

GFS论文阅读笔记
source link: https://imnisen.github.io/read-gfs-paper.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
1 设计总览
1.1 特性
GFS设计的时候几个特性和取舍点: 1.由于采用大量的常规机器,错误是常见的,所以需要实时监控、容错和自动修复机制。 2.文件很大,总体是TB级别的,单一的几个GB的文件很常见。也支持KB级别小文件,但优化不是必须的。 3.负载主要由两种读构成:大的流读取和小的随机读取 4.负载还包括大量的序列写,文件采用Append的方式而不是覆盖的方式进行修改。 5.系统需要实现多个客户端并发写入文件的语义。 6.高带宽比低延迟重要,目标客户端通常采用批处理的方式来交互。
1.2 API
GFS提供常规的文件系统API:create,delete,open,close,read,write,除此之外,还支持snapshot和record append. snapshot低成本复制,record append允许多个客户端并发操作时以最小的锁代价来保持原子性等。
1.3 架构
一个master + 多个chunk servers的架构,然后应用通过集成GFS客户端来和master以及相应的chunk servers通信。 可以参考论文上的Figure1图片。
文件被分成固定尺寸的chunks,根据设定存到多个chunk servers上(论文上说默认3个)。 每个chunk在创建时,被master分配了一个无法修改的全局惟一的64bit的chunk handle。 chunk servers在本地的linux文件系统上读写文件的时候通过chunk handle来
master管理所有文件的元信息:namespece,access control infomation, mapping from files to chunks, the current location of chunks。 还包括系统级别的活动: 1.chunk lease管理 2.孤儿chunk 回收 3.chunk在chunk servers之间迁移 还有master和chunk servers直接的:hearbeat和收集状态信息等。
GFS客户端访问master获取元信息,然后和chunk servers通信获取数据。 GFS client和chunk servers不会cache 传输的文件数据,因为太大了。 不过clients会cache元数据。 chunkservers不需要cache file data因为本身linux的文件系统会自由缓存常访问的文件到内存。
1.4 Signal Master
这里描述了客户端和master以及chunk servers的请求过程。
采用单一master的方式简化了整个设计,但master容易成为瓶颈,所以设计上需要注意。 比如客户端不会从 master上读写文件,客户端请求master获取文件存储在哪个chunk server上,并且将这些信息缓存一段时间。
1.5 Chunk Size
选择chunksize 为64MB,64MB比通常的文件系统区块大小(通常512Bytes)大得多,这样做的几个好处,也有一些弊端。 好处:
- 减少clients和master通信次数
- 由于chunk比较大,客户端访问一个chunk server操作的可能性比较大,也降低了网络负载。(参考原文描述)
- 减少master meatadata存储的数量
A small file consists of a small number of chunks, perhaps just one. The chunkservers storing those chunks may become hot spots if many clients are accessing the same file. In practice, hot spots have not been a major issue because our applications mostly read large multi-chunk files sequentially.
可能的解决途径:存储到更多的分片、错开访问、允许客户端从其他客户端获取等
However, hot spots did develop when GFS was first used by a batch-queue system: an executable was written to GFS as a single-chunk file and then started on hundreds of ma- chines at the same time. The few chunkservers storing this executable were overloaded by hundreds of simultaneous re- quests. We fixed this problem by storing such executables with a higher replication factor and by making the batch- queue system stagger application start times. A potential long-term solution is to allow clients to read data from other clients in such situations.
1.6 元数据Metadata
Master主要存储三类元数据: 1.file and chunk namesapces
- mapping from files to chunks
- locations of each chunk's replicas
上面都存储在master内存里。 前两者还会以"operation log"的方式持久化存储在master的硬盘上(还有checkpoint机制),并且复制给远端的机器。这样方便恢复master。 第三类数据在master启动的时候会询问chunserver相关信息,不做持久存储。
1.7 一致性模型Consistency Model
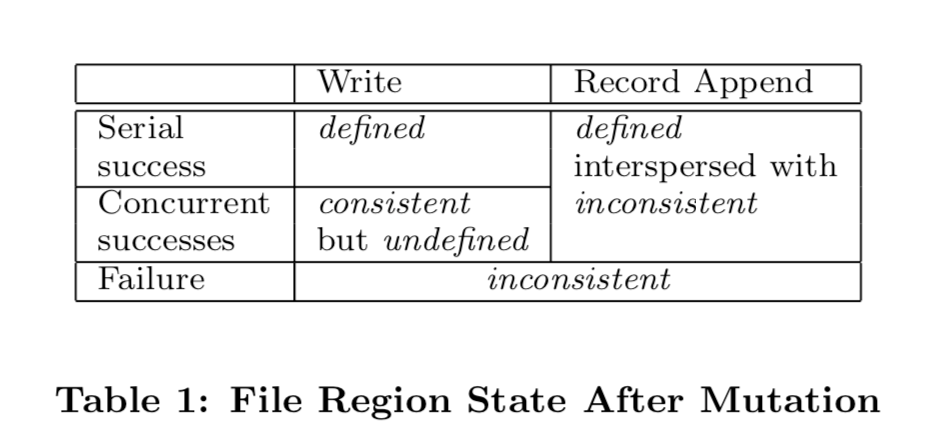
1.file namespace mutations是原子性的,由master通过锁来全局控制 2.file region的状态变化参见下面的图标table 1,与是write还是 record append以及 顺序操作、并发操作以及是否成功相关。
这些是大体是如何保证的,以及对客户端的影响,参见论文2.7
状态转换图表(论文table 1)
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK