

YDB – An open-source Distributed SQL Database
source link: https://ydb.tech/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

YDB is an open-source Distributed SQL Database that combines high availability and scalability with strong consistency and ACID transactions.
True Elastic Scalability
Fault-tolerant
Easy to use
Automatic disaster recovery
Available in any cloud
Open Source
No risk of cloud or vendor lock-in.
Success stories
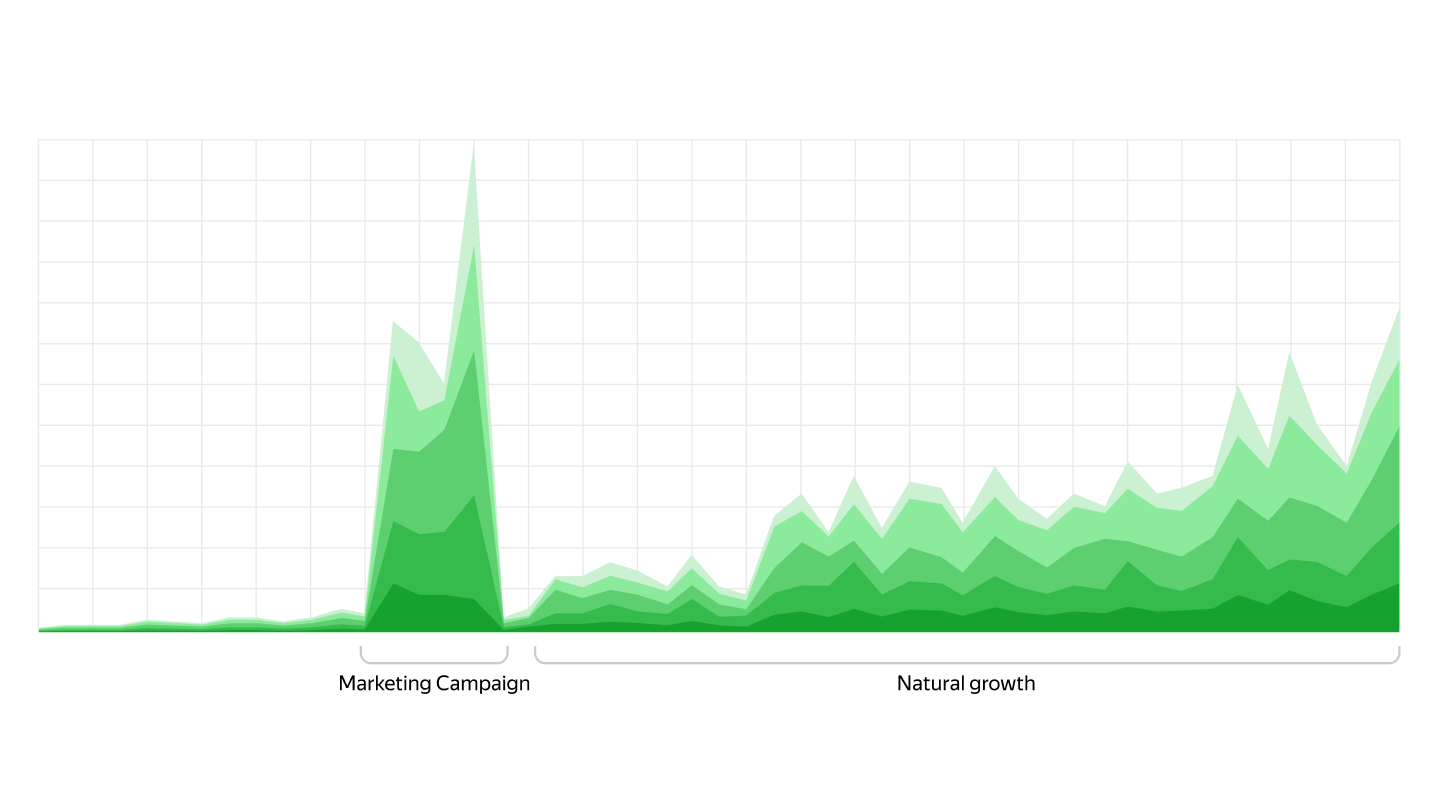
Market Cart
The Cart is one of the key components of any marketplace or online store.
Using YDB as a database allowed Market Cart to withstand a hundredfold increase in the load on the Cart, while observing strict guarantees for response times.
Moreover, the migration was completed by just one developer in one month.
Use cases
How it works
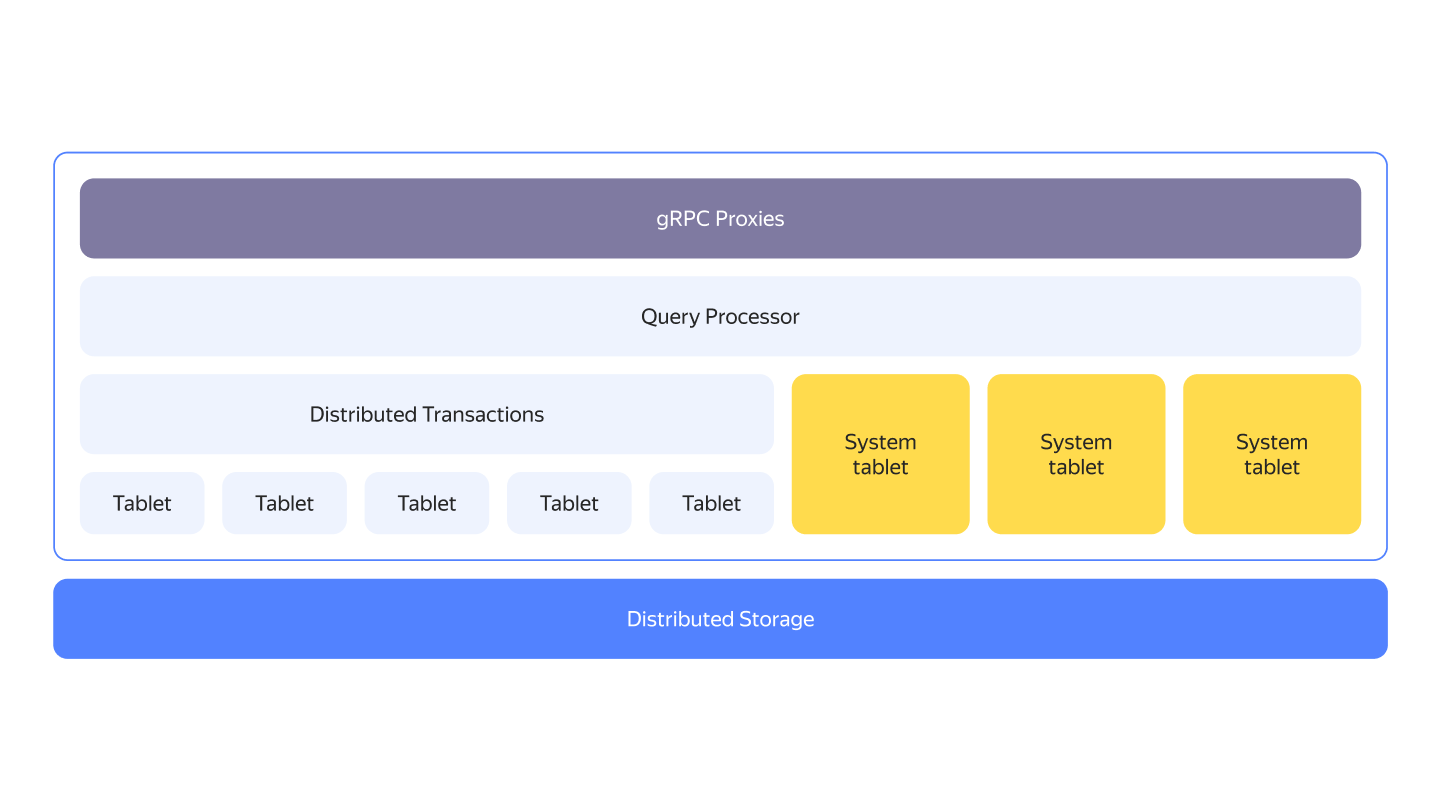
YDB architecture
We use commodity hardware and shared-nothing architecture, disaggregated compute and storage layers, and build a system based on logical components - tablets.
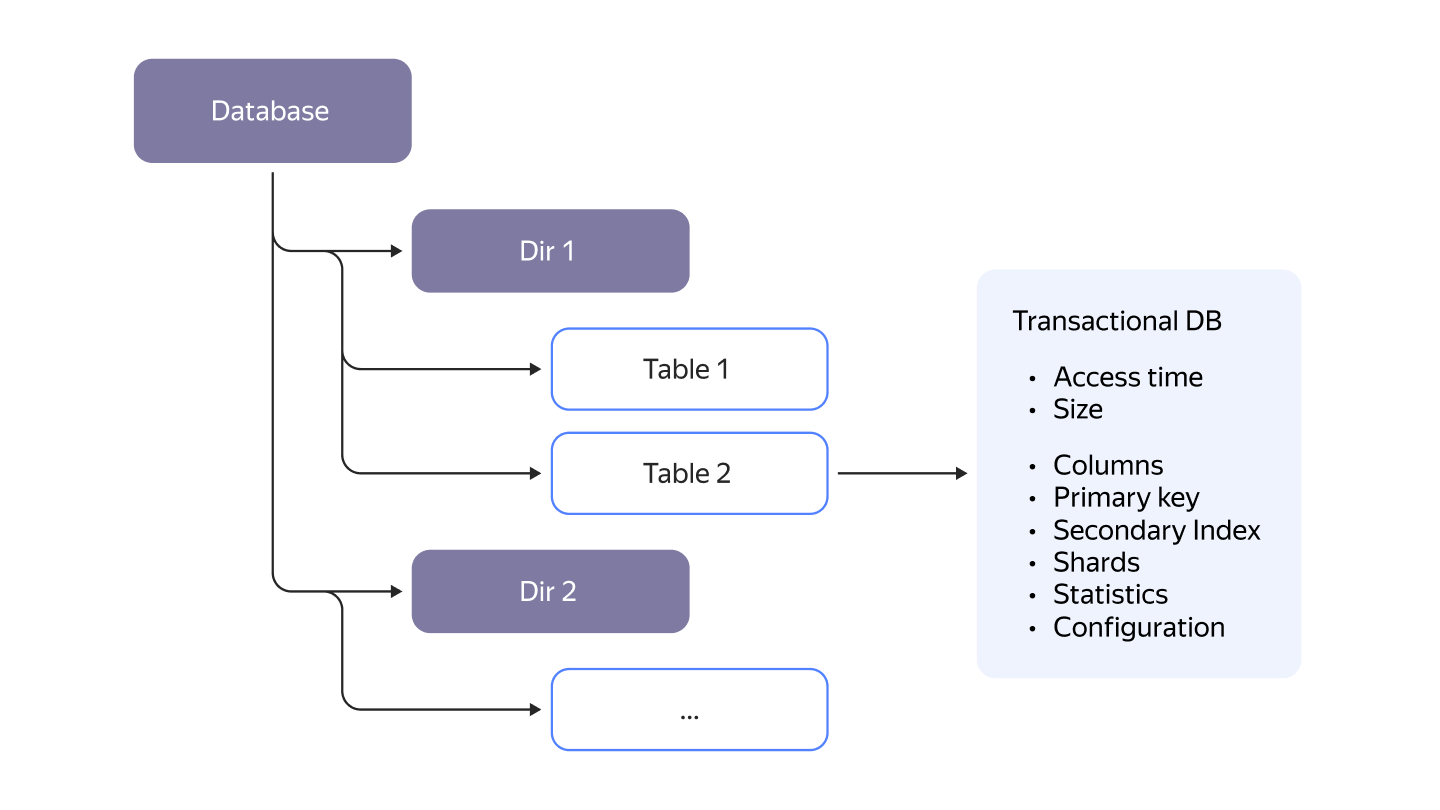
Hierarchy
Similar to a file system tables could be organized into a hierarchy using directories.
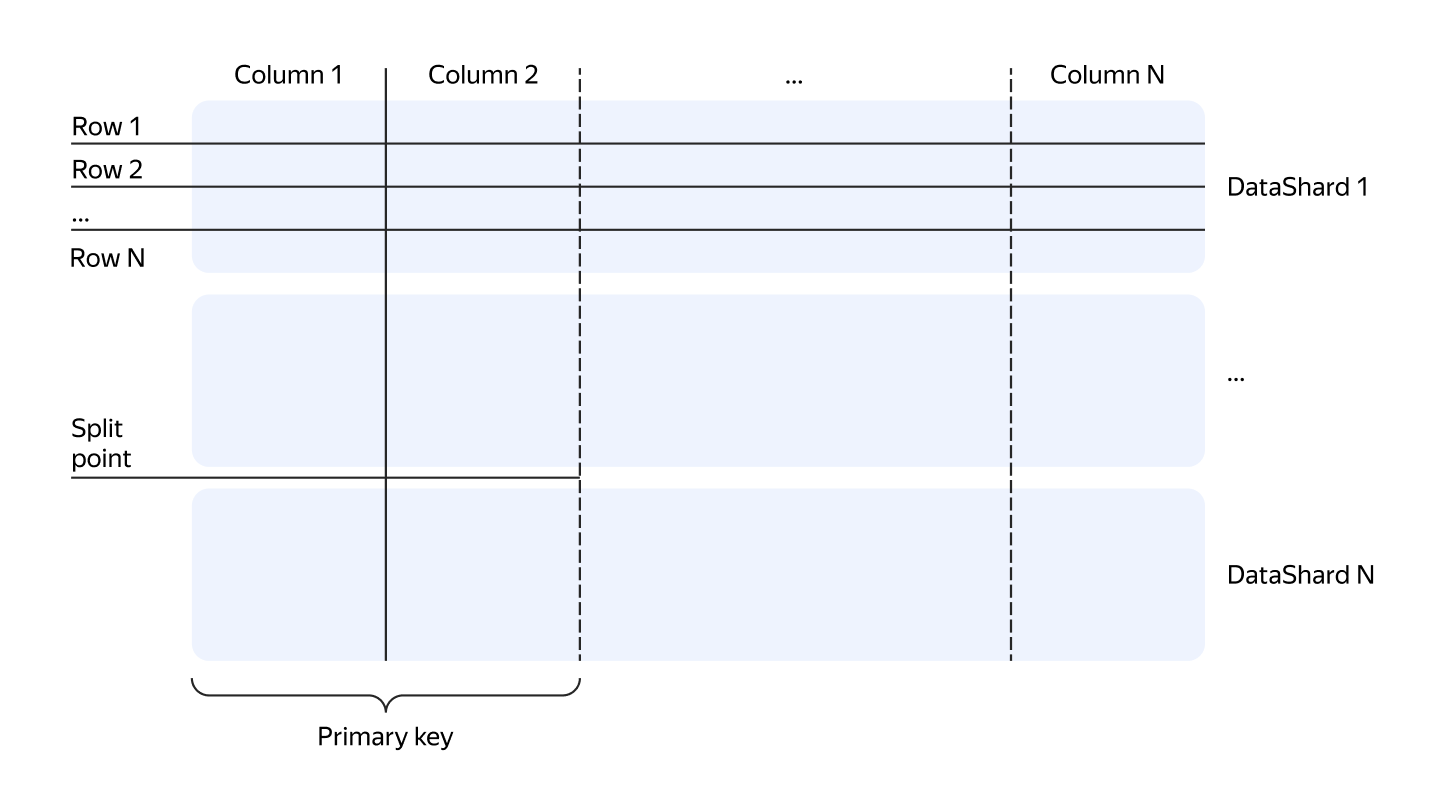
Table
YDB provides users with a familiar abstraction: tables. Tables must contain a primary key, the data is sorted by the primary key. Tables are automatically sharded by primary key range by size or load.

Split by load
The tablet will automatically split when the load increases.
.png)
Split by size
The tablet will automatically split when the size increases.
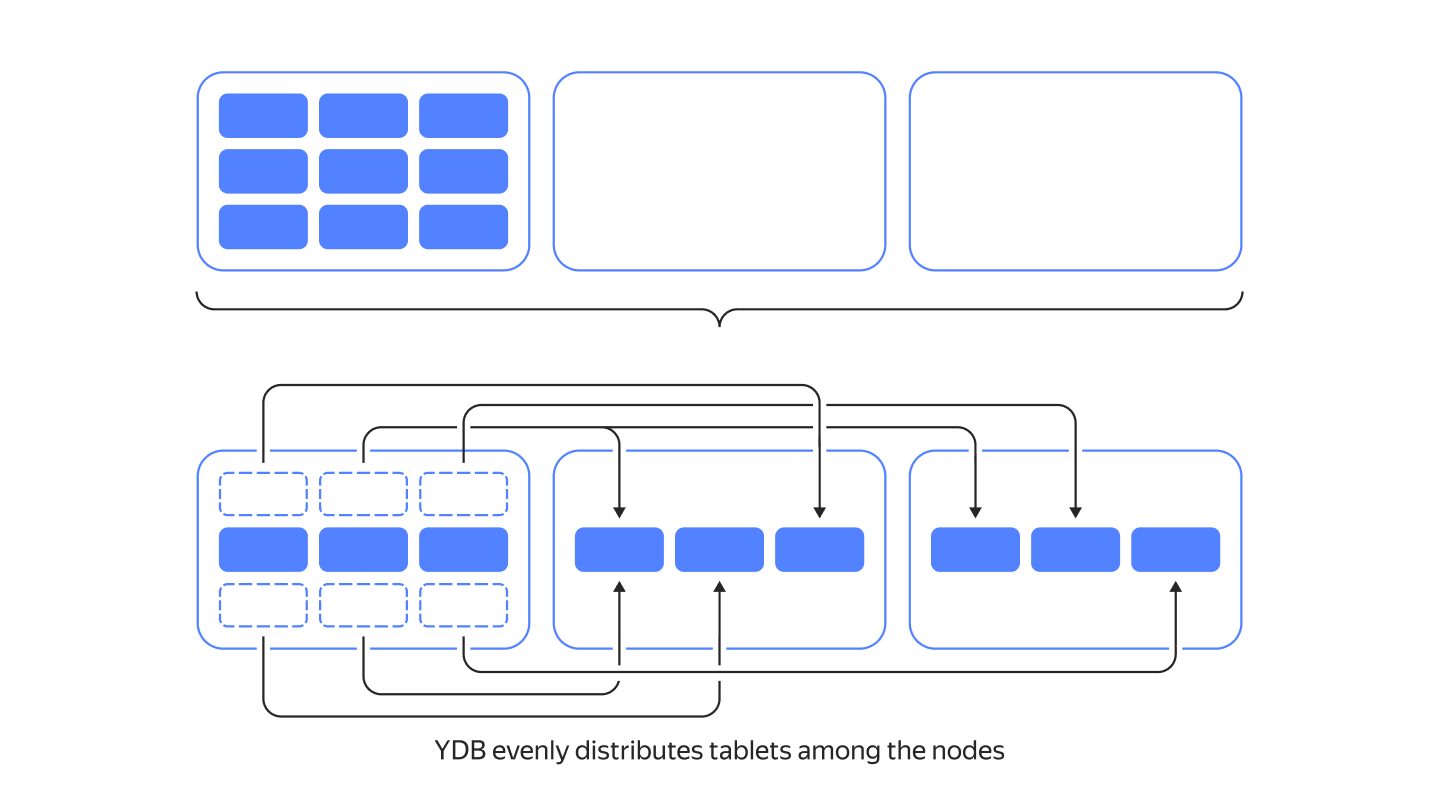
Automatic balancing
YDB evenly distributes tablets among the nodes, and moves loaded tablets from loaded nodes. CPU, Memory, Network metrics are tracked.
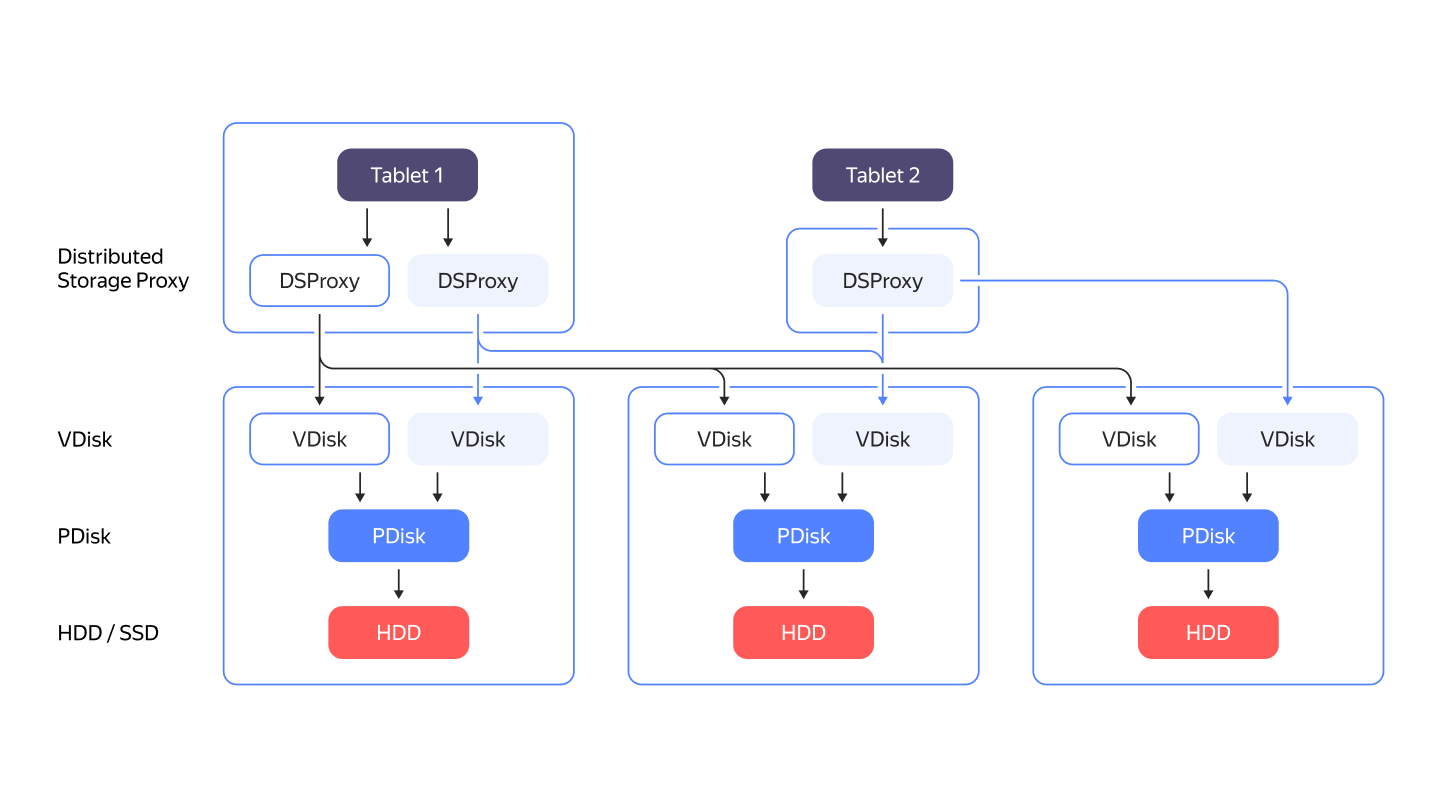
Distributed Storage Internals
We write all the code for working with block devices ourselves. The PDisk component is responsible for working with the block device. Above PDisk is the VDisk abstraction layer. There is a special component — DSProxy between the tablet (part of the table) and VDisk. DSProxy analyzes disk availability and characteristics and depending on it can make a decision to exclude the disk from work.
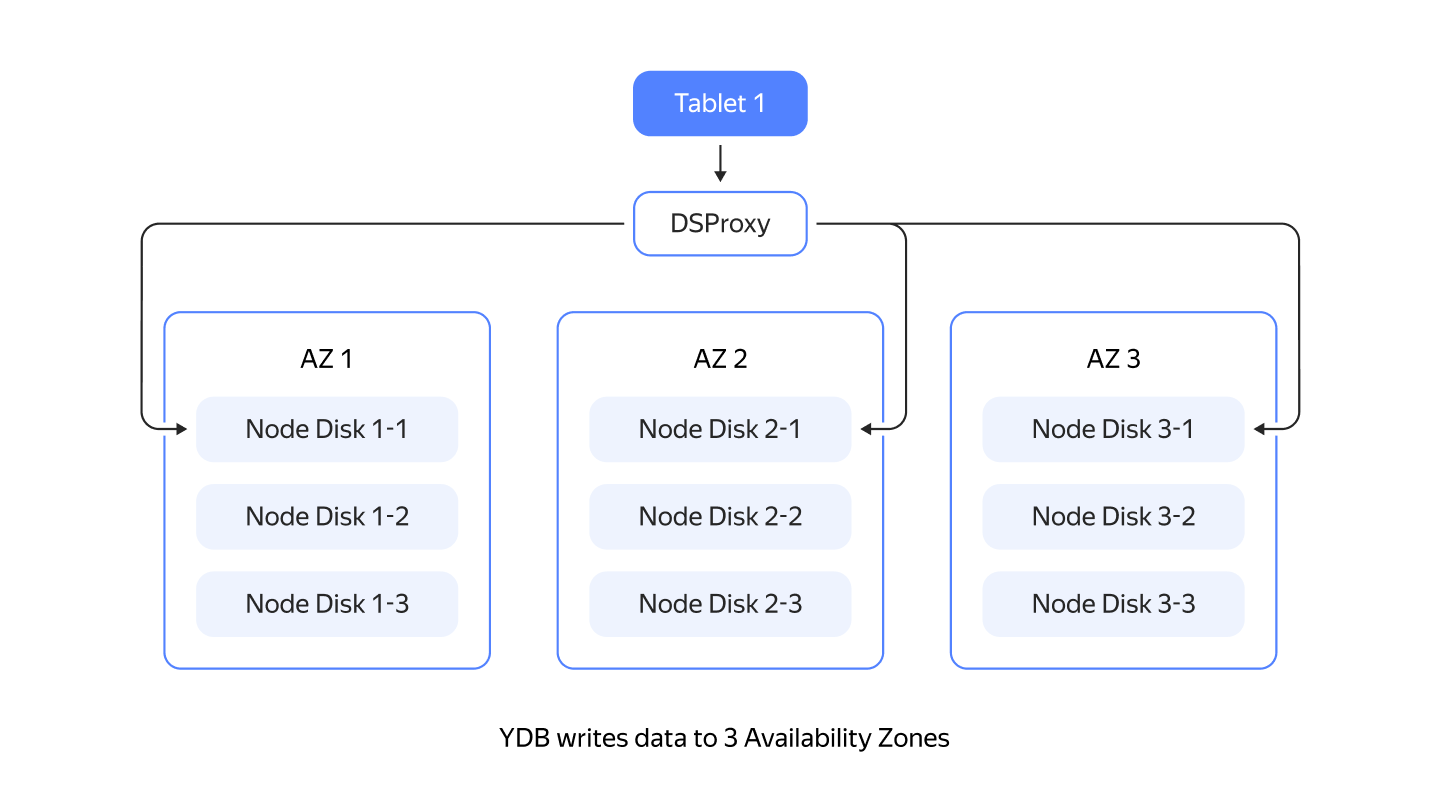
DSProxy
YDB writes data to 3 Availability Zones, doesn’t send requests to obviously bad disks, and continues to operate without interruption even if one AZ and a disk in another AZ are lost.
How to start
Docker
Pull the current public version of the Docker image:
docker pull cr.yandex/yc/yandex-docker-local-ydb:latest
Create a working directory and start the container from it:
docker run -d --rm --name ydb-local -h localhost -p 2135:2135 -p 8765:8765 -p 2136:2136 -v $(pwd)/ydb_certs:/ydb_certs -v $(pwd)/ydb_data:/ydb_data -e YDB_DEFAULT_LOG_LEVEL=NOTICE -e GRPC_TLS_PORT=2135 -e GRPC_PORT=2136 -e MON_PORT=8765 cr.yandex/yc/yandex-docker-local-ydb:latest
Go to the Getting started — Self-hosted deploy — Docker in the YDB documentation to get detailed information.
YDB in a nutshell
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK