

机器学习算法系列之三:SVM6
source link: https://flat2010.github.io/2018/04/21/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E7%AE%97%E6%B3%95%E7%B3%BB%E5%88%97%E4%B9%8B%E4%B8%89%EF%BC%9ASVM6/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
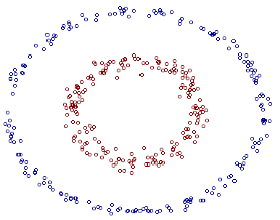
Nothing is perfect, nothing.
一、非线性
1.1 线性 VS 非线性
在本系列的前面我们已经讨论了线性可分和线性非可分问题的求解,虽然线性非可分的问题复杂了点,但终究还是在线性框架内。然而生活中有很多问题并不是咱们简单画一条或者几条直线就能解决的,比如本文开头的那张图片,你能简单的画几条直线(非折线)就把这两种类型的点区分开吗?
显然不能!也就是说这个问题在线性框架内并没有解,这就是本文要讲的非线性问题。
非线性分类问题是指通过利用非线性模型才能很好的进行分类的问题。
——《统计学习方法》P115
1.2 非线性解决方案
对于非线性问题,其解决思路很简单(然而实现起来却不是那么容易),通过将原始的非线性数据转换成线性数据→xif(→xi)→→x′i,从而实现线性分类。这种转换可以看做是一种映射,是一种非线性变换。然而这种转换却存在几个问题:
- 不容易直接找到满足要求的映射函数;
- 并非所有的情况下我们都能找到映射函数;
- 映射后可能会引起维度爆炸(因为我们通常都是将原始数据映射到一个维度更高的空间,从而使得数据线性可分),导致无法计算。
鉴于上述这些原因,我们通常不去显式的定义映射函数(将映射函数记为ϕ(x)),也就是说我们通常都不会直接去找这个映射函数。转而采用一种“投机取巧”的办法,这种方法我们通常称之为核技巧(Kernel Trick),它的思路是:
利用一个容易获取的函数,来代替不容易获得的映射函数的作用效果,从而在没有映射函数的情况下,我们也能获得映射后的运算结果。
具体点来说,对任意两个样本向量,在没有映射函数的情况下,我们也能获得其映射后的向量的内积,而获得的途径就是我们大名鼎鼎的核函数(Kernel Function),记作K(x,y)。核函数的数学表达式如下:
K(→xi,→xj)⏟核函数=ϕ(→xi)⏟映射后的→xi⋅ϕ(xj)⏟映射后的→xj⏟映射后的→xi、→xj的内积
上式(1-1)的意思就是,我将任意两个样本代入核函数进行计算,其结果与先将这两个样本映射到新空间再点积的结果等价。
为了方便理解,我画了如下的图示:
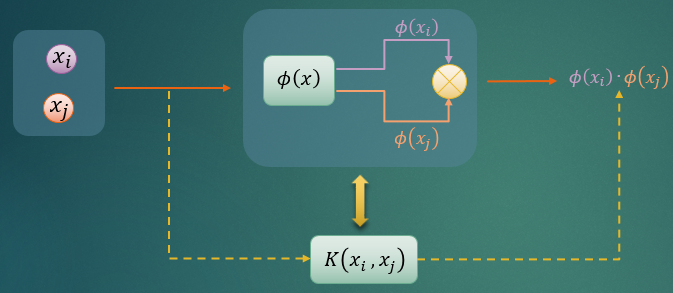
如上图所示,核函数的作用就是替代我们要找寻的映射函数的映射 + 内积效果。
原始的空间(输入空间,记为χ为欧式空间或离散集合)中,数据是非线性可分的。原始数据映射后,在映射后的新空间(特征空间/希尔伯特空间,记为H)中,数据是线性可分的。因为输入空间中数据非线性可分,所以输入空间中的分割面必然是超曲面。相反,特征空间中的分割面则是超平面。
以上这些概念暂时不懂没有关系,有个印象就可以了,我们会在后面做详细的介绍。
1.3 核函数定义之谜
那核函数为什么要定义成上述的形式呢?答案其实很简单!但是不管是网上的博客,还是出版的相关书籍,都没有对这点做出说明,Duang!直接就扔出一个东西,然后告诉你,这就是核函数。虽然这只是个很小的问题,对我们理解SVM也不会有太大影响,但就是这么小小的一个问题,对我们的逻辑思维和数学素养影响却非常大。我相信有一部分人甚至都不会想到这个问题。
为了方便叙述,我们分别记映射前后的样本为→xi、→x′i,我们有:
→x′i=ϕ(→xi)
因为映射后的数据→xi∈T′={(x′1,y′1), (x′2,y′2), …, (x′N,y′N)}已经是线性可分的,根据机器学习算法系列之三:SVM(4)中的分析,对于线性可分的数据,我们由其中的式(1-21)可以求出映射后的数据其对偶优化问题为:
min→α[12N∑i=1N∑j=1αiαjyiyj(→x′i·→x′j)−N∑i=1αi]⇕min→α[12N∑i=1N∑j=1αiαjyiyj[ϕ(→xi)·ϕ(→xj)]−N∑i=1αi]
再由其中的式(1- 28)可以求出映射后的数据其分类决策函数为:
f(x)=sign⟮N∑i=1α∗i·yi·(→x′i⋅→x′)+b∗⟯=sign⟮N∑i=1α∗i·yi·[ϕ(→xi)⋅ϕ(→x)]+b∗⟯
由上式(1-3)以及(1-4)可以看出,不管是在解最优化问题的时候,还是在求解最后的决策函数的时,我们都要先使用映射函数计算出任意样本在新空间的映射值。而我们在前面1.2小节中已经说了我们不会去找这个映射函数,更不用说去计算映射值了,而核函数的作用就是为了让我们避开这个坑。至此一切就都明朗了,核函数之所以要定义成式(1-1)的形式,就是为了用来替代(→x′i⋅→x′)=ϕ(→xi)⋅ϕ(→x)这一坨复杂的东西。
那么使用核函数替代后,上式(1-3)、(1-4)变成如下形式:
{min→α[12N∑i=1N∑j=1αiαjyiyjK(→xi,→xj)−N∑i=1αi]sign⟮N∑i=1α∗i·yi·K(→xi,→x)+b∗⟯
核函数的本质是,通过在输入空间中计算函数K(→xi,→xj)的值,我们就能获得在特征空间中的向量的内积值<ϕ(→xi), ϕ(→xj)>,并且完全不需要映射函数。
1.4 为什么用核函数
尽管已经对核函数解释了这么多,很多读者可能还是无法直观的感受到:我们为什么要用核函数?下面我们通过一个例子来说明这一点。
给定两个样本向量→x=(2,3,1,3)T、→z=(3,2,2,4)T,映射函数:
ϕ(→x)=(x21,x1⋅x2,x1⋅x3,x1⋅x4,x2⋅x1,x22,x2⋅x3,x2⋅x4,x3⋅x1,x3⋅x2,x23,x3⋅x4,x4⋅x1,x4⋅x2,x4⋅x3,x24)T
注:上述映射函数ϕ是一个R4到R16即4维空间到16维空间的映射函数。
K(→x,→z)=(→x⋅→z)2
常规做法(映射 + 内积),则有:
ϕ(→x)=(4,6,2,6,6,9,3,9,2,3,1,3,6,9,3,9)Tϕ(→z)=(9,6,6,12,6,4,4,8,6,4,4,8,12,8,8,16)Tϕ(→x)⋅ϕ(→z)=4⋅9+6⋅6+2⋅6+6⋅12+6⋅6+9⋅4+3⋅4+9⋅8+2⋅6+3⋅4+1⋅4+3⋅8+6⋅12+9⋅8+3⋅8+9⋅16=676
核函数计算,可得:
K(→x,→z)=((2,3,1,3)T⋅(3,2,2,4)T)2=(2⋅3+3⋅2+1⋅2+3⋅4)2=262=676
对比上述两个求解过程可以看出,在最终计算结果完全一致的情况下,核函数所需的计算量大幅减少。
若样本特征取值变成浮点型,并且其绝对值较大,同时映射后的维度也较大的情况下,这种计算量的节省更为可观。
在某些场景下,若映射后的维度n→∞(即映射到无限维特征空间),这时即使我们能找到合适的映射函数ϕ(→x),也会因为维度爆炸而无法计算映射后的值。而核函数却能轻而易举的解决这个难题。
综上,使用核函数的原因有如下几点:
- 1. 显著减少计算量;
- 2. 解决映射导致的维度爆炸问题(无限维空间无法计算问题);
- 3. 避免显示定义映射函数ϕ(→x)问题(难以确定);
1.5 常用核函数
虽然有了核函数让我们不必再去苦苦寻觅映射函数,那么如果没有一些较为通用的核函数供我们选择和使用,我们的问题也只是从寻找映射函数变成了寻找核函数,问题的复杂性可能并不会降低。
由此,我们提供一些比较常用的核函数以供调试、选择(关于如何选择核函数,目前学术界还没有一个具体的公式能给出答案,大多数情况下还是依赖于我们的经验同时结合实际业务来选择。)。下面就列出一些常用的核函数表达式:
名称 表达式 参数 备注
线性核函数 K(→xi,→xj)=a⋅→xiT⋅→xj+c a、c ——
多项式核函数
K(→xi,→xj)=(a⋅→xiT⋅→xj+c)d
a、c、d(d≥1)
d=1时即为线性核函数
特别适合正交归一化后的数据
高斯核函数
(RBF)
K(→xi,→xj)=exp⟮−‖→xi−→xj‖22σ2 ⟯
高斯核带宽σ>0
抗噪能力强,对参数敏感
指数核函数 K(→xi,→xj)=exp⟮−‖→xi−→xj‖2σ2 ⟯ σ>0 属于高斯核函数变种,对参数敏感性降低,适用范围相对较窄
拉普拉斯核函数 K(→xi,→xj)=exp⟮−‖→xi−→xj‖σ ⟯ σ>0 属于高斯核函数变种,对参数敏感性降低
Sigmoid核函数 K(→xi,→xj)=tanh⟮a⋅→xiT⋅→xj+c) a>0,c<0 ——
二次有理核函数 K(→xi,→xj)=1−‖→xi−→xj‖2‖→xi−→xj‖2+ c c 高斯核函数的替代品,作用域广,对参数特别敏感
ANOVA核函数 K(→xi,→xj)=exp⟮−σ(→xki−→xkj)2⟯d σ>0,d≥1 也属于RBF核函数,适用于多维回归问题
多元二次核函数 K(→xi,→xj)=(‖→xi−→xj‖2+ c2)0.5 c 可替代二次有理核,非正定核函数
逆多元二次核函数 K(→xi,→xj)=(‖→xi−→xj‖2+ c2)−0.5 c 不会导致核相关矩阵奇异
对数核函数 K(→xi,→xj)=−log(1 + ‖→xi−→xj‖d) d 图像分割上经常使用
字符串核函数 K(s,t)=∑u∈Σn∑(i,j):s(i)=t(j)=uλl(i)λl(j) n、λ 文本分类,信息检索广泛使用
圆形核函数 K(→xi,→xj)=2πarccos(−∥→xi−→xj∥σ)−2π∥→xi−→xj∥σ(1−∥→xi−→xj∥2σ)0.5 σ ——
球形核函数 K(→xi,→xj)=1−32∥→xi−→xj∥σ+12(∥→xi−→xj∥2σ)3 σ 圆形核函数的简化版
波动核函数 K(→xi,→xj)=θ∥→xi−→xj∥sin(∥→xi−→xj∥θ) θ 适用于语音处理
曲线核函数 K(→xi,→xj)=1+→xti⋅→xj+→xti⋅→xjmin(→xi,→xj)−→xi+→xj2min(→xi,→xj)2+13min(→xi,→xj)3 t ——
Bessel核函数 K(→xi,→xj)=Jv+1(σ∥→xi−→xj∥)∥→xi−→xj∥−n(v+1) σ、n ——
泛化T-Student核函数 K(→xi,→xj)=11+∥→xi−→xj∥d d mercer核
参考链接:
1.5 非线性支持向量机
针对非线性数据,利用核函数学习出来的分类决策模型即为非线性支持向量机。训练样本中,参与了分割超平面决策的这些我们称为非线性支持向量。
非线性支持向量机的分类决策函数表达式如下:
f(x)=sign⟮N∑i=1α∗i·yi·K(→xi,→x)+b∗⟯=sign⟮N∑i=1α∗i·yi·K(→xi,→x)⏟→w⋅→x+⟮yj−N∑i=1α∗i⋅yi⋅K(→xi,→xj)⟯⏟b∗⟯
由上式可以看出,对于b∗的求解,我们也换成了核函数。同线性可分情况一样,要求解b∗,只需要选择一个由上式(1-5)第一个式子求解出来的满足0<α∗j<C的拉格朗日乘子计算即可。
非线性分类决策函数的求解过程与线性可分情况下的求解是一样的,只不过目标函数里面相应的内积替换成了核函数。另外有一点需要特别说明的是,对于非线性支持向量机的求解,我们通常都不会去求→w∗的表达式,因为其求解需要利用映射后的样本,如下所示:
→w∗=N∑i=1α∗i⋅yi⋅→x′i=N∑i=1α∗i⋅yi⋅ϕ(→xi)
因此我们通常都是直接利用核函数求解出式(1-6)的分类决策函数。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK