

Dubbo代码分析—超时和重试设计
source link: https://wangxin.io/2019/02/11/dubbo/dubbo_timeout_design_and_principle/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Dubbo代码分析—超时和重试设计
dubbo提供在provider和consumer端,都提供了超时(timeout)和重试(retries)的参数配置。
一、Dubbo协议中的超时机制
超时机制是dubbo中的一个很重要的机制。在“快速失败”设计中,能将客户端断掉,防止服务端资源耗尽而被压挂。
我们先看一下Dubbo协议中的超时机制是怎么实现的。
超时的实现原理是什么?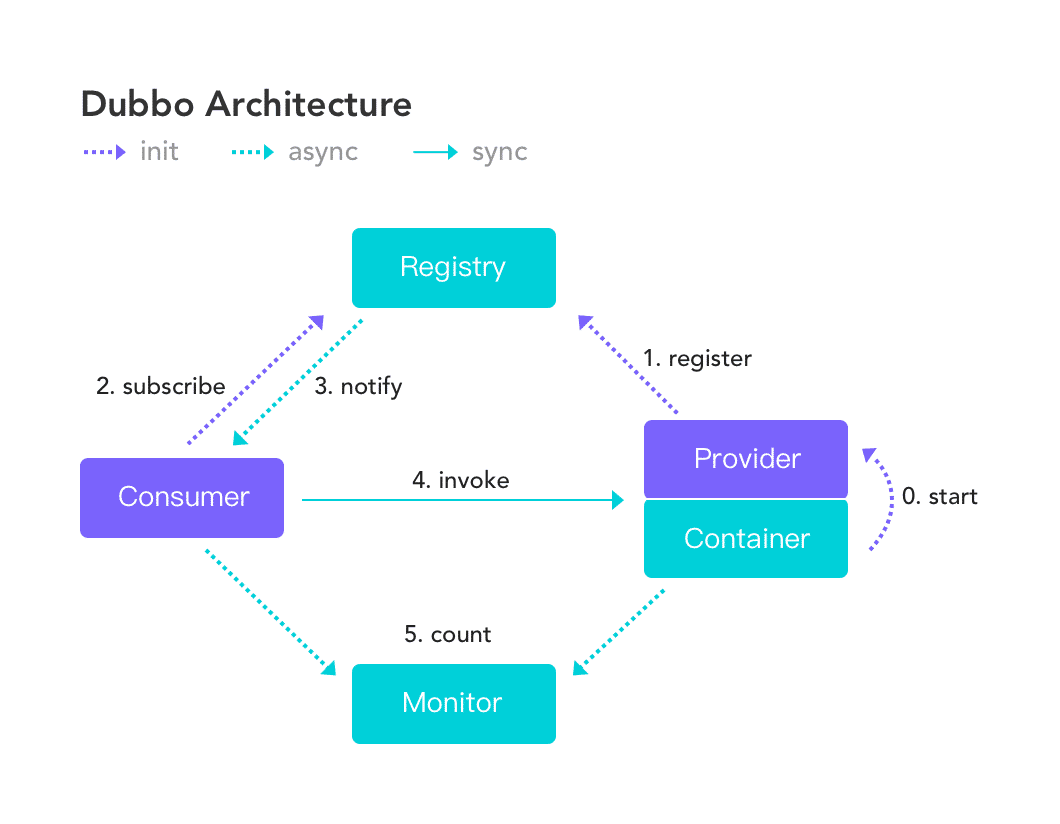
我们先回顾一下dubbo的大致流程图。
在生产过程中都是客户端向服务端发送请求,在流程4。
我们可以看到:4的流程是: 服务消费者,从提供者地址列表中,基于软负载均衡算法,选一台提供者进行调用,如果调用失败,再选另一台调用。
超时是针对消费端还是服务端?
- 如果是争对消费端,那么当消费端发起一次请求后,如果在规定时间内未得到服务端的响应则直接返回超时异常,但服务端的代码依然在执行。
- 如果是争取服务端,那么当消费端发起一次请求后,一直等待服务端的响应,服务端在方法执行到指定时间后如果未执行完,此时返回一个超时异常给到消费端。
dubbo的超时是争对客户端的,由于是一种NIO模式,消费端发起请求后得到一个ResponseFuture,然后消费端一直轮询这个ResponseFuture直至超时或者收到服务端的返回结果。虽然超时了,但仅仅是消费端不再等待服务端的反馈并不代表此时服务端也停止了执行。
超时的实现原理是什么?
之前有简单提到过, dubbo默认采用了netty做为网络组件,它属于一种NIO的模式。消费端发起远程请求后,线程不会阻塞等待服务端的返回,而是马上得到一个ResponseFuture,消费端通过不断的轮询机制判断结果是否有返回。因为是通过轮询,轮询有个需要特别注要的就是避免死循环,所以为了解决这个问题就引入了超时机制,只在一定时间范围内做轮询,如果超时时间就返回超时异常。
//ResponseFuture接口定义
public interface ResponseFuture {
/**
* get result.
*
* @return result.
*/
Object get() throws RemotingException;
/**
* get result with the specified timeout.
*
* @param timeoutInMillis timeout.
* @return result.
*/
Object get(int timeoutInMillis) throws RemotingException;
/**
* set callback.
*
* @param callback
*/
void setCallback(ResponseCallback callback);
/**
* check is done.
*
* @return done or not.
*/
boolean isDone();
}
//ReponseFuture的实现类:DefaultFuture
//只看它的get方法,可以清楚看到轮询的机制。
public Object get(int timeout) throws RemotingException {
if (timeout <= 0) {
timeout = Constants.DEFAULT_TIMEOUT;
}
if (! isDone()) {
long start = System.currentTimeMillis();
lock.lock();
try {
while (! isDone()) {
done.await(timeout, TimeUnit.MILLISECONDS);
if (isDone() || System.currentTimeMillis() - start > timeout) {
break;
}
}
} catch (InterruptedException e) {
throw new RuntimeException(e);
} finally {
lock.unlock();
}
if (! isDone()) {
throw new TimeoutException(sent > 0, channel, getTimeoutMessage(false));
}
}
return returnFromResponse();
}
超时解
超时的实现原理是什么?
之前有简单提到过, dubbo默认采用了netty做为网络组件,它属于一种NIO的模式。消费端发起远程请求后,线程不会阻塞等待服务端的返回,而是马上得到一个ResponseFuture,消费端通过不断的轮询机制判断结果是否有返回。因为是通过轮询,轮询有个需要特别注要的就是避免死循环,所以为了解决这个问题就引入了超时机制,只在一定时间范围内做轮询,如果超时时间就返回超时异常。
二、Dubbo协议中的重试机制
在客户端int DEFAULT_RETRIES = 2;
看到重试次数是2 ,就是说出了本身的一次请求,再失败后,又会再请求一次。
重试策略在集群的失败重试 FailoverClusterInvoker 的策略中:
public Result doInvoke(Invocation invocation, final List<Invoker<T>> invokers, LoadBalance loadbalance) throws RpcException {
List<Invoker<T>> copyInvokers = invokers;
checkInvokers(copyInvokers, invocation);
String methodName = RpcUtils.getMethodName(invocation);
int len = getUrl().getMethodParameter(methodName, RETRIES_KEY, DEFAULT_RETRIES) + 1;
if (len <= 0) {
len = 1;
}
// retry loop.
RpcException le = null; // last exception.
List<Invoker<T>> invoked = new ArrayList<Invoker<T>>(copyInvokers.size()); // invoked invokers.
Set<String> providers = new HashSet<String>(len);
for (int i = 0; i < len; i++) {
//Reselect before retry to avoid a change of candidate `invokers`.
//NOTE: if `invokers` changed, then `invoked` also lose accuracy.
if (i > 0) {
checkWhetherDestroyed();
copyInvokers = list(invocation);
// check again
checkInvokers(copyInvokers, invocation);
}
Invoker<T> invoker = select(loadbalance, invocation, copyInvokers, invoked);
invoked.add(invoker);
RpcContext.getContext().setInvokers((List) invoked);
try {
Result result = invoker.invoke(invocation);
......
可以看到使用的是for循环做的失败重试的。当有异常发生时候,就重试一次访问,直到达到最大重试次数为止。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK