

“Machine learning - Hidden Markov Model (HMM)”
source link: https://jhui.github.io/2017/01/15/Machine-learning-Hidden-Markov-Model-HMM/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Hidden Markov Model (HMM)
There are hidden states of a system that we cannot observe directly. 20% chance that we go to watch a movie when we are happy but also 40% chance when we are upset. People may tell you what they did (observable) but unlikely tell you the truth whether they were happy or upset (the hidden state). Given the information on the chance of what people do when they are upset or happy, we can uncover the hidden state (happy or upset) by knowing what they did.
Prior belief: Here is our belief on the chance of being happy and upset.
Observables (what we do):
Here is the likelihood: the chance of what will we do when we are happy or upset.
| movie | book | party | dinning | |
| Given being happy | 0.2 | 0.2 | 0.4 | 0.2 |
| Given being upset | 0.4 | 0.3 | 0.1 | 0.2 |
Compute the posterior:
Hence, the chance that a person goes to party because he/she is happy is 94%. This is pretty high because we have a high chance of being happy and also high chance to go party when we are happy.
In reality, being happy or upset is not independent. Instead, it can be better model by a Markov Model. Here is the transition probability from xtxt to xt+1xt+1.
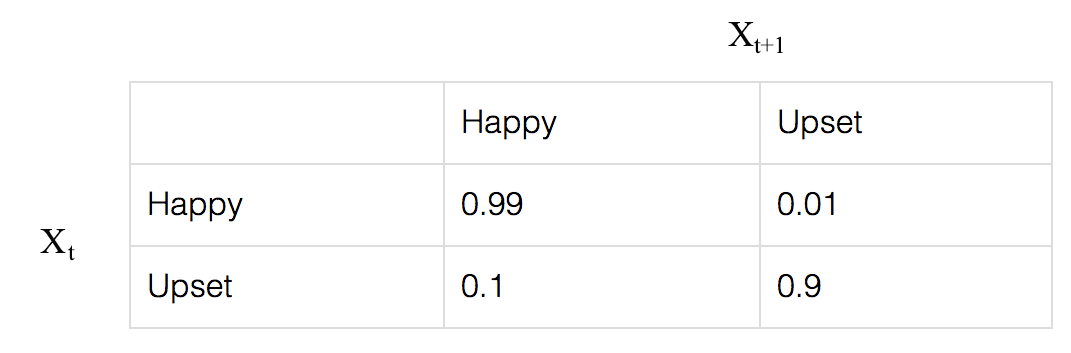
For example,
he Markhov process for 2 timesteps is:
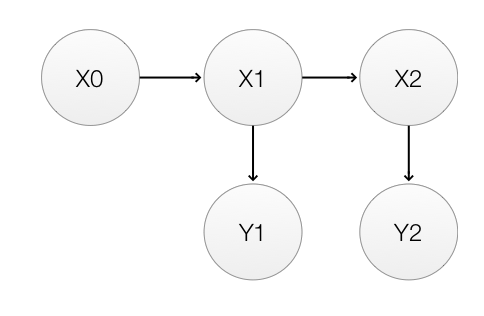
To recap,
P(x0)P(x0):
P(xt+1|xt)P(xt+1|xt):

P(yt|xt)P(yt|xt):
| movie | book | party | dinning | |
| Given being happy | 0.2 | 0.2 | 0.4 | 0.2 |
| Given being upset | 0.4 | 0.3 | 0.1 | 0.2 |
Our objective is to calculate:
Given:
We re-calculate our objective:
Given a modified Bayes’ theorem:
To make prediction:
Recommend
-
39
Hello again friends!This is post number six of our Probability Learning series, listed here in case you have missed any of the previous articles:
-
28
这篇文章主要介绍目前一些语音识别技术与HMM有什么关系,然后你就会发现,很多技术其实有借用HMM的思想 过去,我们用统计模型的方式来做语音识别...
-
15
Dynamic programming for machine learningDynamic programming for machine learning: Hidden Markov Models Jun 24, 2019 • Avik Das
-
8
February 17, 2019 By Abhisek Jana
-
13
PSN hmm... Jul 29, 2008 • Andre Weissflog I have removed the PSN "Portable ID" on the left side. Seems like it's just a static display for my user name and avatar picture doh... And I can't believe that Sony doesn...
-
10
Hi everyone, In this week’s video, Rik Van Bruggen and Marius Hartmann explain how to do fraud detection with graphs. Zuye Zheng analyses r/WallStreetBets, Hadi Fadlallah migrates data from SQL Se...
-
7
【HMM】理论篇 2017年11月11日 Author: Guofei 文章归类: 2-1-有监督学习 ,文章编号: 280 版权声明:本文作者是郭飞。转载随意,但需要标明原文...
-
10
隐马尔科夫模型(Hidden Markov Model,HMM)是经典的机器学习模型,它在语言识别自然语言处理,等领域得到广泛的应用。虽然随着目前深度学习的崛起,尤其是RNN等神经网络序列模型的火热,HMM的地位有所下降。但是作为一个经典的模型,学习HMM,对...
-
10
February 13, 2019 By Abhisek Jana 2 Comments
-
10
隐马尔可夫 (Hidden Markov Model, HMM),条件随机场 (Conditional Random Fields, CRF) 和序列标注 (Sequence Labeling) 范叶亮 / 2020-05-02 分类:
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK