -t nat -A POSTING -s 172.16.94.0/24 -j SNAT -to 10.120.195.2
k8s集群掉线之后所有服务不可访问
docker0和flannel0的网路配置不一样,网段不同,导致双方无法通信。flannel的网路配置在etcd中,所以以它为准,重启docker0并修改–bip保证网段范围和flannel0是一致的。
k8s master机器上ping不通node节点的docker0和容器,但在node上可以
master节点上在INPUT和FORWARD链上拒绝了icmp包,删除就好。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK